大模型应用开发-Langchain(V1-最新版)-上
大模型应用开发-langchain(V1最新版)-上部分
一 结构
1.1 langchain-core
Langchain核心包,定义了基础抽象接口,和最基础Langchain整体运行的依赖
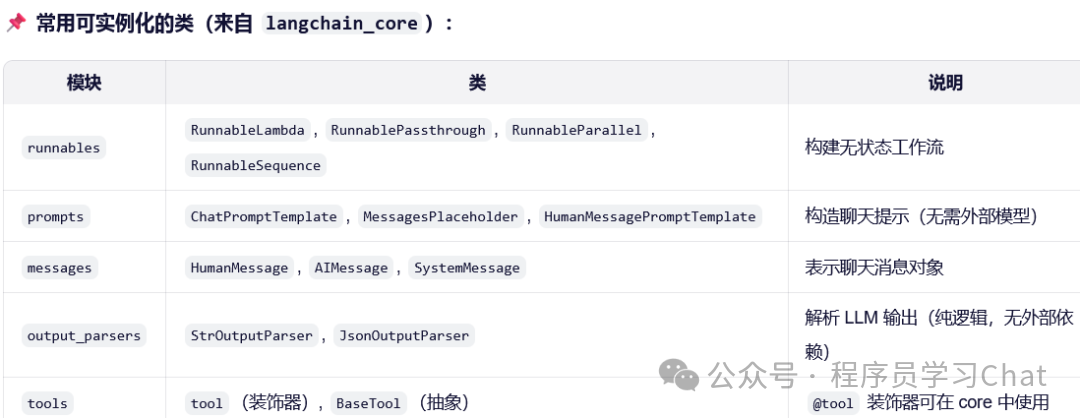
可实例化类说明
Langchain_core.runnables
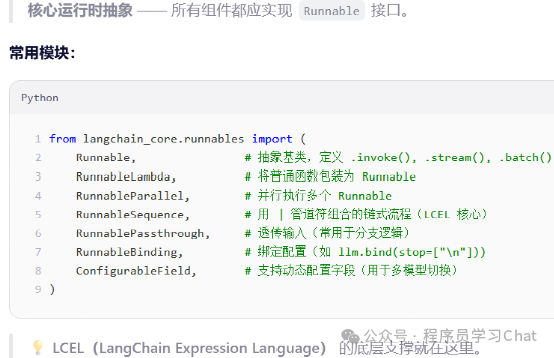
Langchain_core.message
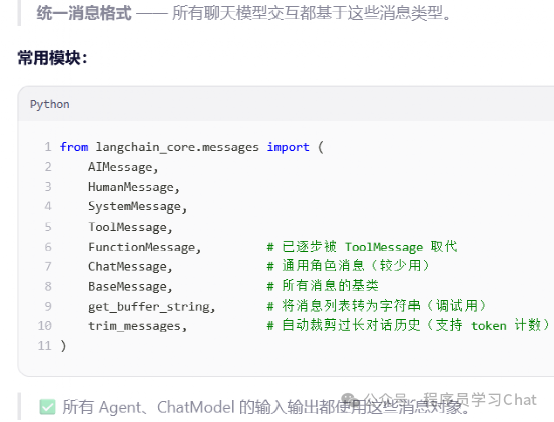
Langchain_core.prompts
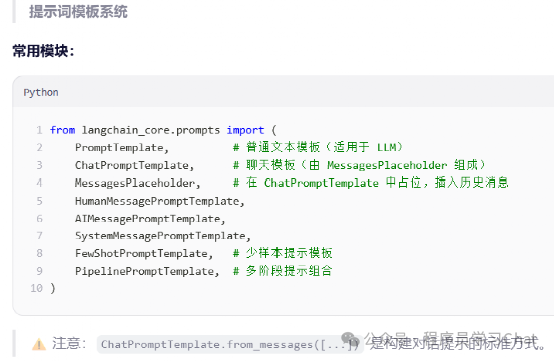
Langchain_core.tools
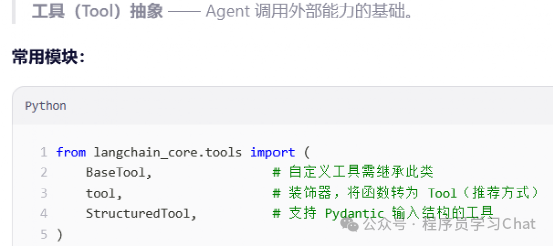
Langchain_core.ouput_parsers
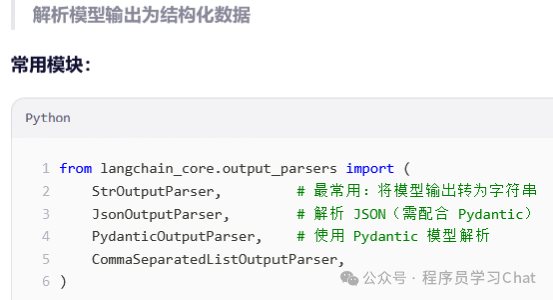
Langchain_core.documents
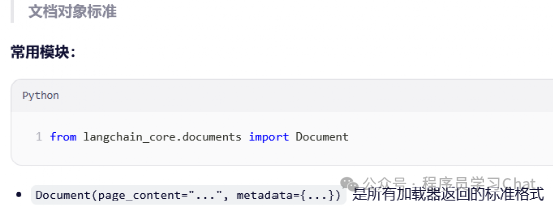
抽象接口类说明
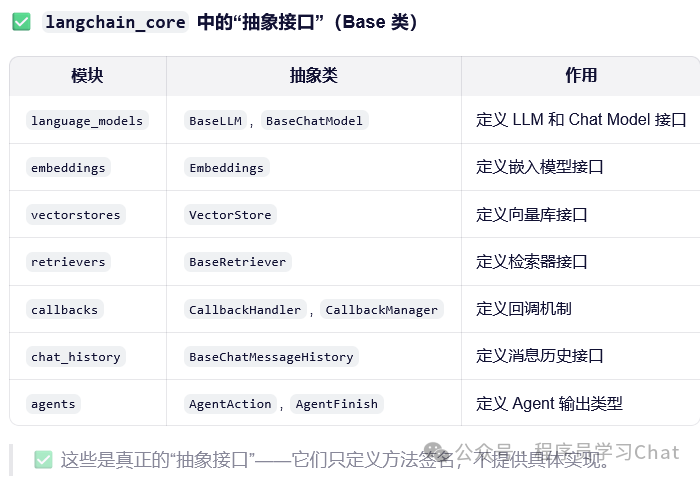
Langchain_core.language_models
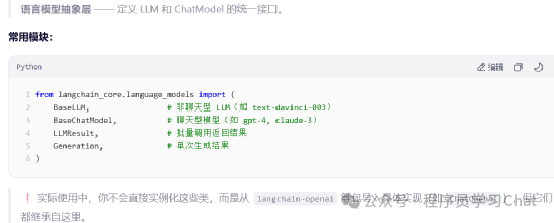
Langchain_core.embeddings
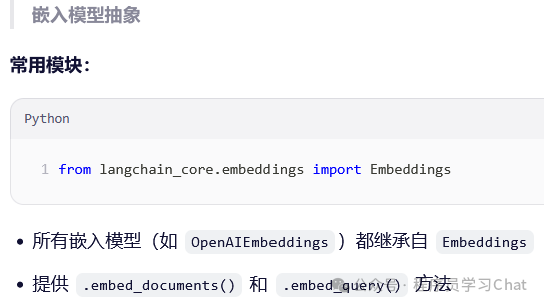
Langchain_core.vectorstores
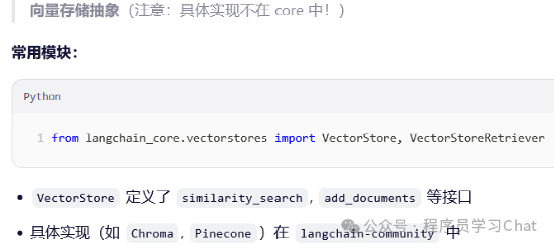
Langchain_core.retrievers
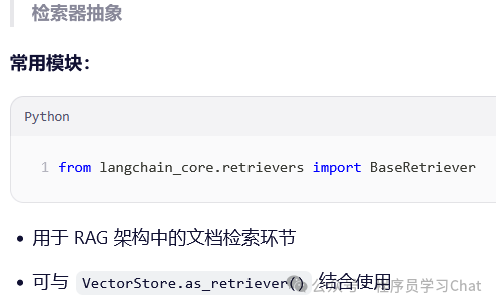
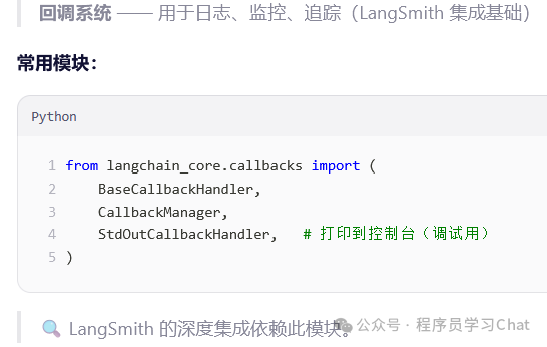
Langchain_core.callbacks
Langchain_core.agents

