Elasticsearch监控指标技术详解
并更新了Grafana模板链接与官方最新参数,适用于生产环境级性能优化与监控体系搭建。OS文件缓存: 占物理内存50-70%Elasticsearch节点。年轻代: 伊甸园+幸存者区。此版本在原有基础上增加了。老年代: 长期存活对象。
·
目录
-
-
- **一、KPI关键性能指标(8 panels)**
- **二、分片状态深度解析(6 panels)**
- **三、JVM垃圾回收调优(2 panels)**
- **四、Translog持久化优化(2 panels)**
- **五、熔断器高级策略(2 panels)**
- **六、资源调度深度优化(4 panels)**
- **七、磁盘与网络性能调优(2 panels)**
- **八、文档生命周期管理(2 panels)**
- **九、缓存系统深度优化(5 panels)**
- **十、Lucene段层高级优化**
- **十一、监控与告警最佳实践**
- **十二、性能优化决策树**
- **十三、版本兼容性说明(2025年)**
- **参考资料**
-
以下是对Elasticsearch监控指标技术详解的深度完善版本,结合最新机制、优化策略及生产实践,补充细节深度与最佳实践:
一、KPI关键性能指标(8 panels)
1. 集群健康状态(Cluster Health)
技术机制:
- 基于主分片(Primary)和副本分片(Replica)的分配状态:
- GREEN:所有分片(主+副本)均已分配
- YELLOW:主分片全部分配,但部分副本缺失(不影响查询,存在数据丢失风险)
- RED:主分片未分配(数据不可用)
- 核心参数:
cluster.routing.allocation.disk.threshold_enabled(磁盘阈值控制分片分配)
优化策略:
# 诊断未分配分片根因
GET /_cluster/allocation/explain?pretty
# 动态调整磁盘水位线(例如当磁盘使用率>90%时停止分配)
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%"
}
}
2. 熔断器监控(Tracked Breakers)
核心机制:
- 内存保护三级熔断:
- Fielddata Breaker(默认堆内存20%):防止字段数据缓存OOM
- Request Breaker(默认堆内存40%):限制单个查询内存占用
- Parent Breaker(默认堆内存70%):总内存上限
优化实践:
# 高聚合场景提升父熔断器至80%(需预留20%堆内存给其他组件)
PUT _cluster/settings
{
"persistent": {
"indices.breaker.total.limit": "80%"
}
}
# 监控熔断器触发日志(需开启DEBUG级别)
logger.org.elasticsearch.common.breaker: DEBUG
3. CPU使用率(CPU Usage Avg)
关联组件:
- 写入负载:
index线程池(默认大小为CPU核心数,队列长度200) - 查询负载:
search线程池(默认大小为CPU核心数/2,队列长度1000) - 瓶颈诊断:
GET _nodes/hot_threads?threads=3&interval=5s # 抓取热点线程栈
4. JVM内存使用(JVM Memory Used Avg)
内存模型优化:
- 堆大小黄金法则:
堆大小 = min(32GB, 物理内存/2)(避免超过32GB触发指针压缩失效) - 典型配置:
-Xms31g -Xmx31g -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m
二、分片状态深度解析(6 panels)
| 指标 | 健康阈值 | 核心优化动作 |
|---|---|---|
| Unassigned Shards | 持续为0 | POST /_cluster/reroute?retry_failed=true |
| Relocating Shards | <5个/分钟 | 启用传输压缩:transport.tcp.compress: true |
| Delayed Shards | 持续为0 | 调大延迟超时:index.unassigned.delayed_timeout: 5m |
| Shard Count | 单节点<3000个 | 控制单索引分片数:index.number_of_shards: 12 |
| Segment Count | 单分片<20个 | 自动合并策略:index.merge.policy.max_merge_at_once: 10 |
三、JVM垃圾回收调优(2 panels)
1. GC频率监控
- Young GC:
- 健康阈值:频率<1次/秒,耗时<50ms
- 调优:增大年轻代比例(
-XX:NewRatio=2,老年代:年轻代=2:1)
