300+FPS 超高速车道检测!parsingNet 核心技术拆解
《Ultra Fast Structure-aware Deep Lane Detection》提出了一种创新的车道检测方法parsingNet,解决了传统分割方法计算量大和回归方法鲁棒性差的问题。该模型采用行锚点+网格分类的稀疏预测范式,结合全局特征和结构约束,在288×800分辨率下实现322 FPS的推理速度。
《Ultra Fast Structure-aware Deep Lane Detection》
在自动驾驶和 ADAS 场景中,车道检测是"保命级"基础任务——既要精准识别遮挡、弱光等复杂场景下的车道线,又要满足车载设备的实时性要求。但传统方法要么靠逐像素分割"慢得离谱",要么在无视觉线索场景下"频频掉线"。
2020 年发表的 parsingNet(论文名《Ultra Fast Structure-aware Deep Lane Detection》)彻底打破这一僵局:以 ResNet18 为骨干,在 288×800 分辨率下实现 322 FPS 推理,同时在 CULane、TuSimple 两大数据集上达到 SOTA 精度,成为实时车道检测的"标杆模型"。今天就来拆解它的核心设计,看懂"快且准"的底层逻辑。
一、核心痛点:传统方法的两大死穴
在 parsingNet 之前,车道检测主要分为两类方法,但都存在致命缺陷:
- 传统分割法(如 SCNN、LaneNet):逐像素分类生成车道掩码,精度尚可但计算量爆炸——单张图需处理数十万像素,推理速度低,根本无法满足车载实时性;
- 传统回归法:直接预测车道线坐标,速度略快但鲁棒性差——遇到车辆遮挡、夜间眩光等"无视觉线索"场景,就会因缺乏全局信息而丢失车道。
parsingNet 的核心思路是:换一种任务范式,用"稀疏预测"替代"稠密预测",同时兼顾全局信息与结构约束。
二、三大核心创新:快且准的关键设计
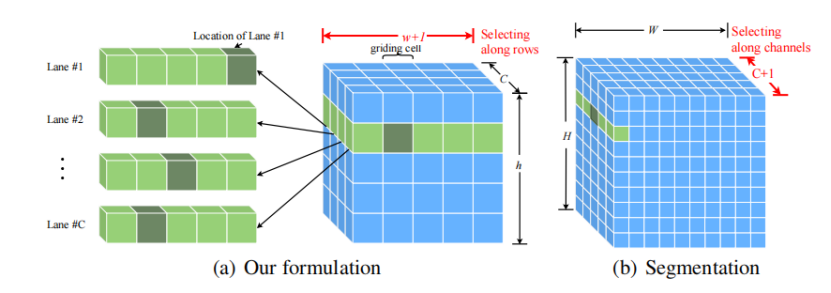
1. 任务范式革命:行锚点+网格分类,计算量骤降
parsingNet 最颠覆性的设计,是彻底抛弃"逐像素预测",把车道检测转化为"基于全局特征的行锚点网格选择任务",从根源上降低计算成本。
(1)设计逻辑:抓住车道检测的"稀疏性本质"
车道线是连续的长线结构,无需逐行预测——只需在垂直方向选取少量"关键行锚点",就能通过插值拟合出完整车道。基于这一观察,parsingNet 做了两步关键设计:
- 第一步:定义"参考基准",锁定预测范围
- 行锚点(Row Anchors):在图像垂直方向筛选关键行,避开天空、车头等无效区域。比如CULane 数据集(1640×590)的行锚点范围是 260~530 像素,步长 10,共 28 个。
- 水平网格(Gridding Cells):将图像水平方向均匀划分成若干网格,把"连续的 xxx 坐标预测"转化为"离散的网格分类"。比如 CULane 设 150 个网格,适配更宽的图像。
- 第二步:全局特征预测,直接"选格子"
用 ResNet 骨干网络提取全图全局特征,针对"CCC 条车道×hhh 个行锚点",分别预测该位置属于"www 个网格+1 个背景类"的概率。
(2)技术细节:从公式到落地的完整链路
-
核心公式与变量定义:
设最大车道数为 CCC(如 4 条)、行锚点数为 hhh、网格数为 www,全局特征为 XXX,分类器 fijf^{ij}fij 负责预测第 iii 条车道、第 jjj 个行锚点的网格概率,则预测结果为:Pi,j,:=fij(X),s.t.i∈[1,C],j∈[1,h]P_{i, j,:}=f^{i j}(X), \quad s.t. \quad i \in[1, C], j \in[1, h]Pi,j,:=fij(X),s.t.i∈[1,C],j∈[1,h]
其中 Pi,j,:P_{i,j,:}Pi,j,: 是 (w+1)(w+1)(w+1) 维向量(www 个网格+1 个背景类),对应每个类别的概率。
