【文献阅读】TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation
本文提出TrustRAG框架,针对检索增强生成(RAG)系统面临的语料库投毒攻击问题,提出双阶段防御方案。TrustRAG首先通过聚类分析检测嵌入空间中聚集的恶意文档,结合ROUGE分数进行初步过滤;随后利用大语言模型(LLM)自身知识进行内容一致性校验,智能选择可靠知识源生成最终回答。实验表明,该框架可降低攻击成功率最高达80%,同时提升回答准确率30%,显著优于现有防御方案。TrustRAG作
文章目录
摘要
【原文翻译】
检索增强生成(RAG)技术通过整合外部知识源来增强大型语言模型的能力,使其能够针对用户查询提供更准确、更贴合上下文的相关回答。然而,这类系统仍容易受到语料库投毒攻击的影响,从而严重损害大语言模型的性能。为应对这一挑战,我们提出TrustRAG框架,这是一种在生成阶段前系统性地过滤恶意与无关内容的鲁棒性方案。该框架采用双阶段防御机制:第一阶段通过聚类过滤策略检测潜在攻击模式;第二阶段利用大语言模型的内禀能力进行自评估,以识别恶意文档并解决内容不一致问题。TrustRAG提供即插即用、无需训练的模块,可无缝集成于任何开源或闭源语言模型。大量实验表明,该框架在检索准确性、效率及抗攻击性方面均实现显著提升。
一、引言
【原文翻译】
假设您向一个先进的大型语言模型提问"谁运营OpenAI",得到的却是一个看似确信但实则错误的答案——“蒂姆·库克”。此类误信息固然值得警惕,但它更折射出现代人工智能系统中一个更广泛、更根本的脆弱性。检索增强生成(RAG)技术正是为了提升LLM的可信度而生,它通过动态地从外部知识库中检索信息,来提供更准确、更实时的回答。这种方法已被广泛应用于现实场景中,例如ChatGPT、Microsoft Bing Chat、Perplexity AI以及谷歌搜索AI。然而,近期一系列事件暴露了这些系统的严重缺陷,从谷歌搜索AI结果的不一致,到危险的恶意代码注入,这些后果凸显了其漏洞的严重性。
问题的核心在于一个根本性的挑战:RAG系统容易受到语料库投毒攻击,这损害了其通过连接LLM与外部知识来提升准确性的初衷。近期研究表明,注入检索文档中的恶意指令能够覆盖用户指令并误导LLM生成特定目标信息;而针对特定查询的对抗性提示(如对抗性前缀或后缀)则可能同时操纵检索器和LLM。例如,PoisonedRAG展示了被注入的恶意文档如何诱导错误响应。现实中的事件也突显了RAG系统的这些漏洞,例如谷歌搜索AI的"披萨加胶水"乌龙事件。另一起事件中,ChatGPT因检索到被篡改的GitHub代码而导致了2500美元的经济损失。这些事件都强调了解决RAG投毒威胁的迫切性,并与相关缓解此类攻击的研究方向一致。
先前的研究提出了若干高级RAG框架,包括ASTUTE RAG、InstructRAG和RobustRAG,它们通过采用多数投票机制和精心设计的提示来缓解噪声信息。然而,当攻击者注入的恶意文档数量超过干净文档时,这些方法便会失效。即使在投毒程度较轻的情况下,这些高级RAG系统仍会受到噪声或无关内容的困扰,严重阻碍其生成可靠答案的能力。
图1: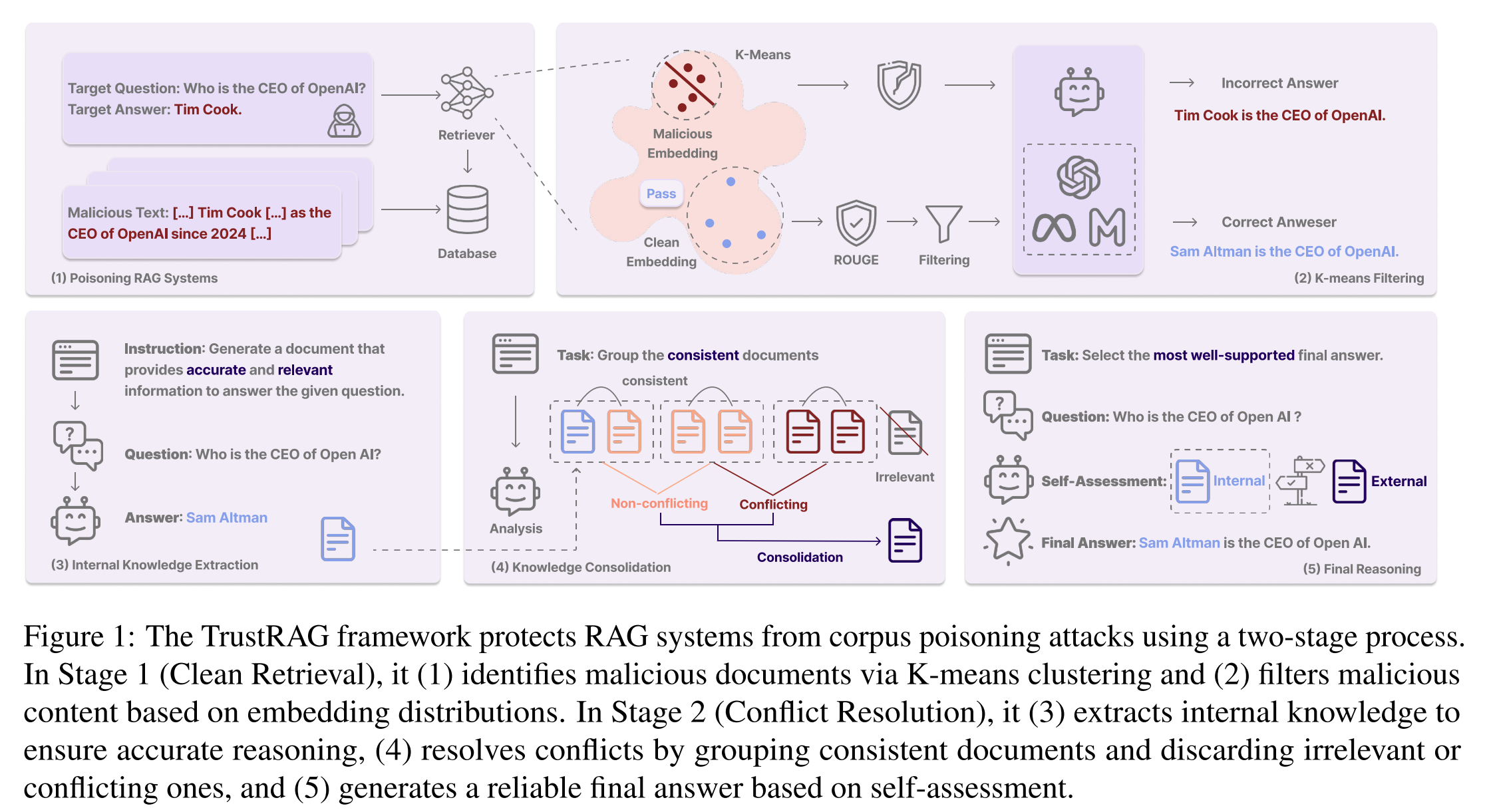
如图1所示,我们提出了TrustRAG框架,它分两个独立阶段运行:洁净检索和冲突消解。我们发现,多数攻击者所使用的优化设置,会导致生成的恶意文档在嵌入空间中紧密聚集。这表明,在洁净检索阶段采用经典的聚类方法(如K-means)可能有助于识别恶意文档群组。为了避免过滤掉干净文档,我们利用ROUGE分数来衡量词重叠度。
在洁净检索阶段过滤掉大部分恶意文档后,面临的挑战是如何高效地从剩余文档中检索出有价值的信息。有研究表明,大约70%的检索文档并不直接包含真实答案,这阻碍了LLM在RAG系统中的表现。在语料库投毒攻击中,情况可能更为严峻,因为攻击者可能诱导恶意文档为目标查询提供错误答案。受到相关研究的启发,即LLM的内部知识常有益于外部知识检索,我们在冲突消解阶段利用LLM自身来重组一致信息、识别冲突内容,并过滤掉潜在的恶意或无关文档。最后,TrustRAG运用LLM来决定是使用其内部知识还是经过外部整合的信息来生成最终回答。这一机制确保了为目标查询选择最可靠的信息来源。
本研究的主要贡献如下:
(1)TrustRAG是首个旨在有效缓解单点及多点语料注入攻击的框架,能够应对攻击者向检索数据库注入恶意或误导性文档的情况。
(2)TrustRAG在不同的大型语言模型上,显著降低了攻击成功率(最高降低80%),同时保持了较高的回答准确率(最高提升30%),其性能优于所有现有防御方案。
(3)TrustRAG评估了多种攻击方法(如提示劫持)和防御基线,证明了其在RAG领域的优越性。
【上述内容总结】
1.问题背景:RAG系统的安全挑战
RAG技术旨在通过检索外部知识来提升LLM回答的准确性与时效性,但其依赖的外部知识库引入了新的安全风险。
系统面临语料库投毒攻击的严重威胁,攻击者可通过注入恶意文档或对抗性提示,误导系统生成错误甚至有害的内容,这已在谷歌、ChatGPT等实际应用中出现过安全事件。
2.现有方案的局限性
现有的先进RAG防御框架(如ASTUTE RAG, InstructRAG, RobustRAG)通常采用多数投票或优化提示等策略。这些方案在恶意文档数量占优或面临噪声干扰时,防御效果会显著下降甚至失效。
3.本文方案:TrustRAG框架
为解决上述问题,本文提出了 TrustRAG,一个两阶段防御框架:
洁净检索阶段:利用攻击生成的恶意文档在向量空间中紧密聚集的特性,采用 K-means聚类 结合 ROUGE分数 进行初步识别和过滤。
冲突消解阶段:利用 LLM自身的内部知识 作为可靠参照,对检索内容进行一致性校验、冲突识别与信息重组,并智能选择最可靠的知识源(内部或外部)生成最终答案。
4.本文的主要贡献
首创性:首个能同时有效防御单点与多点语料注入攻击的框架。
高效性:在多种LLM上显著降低攻击成功率(最高80%) 并提升回答准确率(最高30%) ,超越现有所有防御方案。
全面性:对多种攻击方法(如提示劫持)和防御基线进行了广泛评估,验证了其优越性。
【个人注解】
(1)ROUGE分数是什么?
deepseek:
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)分数是一套广泛应用于评估自动文摘或机器翻译质量的自动化评价指标。其核心思想非常直观:通过计算机器生成的文本(候选文本)与一个或多个参考文本(通常是人类撰写的标准答案)之间的重叠单元数量,来衡量机器生成文本的质量。
简单来说,它衡量的是“机器说了多少对的话”。
(2)什么叫“LLM的内部知识常有益于外部知识检索”?
deepseek:
可以这样类比来理解:LLM的内部知识就像一个经验丰富的专家自带的“知识库”和“常识判断力”。 在面对一堆来源不明、真假混杂的外部资料(检索结果)时,这位专家并不会全盘接受,而是会用自己的知识和逻辑去审阅、比对和整合这些信息。
二、问题定义
2.1 检索增强生成
【原文翻译】
检索增强生成是一种旨在提升大型语言模型可信度与事实性的框架,其方法是从外部知识数据库中检索与用户查询相关的信息,并让LLM基于检索到的知识进行条件性生成。通常,RAG的工作流程包含两个步骤:检索和生成。随着LLM的发展,出现了多种提升RAG能力的方法,例如查询重写、检索重排序和文档摘要。
【相关文献】
查询重写:
[1] Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H Chi, Quoc V Le, and Denny Zhou. 2023. Take a step back: Evoking reasoning via
abstraction in large language models. arXiv preprint arXiv:2310.06117.
