详解BLIP-2的来龙去脉
本文系统梳理了多模态预训练模型的发展脉络,重点分析了ALBEF、BLIP和BLIP-2三个关键模型的技术演进。ALBEF通过双塔结构和动量模型解决了数据噪声问题;BLIP引入MED架构实现了理解与生成任务的统一,并提出了CapFilt数据清洗方法;BLIP-2创新性地采用Q-Former作为桥梁,在冻结视觉和语言大模型参数的情况下实现高效跨模态学习。这三个模型分别针对训练效率、任务扩展性和参数效率
最近在学习多模态的知识,发现了BLIP-2这篇论文,想讲好BLIP-2,就不能只讲BLIP-2
BLIP-2的作者是Junnan Li,新加坡Saleforce亚洲研究院高级研究科学家,先后发表的ALBEF,BLIP,BLIP-2都是Junnan Li大佬的杰作
既然ALBEF,BLIP,BLIP-2有先后关联,我们就从ALBEF讲起
Vision-and-Language Pre-training(VLP)视觉文本预训练任务,也是现在常说的VLP任务。ALBEF其实是总结了当时VLP模型的优点而诞生的(VSE、CLIP、ViLBERT、UNIBERT、ViLT……),当时VLP模型的方法是什么样的?这里我们引用ViLT论文的一张图片,这张图片清晰的总结了之前方法的结构,能够直观表达优缺点
ViLT的作者为了更好凸显ViLT的优势,将当时所有VLP的模型通过两点进行分类:(1)视觉和文本模型的表达力度是否均衡(用了多少参数量/计算量)(2)两个模态的融合
VE:Visual Embedding 视觉嵌入(视觉特征)
TE:Textual Embedding 文本嵌入(文本特征)
MI:Modality Interaction 模态交互(视觉特征和文本特征的融合)
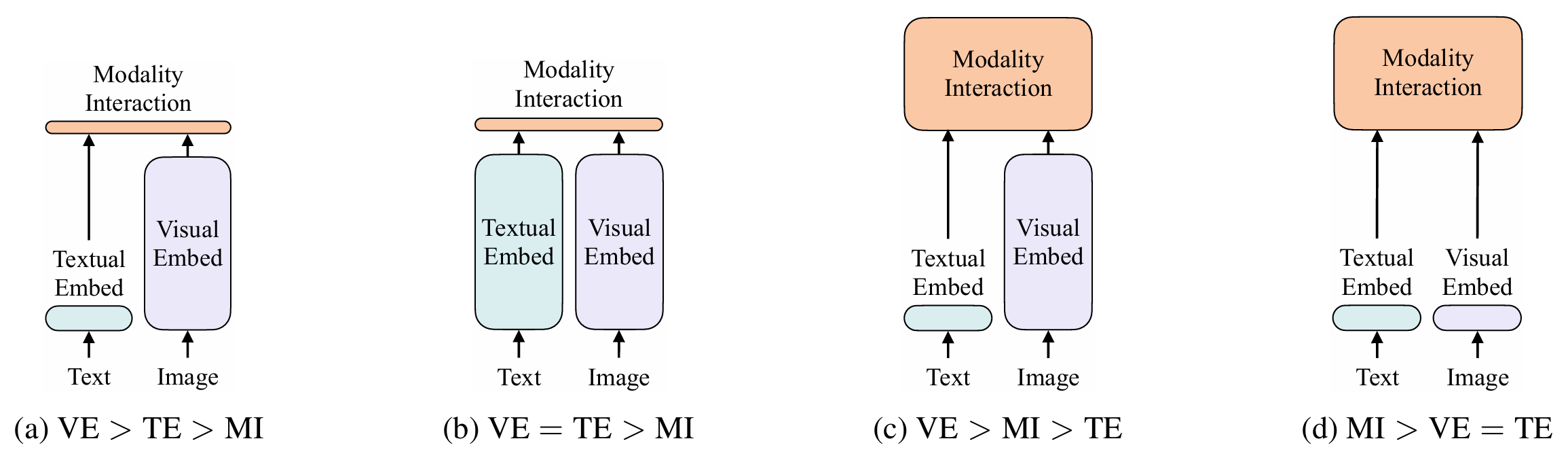
(a)类代表方法是VSE,VE文本特征提取很轻量,TE视觉特征提取很复杂,而MI两个模态融合也很轻量,只是通过一个简单的点乘或者一个非常浅层的神经网络,所以VE>TE>MI
(b)类代表方法是CLIP,VE和TE的表达力度是一样的,所用模型在计算量上基本是等价的,所以VE=TE,在训练时通过对比学习,让已有的图像文本对在空间上拉得更近,让不是一个对的在空间上离得更远,从而学习到很好的图像文本特征。但是MI也很轻量,一个简单的点乘,所以CLIP模型在做模型抽取特征是很强大的,在做图像文本匹配或图像文本检索的任务时非常高效,但是在做VQA视觉问答等就略逊一筹,因为最后模态特征的融合做的很简单,一个不可学习的简单的点乘是没办法做到更深层次的学习的
