BOND: Aligning LLMs with Best-of-N Distillation翻译
基于人类反馈的强化学习 (RLHF) 是推动 SOTA 大语言模型质量和安全的关键因素。然而,一个出人意料地简单且强大的推理时策略是 Best-of-N 采样,它可以从 $N$ 个候选样本中选出最佳生成结果。本文提出了 Best-of-N 蒸馏 (BOND),这是一种新的 RLHF 算法,旨在模拟 Best-of-N,但在推理时不会产生显著的计算开销。具体而言,BOND 是一种分布匹配算法,它**
摘要
基于人类反馈的强化学习 (RLHF) 是推动 SOTA 大语言模型质量和安全的关键因素。然而,一个出人意料地简单且强大的推理时策略是 Best-of-N 采样,它可以从 NNN 个候选样本中选出最佳生成结果。本文提出了 Best-of-N 蒸馏 (BOND),这是一种新的 RLHF 算法,旨在模拟 Best-of-N,但在推理时不会产生显著的计算开销。具体而言,BOND 是一种分布匹配算法,它强制策略中的生成分布更接近 Best-of-N 分布。我们使用 Jeffreys 散度(前向和后向 KL 的线性组合)来平衡模式覆盖和模式搜索行为,并推导出一个利用移动锚点来提高效率的迭代公式。我们通过在抽象概括和 Gemma 模型上的实验,证明了我们方法和几种设计方案的有效性。将 Gemma 策略与 BOND 相结合,可以提高多个基准测试的结果,优于其他 RLHF 算法。
1.介绍
SOTA 大语言模型 (LLM),例如 Gemini 和 GPT-4,通常分三个阶段进行训练。首先,使用下一个 token 预测 (next-token predictive) 在大型知识库上对 LLM 进行预训练。其次,通过有监督微调 (SFT) 对预训练模型进行微调以遵循指令。最后,使用基于人类反馈的强化学习 (RLHF) 进一步提高生成质量。RLHF 步骤通常包括学习基于人类偏好的奖赏模型 (RM),然后使用强化学习算法优化 LLM 以最大化预测奖赏。
RLHF algorithms and their challenges。 使用强化学习 (RL) 对 LLM 进行微调颇具挑战性,尤其因为它可能导致预训练的知识被遗忘,并且 RM 中的漏洞可能导致奖赏黑客攻击。标准策略是使用策略梯度方法,并针对 SFT 策略进行 KL 正则化。这些 RL 算法寻求在低 KL 下获得高奖赏的帕累托最优策略,以保留原始模型的通用能力并解决错位问题。
Best-of-N sampling。在实践中,一种非常简单的推理时扩展方法常被用来提升生成质量:Best-of-N 采样。该方法包括从参考模型(通常是有监督微调模型)中抽取 NNN 个候选生成,并根据 RM 选择奖赏最高的生成。该策略经验上实现了极佳的奖赏-知识库平衡,但计算成本增加了 NNN 倍。
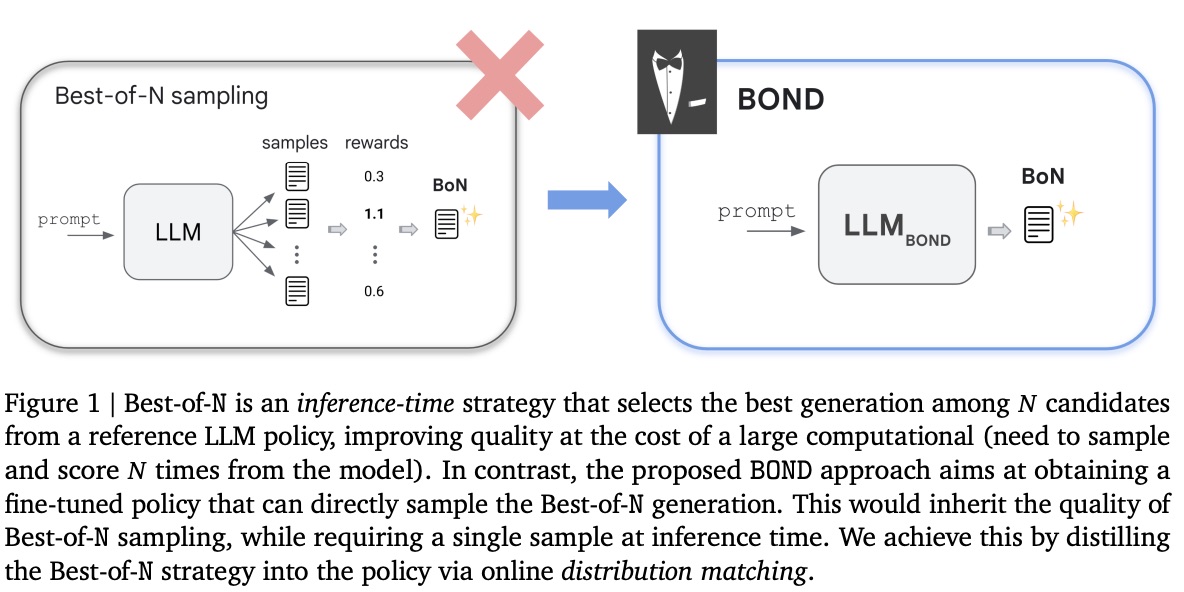
BOND。在本文中,我们提出了 BOND(Best-of-N Distillation),这是一种新的 RLHF 算法,它学习的策略可以实现 Best-of-N 采样的强大性能,但至关重要的是,它在推理时只需要一个样本,如图 1 所示。我们的关键思想是将策略的对齐视为分布匹配问题,我们会对策略进行微调以模拟 Best-of-N 分布。为此,我们首先推导出 Best-of-N 分布的解析表达式。这使我们能够考虑和优化不同的散度指标。我们首先展示如何使用来自 Best-of-N 策略的样本来最小化前向 KL 散度,从而得到具有模式覆盖行为的标准模仿学习设置。我们还展示了如何最小化后向 KL,从而得到一种基于分位数的新型优势,它不依赖于奖赏尺度,并且对应于模式搜索行为。然后,我们提出最小化前向和后向 KL 的线性组合(也称为 Jeffreys 散度),这种方法保留了两种方法的优点。此外,为了在保持较低样本复杂度的同时优化性能,我们提出了一种迭代 BOND 方法,该方法通过迭代提取移动锚点策略的 Best-of-N 值。最后,基于上述思路,我们提出了 J-BOND(J 代表 Jeffreys),这是一种新颖、稳定、高效且实用的 RLHF 算法,用于对齐 LLM。