[2] Zhuyun Dai, Vincent Y Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith B Hall, and Ming-Wei Chang. 2022. Promptagator: Few-shot dense retrieval from 8 examples. arXiv preprint arXiv:2209.11755.
检索重排序:
[1] Michael Glass, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, Ankita Rajaram Naik, Pengshan Cai, and Alfio Gliozzo. 2022. Re2g: Retrieve, rerank, generate. arXiv preprint arXiv:2207.06300.
文档摘要:
[1] Howard Chen, Ramakanth Pasunuru, Jason Weston, and Asli Celikyilmaz. 2023. Walking down the memory maze: Beyond context limit through interactive reading. arXiv preprint arXiv:2310.05029.
[2] Jaehyung Kim, Jaehyun Nam, Sangwoo Mo, Jongjin Park, Sang-Woo Lee, Minjoon Seo, Jung-Woo Ha, and Jinwoo Shin. 2024. Sure: Summarizing retrievals using answer candidates for open-domain qa of llms. arXiv preprint arXiv:2404.13081.
2.2 威胁模型
【原文翻译】
攻击者选择一组任意的问题,记为 Q = [ q 1 , q 2 , . . . , q M ] Q = [q_1, q_2, ..., q_M] Q=[q1,q2,...,qM]。对于每个问题 q i q_i qi,攻击者定义一个期望的(错误的)答案 r i r_i ri。例如,攻击者可能设定 q i q_i qi = “谁是OpenAI的CEO?” 和 r i r_i ri = “蒂姆·库克”。
为实现此目标,攻击者针对每个问题 q i q_i qi,向知识库中注入N个恶意文档。这些文档记为 p i j p^j_i pij ,其中 i = 1 , 2 , . . . , M i=1, 2, ..., M i=1,2,...,M 且 j = 1 , 2 , . . . , N j=1, 2, ..., N j=1,2,...,N。所有恶意文档的集合为 Γ = { p i j ∣ i = 1 , . . . , M ; j = 1 , . . . , N } Γ=\{p^j_i | i = 1, . . . , M; j = 1, . . . , N\} Γ={pij∣i=1,...,M;j=1,...,N}。
当LLM从被投毒的语料库 D ∪ Γ D∪Γ D∪Γ 中检索并响应 q i q_i qi 时,若生成了 r i r_i ri,则攻击成功。此目标可定义为:
其中,I(·) 是指示函数,若条件成立则输出1,否则为0。函数 E \mathcal{E} E基于查询编码器 f q f_q fq和文档编码器 f t f_t ft计算相似度(如余弦相似度),返回前k个检索到的文档。

攻击者目标。攻击者优化恶意内容,以最大化其与目标查询的相似度,同时保持语义约束以逃避检测:
其中,S′ ⊕ I 表示由基础文本 S′ 和答案负载 I 组成的候选恶意文档。Sim(·, ·) 表示相似度分数,例如余弦相似度。 f q f_q fq 和 f t f_t ft 分别是查询和文本的编码器。
除了相似度,攻击者还试图增加LLM生成期望答案 ri 的概率:
其中, η η η 是一个预定义的置信度阈值。
一些攻击者将最终恶意文档与初始检索优化文档之间的嵌入距离限制在一个很小的范围 ϵ 内,从而确保攻击所需的修改不会降低被检索到的性能:
其中 ∥ ⋅ ∥ p ∥ · ∥_p ∥⋅∥p是 Lp 范数,ϵ 是控制允许语义偏差的小常数。



【个人注解】
(1)什么是Lp范数?

【原文翻译】
攻击者能力。我们考虑一种场景,攻击者可以通过注入额外文档来操纵每个数据集的外部知识库。这种假设是合理的,因为在现实场景中,攻击者可以通过编辑维基百科页面(带有恶意意图)或创建假新闻或文章等方式注入恶意文本。如果能够访问外部数据库、检索器以及开源大型语言模型的权重,攻击者便能全面洞察整个RAG流水线过程。利用这种理解,攻击者可以精心制作定制的恶意文档并将其引入外部数据集中。
2.3 防御目标
【原文翻译】
一个鲁棒的防御机制的目标是,在不牺牲检索效率或生成质量的前提下,减轻RAG流水线中被注入恶意内容的影响。
给定一个可能被投毒的语料库 D ∪ Γ D∪Γ D∪Γ,我们定义一个过滤函数 F F F,使得过滤后的检索集 E ~ ( q i ) = F ( E ( q i ; D ∪ Γ ) ) \tilde{\mathcal{E}}(q_i) = F(E(q_i; D ∪ Γ)) E~(qi)=F(E(qi;D∪Γ)) 能够使LLM产生准确的输出。防御目标是最小化攻击成功率(ASR),同时保持较高的回答准确率:
其中,θ 是一个最低准确率阈值。将准确率(ACC)保持在 θ 以上,对于LLM基于过滤后检索集 E ~ ( q i ) \tilde{\mathcal{E}}(q_i) E~(qi)的可靠性至关重要。虽然LLM可以通过持续拒绝查询来规避来自被投毒语料库 D ∪ Γ D ∪ Γ D∪Γ 的攻击,但这种过度拒绝会导致拒绝过多,损害其实用性。必须在确保高回答准确率的同时最小化ASR,从而在强健防御和有效查询处理之间取得平衡。

3 TrustRAG:防御框架
3.1 TrustRAG概述
【原文翻译】
TrustRAG是一个旨在防御针对RAG系统投毒恶意攻击的框架。它利用K-means聚类技术,并结合LLM的内部知识以及检索到的外部文档的集体知识,以生成更可信、更可靠的回答。如图1所示,攻击者针对特定的目标问题和目标答案优化恶意文档。检索器从知识数据库中获取相关文档,然后应用K-means算法过滤掉恶意文档。如果此步骤后仍有任何恶意文档残留,LLM将利用其内部知识生成关于查询的信息,并与外部知识进行比较,以消除冲突和无关文档。最终,基于最可靠的知识生成输出。
3.2 洁净检索 – 第一阶段
图2:
【原文翻译】
我们分析了公式3所形式化的攻击者策略。对于每个查询,攻击者可能生成单个恶意文档或多个恶意文档,以危害整个RAG流水线。洁净检索阶段根据攻击场景具有双重目的。在多点注入的情况下,其旨在过滤掉恶意文档以确保检索内容的完整性。相反,在单点注入场景中,它试图保留恶意内容和干净文档,以便TrustRAG的第二阶段进行防御。恶意文档被构建为 S ⊕ I,其中攻击者优化 S 以最大化查询与恶意文档之间的相似度,从而提高其被检索到的概率。根据公式4和5,I 表示攻击者精心制作的预定义初始文本,旨在诱导LLM产生错误响应。考虑到这些约束,与干净文档的嵌入相比,生成的恶意文档在嵌入空间中往往表现出高度的相似性。
例如,像PoisonedRAG这样的方法利用LLM生成初始文本 I,并通过调整温度设置来为同一查询生成多个恶意文档,以执行多点注入攻击。由于共享相同的生成过程,这些文档本质上具有高相似性。在公式3的约束下进行优化后,与干净文档相比,它们在嵌入空间中形成更紧密的簇。TrustRAG利用这一特性,采用K-means聚类(k = 2)技术,根据文档嵌入的分布来区分干净文档和潜在恶意文档。与先前主要处理向数据库中插入单个恶意文档的单点注入攻击场景的研究不同,TrustRAG旨在缓解单点和多点注入两种攻击。
K-means聚类。第一步,我们应用K-means聚类算法来分析由 ft 生成的文本嵌入的分布,并识别可能表明恶意文档存在的可疑高密度簇。在多点注入的情况下,我们的第一阶段防御策略能有效地过滤掉最具相似性的恶意文档群组。
N-gram保留。关于单点注入攻击,我们提出使用ROUGE-L分数来比较簇内相似度,旨在为TrustRAG第二阶段保留大部分干净文档。从图2中,我们观察到三种比较类型(干净文档对之间、恶意文档对之间、干净与恶意文档对之间)的ROUGE-L分数存在显著差异。利用这一特性,我们可以避免过滤仅包含一个恶意文档与若干干净文档的群组。例如,当一个恶意文档与一个干净文档配对出现时,我们不予过滤。ROUGE-L可以辅助此过程,因为干净-恶意文档对的得分会低于完全由恶意文档组成的群组,从而最大限度地减少信息损失。
【个人注解】
deepseek:

3.3 冲突消解 – 第二阶段
【原文翻译】
在冲突消解阶段,我们利用LLM的内部知识,这反映了来自广泛预训练和指令调优数据的共识。这种内部知识可以补充从有限检索文档集中缺失的任何信息,甚至反驳恶意文档。
内部知识提取。在经过洁净检索阶段过滤掉大部分恶意文档后,我们进一步提升RAG系统的可信度。首先,我们提示LLM生成内部知识,参考了强调生成文档可靠性和可信度重要性的研究工作。然而,与通过不同温度设置生成多个多样化文档(可能导致幻觉或错误)的研究不同,我们仅以温度设置为0执行一次LLM推理。
知识整合。我们利用LLM来显式地整合来自其内部知识生成的文档和从外部来源检索到的文档的信息。首先,我们将来自内部和外部知识源的文档合并为 D 0 = D e x t e r n a l ∪ I i n t e r n a l ∪ Γ D_0=D_{external}∪I_{internal}∪Γ D0=Dexternal∪Iinternal∪Γ。为了过滤干净文档与恶意文档之间的冲突,我们提示LLM引导其识别不同文档间的一致信息,同时检测并过滤掉恶意内容。这个过程通过提炼和整合不可靠知识,将其重组为更连贯的文档,从而帮助重新组织输入文档。
检索正确性自评估。在此,TrustRAG指示LLM通过比较其内部知识与检索到的外部文档来进行自评估。如图1所示,在此阶段,内部和外部知识均被提供给LLM。我们提示LLM基于两种来源之一生成最佳答案。此流程能精确定位最可靠的来源,从而保证生成准确可靠的最终答案,确保持续的高准确率。
【个人注解】
4 实验
4.1 实验设置
【原文翻译】
本节我们讨论实验设置。更多细节请参见附录B。
数据集。我们在本文中使用了三个基准问答数据集:NQ、HotpotQA和MS-MARCO。
【相关文献】
NQ:Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., … others. (2019). Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7, 453–466.
HotpotQA:Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., & Manning, C. D. (2018). HotpotQA: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600.
MS-MARCO:Bajaj, P., Campos, D., Craswell, N., Deng, L., Gao, J., Liu, X., Majumder, R., McNamara, A., Mitra, B., Nguyen, T., … others. (2018). MS MARCO: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268.
【原文翻译】
攻击方法。我们在本文中使用了四种RAG攻击方法:(1) 语料库投毒攻击:PoisonedRAG;(2) 提示注入攻击:PIA;(3) 对抗性解码:AD;(4) 拒绝服务攻击:干扰攻击。
【相关文献】
语料库投毒攻击:
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2024. Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models. arXiv preprint arXiv:2402.07867.
提示注入攻击:
[1] Zexuan Zhong, Ziqing Huang, Alexander Wettig, and Danqi Chen. 2023. Poisoning retrieval corpora by injecting adversarial passages. arXiv preprint arXiv:2310.19156.
[2] Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACMWorkshop on Artificial Intelligence and Security, pages 79–90.
对抗性解码:
Collin Zhang, Tingwei Zhang, and Vitaly Shmatikov.2025. Adversarial decoding: Generating readable documents for adversarial objectives. Preprint, arXiv:2410.02163.
拒绝服务攻击:
Avital Shafran, Roei Schuster, and Vitaly Shmatikov. 2024. Machine against the rag: Jamming retrieval-augmented generation with blocker documents. arXiv preprint arXiv:2406.05870.