(c)类代表方法是ViLBERT/UNIBERT,基本80%的工作围绕在这一类,TE轻量,VE采用目标检测的系统非常贵,MI也很重工,也存在transformer模型,所以整体在很多下游方法的效果很好,但不可避免的是所需时间非常大,资源消耗也很大
Detector-based Methods目标检测模型:是前三种方法都使用的一个视觉模型特征提取器,因为它可以提取到图片中的object目标和region区域,会与文本一起训练,这么做的原因是视觉transformer还没有火起来,缺点是计算复杂度非常大,而且这些数据集比如coco数据集,每张图片包含的物体信息含量是很少的,物体类别数是有限的,所以整个模型性能往往就受限于此。
(d)类代表方法就是画出这张图的ViLT,它巧妙之处在于去掉了VE中的目标检测模型,而是使用了一个简单的patch embedding,极大减轻了计算时间,让TE和VE都很轻量,而MI融合的时候比较复杂能够很好的融合两个模态特征,不过ViLT也是有缺点的,它的性能不高,一些分数是比不过c类中的方法的,它虽然推理时间缩短极大(论文也都是围绕这一非常抓人的特点展开故事),但是它的训练时间非常非常慢,只是在结构上简化了多模态学习,但实际上所需的资源还是非常巨大
在ViLT这篇论文出世之后,其实很少有人讨论这篇论文,很多人都来引用这张图片,ViLT这篇论文是有一偏综述的,因为这张图片清晰的总结了之前方法的结构,简单直观的形式表达了各种方法的优缺点。同时也告诉我们,对现有领域内一些比较好的方法进行分类,是非常有助于我们理解学习的,而且也很有可能理解当前领域的痛点,从而有一些新的idea,所以写一篇综述,不管是投到什么级别,写这一篇论文的意义是远远大于这篇论文中稿的意义。因为在写论文的同时还能锻炼写作能力,不读几十上百篇论文,是无法很好的涵盖该领域的好方法并且找到它们之间的关系从而让逻辑合理有说服力。
总结一下前面VLP模型的特点以及之后应该做那些改进的假设呢?
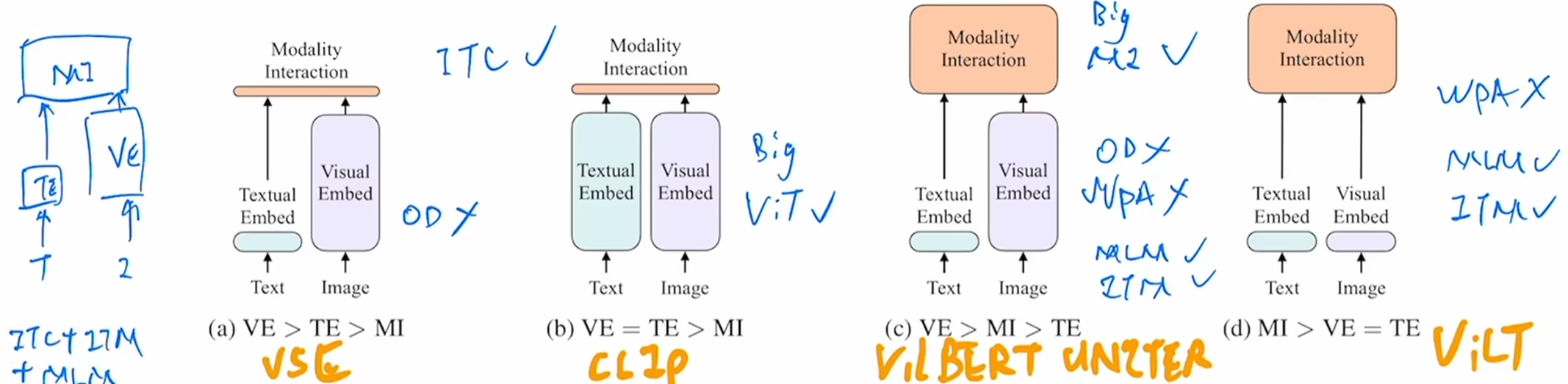
在模型结构来看,通过图像和文本的输入来获取特征,一般的纯文本任务一块4090甚至3090几个小时就能跑,而涉及到图像的任务一般都要两块或者一块更高级别的跑几十小时。所以这其中视觉特征是远远大于文本特征的。所以使用一个更大更好的视觉模型是必要的,同时模态之间的融合也是非常关键的,也需要一个更大更好的模型,所以总结出来一个好的多模态模型的网络结构应该很像c类,TE<VE同时MI也尽可能地大,当然VE不再使用目标检测模型,可以换成Vision Transformer等等而不是像d类只有一个简单的patch embedding去做
模型有了(类似于c),接下来改怎么训练呢?
