产品经理技术篇:必知的模型参数&调优
这些方法。
在深度学习落地实践中,产品经理虽不直接参与算法开发工作,但需要深入理解模型参数的作用原理与调优逻辑。这种技术认知能够帮助产品经理精准评估模型迭代的技术边界,在需求对接和资源协调中建立技术共识。
本文主要介绍超参数、模型训练参数和生成控制参数的概念及在不同阶段发挥的作用。
**超参数:**在训练开始之前设置,并在训练过程中保持不变,影响模型的训练效率和性能。
**模型训练参数:**在训练过程中设置和调整,影响模型的学习过程和性能。
**生成控制参数:**主要应用于基于生成任务的语言模型,如DS系列、Qwen系列、GPT系列。在生成文本时使用,影响生成文本的多样性和质量。
通过合理设置和调整这些参数,可以优化模型的训练效率,提高模型最终性能,在生成文本时平衡多样性和连贯性。
目录
1 构建与训练模型时的参数
1.1 超参数
1.2 模型参数
1.3 调优方法
2 生成式模型的参数
2.1 生成控制参数概念
2.2 生成控制参数的应用
1 构建与训练模型时的参数
在构建和训练大规模神经网络模型时,需要设置和调整超参数和模型参数,我们可以把训练神经网络模型比作烹饪一道美味的菜肴,每个参数就像是烹饪过程中的不同元素和步骤。
1.1 超参数
在机器学习和深度学习中,超参数(Hyperparameters)是在模型训练前需要手动设定(或通过自动优化方法选择)的参数,它们不通过训练数据直接学习得到,不会在训练过程中更新。超参数的选择对模型的性能、训练速度和泛化能力有重要影响。
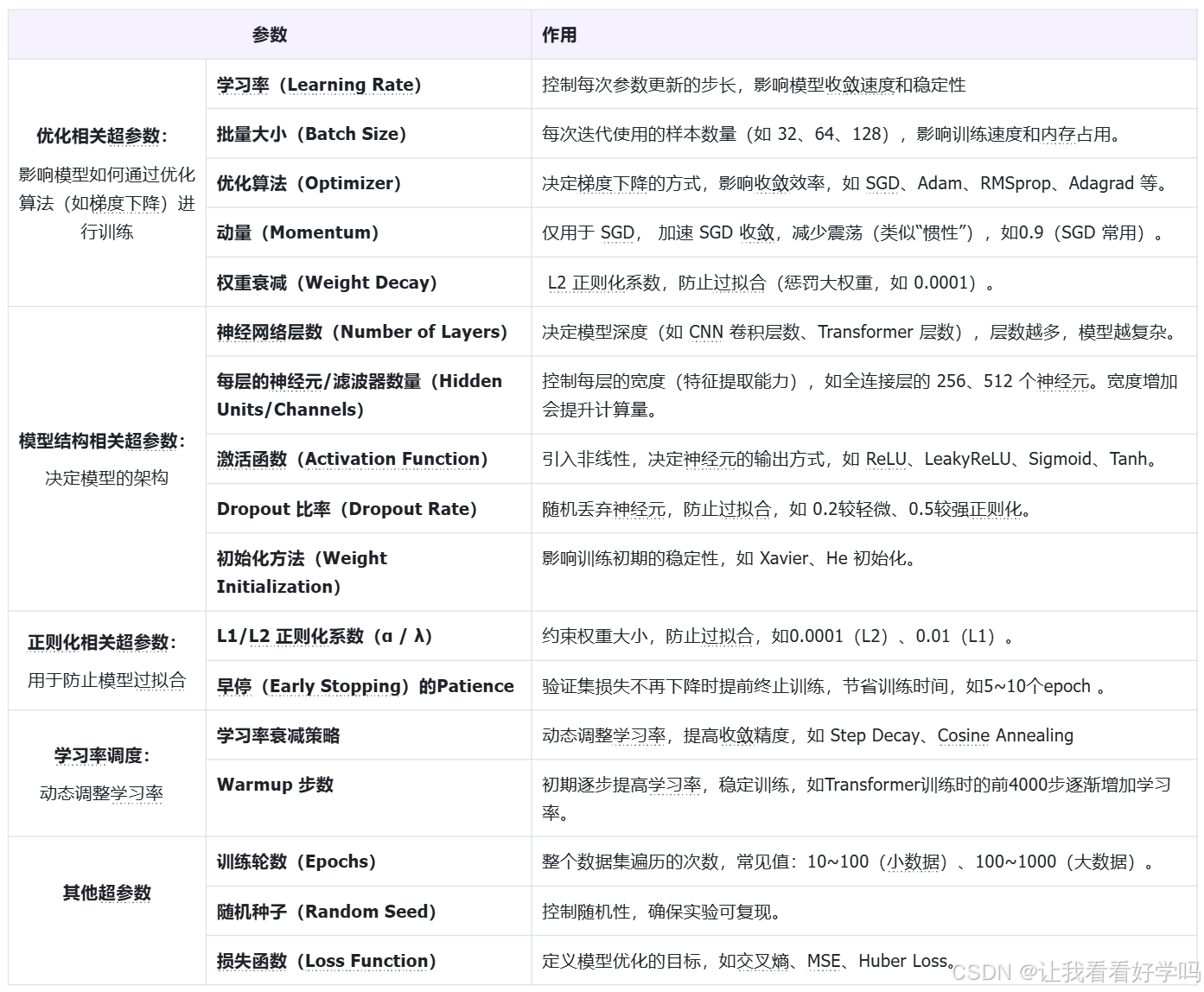
超参数是在训练之前设置的参数,就像是烹饪之前需要准备的工作,不会在烹饪过程中改变。
ps:选取一些重要超参数举例讲解。
1.2 模型参数
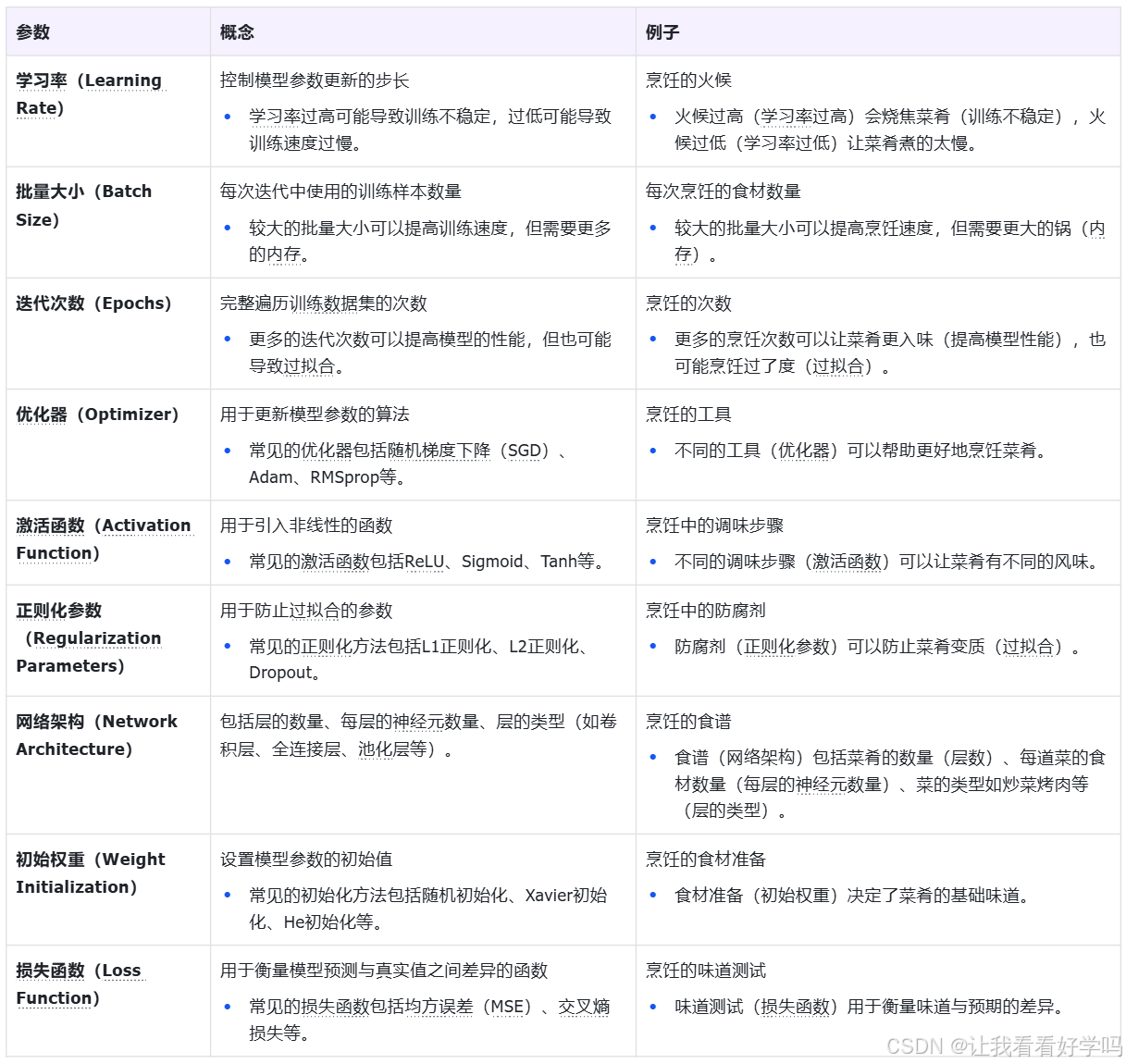
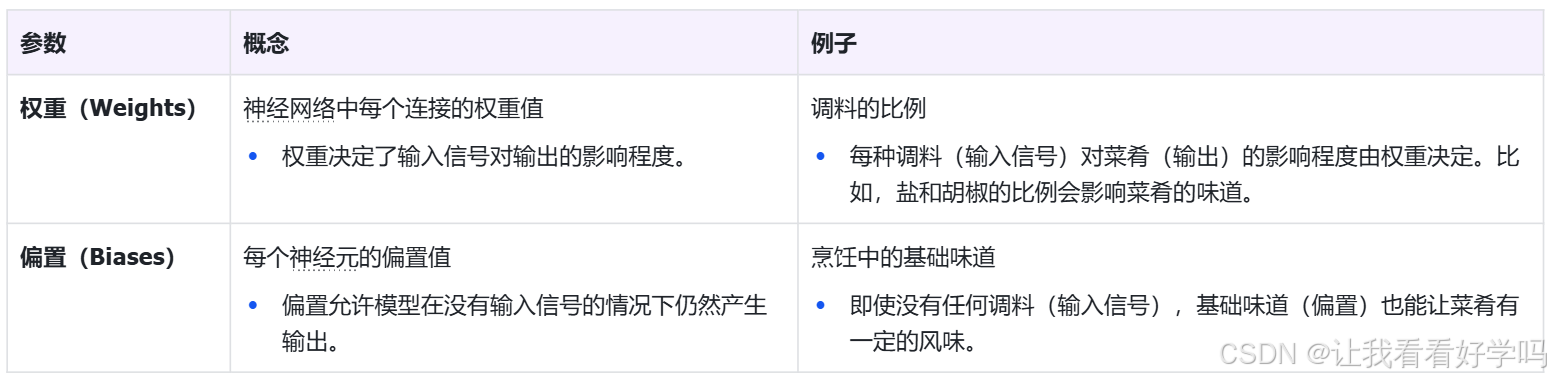
模型参数(Model Parameters)是指在训练过程中通过优化算法学习到的参数,就像是烹饪中的秘密配方,它们是通过不断尝试和调整最终确定的。
1.3 调优方法
