Java微服务架构设计模式终极指南
本文系统介绍了Java微服务架构的核心设计模式。主要内容包括:从单体架构到微服务的演变,重点解决模块耦合、扩展性差等问题;基于领域驱动设计(DDD)的微服务拆分方法;服务间通信的同步(API网关)和异步(领域事件)模式;分布式数据管理策略(数据库隔离、Saga事务);可观测性方案(分布式追踪、日志聚合);弹性设计模式(熔断器、隔舱);以及安全认证机制(JWT)。文章结合Spring Cloud生态
引言
在当今快节奏的软件开发世界中,单体架构(Monolithic Architecture)因其固有的局限性——如发布周期长、可扩展性差、技术栈僵化、一个模块的故障可能导致整个系统崩溃等——而逐渐无法满足业务需求。微服务架构(Microservices Architecture)应运而生,它通过将大型应用程序分解为一组小型、松散耦合、自治的服务来应对这些挑战。
然而,“分解”本身并不能带来成功。微服务是一把双双刃剑,它在带来独立部署、技术多样性、强模块边界等好处的同时,也引入了分布式系统固有的复杂性,如网络延迟、最终一致性、运维开销和跨服务测试的困难。
设计模式 正是为了解决这些特定于微服务架构的挑战而诞生的可重用解决方案。它们是在无数实践中总结出的最佳实践,为我们提供了构建健壮、可扩展、可维护的分布式系统的路线图。
本文将系统性地介绍Java微服务生态中的核心设计模式,并辅以代码示例、架构图表和Prompt示例,助您全面掌握微服务的设计精髓。
第一部分:微服务架构的核心模式与基础
在深入具体模式之前,我们首先要理解支撑微服务的几个核心架构概念。
1. 微服务架构风格
微服务架构是一种将单一应用程序作为一套小型服务开发的方法,每个服务都在自己的进程中运行,并通过轻量级机制(通常是HTTP资源API)进行通信。
graph TB
monolith[单体应用]
subgraph Microservices [微服务架构]
direction TB
client[客户端 / Web/App]
client --> API_G[API网关]
API_G --> ServiceA[服务A]
API_G --> ServiceB[服务B]
API_G --> ServiceC[服务C]
ServiceA --> DatabaseA[(数据库 A)]
ServiceB --> DatabaseB[(数据库 B)]
ServiceC --> DatabaseC[(数据库 C)]
ServiceA --> MQ[消息队列]
ServiceB --> MQ
ServiceC --> MQ
end
monolith -.-> |分解为| Microservices
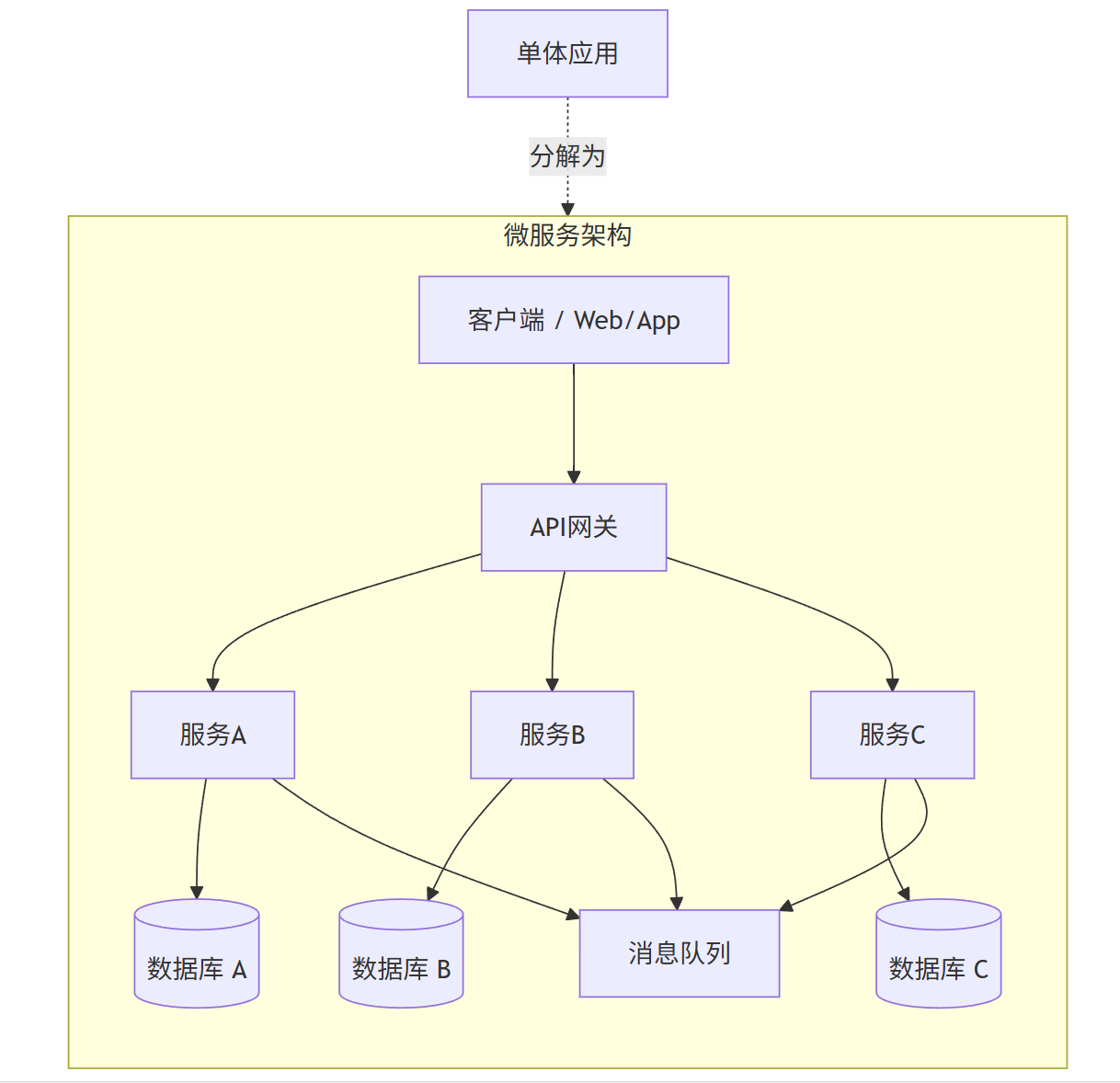
核心特性:
-
服务围绕业务能力构建:而非技术层面。