CLIP模型采用了对比学习的loss——Image Text Contrastive(ITC loss)是有效的,采纳√
以前的c类方法因为VE使用了目标检测模型,所以提出了Word Patch Alignment(WPA loss),我们并不打算继续采用目标检测模型,并且在ViLT论文中证实WPA loss算的非常慢 无效×
剩下常用的还有两个loss,Mask Language Modeling(MLM loss)BERT的训练方式,遮住一个词再去预测一个词,还有一个是Image Text Matching(ITM loss)在之前的c和d中都表现的很好,这两个loss都采纳√
所以对于一个好的模型来说,loss采用ITC + ITM + MLM的方式应该会不错
我们直接来看ALBEF的框架:
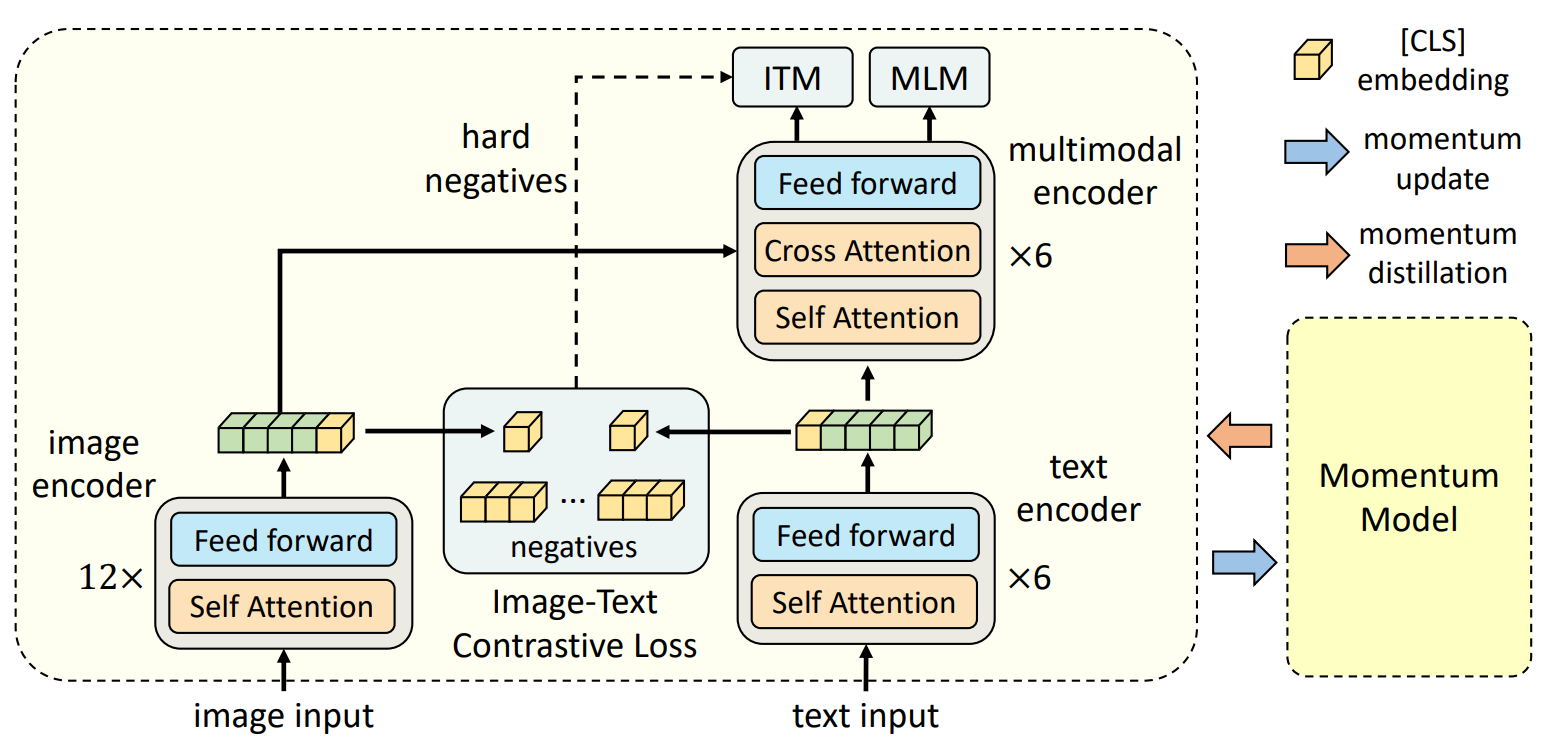
从结构来说,image ecoder也就是我们说的VE,采用了12层的Transformer Base Model;在text encoder文本部分也就是TE,把一个12层的Bert Model分成了两个6层的,前6层用来做text encoder文本编码器,后6层用来做多模态融合编码器也就是MI,满足了我们之前的假设TE<VE同时MI也尽可能地大
从loss来说,ALBEF在图文特征提取使用ITC loss,在图文特征融合使用 ITM loss和 MLM loss去训练模型
之所以我们能通过之前方法的对比和总结,得到接下来研究方向的一些假设,并且真的被一些后续的工作所验证,这并不是巧合。因为大部分工作的出发点/研究动机就是在总结前人工作的优缺点中得到的,所以如果目前没有idea,还是需要阅读更多的文献,不只是读,更重要的是做总结,一篇文章哪些是可取的,哪些是要避免或者最好移除掉的,通过总结对比,大多数时候能给你一个明确的方向
ALBEF (Align before Fuse)
顾名思义就是在融合之前的对齐,在ALBEF之前,多模态模型主要分为两类:
-
单流(Single-stream): 把图片和文本特征直接由一个 Transformer 处理(太慢)。
-
双流(Dual-stream): 图片和文本分开编码(交互性弱)。
此外,网络爬取的图片-文本对(Web Data)通常充满噪声(图片和文字不匹配),直接训练效果不好。
什么是爬取的图片-文本对充满噪声?
