LLM模型
本文系统梳理了神经网络与大语言模型的核心技术要点。首先介绍了神经网络基础概念,包括激活函数(ReLU)、损失函数(MSE)及过拟合解决方案(Dropout、L1/L2正则)。随后深入探讨了Transformer架构的关键组件:自注意力机制(QKV矩阵)、多头注意力、位置编码(RoPE)和前馈网络(FFN)。针对大模型训练优化,分析了FlashAttention的内存效率改进、MOE架构的专家负载均
基本内容
NN演化:
- 找一个近似解, 然后通过不断的给input来猜, 使近似函数逐渐逼近真实函数 -> 多项式
- 激活函数, 让近似函数可以弯一弯, 拟合目标。
- 一个激活函数不行, 就再套一层: 激活函数(线性(f(x))), 每套一层就是一个hidden layer
激活函数(非线性): relu
损失函数: |y' - y|
均方误差(MSE): 平方差/N
增加学习率: |y' - learning_rate * y|
过拟合问题:
- 简化模型复杂度
- 增加训练数据量(数据增强: 图片旋转、翻转)
- 训练结果: 提前终止、加惩罚项(把参数w作为惩罚项, 减少w变复杂的机会)
- L1 norm |w|
- L2 norm power(w)
- 损失函数 = 损失函数+lambda * norm
- drop_out: 防止模型过度依赖某一个w, 整体训练
问题
- 梯度消失: 模型越深, 梯度反向传播时会越来越小
- 梯度爆炸: 梯度数值越来越大,参数失去控制
- 收敛速度过慢:陷入局部最优
- 计算开销过大:
具体方法:
- 梯度裁剪: 防止梯度更新过大
- 残差网络: 防止深度网络的 梯度衰减
- 权重初始化: 使梯度更平滑
- 归一化: 使梯度更平滑
- 动量法/RMSProp/Adam: 加速收敛,减少震荡
- mini-batch: 巨量数据分割, 降低单次计算开销
nlp编码:
- 转成数字: 一个字-> 一个数字;问题: 维度太低了, 数字的表示毫无意义, 无法衡量词之间的相关性
- one-hot: 一个字是一个向量, 每个向量只有一个位置是1; 问题: 维度太高了, 非常稀疏, 词之间仍然找不到相关性
- 词嵌入(word embedding): 上两者的演化。 维度不高不低, 但能表示词之间相关性
- 相关性的求解:
- 点积: a · b = Σ (aᵢ * bᵢ) (i从1到n)
- 余弦相似度: cos(theta) = (a · b) / (|a| · |b| )
- word2vec
- 相关性的求解:
CNN
通过卷积核: 达到: 模糊效果、浮雕效果、轮廓效果、锐化效果
卷积核是未知的, 被训练出来的
池化层: 对卷积层降维、减少计算量、保留主要特征
思考:
为什么适用于图片:因为图片的单像素信息密度太低, 需要将几个像素点聚合, 成为一个可分析、并能够作为一个特征提取的单位。 卷积就是这个特征的单位
适用于: 静态特征: 图片
RNN/GRU/LSTM
动态特征:时间序列、文本、语音、视频
目标的场景: 给几个字的提示, 输出下一个字
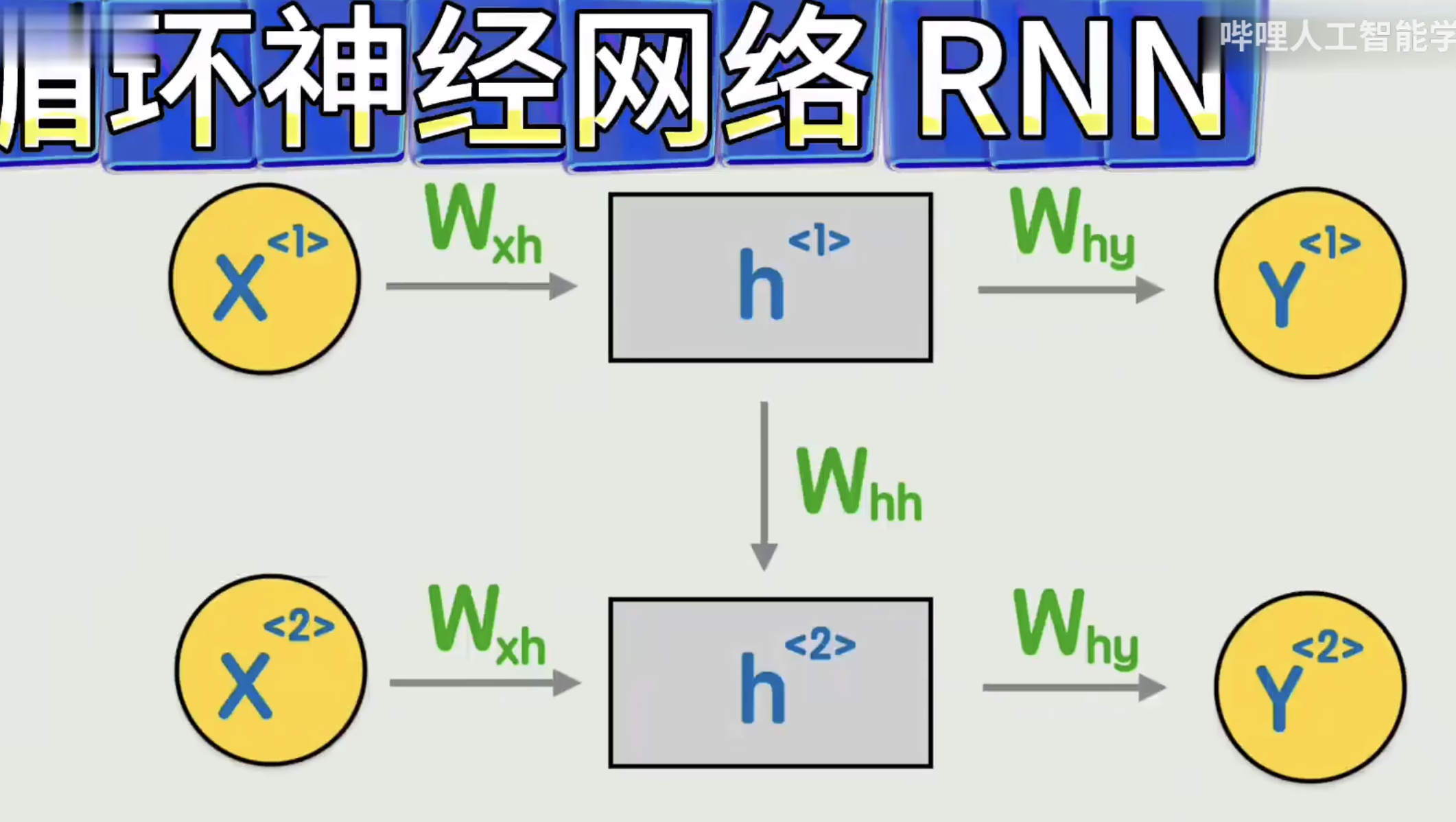
RNN
场景: 第二个词跟第一个词无法关联, 所以RNN提出,第二个词= f(w2) + H(w1)
h1 = g(wX1 + b) # w: wxh矩阵