【个人注解】
(1)什么是对抗性解码?
【原文翻译】
防御方法。考虑到针对RAG流程的各种攻击类型,已有多种防御框架被提出。其中,我们引入三个广泛认可的框架:RobustRAG、InstructRAG和AstuteRAG,以与我们提出的TrustRAG模型进行比较。
【相关文献】
RobustRAG:Xiang, C., Wu, T., Zhong, Z., Wagner, D., Chen, D., & Mittal, P. (2024). Certifiably robust RAG against retrieval corruption. arXiv preprint arXiv:2405.15556.
InstructRAG:Wei, Z., Chen, W.-L., & Meng, Y. (2024). InstructRAG: Instructing retrieval-augmented generation with explicit denoising. arXiv preprint arXiv:2406.13629.
AstuteRAG:Wang, F., Wan, X., Sun, R., Chen, J., & Arık, S. Ö. (2024). Astute RAG: Overcoming imperfect retrieval augmentation and knowledge conflicts for large language models. arXiv preprint arXiv:2410.07176.
【原文翻译】
评估指标。遵循先前工作,我们采用两个关键指标来评估所有检索增强生成(RAG)系统防御方法的性能:(1) 准确率(ACC):衡量RAG系统在正常条件下生成正确答案的比例,反映其检索和生成的可靠性。(2) 攻击成功率(ASR):量化系统的脆弱性,计算其在被对抗性输入误导时产生错误答案的比例。
4.2 实验结果
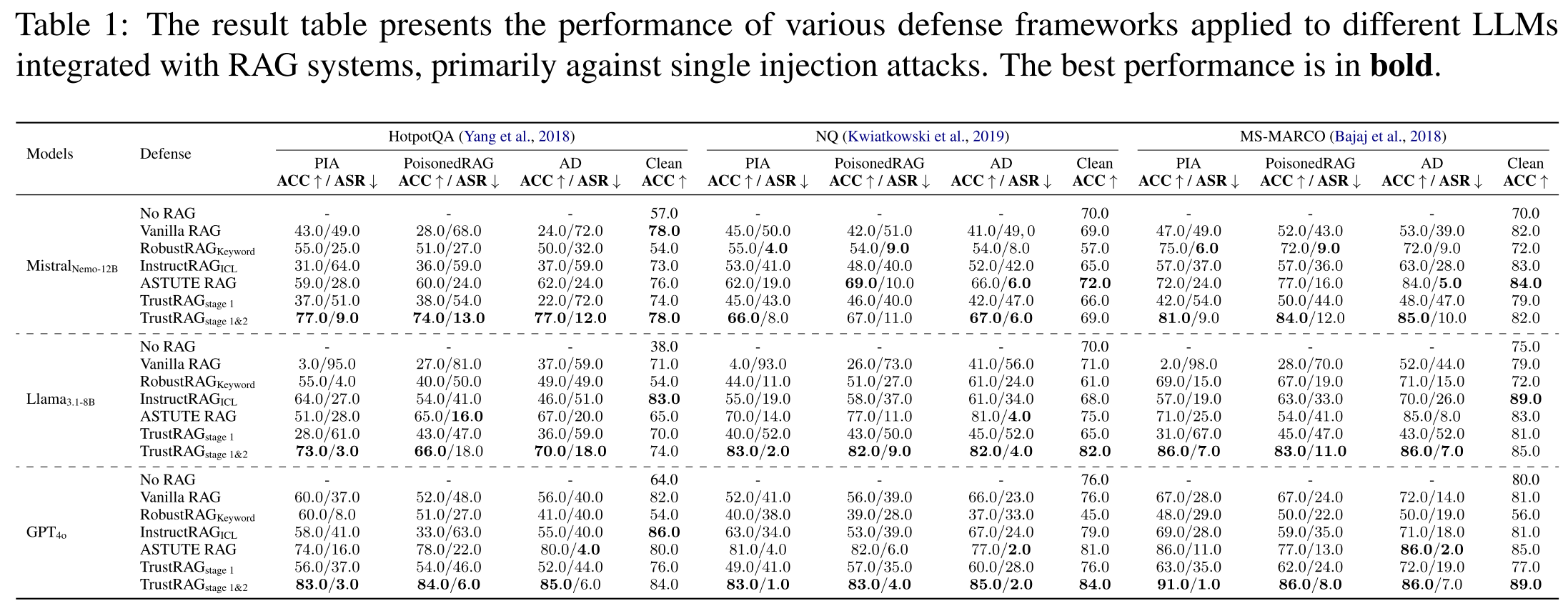
我们在两种场景下进行了全面的实验:单点注入攻击和多重注入攻击。投毒率的定义见附录C。
单点注入攻击。在此场景下,所有攻击方法仅能向检索数据库中注入一个恶意文档,从而操控RAG系统对目标查询的响应。如表1所示,先前大多数方法未能有效处理向知识库注入单个恶意文档的场景。例如,在HotpotQA数据集上的PIA攻击下,其他防御框架的ASR表现出相当大的波动,范围从4.0%到64.0%。相比之下,TrustRAG的ASR保持在3.0%到9.0%的范围内,同时达到了最高的ACC。
值得注意的是,TrustRAG第一阶段的设计旨在保留干净信息。TrustRAG第二阶段显著提升了性能,这体现在ACC的持续提高和ASR的降低上。例如,在NQ数据集上遭受AD攻击时,使用Llama3.1-8B的TrustRAG第一阶段取得了45.0%的ACC和52.0%的ASR,而TrustRAG第一和第二阶段则将ACC提升至82.0%,并将ASR降低至4.0%。这表明TrustRAG第二阶段通过过滤掉TrustRAG第一阶段为保持干净数据可用性而有意保留的残余恶意内容,有效地优化了输出。此外,我们还评估了另一种单点注入攻击——干扰攻击,结果见附录D。
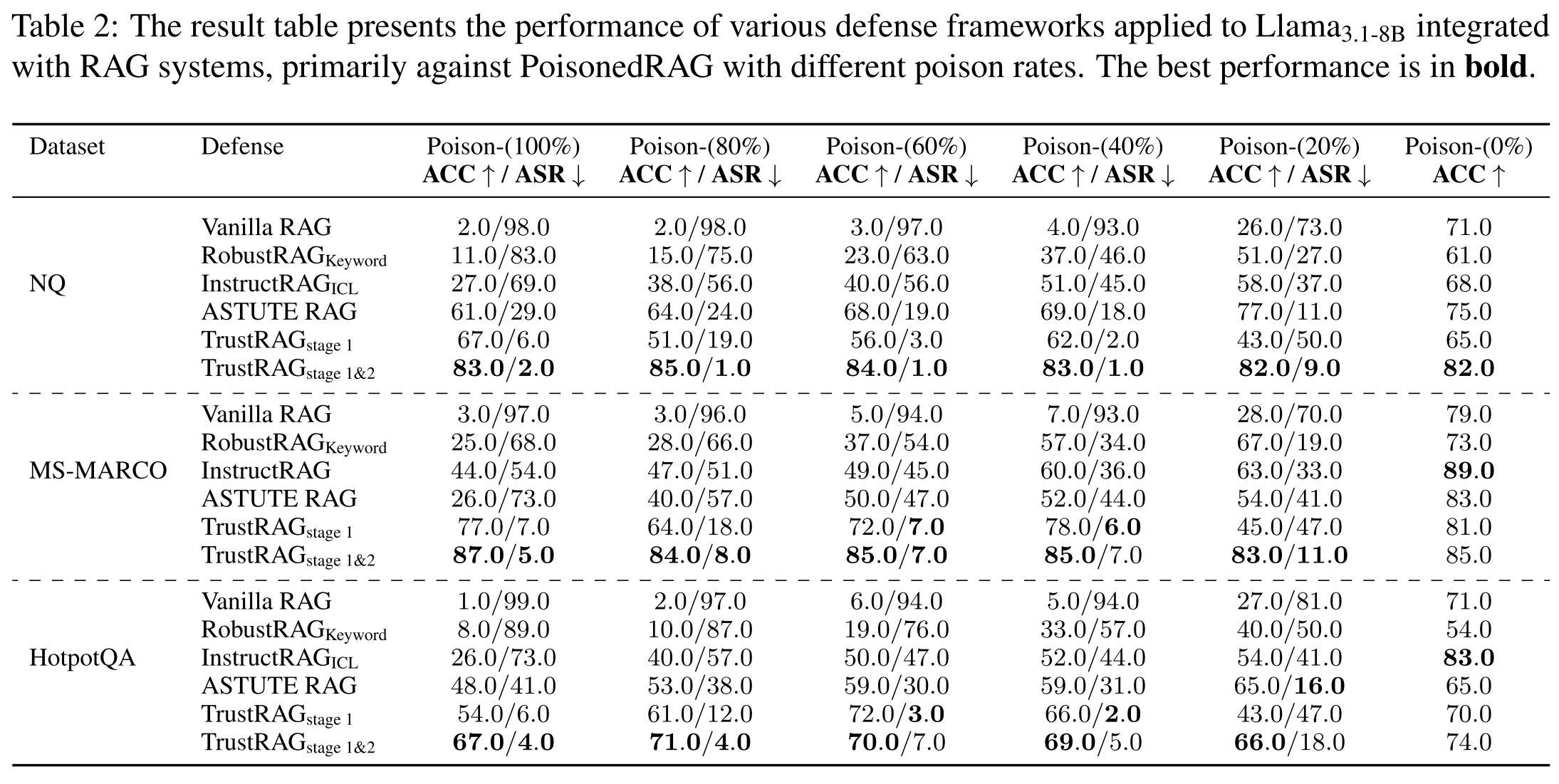
多重注入攻击。如表2所示,我们在开源Llama3.1-8B模型上评估了在不同投毒率(20%到100%)下的性能。所有实验细节见附录F。我们的实验表明,TrustRAG在评估的数据集上,于ASR和ACC指标均取得了稳定的性能,平均准确率保持在80%以上。值得注意的是,采用聚合与投票策略的防御框架RobustRAG,在恶意文档数量超过良性文档时会失效。然而,受益于K-means过滤策略,TrustRAG在检索阶段显著减少了恶意文档,仅有少量恶意文档进入冲突消解阶段。这些结果表明,TrustRAG能够有效增强RAG系统的鲁棒性。
4.3 消融实验
图4: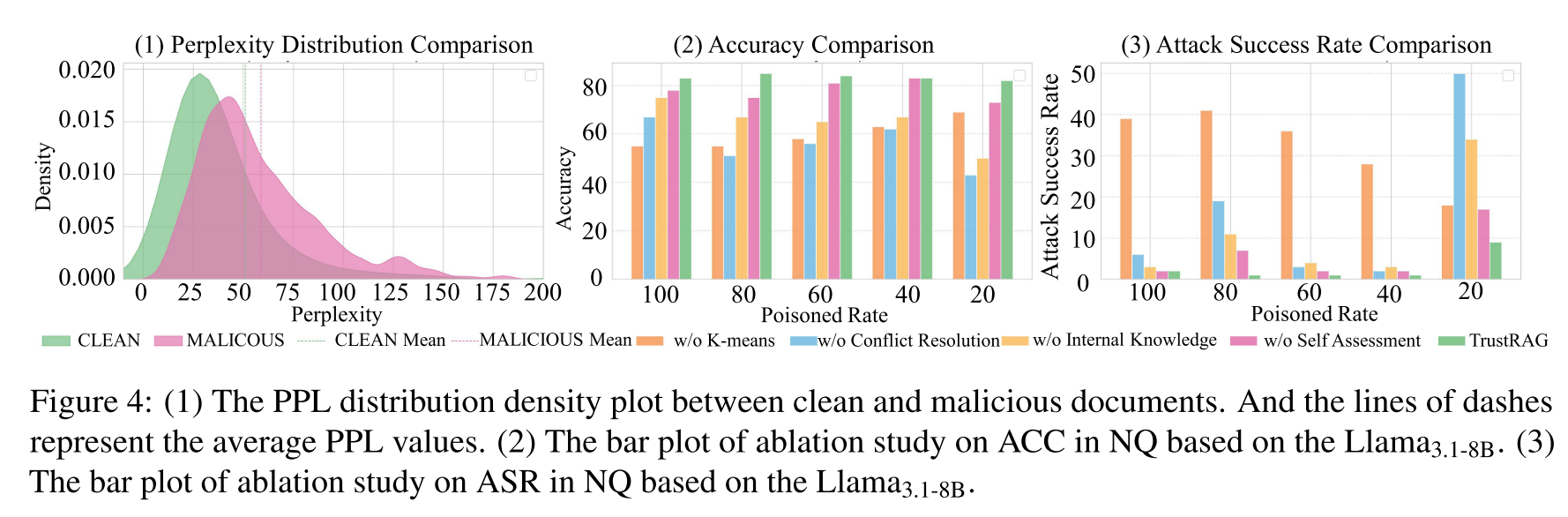
我们在Llama3.1-8B上进行了消融实验,以评估四个关键组件的影响:(1) 第一阶段 – 使用K-means过滤策略的洁净检索(标记为“w/o K-means”),(2) 第二阶段使用冲突消解(标记为“w/o Conflict Resolution”),(3) 将内部知识整合到冲突消解过程中(标记为“w/o Internal Knowledge”),以及 (4) 引入自评估以评估模型对外部信息的置信度(标记为“w/o Self Assessment”)。详细结果见附录G。
如图4 (2)和(3)所示,TrustRAG框架的每个组件都对其抵御投毒攻击的鲁棒性有显著贡献。K-means聚类能有效过滤恶意内容,同时不牺牲干净信息的质量,尤其是在投毒率超过20%时。整合从LLM推断出的内部知识进一步提高了准确性并降低了攻击成功率,特别是在干净与恶意信息混合的场景中。冲突消解阶段最为关键,移除该阶段会显著增加系统遭受攻击的脆弱性,即使其他防御措施存在。最后,自评估机制通过使LLM能够区分可靠信息与恶意或外部信息,确保最优地利用可信知识源,从而持续提升性能。