以这张图为例,不考虑其他因素,这张图描绘的其实是夕阳下,飞跃湖面的鸟群。但在网络上对于这张图片的解释是在我房子附近的一座桥上看到的景色,这就是噪声。

ALBEF 采用了一个双塔结构(独立的图像编码器 ViT 和文本编码器 BERT),但在它们进入多模态融合层(Fusion Encoder)之前,先通过对比学习(ITC loss)拉近图片和文本的特征距离。
为了解决噪声数据问题,ALBEF 引入了一个动量模型(Momentum Model)作为“老师”,生成伪标签(Pseudo-targets)。如果网上的文字描述不准确,模型会通过“老师”的指导,学习图片真正的内容,而不是死记硬背错误的标签。
比如这我们把原句中的remote(偏远的)隐藏,变成,一个什么样的瀑布隐匿森林中?
这个例子是用MLM生成的伪标签,其实前5个最可能的词比原句中的remote都要好,也就是说其实这里用remote不是最合适的

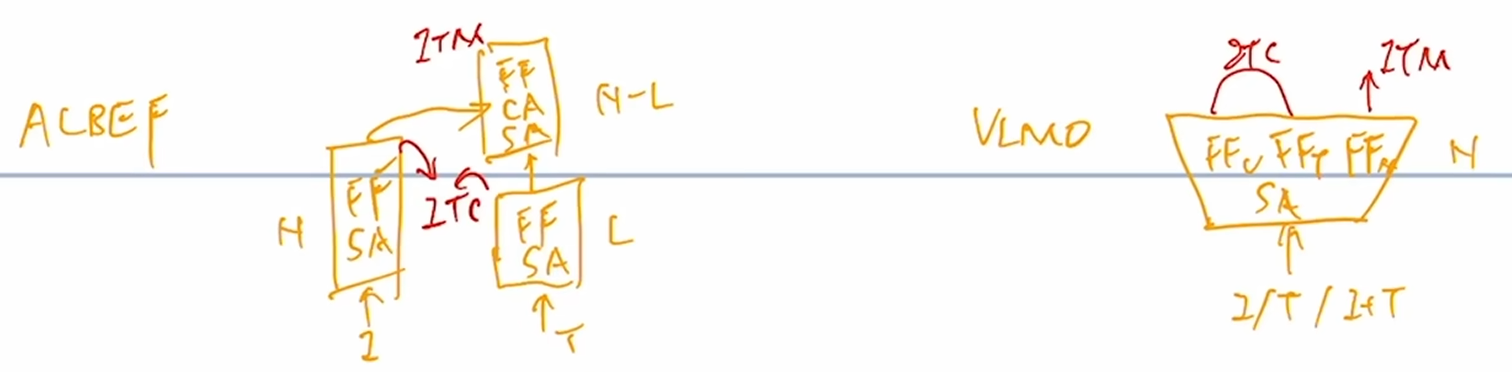
我们刚才说ALBEF的结构分三部分,左边一个N层的图像编码器,右边一个L层的文本编码器,以及一个N-L层的多模态编码器,一个图像进入图像编码器获得图像特征,一个文本进入文本编码器获得文本特征,得到对应的图像文本特征后做一个ITC loss把图像文本特征学好,然后文本特征继续进入self-attention layer去学习,图像特征通过一个cross-attention layer然后和文本特征进行融合,经历N-L层的多模态编码器后得到多模态的特征,最后用这个多模态的特征做ITM任务从而训练更好的模型。其实L层的文本编码器和N-L层的多模态编码器是一个文本编码器劈成两份,这个我们前面讲过了,但其实计算量还是存在,并且不够灵活
那么这时候VLMO出现了,它设计了一个Mixer of Expert,MoE网络让它变得极其灵活,只有一个网络,self-attention layer全部共享参数,唯一根据模态不同改变的地方就是Feed Forward Network,Feed Forward Attacks和Feed Forward Multi Model,用这个区别各个模态,这样训练时候是一个统一的模型,推理的时候根据不同任务进行选择