Experiments。我们首先在摘要任务 XSum 上展示 BOND 及其设计方案的有效性。然后,在第 6 节中,我们应用 J-BOND 来调整 Gemma 策略。J-BOND 不仅比标准强化学习算法提升了 KL 奖励帕累托前沿,而且在学术基准测试以及与 Mixtral 等开源变体的并行比较中也提升了性能。
2.Problem Setup
我们考虑基于 Transformer 架构的 LLM,通过从提示 xxx 自回归生成 token 序列 yyy 来定义策略 π(x,⋅)\pi(x, ·)π(x,⋅)。给定一个预训练且通常经过有监督微调的参考策略 πref\pi_{ref}πref,我们力求使其进一步与人类偏好保持一致。为了实现这一点,在本文的其余部分,我们假设可以使用一个奖赏模型 (RM),我们将其表示为 r(⋅)r(·)r(⋅),该模型经过训练以反映人类偏好。
Standard RLHF。大多数 RL 算法优化期望奖赏与当前策略和参考策略之间的 KL 散度的线性组合:
πRL=argmaxπEπ[r(y)]−βRL⋅KL(π∣∣πref),(1)\pi_{RL}=argmax_{\pi}\mathbb E_{\pi}[r(y)]-\beta_{RL}\cdot KL(\pi||\pi_{ref}),\tag{1}πRL=argmaxπEπ[r(y)]−βRL⋅KL(π∣∣πref),(1)
正则化强度 βRL≥0\beta_{RL}≥0βRL≥0。此 KL 正则化强制策略保持接近其初始策略 πref\pi_{ref}πref,从而减少遗忘和奖赏黑客攻击。公式(1)通常使用在线算法进行优化,因为它们的性能优于离线算法。此外,一些简单的方法已证明效果最佳,例如,使用采样基线来减少方差的 REINFORCE 算法优于PPO算法。
Best-of-N。一种互补的对齐策略是 Best-of-N,这是一种推理时扩展策略,涉及从 πref\pi_{ref}πref 中多次采样,并根据 RM rrr 选择奖赏最高的生成结果。与 RLHF 策略相比,Best-of-N 不会微调 LLM 的权重,而是修改推理过程。经验证明,Best-of-N 在考虑奖赏/KL 权衡时是高效的,并且在帕累托最优方面具有理论保证。遗憾的是,Best-of-N 的推理成本显著较高,并且随 NNN 线性增加,因为生成 NNN 个结果的成本(通常)是采样单个的 NNN 倍。
基于上述考虑,我们提出了一种新的对齐方法,称为 BOND(Best-of-N Distillation)。BOND 的目标是将最佳样本策略蒸馏到策略 πref\pi_{ref}πref 中。这使得该策略能够达到最佳样本采样的强大性能,同时在推理时仅需一个样本。我们将在下一节概述我们的总体方法。
3.The BOND Approach
我们将 BOND 方法的公式化分为两个主要步骤。首先,我们推导出 Best-of-N 分布的解析表达式(第 3.1 节)。其次,利用推导出的表达式,我们将问题表述为分布匹配问题(第 3.2 节),即我们希望使策略 π\piπ 更接近 Best-of-N 分布。在第 3.3 节中,我们深入分析了 BOND 与标准 RLHF 之间的联系。
