构建多模态大模型trick探究及六大结论
实验设计:(1)使用Perceiver Resampler(可学习的Transformer池化器)将图像token从729压缩到更少。(2)测试不同压缩数量:128 vs 64。实验设计:图像切分:在训练时将每张图像切分为4个子图 + 原图 = 5张图,每张图仍送入模型 → 总token数从64 → 320,仅在指令微调阶段使用此策略。实验设计对比:(1)强制resize为768×768正方形;1
多模态主要结构有三部分:
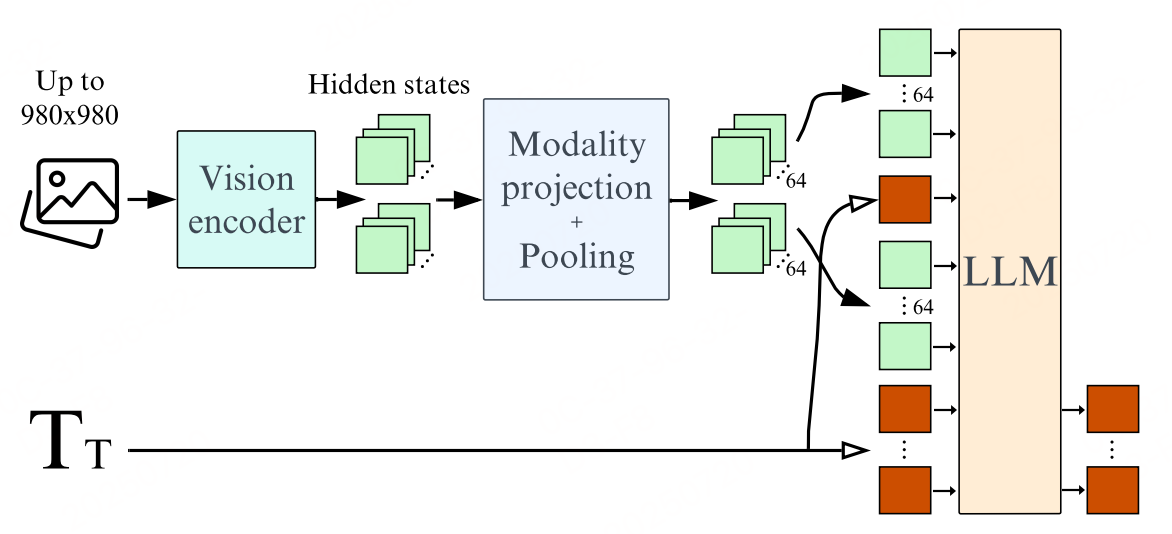
- Vision Backbone:负责处理图像输入,通常是预训练的Vision Transformer(如CLIP-ViT、SigLIP、EVA-CLIP等)。
- Language Backbone:负责处理文本输入,通常是预训练的大语言模型
- Connector Modules:为了将视觉和语言模态连接起来,需要引入新的参数模块,称为:
- Modality Projection Layers(模态投影层):将视觉编码器的输出(图像特征)映射到语言模型的输入空间(文本嵌入空间)。
- Pooling(池化):为了减少视觉token数量,提高效率,可以使用如Perceiver Resampler等机制对视觉特征进行压缩。
VLM的关键设计探究
1、视觉/语言主干是否同等重要?
- 固定:训练数据量、训练步数、模型大小
- 变量:语言模型:LLaMA-1-7B vs Mistral-7B;视觉编码器:CLIP-ViT-H vs EVA-CLIP-5B vs SigLIP-SO400M
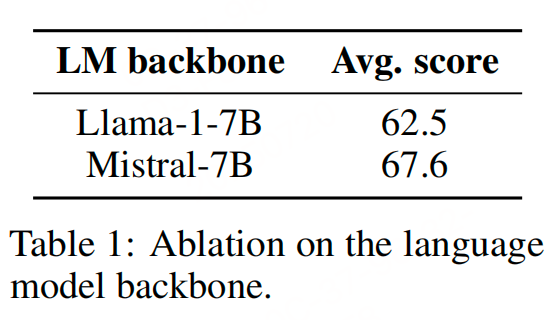
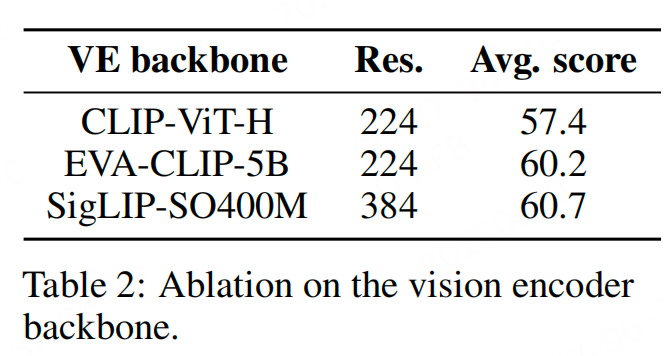
结论:在参数数量相同的前提下,语言模型的质量对最终VLM性能的影响比视觉编码器更大。
2、哪种架构更好?Cross-attention vs Fully autoregressive
两种架构:
- Cross-attention(CA):在LLM中插入cross-attention层
- Fully autoregressive(FA):将视觉token拼接到文本token前
变量:
- 是否冻结主干(Frozen vs LoRA)