如果说ALBEF是结合了前人的经验,BLIP就是结合了ALBEF和VLMO的经验。
BLIP (Bootstrapping Language-Image Pre-training)
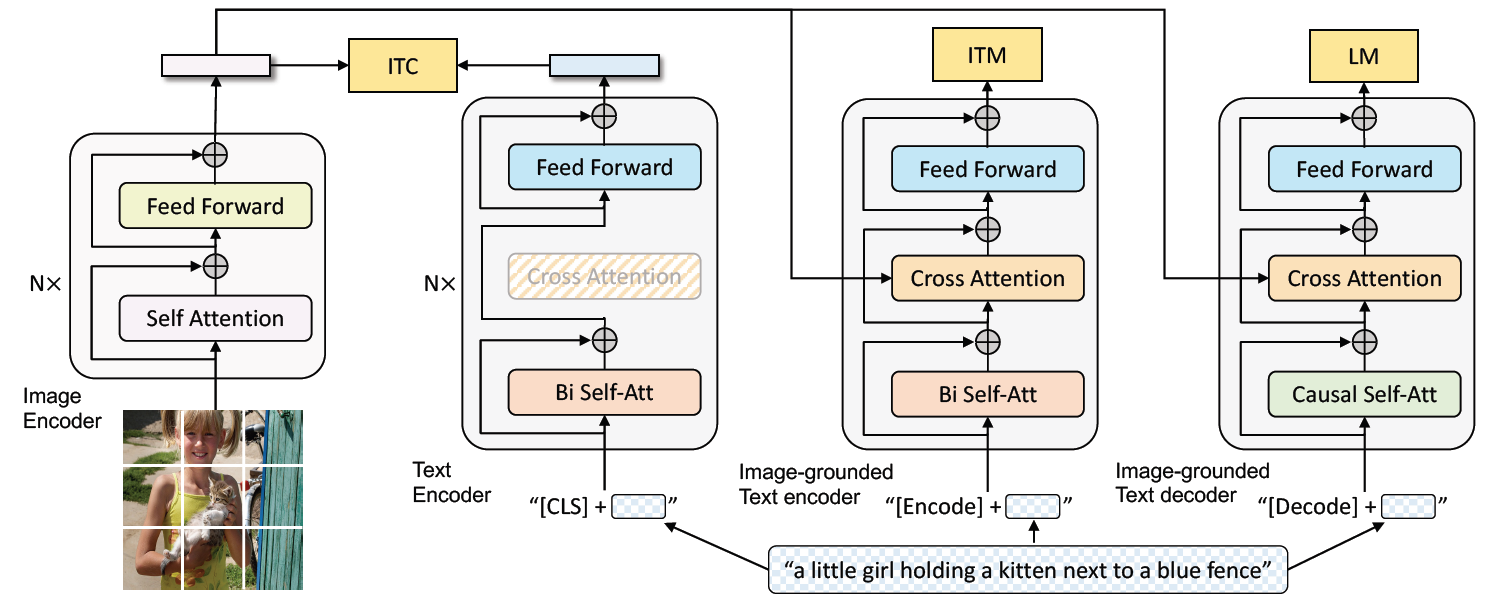
文章把BLIP的模型结构称为MED(Mixture of Encoder and Decoder),BLIP的结构由四部分组成,一个图像模型,三个文本模型(包含多模态)。如果我们不看最后一列的模型,并且把ITM这列放到ITC上面,这其实就是ALBEF,但不同之处在于BLIP采用了和VLMO一样的只有一个网络,根据模态的不同进行不同选择,并且共享参数。
ALBEF 通常擅长“理解”任务(如图文检索),但不擅长“生成”任务(如图像描述 Captioning)。并且网络数据的噪声问题依然存在,单纯靠模型内部机制(如 ALBEF 的蒸馏)还不够彻底。
对于生成的问题,BLIP 设计了一个灵活的架构,可以根据任务切换模式:
-
Unimodal Encoder: 单独编码文本/图像。
-
Image-grounded Text Encoder: 用于理解任务(如 VQA)
-
Image-grounded Text Decoder: 用于生成任务(如 Captioning)
这使得 BLIP 既能做理解,也能做生成
我们刚才说的最后一列LM,就是添加的能够用于生成的Decoder,进入的第一层发生了改变,采用了causal Self-Att因果关系自注意力机制,因为我们做生成的时候是不能看到完整的原始句子,要mask掉一部分,如果看到了它岂不是会100%生成一模一样的原始句子。所以这里和其他输入第一层的颜色不同,不同颜色之间是无法共享参数的。
最后的目标函数采用了GPT系列的Language Modeling,即LM。也就是给定一些词,来预测剩下的那些词,这就是Language Modeling。
对于LML,也就是ALBEF和VLMO最后用的那个目标函数,是属于完形填空,给定一句话,把中间一个词扣掉进行预测,所以LM和MLM是不同的。
对于数据噪声的问题,BLIP提出了CapFilt (Captioning and Filtering) - 数据自举
