RAG知识库
构建文档分割器对象的时候可指定两个参数,500指的是每个文本片段最多的字符,50指的是两个文本片段最多相同字符数(给拆分后的文本片段"搭桥",让模型不会因为拆分而丢失跨片段的语义)的核心方案,其核心是将 “大模型生成” 与 “知识库检索” 结合,让模型回答基于真实、最新的知识库内容。默认的功能不是很强大,检索的时候可能没那么精准,所以可以替换更强大的向量模型。1.两个向量的余弦相似度越高,说明向量
·
RAG知识库
原理
RAG(Retrieval-Augmented Generation,检索增强生成)是解决大模型 “知识过期”“事实性错误”
的核心方案,其核心是将 “大模型生成” 与 “知识库检索” 结合,让模型回答基于真实、最新的知识库内容。
有知识库之后大模型的调用流程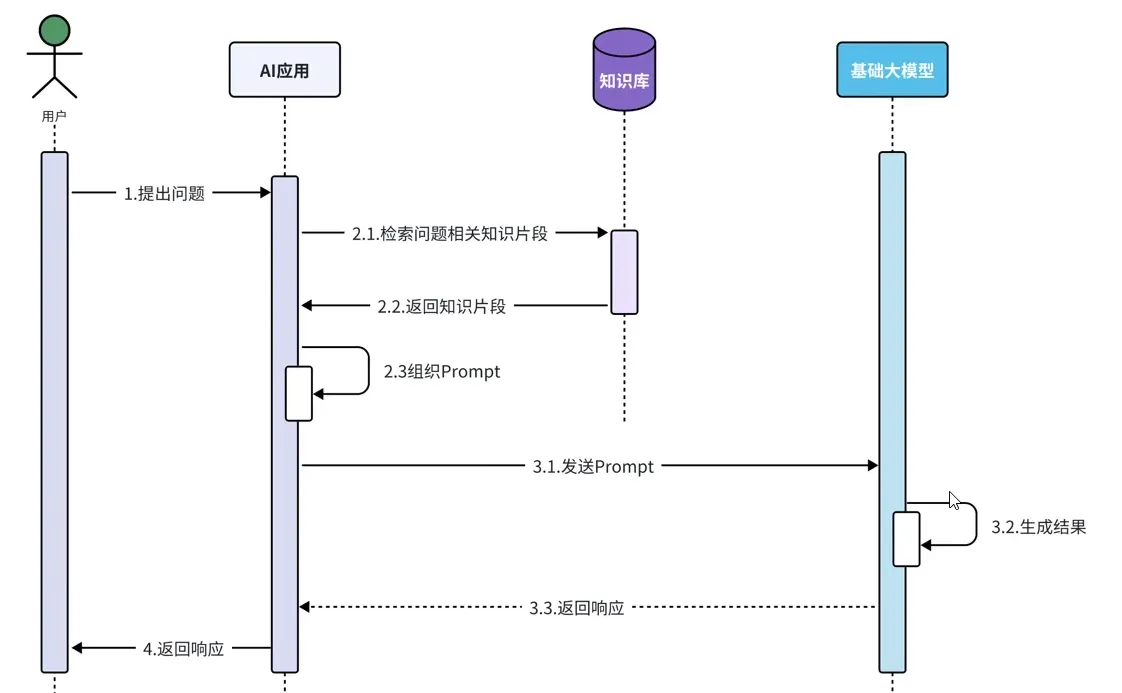
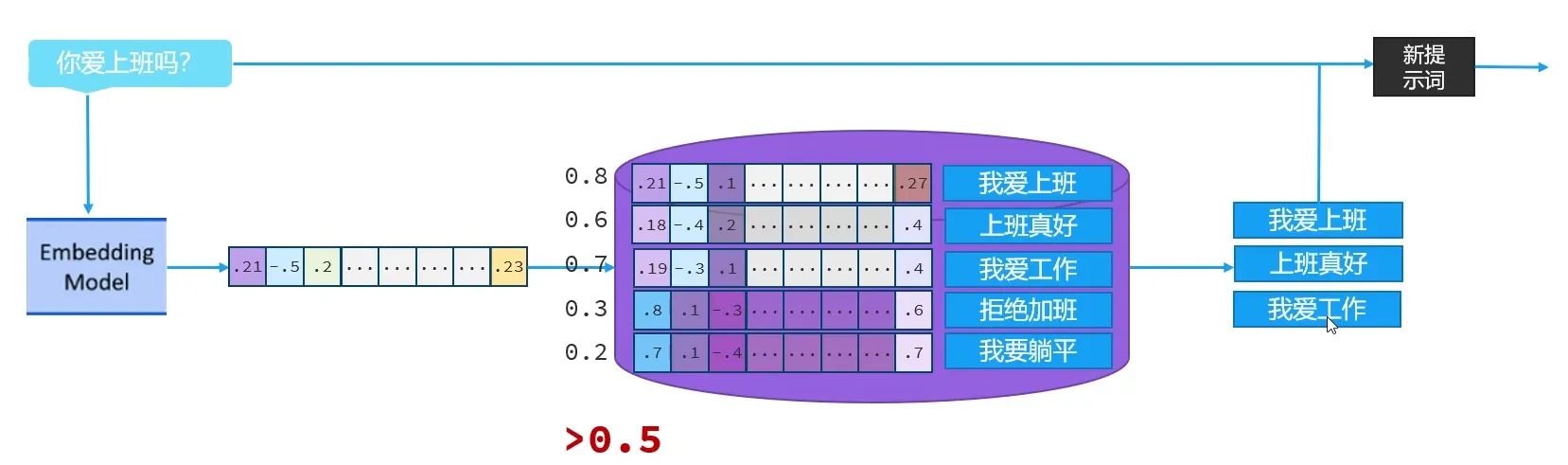
1.两个向量的余弦相似度越高,说明向量对应的文本相似度越高
2.向量数据库使用流程
- 借助于向量模型,把文档知识数据向量化后存储到向量数据库
- 用户输入的内容,借助于向量模型转化为向量后,与数据库中的向量通过计算余弦相似度的方式,找出相似度比较高的文本片段
快速入门
<!--rag-easy依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.2.0-beta8</version>
</dependency>
> //构建向量数据库操作对象 @Bean public EmbeddingStore
> store(){//依赖中有个embeddingStore对象,名字不能重复,所以设置成store
> // 加载文档进内存
> List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
> // 构建向量数据库操作对象
> InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
> // 构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化,存储
> EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
> .embeddingStore(store)
> .build();
> ingestor.ingest(documents);
> return store; } //构建向量数据库检索对象 @Bean public ContentRetriever contentRetriever(EmbeddingStore store){ return
> EmbeddingStoreContentRetriever.builder()
> .embeddingStore(store)
> .minScore(0.5)
> .maxResults(3)
> .build(); }
核心API