-
去中心化治理:各服务可选用最适合其需求的技术栈。
-
去中心化数据管理:每个服务拥有自己的私有数据存储。
-
基础设施自动化:强调CI/CD、自动化部署。
-
为失败而设计:服务必须能够处理其依赖服务的故障。
2. 领域驱动设计(DDD)与限界上下文(Bounded Context)
微服务的拆分并非随意进行。领域驱动设计(Domain-Driven Design, DDD) 提供了至关重要的指导原则,其中 限界上下文(Bounded Context) 是进行服务拆分的核心依据。
一个限界上下文是一个明确的边界,领域模型在这个边界内适用。它通常对应一个微服务。例如,“订单上下文”和“物流上下文”对“产品”这个概念会有不同的属性和行为定义。
Prompt示例:
“Act as a software architect. I am designing an e-commerce system. Help me identify the core bounded contexts and map them to potential microservices. Consider domains like product catalog, inventory, ordering, payment, shipping, and customer support.”
第二部分:分解模式 - 如何拆分单体应用
这是微服务之旅的第一步,也是最关键的一步。错误的拆分会导致分布式大泥球(Distributed Big Ball of Mud)。
1. 按业务能力分解(Decompose by Business Capability)
根据业务组织的结构(如销售、市场、客服)来定义服务。
示例: 电商系统可以被分解为:
-
用户服务 -
产品目录服务 -
订单服务 -
支付服务 -
库存服务 -
物流服务
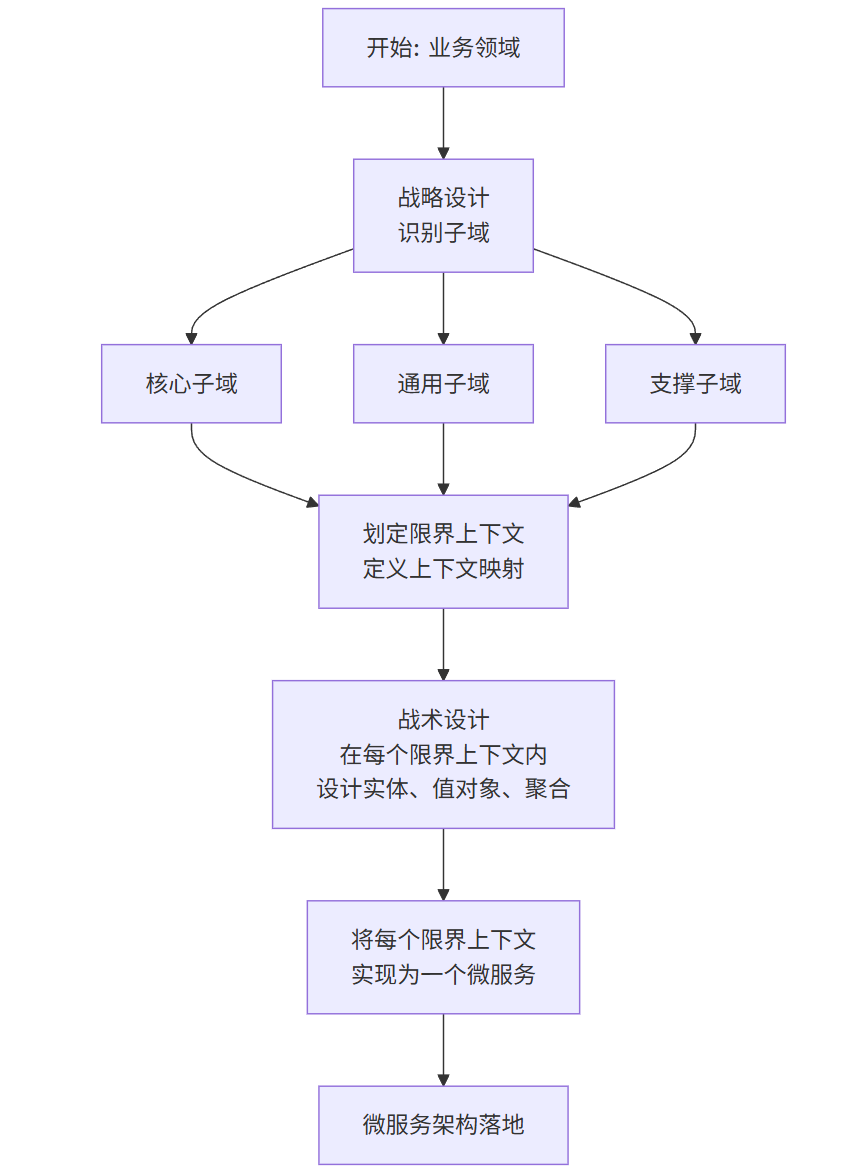
2. 按子域分解(Decompose by Subdomain)
基于DDD,将领域划分为多个子域(核心域、通用域、支撑域),每个子域对应一个或多个微服务。
流程图:从战略设计到微服务
flowchart TD
A[开始: 业务领域] --> B[战略设计<br>识别子域]
B --> C[核心子域]
B --> D[通用子域]
B --> E[支撑子域]
C --> F[划定限界上下文<br>定义上下文映射]
D --> F
E --> F
F --> G[战术设计<br>在每个限界上下文内<br>设计实体、值对象、聚合]
G --> H[将每个限界上下文<br>实现为一个微服务]
H --> I[微服务架构落地]
第三部分:集成模式 - 服务间如何通信
服务是分布式的,因此它们必须通过网络进行通信。通信模式决定了系统的耦合度和可靠性。