在机器学习和深度学习的参数调优中,超参数和模型参数的优化方法是不同的,但某些方法可以同时适用于两者(例如某些自动化工具)。
1. 超参数**(Hyperparameters)调优方法**
超参数是训练前手动设定的,不通过反向传播学习,通常需要通过实验(如交叉验证)来优化。不同任务(如 CV、NLP)可能需要不同的超参数组合,经验 + 调参工具能帮助找到最佳配置。
以下方法专门用于超参数调优:
-
网格搜索(Grid Search)
-
遍历所有可能的超参数组合(如学习率 [ 0.001, 0.01 ] + 批量大小 [32, 64] )。
-
缺点:计算成本高,尤其在高维空间。
-
-
随机搜索(Random Search)
-
从超参数空间中随机采样(如学习率从 [ 0.0001, 0.1 ] 均匀随机抽取)。
-
优点:比网格搜索更高效,尤其对不重要参数不敏感时。
-
-
贝叶斯优化(Bayesian Optimization)
-
基于高斯过程或树结构(如TPE)建模超参数与模型性能的关系,主动选择最有潜力的参数。
-
优点:适合昂贵实验(如训练大型模型)。
-
-
**自动化工具(Optuna/Hyperopt/**Keras Tuner)
- 封装了上述方法(支持网格/随机/贝叶斯优化),提供统一接口。
总结:这些方法仅用于超参数(如学习率、批量大小、层数等),不涉及模型内部权重。
2. 模型参数(Model Parameters)调优方法
模型参数是训练中自动学习的(如神经网络的权重、偏置),通过优化算法(如梯度下降)更新,而非手动调优。
以下方法专门用于模型参数调优:
-
梯度下降**(Gradient Descent)及变种**
- SGD、Adam、RMSprop 等优化器,直接更新权重和偏置。
-
正则化****技术
- L1/L2 正则化、Dropout 等,通过修改损失函数或网络结构间接影响参数。
注意:模型参数不需要外部调优方法(如网格搜索),而是通过反向传播自动学习。
3. 共用方法(同时涉及超参数和模型参数)
严格来说,超参数调优方法不直接用于模型参数,但某些工具可以扩展支持:
-
自动化工具的部分功能