Y1 = g(wH1 + b) # w: why矩阵
h2 = g(wX2 + wH1 + b) # w: wxh矩阵, whh矩阵
Y2 = g(wH2 + b) # 最终输出结构
总结一下:
ht = g1(wxhXt + whhHt-1 + bh)
yt = g2(whyHt + by)
问题:
无法捕捉长期依赖: 有的词离另一个很远,但有关系
无法并行计算: 必须一个算完,另一个算
GRU 公式
重置门(Reset Gate) $r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r)$
更新门(Update Gate) $z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z)$
候选隐藏状态 $\tilde{h}_t = \tanh(W \cdot [r_t \odot h_{t-1}, x_t] + b)$
最终隐藏状态 $h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t$
LSTM 公式
输入门(Input Gate) $i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)$
遗忘门(Forget Gate) $f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)$
候选记忆单元 $\tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)$
记忆单元更新 $C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t$
输出门(Output Gate) $o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)$
隐藏状态输出 $h_t = o_t \odot \tanh(C_t)$
transformer (重中之重, 反复背诵)

图片解释:
左侧为encoder, 右侧为decoder
左侧: 计算出来: K,V矩阵, 输入到右侧
右侧: 中间的输入是: Q矩阵(为什么这里是Q矩阵, 原因在于输入做了Mask, 也就是翻译任务中, mask了后面的字符, 需要给定前面的字符, 猜下一个字符了)
decoder之后: 经过一个Linear层(全连接层)线性变换,投射到词表向量中。 softmax计算概率
特点:
- 位置编码(position encoding)
- 自注意力机制
- 多头注意力
- 前馈神经网络FFN
- 堆叠编码器-解码器层实现序列建模
总体架构(编码器部分 Encoder)
编码器层的计算公式:$$ \text{EncoderLayer}(x) = \text{LayerNorm}(x + \text{Dropout}(\text{MultiHeadAttention}(x, x, x))) $$ $$ \text{Output} = \text{LayerNorm}(z + \text{Dropout}(\text{FFN}(z))) $$
其中$z$为第一个子层的输出。
训练优化技术
- 残差连接与层归一化加速收敛
- 标签平滑(Label Smoothing)提升泛化能力
