上海交大:LLM策略优化算法FlowRL
如何在大语言模型(LLM)的推理过程中有效地促进多样化的解决方案探索,避免模式坍塌的问题?论文提出一种新的策略优化算法FlowRL,通过对奖励分布进行匹配,提升了大型语言模型在推理任务中的性能和多样性。
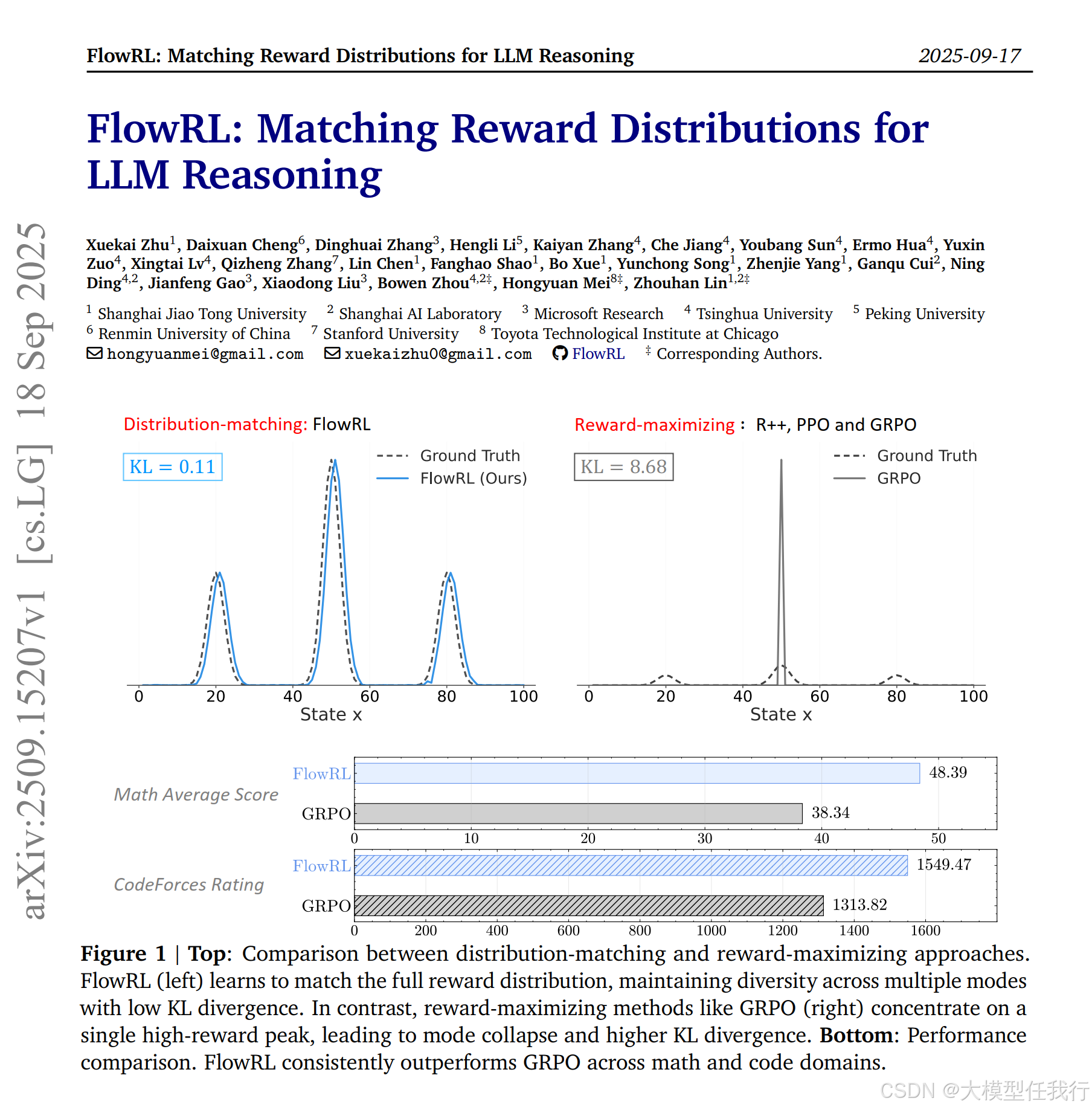
📖标题:FlowRL: Matching Reward Distributions for LLM Reasoning
🌐来源:arXiv, 2509.15207
🌟摘要
我们提出了 FlowRL:通过流平衡匹配完整的奖励分布,而不是最大化大型语言模型 (LLM) 强化学习 (RL) 中的奖励。最近的高级推理模型采用奖励最大化方法(例如 PPO 和 GRPO),该方法倾向于过度优化主要奖励信号,而忽略了不太频繁但有效的推理路径,从而减少多样性。相比之下,我们使用可学习的分区函数将标量奖励转换为归一化目标分布,然后最小化策略和目标分布之间的反向 KL 散度。我们将此想法实现为促进多样化探索和可泛化推理轨迹的流平衡优化方法。我们对数学和代码推理任务进行了实验:FlowRL 在数学基准上实现了 10.0% 的 GRPO 和 5.1% 的显着平均改进,并且在代码推理任务上的表现始终优于 PPO。这些结果突出了奖励分布匹配作为LLM强化学习中高效探索和多样化推理的关键步骤。
🛎️文章简介
🔸研究问题:如何在大语言模型(LLM)的推理过程中有效地促进多样化的解决方案探索,避免模式坍塌的问题?