1. 通信风格
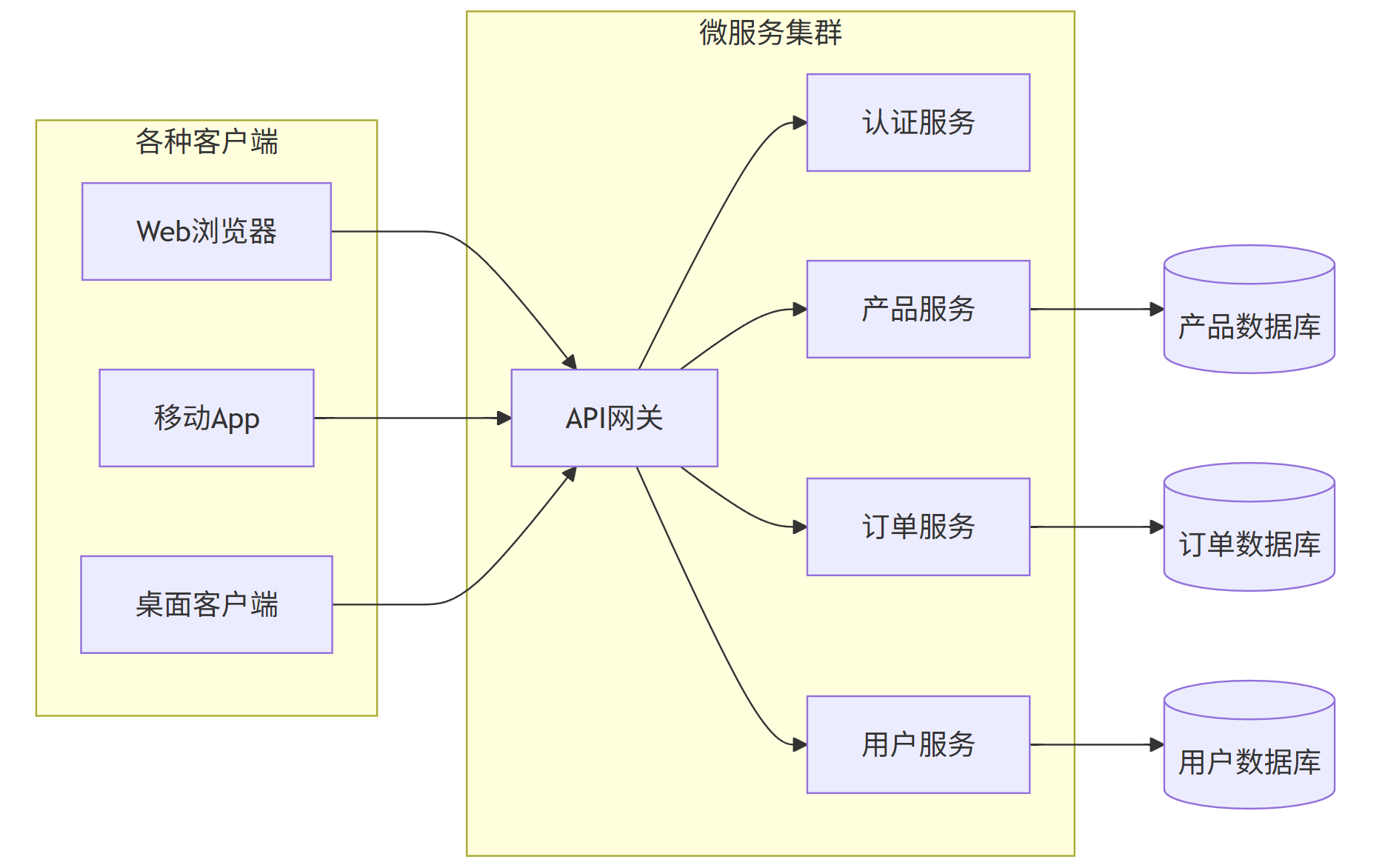
a. 同步模式:API网关模式(API Gateway Pattern)
问题:客户端如何访问由多个微服务组成的应用?直接让客户端调用各个服务会导致:
-
客户端代码复杂。
-
跨服务请求次数多,网络效率低。
-
服务实例的位置(IP+Port)暴露且难以管理。
-
统一交叉切面关注点(如认证、限流、日志)难以实现。
解决方案:API网关作为所有客户端的单一入口点。它负责请求路由、组合、协议转换,并实现认证、监控、限流等功能。
架构图:
graph LR
subgraph Clients [各种客户端]
Web[Web浏览器]
Mobile[移动App]
Desktop[桌面客户端]
end
Web --> API_G[API网关]
Mobile --> API_G
Desktop --> API_G
subgraph Microservices [微服务集群]
API_G --> AuthS[认证服务]
API_G --> ProductS[产品服务]
API_G --> OrderS[订单服务]
API_G --> UserS[用户服务]
end
ProductS --> DB1[(产品数据库)]
OrderS --> DB2[(订单数据库)]
UserS --> DB3[(用户数据库)]
Java实现(使用Spring Cloud Gateway):
pom.xml 依赖:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
application.yml 配置:
yaml
spring:
cloud:
gateway:
routes:
- id: product_service_route
uri: lb://product-service # lb代表从服务发现中心负载均衡
predicates:
- Path=/api/products/**
filters:
- StripPrefix=2 # 移除路径中的前两部分(/api/products)
- id: order_service_route
uri: lb://order-service
predicates:
- Path=/api/orders/**
filters:
- StripPrefix=2
- id: user_service_auth_route
uri: lb://user-service
predicates:
- Path=/api/auth/**
filters:
- StripPrefix=2
b. 异步模式:领域事件模式(Domain Event Pattern)
问题:如何在不紧密耦合服务的情况下,使一个服务中的状态变化触发其他服务的操作?
