大模型调参前先看这篇!Text-to-SQL 任务里,数据集 “对不对味” 直接决定效果
这篇论文揭示了Text-to-SQL任务中训练数据与目标任务的结构对齐度对模型性能的关键影响。研究发现,通过计算训练数据与目标任务的SQL结构特征分布差异(KL对齐度)和对齐比(AR),可有效预测微调效果:当AR>1时,微调通常能提升性能;反之则可能适得其反。实验表明,像Qwen2.5-coder等预训练充分的基础模型对结构变化更稳健,而传统模型更依赖数据对齐。研究还发现少样本提示对改善结构
作为天天跟代码和模型打交道的程序员,咱们肯定都经历过这种崩溃时刻:花了好几天给大模型做监督微调(SFT),结果跑测试的时候发现,要么 accuracy 没涨多少,要么干脆不升反降。尤其做 Text-to-SQL 这种要跟数据库打交道的任务,明明用的是业界公认的 SFT 流程,咋效果就这么飘忽不定?最近看到一篇来自阿尔伯塔大学和华为加拿大团队的论文,才算把这事儿给说透了 —— 问题压根不在调参技巧上,而在你选的训练数据集,跟目标任务 “对齐” 没对齐。
先跟大家掰扯清楚啥是 Text-to-SQL。简单说就是把用户的自然语言问题,自动转成能在数据库上跑的 SQL 语句。比如用户问 “2024 年每个地区的木材总产量是多少”,模型得输出对应的 SELECT...GROUP BY 语句。这活儿对非技术用户太友好了,不管是企业做报表还是医院查数据,都用得上。但实际落地的时候,模型经常掉链子 —— 同一个模型,在 A 数据集上训完能打 90 分,换个 B 数据集可能就只剩 60 分,关键就在于训练数据和目标任务的 “结构对齐度”。
论文里提了个核心假设:与其盲目找数据微调,不如先算一算训练数据、目标数据,还有模型微调前预测结果的 “SQL 结构特征分布”。要是这三者能对上,微调效果肯定差不了;要是对不上,花再多时间都是白费。为了验证这个假设,他们用了三个跨领域的 Text-to-SQL benchmark(BIRD、Spider、Gretel),还测了 QWen2、CodeLlama、Qwen2.5-coder 这三大类模型,从 0.5B 到 14B 参数都覆盖了,结果确实很有说服力。
先给大家看个直观的例子,论文里的图1 展示了不同模型在 Gretel 测试集上,微调前后的执行准确率变化。你会发现,有的模型(比如 Qwen2-7B-Instruct)微调后准确率涨了一截,有的(比如 CodeLlama-7B)微调后居然还降了。这就很奇怪了,为啥同样的微调流程,效果差这么多?答案就是 “数据集对齐”—— 如果用的 SFT 数据跟 Gretel 的结构差太远,模型越训越偏,自然就掉分了。
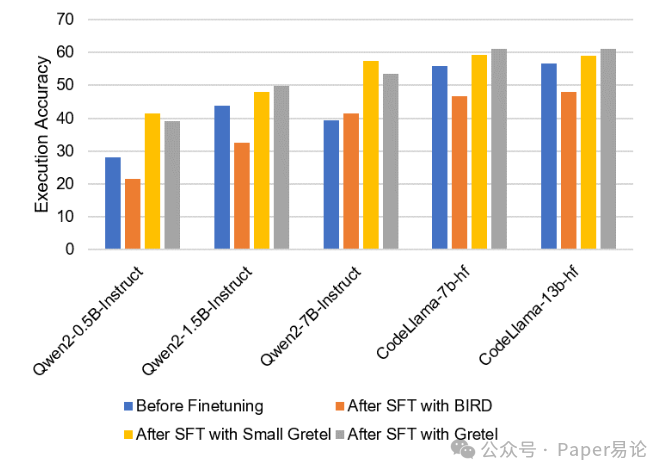
图1:不同模型在 Gretel 测试集上微调前后的执行准确率
要搞懂 “对齐”,首先得明确用啥指标衡量。论文里没搞花里胡哨的,直接从 SQL 的结构入手。咱们都知道,SQL 语句不管多复杂,核心都是 “模板”—— 比如 “SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 列名”,只不过不同任务里的表名、列名、具体条件不一样。所以他们先把 SQL 语句里的 “ schema 相关 token”(比如具体的表名、列名、数值)去掉,只保留结构模板,再用 n-gram(从 1 到 15 个 token 长度,因为数据集里 SQL 平均长度也就 12-14 个 token)来表示这些模板的分布。
