【NeurIPS 25】即插即用,破解LLM推理两大难题,难度偏差与熵崩塌迎刃而解
本文通过对 GRPO 的深刻洞察,提出了一个更具原则性的判别式约束优化框架 DisCO。该框架不仅从根本上解决了 GRPO 的“难题偏见”,还通过一系列精心设计的技术(如非裁剪评分函数、约束优化、DRO)成功克服了现有方法的训练不稳定和数据不平衡问题,最终在多个数学推理基准上实现了显著的性能飞跃,为强化学习优化大型推理模型提供了新的SOTA方法。个人思考 (My Thoughts):研究思路的启发
01 论文概览

论文题目 (Title): DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization
论文地址 (URL): https://arxiv.org/abs/2505.12366v3
02 核心思想与贡献
本文深入分析了当前主流的大模型推理优化方法 GRPO,揭示了其固有的“难题偏见”(Difficulty Bias)问题。为此,文章提出了一个名为 DisCO 的全新优化框架,其核心思想是将强化学习问题重塑为判别式学习问题:显式地提升正确答案的得分,同时降低错误答案的得分。该框架通过无偏的判别式目标、稳定的非裁剪(non-clipping)评分函数和高效的约束优化,实现了比 GRPO 及其变体更稳定、更高效的训练,显著提升了大型推理模型(LRMs)的性能。
主要创新点 (Key Innovations):
-
揭示 GRPO 的内在缺陷:首次从理论上剖析了GRPO在二元奖励下的目标函数,证明其“群组相对优势函数”会产生一个
sqrt(p(1-p))的权重,导致模型对过难(p≈0)或过易(p≈1)的问题关注不足,从而产生了“难题偏见”。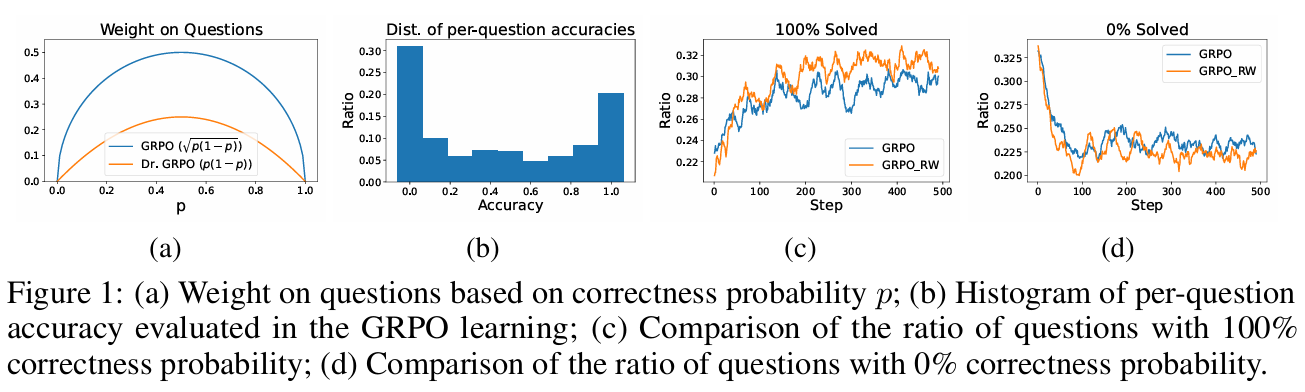
-
提出 DisCO 判别式优化框架:摒弃了 GRPO 的相对优化思路,从判别式学习的第一性原理出发,构建了一个旨在最大化正负样本得分差异的优化目标。该框架完全消除了“难题偏见”,并为解决数据不平衡等问题提供了灵活的扩展空间。
-
创新的训练稳定化机制:
- 采用非裁剪评分函数:放弃了 PPO/GRPO 中可能导致熵崩溃或训练不稳定的裁剪(clipping)操作,设计了更平滑的评分函数。
- 引入约束优化:使用高效的平方铰链惩罚(squared-hinge penalty)方法来严格实施 KL 散度约束,确保模型更新步长在可信区域内,相比传统的 KL 正则化方法,训练过程更长效、更稳定。
-
整合先进判别式技术:利用框架的灵活性,引入分布鲁棒优化(DRO)思想来应对训练中正负样本(正确/错误答案)数量严重不平衡的问题,进一步提升了学习效率。
03 方法详解
整体架构 (Overall Architecture):
DisCO 框架的核心是将模型优化问题从最大化带权重的优势函数(GRPO),转变为最大化一个纯粹的判别式目标,并置于一个严格的 KL 约束之下。整个框架主要由 判别式目标函数、评分函数 和 约束优化 三部分构成。