解决方案:当聚合根的状态发生变化时,它会产生一个领域事件。该事件被发布到消息代理(Message Broker),其他服务可以订阅这些事件并作出反应。
示例:在订单服务中,订单被创建后,它发布一个OrderCreatedEvent。库存服务和支付服务监听此事件,分别进行库存锁定和创建支付订单。
Java实现(使用Spring Cloud Stream + RabbitMQ):
Order 实体中发布事件:
java
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String status;
// ... other fields
@DomainEvents // Spring Data Domain-Driven Design annotation
public Collection<Object> domainEvents() {
List<Object> events = new ArrayList<>();
if ("CREATED".equals(this.status)) {
events.add(new OrderCreatedEvent(this.id, ...));
}
// ... other event types
return events;
}
@AfterDomainEventPublication
public void clearDomainEvents() {
// Clear the events after publication
// ... implementation
}
}
OrderCreatedEvent 事件类:
java
public class OrderCreatedEvent {
private final Long orderId;
private final Instant createdAt;
// ... other event data
public OrderCreatedEvent(Long orderId, ...) {
this.orderId = orderId;
this.createdAt = Instant.now();
// ...
}
// getters
}
OrderService (消息生产者):
java
@Service
@RequiredArgsConstructor
public class OrderService {
private final OrderRepository orderRepository;
private final StreamBridge streamBridge; // Spring Cloud Stream utility
@Transactional
public Order createOrder(Order order) {
Order savedOrder = orderRepository.save(order);
// The domainEvents() method will be called by Spring Data automatically
// But we can also manually send via StreamBridge for more control
streamBridge.send("orderCreated-out-0",
new OrderCreatedEvent(savedOrder.getId(), ...));
return savedOrder;
}
}
InventoryService (消息消费者):
java
@Service
@RequiredArgsConstructor
@Slf4j
public class InventoryService {
private final InventoryRepository inventoryRepository;
@Bean
public Consumer<OrderCreatedEvent> handleOrderCreated() {
return event -> {
log.info("Received OrderCreatedEvent for order id: {}", event.getOrderId());
// Business logic: lock inventory for the items in the order
// 1. Fetch order details (might need to call OrderService via REST)
// 2. Update local inventory records
try {
lockInventoryForOrder(event.getOrderId());
log.info("Inventory locked for order: {}", event.getOrderId());
} catch (Exception e) {
log.error("Failed to lock inventory for order: {}", event.getOrderId(), e);
// Implement compensation logic (e.g., publish an event to cancel the order)
}
};
}
private void lockInventoryForOrder(Long orderId) {
// ... implementation
}
}
配置 application.yml (生产者端):
yaml
spring:
cloud:
stream:
bindings:
orderCreated-out-0:
destination: order.created # Topic/Exchange name in the broker
content-type: application/json
binders:
defaultBinder:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
配置 application.yml (消费者端):
yaml
spring:
cloud:
stream:
bindings:
handleOrderCreated-in-0: # Matches the method name in @Bean
destination: order.created
group: inventory-service-group # For persistent subscriptions
content-type: application/json
binders:
defaultBinder:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
2. 服务发现模式(Service Discovery Pattern)
问题:在云环境中,服务实例的网络位置是动态分配的(如Kubernetes Pod IP)。客户端如何发现服务实例的位置?
