清华 | 提出统一LLM训练方法,打破SFT与RL的界限!
本文提出了一种统一大型语言模型(LLM)后训练方法的新框架,将监督微调(SFT)和强化学习(RL)两种主流范式整合为单一优化过程。研究团队推导出统一策略梯度估计器(UPGE)理论,证明不同后训练算法的梯度计算是该框架在不同数据分布假设下的特例。基于此理论,开发了混合后训练(HPT)算法,根据模型实时性能动态切换SFT和RL训练信号。实验表明,HPT在多个数学推理基准测试中显著优于传统方法,不仅能提
一、导读
大型语言模型(LLM)的后训练(Post-Training)主要依赖两种数据:由强化学习(Reinforcement Learning, RL)利用的在线模型生成数据,以及由监督微调(Supervised Fine-Tuning, SFT)利用的离线专家数据。传统方法通常将二者分离或按序执行(SFT-then-RL),但这不仅资源消耗大,且缺乏统一的理论支撑。本文旨在解决这一挑战,论证了SFT和RL并非相互矛盾,而是单一优化过程的不同实例。为此,论文推导出一个名为统一策略梯度估计器(Unified Policy Gradient Estimator, UPGE)的理论框架,将多种后训练方法的梯度计算统一为一个通用表达式。基于该理论,论文提出了一种名为混合后训练(Hybrid Post-Training, HPT)的算法,该算法能根据模型的实时性能动态选择SFT或RL训练信号。HPT旨在高效利用专家数据进行利用(exploitation),同时通过RL进行稳定的探索(exploration),从而在多个数学推理基准测试中显著超越了现有基线模型。
二、论文基本信息
基本信息

-
论文标题:Towards a Unified View of Large Language Model Post-Training
-
作者:Xingtai Lv, Yuxin Zuo, Youbang Sun, Hongyi Liu, Yuntian Wei, Zhekai Chen, Lixuan He, Xuekai Zhu, Kaiyan Zhang, Bingning Wang, Ning Ding, Bowen Zhou
-
作者单位:Tsinghua University, Shanghai AI Laboratory, WeChat AI
摘要精炼
本文旨在统一SFT和RL两种主流的LLM后训练范式。研究的核心问题是:SFT和RL的训练信号是否可以在一个共同的优化目标下进行理论整合?为此,论文提出了统一策略梯度估计器(UPGE)理论框架,证明了多种后训练算法的梯度是同一目标函数在不同数据分布假设和偏见-方差权衡下的特例。该框架将梯度估计器分解为四个可互换的部分:稳定掩码(stabilization mask)、参考策略(reference policy)分母、优势估计(advantage estimate)和似然梯度(likelihood gradient)。基于此理论,论文设计了HPT算法,该算法根据模型的实时采样准确率动态地在SFT和RL损失之间切换。实验结果表明,在六个数学推理基准和两个分布外测试集上,HPT在不同规模和家族的模型上均一致超越了SFT、GRPO及SFT→GRPO等强基线。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/Rvi8g96ycP05dQZ3X_V48Q
https://mp.weixin.qq.com/s/Rvi8g96ycP05dQZ3X_V48Q
三、研究背景与相关工作
研究背景
