终极疑问:当前VLA SOTA模型已进化到顶了吗?自变量 + PI 开源,答案藏在这!
相比LLM用了3年才实现SOTA模型开源,VLA领域仅用不到1年就做到了——这不仅说明“具身智能是行业热点”,更反映出“开源是VLA快速落地的最佳路径”。开发者更活跃:中小团队、高校研究者能低成本参与VLA创新,比如有人会给模型加“老人护理场景的动作”,有人会优化“工业分拣的精准度”;硬件适配更快:机器人厂商不用再“自研AI”,直接用开源模型适配硬件,能加速“家庭服务机器人、工业协作机器人”的商业

一、里程碑:VLA开源密集落地,两大SOTA模型解锁生态
今年,具身智能领域的视觉-语言-动作(VLA)模型迎来“开源爆发季”——全球顶尖团队相继释放核心模型权重与代码,把“能理解、会动作”的智能能力从“实验室”推向“开发者社区”,每一步都堪称行业里程碑:
-
2月4日:PI首破僵局,开源初代SOTA模型π0
物理智能公司(Physical Intelligence)率先开源当时业界最优的VLA模型π0,首次打通“视觉理解→语言指令解析→连续动作生成”的端到端链路,为后续模型搭建了技术框架,开源地址:PI/openpi。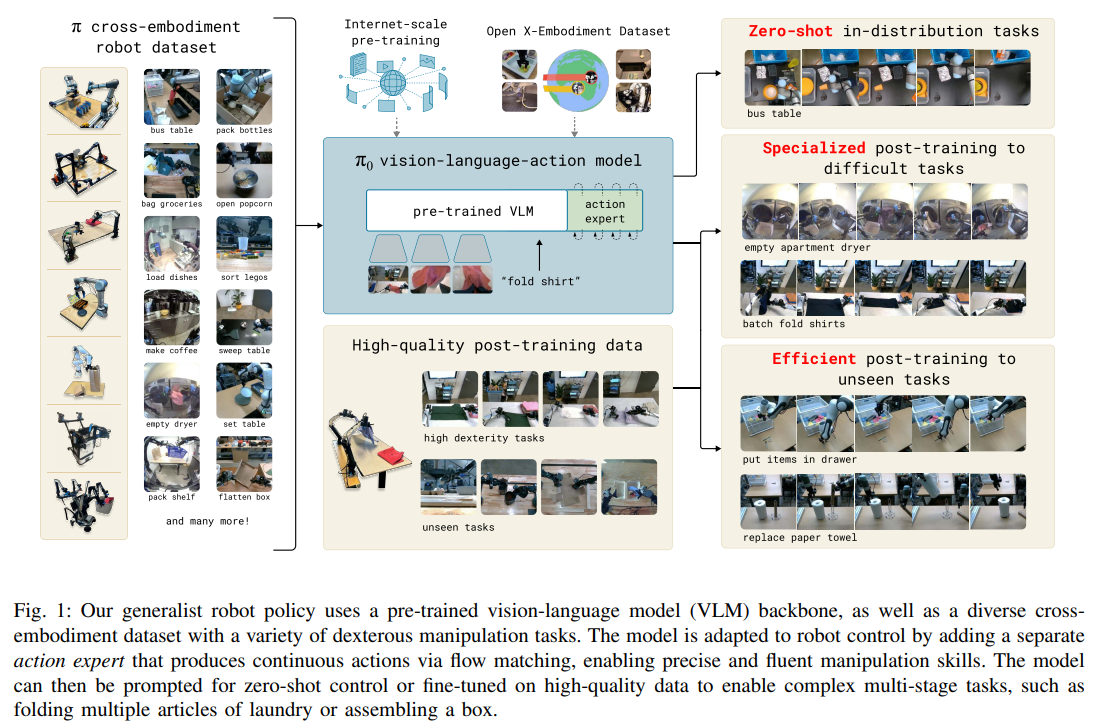
-
9月8日:中国自变量发力,WALL-OSS带创新架构开源
自变量机器人推出端到端具身智能基础模型WALL-OSS,核心突破是“紧密耦合MoE架构”——既能精准执行动作,又能深度推理长程任务,且上线即开源(支持多机器人本体微调),开发者可直接适配自家硬件: -
9月9日:PI快速迭代,π0.5聚焦真实环境泛化
仅隔1天,PI就跟进开源π0.5,重点优化“跨场景、跨机器人本体”的动作适应性,比如在家庭、实验室等不同环境中,面对不同机械臂时仍能稳定执行任务,与WALL-OSS形成“技术互补”。

值得关注的是,两大团队核心成员——自变量CTO王昊与PI研究员柯丽一鸣(Kay Ke),还在对话节目《临近机器人GPT-3时刻,具身智能开源模型的加速演进》中坦言:“开源不是终点,而是希望更多人一起解决VLA的核心难题。”这种“开放协作”的态度,正是生态崛起的关键。
二、开源背后的深意:复刻LLM成功路径,VLA要走“生态先赢”路线
VLA模型密集开源,绝非单纯的“技术分享”——而是直接对标大语言模型(LLM)的生态崛起逻辑,从学术到商业,都在为行业铺就“快车道”:
1. 学术端:打破壁垒,让中小团队也能“玩得起”VLA
回顾LLM的发展,2022年Meta的OPT(首个大型开源LLM)降低了“训练大模型”的门槛,2023年LLaMA1代码泄露后,斯坦福、伯克利等高校快速推出Alpaca、Vicuna等衍生模型,直接推动开源LLM从“小众探索”变成“主流方向”。
如今VLA的开源,正在复制这一路径:
- 降成本:中小团队无需投入千万级算力训练基础模型,只需基于π0.5、WALL-OSS微调(比如适配餐厅服务机器人、工业分拣机械臂);
- 促创新:社区可针对“动作泛化差”“物理常识不足”等痛点定向优化,比如有人给模型加“防滑动作反馈”,有人补充“厨房场景数据”,形成“众人拾柴”的迭代氛围。
2. 商业端:锁定技术路线,用“开源”抢滩未来市场
LLM早已证明“开源是好生意”:DeepSeek通过开源6710亿参数量的R1模型,快速成为“开源LLM头部玩家”,后续通过“企业级微调服务”实现盈利;Meta则靠LLaMA系列锁定“开源生态主导权”,吸引全球开发者基于其框架创新。
