【值得收藏】大语言模型输出机制与采样策略:从原理到实践
文章主要介绍了大语言模型输出环节的采样策略和不确定性管理。详细解释了温度、top-k和top-p三种采样方法的工作原理和应用场景,以及如何通过提示词设计、后置处理和受限采样等方式实现结构化输出。文章还讨论了LLM输出的不确定性和"幻觉"现象,认为这是模型创造力的来源,需要合理管理而非消除。
文章主要介绍了大语言模型输出环节的采样策略和不确定性管理。详细解释了温度、top-k和top-p三种采样方法的工作原理和应用场景,以及如何通过提示词设计、后置处理和受限采样等方式实现结构化输出。文章还讨论了LLM输出的不确定性和"幻觉"现象,认为这是模型创造力的来源,需要合理管理而非消除。
通过前面的文章,我们了解了输入阶段的嵌入,以及 Transformer 模型的处理。从整体来看,输出环节还没有“打开”,本文将一探究竟。
借用 Chip Huyen 的著作《AI Engineering》[1]中的一张配图:
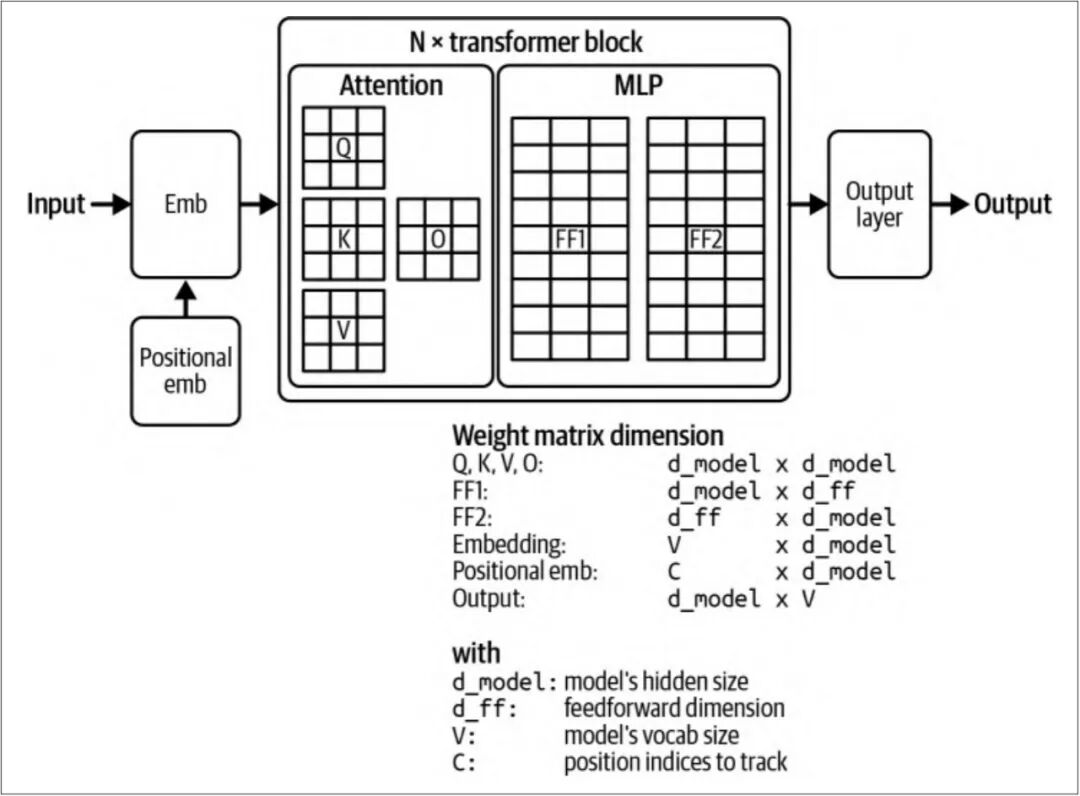
从矩阵运算的角度来看,最终输出的是一个长度为字典大小的向量,经过 softmax 激活函数得到就是每个token的概率分布。
如何选择 token 呢?这蕴含着确定性与随机性的权衡:选择概率最大的 token 会使输出更稳定、更可预测,而采用随机采样则能提升多样性与创造性。这一权衡最终反映在模型的采样策略上。
- 采样策略
总的来说有温度、top-k 和 top-p 三种采样策略。
1.1 温度
“温度”这个名字比较传神,温度越高越活跃,也就是更有创造性。
我们就以 DeepSeek 体验一下温度的作用,发送下述提示词,控制温度的值,观察输出:
{ "model": "deepseek-chat", "messages": [ {"role": "system", "content": "你是一位诗人,我出上句,你来对下句"}, {"role": "user", "content": "天若有情天亦老,"} ], "temperature": 0, "stream": false}
当 temperature 设置为 0 时,输出是固定的:
- • 月如无恨月长圆
当 temperature 设置为 2 时,输出比较随机:
- • 月如无恨月长圆
- • 人间道义尽沧桑
- • 情深偏易断肠多
- • 月如无恨月长圆。踏破璀璨星空,为寻前世因缘。清风拂柳千年慢,我倾战意翻云,乾坤内,与谁来争。凝望明月高悬,此意气飘然,今夜群星皆不醒,我本肆意剑出行!啊 举杯与苍天似深情,放声狂笑称心情。剑指长天向侠行!尽我此生豪马踏名城!