这是 BLIP 最著名的部分。它利用一个训练好的模型去清洗网络数据:
-
Captioner (生成器): 给网上的图片生成新的、更准确的文本描述(合成数据)
-
Filter (过滤器): 检查原本的文本和生成的文本,删掉那些与图片不匹配的“脏数据”
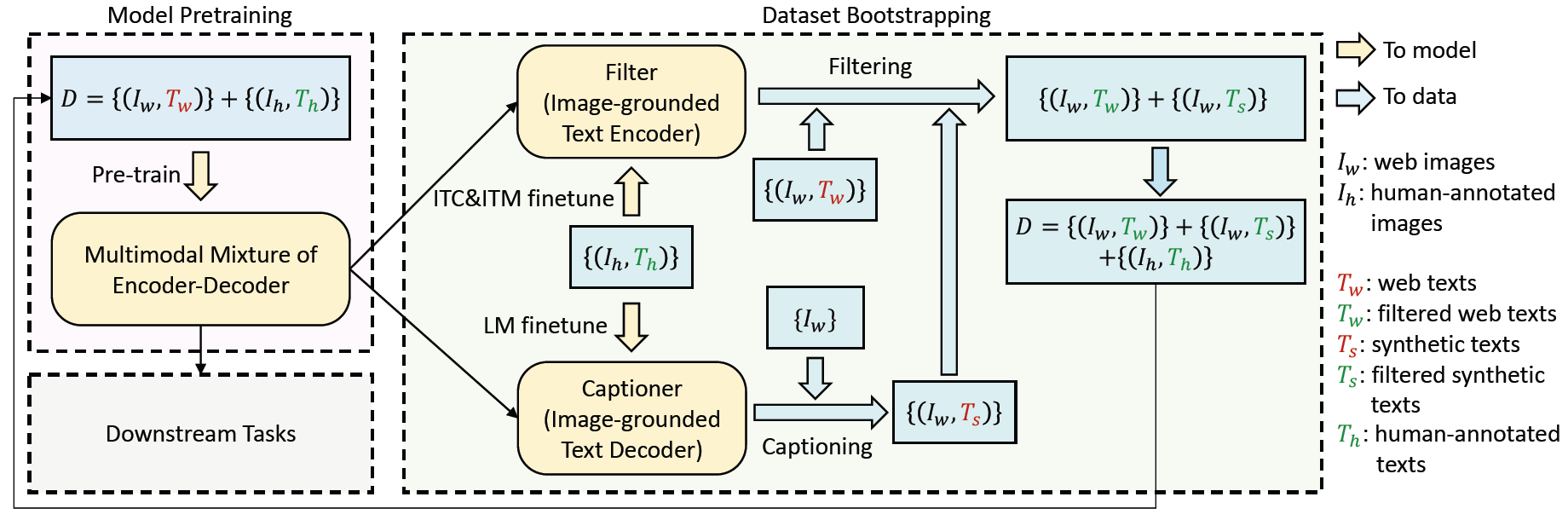
D代表所有的数据集,其中(Iw,Tw)代表在网络上爬下来的数据集,会存在图文不匹配的情况,用红色表示不匹配的文本,(Ih,Th)代表人工标注的数据集(比如coco数据集),那显然这组数据的图文一定是匹配的所以用绿色表示。
紧接着下方Multimodal Mixture of Encoder-Decoder就是我们刚才讲的BLIP模型MED,为了进一步清洗有噪音的网络数据,把提前预训练好的MED模型,也就是其中做ITC、ITM的文本模型拿出来,在人工标注干净的coco数据集(Ih,Th)上进行微调,微调过的MED就是Filter,Filter通过计算图像文本对(Iw,Tw)中的图文相似度Flitering,尤其是其中的ITM分数,就能够判断图像文本是否匹配,不匹配的去掉最后就可以得到一个相对更干净一些的图像文本对(Iw,Tw)。
即使图像文本对是匹配的,但是可能根据图像新生成文本更匹配,质量更高呢,BLIP就用新生成的文本充当新的训练数据集,在coco数据集把已经训练好的lmage-grounded Text Decoder又微调一下,就得到了Captioner,用任意一张网上的图片通过Captioning给这张图生成一个新的文本,形成(Iw,Ts),这里Ts的质量可高可低因为不能保证所有新生成的文本都是更好的。最后通过Filter和Captioner,左边原始的数据集D就变成了右边新的相对干净的数据集D,相对干净的数据集包含Filter筛选过的图像文本对、新生成的图像文本对和人工标注的图像文本对。不仅数据集变大了,质量也提升了。
最后用相对干净的数据集D重新进入左边的操作预训练MED模型,模型性能得到显著提升,在下游任务上应用也很广泛。

我们这时候再来看这些例子,Tw是直接在网络上下载的对应这张图片的文本,Ts是Captioner新生成的文本,红色代表被Filter筛掉的,绿色是最后保留的与图像更匹配的文本。