解决方案:使用一个服务注册表(Service Registry)(如Netflix Eureka, Consul, Nacos)。服务在启动时向注册表注册自身,关闭时注销。客户端通过查询注册表来发现可用的服务实例。
模式:
-
客户端发现(如Spring Cloud Netflix):客户端从注册表获取所有实例信息,并自行负载均衡(如使用Ribbon)。
-
服务端发现(如Kubernetes):客户端通过负载均衡器(如Kubernetes Service)发起请求,负载均衡器查询注册表并将请求转发到具体实例。
Java实现(使用Spring Cloud Netflix Eureka):
1. Eureka Server (服务注册中心)
pom.xml:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
主应用类 EurekaServerApplication.java:
java
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
application.yml:
yaml
server:
port: 8761
eureka:
client:
register-with-eureka: false # 服务器不注册自己
fetch-registry: false # 服务器不获取注册信息
2. 微服务客户端 (如 product-service)
pom.xml:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
主应用类 ProductServiceApplication.java:
java
@SpringBootApplication
@EnableEurekaClient // 或 @EnableDiscoveryClient (更通用)
public class ProductServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ProductServiceApplication.class, args);
}
}
application.yml:
yaml
spring:
application:
name: product-service # 服务名称,用于注册和发现
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/ # 注册中心地址
3. 使用发现客户端进行服务调用 (在 order-service 中调用 product-service)
java
@Service
@RequiredArgsConstructor
public class OrderService {
private final RestTemplate restTemplate;
private final DiscoveryClient discoveryClient; // Option 1: Low-level client
// Option 1: Using DiscoveryClient directly (not recommended for most cases)
public Product getProductById(Long productId) {
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
if (instances.isEmpty()) {
throw new RuntimeException("No product-service instances available");
}
ServiceInstance instance = instances.get(0); // Simple selection, should use LB
String url = String.format("%s/api/products/%d", instance.getUri(), productId);
return restTemplate.getForObject(url, Product.class);
}
// Option 2: Using @LoadBalanced RestTemplate (Recommended)
// In a @Configuration class:
@Bean
@LoadBalanced // This annotation enables client-side load balancing via Ribbon
public RestTemplate restTemplate() {
return new RestTemplate();
}
// Then inject this RestTemplate and use the service name in the URL
public Product getProductByIdBetter(Long productId) {
String url = String.format("http://product-service/api/products/%d", productId); // Note the use of service name
return restTemplate.getForObject(url, Product.class); // Ribbon resolves 'product-service' to an actual instance
}
// Option 3: Using Feign Client (Even better, declarative approach)
}
第四部分:数据管理模式 - 如何应对分布式数据
这是微服务架构中最复杂的挑战之一。“每个服务拥有自己的数据库”意味着数据一致性从ACID转变为BASE。
1. 数据库 per 服务模式(Database per Service Pattern)
问题:服务之间如何解耦数据库?如果服务共享数据库,那么 schema 变更会变得极其困难,无法实现技术异构,并且服务边界会模糊。
解决方案:每个微服务拥有自己私有的数据库(可以是不同技术的SQL或NoSQL),只能通过其API访问。其他服务绝对不能直接访问此数据库。
2. Saga模式(Saga Pattern)
问题:如何在多个服务之间维护数据一致性,而不使用分布式事务(如两阶段提交,2PC)?(2PC在微服务中被认为是反模式,因为它会导致同步阻塞、可用性降低)。
解决方案:Saga是一种在微服务架构中管理分布式(长期运行)事务的模式,它通过一系列本地事务和补偿事件来保证最终一致性。
协调方式:
-
编排(Choreography):每个服务产生并监听事件,自行决定下一步做什么。没有中央协调器。松耦合但难以调试。
-
协作者(Orchestration):一个中央协调器(Orchestrator)(一个专门的Saga执行协调服务)负责调用参与者服务并告诉他们该做什么。控制流集中,更易于理解和调试。
示例:创建订单的Saga(编排方式)
sequenceDiagram
participant Client
participant OS as Order Service
participant PS as Payment Service
participant IS as Inventory Service
participant NS as Notification Service
Client->>OS: POST /orders
OS->>OS: Create Order (PENDING)
OS->>PS: Publish OrderCreatedEvent
PS->>PS: Process Payment
alt Payment Succeeded
PS->>IS: Publish PaymentSucceededEvent