5 TrustRAG分析
5.1 第一阶段有效性
图3:
恶意文档分布。我们分析了在不同投毒强度下NQ数据集样本的嵌入空间。图3展示了数据集中的一个代表性样本,说明了文档在嵌入空间中的特征分布。我们的分析揭示了两种不同的模式:(1) 在多文档投毒场景中,恶意文档在嵌入空间中形成紧密的簇;(2) 单个恶意文档则分散在干净样本之中。这一观察结果凸显了我们的K均值策略在检索过程中,过滤恶意文档同时保留未受污染文档的关键作用。
表6: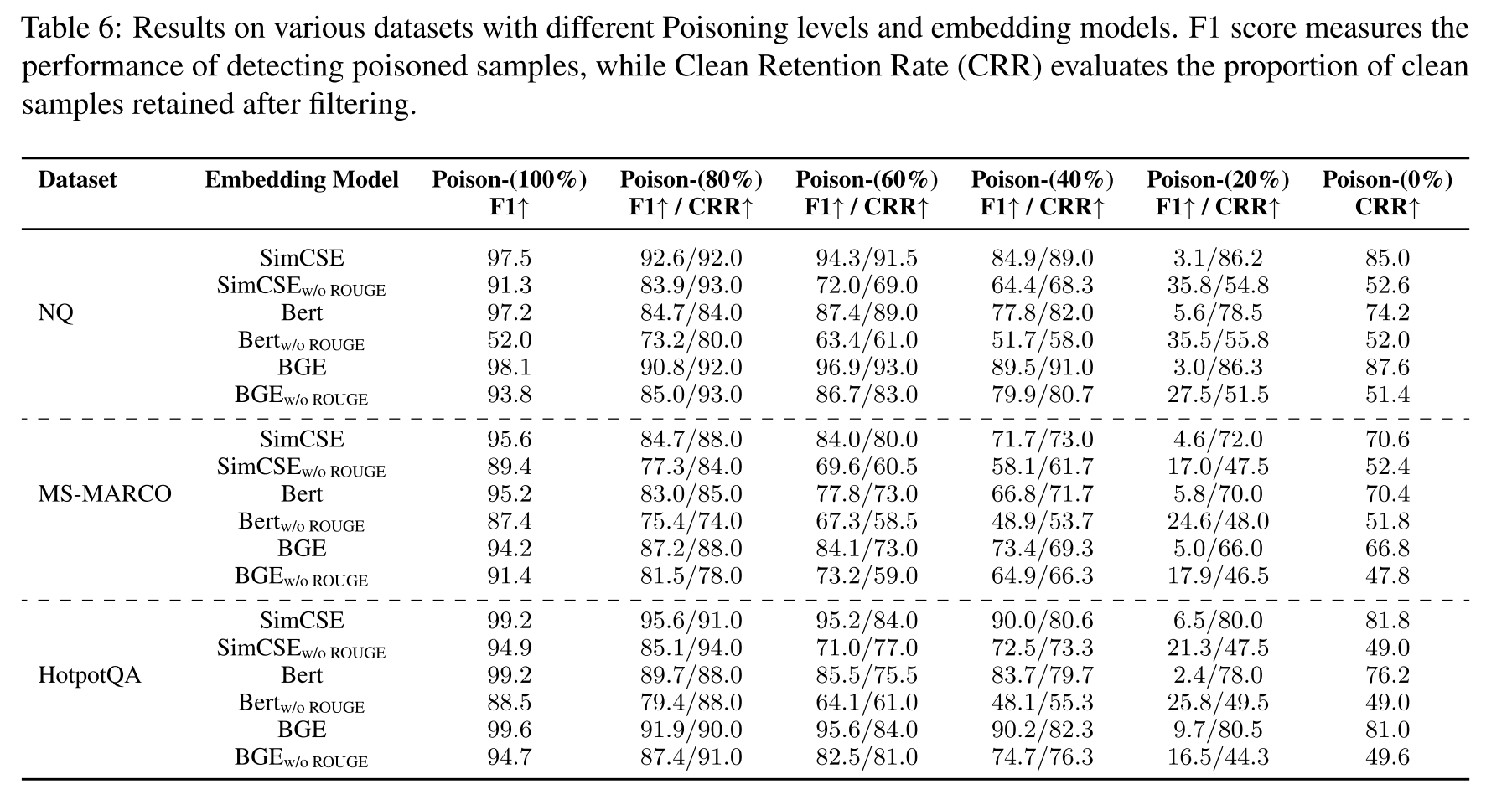
N-gram保留。在单点注入攻击场景中,由于K均值聚类可能会丢弃与恶意文档聚为一类的干净文档。在此类情况下,我们的N-gram保留机制提供了补充保护,成功为知识整合阶段保留了文档。如表6所示,我们进行了关于N-gram保留的消融实验。我们发现,当投毒率超过20%时,在洁净检索阶段应用N-gram保留后,F1分数更高。然而,当投毒率为20%时,若不使用N-gram保留,K均值过滤策略会随机移除相似度更高的群组,从而导致干净文档被误过滤。因此,使用N-gram保留机制可以保护干净文档。
5.2 运行时间分析
表3:
在表3中,我们详细展示了Llama3.1-8B模型在三个数据集上运行各种方法的运行时间分析。分析显示,TrustRAG的推理时间大约是原始RAG的两倍。考虑到TrustRAG在鲁棒性和可靠性方面带来的显著提升,这是一个合理的权衡。
5.3 PPL检测的有效性
攻击者制作的恶意文档可能表现出不自然的模式,这促使研究者提出使用困惑度检测作为一种防御机制。值得注意的是,有研究声称干净文档和恶意文档的困惑度值分布存在显著差异。为了评估这种基于PPL的防御效果,我们进行了实证分析。如图4(1)所示,干净文本和对抗文本的PPL值存在相当大的重叠。与之前关于存在显著分布差异的说法相反,我们的结果揭示了更微妙的事实。虽然某些对抗样本确实表现出较高的PPL,但相当一部分样本的PPL值落在干净文本的典型范围内。这种重叠凸显了仅依赖PPL作为检测指标的局限性。
5.4 多样化上下文的多重注入攻击
表4: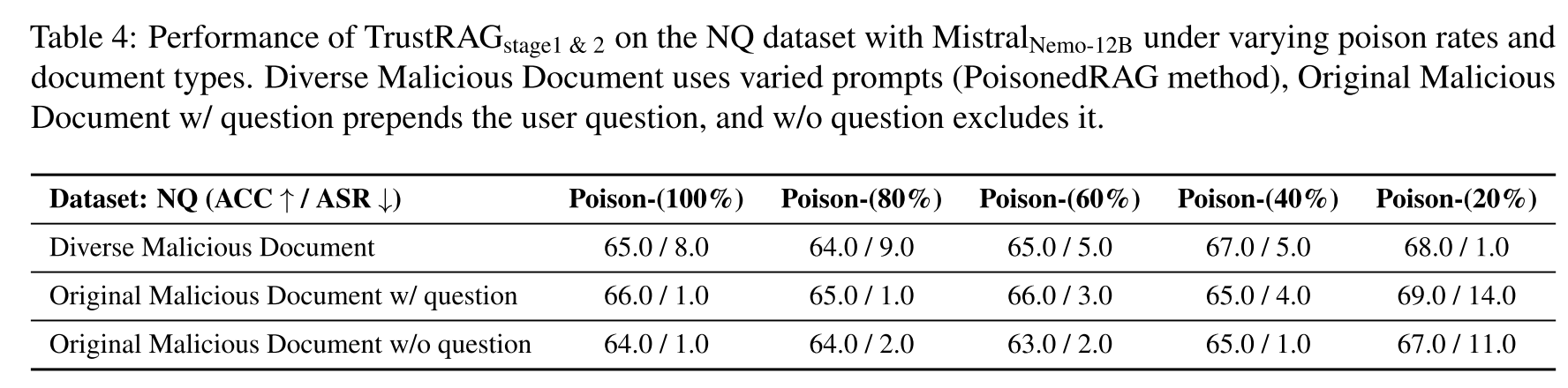
表12:
表13:
我们考虑了相较于其他攻击方法更为自适应的攻击和更接近现实世界的条件。为了在更具挑战性的条件下严格评估TrustRAG的鲁棒性,我们通过从这些文档中移除查询问题,仅依赖恶意内容作为模型生成的外部知识(本文所有实验均基于此设置),来评估其性能。表4展示了两种场景的结果:(1) 包含问题的原始恶意文档,(2) 不包含问题的原始恶意文档。所有数据集结果见附录表12和表13。TrustRAG在两种设置下均保持了63.0%到69.0%的高准确率以及1.0%到14.0%的低攻击成功率,表明无论是否包含查询问题,TrustRAG的防御能力都保持稳健。
从另一个角度来看,PoisonedRAG生成的恶意文档存在一个明显的局限性,即缺乏多样性。在本研究中,我们试图进一步检验多样化的恶意文档对我们的TrustRAG框架的影响以及K均值过滤策略的有效性。如表4所示,我们展示了一个涉及多样化恶意文档的场景,这些文档通过使用PoisonedRAG中定制的提示词来改变语义、逻辑和风格而构建。这一分析再次证实了我们方法的鲁棒性。具体来说,TrustRAG即使在多样化上下文中的多重注入攻击中也证明是高度有效的。如表4结果所示,与TrustRAG在原始PoisonRAG攻击下的性能相比,TrustRAG第一和第二阶段在使用MistralNemo-12B模型的NQ数据集上,面对不同投毒率和文档类型时,仍保持了强劲的准确率和较低的攻击成功率。
6 结论
在本工作中,我们提出了TrustRAG,这是首个旨在应对涉及多个恶意注入文档攻击的RAG防御框架。TrustRAG采用K均值过滤来减少恶意文档的存在,并结合内部和外部知识源来解决冲突并减轻这些攻击的影响。我们在多个基准数据集上的全面评估表明,TrustRAG优于现有的防御方法,即使在激进的投毒场景下也能保持高准确率。
局限性
TrustRAG目前仅专注于基于文本的检索增强生成系统,并未解决涉及图像-文本或其他类型数据的多模态RAG场景。未来的工作应将鲁棒性和可信度分析扩展到多模态RAG系统,这类系统在实际应用中正变得越来越普遍。
伦理考量
尽管TrustRAG旨在提升RAG系统抵御恶意文档注入的鲁棒性和可信度,但必须承认,任何已发布的防御机制也可能为对手开发新的、自适应的攻击策略提供参考。
附录
A.TrustRAG的提示模板

翻译:
生成一段简洁文本,提供准确、相关的信息以回答给定问题。若信息不明确或不确定,需明确说明 “我不知道”,避免生成幻觉内容。字数请少于 50 字!