如果说前面ALBEF探究的是训练效率的提高,BLIP探究如何将推理+生成融入一个模型,并且对数据质量进行进一步提升,那么BLIP-2探究的就是结合大模型的训练效率
BLIP-2
我们知道现在大模型的训练讲究的是模型大、数据大,非常消耗资源并且训练时间非常长,那我们能不能在大模型训练的时候部分冻结它,或者根本不让大模型进行训练,这样训练效率会不会提升呢,这就是BLIP-2的动机。
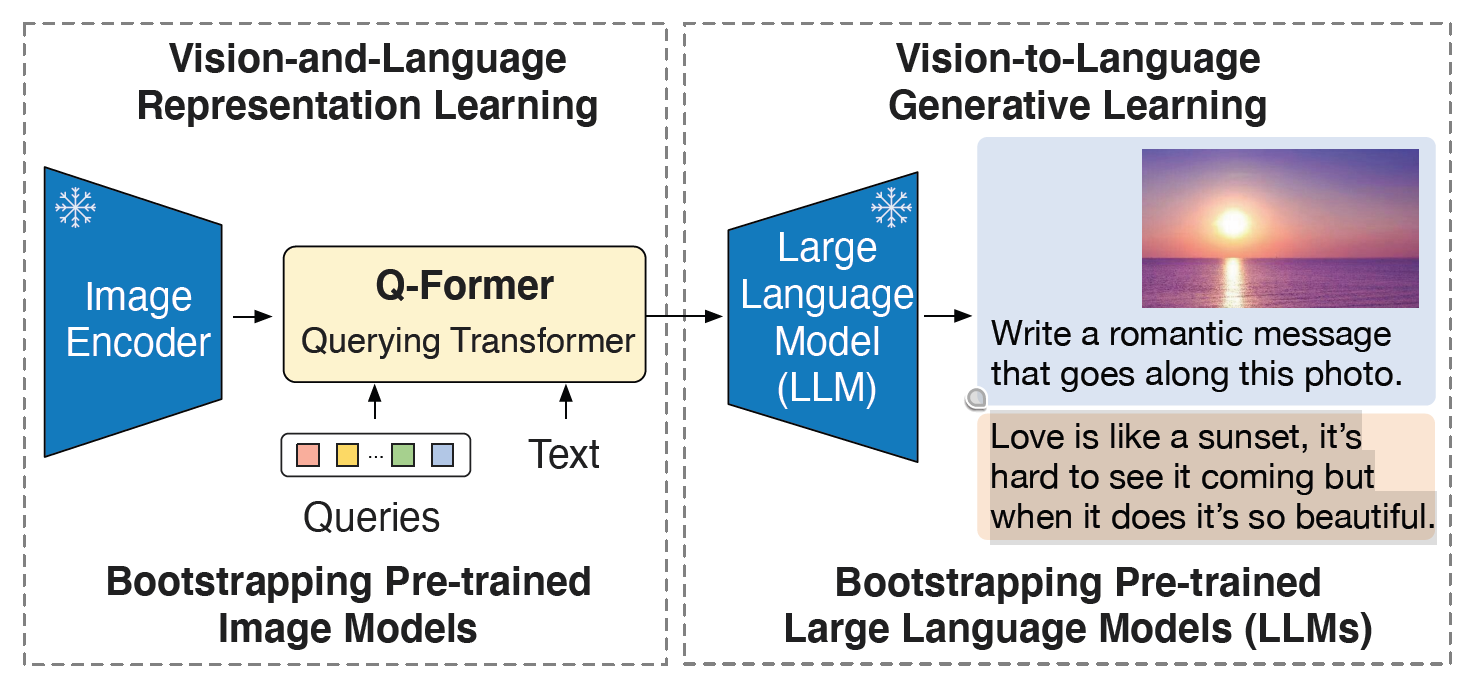
刚才说冻结大模型,那我们就把图像编码器和文本编码器都冻结不让它们更新,那这时候二者都不更新,他们的特征之间存在的gap太大,BLIP-2就引入了一个很小的transformer,大概只有one hundred million的参数量,全名为querying transformer。Q-Foemer相对于图像编码器和文本编码器来说参数量是非常小的了。
通过querying transformer把文本与图像之间的gap抹平,这样的思想类似于阿基米德的一句名言“给我一个支点,我就能撬动整个地球”
第一阶段为表征学习阶段,第二阶段为生成学习阶段
Q-Foemer的输入是一个可学习的query的vector或embedding和一个目标文本text。以及图像编码器端会输入一张图像,Q-Foemer作为一个查询器,来查询与当前文本text最相关的信息是什么,把不相关的信息抹掉,只留下相关信息。也就是说Q-Foemer提取到了与目标文本最相关的视觉信息,并且把提取到的视觉信息传入第二阶段的LLM中,之后用LLM做下游任务,同时Q-Foemer也作为信息通路进行最有用信息的传输。
表征学习阶段
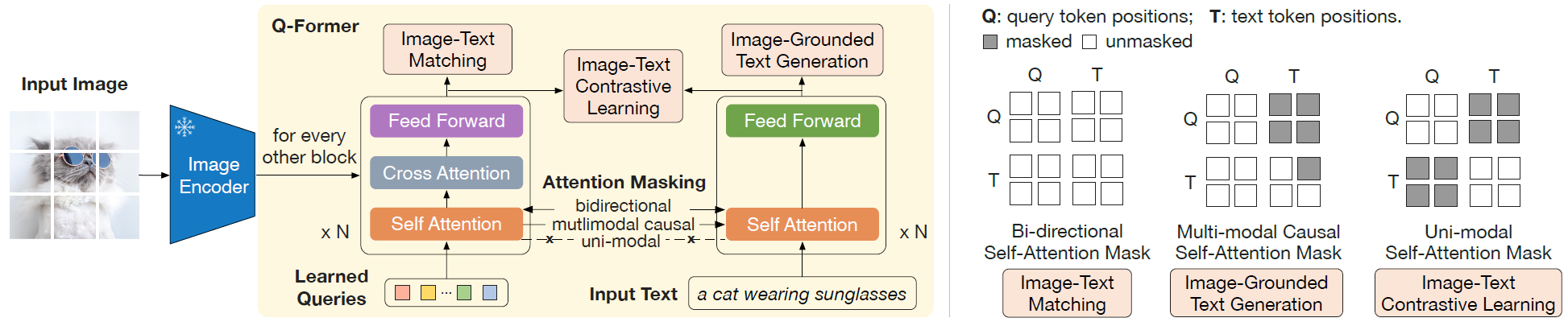
表征学习阶段的输入是一张图像Input Image和目标文本Input Text,通过冻结的图像编码器会得到图像的embedding,Q-former除了输入目标文本Input Text还会输入可学习的qurey vector,qurey vector输入到Self-Attention中,图像embedding输入Cross Attention中,图像embedding会和qurey vector进行交互,qurey就可以真正去查询图像上有用的信息,图像的目标信息少不了目标文本的指导,目标文本通过三个损失函数进行指导,ITM、ITG、ITC。