IS->>IS: Lock Inventory
IS->>OS: Publish InventoryLockedEvent
OS->>OS: Update Order (CONFIRMED)
OS->>NS: Publish OrderConfirmedEvent
NS->>NS: Send Confirmation Email/SMS
else Payment Failed
PS->>OS: Publish PaymentFailedEvent
OS->>OS: Update Order (CANCELLED)
OS->>NS: Publish OrderCancelledEvent
end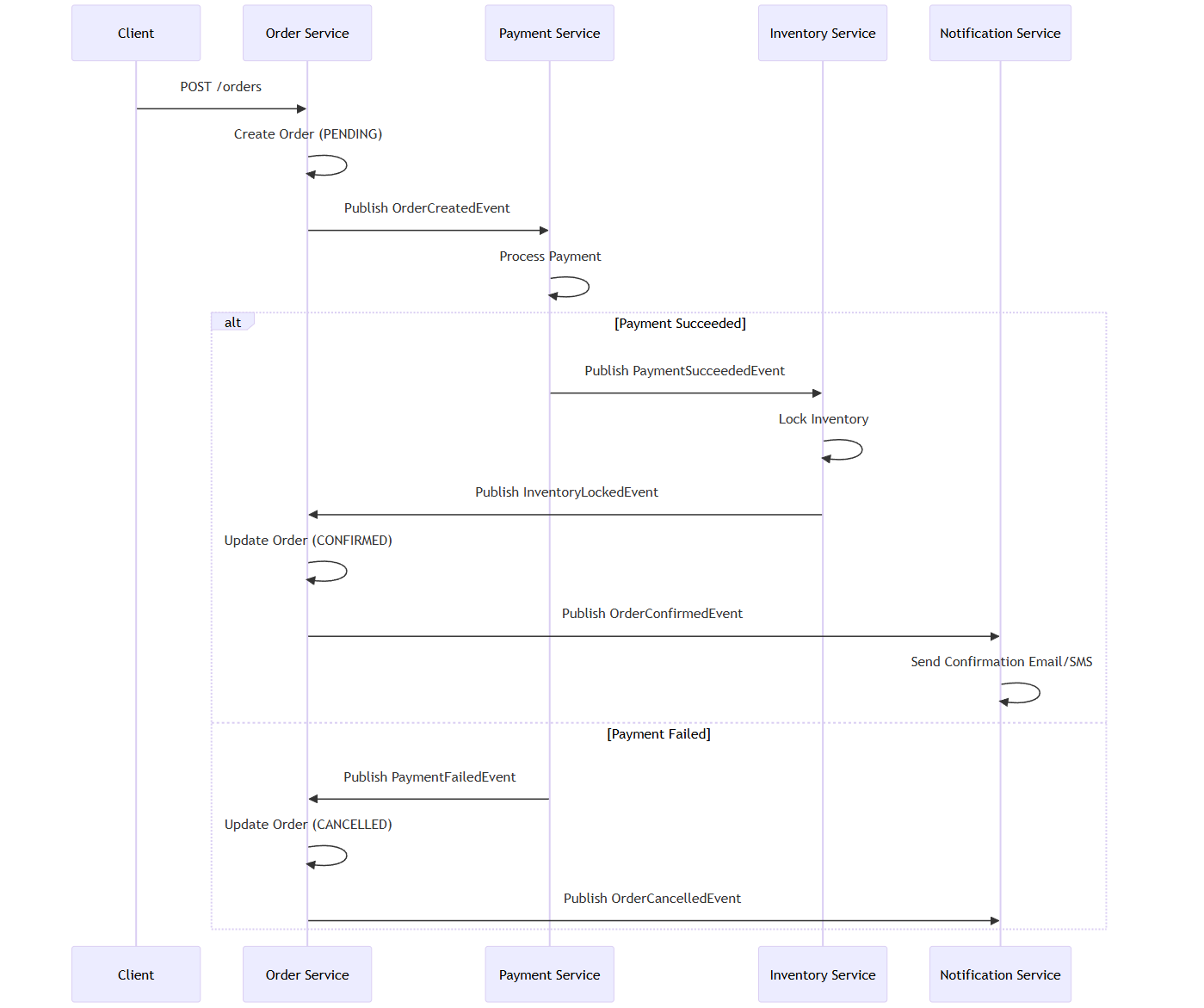
Java实现(Saga协调器方式 - 使用Trampoline框架示例):
OrderSaga.java (协调器):
java
public class OrderSaga {
private final SagaManager<OrderSagaData> sagaManager;
private final CommandDispatcher dispatcher;
public void createOrder(OrderSagaData data) {
SagaInstance sagaInstance = sagaManager.begin(data);
// Step 1: Validate Order
dispatcher.send(new ValidateOrderCommand(sagaInstance.getSagaId(), data.getOrderDetails()));
}
@SagaEventHandler(associationProperty = "sagaId")
public void handle(OrderValidatedEvent event) {
// Step 2: Order validated, process payment
OrderSagaData data = sagaManager.getData(event.getSagaId());
dispatcher.send(new ProcessPaymentCommand(event.getSagaId(), data.getPaymentDetails()));
}
@SagaEventHandler(associationProperty = "sagaId")
public void handle(PaymentSucceededEvent event) {
// Step 3: Payment succeeded, lock inventory
OrderSagaData data = sagaManager.getData(event.getSagaId());
dispatcher.send(new LockInventoryCommand(event.getSagaId(), data.getOrderId(), data.getItems()));
}
@SagaEventHandler(associationProperty = "sagaId")
public void handle(InventoryLockedEvent event) {
// Step 4: Inventory locked, confirm order
OrderSagaData data = sagaManager.getData(event.getSagaId());
dispatcher.send(new ConfirmOrderCommand(event.getSagaId(), data.getOrderId()));
sagaManager.end(event.getSagaId()); // Saga completes successfully
}
@SagaEventHandler(associationProperty = "sagaId")
public void handle(PaymentFailedEvent event) {
// Compensation Step: Payment failed, reject order
OrderSagaData data = sagaManager.getData(event.getSagaId());
dispatcher.send(new RejectOrderCommand(event.getSagaId(), data.getOrderId(), "Payment failed"));
sagaManager.end(event.getSagaId());
}
@SagaEventHandler(associationProperty = "sagaId")
public void handle(InventoryOutOfStockEvent event) {
// Compensation Step: Inventory insufficient, refund payment and reject order
OrderSagaData data = sagaManager.getData(event.getSagaId());
dispatcher.send(new RefundPaymentCommand(event.getSagaId(), data.getPaymentId()));
// After refund succeeds, an event would trigger the final rejection
}
@SagaEventHandler(associationProperty = "sagaId")
public void handle(RefundProcessedEvent event) {
// Final Compensation after refund
OrderSagaData data = sagaManager.getData(event.getSagaId());
dispatcher.send(new RejectOrderCommand(event.getSagaId(), data.getOrderId(), "Inventory out of stock, payment refunded"));
sagaManager.end(event.getSagaId());
}
}
第五部分:可观测性模式 - 如何监控与调试
分布式系统难以调试。你需要强大的工具来洞察系统内部。
1. 分布式追踪模式(Distributed Tracing Pattern)
问题:一个请求流经多个服务,如何跟踪它的完整执行路径、性能瓶颈和故障点?
解决方案:为每个外部请求分配一个唯一的追踪ID(Trace ID),并在服务间传递。每个服务内部的工作(跨度,Span)都会记录并与该Trace ID关联。使用工具如 Zipkin 或 Jaeger 来收集、存储和可视化这些追踪数据。
Java实现(使用Spring Cloud Sleuth + Zipkin):
pom.xml:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
application.yml:
yaml
spring:
zipkin:
base-url: http://localhost:9411/ # Zipkin server address
sleuth:
sampler:
probability: 1.0 # 采样率,1.0=100%,生产环境可调低
无需代码更改,Sleuth会自动注入Trace ID并在日志和HTTP调用中传递。在日志中你会看到 [appname,traceId,spanId,exportable]。
2. 聚合日志模式(Aggregated Logging Pattern)
问题:日志分散在每个服务实例的文件中,如何集中查看和分析?