接下来就是算 “距离” 了 —— 用 KL 散度来衡量训练数据和目标数据的 n-gram 分布差异。KL 散度越小,说明两者分布越像;为了方便理解,他们还把 KL 散度转成了 0 到 1 之间的 “KL-alignment”(公式是 exp (-KL 散度 /c),c 是缩放系数,保证最低分不低于 1/e),这个值越接近 1,就说明训练数据和目标数据越对齐。
更关键的是,他们还提出了一个 “对齐比(AR)” 的概念 —— 用 “训练数据和目标数据的 KL-alignment” 除以 “模型微调前预测结果和目标数据的 KL-alignment”。如果 AR>1,说明训练数据比模型原本的认知更贴近目标任务,微调大概率能涨分;要是 AR<1,那微调可能不仅没用,还会让模型 “学歪”。
为了让大家更清楚,咱们看论文里的表1,这是不同模型和训练数据集,对三个目标集(Spider 开发集、BIRD 开发集、Gretel 测试集)的 KL-alignment 得分。比如 Qwen2.5-coder-14B 对 Spider 的对齐得分是 0.80,对 BIRD 是 0.67,对 Gretel 是 0.71,明显比老款的 CodeLlama-7B(Spider 0.58、BIRD 0.49、Gretel 0.68)更能打。再看训练集,Spider 训练集对自己开发集的对齐得分是 0.81,但对 BIRD 开发集只有 0.46,这就解释了为啥用 Spider 数据训的模型,在 BIRD 上效果差 —— 压根不对齐啊!
表 1:基础模型和训练数据集对 Spider 开发集、BIRD 开发集、Gretel 测试集的 KL 对齐得分(得分越高,语法对齐度越高)
|
Model/Dataset |
Spider |
BIRD |
Gretel |
|---|---|---|---|
|
CodeLlama 13B |
0.52 |
0.51 |
0.64 |
|
CodeLlama 7B |
0.58 |
0.49 |
0.68 |
|
QWen2 7B |
0.63 |
0.61 |
0.68 |
|
QWen2 1.5B |
0.61 |
0.60 |
0.69 |
|
QWen2 0.5B |
0.46 |
0.57 |
0.66 |
|
Deeepseek 6.7B |
0.59 |
0.53 |
0.67 |
|
Qwen2.5-coder 14B |
0.80 |
0.67 |
0.71 |
|
Qwen2.5-coder 7B |
0.61 |
0.66 |
0.72 |
|
Qwen2.5-coder 3B |
0.76 |
0.67 |
0.71 |
|
Spider Train |
0.81 |
0.46 |
0.43 |
|
BIRD Train |
0.49 |
0.74 |
0.42 |
|
Gretel Train |
0.61 |
0.52 |
0.88 |
|
SmGretel Train |
0.46 |
0.44 |
0.71 |
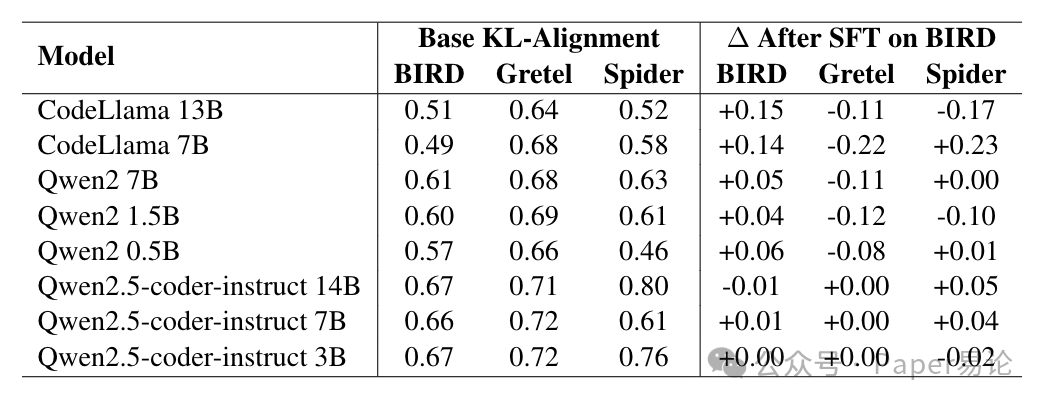