- 学习率预热(Learning Rate Warmup)策略稳定训练过程
残差连接(Residual Connection)
- 残差连接的公式如下:$y = F(x) + x$
- 其中:$x$ 是输入,$F(x)$ 是神经网络的变换函数,$y$ 是输出
Bert
模型:
1. Encoder-only模型:
- 预训练的任务: MLM( mask language model: mask一部分词, 训练完猜这些词)+ NSP:
- 与原Transformer不同的结构变化
- 位置编码: 可学习的位置嵌入, 与transformer固定位置编码不同。
- 思考: 已经有一个可训练的词向量, 为什么还要加一个位置的向量?我的理解是, 词embedding与位置embedding的维度不同, 词可以有上万个, 位置embedding如bert是512长度; 维度不同会导致学习后的矩阵信息压缩的程度不同, 信息压缩覆盖的信息范围不同
- vs transformer
- 设计目标: transformer: 序列2序列, bert: NLU任务, 分类, 问答
- 上下文建模: tranformer, encoder双向, decoder单向。 bert: 全双向
- 训练范式: transformer: 端到端生成, bert: 预训练 + 微调
- 生成能力: transformer: 原生支持生成, bert: 需要后面添加decoder层?或生成head
2. transformer:
- 优点: 通用性强, decoder生成能力原生支持
- 缺点: decoder的结构导致理解能力有缺失, 计算成本高
- 发展方向: decoder-only的各种生成式模型、多模态
- 目标场景: 机器翻译、文本摘要、代码生成、对话系统
- 需要统一建模 理解 + 生成
bert:
- 优点:理解能力强 + 训练效率高 + 微调适配性好
- 缺点: 生成能力弱 + 长序列处理受限
- 发展方向:
- 优化训练策略: Roberta(动态掩码)、Albert(参数轻量化)、ELECTRA(替换检测任务)。
- 长文本增强: Longformer(滑窗注意力)、BigBerd(稀疏注意力)
- 目标方向: 纯语义理解、意图识别、信息检索、事实核查
- 效率敏感的场景(实时推荐?边缘设备上的语义分析)
尝试融合两种模式的论文: T5, UL2
层归一化(Layer Normalization)
层归一化的公式如下:$y = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta$
其中:$x$ 是输入,$\mu$ 是均值,计算方式为 $\mu = \frac{1}{H}\sum_{i=1}^{H}x_i$,$\sigma^2$ 是方差,计算方式为 $\sigma^2 = \frac{1}{H}\sum_{i=1}^{H}(x_i - \mu)^2$,$H$ 是隐藏层维度,$\epsilon$ 是防止除零的小常数,$\gamma$ 和 $\beta$ 是可学习的缩放和偏移参数,$y$ 是归一化后的输出
RMSNorm
Layer Norm -> RMSNorm
Layer Norm:
- 公式: x = (x - 均值)/标准差。 标准差 = sqrt(power(x-均值))/d + 系数 标准差里带了个小系数, 防止除0.