ITM(Image-Text Matching):简单来说就是图文匹配,所以这里不会被mask掉,完全看到然后寻找匹配的图文对
ITG(Image-grounded Text Generation):能够根据输入图像作为条件生成新的文本。会通过mask一部分然后再生成文本,Q是不能看到T的,如果看到就能100%生成出原始匹配的句子,就失去了“新”
ITC(Image-Text Contrastive Learning):也就是我们上面讲的对比学习损失函数,拉近正样本对,推远正负样本对。
所以在表征学习阶段,通过输入一张图像,一个query vector,最后会输出一个output embedding,它包含了图像的视觉信息,并且与目标文本是非常贴合的。
生成学习阶段
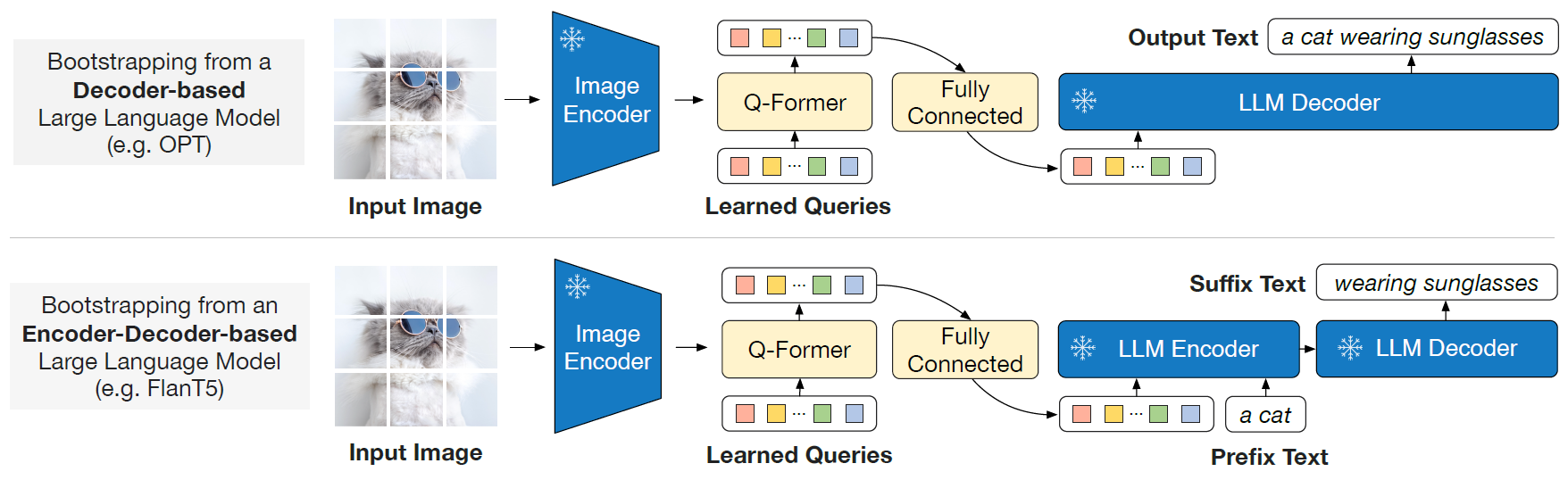
生成学习阶段就相对简单了,我们已经在表征学习阶段得到了与目标文本非常贴合的图像视觉信息,我们就通过一个全连接层产生一个embedding,作为条件输入到LLM Decoder中进行各种下游任务,这里有两种情况:
1.把语言全部mask掉。直接通过图像视觉信息把原始的句子预测出来。
2.输入前缀把语言后面mask掉。给定语言的前缀,将给出的前缀和图像视觉信息输入LLM编码器进行编码,之后再输入LLM解码器进行解码,最后把后面的句子预测出来。
无论是哪种情况,都是基于Q-former得到的图像视觉信息来进行文本生成任务的预测。
总结
ALBEF探究的是如何去掉繁杂冗余的目标检测器,使训练效率提高
BLIP探究如何将推理+生成融入一个模型,同时对数据质量进行进一步提升
BLIP-2用四两拨千斤的方法,通过一个query查询,把查询的信息输入到文本大模型中,将两个冻结的模型串联,让他们学习的更好
参考资料:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)