- 例如 Optuna 可优化超参数,但结合自定义训练逻辑时,可能间接影响模型参数的学习过程(如动态调整优化器参数)。
-
联合优化(较少见)
- 某些研究尝试将超参数和模型参数联合优化(如通过元学习),但这属于前沿方向,非主流实践。
分类总结表
|
调优方法 |
适用对象 |
示例场景 |
|
网格搜索/随机搜索/贝叶斯优化 |
仅超参数 |
学习率、批量大小、网络层数 |
|
梯度下降类优化器(SGD/Adam) |
仅模型参数 |
权重和偏置的更新 |
|
自动化工具(Optuna等) |
主要超参数,间接影响模型 |
调优超参数后,模型参数通过训练自动更新 |
关键区别
-
超参数****调优:在训练前或训练外完成,目标是找到最佳配置。
-
模型参数学习:在训练中通过优化器自动完成,目标是最小化损失函数。
2 生成式模型的参数
在生成式模型(如GPT、扩散模型等)中,生成控制参数是用户在推理阶段(inference)手动调节的超参数,用于控制生成结果的特性(如多样性、确定性、长度等)。这些参数独立于模型训练过程,仅在生成内容时(如自回归采样或迭代去噪)动态影响输出行为。”
2.1 生成控制参数概念
在自然语言处理(NLP)中和生成模型(如GPT-4o)中,有许多参数可以控制生成文本的多样性和质量。我们可以把生成文本比作举办一场派对,每个参数就像是派对上的不同元素和规则。

示例:
假设我们用GPT-4o生成一段文本,并设置不同的采样温度:
-
高温度(如T=1.5):生成的文本可能包含更多的意外和创意,但也可能出现一些不连贯或不合理的词句。
- 示例输出:The cat danced on the moon while singing a song about purple elephants.
-
低温度(如T=0.7):生成的文本可能更加连贯和合理,但也可能显得平淡和缺乏创意。
- 示例输出:The cat sat on the mat and looked out the window.
-
T=1:生成的文本直接基于模型的原始预测概率,既有一定的连贯性,也有一定的多样性。
- 示例输出:The cat sat on the mat and watched the birds outside.