这一逻辑在VLA领域同样成立:
- 对企业:自变量、PI通过开源“定义VLA技术标准”——未来开发者用惯了WALL-OSS/π0.5,硬件厂商自然更愿意与它们合作;
- 对行业:开源让VLA从“定制化技术”变成“通用基础设施”,比如以前每个机器人厂商都要自研AI,现在直接用开源模型,能加速“家庭服务机器人、工业协作机器人”的落地。
就像《大教堂与集市》里说的:“想成为更大的青蛙,最好的办法是让水池先变大。”对VLA来说,“水池”就是开源生态——生态越大,技术落地越快,整个行业才能更快迎来“机器人GPT-3时刻”。
三、VLA仍需跨越的鸿沟:从“懂理论”到“会实操”的难题
尽管π0.5、WALL-OSS已是SOTA水平,但VLA模型要真正“融入物理世界”,还得解决两大核心挑战——本质是“如何让‘看图像、懂语言’的AI,学会像人一样精准动作”:
挑战1:跨模态数据“难协同”,语言和动作像“两套系统”
语言、视觉、动作的数据形态完全不同,强行融合容易“互相拖后腿”:
- 形态不兼容:语言是“离散的token”(比如“我喝了一杯___”,模型能预测“水”),动作是“连续的信号”(比如机械臂关节每秒要转5度、10度,像一条平滑的曲线);如果用“预测token”的方式训练动作,会把流畅的动作拆成“碎片化指令”,导致机器人抓握时“一顿一顿”。
- 训练互干扰:如果把“语言模块”和“动作模块”分开,机器人会“不听指令”——比如你说“拿杯子”,它却去抓盘子;如果把两个模块绑太紧,动作训练产生的“错误信号”会污染VLM(视觉语言模型),导致模型连“杯子是什么”都认不清了。
挑战2:VLM缺“物理常识”,懂理论却不会“实操”
现有VLM都是“在互联网上长大的”——只看过千万张“杯子的图片”,读过无数“如何拿杯子”的文字,却从没真正碰过杯子,就像“背熟游泳理论却没下过水的人”:
- 不会用反馈修正:如果抓杯子时没抓稳,杯子滑了,VLM不知道“是力度不够”,只会重复原来的动作;
- 不会规划动作:看到“叠衣服”的指令,VLM能理解“要把衣服叠整齐”,却不知道“先把袖子折进去,再对折”的步骤,更不会生成对应的动作。

四、破局方案:PI与自变量的技术创新,各有高招
针对上述难题,PI和自变量分别给出了“差异化解决方案”——既有技术接力,也有创新突破,共同推动VLA进步:
方向1:解决“跨模态协同”,让语言和动作“同频”
(1)先让动作“适配”VLM:把连续动作变成“模型能懂的形式”
核心思路是“给动作做‘翻译’”,让VLM能理解连续动作信号:
- PI π0:首设“动作专家”,单独处理连续动作
在VLM主干模型外,新增一个“动作专家分支”,用“流匹配(Flow Matching)”技术直接建模连续动作——就像给模型配了个“动作翻译官”,专门负责把“连续信号”转化为模型能处理的格式,不干扰VLM原本的语言理解能力。 - PI π0.5:升级FAST tokenizer,给动作“分段落”
设计了专门的“动作token化工具”:把机械臂的连续动作拆成“短片段”(比如每0.1秒的动作算一个“动作token”),既保留动作的连续性,又能让Transformer模型(VLM的核心框架)像处理语言一样处理动作。 - 自变量WALL-OSS:融合两种方案,兼顾流畅与兼容