- • 酒逢知己醉千杯
- • 水能无怨水当干,然未曾几测高深。
- • 红绡先冷迎风眠
- • …
效果与直观理解一致,其背后的原理也很简单,作用点就在 softmax 的计算上。
token 的 logit 除了一下温度值,实现的效果就是 越大, 之间的差值就越小,也就是提高了其他 token 被选中的概率。
1.2 top-k
top-k 采样的动机是减少 softmax 激活函数的计算量,对 logits 进行排序选择数值最大的 k 个,然后对这个 k 个,不是整个字典,进行 softmax 计算。
该采样策略使用的比较少,例如 DeepSeek 就没有提供相关的参数,原因是 k 是绝对的数,需要根据输出的大小进行调整。
1.3 top-p
top-p 采样策略是当前比较流行的策略,它并没有降低计算量,还是得全量计算 softmax 激活函数,然后对概率进行排序,选择累积概率大于 p 的 tokens 作为备选。
我们还是以上面的示例,控制 top_p 的值,观察输出:
当 top_p 设置为 0.01 时,输出是固定的:
- • 月如无恨月长圆
当 top_p 设置为 1 时,输出也很固定:
- • 月如无恨月长圆
与预期不太相符,笔者猜测可能的原因是最相关的 token 概率值遥遥领先,此时可以通过设置 logprobs 来验证一下:
{ "token": "月", "logprob": -0.031558793, "bytes": [ 230, 156, 136 ], "top_logprobs": [ { "token": "月", "logprob": -0.031558793, "bytes": [ 230, 156, 136 ] }, { "token": "人间", "logprob": -3.471668, "bytes": [ 228, 186, 186, 233, 151, 180 ] }, { "token": "人", "logprob": -14.080235, "bytes": [ 228, 186, 186 ] } ]}
返回的这个是对数概率,换算一下,“月”的概率是96.89%,“人间”的概率是3.1%,“月”的概率确实遥遥领先。
- 结构化输出
在某些实际的应用场景中,我们期望 LLM 的输出是结构化的,例如生成一个 SQL 或者正则表达式。
对于结构化输出,有办法对 LLM 进行限制么?方法还是有一些,但是不能完全保障。
-
- 提示词,在提示词中明确要求输出的格式
-
- 后置处理,对输出进行格式校验
-
- 受限采样,在采样的过程中进行限制,过滤掉不符合格式的token
-
- 微调
一般情况下“后置处理”是成本最小,但是效果最好的方式。
- 如何看待输出的不确定性
大模型在训练时汇集了海量的数据,对于相同或相似的输入,可能生成截然不同的输出。这种不一致是预期内的,比较难理解的现象是幻觉,对其原因业界也有一些猜想,但是并没有原理解释(如果理解了其原理,不就能解决了😅)。
笔者经过这短短十一篇文章的学习,感觉开始理解了 Martin Fowler 的这个观点[2]:
My former colleague Rebecca Parsons, has been saying for a long time that hallucinations aren’t a bug of LLMs, they are a feature. Indeed they are the feature. All an LLM does is produce hallucinations, it’s just that we find some of them useful.
当然 Martin 大叔在表述上有点儿偏颇,作为中庸之道熏陶下的笔者,可能会这样表述:LLM 的创造力来源于概率性,要理解并管理好这种不确定性,不能因噎废食。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
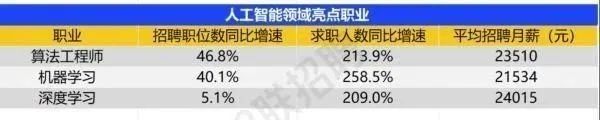
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献760条内容
已为社区贡献760条内容

所有评论(0)