【AI论文】Mind2Web 2:以智能体作为评判者评估具备智能体特性的搜索方法
摘要:本研究针对智能体搜索系统评估的局限性,提出Mind2Web2基准测试和新型评估框架。该基准包含130个需实时网页浏览和深度信息整合的现实任务,构建耗时超1000人工小时。为解决复杂答案评估难题,创新性地采用"智能体作为评判者"方法,通过树状评分标准自动验证答案正确性和来源。测试显示,OpenAI深度研究系统达到人类表现水平的50-70%,用时仅为人工作业的一半。研究为智能
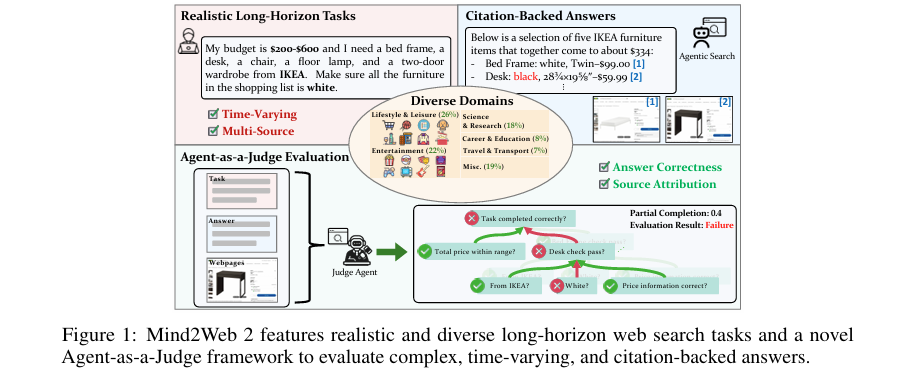
摘要:诸如深度研究(Deep Research)系统这类具备智能体特性的搜索方法,其中大型语言模型能够自主浏览网页、整合信息,并返回有全面引用支持的答案,这代表了用户与网络规模信息交互方式的重大转变。尽管这类方法有望大幅提高效率并减轻认知负担,但智能体搜索日益增长的复杂性和开放性已超越了现有的评估基准和方法,这些基准和方法大多基于简短的搜索范围和静态答案。在本文中,我们推出了Mind2Web 2基准测试,该测试包含130个需要实时网页浏览和广泛信息整合的现实、高质量、长跨度任务,这些任务构建耗时超过1000个人工小时。为应对评估动态变化且复杂答案的挑战,我们提出了一种新颖的“以智能体作为评判者”框架。我们的方法基于树状评分标准设计构建特定任务的评判智能体,以自动评估答案的正确性和来源归属。我们对九个前沿的智能体搜索系统和人类表现进行了全面评估,并进行了详细的错误分析,为未来的发展提供了见解。表现最佳的系统——OpenAI深度研究系统,在仅花费一半时间的情况下,已能达到人类表现水平的50%至70%,显示出巨大潜力。总之,Mind2Web 2为开发和评估下一代智能体搜索系统奠定了严格的基础。Huggingface链接:Paper page,论文链接:2506.21506
研究背景和目的
研究背景:
随着互联网信息的爆炸性增长,用户对高效、准确的信息检索和整合需求日益增加。传统的搜索引擎虽然能够提供大量的信息,但主要依赖于用户手动筛选和整合,这在大规模、复杂或时间敏感的任务中显得力不从心。近年来,具备智能体特性的搜索系统(Agentic Search Systems)应运而生,这些系统利用大型语言模型(LLMs)自主浏览网页、合成信息,并提供有全面引用支持的答案,从而极大地提高了信息检索的效率和准确性。然而,随着这些系统功能的增强和任务的复杂化,现有的评估基准和方法已难以满足需求,特别是在处理长跨度、实时变化和复杂答案的任务时显得力不从心。
研究目的:
本文旨在解决现有评估基准在评估具备智能体特性的搜索系统时的局限性,提出一个新的基准测试Mind2Web 2,该基准包含130个现实、高质量、长跨度的任务,要求系统进行实时网页浏览和广泛的信息整合。同时,本文提出了一种创新的“以智能体作为评判者”(Agent-as-a-Judge)框架,用于自动评估这些复杂任务中答案的正确性和来源归属。通过这一基准和评估方法,本文希望为下一代智能体搜索系统的开发和评估提供一个严格的基础,推动该领域技术的进一步发展。
研究方法
1. 基准测试构建:
Mind2Web 2基准测试包含了130个任务,这些任务覆盖了生活娱乐、科学研究、职业教育、旅游交通等多个领域,每个任务都需要系统进行实时网页浏览和广泛的信息整合。任务的构建经过了任务提出、细化、验证等多个阶段,确保了任务的真实性、复杂性和可验证性。整个基准测试的构建耗时超过1000个人工小时,体现了其高质量和严谨性。
2. 评估框架设计:
为了应对评估动态变化且复杂答案的挑战,本文提出了“以智能体作为评判者”框架。该框架基于树状评分标准设计,为每个任务构建特定的评判智能体,这些智能体能够自动评估答案的正确性和来源归属。具体实现上,评判智能体利用LLMs进行信息抽取和验证,通过设计详细的评分标准树(Rubric Tree),将复杂的评估任务分解为多个可管理的子任务,每个子任务都有明确的评估标准和验证方法。
3. 系统评估与比较:
本文对九个前沿的智能体搜索系统进行了全面评估,包括ChatGPT Search、Perplexity Pro Search、OpenAI Operator、Hugging Face Open Deep Research等。评估过程中,每个系统独立运行三次,以减少随机误差。评估指标主要包括部分完成度(Partial Completion)和成功率(Success Rate),同时记录了任务的平均完成时间和答案的平均长度。此外,本文还进行了人类表现研究,以提供人类水平的基准参考。