既保留“动作专家+流匹配”,保证动作流畅;又采纳FAST tokenizer,让动作能更好地与VLM的语言模块协同——比如你说“慢慢拿杯子”,模型能生成“力度轻、速度慢”的连续动作,不会出现“猛抓”的情况。
(2)再解决“训练干扰”:既保护VLM,又学好动作
核心是通过“架构设计”隔离干扰,两大团队的思路各有侧重:
| 模型 | 架构设计 | 核心逻辑(通俗解释) |
|---|---|---|
| PI π0/π0.5 | MoE混合专家+知识绝缘 | 模型里有“语言专家”和“动作专家”两个团队;训练时用“知识绝缘”把“动作专家”的错误信号挡住,不让它影响“语言专家”的知识。 |
| 自变量WALL-OSS | 紧密耦合MoE | “语言专家”和“动作专家”共享“注意力机制”(相当于共用“大脑核心”),但各有专属“技能网络”;既能一起理解指令,又不会互相干扰。 |
方向2:补“物理常识”,让VLM学会“思考+实操”
核心是“让模型积累‘物理经验’,并学会拆解任务”:
(1)学会“长推理”:把复杂任务拆成“小步骤”
- PI π0.5:层次化推理,先定目标再做动作
面对“整理书桌”这样的任务,模型会先拆出“高层子任务”:“第一步拿废纸→第二步扔垃圾桶→第三步摆书本”,再让“动作专家”生成每个子任务的动作——就像先列清单,再按清单做事。 - 自变量WALL-OSS:思维链(CoT)闭环,边想边做
更进一步实现“思考-规划-动作”全流程端到端,比如接到“整理书桌”指令:
① 先“思考”:“桌上有废纸、书本、杯子,要先扔垃圾再摆东西”;
② 再“规划”:“第一步抓废纸→第二步移到垃圾桶上方→第三步松手”;
③ 最后“动作”:精准执行每个步骤,不会漏步骤或重复。
整个过程在一个模型里完成,没有“思考和动作脱节”的问题。
(2)建立“具身语义”:让VLM“懂物理”而非“背理论”
- PI π0.5:补互联网多模态数据,学“物体属性”
在预训练时加入“图像描述、视觉问答(VQA)、目标定位”数据,比如让模型看“杯子滑落在地”的图片,回答“杯子为什么会掉”,帮模型理解“杯子光滑、易滑落”的物理属性。 - 自变量WALL-OSS:两阶段预训练,先“懂”再“做”
把预训练分成两步,针对性补“物理常识”:- 第一阶段(Inspiration,开窍):给模型看大量“机器人在真实场景里的图片/视频”,并让它回答问题——比如“桌子上的苹果离杯子有多远?”“怎么拿才不会掉?”,先让模型“看懂物理世界”;
- 第二阶段(Integration,整合):用“流匹配”技术教模型学动作,让“常识”转化为“实操能力”——比如模型知道“杯子易滑”,就会生成“力度稍大但不捏碎”的抓握动作。
(3)用“真实数据”练手,避免“纸上谈兵”
PI和自变量都认为“真实数据比互联网数据更重要”——毕竟机器人要在真实世界动作,光看图片没用:
- PI π0.5:采集多本体真实数据
用不同类型的机器人(比如6轴机械臂、协作机械臂)在家庭、实验室等场景采集动作数据,保证模型在不同硬件上都能“适配”。 - 自变量WALL-OSS:构建“三万小时+多源数据集”
数据分三类,覆盖“理解-动作-推理”全需求:
① 自研高质量动作数据:比如“抓握不同重量的杯子”“摆放不同形状的书本”,保证任务复杂性;
② 开源动作数据:从社区收集其他机器人的动作数据,提升跨硬件泛化能力;
③ 多模态VQA数据:比如“怎么叠衣服才不会散?”“怎么推桌子更省力?”,补全物理推理能力。

五、实测见真章:WALL-OSS的“实操能力”有多强?