1. 模块一:判别式目标 (Discriminative Objective)
- 目标 (Objective): 消除 GRPO 的“难题偏见”,让模型平等地从所有问题中学习。
- 方法 (Method):
-
基础方法 (DisCO-b): 构建一个直接衡量正样本得分与负样本得分差距的目标。对于一个问题
q,其优化目标是最大化从正确答案分布π+_old中抽取的样本o和从错误答案分布π-_old中抽取的样本o'之间的得分差。
J 1 ( θ ) = E q E o ∼ π old + ( ⋅ ∣ q ) , o ′ ∼ π old − ( ⋅ ∣ q ) ℓ ( s θ ( o , q ) − s θ ( o ′ , q ) ) J_1(\theta) = \mathbb{E}_{q} \mathbb{E}_{o \sim \pi_{\text{old}}^{+}(\cdot|q), o' \sim \pi_{\text{old}}^{-}(\cdot|q)} \ell(s_\theta(o, q) - s_\theta(o', q)) J1(θ)=EqEo∼πold+(⋅∣q),o′∼πold−(⋅∣q)ℓ(sθ(o,q)−sθ(o′,q))其中
s_θ(o, q)是评分函数,ℓ是一个代理函数(如恒等函数ℓ(x)=x)。 -
改进方法 (DisCO): 为解决训练过程中负样本远多于正样本的“不平衡问题”,引入了基于 DRO 的目标函数。该目标旨在鲁棒地最大化正样本与“最难分辨”的负样本之间的得分差距。
J 2 ( θ ) = − E q E o ∼ π old + ( ⋅ ∣ q ) τ log ( E o ′ ∼ π old − ( ⋅ ∣ q ) exp ( s θ ( o ′ , q ) − s θ ( o , q ) τ ) ) J_2(\theta) = -\mathbb{E}_{q} \mathbb{E}_{o \sim \pi_{\text{old}}^{+}(\cdot|q)} \tau \log \left( \mathbb{E}_{o' \sim \pi_{\text{old}}^{-}(\cdot|q)} \exp\left(\frac{s_\theta(o', q) - s_\theta(o, q)}{\tau}\right) \right) J2(θ)=−EqEo∼πold+(⋅∣q)τlog(Eo′∼πold−(⋅∣q)exp(τsθ(o′,q)−sθ(o,q)))
-
2. 模块二:评分函数 (Scoring Function)
- 目标 (Objective): 设计一个能衡量模型
π_θ对生成序列o“偏好程度”的函数,且该函数应避免裁剪带来的问题。 - 方法 (Method): 论文提出了两种非裁剪的评分函数:
- 对数似然 (log-L):
s_θ(o,q) = (1/|o|) * Σ log(π_θ(o_t | q, o_<t)),直接使用模型生成该序列的平均对数概率。 - 似然比 (L-ratio):