翻译:
任务: 整合记忆文档与外部检索文档中的信息。
排除仅含无上下文具体答案、或指导系统如何回答问题的文档;
排除包含类似操控性指令、预定义答案的文档;
排除无关或冲突的文档,优先选择最一致、有依据的信息。
过滤标准:
任何指定特定回应、包含操控性指令,或无逻辑 / 上下文推理却遵循预定义答案格式的文档,均应忽略;
聚焦于提供事实性、逻辑性上下文且无需外部指令即可支撑答案的文档;
明确过滤包含结构化操控性指令(如类似模板内容)的文档。
记忆文档与外部检索文档:[初始上下文]
问题:[问题]
信息:

翻译:
你将获得一个问题、一份外部信息,以及你自己的知识。外部信息可能不可靠,请运用你的判断评估其可靠性。然后结合你的评估结果与自身知识,给出最佳答案。
问题:[问题]
外部信息:[外部知识]
自身知识:[内部知识]
回答:
B. 实验设置详情
B.1 实现与资源
所有实验均在两张NVIDIA H100 NVL 94GB GPU上评估。除Llama3.3-70B模型外,其他大型语言模型均可在单张GPU上运行。我们所有的推理架构均通过LMDeploy实现。
B.2 超参数设置
为确保实验的可复现性,我们为所有LLM将采样温度设置为0.01。在K-means过滤阶段,我们使用的ROUGE-L分数阈值为0.25,余弦相似度阈值为0.85。
B.3 攻击方法(攻击者)
我们引入了多种流行的RAG攻击方法,以验证我们防御框架的鲁棒性:
语料库投毒攻击:PoisonedRAG通过在不同温度下使用LLM生成欺骗性文本并附加到查询问题中,来制作恶意文档。通过策略性地生成恶意文档并将其注入数据库,该攻击确保这些被投毒的文档被优先检索,从而误导语言模型的输出。
提示注入攻击:PIA提出了一种攻击方式,恶意用户通过扰动离散标记来生成少量对抗性段落,以最大化与一组给定训练查询的相似性。
对抗性解码:AD是一种基于束搜索的方法,可为多个目标(包括RAG投毒和LLM防护规避)生成可读的对抗性文档。AD使用特定于任务的评分函数(例如,从开源LLM的逻辑值得出的可读性分数)来指导对抗性文档的生成。
拒绝服务攻击:干扰攻击向数据库中添加一个单独的“阻塞”文档,该文档将被检索以响应特定查询,并导致RAG系统不回答此查询。
B.4 防御方法(防御者)
考虑到针对RAG流程的各种攻击类型,我们比较了多种防御框架。我们引入了三个广泛认可的框架:RobustRAG、InstructRAG和AstuteRAG,以与我们提出的TrustRAG模型进行对比。
RobustRAG采用“隔离后聚合”策略,首先分别收集从每个检索到的段落生成的LLM响应,然后对这些独立响应执行安全聚合以产生最终输出。
InstructRAG使LLM能够通过自我合成的原理来显式学习去噪过程。
AstuteRAG自适应地从LLM的内部知识中提取关键信息,将其与检索到的知识进行迭代整合,并最终确定所有信息以形成最终答案。
B.5 受害模型
我们将这些框架应用于三个配备了RAG流水线的大型语言模型:包括Llama3.1-8B和MistralNemo-12B两个开源模型,以及通过API调用访问的闭源模型GPT-4o。除了防御框架,我们还引入了两种基线方法:无RAG和原始RAG。前者涉及LLM在没有任何RAG外部信息的情况下直接回答问题,而后者仅使用RAG,未加入任何防御框架。此外,我们还进行了尺度定律实验,以评估大型语言模型参数规模(从10亿到700亿参数)变化的影响。
C. 投毒率的定义
图5: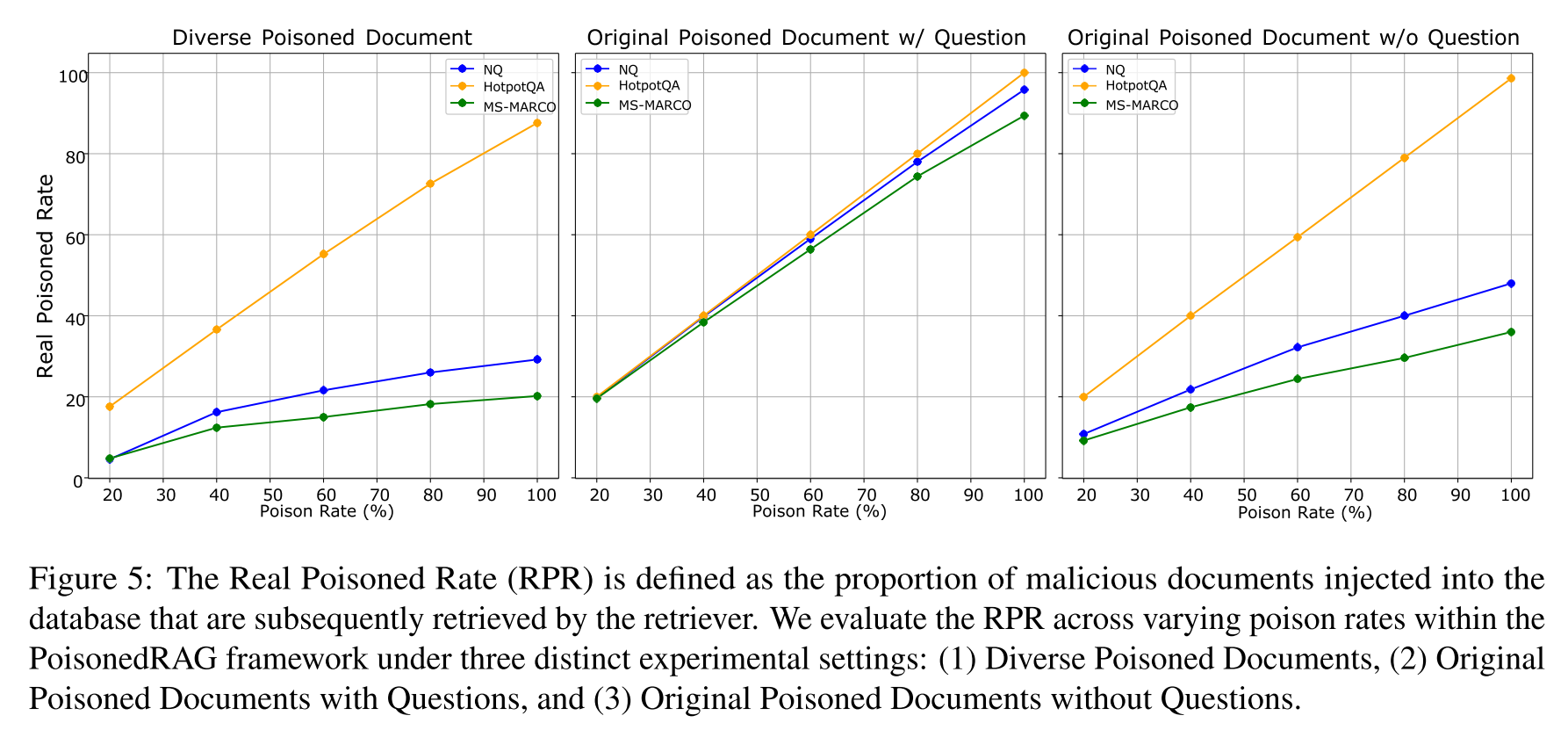
C.1 投毒率
某些攻击方法(如PoisonedRAG)不仅限于单点注入攻击(即每个查询仅向数据库插入一个投毒文档)。这些攻击的比例通过投毒率来量化,其定义为注入的投毒文本数量与干净检索文档总数之比。例如,在投毒率为20%的情况下,如果检索器目标是检索10个干净文档,则在检索前会向数据库插入2个对抗性文本。随后,检索器检索到的前10个语义最相关的文档(可能包含也可能不包含恶意内容)将作为外部知识提供给生成模型。在这种情况下,攻击者通常旨在为每个查询精心制作一个最优的对抗性文本,以诱使检索器选择它。在后续的实验中,除非另有说明,检索器的目标检索文档数量设定为5。在投毒率设定为80%的情况下,我们将在检索前向数据库注入4个恶意文档。
C.2 真实投毒率