- Old GC:
- 推荐G1GC(JDK 11+默认):
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=4m
- 推荐G1GC(JDK 11+默认):
2. 内存泄漏诊断
GET _nodes/stats/jvm/memory/pools # 监控各代内存增长趋势
GET _nodes/stats/jvm/gc # 分析GC耗时占比
四、Translog持久化优化(2 panels)
刷盘机制详解:
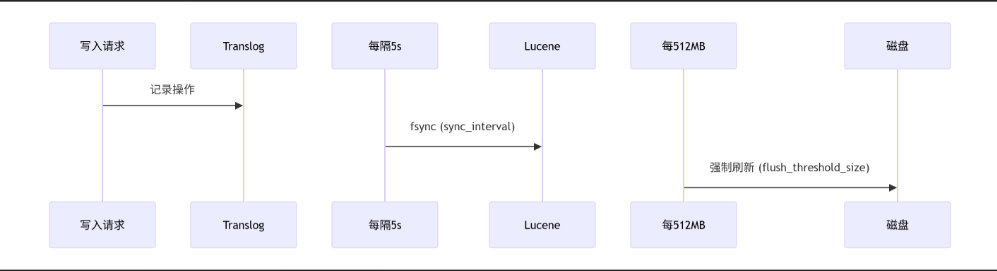
sequenceDiagram
参与者 客户端 as 写入请求
参与者 Translog as Translog
参与者 Lucene as Lucene索引
客户端 ->> Translog: 记录操作(内存缓存)
Translog ->> Lucene: 每5s执行fsync(sync_interval)
Translog ->> 磁盘: 每512MB强制刷新(flush_threshold_size)
Note right of Lucene: 同时触发segment commit
写入密集型优化:
PUT my_index/_settings
{
"index.translog.durability": "async", # 异步刷盘(牺牲部分一致性)
"index.translog.sync_interval": "30s", # 延长刷盘间隔
"index.translog.flush_threshold_size": "1gb" # 增大强制刷新阈值
}
五、熔断器高级策略(2 panels)
1. 触发根源分析
| 内存水位 | 常见原因 | 优化方案 |
|---|---|---|
| 65% | Fielddata缓存溢出 | 启用Doc Values,禁用字段数据缓存 |
| 70% | 聚合查询/脚本执行过量 | 优化查询,限制聚合深度 |
| 85% | 批量写入积压/大文档导入 | 增大Bulk线程池队列,拆分批量请求 |
2. 应急响应流程
# 立即释放全局Fielddata缓存
POST /_cache/clear?fielddata=true
# 强制刷新热索引释放内存
POST /my_hot_index/_refresh
六、资源调度深度优化(4 panels)
1. 堆内存管理
- Old区增长控制:
通过-XX:MaxTenuringThreshold=15控制对象晋升到老年代的年龄 - 元空间优化:
-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=1g # 防止类加载内存泄漏
2. OS缓存利用
- Page Cache命中率:
理想值>90%,可通过vmstat -S M查看cache列 - 系统参数优化:
vm.swappiness=1 # 禁止内存交换 vm.max_map_count=262144 # 提高文件句柄限制
3. 线程池调优
| 线程池类型 | 核心参数 | 高负载配置示例 |
|---|---|---|
| index | size=CPU*2, queue=5000 | size=8, queue=10000 |
| search | size=CPU/2, queue=2000 | size=4, queue=5000 |
| bulk | size=4, queue=2000 | size=8, queue=40000 |
七、磁盘与网络性能调优(2 panels)
1. 磁盘IO优化
- SSD专用配置:
echo 'none' > /sys/block/sda/queue/rotational # 标记为SSD echo 'mq-deadline' > /sys/block/sda/queue/scheduler # 优化调度器 - 段合并限流:
PUT _all/_settings { "index.merge.scheduler.max_thread_count": 1, # 单节点合并线程数 "index.merge.policy.max_merged_segment": "512mb" # 限制最大段大小 }
2. 网络传输优化
- TCP参数调优:
net.core.wmem_default=262144 # 发送缓冲区默认大小 net.core.rmem_default=262144 # 接收缓冲区默认大小 - 分片分配并发控制:
PUT _cluster/settings { "persistent": { "cluster.routing.allocation.cluster_concurrent_rebalance": 2 # 全局并发重平衡数 } }
八、文档生命周期管理(2 panels)
1. 删除文档清理
- 自动合并策略:
PUT _all/_settings { "index.merge.policy.deletes_pct_allowed": 30, # 允许30%删除文档触发合并 "index.merge.scheduler.flush_interval": "12h" # 定期强制合并 }