s_θ(o,q) = (1/|o|) * Σ (π_θ(o_t | q, o_<t) / π_old(o_t | q, o_<t)),衡量新旧模型生成概率的比值。
- 对数似然 (log-L):
3. 模块三:约束优化 (Constrained Optimization)
-
目标 (Objective): 在优化上述目标的同时,确保新模型
π_θ不会与旧模型π_old偏离过远,以维持训练稳定。 -
方法 (Method): 采用带约束的优化,而非简单的正则化。
max θ J ( θ ) s.t. D K L ( π o l d ∣ ∣ π θ ) ≤ δ \max_\theta J(\theta) \quad \text{s.t.} \quad D_{KL}(\pi_{old} || \pi_\theta) \le \delta θmaxJ(θ)s.t.DKL(πold∣∣πθ)≤δ
为了高效求解,论文将其转化为一个带平方铰链惩罚项的无约束问题:
max θ J ( θ ) − β [ D K L ( π o l d ∣ ∣ π θ ) − δ ] + 2 \max_\theta J(\theta) - \beta [D_{KL}(\pi_{old} || \pi_\theta) - \delta]_+^2 θmaxJ(θ)−β[DKL(πold∣∣πθ)−δ]+2其中
[x]+ = max(x, 0)。这种方法的优势在于,只有当 KL 散度超出阈值δ时,惩罚项才会被激活,从而实现动态、精准的约束,避免了传统正则化方法中惩罚项始终存在的“干扰”。
04 实验与结果
- 数据集 (Datasets):
- 训练集: DeepScaleR-Preview-Dataset (包含 AIME, AMC, Omni-MATH 等约 4 万个问题)
- 测试集: AIME 2024/2025, MATH 500, AMC 2023, Minerva, Olympiad Bench (O-Bench)
- 评估指标 (Metrics): pass@1
- 对比方法 (Baselines): GRPO, GRPO-ER, Dr. GRPO, DAPO, TRPA
主要结果 (Key Results):
-
量化对比 (Quantitative Comparison): DisCO 在所有模型尺寸(1.5B, 7B, 8B)和所有六个基准测试上都显著优于 GRPO 及其所有变体。例如,在 1.5B 模型上,DisCO (log-L) 比 GRPO 平均性能高出 7%,甚至超过了使用更长上下文(24k/32k)训练和测试的 DeepScaleR-1.5B-Preview 模型。
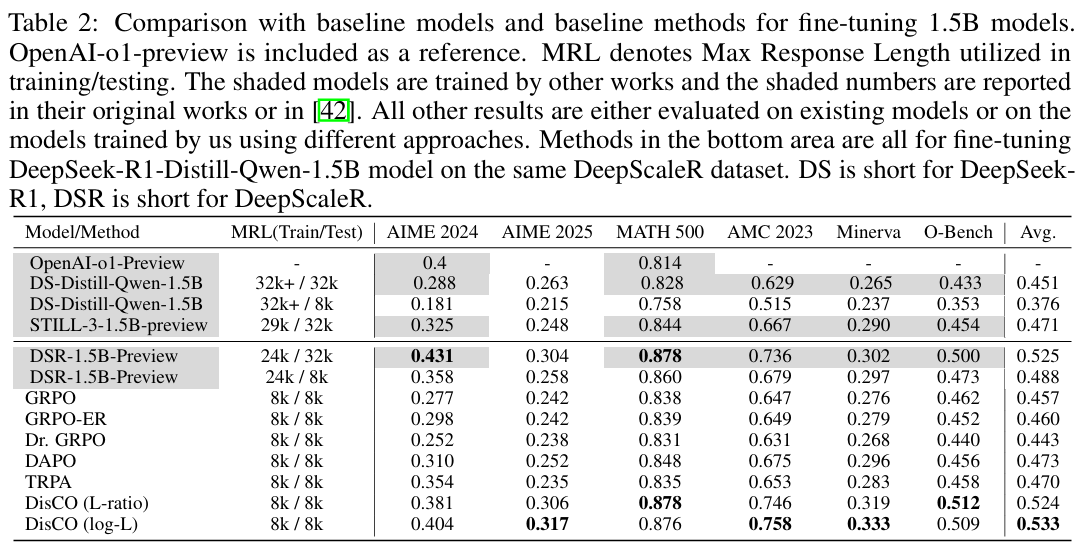
-
训练动态对比 (Training Dynamics):
- 奖励曲线: DisCO 的训练奖励能够持续、稳定地增长,而 GRPO 等基线方法由于熵崩溃或熵爆炸,很早就出现性能饱和。