为了验证WALL-OSS的实力,研究团队做了多轮对比实验——结果显示,它在“物理理解、动作泛化、长程任务、逻辑推理”上都达到SOTA水平,部分指标甚至超过π0.5:
1. 更懂物理世界:能“看懂”也能“预判”
- 基础能力不丢:完全继承VLM的语言理解、文本生成能力,能准确识别“杯子、书本”等物体,理解“轻轻拿、慢慢放”等指令;
- 具身理解跃升:在“物体定位(Grounding)”“场景描述(Captioning)”“动作规划(Action Planning)”三个核心任务中,对比基础模型Qwen2.5-VL-3B,提升非常显著:
- 物体定位:从46.1%提升到91.6%(近乎翻倍),能精准指出“杯子在桌子左上角”;
- 场景描述:从57.7%提升到87.6%(提升52%),能描述“桌上有一个红色杯子,旁边放着三本书”;
- 动作规划:从59.8%提升到69.0%(提升15%),能规划“拿杯子→移到饮水机→接水”的步骤。
2. 动作精准且泛化:面对“新情况”不慌
- 指令对齐度高:在“捡垃圾、摆杯子”等基础任务中,WALL-OSS的动作与指令的匹配度,显著高于π0和Diffusion-Policy(另一个VLA模型)——比如你说“把杯子放在盘子右边”,它不会放错位置;
- 零样本能力强:面对“没见过的物体、没去过的环境”,仍能稳定执行任务:
- 已知物体(比如之前见过的杯子):pick-and-place任务平均进度85%;
- 全新物体(比如从没见过的异形花瓶):pick-and-place任务平均进度61%,远超行业平均的40%。
3. 能搞定复杂长任务:不会“忘步骤、做无用功”
在“整理卧室、布置餐桌”等多步骤任务中,其他模型常犯两个错:要么“中途失忆”(比如摆了盘子忘了摆筷子),要么“重复动作”(比如反复抓同一本书);而WALL-OSS靠“子任务规划能力”,能有条不紊地完成:
- 任务连贯性:能记住“已完成步骤”和“待完成步骤”,比如整理卧室时,先叠被子、再擦桌子、最后扫地,不会跳步;
- 稳定性强:长程任务的成功率比π0.5高12%,不会因为步骤多而“崩溃”。
4. 会思考、能推理:不只是“执行工具”
最让人惊喜的是“逻辑推理能力”——在“用字母积木拼单词”任务中(需要先想“怎么拼”,再做“怎么动”):
- 其他模型:只会盲目抓字母,比如要拼“CAT”,却抓来D、O、G,拼不出目标单词;
- WALL-OSS:会先在“大脑里”推理“拼CAT需要C、A、T三个字母”,再规划“先抓C放在左侧,再抓A放中间,最后抓T放右侧”,然后精准执行动作,真正实现“先想后做”。
六、总结:VLA开源潮,让机器人AI离落地更近一步
相比LLM用了3年才实现SOTA模型开源,VLA领域仅用不到1年就做到了——这不仅说明“具身智能是行业热点”,更反映出“开源是VLA快速落地的最佳路径”。
随着π0.5、WALL-OSS的开源,VLA生态会迎来三个变化:
- 开发者更活跃:中小团队、高校研究者能低成本参与VLA创新,比如有人会给模型加“老人护理场景的动作”,有人会优化“工业分拣的精准度”;
- 硬件适配更快:机器人厂商不用再“自研AI”,直接用开源模型适配硬件,能加速“家庭服务机器人、工业协作机器人”的商业化;
- 技术路线更清晰:WALL-OSS的“紧密耦合MoE”“两阶段具身训练”,π0.5的“知识绝缘”“层次化推理”,为后续模型指明了方向——未来的VLA,要“既懂物理世界,又会精准动作,还能深度推理”。
对开发者来说,现在正是参与VLA生态的好时机——如果你有机器人硬件,不妨试试在上面微调WALL-OSS或π0.5;如果你擅长算法,也可以针对“物理常识不足”“跨场景泛化差”等痛点做优化。毕竟,具身智能的“GPT-3时刻”,需要更多人一起推动才能到来。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)