3.1 The Best-of-N distribution
在本节中,我们将推导 Best-of-N 采样的精确解析分布,并研究其性质。为简单起见,在不失一般性的前提下,我们从所有符号中删除上下文 xxx,并假设奖励 r(y)r(y)r(y) 在所有生成 yyy 上都满足严格排序(如果有两个或多个生成结果 yyy 的奖励 r(y)r(y)r(y) 一样大(出现并列),为了满足“奖励对所有生成严格排序”的假设,可以用任意方式把它们强行排个先后(建立一个严格的、没有相等项的次序)。怎么排都行,只要保证没有平手即可;这样做不会影响后面给出的概率公式与推导)。我们可以肯定以下主要定理(证明见附录 A.1)。
Theorem 1。对于任何生成 yyy,令:
p<(y)=Py′∼πref[r(y′)<r(y)](2)p_<(y)=\mathbb P_{y'\sim\pi_{ref}}[r(y')<r(y)]\tag{2}p<(y)=Py′∼πref[r(y′)<r(y)](2)
表示从 πref\pi_{ref}πref 随机生成的 y′y'y′ 严格差于 yyy 的概率,并令:
p≤(y)=Py′∼πref[r(y′)≤r(y)],(3)p_{\le}(y)=\mathbb P_{y'\sim\pi_{ref}}[r(y')\le r(y)],\tag{3}p≤(y)=Py′∼πref[r(y′)≤r(y)],(3)
表示 y′y'y′ 不优于 yyy 的概率(因此包括相等的情况)。然后,yyy 是 Best-of-N 采样输出的概率为:
πBoN(y)=πref×p≤(y)N−1⏟(A)×∑i=1N[p<(y)p≤(y)]i−1⏟(B).(4)\pi_{BoN}(y)=\pi_{ref}\times \underbrace{p_{\le}(y)^{N-1}}_{(A)}\times\underbrace{\sum^{N}_{i=1}[\frac{p_<(y)}{p_{\le}(y)}]^{i-1}}_{(B)}.\tag{4}πBoN(y)=πref×(A)
p≤(y)N−1×(B)
i=1∑N[p≤(y)p<(y)]i−1.(4)
Interpretation。定理 1 对 Best-of-N 采样的行为提供了直观的解释:它本质上是通过乘法项 (A) 和 (B) 对原始采样分布 πref\pi_{ref}πref 进行重新加权。
项 (A) 对应于 NNN 中的惩罚指数,该指数基于(针对同一提示)比所考虑的 yyy 更差或相等的生成比例。直观地讲,这确保了随着 NNN 的增加,我们从不良生成中采样的样本量呈指数级减少。
项 (B) 是一个额外的校正因子,用于计算生成崩塌的可能性。重要的是,它最多与 NNN 呈线性关系,因为它始终在 [1,N][1, N][1,N] 范围内:
1≤1+∑i=2N[p<(y)p≤(y)]i−1=∑i=1N[p<(y)p≤(y)]i−1≤∑i=1N1≤N(5)1\le 1+\sum^N_{i=2}[\frac{p_<(y)}{p_{\le}(y)}]^{i-1}=\sum^N_{i=1}[\frac{p_{<}(y)}{p_{\le}(y)}]^{i-1}\le\sum^N_{i=1}1\le N\tag{5}1≤1+i=2∑N[p≤(y)p<(y)]i−1=i=1∑N[p≤(y)p<(y)]i−1≤i=1∑N1≤N(5)