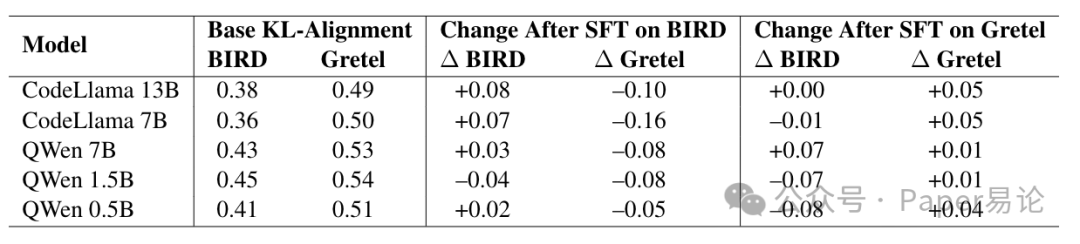
微调之后的变化更能说明问题。Table 2 是用 BIRD 训练集微调后,模型对三个目标集的 KL 对齐得分变化。比如 CodeLlama-13B 微调后,对 BIRD 的对齐得分涨了 0.15(从 0.51 到 0.66),但对 Gretel 掉了 0.11,对 Spider 掉了 0.17—— 这就是典型的 “过拟合到训练数据结构”,微调后在目标域(BIRD)变好,但在其他域(Gretel、Spider)变差了。而 Qwen2.5-coder 系列就稳很多,微调后对齐得分变化大多在 - 0.01 到 + 0.05 之间,说明这代模型本身就跟各个数据集的结构很对齐,不用怎么调就很能打。
表 2:用 BIRD 训练集微调前后,模型输出(零样本)在 BIRD 开发集、Gretel 测试集、Spider 开发集上的 KL 对齐得分(左侧是基础得分,右侧是微调后的变化值∆)
可能有同学会问,那少样本提示(few-shot)能不能救一下?比如给模型塞几个跟目标任务像的例子,能不能提升对齐度?论文里也测了,结果在 Table 3 里。不管是零样本、给 1 个共享模板的例子(ExS1),还是给 2 个(ExS2),基础模型的 KL 对齐得分也就从 0.61 涨到 0.63,微调后的模型更是几乎没变化(一直是 0.61 左右)。这说明啥?少样本提示的作用太有限了,跟正经的 SFT 比起来,根本撼动不了模型的底层结构认知,要是训练数据本身不对齐,靠几个例子补不上来。
表 3:基础模型和微调后模型在零样本、少样本提示下的 KL 对齐得分(均值 ± 标准差)。少样本设置包括 ExS1(1 个与目标数据集共享的查询模板)和 ExS2(2 个共享模板)
|
少样本设置 |
基础模型(均值 ± 标准差) |
微调后模型(均值 ± 标准差) |
|---|---|---|
|
Zero-shot |
0.61 ± 0.07 |
0.61 ± 0.10 |
|
Few-shot (ExS1) |
0.62 ± 0.06 |
0.61 ± 0.08 |
|
Few-shot (ExS2) |
0.63 ± 0.04 |
0.61 ± 0.08 |
对齐度跟模型准确率的关系更直接。Figure 2 里,左边是 KL 对齐度和执行准确率的关系,右边是和精确匹配率(EM)的关系。你能明显看到,点越往右上角走,对齐度和准确率都越高。比如 Qwen2.5-coder 系列(灰色点)几乎都在右上角,而 CodeLlama(橙色点)大多在左下角 —— 这就实打实地证明了,对齐度高的模型,准确率肯定差不了。
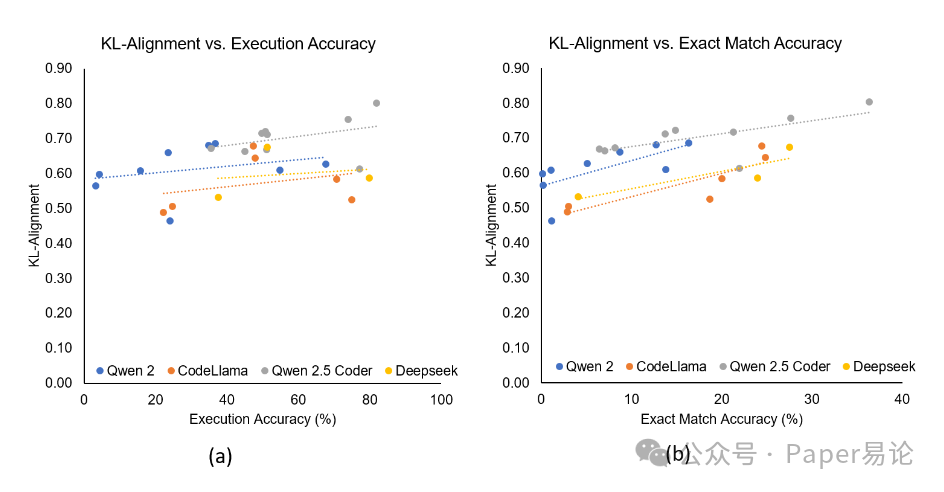
图2:基础模型输出的 KL 对齐度与执行准确率(a)、精确匹配准确率(b)的相关性
最有用的还是 “对齐比(AR)” 的预测能力。论文里的 Figure 3 展示了 AR 值和微调后执行准确率变化的关系:只要 AR>1,微调后准确率基本都是涨的;要是 AR<1,要么涨得很少,要么直接降。比如 CodeLlama 模型的相关性系数 r=0.624(p 值 0.03,统计显著),Qwen2 模型 r=0.54(p=0.037),这意味着咱们以后调参前,先算个 AR 值,就能大概知道这波微调值不值得做 —— 再也不用瞎猜了!
