用文字、图片和音频“拼”出一个视频!HuMo教你如何做到
字节跳动联手清华大学开源多模态视频生成神器——HuMo!它凭一张图、一段文字、一段音频,就能轻松生成电影级效果的说话视频,彻底解决了传统技术中人物身份不一致、声音画面不同步的老大难问题
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
生成逼真、可控的视频,具体要求包括人物、背景、动作、语态和口型同步等,一直是视频生成领域的重大挑战。而现有的HCVG(Human-Centric Video Generation,以人为主题的视频生成)方法,因为同时协调文字、图片和音频这三大模态很困难,往往容易在三个方面翻车:
-
要么文字描述没被好好利用,导致视频跟要求脱节;
-
要么参考图片的人物身份、外观没保持住,视频里的人“变脸”或者“变样子”;
-
要么音频和口型对不上,人物说话的样子很尴尬。
更糟糕的是,训练一个能处理这三种模态的模型,需要大量精准对齐的三元组数据(文字+图片+音频),而这恰恰是稀缺资源。

清华大学和字节跳动智能创作实验室的研究人员提出了一个叫HuMo的框架,专门解决这些问题。它的核心亮点在于:
-
构建高质量的多模态数据集,解决数据稀缺问题;
-
提出一种渐进式的多模态训练范式,平衡文字、图片、音频的协作;
-
在推理阶段,用时间自适应的分类器自由引导(CFG)策略,动态调整各模态的控制权重。
论文链接:https://arxiv.org/pdf/2509.08519
项目链接:https://github.com/phantom-video/humo
传统方法vs HuMo,到底差在哪?

图2非常直观地展示了传统方法和HuMo的差异。传统方法主要有两种思路:
-
先用文字生成一张“起始图片”(比如OmniHuman-1),再基于这张图生成视频:但这样生成的视频,很容易受起始图片限制,后续哪怕文字要求改掉某些细节(比如加个玩具),也很难实现;
-
利用参考图片生成视频(比如Phantom和HunyuanCustom):虽然能保证人物外观一致,但它们通常不支持音频输入,无法控制人物该说什么,或者口型和音频完全对不上。
而HuMo呢?它完全不受这些限制,既能根据文字灵活调整细节,又能保证参考图片中的人物身份不变,还能让口型完美同步音频。图2里对比了几种方法生成的效果,传统方法在细节和连贯性上明显不如HuMo。