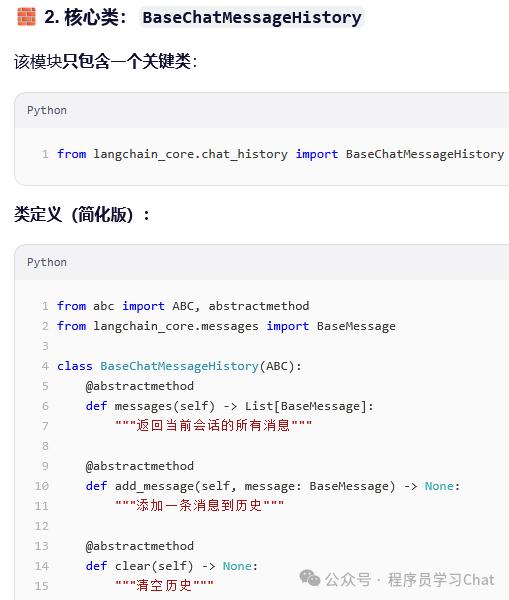
Langchain_core.chat_history
langchain_core.chat_history 的核心作用是为“对话历史”提供统一的抽象协议,使任何 Runnable 链能以标准方式读写消息历史。
1.2 langchain-community
LangChain 中集成所有第三方功能实现的核心包。

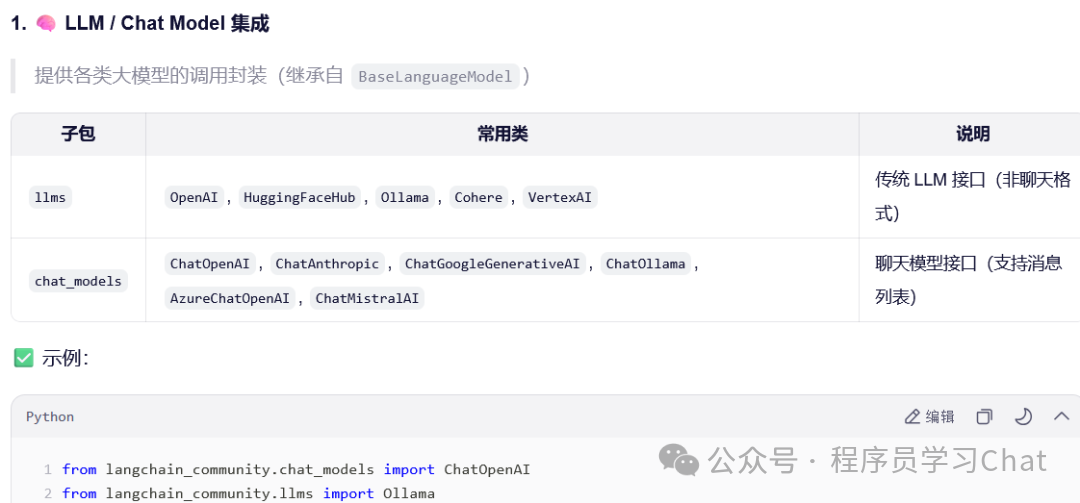
大模型集成

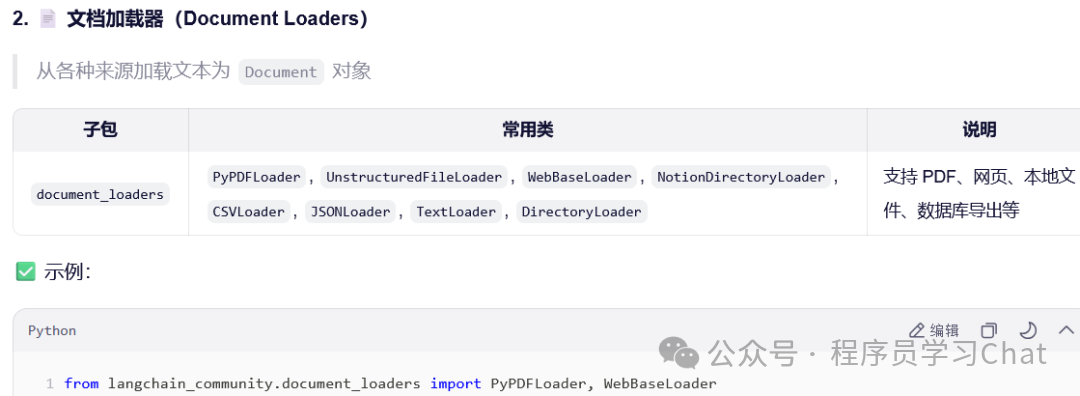
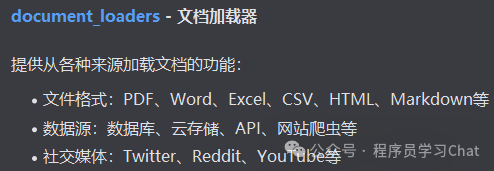
文档加载器
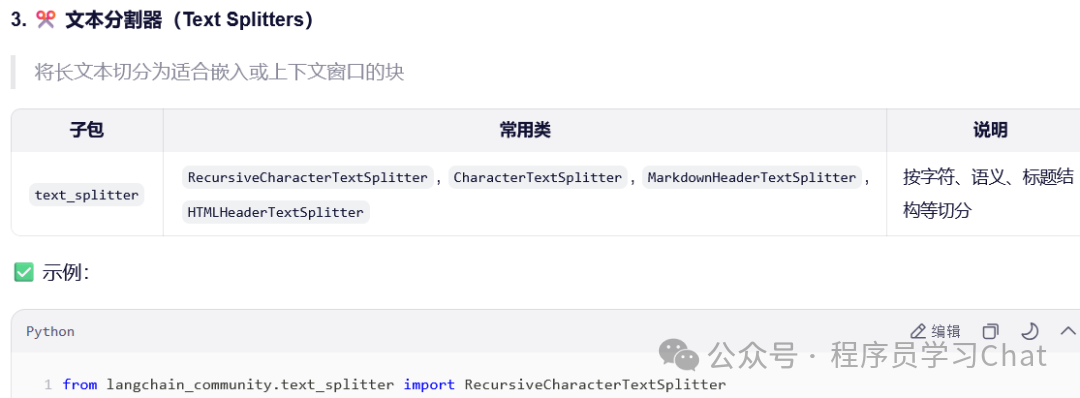
文本分割器
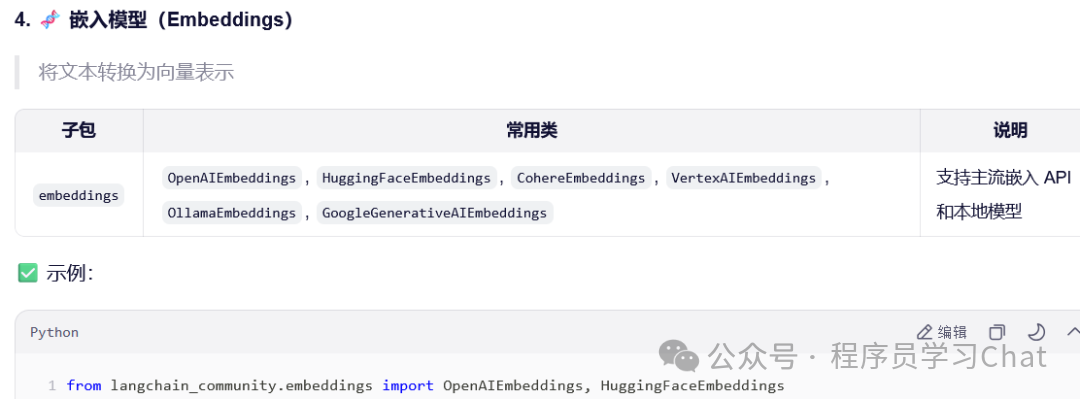
嵌入模型