生成控制参数的数学本质
生成控制参数通过修改模型输出的概率分布或采样策略间接影响结果,而非改变模型内部参数。例如:
-
温度采样:调整 Softmax 输入的 logits 尺度。
-
重复惩罚:对历史 token 的 logits 进行缩放。
生成控制参数 vs. 模型参数
|
参数类型 |
训练阶段 |
推理阶段 |
是否可学习 |
示例 |
|
模型参数 |
参与 |
固定 |
是(如权重) |
神经网络的权重矩阵 |
|
生成控制参数 |
不参与 |
动态调节 |
否 |
温度、Top-p、最大长度 |
2.2 生成控制参数的应用
|
参数 |
创意写作 文本:创意、多样性 需要丰富描述和细节的场景 |
正式文档 文本:连贯、合理性 需要简洁和明确表达的场景 |
对话系统 需平衡对话的多样性和连贯性,确保对话有趣又合理 |
|
采样温度 |
较高的温度 |
较低的温度 |
根据需求调整 |
|
Top-K采样 |
较大的K值 |
较小的K值 |
根据需求调整 |
|
Top-P采样 |
较大的P值 |
较小的P值 |
根据需求调整 |
|
重复惩罚 |
较小的惩罚因子 |
较大的惩罚因子 |
根据需求调整 |
|
最大token数 |
较大的最大token数 |
根据需求调整 |
较小的最大token数 |
典型应用场景:
1)文本生成(如DeepSeek)
调节 temperature=0.7 + Top-P=0.9,平衡创造性和连贯性。
2)图像生成(如Stable Diffusion)
调节 guidance_scale=7.5,强化文本描述约束。
3)代码生成(如GitHub Copilot)
设置 max_length=200 限制生成代码片段长度。

大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
内容包括:项目实战、面试招聘、源码解析、学习路线。
如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献429条内容
已为社区贡献429条内容

所有评论(0)