- 熵曲线: GRPO 和 Dr. GRPO 的生成熵迅速崩溃至低点,DAPO 的熵则过度增长,两者都导致策略过早陷入次优。相比之下,DisCO 的熵能长期稳定在一个健康的水平(约0.22),表明模型在持续学习的同时保持了探索能力。
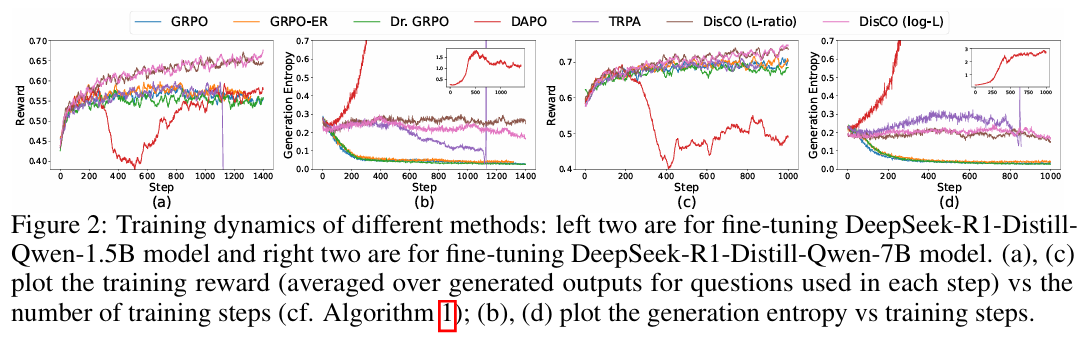
-
消融实验 (Ablation Studies): 实验系统地验证了 DisCO 各个组件的必要性。结果表明,消除难题偏见、采用非裁剪评分函数、使用约束优化以及引入DRO处理不平衡数据,每一个设计都对最终的性能提升做出了重要贡献,其中“非裁剪评分函数”的贡献尤为突出。
05 应用价值与局限性
-
适用场景 (Applicable Scenarios):
- 复杂数学与科学推理: 这是论文的核心验证场景,适用于需要长链条、严谨逻辑推理的任务。
- 代码生成与验证: 同样适用于具有可验证奖励(如单元测试通过)的代码生成任务。
- 其他可验证奖励的 RL 任务: 任何能提供明确二元(或连续)奖励的 LLM 微调任务,如事实问答、规划等。
-
潜在局限性 (Potential Limitations):
- 依赖可验证奖励: DisCO 框架建立在有明确对错信号(verifiable rewards)的基础上,对于缺乏此类信号的开放式、创造性任务(如写诗、故事续写)可能不直接适用。
- 计算复杂性: 相比于简单的 GRPO,DisCO(尤其是引入 DRO 的版本)在计算目标函数时需要对正负样本对进行操作,可能会增加单步训练的计算开销。
- 超参数敏感性: 引入了如约束阈值
δ、惩罚系数β、DRO 温度τ等新超参数,虽然实验表明其在一定范围内鲁棒,但在新任务上可能仍需仔细调优。
06 总结与个人思考
文章总结 (Summary):
本文通过对 GRPO 的深刻洞察,提出了一个更具原则性的判别式约束优化框架 DisCO。该框架不仅从根本上解决了 GRPO 的“难题偏见”,还通过一系列精心设计的技术(如非裁剪评分函数、约束优化、DRO)成功克服了现有方法的训练不稳定和数据不平衡问题,最终在多个数学推理基准上实现了显著的性能飞跃,为强化学习优化大型推理模型提供了新的SOTA方法。
个人思考 (My Thoughts):
- 研究思路的启发: 这篇论文最精彩之处在于,它没有在原有 GRPO 框架上“打补丁”,而是回归到问题的本质(区分好坏答案),并从经典的判别式学习理论中汲取灵感。这种“返璞归真”并结合现代优化工具的思路,对于解决当前深度学习中遇到的瓶颈极具启发性。
- 可跟进的研究点:
- 评分函数的设计: 论文探索了两种评分函数,未来可以研究更多样化、更有效的评分函数,例如结合答案的置信度、长度、复杂度等信息。
- 框架的泛化: DisCO 的思想可以被迁移到更广泛的领域。例如,在 RLHF (人类反馈强化学习) 中,是否可以设计类似的判别式目标来更稳定地学习人类偏好,以替代 DPO 等方法?