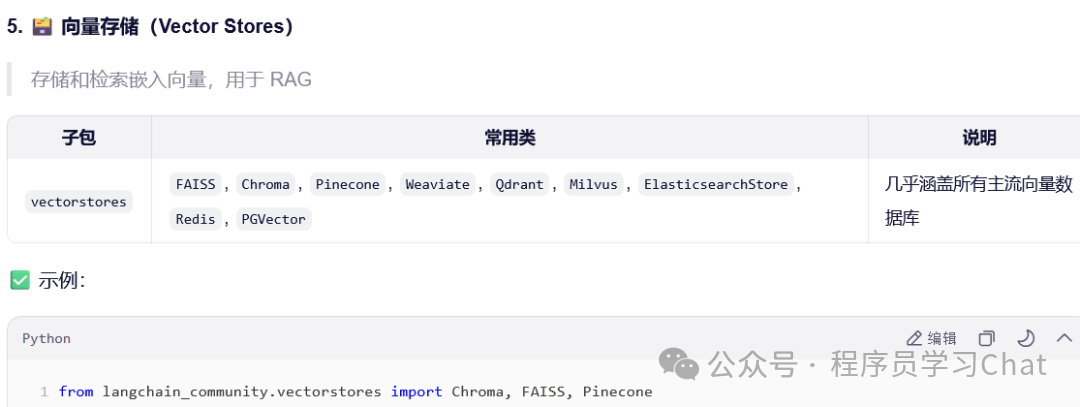
向量存储
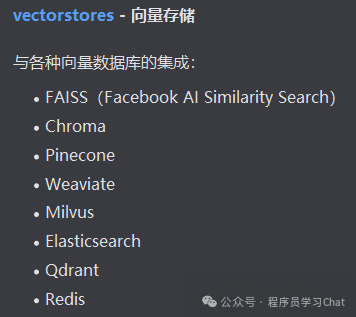
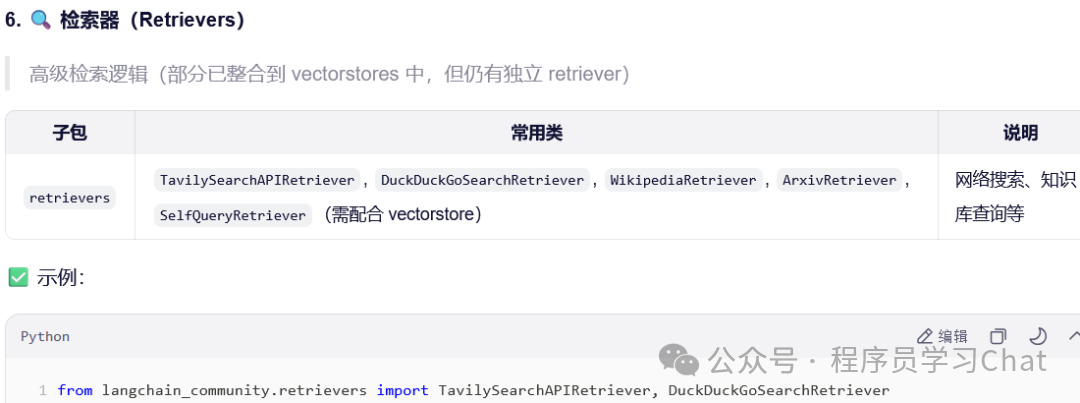
检索器
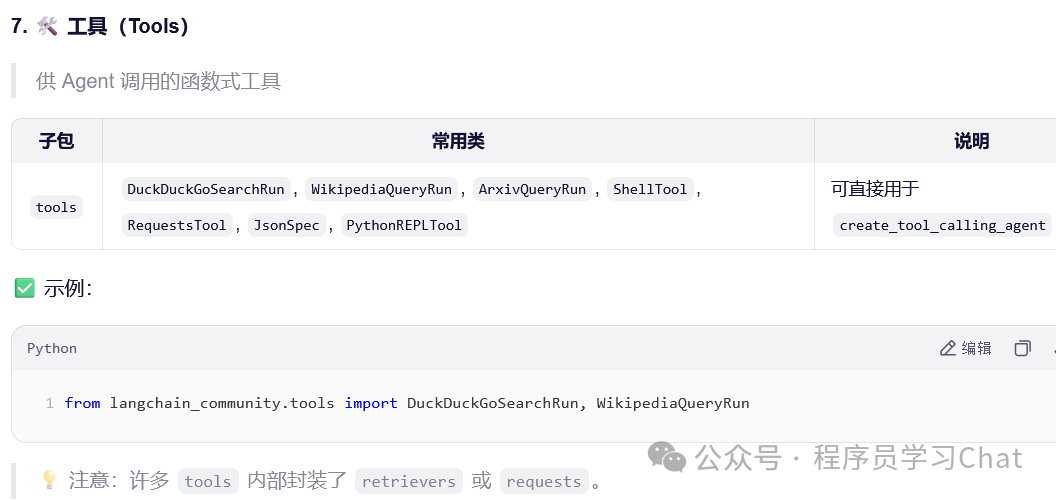
工具

