快速上手大模型:深度学习8(卷积层填充和步幅、多输入输出通道、池化层)
摘要:本文介绍了卷积神经网络中填充(Padding)和步幅(Strides)的作用及实现方法。Padding通过在输入边缘填充行列来保持特征图尺寸,避免卷积后尺寸过小;Strides通过调整滑动步长来控制输出尺寸和计算量。文中提供了PyTorch实现代码,并讨论了多输入/输出通道的处理方式,包括1×1卷积层的特殊应用。此外,还介绍了计算资源(CPU/GPU)性能的查询方法和卷积层计算复杂度的估算方
由于在做卷积的时候会将图片不断压缩,经过有限次卷积后则无法再进行,故为了做更深的卷积,使用填充(Padding);默认步幅1*1,但当输入图片较大时会导致运算量增加,故可以调整步幅(Strides)。
1 填充(Padding)
填充
行和
列,输出形状为
,
为输入形状,
为卷积核形状。
通常取
,
注意
2 步幅(Strides)
给定高度
,宽度
的步幅,输出形状
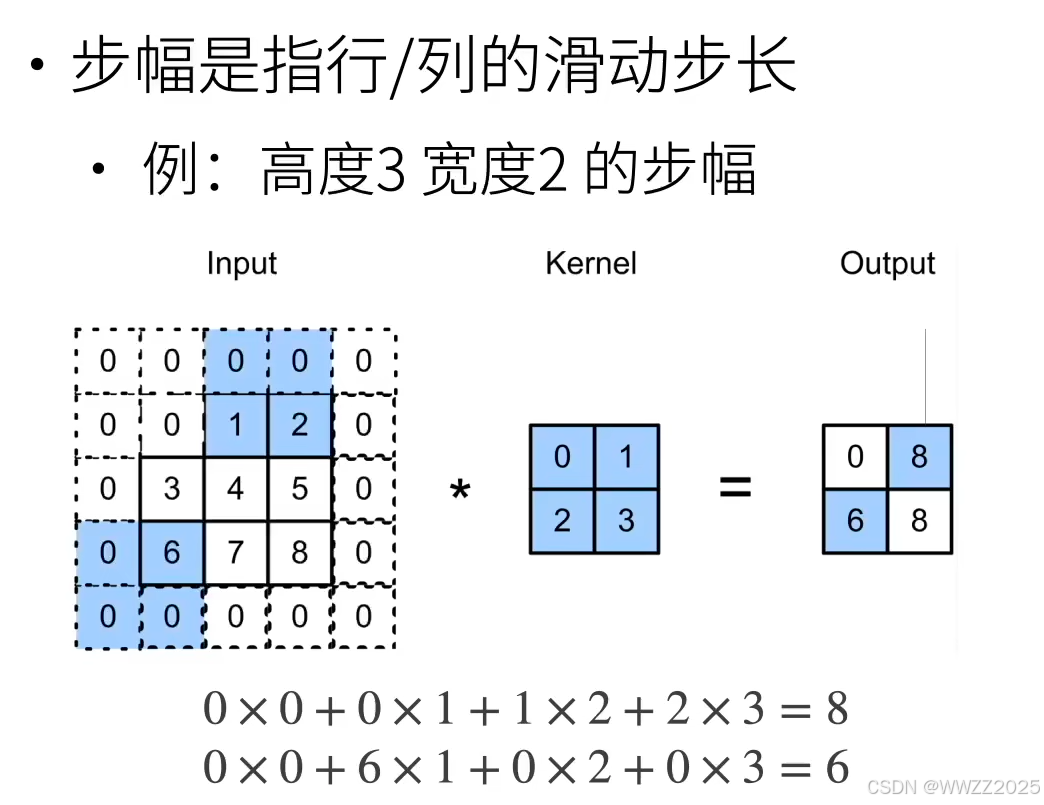
3 代码
import torch from torch import nn # 为了方便起见,我们定义了一个计算卷积层的函数。 # 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数 def comp_conv2d(conv2d, X): # 这里的(1,1)表示批量大小和通道数都是1 X = X.reshape((1, 1) + X.shape) Y = conv2d(X) # 省略前两个维度:批量大小和通道 return Y.reshape(Y.shape[2:]) # 