- 为了可学习, 加一个w和b; y = r*x + b
RMSNorm:
- 公式: x = x/rms() 。 rms(sqrt([power(x) + 小系数] /d)
- 不要均值了, 做近似归一就行了
自注意力
计算查询(Q)、键(K)、值(V)矩阵的缩放点积注意力:$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
其中\(d_k\)为键向量维度,**缩放**因子防止梯度消失。
QK相乘: 得到一个相似度系数的矩阵, query中的每一个词跟其他位置的词, 计算相关性
和V相乘: 得到一个包含上下文信息的词向量矩阵
QKV 分别表示什么
1. Q(Query,查询向量)
• 表示“我要找什么信息”
• 每个 token(例如一个词)会生成一个 Query,表示它希望从其他 token 中获取哪些相关信息。
2. K(Key,键向量)
• 表示“我能提供什么信息”
• 每个 token 会生成一个 Key,用来与其他 token 的 Query 进行匹配。
3. V(Value,值向量)
• 表示“具体要传递给对方的信息内容”
• 如果 Query 和 Key 匹配得高(注意力高),对应的 Value 就会被加权加入到输出中。
多头注意力
(给多次机会, 从n个不同角度的向量)
并行执行多组自注意力计算,增强模型捕捉不同子空间信息的能力:
多头注意力机制公式(拼接各个头, 并*全连接层):$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O $$
每个注意力头的计算方式为:$$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$
$W_i^Q \in \mathbb{R}^{d_{\text{model}} \times d_k}$,$W_i^K \in \mathbb{R}^{d_{\text{model}} \times d_k}$,$W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v}$,$W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}}$,$h$:注意力头的数量
每个注意力头独立学习不同表征模式。
MHA/MQA/GQA学习:
MHA:
Multi-Head Attention: 标准注意力, 每个注意力头的组成是标准attention
问题: 越往每一个字的后面计算, 发现后面的字只用到了前面的KV, 空间换时间 , 所以缓存了每一个KV Cache
FlashAttention
FlashAttention1 (2022): 比传统attention快2-4倍
1. 将 Q/K/V 按 GPU 缓存容量分块,避免存储中间结果(如注意力矩阵),显著降低内存占用。计算过程中采用重计算(recomputation)策略,减少显存需求。
注意这里: 计算 QK^T、softmax 和乘 V 的过程中分别调用多个 kernel
2. 同时通过nvidia cuda 融合内核(kernel fusion)减少内存读写操作,提升计算吞吐量。
提升:
- 速度提升:相比传统注意力实现,训练速度可提升2-4倍。
- 显存节省:内存占用O(N2)降低为线性复杂度(O(N)),支持更长序列处理。
- 精度保留:通过数值稳定化技术(如缩放),保持与标准注意力相同的模型精度。
FlashAttention2 (2023年): 比flashattention1 快2倍
- FlashAttention的分块和nvidia融合内核都支持
- 计算修改:
- FlashAttention 2 将 QK^T→softmax→×V 三步全部融合在一个 CUDA kernel 中完成,无需中间写入 global memory,代码也更工程化。
- 反向传播阶段,使用minimal FLOPs版本kernel,减少非matmul FLOPs,仅重建需要反向链条的部分。
- 改进线程块划分:
- 调整块大小,通常设置为{64, 128} × {64, 128}时效果较佳。
- 同时,优化线程块内循环顺序,在前向传播中将Q设为外循环,KV设为内循环,使每个warp无需同步等待,加快运算。
vs v1:
- v1 在序列维度并行 (每个线程块处理一个序列位置)。Qi
- v2 在序列维度切分块 (Tile),在块内并行计算。Q[block]
- 效果: 将计算密集型操作 (如矩阵乘法) 集中在一起,减少了对高带宽显存的访问次数和同步开销。
FlashAttention3(2024)
- 将分块计算和重计算融合成一个单一的操作符。效果: 避免了在分块计算中反复加载/存储中间状态的开销,进一步减少了显存访问次数。
- 芯片从FlashAttention2适配的A100 转为H100, Hopper架构?, 所以适配了新算子?