数据库连接

工具
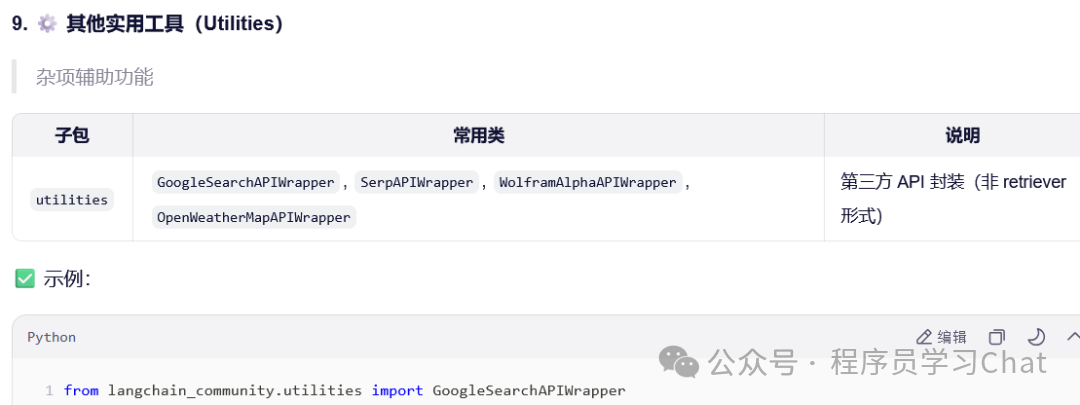
1.3 整体架构



二 模型IO
2.1 大模型接入
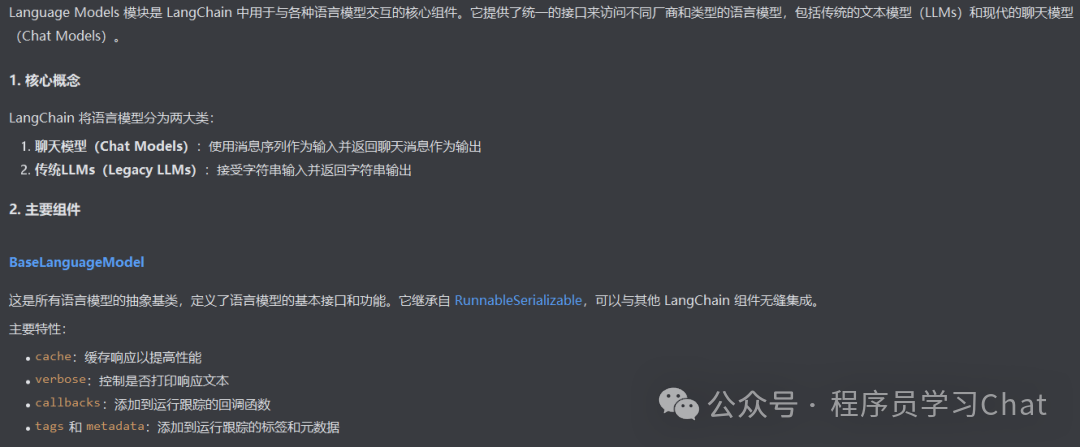
Langchain将所有的大模型分为两类:
1)llm:输入文本,输出文本的模型
2)Chat Model:支持多轮对话的模型
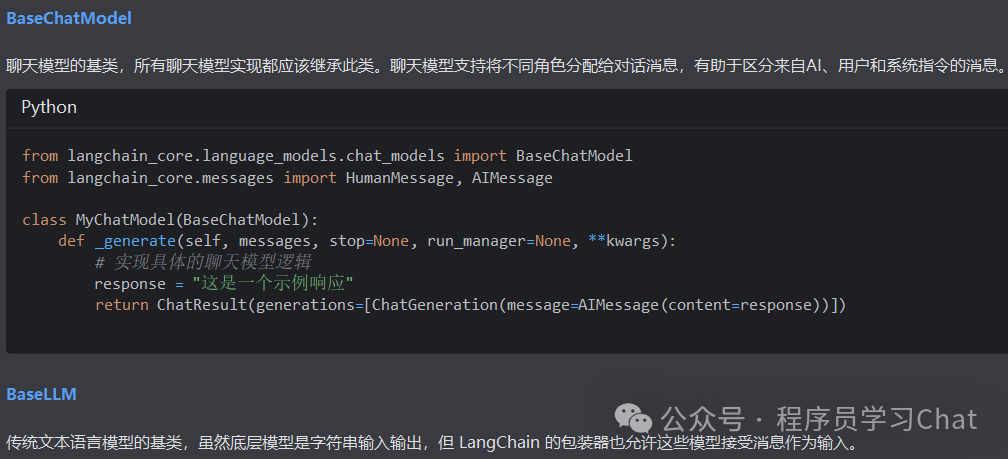
Lanchain_core中的抽象
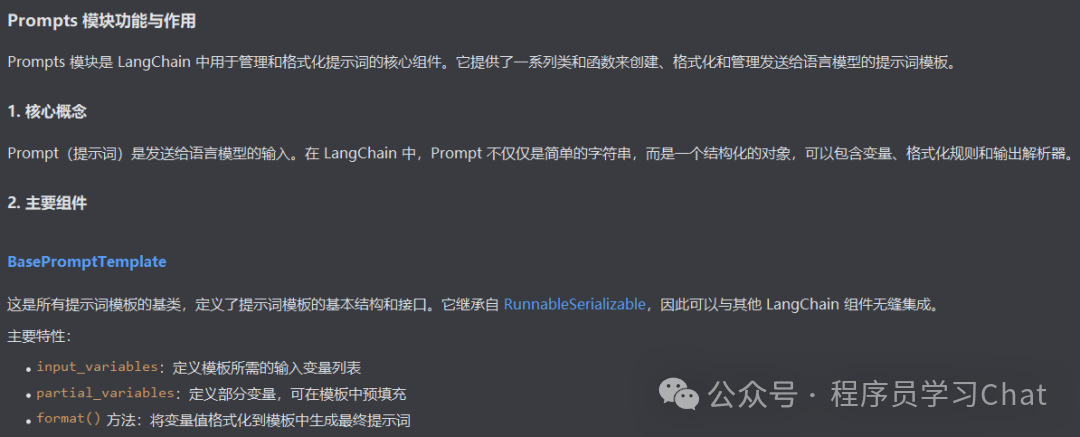
2.2 模型输入
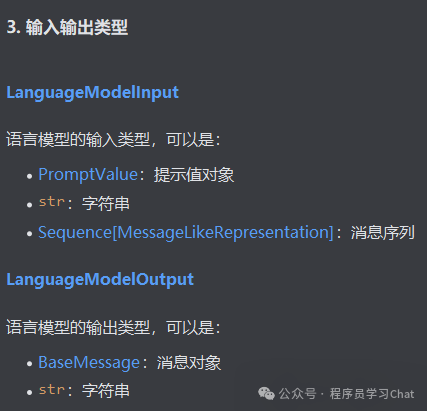
Langchain_core中的抽象
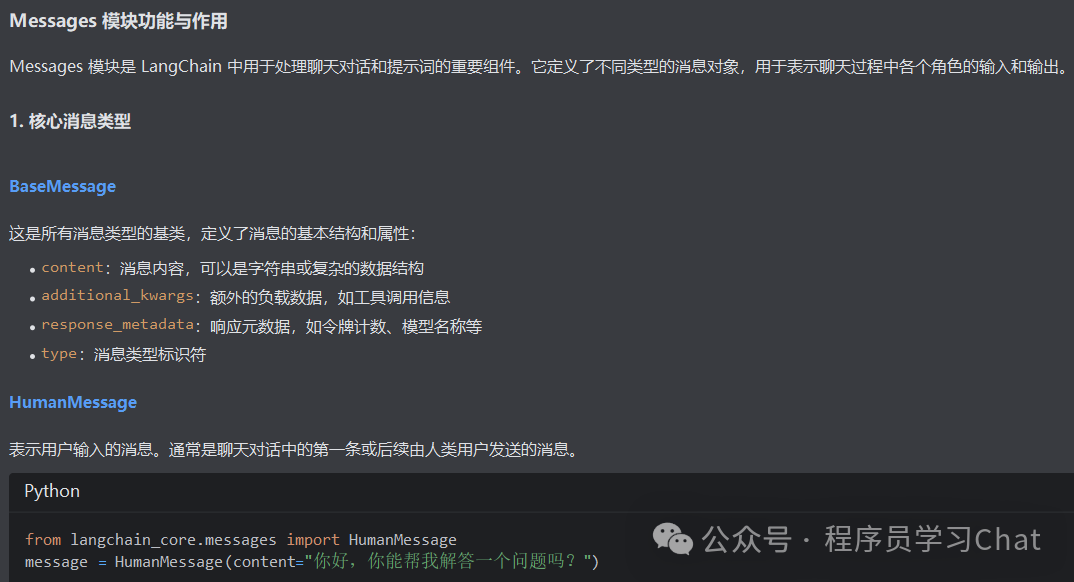
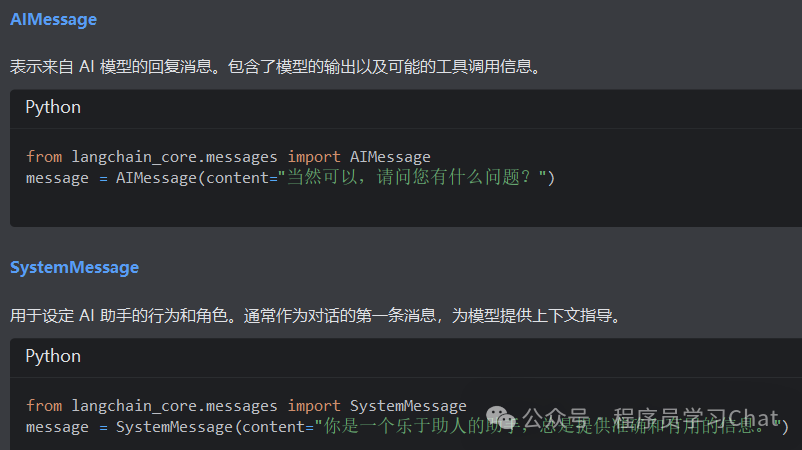
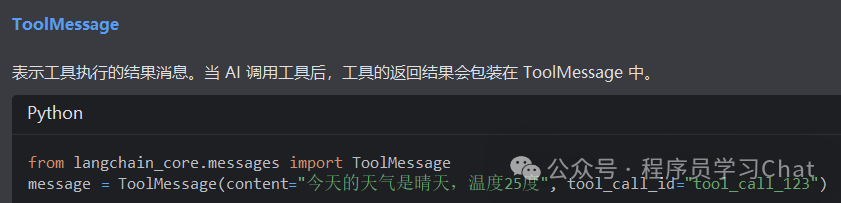
Message