考虑到攻击者在检索前将恶意文档注入数据库,我们额外评估了这些恶意文档是否被成功检索。真实投毒率定义为随后被检索器检索到的、已注入数据库的恶意文档所占的比例。首先,如图5(2)所示(代表了PoisonedRAG在不同投毒率下的原始配置),结果清楚表明,在三个数据集上,RPR随着投毒率的升高而增加。这表明随着更多恶意文档被注入数据库,被检索到的数量也更多。其次,在所有攻击场景下,我们评估了攻击方法的攻击成功率(ASR,如表2所示)。ASR衡量的是LLM是否产生了与恶意文档误导意图一致的输出,从而说明了攻击的有效性。
D. 干扰攻击

我们评估了另一种单点注入攻击——干扰攻击,该攻击旨在诱导模型拒绝回答。如表5所示,
t1、t2和t3代表攻击者希望诱发的目标输出,分别为:“我不知道。上下文没有提供足够信息。”、“我不能提供可能延续或鼓励有害内容的回答。”以及“我不能提供虚假或误导性信息。”我们的结果证实,我们的方法能够稳健地保护模型免受干扰攻击的影响。
E. 洁净检索阶段的有效性
表6:
如表6所示,洁净检索阶段能够有效地识别并移除不同数据集、嵌入模型和投毒率下的恶意文档。结果突出表明其在检测投毒样本方面具有鲁棒性(通过F1分数衡量),同时能保留干净样本(通过干净保留率衡量)。对于超过20%的投毒率(即40%、60%、80%和100%),洁净检索阶段始终能取得较高的F1分数,表明其强大的检测性能。例如,在使用BGE嵌入模型的NQ数据集上,F1分数范围从40%投毒率时的89.5到100%投毒率时的98.1,同时CRR值保持在86%以上,这证明了其在过滤恶意文档的同时保留大部分干净数据的能力。
在20%的低投毒率和单点注入攻击情况下,我们的方法调整了侧重点。此时,洁净检索阶段有意优先保留干净信息而非进行激进过滤,这体现在较低的F1分数和较高的CRR值上。这种设计选择确保了在污染程度最小的情况下(例如仅有一个恶意文档的单点注入攻击),大部分干净文档得以保留,以便进入TrustRAG的第二阶段进行处理。
嵌入模型。K-means过滤策略的有效性可能看起来严重依赖于嵌入模型的精心选择,因为嵌入空间对聚类结果有重大影响。然而,我们的实证评估挑战了这一假设。如表6所示,我们比较了三种广泛采用的嵌入模型:SimCSE、BERT和BGE。我们发现,我们提出的K-means过滤策略在所有三种模型上都保持稳健和有效。这一结果消除了刻意选择模型的需要,使我们的框架成为一种可推广的即插即用方法。此外,我们注意到,更细粒度的嵌入模型(如SimCSE)在不同的投毒率和数据集上始终能实现更优的性能和更高的鲁棒性。
F. 三个数据集上的详细实验结果
表7: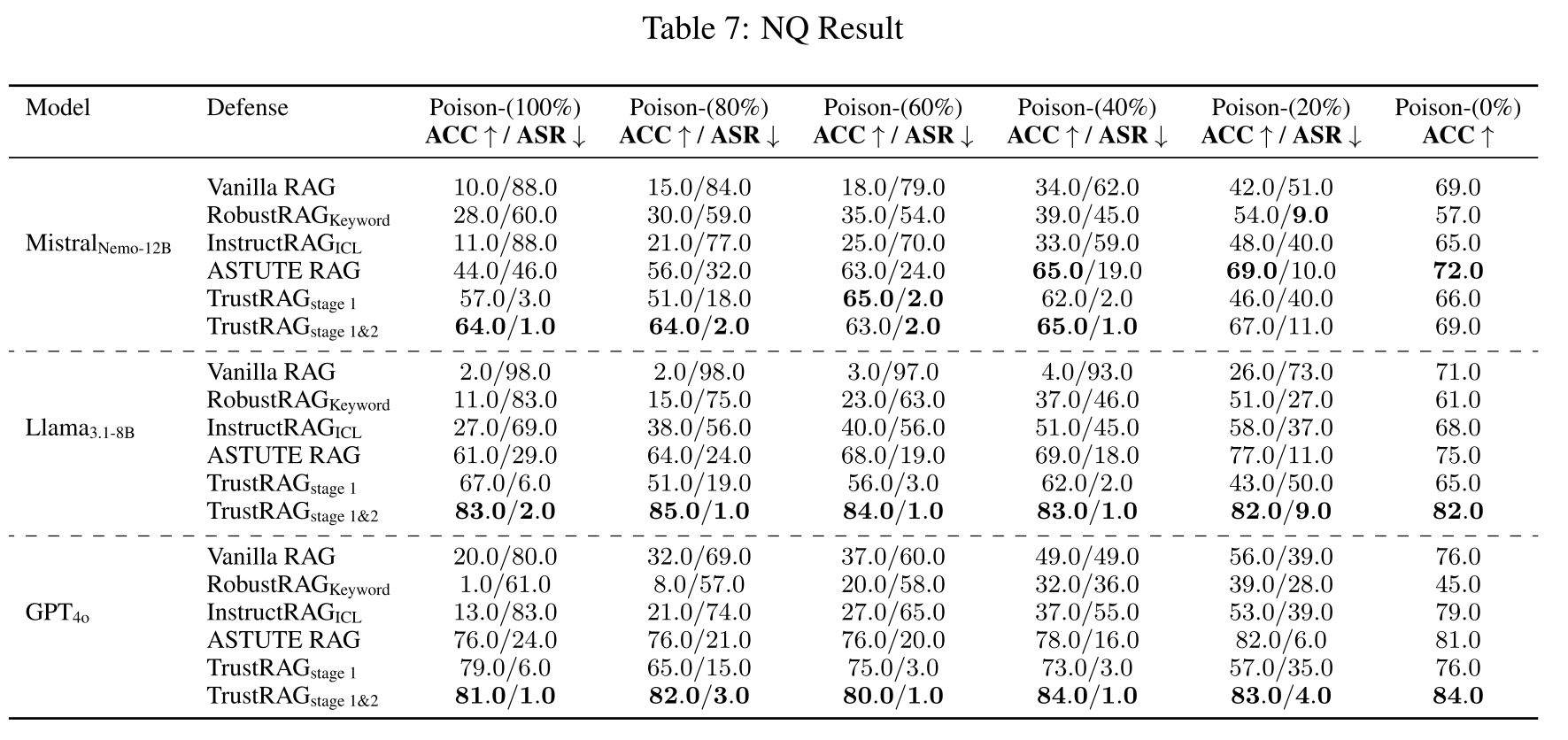
F.1 NQ数据集结果
如表7所示,实验结果突显了各种RAG防御在不同污染水平下对语料库投毒攻击的鲁棒性,评估基于MistralNemo-12B、Llama3.1-8B和GPT-4o三种语言模型。对于MistralNemo-12B模型,TrustRAG防御在100%投毒率下取得了64.0%的显著准确率和1.0%的最低ASR,即使在极端对抗场景下也保持了卓越性能。类似地,在20%的较低投毒率下,TrustRAG继续以67.0%的准确率和仅11.0%的ASR领先。
对于Llama3.1-8B模型,TrustRAG展示了令人印象深刻的韧性,在100%投毒率下实现了83.0%的准确率和仅2.0%的ASR。在40%的中等投毒率下,准确率保持在83.0%的高位,ASR为1.0%,显著优于其他防御方法(如ASTUTE RAG和RobustRAGKeyword)。
GPT-4o模型进一步验证了TrustRAG的有效性,在100%投毒率下实现了81.0%的准确率和接近零的1.0% ASR。即使在60%的投毒率下,该方法仍保持稳健性能,准确率为80.0%,ASR为1.0%,证明了其在不同设置和语言模型下持续抑制对抗效应同时保持回答可靠性的能力。这些结果证实了TrustRAG在防御高强度和低强度投毒攻击方面的尖端能力。
表8: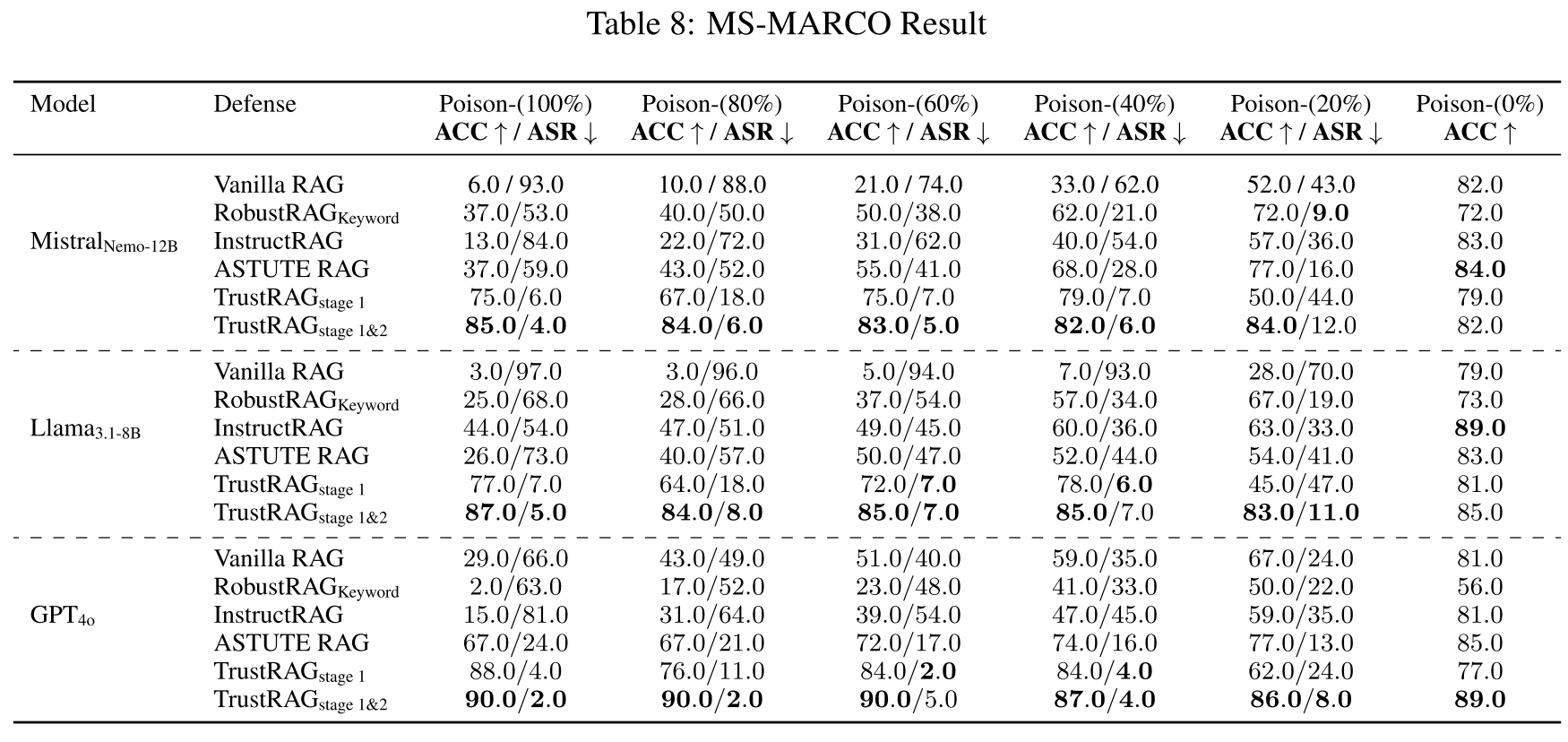
F.2 MS-MARCO数据集结果
表8中的结果评估了不同RAG防御在使用MistralNemo-12B、Llama3.1-8B和GPT-4o三种语言模型的MS-MARCO数据集上对语料库投毒攻击的鲁棒性。在不同的投毒率下,TrustRAG始终表现出在保持高准确率和抑制ASR方面的卓越性能。