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列 conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1) X = torch.rand(size=(8, 8)) comp_conv2d(conv2d, X).shape # 步幅 conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2) comp_conv2d(conv2d, X).shape
4 多输入输出通道
4.1 多输入通道
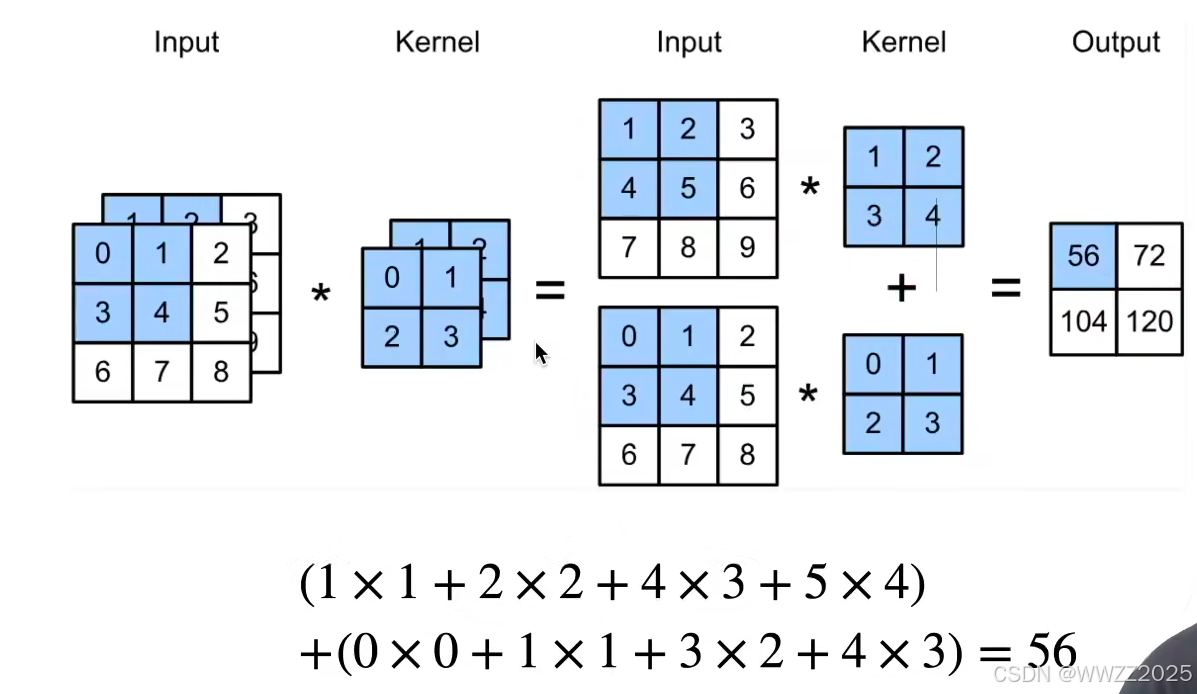
4.2 多输出通道
每个输出通道的巻积核都不一样,所以每个输出通道结果都不一样。

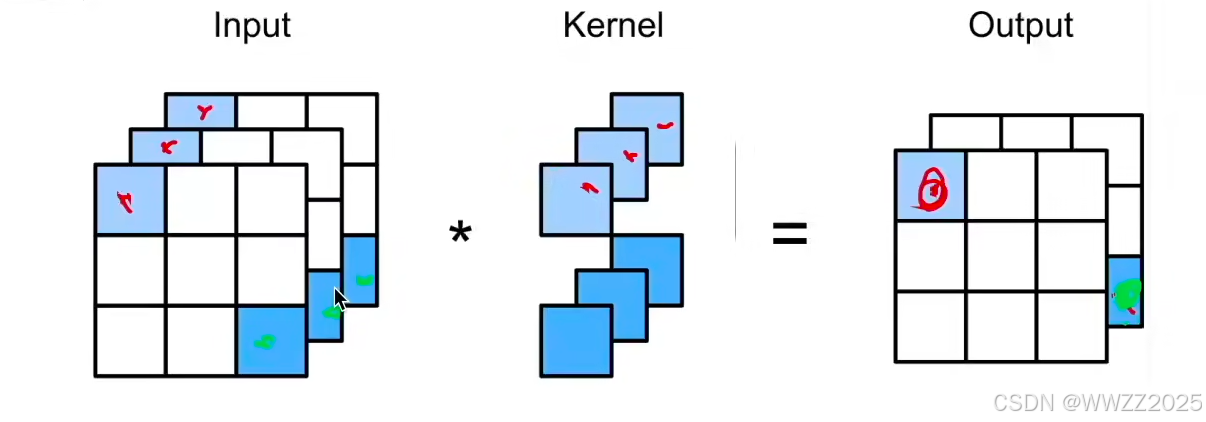
4.3 1X1卷积层
输入是三通,卷积核是两个3*1*1的,输出是双通。
4.4 二维卷积层算力估计
假设
输入X:
核W:
偏差B:
输出Y:
计算复杂度(浮点计算数FLOP)
,
如果训练10层,有1M样本,运算时间为:


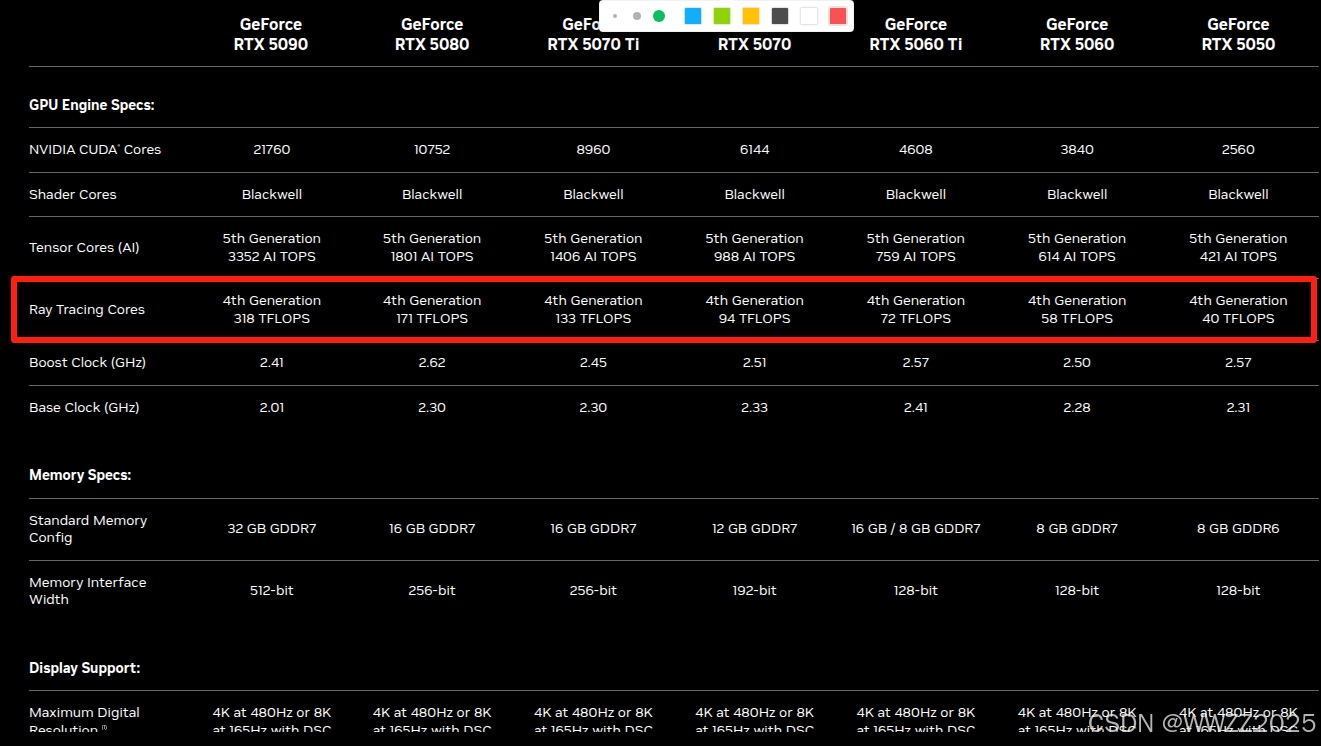
4.4.1 GPU TFLOPS查询
(1)终端查询自己设备GPU设备型号
nvidia-smi --query-gpu=name --format=csv(2)查NVIDIA官方参数
官网参数链接:https://www.nvidia.com/en-gb/geforce/graphics-cards/compare/?utm_source=chatgpt.com
4.4.2 CPU TFLOPS查询