对于最差生成 y−y_-y−,它达到最小值 1,因为根据定义,p<(y−)=0p_<(y_−) = 0p<(y−)=0。这并不奇怪,因为我们需要连续对 y−y_−y− 进行恰好 NNN 次采样,这对应于 πBoN(y−)=πref(y−)N\pi_{BoN}(y_-) = \pi_{ref}(y_−)^NπBoN(y−)=πref(y−)N(注意,𝑝≤(y−)=πref(y−)𝑝_{\le}(y_−) = \pi_{ref}(y_−)p≤(y−)=πref(y−))。相反,如果各个生成 yyy 的可能性较低且这些生成是好的,则 p<(y)p_<(y)p<(y) 几乎与 p≤(y)p_≤ (y)p≤(y) 相等,且项 (b) 接近 NNN。直观地讲,这对应于“同一个生成 yyy 被抽到多次的情况几乎不会发生”。在极端情况下,当 πref\pi_{ref}πref 为连续分布时,项 (B) 为常数且等于 NNN(参见附录 A.2)。
3.2 The BOND objective
对 Best-of-N 分布的解析刻画使我们可以把 BOND 表述为一个分布匹配问题。也就是说,我们要解如下目标:
πBoND=argminπ∈ΠD(π ∥ πBoN),(6)\pi_{\text{BoND}} = \arg\min_{\pi \in \Pi} D(\pi \,\|\, \pi_{\text{BoN}}),\tag{6}πBoND=argπ∈ΠminD(π∥πBoN),(6)
其中 D(⋅∥⋅)D(\cdot\|\cdot)D(⋅∥⋅) 是一种散度度量,用来引导训练策略 π\piπ 向 πBoN\pi_{\text{BoN}}πBoN 靠拢。为此,文献中已有许多可用的散度,比如正向和反向 KL。此外,我们可以利用现有的分布匹配技术,从在线和离线样本中估计 DDD。关于选择哪些合适的散度以及由此得到的 BOND 算法,我们放到第 4 节再讨论。
3.3 Connection with standard RLHF
在本节中,我们把看似不同的两个目标——标准 RLHF(式(1))和 BOND(式(6))——之间的重要联系理清。
众所周知,使式 (1) 中的 RLHF 目标最大化的策略为
πRL(y)∝πref(y) exp (1βRL r(y)).(7)\pi_{\text{RL}}(y) \propto \pi_{\text{ref}}(y)\,\exp\!\left(\frac{1}{\beta_{\text{RL}}} \, r(y)\right).\tag{7}πRL(y)∝πref(y)exp(βRL1r(y)).(7)
由定理 1 推导出的 πBoN\pi_{\text{BoN}}πBoN 表达式可以看出,当采用下面这个特定的 BOND 奖赏时,Best-of-N 采样分布与标准 RLHF 的最优解一致:
rBOND(y)=logp≤(y)⏟(A)+1N−1log∑i=1N[p<(y)p≤(y)] i−1⏟(B),(8)r_{\text{BOND}}(y)=\underbrace{\log p_{\le}(y)}_{\text{(A)}} +\frac{1}{N-1}\underbrace{\log \sum_{i=1}^{N}\left[\frac{p_{<}(y)}{p_{\le}(y)}\right]^{\,i-1}}_{\text{(B)}} , \tag{8}rBOND(y)=(A)
logp≤(y)+N−11(B)
logi=1∑N[p≤(y)p<(y)]i−1,(8)
并且相应的正则强度为 βBOND=1N−1\beta_{\text{BOND}}=\frac{1}{N-1}βBOND=N−11。项 (B) 对应于定理 1 中的校正因子,对所有生成 yyy 都被限制在 [0,logNN−1]\big[0,\frac{\log N}{N-1}\big][0,N−1logN] 内。而项 (A) 则落在 (−∞,0](-\infty,0](−∞,0]。这为 Best-of-N 采样带来了两个有趣的洞见:
- Best-of-N 采样等价于一个带 KL 正则项的标准 RLHF 问题,其正则强度由 NNN 的选择决定。
- Best-of-N 采样等价于优化“期望对数奖励分位数”——也就是:生成结果的奖赏大于参考分布随机样本的概率的对数似然。由于对数函数是凹的,rBOND(y)r_{\text{BOND}}(y)rBOND(y) 会强烈地鼓励模型避免坏的生成,而不是鼓励产生特别好的生成。并且 rBOND(y)r_{\text{BOND}}(y)rBOND(y) 对奖赏函数 r(⋅)r(\cdot)r(⋅) 的任何单调变换都是不变的,因为它只依赖于各生成之间的排名。我们推测这两点让 BOND 的奖赏相比标准 RLHF 更不容易被“奖励黑客”(reward hacking) 利用。
与 RLHF 的联系也启发了本文提出的方法:如果我们能计算出 BOND 奖赏,或者等价地算出 Best-of-N 分布 πBoN\pi_{\text{BoN}}πBoN,就可以通过分布匹配把策略引向 Best-of-N。在下一节我们将探讨为解决其中主要挑战而设计的不同算法。
4.BOND Challenges and Algorithms
实现 BOND 方法会引发以下三个挑战:(1) 如何估计奖赏分位数;(2) 哪个散度指标合适;以及 (3) 如何选择表示 Best-of-N 算法中采样生成数目的超参数 𝑁。我们将在接下来的三个小节中讨论并解决这些挑战。
4.1 Monte-Carlo quantile estimation
估计 πBoN\pi_{\text{BoN}}πBoN 分布的一个关键难点是我们需要估计分位数
p≤(y)=Py′∼πref[ r(y′)≤r(y) ],(9)p_{\le}(y)=\mathbb{P}_{y'\sim \pi_{\text{ref}}}[\,r(y')\le r(y)\,],\tag{9}p≤(y)=Py′∼πref[r(y′)≤r(y)],(9)
即给定生成 yyy 的分位数。这个分位数衡量的是:在相同提示下,从参考分布 πref\pi_{\text{ref}}πref 产生的结果里,yyy 的质量有多好(注意我们在符号里省略了对 xxx 的条件)。
一个非常简单但有效的分位数估计方法是蒙特卡洛采样:从 πref\pi_{\text{ref}}πref 采样 kkk 个生成,然后得到如下经验估计:
p^≤(y)=1k∑i=1k1{ r(yi)≤r(y) }.(10)\hat p_{\le}(y)=\frac{1}{k}\sum_{i=1}^{k}\mathbf{1}\{\,r(y_i)\le r(y)\,\}.\tag{10}p^≤(y)=k1i=1∑k1{r(yi)≤r(y)}.(10)
我们发现在实验中即使样本数量有限,这种方法也非常有效。原则上也可以用其他方法,例如训练一个学习到的分位数模型(我们在附录 B.1 中进行了探索)。
4.2 Jeffreys divergence as a robust objective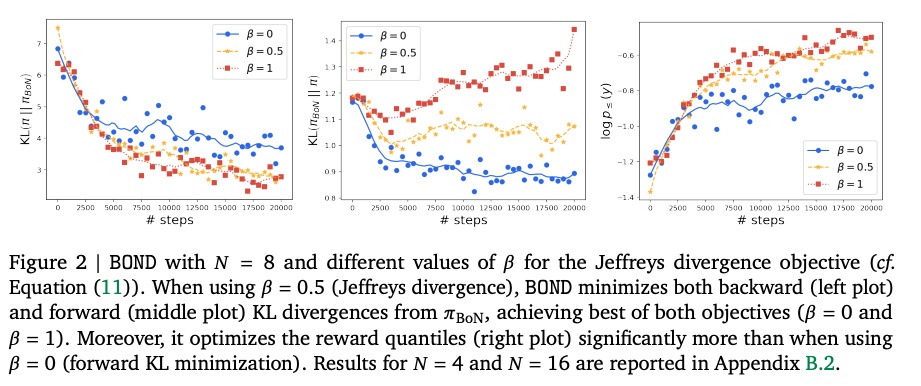
在 BOND 中所用散度度量的选择至关重要:不同的散度会把策略引向截然不同的解。这里我们提出使用 Jeffreys 散度,把它作为一个稳健的分布匹配目标。
两个分布之间的 Jeffreys 散度定义为:
Jeffreysβ(p∥q):=(1−β) KL(q∥p)⏟Forward KL + β KL(p∥q)⏟Backward KL.(11)J^\beta_{\text{effreys}}(p \parallel q) := (1-\beta)\,\underbrace{\mathrm{KL}(q \parallel p)}_{\text{Forward KL}} \;+\; \beta\,\underbrace{\mathrm{KL}(p \parallel q)}_{\text{Backward KL}} .\tag{11}Jeffreysβ(p∥q):=(1−β)Forward KL