-
损失函数:用交叉熵损失(LCEL_{CE}LCE)优化分类结果,目标是让预测概率与真实标签(Tij,:T_{ij,:}Tij,:)对齐,总分类损失为:
Lcls=∑i=1C∑j=1hLCE(Pi,j,:,Ti,j,:)L_{cls}=\sum_{i=1}^{C} \sum_{j=1}^{h} L_{CE}\left(P_{i, j,:}, T_{i, j,:}\right)Lcls=∑i=1C∑j=1hLCE(Pi,j,:,Ti,j,:)
-
坐标解码:预测后通过"概率期望"计算具体 xxx 坐标:
先对网格概率做 softmax 归一化,再以网格索引为权重计算加权平均:Probi,j,:=softmax(Pi,j,1:w)Prob_{i, j,:}=softmax\left(P_{i, j, 1: w}\right)Probi,j,:=softmax(Pi,j,1:w)
Loci,j=∑k=1wk⋅Probi,j,kLoc_{i, j}=\sum_{k=1}^{w} k \cdot Prob_{i, j, k}Loci,j=∑k=1wk⋅Probi,j,k
最终 xxx 坐标 = (Locij+0.5)×(Loc_{ij} + 0.5) \times(Locij+0.5)× 网格的宽度 。
(3)为什么快?计算量的量级差异
预定义的行锚点数量h远小于图像高度H,网格单元格数量w远小于图像宽度W(即h≪H且w≪W)。
(4)额外优势:天然解决"无视觉线索"问题
全局特征的覆盖整图,即使某行锚点的车道被遮挡(无视觉线索),模型也能通过道路形状、相邻车道位置、车辆行驶方向等全局信息推测出网格位置——这是传统分割法无法做到的。
2. 结构损失:显式约束车道的"连续平滑性"
车道线有天然的结构先验:① 连续不跳变(相邻行锚点的位置接近);② 平滑不折线(直车道二阶变化为 0,曲线车道渐变)。parsingNet 首次提出"双重结构损失",把这些先验转化为可优化的损失函数,让模型主动学习车道结构。
(1)相似性损失(LsimL_{sim}Lsim):保证车道连续不跳变
-
设计逻辑:相邻行锚点属于同一条车道的概率分布应尽可能相似,避免出现"第 20 行在第 45 格,第 21 行突然跳到第 60 格"的跳变情况。
-
公式与实现:用 L1 范数约束相邻行锚点的概率分布差异,总损失为:
Lsim=∑i=1C∑j=1h−1∥Pi,j,:−Pi,j+1,:∥1L_{sim}=\sum_{i=1}^{C} \sum_{j=1}^{h-1}\left\| P_{i, j,:}-P_{i, j+1,:}\right\| _{1}Lsim=∑i=1C∑j=1h−1∥Pi,j,:−Pi,j+1,:∥1
其中 Pi,j,:P_{i,j,:}Pi,j,: 是第 iii 条车道、第 jjj 个行锚点的 (w+1)(w+1)(w+1) 维概率向量,L1 范数能有效惩罚分布差异大的情况。
(2)形状损失(LshpL_{shp}Lshp):保证车道平滑不折线
-
设计逻辑:直车道的"相邻行位置差"是恒定的,二阶差分为 0;曲线车道的二阶差分也应是渐变的,而非突变。用二阶差分约束,能让车道线更贴合真实形状。
-
公式与实现:基于"概率期望"得到的 LocijLoc_{ij}Locij,计算二阶差分的 L1 损失:
Lshp=∑i=1C∑j=1h−2∥(Loci,j−Loci,j+1)−(Loci,j+1−Loci,j+2)∥1L_{shp}=\sum_{i=1}^{C} \sum_{j=1}^{h-2} \| \left(Loc_{i, j}-Loc_{i, j+1}\right) - \left(Loc_{i, j+1}-Loc_{i, j+2}\right) \| _{1}Lshp=∑i=1C∑j=1h−2∥(Loci,j−Loci,j+1)−(Loci,j+1−Loci,j+2)∥1
-