LangChain4j 将 RAG 流程拆解为 “文档加载→解析→分割→向量化→存储→检索” 六大环节,每个环节提供可插拔的 API: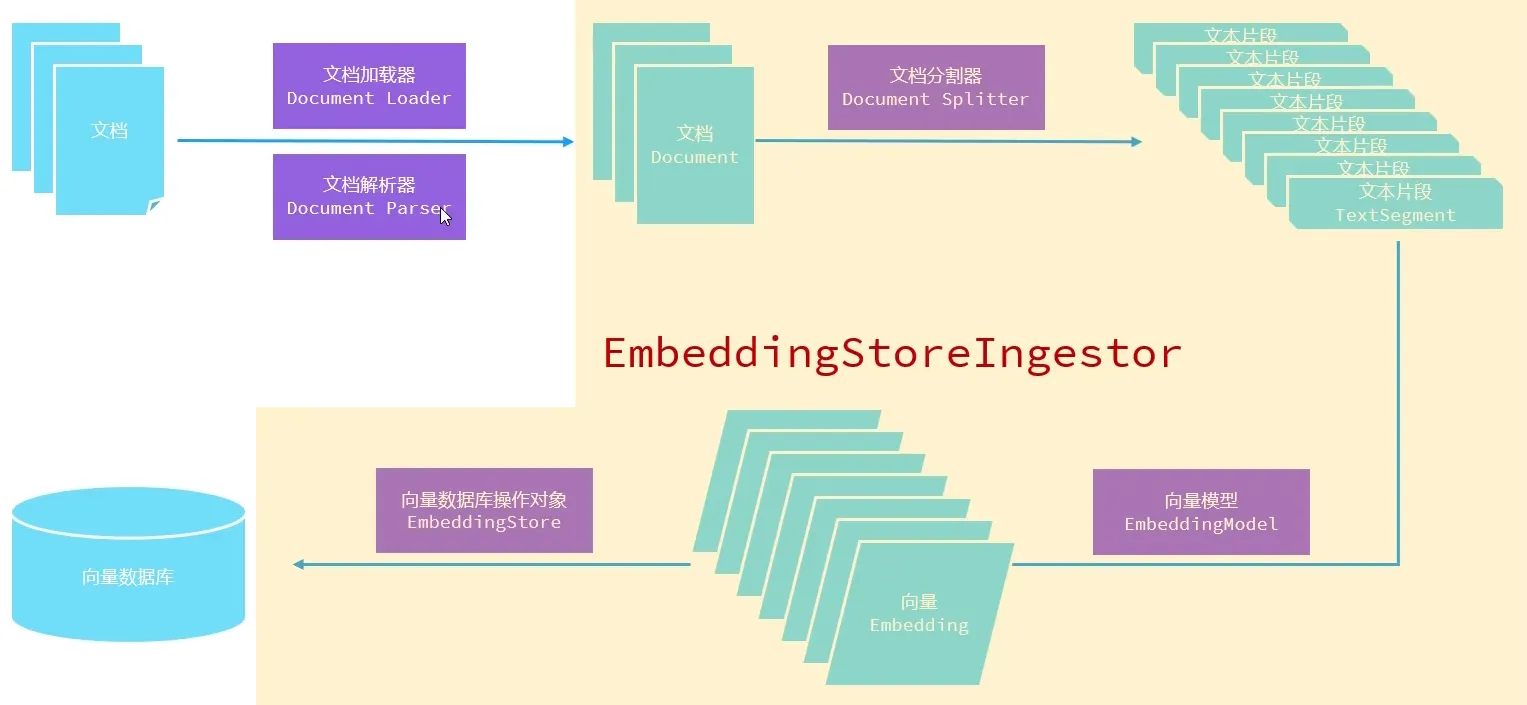
文档加载器:用于把磁盘或者网络中的数据加载进程序
| 加载器类名 | 适用场景 |
|---|---|
| FileSystemDocumentLoader | 根据本地磁盘绝对路径加载 |
| ClassPathDocumentLoader | 相对于类路径加载 |
| UrlDocumentLoader | 根据url路径加载 |
文档解析器:用于解析使用文档加载器加载进内存的内容,把非纯文本数据转化成纯文本
| 解析器类名 | 适用格式 | 依赖要求 |
|---|---|---|
| TextDocumentParser | 纯文本(.txt/.md 等) | 无需额外依赖 |
| ApachePdfBoxDocumentParser | PDF 文件 | 需引入 pdfbox 解析依赖 |
| ApachePoiDocumentParser | Word/Excel/PPT(.doc/.xls/.ppt) | 需引入 poi 依赖 |
| ApacheTikaDocumentParser | 几乎所有格式(默认) | 内置依赖,兼容性强但性能略低 |
若想解析pdf文档则需要
<!--pdf解析器依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.2.0-beta8</version>
</dependency>
@Bean
public EmbeddingStore store(){
// 加载文档进内存时指定文档解析器
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content", new ApachePdfBoxDocumentParser());
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}
文档分割器:用于把一个大的文档,切割成一个一个的小片段
| 分割器类名 | 分割规则 | 适用场景 |
|---|---|---|
| DocumentByParagraphSplitter | 按段落分割 结构化文本 | (如文章、文档) |
| DocumentByLineSplitter | 按行分割 | 日志、配置文件等行式文本 |
| DocumentBySentenceSplitter | 按句子分割 | 对话、新闻等短文本 |
| DocumentByWordSplitter | 按词分割 | 小语种、短文本 |
| DocumentByCharacterSplitter | 按固定字符数分割 | 无结构长文本 |
| DocumentByRegexSplitter | 按正则表达式分割 | 自定义分割规则(如按 ### 分割) |
| DocumentSplitters.recursive() | 递归分割(默认) | 通用场景,优先段落→行→句子→词 |