Prompts
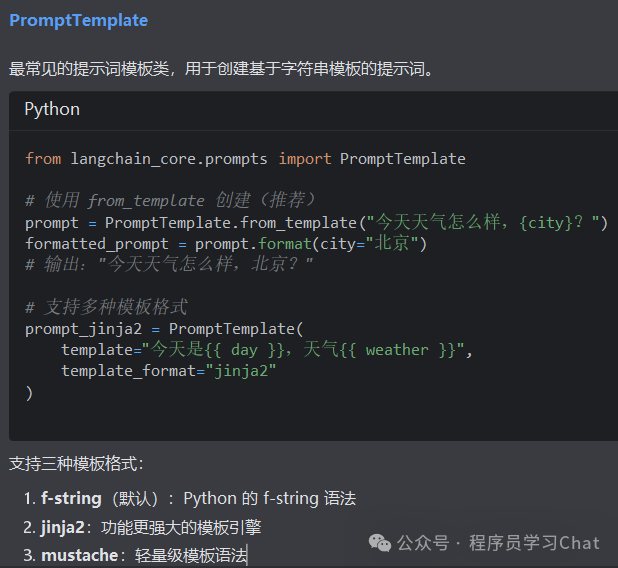
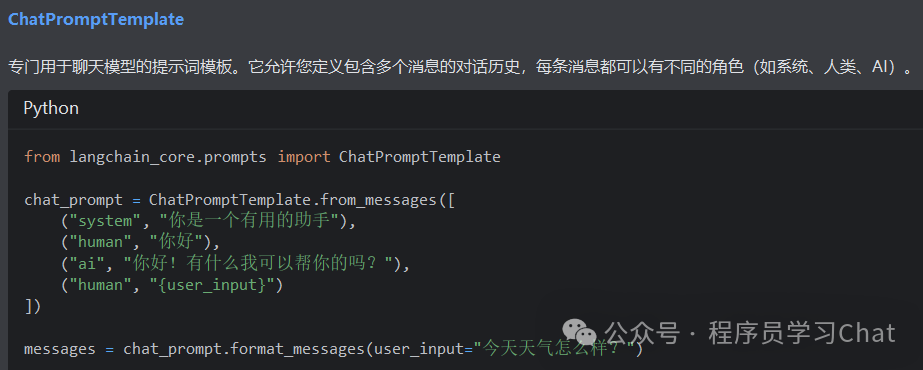
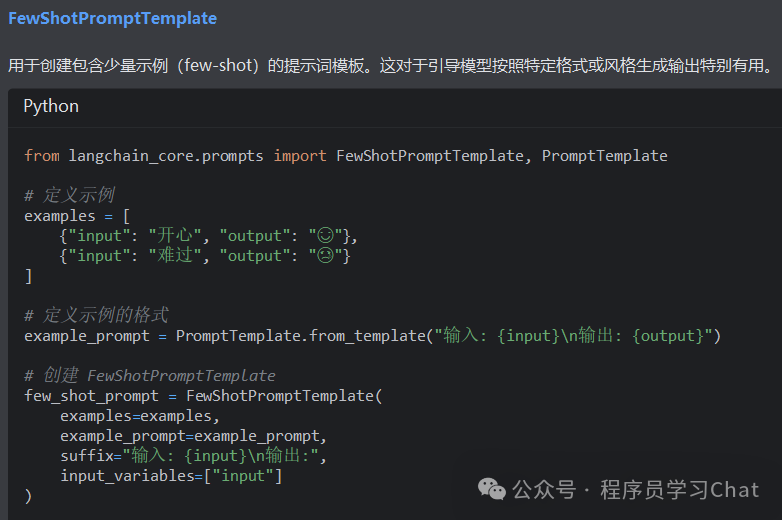
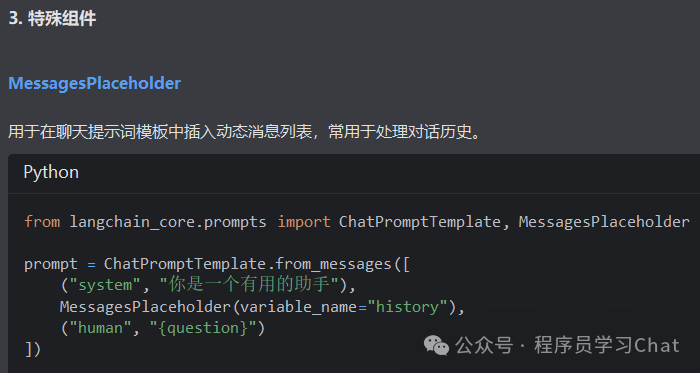
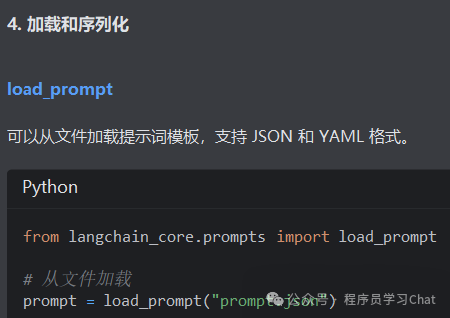
2.3 模型输出
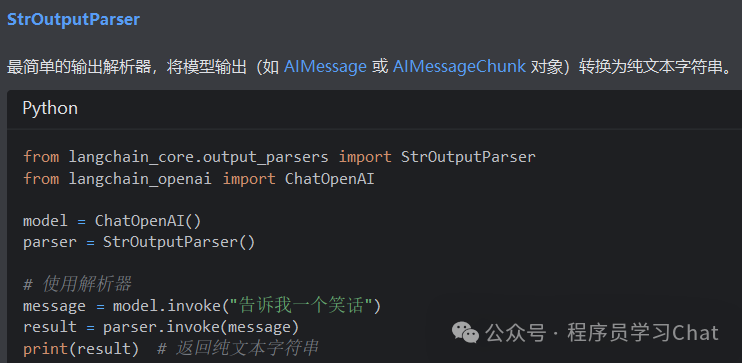
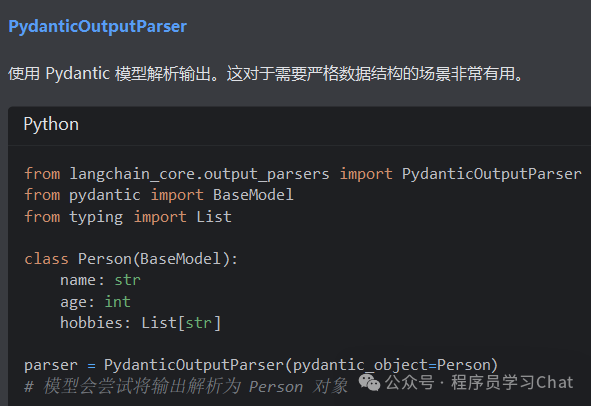
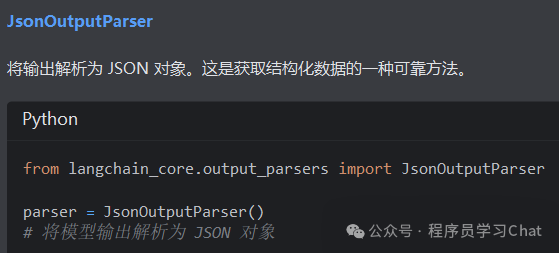
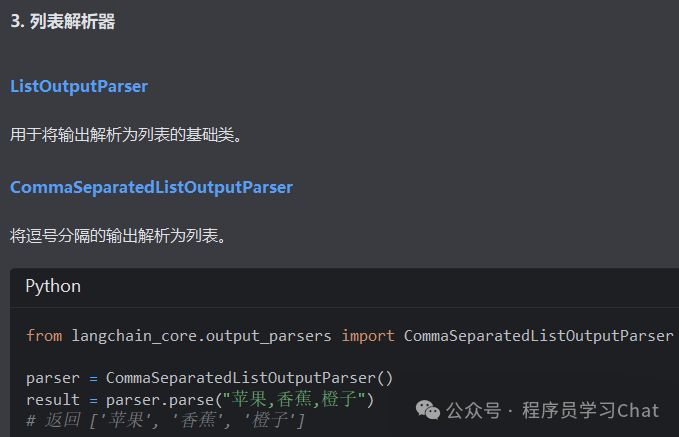
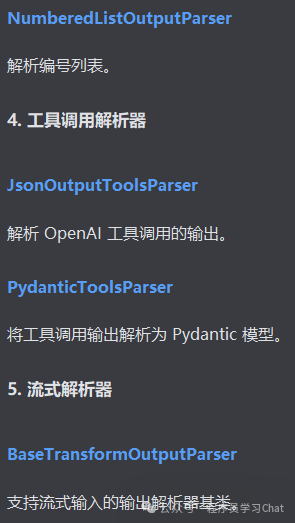
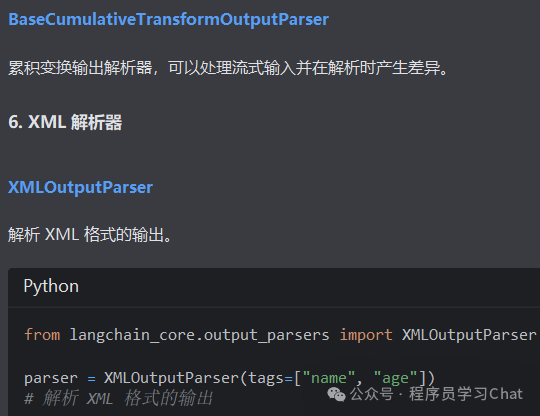
2.4 示例
2.4.1 聊天对话提示+字符串格式输出
import dotenv
import os
# 加载.env环境变量,在.env文件中填入你在阿里百炼平台申请的api_key
dotenv.load_dotenv()
######################################
#接入通义模型
######################################
api_key=os.getenv("DASHSCOPE_API_KEY")
from langchain_community.chat_models import ChatTongyi
model=ChatTongyi(
api_key=api_key,
model="qwen-plus"
)
# 测试是否成功接入
# print(model.invoke("你好"))
######################################
#定义对话输入提示模板
######################################
template="""请扮演一位资深的技术博主,你将负责为用户生成适合在微博发布的中文文章,请把用户输入的内容拓展为
200字左右的文章,并且添加适当的表情、符号使内容引人入胜并体现专业性"""
from langchain_core.prompts import ChatPromptTemplate
prompt=ChatPromptTemplate.from_messages(
[
#系统提示模板,设置大模型的整体回答环境
("system",template),
#人类的输入
("human","{input}")
]
)
######################################
#使用模型
######################################
# 用户输入
user_input = "大模型微调有哪些常用方法?"
# 手动渲染提示(得到 BaseMessage 列表)
messages = prompt.format_messages(input=user_input)
# 调用模型(传入消息列表)
response = model.invoke(messages)
# 3. 使用 StrOutputParser 显式解析模型输出为字符串
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
final_output = output_parser.invoke(response) # ← 关键:显式调用 invoke