数据不会骗人,HuMo到底多强?
再来看实验结果。论文中提供了两组表格(表1和表2),分别对应“保留主体任务”和“音画同步任务”的定量评估。
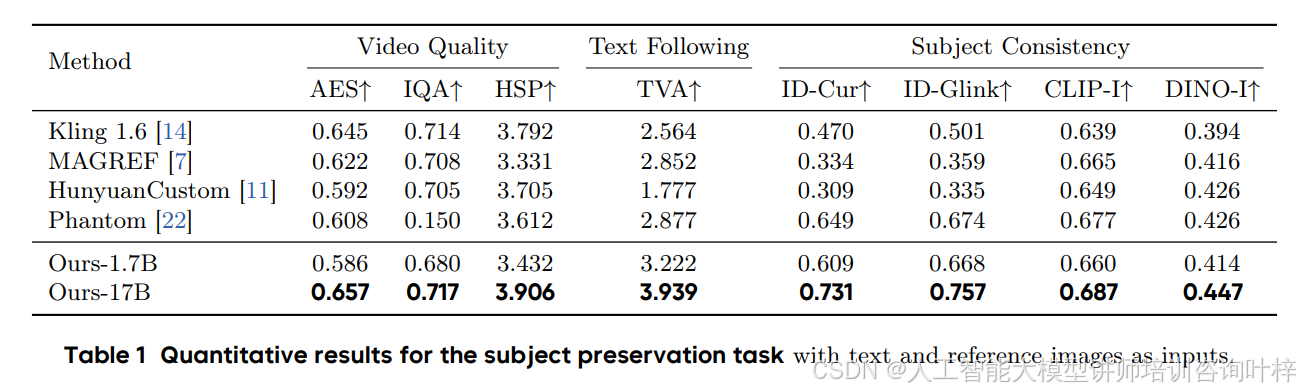
表1:保留主体任务评估
表1从视频质量(AES、IQA)、文本对齐(TVA)、主体一致性(ID-Cur、ID-Glink)等多方面对比了几种方法。结果很明显:
-
在保留参考图片中人物身份的能力上,HuMo表现最佳,尤其是在多人场景中(比如图5中的四人同时进入寺庙的案例),它能精准保持每个人物的外观,而其他方法容易丢人或者让身份“串戏”;
-
在文本跟随能力上,HuMo丝毫不逊色,它能根据文字描述生成高度符合要求的细节,比如让人物做出特定动作或者穿特定服装。
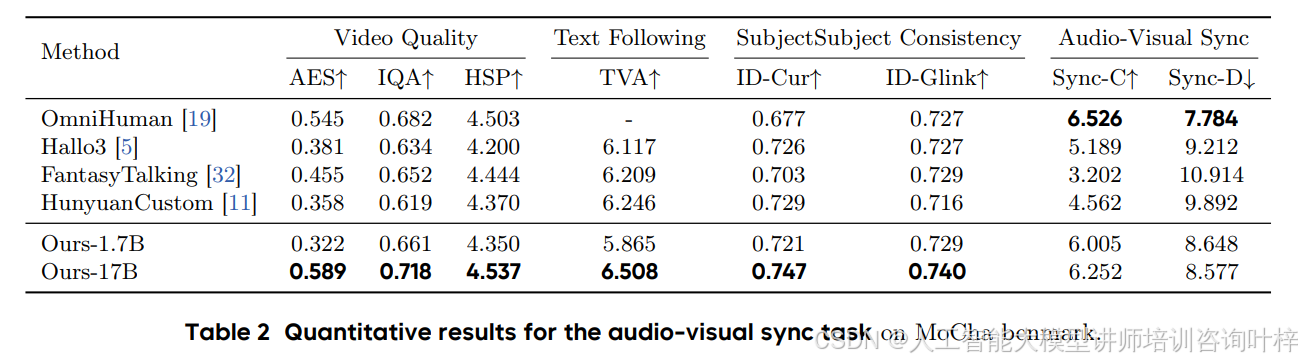
表2:音画同步任务评估
表2则聚焦于音画同步能力,还加入了其他支持音频输入的方法(比如Hallo3、FantasyTalking)。结果显示:
-
即使对比那些依赖完整“起始帧”的方法(比如OmniHuman-1),HuMo依然能凭借参考图片生成高质量的音画同步视频;
-
它在文本跟随和视觉质量上的表现也尤为突出,比如成功渲染出文字描述中的“银色吉他”“金色灯光”等细节。
时间自适应CFG:推理时的“秘密武器”
论文还提到一个关键点,就是推理时采用的时间自适应CFG策略。简单来说,就是让模型在不同生成阶段,自动调整对文字、图片、音频的依赖程度:
-
一开始,优先听从文字描述,搭建起视频的大致框架(比如场景布局、人物位置);
-
后面的生成阶段,则更多依赖图片和音频,专注于细节优化(比如让口型更贴合音频、让人物外观更符合参考图片)。
这种方法避免了传统静态权重分配的弊端,生成的视频细节更丰富、逻辑更连贯。论文里的图4展示了这种动态调整的效果,有兴趣可以去论文里细品。
HuMo的野心不止是“生成视频”
HuMo的意义不止是生成一段视频这么简单。它其实在探索一个更深层次的问题:如何让大模型真正理解并融合多种模态的信息,完成复杂的创作任务?
它的优势在于:
-
不再需要一个“完美的起始图片”来限制生成;
-
文字、图片、音频三者协作无压力,细节和连贯性都在线;
-
推理时还能灵活调整生成策略,让视频更贴合用户需求。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)