- 是否训练视觉/语言主干参数
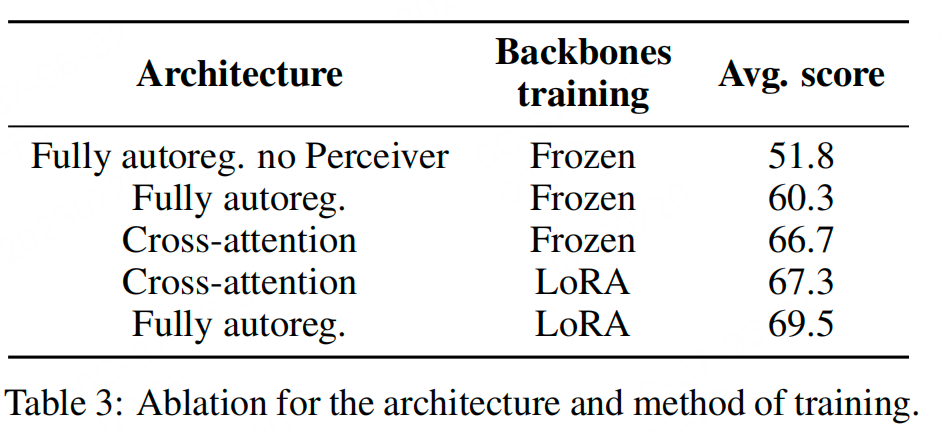
结论:
- 当主干冻结时,cross-attention更好;但当使用LoRA微调主干时,fully autoregressive架构性能反超。
- Fully autoregressive架构在解冻主干时容易训练发散,LoRA能有效稳定训练并提升性能。
3、如何提高效率?
3.1、减少视觉token数量是否可行?
实验设计:(1)使用Perceiver Resampler(可学习的Transformer池化器)将图像token从729压缩到更少。(2)测试不同压缩数量:128 vs 64
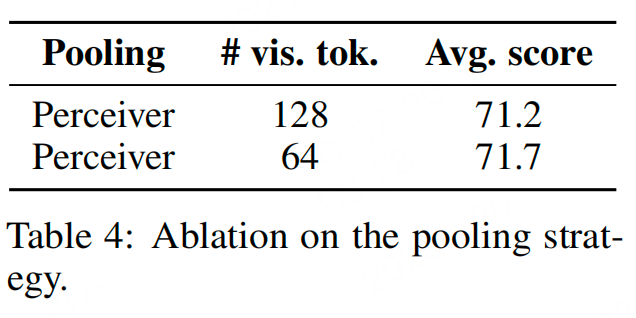
结论:将token从729压缩到64,不仅不损失性能,反而提升了效率和效果。
3.2、是否必须将图像resize成正方形?
实验设计对比:(1)强制resize为768×768正方形;(2)保持原图长宽比,最小边378,最大边768

结论:保持原图长宽比和分辨率不会明显降低性能,但能节省显存、加快训练/推理速度。
4、能否用更多计算换性能?
实验设计:图像切分:在训练时将每张图像切分为4个子图 + 原图 = 5张图,每张图仍送入模型 → 总token数从64 → 320,仅在指令微调阶段使用此策略。

结论:在训练阶段使用图像切分(image splitting)可以显著提升需要高分辨率视觉输入的任务(如OCR、文档理解)性能,且只需在50%样本上使用即可。
总览:
| 发现 | 总结 |
|---|---|
| 1 | LLM质量 > Vision Encoder质量 |
| 2 | 冻结主干时CA更好;LoRA微调时FA反超 |
| 3 | FA架构需LoRA防止训练发散 |
| 4 | Perceiver池化压缩token数,提升效率与性能 |
| 5 | 保留原图比例不损性能,节省显存 |
| 6 | 图像切分策略可“用计算换性能”,适用于OCR任务 |
参考文献:What matters when building vision-language models?,https://arxiv.org/pdf/2405.02246

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)