总结
- v1: 革命性地解决了显存瓶颈 ($O(N^2) \to O(N)$),通过分块计算和重计算。
- v2: 在 v1 基础上,优化算法流程和并行策略,减少非矩阵乘法开销,提升速度。Qi -> Q[block], 一个block的attention放一个kernel里完成
- v3: 引入新的计算范式 (融合分块与重计算),进行更深度的硬件感知优化,追求极致性能。
一些没用的碎碎念:
H20:
- 显存最大、带宽最高?所以deepseek,用KV缓存策略?
- Hopper架构, 比A100架构好一点。
- 支持多实例GPU技术(讲一个GPU画成多个实例)。 比H100砍掉RT Core。图像缺功能、安全缺功能
A100训推均衡, 能耗还可以。 Ampere架构
H100:极致性能
芯片显存: SRAM(计算最快最小)、HBM(带宽最大, 传输最快)、DRAM(便宜)
MQA:
- 场景: 用于解决KV cache的体积过大的问题
- 保留一个: 只保留一个KV并可以共享: 第i个查询头公式:
GQA:
- 场景: MQA,KV只有一个, 提取的特征缺失
- 处理: 几个头 group共享一个KV
MLA
策略1(投影矩阵):
- 场景: GQA的KV 是Xi的直接投影、再复制、在分割,(硬切分损失语义)
- 处理: KV都基于ci(简单理解成子kv)生成?
策略2: dot-attention 的恒等变换;
- 场景:策略1 导致问题: 会导致KV反而变大?
- 处理:
- 训练阶段照常。 推理阶段: qk = (x*wq) * (ci* wk).transpose() = x(wq * wk.transpose()) * ci.transpose()
- (wq * wk.transpose()) 变成新的query投影阵, ki: ci.transpose()
- 没太搞懂。 反正就是k、v都可转换为一个对ci的存储的计算
- 附带问题: 当MLA+ RoPE 且RoPE放到attention里 + 相对位置编码(作为一个变量在Q* K中),这个位置开始对前一个位置有依赖了。 不能保证相对位置不变(RoPE目标)
- 解决方式: Q、K新增一些维度用于跟RoPE
策略3:
- 问题: 模型训练时的显存占用来自于两部分: 模型参数(静态, 各种w), 激活值(动态, 各种激活函数弄出来的中间值)。要减少激活值占的显存。
- 解决方式: 对Q做低秩投影
FFN
Position-wise Feed-Forward Networks
前馈网络公式:$$ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $$
参数说明:$W_1 \in \mathbb{R}^{d_{\text{model}} \times d_{ff}}$,$W_2 \in \mathbb{R}^{d_{ff} \times d_{\text{model}}}$,$d_{ff}$:内部隐藏层维度(通常为2048)
MOE
重点视频
架构:
- FFN层前加一个router: FFN+ softmax, 可以输出多个expert的概率
- FFN层换成MOE层。 FFN切成几个group, 每个group是一个专家。 N.B.: 注意每一个decoder 层的FFN都是MOE专家
- 聚合结果: F(MOEs), 加权求和
- 每层专家的组合是一个path
演变: 大参数少专家-> 小参数多专家, 有负载均衡问题。 现在的趋势是看怎么解决负载均衡问题
小参数多专家优点:
- 计算效率更高、扩展性更强、部署成本更低
- 更高参数量、推理成本低、任务适配性高
问题: 有些专家算的慢, 有的快。 模型倾向于选算的快的
均衡负载(load-balancing)处理:
- 加噪声: output = x * weight + N。 N指Gaussian noise,某些专家使唤太多了,就给他点噪声, 让别的能训练
- keep top-k: output 选前top-k个专家
- 加个loss: 生成一个专家重要性系数矩阵CV(加总每个专家的调用次数), 加到loss上, 作为惩罚? (辅助损失 Auxiliary Loss)
- 最后生成一个CV * weight(weight训练完后负责均衡)
- 专家容量(expert capacity): 限制每个专家能处理的token数,硬逼专家不工作
位置编码(需要解决的问题: 1.位置需要数值化可计算 2.位置的含义应该是相对的 3.没见过的位置如何编码 4.使编码可训练?)