print(final_output) # 纯字符串格式输出2.4.2 少样本提示+列表格式输出
import dotenv
import os
from langchain_community.chat_models import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_core.output_parsers import JsonOutputParser
# 加载环境变量
dotenv.load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
# 接入通义模型
model = ChatTongyi(api_key=api_key, model="qwen-plus")
# 少样本示例(输出为 JSON 列表)
examples = [
{"input": "郭德纲", "output": ["于谦,他们在德云社搭档合作相声"]},
{"input": "赵本山", "output": ["范伟,他们合作过多个春晚小品,以及电视剧《乡村爱情》", "高秀敏,他们合作过多个春晚小品,比如《卖拐》", ]},
]
# 构造少样本示例的模板
example_prompt = ChatPromptTemplate.from_messages([
#人类的输入
("human", "{input}"),
#模型的输出
("ai", "{output}") # 注意:这里 output 是 JSON 字符串
])
# 构造 few-shot 示例
few_shot_prompt = FewShotChatMessagePromptTemplate(
#注册少样本示例的提示
example_prompt=example_prompt,
#少样本示例
examples=[
{"input": ex["input"], "output": str(ex["output"])} for ex in examples
]
)
# 主提示:强制要求 JSON 列表格式
system_prompt = """你是一个搭档匹配助手。根据用户输入的名人姓名,返回其所有常见搭档的名字,并给出具体解释。
请以严格的 JSON 列表格式回答,例如:["搭档1", "搭档2"]。
"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
few_shot_prompt,
("human", "{input}")
])
# 用户输入
user_input = "周星驰"
# 渲染提示
messages = prompt.format_messages(input=user_input)
# 调用模型
response = model.invoke(messages)
# 使用 JsonOutputParser 解析为 Python list
parser = JsonOutputParser()
try:
partners = parser.invoke(response)
print("搭档列表:", partners)
except Exception as e:
print("解析失败,原始输出:", response.content)三 链
链(chain)是langchain的核心,也是它名字的由来。Langchain利用“链”来管理大模型应用中不同的组件,将这些不同的组件通过链连接在一起,形成一个完整的、借助大模型解决实际问题的流程,链会自动管理、转换各个组件之间数据的传递和格式,从而保证整体链能顺利运行,每个链中的组件被langchain抽象为一个Runnable,通过“|”连接这些Runnables构建链。
Runnables