LLM的后训练对于提升其在特定任务(尤其是推理)上的能力至关重要。目前主流范式分为SFT和RL。SFT通过高质量的专家标注数据直接高效地传授知识,但容易导致模型在演示数据上过拟合,损害其泛化能力。RL则允许模型自由探索推理空间并根据环境反馈进行优化,但直接应用于基础模型(即“Zero RL”)时,对于能力较弱的模型或复杂任务,探索过程往往难以发现有意义的奖励信号。因此,“SFT-then-RL”的序贯流程成为标准,但此流程资源密集且调优复杂。如何更高效、更原则性地结合SFT和RL的优势,是当前LLM后训练领域面临的核心挑战。
相关工作
相关工作主要围绕SFT和RL的结合展开。一些方法将SFT和RL视为两个独立的目标,通过加权组合损失函数进行训练,权重可以是固定系数、预定调度或基于策略熵的动态调整(如SRFT)。例如,LUFFY在每个训练批次中混合固定比例的离线数据和在线数据。这些工作大多在实践上验证了混合训练的有效性,但普遍缺乏一个根本的理论分析来解释为何这两种看似不同的学习信号可以被有效结合。本文的工作正是在此基础上,从梯度计算的层面建立了一个统一的理论框架,为设计更具原则性的混合训练算法提供了理论依据,如本文提出的HPT。
四、主要贡献与创新
-
理论统一: 首次提出了统一策略梯度估计器(UPGE),从理论上将SFT和多种RL算法(如PPO, GRPO)的梯度计算统一到了一个包含四个可分解组件的通用框架下,揭示了它们优化的是一个共同目标。
-
算法创新: 基于统一理论,提出了混合后训练(HPT)算法。该算法不再使用固定的混合比例或复杂的调度策略,而是根据模型在具体问题上的实时表现(rollout accuracy)动态、自适应地在SFT和RL之间进行切换,实现了探索与利用的智能平衡。
-
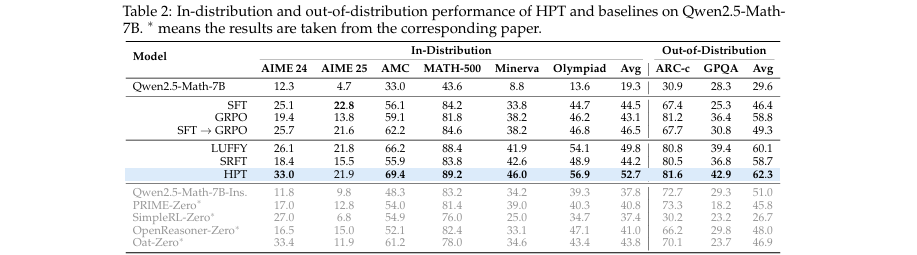
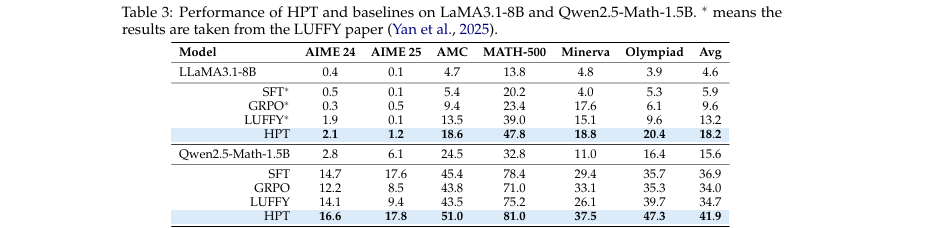
卓越性能: 在多个数学推理基准测试中,证明了HPT的有效性。实验结果(如表2、表3所示)表明,HPT在不同规模(1.5B, 7B, 8B)和家族(Qwen, Llama)的模型上均显著优于SFT、GRPO、SFT→GRPO以及LUFFY等强基线方法。
五、研究方法与原理
总体框架与核心思想
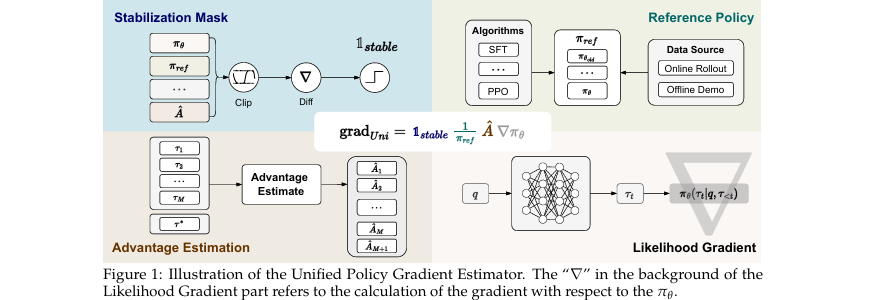
本文方法的核心思想是:将SFT和RL视为同一优化目标的两个不同“梯度估计器”,而非两个独立的目标。 论文首先定义了一个通用的后训练目标,即最大化期望奖励,同时通过KL散度约束模型策略接近专家演示策略:
通过对该目标求导,论文推导出了**统一策略梯度估计器 (UPGE)**的一般形式:
这个框架(如图1所示)揭示了不同算法的差异本质上是对stable(稳定掩码)、π_ref(参考策略)、Â(优势估计)这三个组件的不同选择,从而产生了不同的偏见-方差权衡。基于这一洞察,HPT算法的核心设计哲学是“因材施教”:当模型能力不足、探索收益低时,采用低方差的SFT梯度(利用);当模型能力足够、能有效探索时,采用RL梯度以寻求更优解(探索)。
关键实现与评估原理
关键实现细节:
-
HPT算法实现: HPT的核心是一个基于性能反馈的切换机制。对每个问题,模型首先生成
n个候选答案(rollouts),计算其平均准确率P。 -
切换门控: 算法根据
P与一个预设阈值γ的比较来决定使用SFT还是RL。具体实现了一个简单的切换函数: 其中α和β分别是RL损失和SFT损失的权重。实验中γ被设为0,意味着只有当模型在某个问题上所有尝试都失败时,才会切换到SFT。 -
损失函数: 最终的混合损失为
L = αL_RL + βL_SFT。
核心评估原理与指标:
-
评估指标: 论文主要使用
Pass@k作为核心评估指标,特别关注Pass@1(衡量模型最可能输出的正确率)和Pass@1024(衡量模型的探索能力和知识边界)。这能够全面评估算法在提升准确率(利用)和扩展能力边界(探索)两方面的效果。 -
选择理由:
Pass@1直接反映了模型的实际应用性能。而高k值的Pass@k(如文中的Pass@1024)则能揭示模型是否通过训练获得了新的解题路径,从而评估其探索能力的提升,这正是传统RL方法所追求的目标。
六、实验结果与分析
实验设置
-
数据集: 训练数据来自MATH数据集,评估在6个数学推理基准(AIME 2024/2025, AMC, MATH-500, Minerva, OlympiadBench)和2个分布外推理基准(GPQA, ARC-c)上进行。
-
评估指标: Pass@k (主要是Pass@1,以及用于分析探索能力的Pass@1024)。
-
对比基线: SFT, GRPO (一种先进的RL算法), SFT→GRPO (标准序贯流程), LUFFY (静态混合策略)。
-
关键超参: 切换门控阈值
γ=0(Qwen系列),学习率5e-6,rollout数量n=8。
核心实验与结论
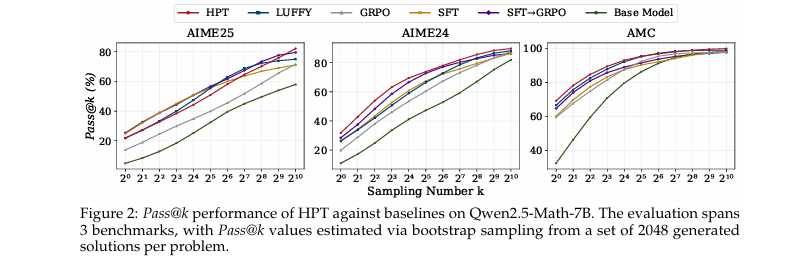
一项最能体现本文贡献的核心实验是 HPT 与基线在探索与利用上的对比分析(Pass@k 性能,如 图2 所示)。
-
实验目的: 该实验旨在验证HPT是否能在提升模型单次采样准确率(
Pass@1,即利用)的同时,有效增强模型的探索能力和知识边界(高k值的Pass@k)。这是对传统RL方法(提升Pass@1但可能损害探索能力)和SFT方法(扩展知识但Pass@1提升有限)局限性的直接回应。 - 关键结果: 如图2所示,在AIME24、AIME25和AMC三个基准测试中:
-
HPT在
k=1时的性能(曲线最左端)显著优于所有基线。 -
随着
k值增大至1024,HPT的Pass@k曲线始终位于所有其他方法的上方,达到了最高的Pass@k值。这表明HPT不仅让模型更“准”,也让模型更“广博”。 -
有趣的是,纯RL方法(GRPO)在高
k值处的表现不如包含SFT组件的方法,而HPT的表现甚至优于纯SFT,表明动态结合策略产生了1+1>2的效果。
-
-
作者结论: HPT通过动态地整合SFT和RL,成功地调和了探索与利用的矛盾。它不仅在“利用”层面(提高
Pass@1)超越了所有基线,更在“探索”层面(提升高k值的Pass@k)上最大化地保留并增强了模型的能力。这证明了HPT的设计能够有效利用离线数据引入新知识,并通过在线探索将这些知识内化并加以改进,从而突破了单一训练范式的能力上限。
七、论文结论与启示
总结
本文通过提出统一策略梯度估计器(UPGE)框架,为LLM后训练中SFT与RL的结合提供了坚实的理论基础,论证了二者是同一优化目标下的不同实现。基于此理论,论文设计的HPT算法通过一种简洁而有效的性能反馈机制,实现了SFT(利用)和RL(探索)的动态自适应切换。大量实验证明,HPT不仅在最终性能上超越了SFT、RL以及它们的静态/序贯组合,还在训练动态中展现出更健康的熵和响应长度变化,成功地将离线数据的知识内化为模型的推理能力。
展望
论文的未来工作可以朝以下几个方向发展:
-
更精细的切换机制:当前的HPT使用一个简单的二进制门控。未来可以探索更平滑、更细粒度的混合策略,例如基于不确定性或梯度的动态加权,以实现更优的训练动态。
-
扩展统一框架:UPGE框架目前主要统一了SFT和在线RL。未来可以尝试将离线RL算法(如DPO/KTO)也纳入该框架,从而构建一个更全面的LLM后训练理论。
-
跨领域应用:HPT在数学推理上表现出色,未来可以将其应用于代码生成、长文本摘要等其他需要复杂推理和规划能力的领域,以验证其通用性。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/Rvi8g96ycP05dQZ3X_V48Q
https://mp.weixin.qq.com/s/Rvi8g96ycP05dQZ3X_V48Q

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)