固定位置编码(transformer里 使用sin来做编码。 硬编码, 不能修改):
采用正弦位置编码注入序列顺序信息:$$ PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{\text{model}}}) $$ $$ PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}}) $$
其中:$pos$:位置序号,$i$:维度索引,$d_{\text{model}}$:模型维度
Bert:可训练的编码。
问题: 对没见过的序列长度泛化能力差
相对位置编码:
- 将相对位置信息直接注入注意力计算,使用可学习的嵌入表编码相对距离。
- 公式: Attention 公式中的qk -> qk + qr. r是相对位置
RoPE 旋转位置编码
- 将绝对位置信息融入自注意力机制中的键和查询向量。使得模型能够捕捉相对位置关系。
- 其核心思想是对位置信息进行旋转操作,
- 具体实现中,每个位置通过复数域的旋转矩阵变换,将位置编码与词向量相结合。
- 优势: 能够保持相对位置不变性,同时支持任意长度的序列扩展。
数学表达上,给定位置$m$和$n$,查询向量$q_m$和键向量$k_n$的注意力分数计算为: $$ \text{Attention}(q_m, k_n) = (q_m e^{im\theta})^T (k_n e^{in\theta}) = q_m^T k_n e^{i(m-n)\theta} $$ 其中$\theta$为旋转角度参数,$i$为虚数单位。
激活函数:
1. 传统激活函数(基本不用了)
|
激活函数 |
特点 |
|---|---|
|
Sigmoid |
易饱和、梯度消失;不再用于深层网络。 |
|
Tanh |
比 sigmoid 好,但仍易梯度消失。 |
|
ReLU |
目前最经典;计算简单;但会有 “ReLU 死亡” 问题。cv很有效, nlp不行 |
|
Leaky ReLU |
减少死亡 ReLU,负区间给一点斜率。 |
|
PReLU |
leaky 斜率可学习。 |
2. 平滑类 / 优化类激活函数
|
激活函数 |
特点与用途 |
|---|---|
|
GELU |
Gaussian Error Linear Unit;光滑 ReLU;Transformer 系列最经典。 |
|
Swish |
x * sigmoid(x),Google 提出的;性能好。 |
|
SiLU |
swish 的另一个名字(Pytorch 名称)。 |
|
ELU / SELU |
比 ReLU 更平滑,但不用于 LLM。 |
3. 支持大模型稳定训练的激活函数
|
激活函数 |
特点 |
|---|---|
|
GLU (Gated Linear Units) |
有门控机制;经常用在 LLM 中。 |
|
SwiGLU |
swish + GLU;现在最主流 LLM 激活函数。 |
|
GeGLU |
gelu + GLU;性能强,部分 LLM 使用。 |
|
ReGLU |
relu + GLU;也有使用,但较少。 |
公式: (todo)
结论:现代主流大模型(GPT-4 / GPT-4o / Qwen2 / LLaMA3 / Mistral / Claude3 / Baichuan2 等)几乎都使用 GLU 家族,特别是 SwiGLU。
原因:
-
收敛更稳定,梯度更平滑
-
在 Transformer FFN 中更强表达能力
-
训练巨型模型(>10B 参数)时更稳定
-
比 GELU 实测能提升 2–5% 任务性能
-
计算量不大,适合大模型
优化器
类型
1. 经典优化器
|
优化器 |
特点 |
|---|---|
|
SGD |
最基础;收敛稳定但慢。 |
|
SGD + Momentum |
加速收敛、减少震荡。 |
|
Nesterov Momentum |
更快的动量版本。 |
2. 自适应学习率(Adaptive)优化器
这些是深度学习主流:
|
Optimizer |
特点 |
|---|---|
|
Adam |
最经典;适合 NLP;收敛快。 |
|
AdamW |
Adam + decoupled weight decay;🔥 成为最常用优化器。 |
|
RMSProp |