为什么要定义Runnables
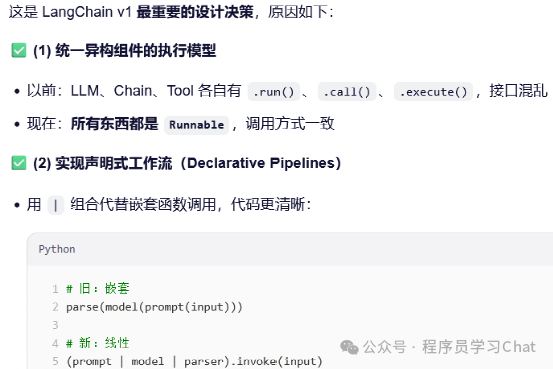
Runnables底层实现原理
基于操作符重载 + 类型组合的运行时构建




使用方法
runnables 模块是 LangChain 架构的核心,它使开发者能够以声明式的方式构建复杂的链式处理流程,同时享受同步、异步、批处理和流式传输等丰富的功能。
Runnable 是 LangChain 中的基本执行单元,代表一个可以被调用、批处理、流式传输、转换和组合的工作单元。所有 Runnable 都具备以下关键方法(a开头为异步调用模式):
1)invoke/ainvoke:将单个输入转换为输出
2)batch/abatch:高效地将多个输入转换为输出
3)stream/astream:在生成输出时进行流式传输
4)astream_log:流式传输输出和选定的中间结果
主要组件:
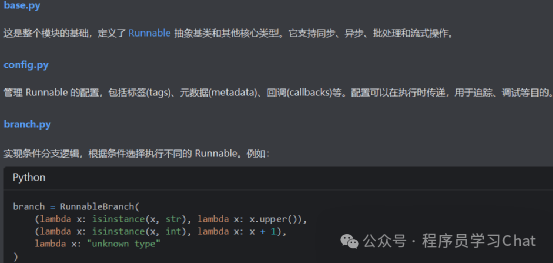
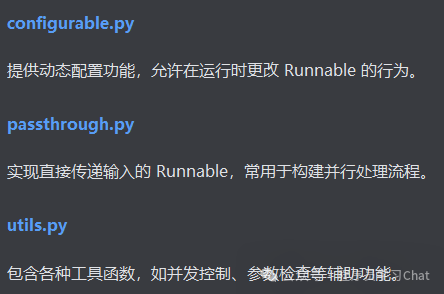
Runnables的组合方式:
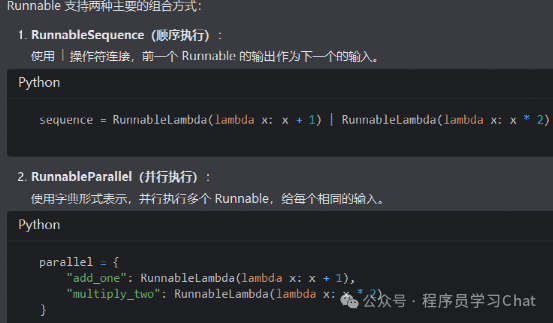
优势:
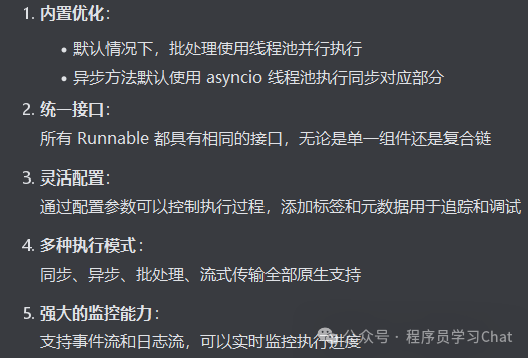
应用场景:

四 文档处理
4.1 基础文档对象
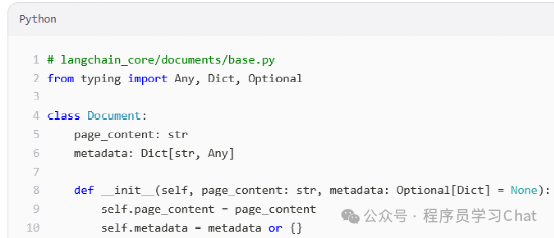
Langchain将所有文档都抽象为一个文档对象,文档对象由“内容”+“文档元信息”组成,文档对象的定义在langchain_core中

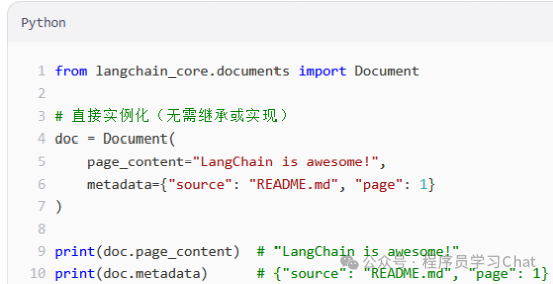
使用示例
4.2 文档加载器
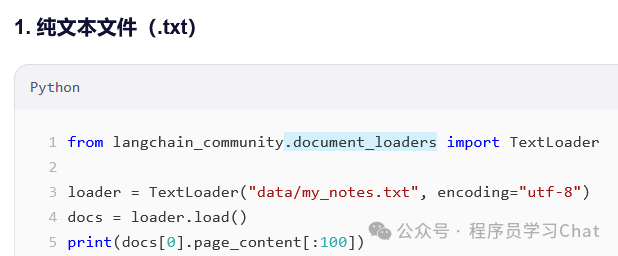
文档加载器负责从不同数据源加载数据,构建成基础文档对象Document列表
所有文档加载器在最新langchain中都由langchain_community.document_loaders管理实现。