🔸主要贡献:论文提出一种新的策略优化算法FlowRL,通过对奖励分布进行匹配,提升了大型语言模型在推理任务中的性能和多样性。
📝重点思路
🔸将推理问题建模为条件生成问题,使用比例于给定奖励的策略学习。
🔸引入生成流网络(GFlowNets)的框架,利用流匹配原理实现正向和反向概率流的平衡,从而发现多样化的高奖励解决方案。
🔸通过最小化反向KL散度,将策略模型的输出分布与目标奖励分布对齐,从而实现更高效的探索。
🔸采用长度归一化和重要性采样,解决长链思维推理中梯度爆炸和采样不匹配的问题。
🔎分析总结
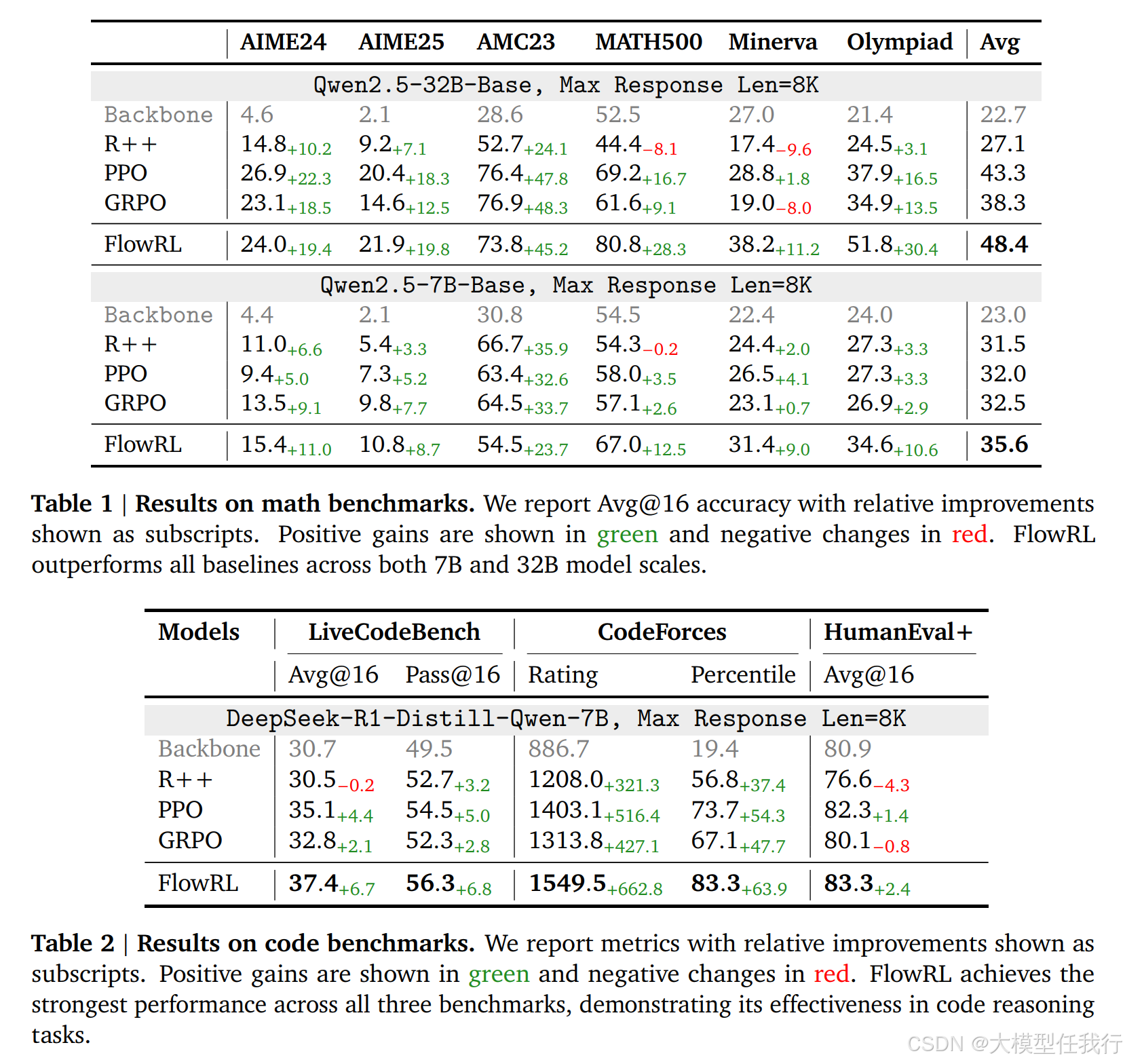
🔸FlowRL在数学基准测试中,相较于GRPO和PPO分别提升了10.0%和5.1%的性能表现,显示了其在复杂推理任务中的有效性。
🔸实验分析表明,FlowRL生成的推理路径具有显著更高的多样性,验证了其在探索解决策略方面的有效性。
🔸通过引入长度归一化,FlowRL成功缓解了对变长序列的训练中出现的梯度爆炸现象。
🔸重要性采样的引入极大地改善了训练数据的利用效率,并且在推理基准测试中的表现显示出显著的性能提升。
💡个人观点
论文从单一的奖励最大化目标转变为匹配奖励分布,不仅提高了生成结果的多样性,还增强了模型在未见过情况中的泛化能力。
🧩附录

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献305条内容
已为社区贡献305条内容

所有评论(0)