总结构损失:Lstruct=Lsim+λLshpL_{struct} = L_{sim} +\lambda L_{shp}Lstruct=Lsim+λLshp,平衡分类损失与结构损失。
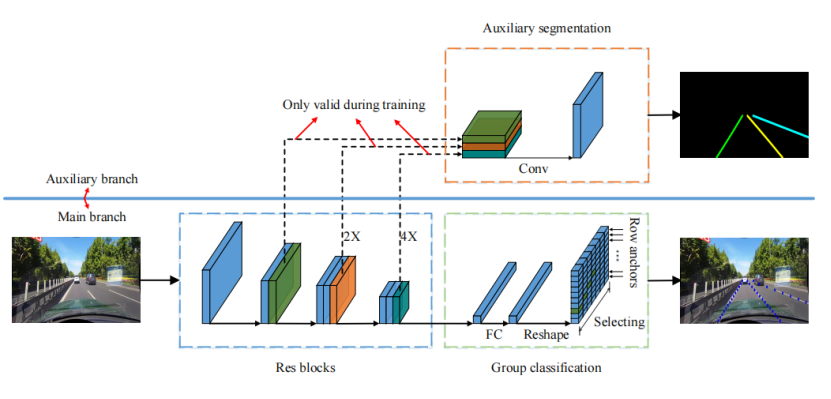
3. 辅助分割分支:训练时"加餐",测试时"隐身"
为了弥补全局特征在"局部细节"上的不足(如车道线边缘、微弱车道标记),parsingNet 设计了"辅助分割分支"——训练时用像素级监督补充信息,测试时直接砍掉,不影响推理速度。
(1)分支设计:多尺度特征+二分类分割
- 结构:在骨干网络的多尺度特征图上,添加轻量卷积模块,输出与输入图像尺寸一致的二值分割图,区分"车道线"和"背景"。
- 损失:用交叉熵损失(LsegL_{seg}Lseg)计算分割图与真实掩码的差异,作为辅助损失。
- 总损失:Ltotal=Lcls+αLstruct+βLsegL_{total} = L_{cls} + \alpha L_{struct} + \beta L_{seg}Ltotal=Lcls+αLstruct+βLseg,保证主任务与辅助任务的平衡。
(2)核心优势:不牺牲速度的精度提升
- 训练阶段:分割分支提供像素级稠密监督,让模型学习到车道线的局部纹理、边缘细节,间接提升主任务在"弱车道线""阴影遮挡"场景的鲁棒性。
- 测试阶段:直接移除分割分支,推理速度与无分支模型完全一致——相当于"训练时多学一项技能,测试时只靠核心技能干活"。
- 消融实验验证:论文 Table4 显示,在 ResNet34 骨干下,加入辅助分割分支(特征聚合)后,TuSimple 数据集准确率从 92.84% 提升至 95.64%,提升 2.8 个百分点;若同时结合新范式+结构损失+辅助分支,准确率可达 96.06%,比 baseline 提升 3.22 个百分点。
三、实验结果:速度与精度双杀 SOTA
1. 速度:322 FPS 碾压同类模型
在相同分辨率(288×800)下,parsingNet 的速度优势堪称"降维打击":
| 模型 | 骨干网络 | 速度(FPS) | 比 SCNN 快多少 |
|---|---|---|---|
| SCNN(传统分割) | ResNet50 | 7.5 | 1 倍(基线) |
| SAD(轻量化分割) | ResNet34 | 74.6 | 10 倍 |
| parsingNet | ResNet18 | 322.5 | 43 倍 |
| parsingNet | ResNet34 | 175.4 | 23 倍 |
用 ResNet18 做骨干时,parsingNet 达到 322 FPS,相当于每张图仅需 3.1 毫秒,完全满足车载设备"毫秒级"推理需求。
2. 精度:复杂场景表现顶尖
在两大权威数据集上,parsingNet 精度不输甚至超越传统分割模型:
- TuSimple(高速场景):准确率 95.87%(ResNet18)、96.06%(ResNet34),接近 SCNN 的 96.53%,但速度快 41 倍;
- CULane(城市复杂场景):总 F1 分数 72.3%(ResNet34),在"拥堵"“夜间”"曲线"等 9 个细分场景中,均优于 SCNN、SAD 等模型,尤其在"无车道线"场景下,F1 达 44.4%,比传统方法高 3-5 个百分点。
甚至在车辆完全遮挡车道的"无视觉线索"场景,parsingNet 也能靠全局信息推测出车道位置——这就是全局特征+结构约束的威力。
四、核心总结:为什么 parsingNet 成为工业界首选?
- 速度够快:300+ FPS 推理,适配车载嵌入式低算力设备;
- 精度够稳:全局特征+结构损失+辅助分割,复杂场景鲁棒性强;
- 范式够新:开创"行锚点+网格分类"范式,后续很多实时车道检测模型(如 CLRNet)都沿用这一思路。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)