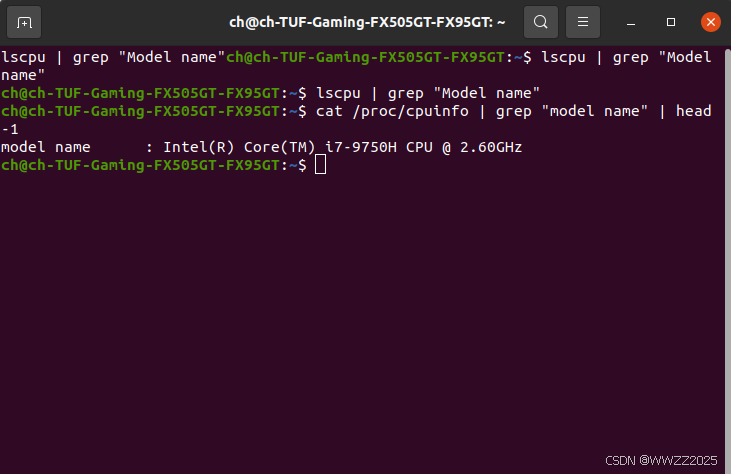
(1)终端查看本机型号
lscpu | grep "Model name"或者
cat /proc/cpuinfo | grep "model name" | head -1
(2)网上查询
4.5 代码
4.5.1 多输入通道
import torch from d2l import torch as d2l def corr2d_multi_in(X, K): # 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起 return sum(d2l.corr2d(x, k) for x, k in zip(X, K)) X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]], [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]]) K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]]) corr2d_multi_in(X, K)
4.5.2 多输出通道
def corr2d_multi_in_out(X, K): # 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。 # 最后将所有结果都叠加在一起 return torch.stack([corr2d_multi_in(X, k) for k in K], 0) K = torch.stack((K, K + 1, K + 2), 0) K.shape corr2d_multi_in_out(X, K)