更适合 RNN;现在少用了。 |
|
Adagrad |
老牌;学习率随时间下降。 |
|
Adadelta |
Adagrad 改进版。 |
3. 面向大规模训练的新型优化器
|
Optimizer |
特点 |
|---|---|
|
LAMB |
可训练 100B+ 参数,适合大 batch。 |
|
LARS |
ResNet、CNN 用的多;大 batch 稳定。 |
|
Adafactor |
节省显存;T5 默认优化器。 |
|
Lion(2023) |
比 Adam 更省显存,优化效果好(By Google)。 |
|
Sophia-g(2023) |
用二阶 Hessian 信息;训练 LLM 更快。 |
LLM使用的优化器
结论:现今几乎所有主流 LLM 都使用 AdamW(含特定变体,如 Decoupled Weight Decay + Warmup)。(0.9, 0.95))
选AdamW原因
1. 收敛稳定
-
对深层 Transformer 友好
-
对稀疏梯度、长序列非常稳
2. 权重衰减与 Adam 解耦
减少 overfitting,训练更平滑。
3. 对超大模型更 robust
LLM 往往训练几万亿 tokens,AdamW 更可靠。
4. 实现成熟、高效
如:
-
FusedAdamW(NVIDIA)
-
DeepSpeed ZeRO 优化器
生态完善。
有哪些新优化器在挑战 AdamW?
1. Lion(Google 2023)
-
优势:更少内存,更快训练。
-
部分开源 LLM(如 Pythia)开始尝试,但仍不是主流。
2. Sophia-g(2023)
-
利用 Hessian 近似,二阶信息优化
-
在 LLM 训练中加速效果明显
-
学界关注度高,但工业界采用较少
3. PagedAdamW(DeepSpeed)
-
针对大模型分布式训练
-
更省显存
推理加速:
vllm
重点视频:
https://www.bilibili.com/video/BV1kx4y1x7bu?t=27.2![]() https://www.bilibili.com/video/BV1kx4y1x7bu?t=27.2
https://www.bilibili.com/video/BV1kx4y1x7bu?t=27.2
出现的目的: 为了处理attention机制中, KV cache缓存导致的碎片问题
具体策略:
Page Attention(os: 处理内存碎片):
- 把预分配一大块(不知道未来要生成多少个字, 所以按最大字数分配) -> 变成切成一个块, 按需分配, 不提前占用
- 虚拟内存: 逻辑和物理存储弄个映射表
KV blocks的共享, share KV :
- 场景: 一个prompt想生成多个output ? 不知道这个是咋用。 Beam Search场景
- 解决方式:blocks设一个引用计数器, 被引用实现一次, 计数-1。如果剩余计数是1, 说明直接用就行。 如果> 1, 复制一份再用
成果:系统可以吞吐更大的batch_size
代码:
from vllm import LLM, SqmplingParams
sampling_params = SamplingParams()
llm = LLM (model =')
output = llm.generate(prompts, sampling_params)主流大模型核心信息对比表
| 架构 | 调优特性 | 算法结构 | |
| GPT-4 |
openAI |
1. 核心为多头自注意力机制,精准捕捉序列中局部与全局依赖关系; 2. 采用多层 Transformer 堆叠设计,每层包含自注意力模块与前馈神经网络模块; 3. 通过残差连接与层归一化优化训练稳定性,提升模型收敛效率。 |
|
| LLaMA 3 | 预训练中,覆盖多语种, 适合多语种微调 |
基于 Transformer 架构, Grouped-Query Attention(GQA),多个注意力头共享相同的键和值投影,减少内存使用,降低模型参数量,在推理期间也能减少键值缓存(KV cache)的内存带宽使用。 |
|
| 百川 | 百川智能 | ||
| 文心一言 | 百度 | ||
| 通义千问 | 阿里 |