解决方案:将所有服务的日志流式传输到一个中央日志系统(如ELK Stack: Elasticsearch, Logstash, Kibana 或 EFK Stack: Elasticsearch, Fluentd, Kibana)。
架构图:
graph TB
subgraph Microservice Instance
App[Application] -->|写日志到 stdout| Docker[Container Logger]
end
Docker -->|推送日志| Agent[Log Shipper<br>e.g., Filebeat/Fluentd]
subgraph Centralized Logging Stack
Agent -->|收集转发| Logstash[Logstash<br>解析和过滤]
Logstash -->|存储| ES[Elasticsearch<br>索引和搜索]
ES -->|可视化| Kibana[Kibana<br>查询和仪表盘]
end
User[运维人员] -->|访问| Kibana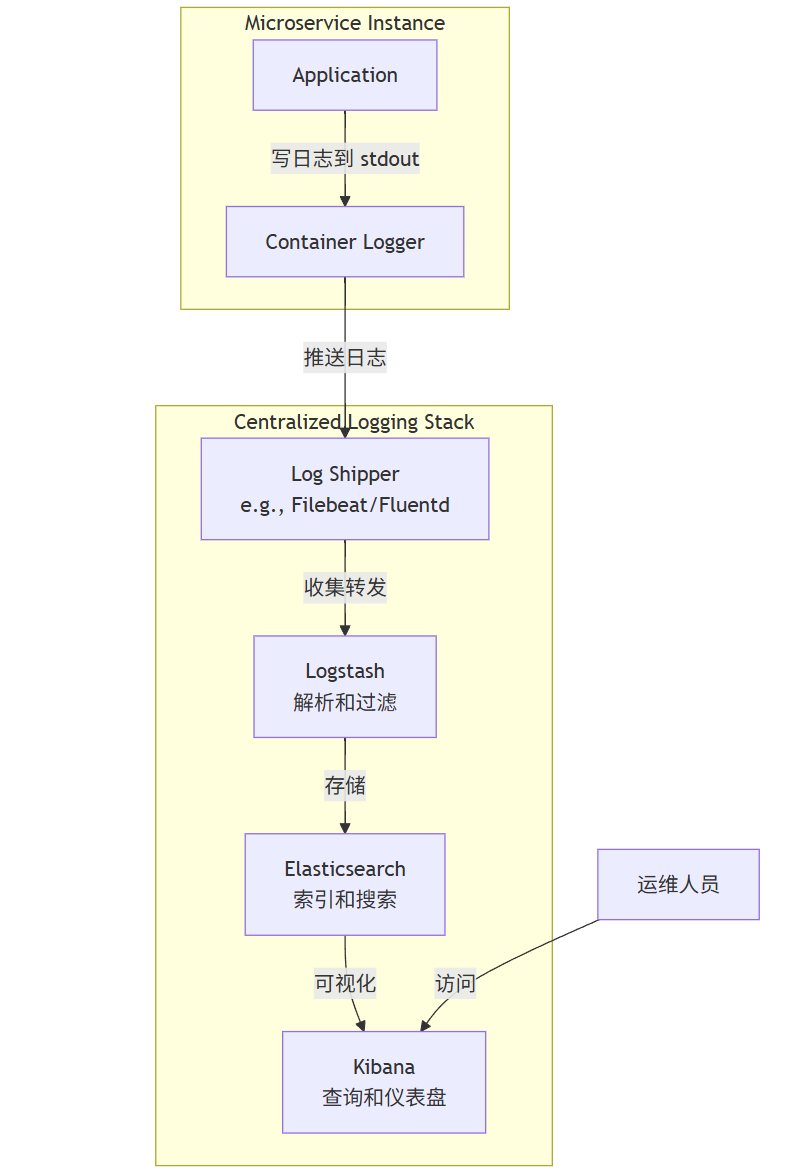
提示示例:
“I am getting a ‘500 Internal Server Error’ for a specific user request. The trace ID is
f4a2c1be38f95673. Find all related logs across all services for this trace ID and show me the complete request flow and where the error occurred.”
第六部分:弹性模式 - 如何为失败而设计
网络是不可靠的,服务会故障。弹性模式使你的系统能够优雅地降级而非彻底崩溃。
1. 熔断器模式(Circuit Breaker Pattern)
问题:如何防止一个故障的服务导致级联故障,拖垮整个系统?例如,一个服务缓慢会导致线程池积压,耗尽资源。
解决方案:使用熔断器包装对依赖服务的调用。它监控失败率,当失败率达到阈值时,熔断并快速失败,不再发出实际请求。经过一段时间后,进入半开状态试探依赖是否恢复。
Java实现(使用Resilience4j):
pom.xml:
xml
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot2</artifactId>
<version>1.7.1</version> <!-- Check for latest version -->
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
在Service方法上使用注解:
java
@Service
public class ProductService {
private final RestTemplate restTemplate;
private final static String INVENTORY_SERVICE = "inventoryService";
// 使用 @CircuitBreaker 注解
@CircuitBreaker(name = INVENTORY_SERVICE, fallbackMethod = "getDefaultInventory")
public String getInventoryStatus(String productId) {
String url = "http://inventory-service/api/inventory/" + productId;
return restTemplate.getForObject(url, String.class);
}
// Fallback 方法,签名需与原方法一致,最后加一个异常参数
private String getDefaultInventory(String productId, Exception e) {
return "Check later"; // 返回降级数据
// 也可以缓存旧数据、返回空值等
}
// 也可以使用代码式配置
private final CircuitBreaker circuitBreaker;
public ProductService(CircuitBreakerRegistry registry) {
this.circuitBreaker = registry.circuitBreaker(INVENTORY_SERVICE);
}
public String getInventoryStatusManual(String productId) {
return CircuitBreaker.decorateSupplier(circuitBreaker, () -> {
String url = "http://inventory-service/api/inventory/" + productId;
return restTemplate.getForObject(url, String.class);
}).get();
}
}
application.yml 配置:
yaml
resilience4j:
circuitbreaker:
instances:
inventoryService:
register-health-indicator: true
sliding-window-size: 10 # 计算失败率的调用次数窗口
minimum-number-of-calls: 5 # 至少5次调用后才开始计算
wait-duration-in-open-state: 10s # 熔断后10秒进入半开状态
failure-rate-threshold: 50 # 失败率阈值50%
permitted-number-of-calls-in-half-open-state: 3 # 半开状态允许的试探调用次数
2. 隔舱模式(Bulkhead Pattern)
问题:如何防止一个服务的故障(如线程池耗尽)扩散到其他不相关的服务调用?