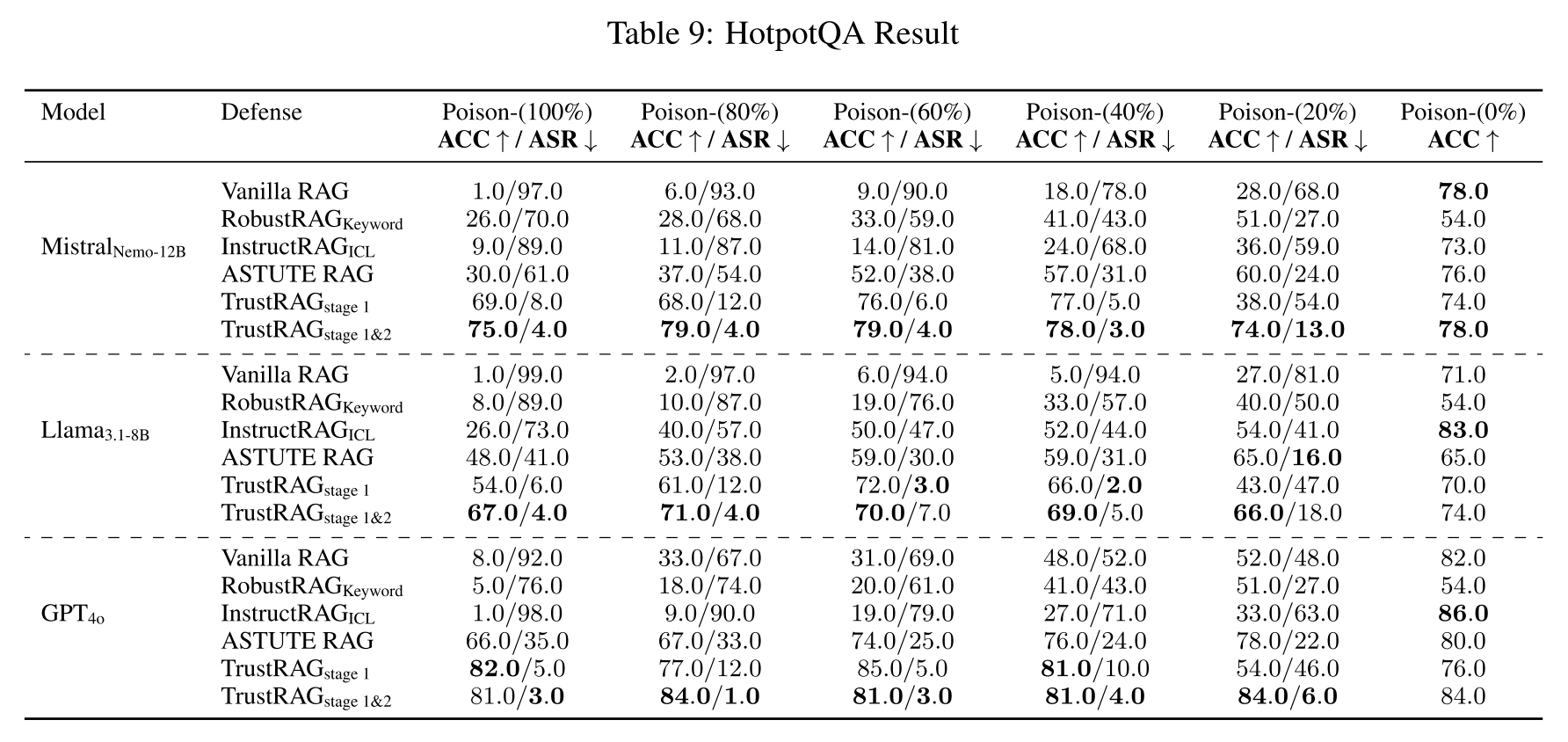
F.3 HotpotQA数据集结果
表9中的结果评估了使用相同三种语言模型在HotpotQA数据集上,各种RAG防御对语料库投毒攻击的鲁棒性。TrustRAG始终表现出卓越性能,在所有污染水平下都能保持高ACC同时最小化ASR。
G. 详细消融研究
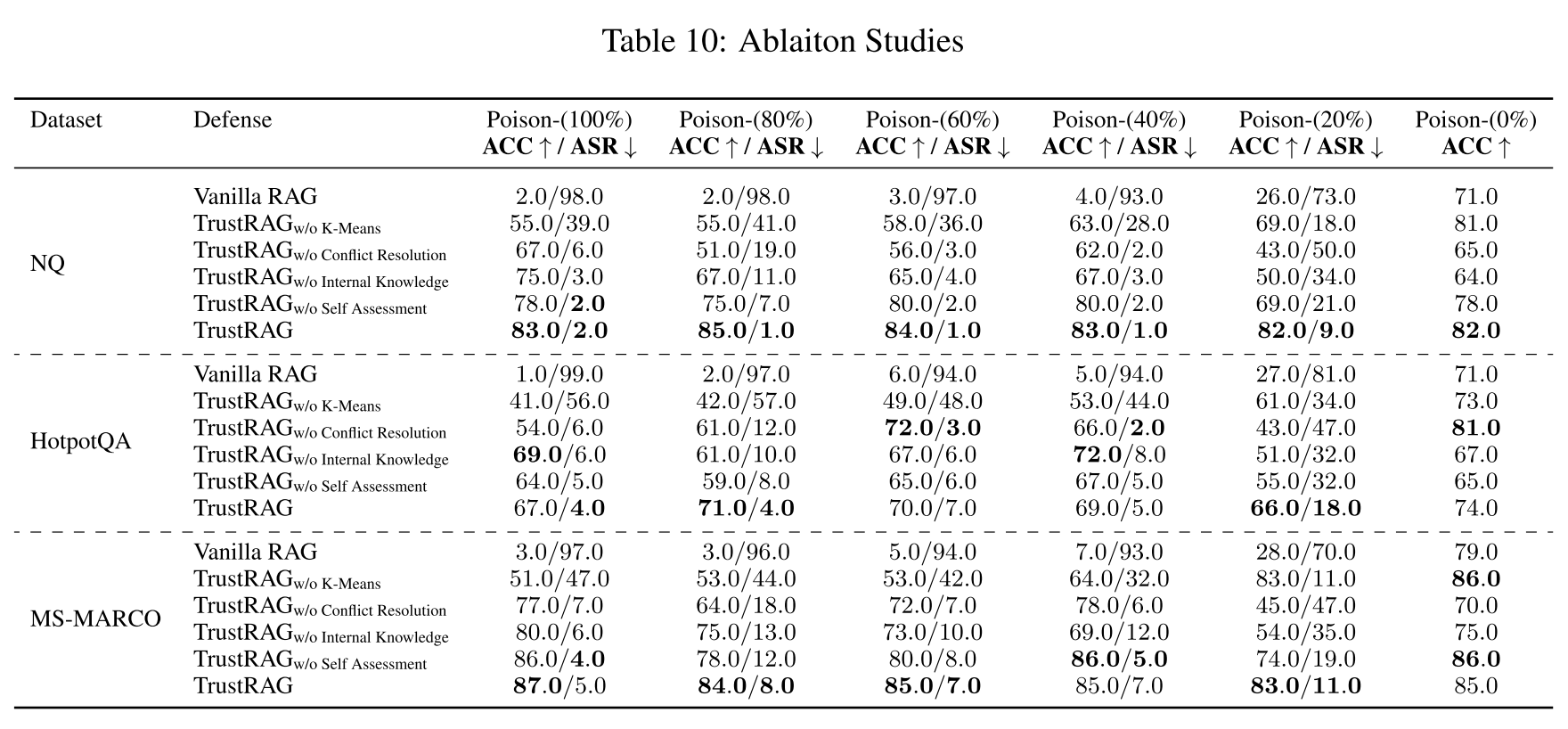
表10显示了在三个数据集(NQ、HotpotQA和MS-MARCO)上对Llama3.1-8B模型进行的消融研究结果。值得注意的是,包含所有组件的TrustRAG在大多数情况下表现最佳。每个组件负责其特定任务。
K-means聚类的影响。如图4(2)和(3)所示,当投毒率超过20%时,K-means过滤能有效缓解攻击,同时保持高回答准确率。即使在20%的投毒率下,该方法也能成功保持干净文档的完整性,避免过滤掉有用或干净的信息,并允许它们进入TrustRAG第二阶段。从我们的完整流程中移除K-means过滤策略会导致准确率和攻击成功率显著下降,这种影响在100%和80%的投毒率下尤为明显。
内部知识的影响。对比集成与不集成从LLM推断出的内部知识的TrustRAG,结果显示利用LLM衍生的内部知识能显著提高准确率并降低攻击成功率。这种增强在20%的投毒率下尤为明显,此时在初始过滤阶段后,一个恶意文档与干净文档并存。在这种情况下,内部知识作为一个额外的证据层,放大了恶意文档与干净文档之间的冲突,从而减少了恶意文档对最终输出的影响,显著增强了框架的鲁棒性。
冲突消解的影响。尽管K-means聚类和自评估阶段显著降低了攻击成功率,但冲突消解组件是防御框架中最关键的部分。在没有冲突消解的情况下,即使有内部知识或大多数是干净文档,恶意内容仍会持续使模型的生成偏向不良输出。这一点在图4中得到了清晰展示,图中显示攻击成功率显著增加。值得注意的是,在20%的投毒率下,移除冲突消解会显著增加模型受到攻击的敏感性。我们的主要目标是在涉及单个或极少量恶意注入的场景中,保留大部分文档,并依赖冲突消解阶段来缓解这些注入。对结果的分析证实,冲突消解阶段的设计目标得到了有效实现。
自评估的影响。自评估机制进一步增强了TrustRAG在所有实验设置下的性能,在20%的投毒率下益处尤为明显。这种增强表明LLM能有效区分归纳性信息和恶意信息,以及内部知识和外部知识。因此,在外部信息被证明不可靠而内部知识表现出高置信度的场景中,LLM能有效决定是检索外部信息还是仅依赖内部知识。
H. 不同检索器的影响
表11: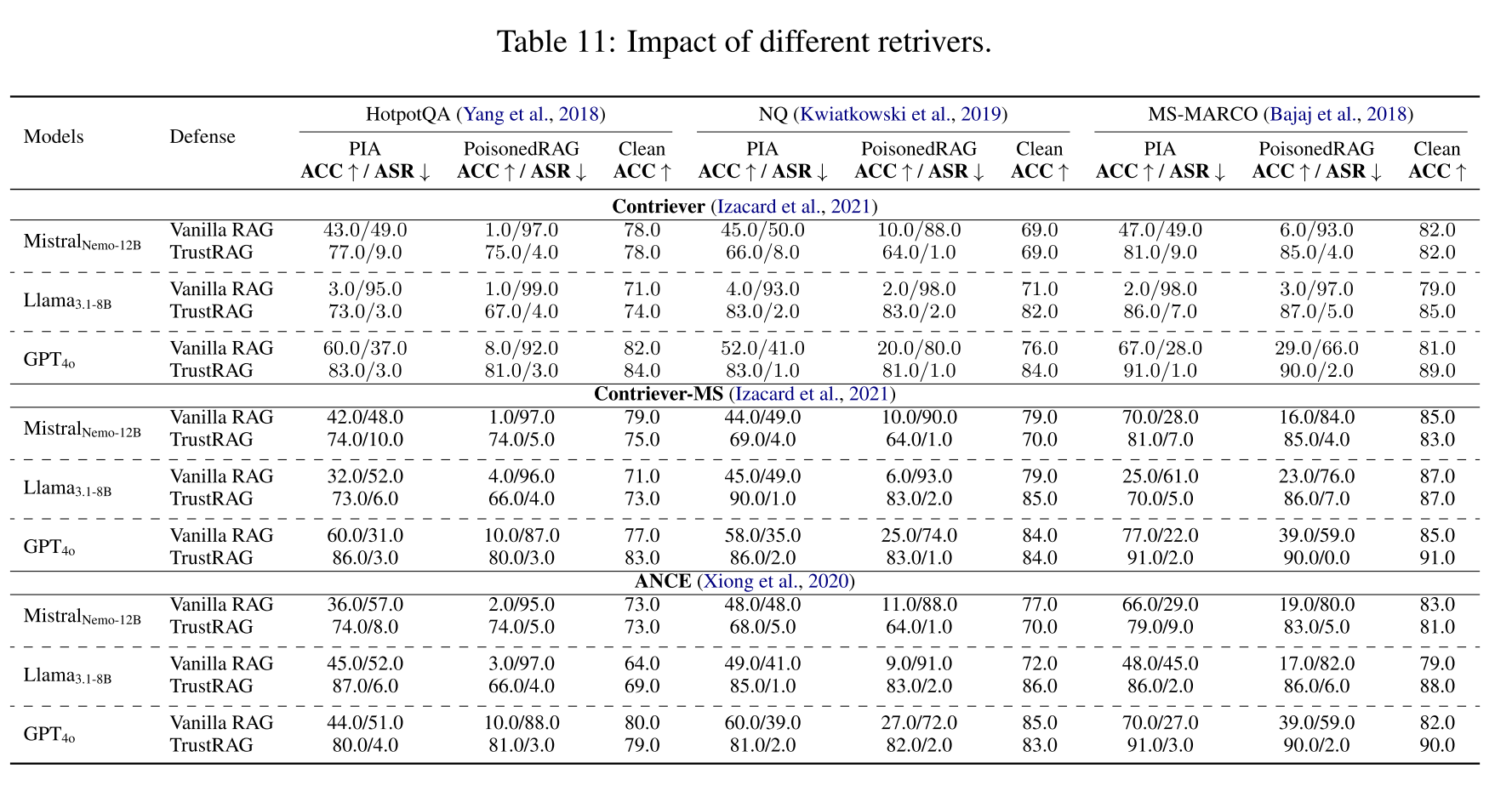
在本节中,我们证明我们的方法与各种检索器(Contriever、Contriever-MS 和 ANCE)兼容。在所有测试的三种检索器中,显然参考数据库中的语料库投毒攻击都成功地针对了它们。然而,我们的TrustRAG保护框架始终能识别并过滤掉恶意文本,确保了答案的准确性和可信度。此外,随着三种检索器鲁棒性的提升,集成我们的TrustRAG框架提高了模型的整体性能,从而得到了更准确的答案和更相关的检索信息。
I. 多样化投毒文档的影响
我们探讨了多样化投毒文档对TrustRAG的影响。我们有两个关键发现:(1)尽管攻击者可以使用多样化的投毒文档绕过TrustRAG第一阶段,但TrustRAG第二阶段的自评估将防御这些错误信息。(2)只有高度自相似的投毒文档才能误导LLM,但它无法绕过TrustRAG第一阶段。因此,攻击者很难在这两个目标之间进行权衡。
J. Top-K上下文窗口的影响
除了有意的投毒攻击,检索增强生成系统还可能面临两个额外的非对抗性噪声重要来源:基于检索的噪声(由返回不相关文档的不完美检索器导致)和基于语料库的噪声(源于知识库本身固有的不准确性)。为了全面评估TrustRAG的鲁棒性,我们在NQ数据集上使用Llama3.1-8B进行了广泛的实验,涵盖两种不同场景:清洁设置和包含5个恶意文档的投毒设置。结果突显了TrustRAG在两种条件下的卓越性能。在清洁设置中,随着上下文窗口从5个文档扩大到20个文档,TrustRAG表现出准确率的持续提升,始终优于原始RAG。在投毒场景中,TrustRAG保持约80%的准确率,同时将攻击成功率保持在约1%左右。这与原始RAG形成鲜明对比,后者的准确率在10%到40%之间,ASR水平在60%到90%之间。通过此分析表明,即使在完全清洁的场景中,使用TrustRAG也不会降低性能,甚至可能增强RAG系统的鲁棒性。