公共方法都为load(),加载指定数据为documents对象列表
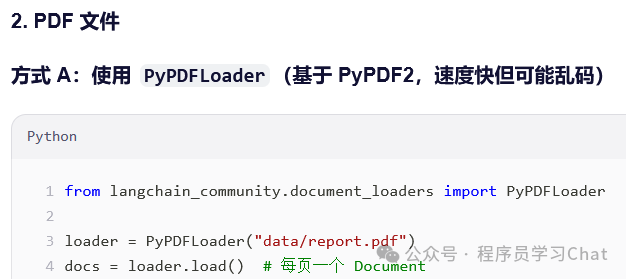

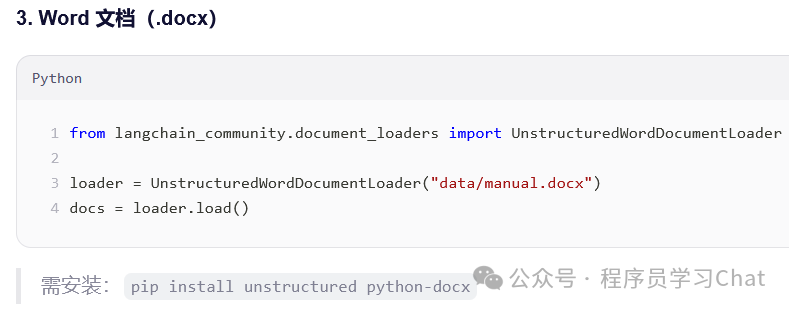
4.3 文档分割器
文档分割器对文档加载器加载到的基础文档对象进行分割,便于接下来的处理,在最新版的langchain(V1)中,所有文档分割器由langchain_text_splitters管理。
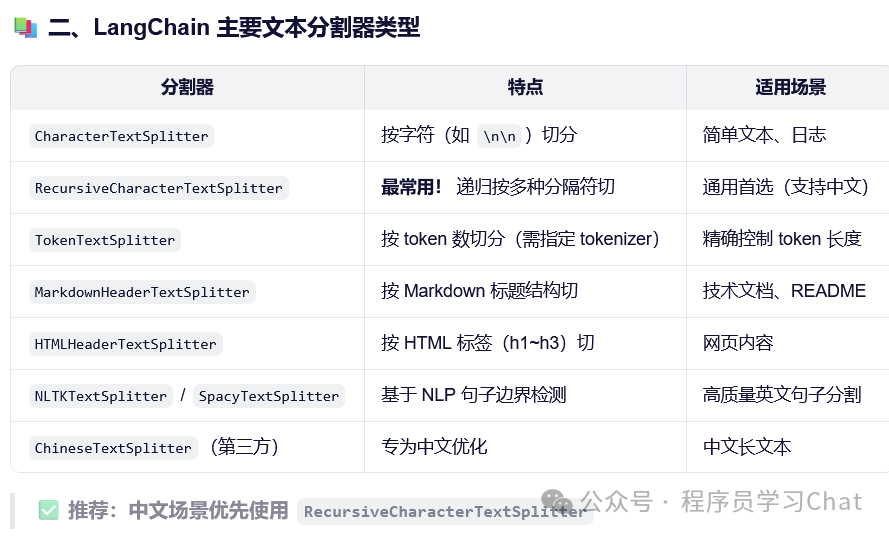
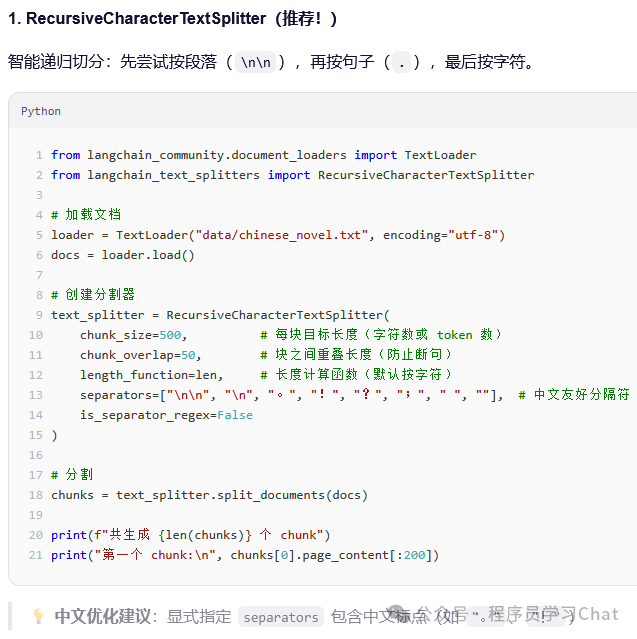

4.4 文档处理方式
文档处理方式指的是采取何种策略处理我们加载完毕的文档对象
4.4.1 Stuff策略:合并处理
Stuff策略将我们解析到的所有文档对象合并为一个大的文档,对这个大的文档进行处理,适合小型文档的处理
from langchain_core.prompts import PromptTemplate, format_document
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models import ChatOllama
from langchain_community.document_loaders import ArxivLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载指定的arxiv论文
loader = ArxivLoader(query="2210.03629", load_max_docs=1)
docs = loader.load()
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
chunks = text_splitter.split_documents(docs)
# 文档格式化提示 page_content对应Document中的具体内容的字段
#这个提示表示提取文档中的内容
doc_prompt = PromptTemplate.from_template("{page_content}")
#提取所有文档的内容 并用\n\n连接起来
input_doc = {
"content": lambda docs: "\n\n".join(format_document(doc, doc_prompt) for doc in docs)
}
# 构建论文总结链
chain = (
input_doc
| PromptTemplate.from_template("使用中文总结以下内容:\n\n{content}")
| ChatOllama(model="deepseek-r1:14b")
| StrOutputParser()
)
print(chain.invoke(chunks[:4]))4.4.2 MapReduce策略:分治处理
MapReduce策略并行处理每个小的文档块,然后利用一个Reduce合并处理所有文档块的处理结果,适合对大规模文档进行处理
from functools import partial
from langchain_core.prompts import PromptTemplate, format_document
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models import ChatOllama
from langchain_community.document_loaders import ArxivLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载指定的arxiv论文
loader = ArxivLoader(query="2210.03629", load_max_docs=1)
docs = loader.load()
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(docs)
# 构建模型
llm = ChatOllama(model="deepseek-r1:14b")
#文档格式化提示 提取Document中的内容字段page_content
document_prompt = PromptTemplate.from_template("{page_content}")
#封装format_document函数,固定prompt参数为document_prompt 返回还是一个函数
partial_format_document = partial(format_document, prompt=document_prompt)
# map链
map_chain = (
{"context": partial_format_document}
| PromptTemplate.from_template("总结以下文本的内容{context}")
| llm
| StrOutputParser()
)
# reduce链
reduce_chain = (
{"context": lambda strs: "\n\n".join(strs)}
| PromptTemplate.from_template("对以下总结内容进行一个整体总结:{context}")
| llm
| StrOutputParser()
)
# 构建mapreduce链 map()分发map链,并行处理不同的文档快
mapreduce_chain = map_chain.map() | reduce_chain
#max_concurrency限制最大并发数量
print(mapreduce_chain.invoke(chunks[:4], config={"max_concurrency": 5}))4.4.3 Refine策略:迭代求精
Refine策略通过循环迭代式的处理文档块,当前文档块的处理依赖上一个文档块的处理,适用于文档总结性任务
from functools import partial
from langchain_core.prompts import PromptTemplate, format_document
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models import ChatOllama
from langchain_community.document_loaders import ArxivLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from operator import itemgetter
# 加载指定的arxiv论文
loader = ArxivLoader(query="2210.03629", load_max_docs=1)
docs = loader.load()
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
chunks = text_splitter.split_documents(docs)
#构建模型
llm=ChatOllama(model="deepseek-r1:14b")
#文档格式转换 提取Document对象的page_content字段中的内容
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt)
#总结第一个文档块的链
first_prompt=PromptTemplate.from_template("使用中文总结以下内容:\n\n{context}")
context_chain=(
{"context": partial_format_document}
| first_prompt
| llm
| StrOutputParser()
)
#每轮循环迭代的refine链
refine_prompt=PromptTemplate.from_template(
"这是你之前总结的内容:{prev_response}.现在需要根据新内容{context}更新你的总结"
)
refine_chain=(
{
"prev_response": itemgetter("pre_response"),
"context": lambda x: partial_format_document(x["doc"]),
}
| refine_prompt
| llm
| StrOutputParser()
)
#构建refine流程
def refine_loop(docs):
#先总结第一个文档片段
summary=context_chain.invoke(docs[0])
#refine循环
for i,doc in enumerate(docs[1:]):
summary=refine_chain.invoke({"pre_response":summary,"doc":doc})
#返回最终总结
return summary
print(refine_loop(chunks[:4]))
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)