KL(q∥p)+βBackward KL
KL(p∥q).(11)
(广义的)Jeffreys 散度是前向 KL 和反向 KL 的加权平均(权重 β∈[0,1]\beta \in [0,1]β∈[0,1])。值得注意的是,在微调策略 ppp 时,前向 KL(q∥p)\mathrm{KL}(q\|p)KL(q∥p) 会鼓励在 ppp 下也覆盖到 qqq 下可能性大的生成(即 mode-covering 行为);而反向 KL(p∥q)\mathrm{KL}(p\|q)KL(p∥q) 早已被认为具有 mode-seeking 的倾向,使得策略 ppp 生成在 qqq 下概率很高的样本。前向 KL 可能导致分布“过度扩散”,而反向 KL 则可能造成策略和熵的塌缩。我们实证表明,Jeffreys 散度继承了二者的优点,从而得到更对齐的策略。
在 BOND 的背景下,这转化为最小化散度 Jeffreysβ(π∥πBoN)J_{\text{effreys}}^{\beta}(\pi \parallel \pi_{\text{BoN}})Jeffreysβ(π∥πBoN)。我们可以用训练策略 π\piπ 和参考策略 πref\pi_{\text{ref}}πref 的样本来估计它,如下所示。
Estimation of the forward KL. 前向 KL 定义为:
KL(πBoN∥π)=Ey∼πBoN[logπBoN(y)−logπ(y)](12)\mathrm{KL}(\pi_{\text{BoN}} \parallel \pi) = \mathbb{E}_{y \sim \pi_{\text{BoN}}}[\log \pi_{\text{BoN}}(y)-\log \pi(y)] \tag{12}KL(πBoN∥π)=Ey∼πBoN[logπBoN(y)−logπ(y)](12)
可以直接通过从 πBoN\pi_{\text{BoN}}πBoN 采样(即从 πref\pi_{\text{ref}}πref 采 NNN 次并选最好那个)来估计,可视为在 Best-of-N 样本上的一次有监督微调损失:
∇θKL(πBoN∥π)=− Ey∼πBoN∇θlogπ(y).(13)\nabla_{\theta}\mathrm{KL}(\pi_{\text{BoN}} \parallel \pi) = -\,\mathbb{E}_{y\sim \pi_{\text{BoN}}} \nabla_{\theta}\log \pi(y). \tag{13}∇θKL(πBoN∥π)=−Ey∼πBoN∇θlogπ(y).(13)
Estimation of the backward KL. 反向 KL 定义为:
KL(π∥πBoN)=Ey∼π[logπ(y)−logπBoN(y)](14)\mathrm{KL}(\pi \parallel \pi_{\text{BoN}}) = \mathbb{E}_{y\sim \pi}[\log \pi(y)-\log \pi_{\text{BoN}}(y)] \tag{14}KL(π∥πBoN)=Ey∼π[logπ(y)−logπBoN(y)](14)
可由策略 π\piπ 自己生成的样本来估计(注意期望是关于 π\piπ 的),并利用对 πBoN\pi_{\text{BoN}}πBoN 下似然的估计。特别地,借助第 3.3 节中的类比,我们在附录 A.3 中展示其梯度与策略梯度(例如 REINFORCE;Williams, 1992)是一致的(与标准 RLHF 相同):