不过有个例外,就是 Qwen2.5-coder 系列,AR 值和准确率变化几乎没相关性(r=0.029,p=0.941)。这也能理解,因为这代模型本身预训练就做得好,对 Text-to-SQL 的结构已经吃得很透了,微调能带来的提升空间本来就小,所以 AR 值自然就没那么管用了。
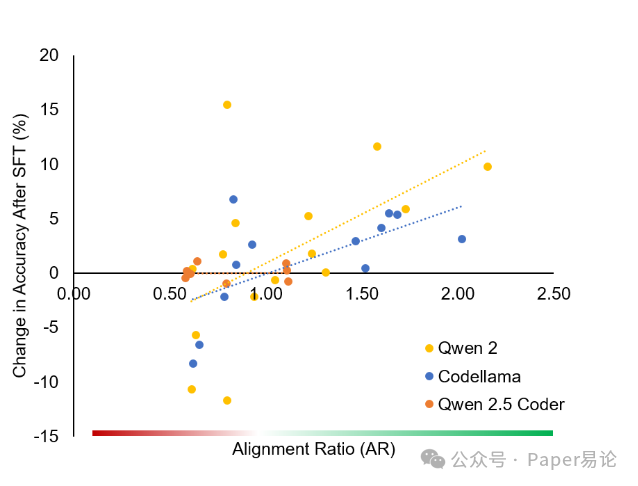
图3:对齐比(AR)的预测能力:AR>1 的数据集通常能带来准确率提升
还有个很实用的发现:不用拿全量数据来算对齐度,小样本就够了。论文里用 BIRD 开发集每个数据库选 2 个查询,Gretel 测试集只取 1%,算出来的 KL 对齐度趋势,跟用全量数据算的几乎一样(Table 4)。这对咱们实际工作太友好了 —— 比如企业里要做内部 Text-to-SQL 系统,不用把所有用户查询日志都标一遍,抽一小部分算对齐度,就能判断用哪个数据集微调更合适,省了多少标注成本啊!
表 4:用目标查询小样本(BIRD 开发集每个数据库 2 个查询,Gretel 测试集 1%)计算的,模型微调前后的 KL 对齐度。尽管样本量减少,相对对齐趋势仍与全量数据集一致
最后再给大家看个具体的例子,看看模型微调后到底 “学歪” 了啥。论文里分析了 QWen-7B 和 CodeLlama-7B 在 Gretel 测试集上的输出,发现有些原本正确的查询,微调后反而错了。比如 “att, SUM (exp)” 这种模板(比如 “SELECT region, SUM (amount) FROM investments GROUP BY region”),QWen-7B 微调前出现 129 次,微调后只剩 13 次;而 “SUM (exp)” 这种模板(比如 “SELECT SUM (amount) FROM investments”),微调前 63 次,微调后涨到 209 次。为啥?因为 BIRD 训练集里 “SUM (exp)” 出现了 1168 次,“att, SUM (exp)” 只出现 35 次 —— 模型硬生生被训练数据的结构带偏了,哪怕目标任务需要的是另一种结构,也只会往训练数据的方向走。
这篇论文给咱们的启发太实在了。以后做 Text-to-SQL 任务,别上来就闷头调参,先做三件事:第一,把目标任务的 SQL 结构模板提出来;第二,算一算候选训练数据集跟目标模板的 KL 对齐度,再算个 AR 值;第三,优先选 AR>1 的数据集来微调,要是 AR<1,要么换数据集,要么干脆别瞎调了,省得越调越差。对了,要是用的是 Qwen2.5-coder 这种本身就很能打的模型,也别花太多精力在微调上,不如把时间花在数据清洗和模板验证上,效果可能更好。
现在大模型卷得厉害,但落地的时候,往往是这些 “对齐” 之类的细节决定成败。这篇论文没搞什么高大上的新算法,就是把 “数据和任务要匹配” 这个朴素的道理,用严谨的实验和清晰的指标说透了,对咱们一线程序员来说,比那些飘在天上的理论有用多了。以后再有人问你 “为啥我微调的模型效果差”,直接把这篇甩给他,让他先算算对齐度再说!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)