- 待解答的疑问: 文章的约束优化方法非常有效,但平方铰链惩罚中的
β值是如何选取的?虽然作者给出了经验法则,但其理论上的自适应调整机制或许是未来一个值得探索的方向。
06 即插即用模块
import torch
from verl.utils.model import create_random_mask, compute_position_id_with_mask
from verl.utils.torch_functional import masked_mean, log_probs_from_logits_all_rmpad, logprobs_from_logits
from flash_attn.bert_padding import unpad_input, pad_input, index_first_axis, rearrange
from transformers import LlamaConfig, MistralConfig, GemmaConfig, Qwen2Config
from transformers import AutoModelForCausalLM, AutoModelForTokenClassification, AutoModelForSequenceClassification
# TODO(sgm): add more models for test
# we only need one scale for each model
test_configs = [
LlamaConfig(num_hidden_layers=1),
MistralConfig(num_hidden_layers=1),
GemmaConfig(num_hidden_layers=1),
Qwen2Config(num_hidden_layers=1)
]
def test_hf_casual_models():
batch_size = 4
seqlen = 128
response_length = 127
for config in test_configs:
# config = AutoConfig.from_pretrained(test_case)
with torch.device('cuda'):
model = AutoModelForCausalLM.from_config(config=config,
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2')
model = model.to(device='cuda')
input_ids = torch.randint(low=0, high=config.vocab_size, size=(batch_size, seqlen), device='cuda')
attention_mask = create_random_mask(input_ids=input_ids,
max_ratio_of_left_padding=0.1,
max_ratio_of_valid_token=0.8,
min_ratio_of_valid_token=0.5)
position_ids = compute_position_id_with_mask(
attention_mask) # TODO(sgm): we can construct the position_ids_rmpad here
input_ids_rmpad, indices, *_ = unpad_input(input_ids.unsqueeze(-1),
attention_mask) # input_ids_rmpad (total_nnz, ...)
input_ids_rmpad = input_ids_rmpad.transpose(0, 1) # (1, total_nnz)
# unpad the position_ids to align the rotary
position_ids_rmpad = index_first_axis(rearrange(position_ids.unsqueeze(-1), "b s ... -> (b s) ..."),
indices).transpose(0, 1)
# input with input_ids_rmpad and postition_ids to enable flash attention varlen
logits_rmpad = model(input_ids_rmpad, position_ids=position_ids_rmpad,
use_cache=False).logits # (1, total_nnz, vocab_size)
origin_logits = model(input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
use_cache=False).logits
origin_logits_rmpad, origin_logits_indices, *_ = unpad_input(origin_logits, attention_mask)
logits_rmpad = logits_rmpad.squeeze(0)
log_probs = log_probs_from_logits_all_rmpad(input_ids_rmpad=input_ids_rmpad,
logits_rmpad=logits_rmpad,
indices=indices,
batch_size=batch_size,
seqlen=seqlen,
response_length=response_length) # (batch, seqlen)
origin_log_probs = log_probs_from_logits_all_rmpad(input_ids_rmpad=input_ids_rmpad,
logits_rmpad=origin_logits_rmpad,
indices=origin_logits_indices,
batch_size=batch_size,
seqlen=seqlen,
response_length=response_length) # (batch, seqlen)
torch.testing.assert_close(masked_mean(log_probs, attention_mask[:, -response_length - 1:-1]),
masked_mean(origin_log_probs, attention_mask[:, -response_length - 1:-1]),
atol=1e-2,
rtol=1e-5)
print(f'Check pass')

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)