∇θKL(π∥πBoN)=−(N−1) Ey∼π[∇θlogπ(y) (rBOND(y)−βBOND(logπ(y)−logπref(y)))],(15)\nabla_{\theta}\mathrm{KL}(\pi \parallel \pi_{\text{BoN}}) = -(N-1)\; \mathbb{E}_{y\sim \pi} \big[ \nabla_{\theta}\log \pi(y)\, ( r_{\text{BOND}}(y)-\beta_{\text{BOND}}(\log \pi(y)-\log \pi_{\text{ref}}(y)) ) \big], \tag{15}∇θKL(π∥πBoN)=−(N−1)Ey∼π[∇θlogπ(y)(rBOND(y)−βBOND(logπ(y)−logπref(y)))],(15)
其中 rBONDr_{\text{BOND}}rBOND 和 βBOND\beta_{\text{BOND}}βBOND 如第 3.3 节所定义。注意 rBOND(y)r_{\text{BOND}}(y)rBOND(y) 依赖于真实但未知的分位数 p≤(y)p_{\le}(y)p≤(y) 以及式(8)中的校正因子 (B)。在实践中,我们用其估计值替代真实分位数,而我们观察到校正因子影响不大。因此直接用 rBOND(y)=p^≤(y)r_{\text{BOND}}(y)=\hat p_{\le}(y)rBOND(y)=p^≤(y)。另外,为了降低方差,我们使用一个策略梯度基线,取该 batch 中其他生成的平均回报。
因而,整体的 JeffreysβJ_{\text{effreys}}^{\beta}Jeffreysβ 损失就是一次有监督微调损失与一次策略梯度损失的线性加权组合。
Experiments。在图 2 中,我们考虑抽象摘要 XSum 任务,其中 πref\pi_{ref}πref 为 T5 有监督微调策略,r(⋅)r(·)r(⋅) 为 T5 NLI 奖赏模型。我们运行 BOND,其目标函数为 Jeffreysbeta,β∈{0,0.5,1}J^{beta}_{effreys}, \beta ∈ \{0, 0.5, 1\}Jeffreysbeta,β∈{0,0.5,1}。训练期间,我们使用 16 个 MC 样本(每个提示)来估计分位数。在评估阶段(每 500 个训练步),我们使用 32 个 MC 样本来估计训练策略与 πBoN\pi_{BoN}πBoN 分布之间的后向和前向 KL 散度。我们在图 2 中设定了 N=8N = 8N=8,并在附录 B.2 中提供了 N=4N = 4N=4 和 16 的类似图表。结果证实了我们的直觉:相比于仅最小化后向(β=1\beta =1β=1)或前向(β=0\beta = 0β=0)KL 散度,Jeffreys 散度 (β=0.5\beta = 0.5β=0.5) 可以最小化与 πBoN\pi_{BoN}πBoN的两个散度(左图和中图)。此外,在最右边的图中,我们报告了训练策略的奖赏对数分位数(在评估批次上取平均值)。有趣的是,β=0.5\beta = 0.5β=0.5 的 BOND 最大化分位数的方式与模式搜索 β=1\beta = 1β=1 的选择类似,而模式覆盖的前向 KL (β=0\beta = 0β=0) 则滞后。
4.3 Iterative BOND
5.The J-BOND Algorithm


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)