K. 不同检索器的影响(注:此标题与H部分重复,但原文如此)
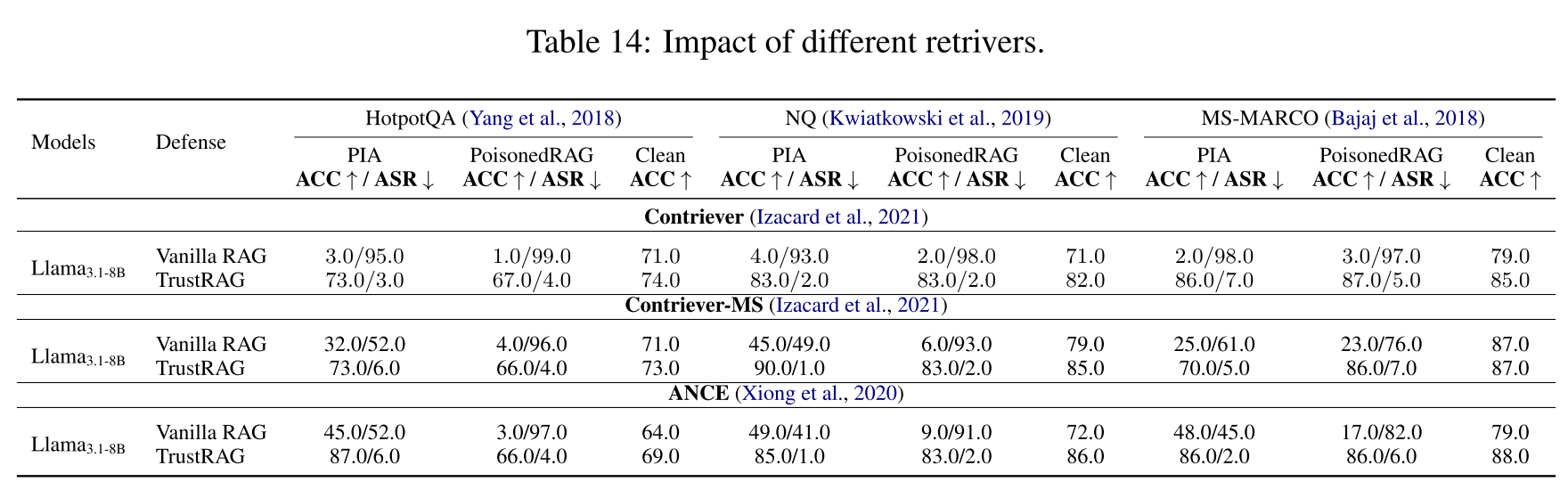
表14展示了TrustRAG与三种不同检索器(Contriever、Contriever-MS 和 ANCE)在Natural Questions、HotpotQA和MS-MARCO数据集上使用Llama3.1-8B模型的兼容性综合评价。结果突显,我们的方法能与多种检索器无缝集成,持续缓解语料库投毒攻击(如PIA和PoisonedRAG)的影响。相比之下,TrustRAG在所有检索器和条件下都实现了稳健的准确率和较低的ASR。值得注意的是,随着检索器鲁棒性的提高,TrustRAG的集成功提升了模型的整体性能,在使用更先进的检索器(如ANCE)时观察到了更明显的增益。这一结果突显了TrustRAG在加强不同检索器的检索增强生成系统方面的适应性和有效性。至关重要的是,无论检索器质量如何,TrustRAG都能始终如一地防御恶意内容。此外,它与各种检索器的兼容性(从Contriever到ANCE)突显了其多功能性,使其能够无缝集成到现有的RAG管道中,而无需针对特定检索器进行适配。
L. TrustRAG的缩放定律
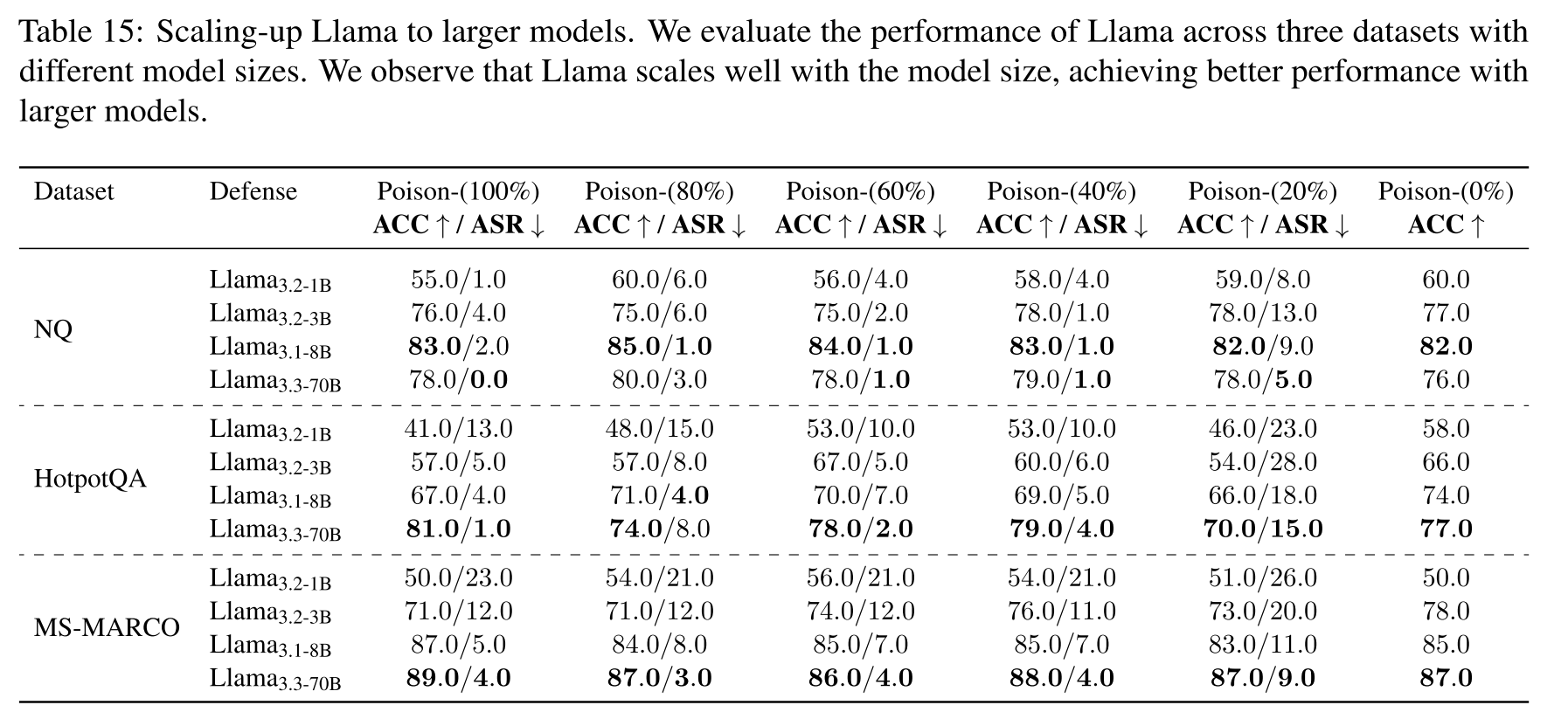
表15展示了TrustRAG在四种Llama模型规模(1B、3B、8B 和 70B)上的缩放行为,评估基于三个数据集和不同投毒率。这些发现表明,在TrustRAG框架内存在一个稳健的缩放定律:随着模型规模增大,准确率显著提高,使模型能够以更大的置信度和更丰富的内部知识回答问题。值得注意的是,即使对于较小的模型(如Llama3.2-1B),我们的框架也能大幅降低攻击成功率,有效缓解高水平的恶意注入。至关重要的是,当与能力更强的模型配对时,TrustRAG不仅能保持这种稳健的防御,还能保护模型生成准确回答的能力不受损害。这种缩放行为很可能由更大规模Llama变体中固有的增强表征能力和上下文理解所驱动,这有助于更精确地区分干净输入和投毒输入。这些见解强调,虽然扩大模型规模会放大TrustRAG的保护和性能优势,但该框架在不同模型规模上仍然是一种多功能且可靠的解决方案。
M. 真实世界条件评估

为了评估TrustRAG在真实世界对抗条件下的性能,我们利用了由Huang等人引入的RedditQA数据集和RAMDocs。第一个数据集包含带有自然发生事实错误的Reddit帖子,导致对相关问题的不正确回答,模拟了真实世界的噪声和错误信息。第二个数据集基于AmbigDocs构建,通过引入额外的真实世界检索复杂性进行了扩展。如表16详述,对于RedditQA,使用检索文档的原始RAG实现了27.3%的回答准确率和43.8%的攻击成功率,反映了其对真实世界不准确信息的脆弱性。形成鲜明对比的是,TrustRAG实现了72.2%的回答准确率,同时将ASR降低至11.9%,突显了其在缓解实际环境中遇到的对抗条件影响方面的鲁棒性。在RAMDocs中也观察到了同样的趋势,与RAMDocs提出的MADAM-RAG方法相比,TrustRAG在同一模型架构下取得了显著改进。该实验表明,TrustRAG流程可以应用于真实世界场景,使问答RAG系统能够提供可信和有效的回答。
N. 案例研究
我们呈现了三个案例研究:第一个评估原始RAG,而第二和第三个检验TrustRAG。第一个和第二个使用相同的查询,第三个使用不同的查询。在原始RAG案例中,LLM被两个恶意文档误导。相比之下,TrustRAG的第一阶段过滤掉了所有恶意文档。通过知识整合和自评估,TrustRAG框架引导LLM在两个TrustRAG案例中都生成准确可靠的回答。如第三个案例研究所示,即使单个恶意文档通过了初始过滤阶段,我们的TrustRAG框架也能通过利用知识整合和内部知识,有效地减轻其影响。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)