4.5.3 1*1卷积层
def corr2d_multi_in_out_1x1(X, K): c_i, h, w = X.shape c_o = K.shape[0] X = X.reshape((c_i, h * w)) K = K.reshape((c_o, c_i)) # 全连接层中的矩阵乘法 Y = torch.matmul(K, X) return Y.reshape((c_o, h, w)) X = torch.normal(0, 1, (3, 3, 3)) K = torch.normal(0, 1, (2, 3, 1, 1)) Y1 = corr2d_multi_in_out_1x1(X, K) Y2 = corr2d_multi_in_out(X, K) assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
5 池化层
5.1 作用
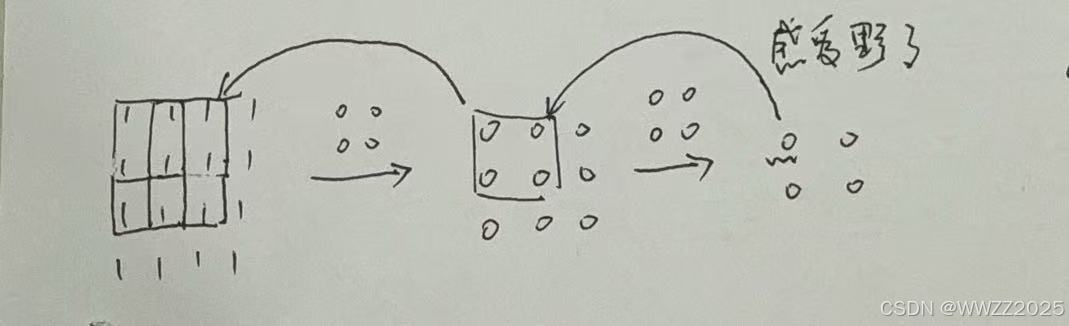
(1)降采样,降低计算量、减少参数;
(2)扩大感受野,捕捉更大结构;
(3)平移不变性,稳定性强;
(4)特征筛选,去噪、保留关键特征。
有最大池化、平均池化,最大池化最常用、保留了区域内最强特征;平均池化会使图像更加柔和。


5.2 代码
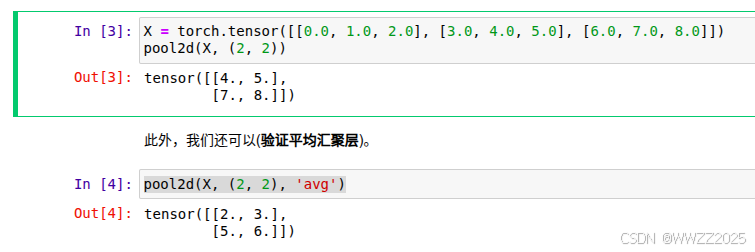
5.2.1 最大/平均池化