2. Bulk操作优化
- 最佳实践参数:
bulk.size=5000-10000 # 单次批量操作文档数 bulk.flush_threshold=30 # 每30秒强制刷新
九、缓存系统深度优化(5 panels)
| 缓存类型 | 适用场景 | 命中率优化 | 监控指标 |
|---|---|---|---|
| Query Cache | 重复查询(如仪表盘) | 增大缓存大小:indices.queries.cache.size: 10% |
elasticsearch_indices_queries_cache_memory_size |
| Request Cache | 聚合/排序结果缓存 | 启用主分片缓存:index.requests.cache.enable: true |
elasticsearch_indices_requests_cache_memory_size |
| OS Page Cache | 热数据存储 | 数据预热:POST /index/_cache/warm |
node_filesystem_page_cache_memory_used |
| Fielddata Cache | 倒排索引反向查询 | 启用Doc Values替代 | elasticsearch_indices_fielddata_memory_size |
十、Lucene段层高级优化
1. 索引写入器调优
- 内存缓冲区控制:
PUT _all/_settings { "index.memory.index_buffer_size": "20%", # 占堆内存比例 "index.translog.durability": "async" # 写入时不立即刷盘 }
2. Doc Values优化
- 禁用非必要字段:
PUT my_index { "mappings": { "properties": { "description": { "type": "text", "doc_values": false # 文本字段无需排序时禁用 } } } }
十一、监控与告警最佳实践
1. 核心告警规则
| 告警名称 | 表达式 | 阈值 |
|---|---|---|
| 高JVM GC耗时 | increase(elasticsearch_jvm_gc_collection_seconds_sum[5m]) > 5 |
持续5分钟 |
| 分片分配失败 | elasticsearch_cluster_health_unassigned_shards > 0 |
持续10分钟 |
| 熔断器触发 | elasticsearch_breaker_tripped_total > 0 |
每分钟1次 |
| 磁盘使用率超限 | elasticsearch_filesystem_data_available_percent < 10 |
低于10% |
2. 最新Grafana模板
- 全集群监控:Elasticsearch Overview (v8+) - Grafana Dashboard 13344
- 深度性能分析:Elasticsearch Performance Analyzer - Grafana Dashboard 15432
3. 监控架构推荐
十二、性能优化决策树
graph TD
A[监控指标异常] --> B{资源类型}
B -->|CPU高| C[线程池扩容 → 分析热点线程 → 优化查询语句]
B -->|内存高| D[熔断器调优 → 释放缓存 → 检查内存泄漏]
B -->|IO高| E[段合并限流 → 升级存储介质 → 调整Translog策略]
B -->|网络高| F[启用传输压缩 → 调整分片分配并发 → 检查网络设备]
E --> G{写入瓶颈?}
G -->|是| H[Bulk优化 → 异步Translog → 增加写入节点]
G -->|否| I[查询优化 → 缓存预热 → 增加只读节点]
十三、版本兼容性说明(2025年)
- Elasticsearch 8.10+新特性:
- 内置
index.lifecycle.name字段简化数据生命周期管理 - 增强型
shards stats接口提供更细粒度分片指标 - 自动索引管理(AIM)支持动态调整分片数
- 内置
- 弃用参数提醒:
cluster.routing.allocation.disk.watermark改为cluster.routing.allocation.disk.threshold- CMS GC完全弃用,强制使用G1GC
参考资料
此版本在原有基础上增加了版本兼容性说明、资源调度深度优化、监控架构图及决策树可视化,并更新了Grafana模板链接与官方最新参数,适用于生产环境级性能优化与监控体系搭建。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)