基于 Transformer 架构, 旋转位置嵌入(RoPE)等技术,长文本优秀 Grouped-Query Attention |
|
| DeepSeek-V3 |
以 DeepSeek-V3 为例, 采用多头潜在注意力(MLA)和专家混合(MoE)架构。 MLA 将键和值张量压缩到低维空间后存储到 KV 缓存中,推理时再投影回原始大小,可显著减少内存使用量,且性能优于传统的多头注意力(MHA)。 MoE 则是将 Transformer 块中的每个前馈模块替换为多个专家层,由路由器为每个 token 选择一小部分专家处理,DeepSeek-V3 有 256 个专家,推理时每次只激活 9 个专家,其中包括 1 个共享专家。 |
微调工具:
在线平台
离线工具: llama factory ,ms-swift
python库: tr1
llama Factory: (todo)
- 框架特性:
- 模型种类: LLaMA, Qwen
- 训练算法: (增量)预训练, (多模态)指令监督微调,奖励模型训练, PPO训练, DPO训练, KTO训练, ORPO训练
- 运算精度: 16bit全参微调、冻结微调、LoRA微调、基于AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的2/3/4/5/6/8 bit QLoRA微调
- 优化算法: GaLore、BAdam、DoRA、LongLoRA、LLaMAPro、Mixture-of-Depths、LoRA+、LoftQ和PiSSA
- 加速算子: FlashAttention-2 和 Unsloth
- 推理引擎: Transformers 和vllm
- 实时监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab
数据集格式:
- Alpaca: (instruction, input, output)
- ShareGPT (messages role, content)
算法
使用标注数据直接进行微调
LoRA(todo)
一些思考:
Lora/ PCA:
- 都是在尝试解决线性空间中一组wb与另一组wb不是线性独立的
- 通过扔掉这些没用的wb, 降低复杂度, 减少计算量
使用tr1 & swift
unsloth
强化学习RLHF: 各种PO(todo): PPO, PRO, DPO, GRPO
指令微调
闲聊
热词:
- temperature: 控制随机性, temerature升高, 随机性升高, 使模型生成下一个词并不是之前概率最高的那个词
- top-k: 使模型从概率最高的top-k个值里做选择
幻觉:
- 问题原因:
- transformer本身是一种预测下一个词概率的模型, 本身没有逻辑性,
- 所以进一步分析: 语料本身,没这个内容, 或者频率不够大
- 解决方式:
- context里加上检索信息, 拼起来发给大模型。
- 两种方式: 拼上搜索引擎的公开答案 or RAG( 使用公司内部信息。文字 -> embedding -> 上向量数据库中搜索(向量检索))
llm 发展快到极限
- 模型大小到极限: 一个顶级大模型, 训练成本1亿美元
- 模型能力到极限: 顶级模型间能力差距越来越小, 2023年顶级模型间差距12%, 2025年5.4%. 前两名4.9% -> 0.7%
所以开始卷其他方向:
- 模型压缩:
- 量化、
- 蒸馏: 大模型教小模型
- 剪枝: 去掉不重要的神经元
- Lora、Qlora、adapter: 更低成本微调
- 推理方向: CoT, 思维链
- RLHF: 人类反馈强化学习
- 套壳: 封装并提供服务
- 周边: 卖铲子
NLP: ChatGPT、Claude、Gemini、 DeepSeek、豆包、通义千问、腾讯元宝
CV: Midjourney, Stable Diffusion, ComfyUI(会话工作流?)
文本转语音: TTS
语音转文字: ASR
视频: Sora、Kling、即梦
数字人:
GPU
TPU: 专门针对人工智能训练、推理
NPU: 终端设备推理, 终端加速芯片
AI编程助手 :
软件: cursor
插件: Github Copilot

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)