构建文档分割器对象的时候可指定两个参数,500指的是每个文本片段最多的字符,50指的是两个文本片段最多相同字符数(给拆分后的文本片段"搭桥",让模型不会因为拆分而丢失跨片段的语义)

@Bean
public EmbeddingStore store(){
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content", new ApachePdfBoxDocumentParser());
// 构建文档分割器对象
DocumentSplitter ds = new DocumentByParagraphSplitter(500, 50);
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
// 指定文档分割器
.documentSplitter(ds)
.build();
ingestor.ingest(documents);
return store;
}
向量模型:用于把文档分割后的片段向量化或者查询时把用户输入的内容向量化
默认的功能不是很强大,检索的时候可能没那么精准,所以可以替换更强大的向量模型
langchain4j:
embedding-model:
api-key: ${API-KEY:sk-576746ec85384deea25770688e439042}
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
model-name: text-embedding-v4
@Autowired
private EmbeddingModel embeddingModel;
//构建向量数据库操作对象
@Bean
public EmbeddingStore store(){
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content", new ApachePdfBoxDocumentParser());
DocumentSplitter ds = new DocumentByParagraphSplitter(500, 50);
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(ds)
// 指定向量模型
.embeddingModel(embeddingModel)
.build();
ingestor.ingest(documents);
return store;
}
//构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
// 指定向量模型
.embeddingModel(embeddingModel)
.minScore(0.5)
.maxResults(3)
.build();
}

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)