解决方案:借鉴船的隔舱设计,将资源(如线程池)隔离成不同的组。例如,为调用InventoryService和PaymentService分配独立的线程池。这样即使库存服务卡死,耗尽了它的线程池,支付服务的调用依然有可用线程。
Java实现(使用Resilience4j):
java
@Service
public class OrderService {
private final RestTemplate restTemplate;
private final Bulkhead inventoryBulkhead;
private final Bulkhead paymentBulkhead;
public OrderService(BulkheadRegistry registry) {
this.inventoryBulkhead = registry.bulkhead("inventoryBulkhead");
this.paymentBulkhead = registry.bulkhead("paymentBulkhead");
}
public String checkInventory() {
Supplier<String> supplier = () ->
restTemplate.getForObject("http://inventory-service/check", String.class);
return Bulkhead.decorateSupplier(inventoryBulkhead, supplier).get();
}
public String processPayment() {
Supplier<String> supplier = () ->
restTemplate.getForObject("http://payment-service/process", String.class);
return Bulkhead.decorateSupplier(paymentBulkhead, supplier).get();
}
}
application.yml 配置:
yaml
resilience4j:
bulkhead:
instances:
inventoryBulkhead:
max-concurrent-calls: 5 # 该隔舱允许的最大并发调用数
max-wait-duration: 100ms # 获取权限的最大等待时间
paymentBulkhead:
max-concurrent-calls: 10
max-wait-duration: 0ms # 0表示不等待,立即失败
第七部分:安全模式 - 如何保护微服务
1. 访问令牌模式(Access Token Pattern)
问题:服务如何安全地识别调用者的身份和权限?
解决方案:使用JSON Web Tokens (JWT) 作为访问令牌。用户登录后,认证服务颁发一个签名的JWT。客户端在后续请求的 Authorization Header中携带此JWT(Bearer <token>)。每个服务都可以独立验证JWT的签名并提取其中的用户声明(Claims),而无需每次都与认证服务通信。
Java实现(使用Spring Security + JWT):
pom.xml:
xml
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-api</artifactId>
<version>0.11.5</version>
</dependency>
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-impl</artifactId>
<version>0.11.5</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-jackson</artifactId>
<version>0.11.5</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
JWT工具类 JwtUtil.java:
java
@Component
public class JwtUtil {
@Value("${jwt.secret}")
private String secret;
public Claims extractAllClaims(String token) {
return Jwts.parserBuilder()
.setSigningKey(secret.getBytes())
.build()
.parseClaimsJws(token)
.getBody();
}
public Boolean validateToken(String token) {
try {
Jwts.parserBuilder().setSigningKey(secret.getBytes()).build().parseClaimsJws(token);
return true;
} catch (JwtException | IllegalArgumentException e) {
throw new RuntimeException("JWT is invalid", e);
}
}
}
Spring Security配置 SecurityConfig.java:
java
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
private final JwtUtil jwtUtil;
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().disable()
.authorizeRequests()
.antMatchers("/api/auth/**").permitAll()
.anyRequest().authenticated()
.and()
.addFilterBefore(new JwtTokenFilter(jwtUtil), UsernamePasswordAuthenticationFilter.class);
}
}
JWT过滤器 JwtTokenFilter.java:
java
public class JwtTokenFilter extends OncePerRequestFilter {
private final JwtUtil jwtUtil;
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain chain)
throws ServletException, IOException {
final String authorizationHeader = request.getHeader("Authorization");
String username = null;
String jwt = null;
if (authorizationHeader != null && authorizationHeader.startsWith("Bearer ")) {
jwt = authorizationHeader.substring(7);
try {
username = jwtUtil.extractUsername(jwt); // Implement this method to extract subject
} catch (Exception e) {
// handle invalid token
}
}
if (username != null && SecurityContextHolder.getContext().getAuthentication() == null) {
if (jwtUtil.validateToken(jwt)) {
// Create Authentication object and set it in SecurityContext
UsernamePasswordAuthenticationToken authToken =
new UsernamePasswordAuthenticationToken(username, null, new ArrayList<>());
SecurityContextHolder.getContext().setAuthentication(authToken);
}
}
chain.doFilter(request, response);
}
}
总结与组合使用
微服务架构模式很少单独使用。一个健壮的生产系统通常是多种模式的组合。
一个典型的现代Java微服务栈可能如下所示:
-
服务开发: Spring Boot
-
服务发现 & 客户端负载均衡: Netflix Eureka / Spring Cloud LoadBalancer
-
API网关: Spring Cloud Gateway
-
外部配置: Spring Cloud Config
-
容错: Resilience4j (熔断、隔舱、重试、限流)
-
服务通信:
-
同步: OpenFeign /
@LoadBalancedRestTemplate -
异步: Spring Cloud Stream (基于RabbitMQ/Kafka)
-
-
分布式追踪: Spring Cloud Sleuth + Zipkin
-
认证授权: Spring Security + JWT
-
部署与编排: Docker + Kubernetes

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)