import torch from torch import nn from d2l import torch as d2l def pool2d(X, pool_size, mode='max'): p_h, p_w = pool_size Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): if mode == 'max': Y[i, j] = X[i: i + p_h, j: j + p_w].max() elif mode == 'avg': Y[i, j] = X[i: i + p_h, j: j + p_w].mean() return Y X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) pool2d(X, (2, 2)) pool2d(X, (2, 2), 'avg')
5.2.2 填充和步幅
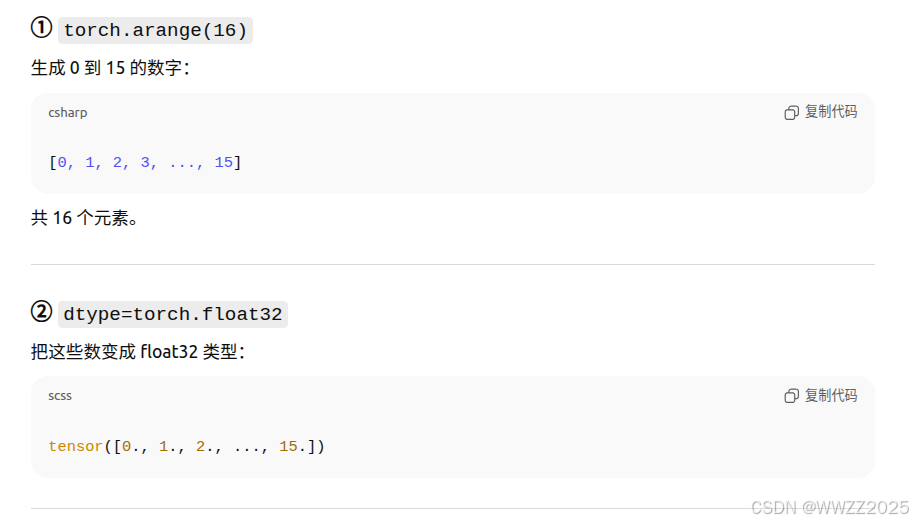
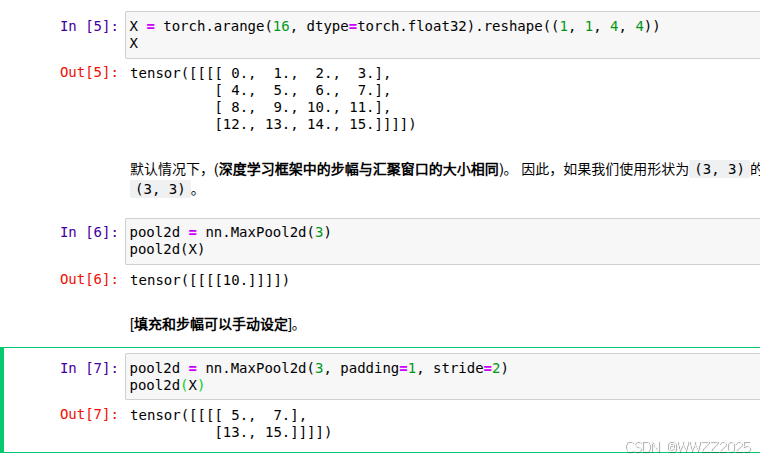
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) X
pool2d = nn.MaxPool2d(3) pool2d(X)
手动设定填充、步幅:
pool2d = nn.MaxPool2d(3, padding=1, stride=2) pool2d(X)


5.2.3 多个通道
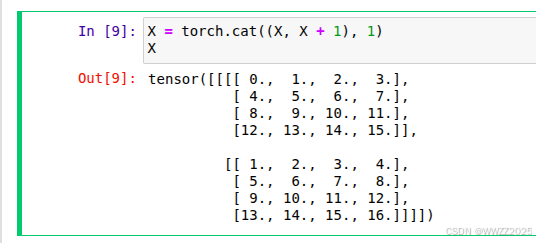
X = torch.cat((X, X + 1), 1) X pool2d = nn.MaxPool2d(3, padding=1, stride=2) pool2d(X)
表示在第一个维度上拼接。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)