研究结果
1. 基准测试特性:
Mind2Web 2基准测试中的任务具有高度的复杂性和多样性,平均每个任务的评分标准树包含50个节点,最大节点数达到603个。这些任务要求系统进行深入的网页浏览和信息整合,体现了现实世界中信息检索的复杂性和挑战性。人类参与者完成这些任务平均需要188分钟,访问多达31个网站和375个网页,进一步证明了任务的艰巨性。
2. 系统性能评估:
评估结果显示,各系统在Mind2Web 2基准测试上的表现差异显著。传统的商业搜索产品如ChatGPT Search和Perplexity Pro Search表现较弱,主要受限于其搜索范围和浅层信息合成能力。相比之下,深度研究系统如OpenAI Deep Research和Grok DeeperSearch表现优异,这些系统能够持续进行详细的任务参与,并利用先进的工具和推理能力生成更全面、准确的答案。其中,OpenAI Deep Research系统在部分完成度和成功率上均表现最佳,同时完成任务的时间也最短,显示了其巨大的潜力。
3. 人类表现对比:
人类参与者在Mind2Web 2基准测试上的表现优于大多数系统,但仍有提升空间。人类在完成复杂任务时表现出更高的准确性和细致度,但同时也受到认知疲劳和有限工作记忆的限制。相比之下,智能体搜索系统在处理大规模、重复性和时间敏感的任务时具有明显优势,能够自动化地完成信息检索和整合工作,减轻用户的认知负担。
研究局限
1. 任务覆盖范围有限:
尽管Mind2Web 2基准测试包含了130个高质量的任务,但仍然无法覆盖所有现实世界中的信息检索场景。某些任务类别(如模糊或高度主观的查询)由于其实用性和评估难度的考虑被排除在外。)因此,该基准测试在任务覆盖范围上仍存在一定的局限性。
2. 评估框架假设:
本文提出的“以智能体作为评判者”框架依赖于URL的来源归属验证,假设引用的URL提供真实可信的信息。然而,网络信息的真实性和可信度是一个复杂且多变的问题,评估框架可能无法完全捕捉到这一点。此外,评估过程中对LLMs的依赖也可能引入一定的偏差和不确定性。
3. 有限分析黑盒系统:
由于本文主要评估的是前沿的商业和闭源智能体搜索系统,对于这些系统的内部工作原理和实现细节了解有限。这限制了我们对系统性能差异的深入分析和解释能力。同时,由于无法获取这些系统的详细运行数据和日志信息,评估过程中可能存在一定的主观性和不确定性。
未来研究方向
1. 扩展任务覆盖范围:
未来的研究可以进一步扩展Mind2Web 2基准测试的任务覆盖范围,包括更多样化的任务类型和更复杂的任务场景。通过引入更多具有挑战性和实用性的任务,可以更全面地评估智能体搜索系统的性能和泛化能力。同时,可以考虑引入跨语言和跨文化的任务,以评估系统在不同语言和文化背景下的表现。
2. 改进评估框架:
针对现有评估框架的局限性,未来的研究可以探索更先进的评估方法和技术。例如,可以结合多模态信息和上下文理解来提高答案正确性和来源归属的评估准确性;可以引入更复杂的评分标准和验证机制来捕捉网络信息的真实性和可信度;还可以利用对抗性测试和鲁棒性评估来增强系统的稳定性和可靠性。
3. 深入分析系统内部机制:
为了更深入地理解智能体搜索系统的性能差异和优化方向,未来的研究可以进一步探索这些系统的内部工作原理和实现细节。通过开源系统或与商业系统提供商的合作,获取更详细的运行数据和日志信息,从而进行更深入的性能分析和优化建议。同时,可以探索新的算法和模型结构来提高系统的信息检索和合成能力。
4. 推动实际应用和商业化:
最终,未来的研究应该致力于将智能体搜索系统推向实际应用和商业化。通过与各行各业的合作和应用场景的探索,发现系统的实际应用价值和市场需求。同时,可以探索如何降低系统的运行成本和提高用户体验,从而推动智能体搜索系统的广泛普及和应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 42
42 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)