AI进化论10:AlphaGo的震撼——AI把人类“下”懵了,强化学习“出圈”了
系列目录
AI的萌芽:计算的哲学与逻辑的开端
AI进化论02:图灵的遗产——机器能否思考
AI进化论03:达特茅斯会议——AI的“开宗立派”大会
AI进化论04:专家系统——AI的第一次“实用浪潮”,然后就“翻车”了?
AI进化论05:第一次AI寒冬——当年AI的“饼”没烙熟,把投资人给烫着了
AI进化论06:连接主义的复兴——神经网络的“蛰伏”与“萌动”
AI进化论07:第二次AI寒冬——AI“改头换面”,从“AI”变成“机器学习”
AI进化论08:机器学习的崛起——数据和算法的“二人转”,AI“闷声发大财”
AI进化论09:深度学习的黎明——AlexNet“一鸣惊人”,AI“重获新生”
AI进化论10:AlphaGo的震撼——AI把人类“下”懵了,强化学习“出圈”了
AI进化论11:Transformer架构——AI的“架构升级”,开启“大模型时代”
AI进化论12:大语言模型的爆发——GPT系列“出圈”,AI飞入寻常百姓家
AI进化论13:生成式AI的浪潮——AI不光能“说”,还能“画”和“拍”
AI进化论14:多模态AI——AI的“六边形战士”,离“通用智能”又近一步
AI进化论15:通用人工智能(AGI)的“终极梦想”与“潘多拉魔盒”
各位老铁,上回咱们聊了AlexNet怎么在图像识别上“一鸣惊人”,让深度学习“重获新生”。但真正让AI“出圈”,让全世界都“炸锅”的,还得是2016年那场围棋人机大战——AlphaGo把人类围棋冠军给“下”懵了!这场对决,不光是技术的胜利,更是对人类“智商”的一次深刻叩问,也让**强化学习(Reinforcement Learning, RL)**这个AI范式,彻底“火”了!
1. 什么是强化学习?:AI自己“玩”游戏,自己“悟”套路
强化学习,是机器学习的一个重要分支。它的核心思想,就是让AI自己“玩”游戏,自己“悟”套路。AI就像个“玩家”(Agent),在一个“游戏环境”里不断地“试错”。它每做一个动作,环境就会给它“奖励”(Reward)或“惩罚”(Penalty)。AI的目标,就是通过最大化这些“奖励”,来学习一套“最优攻略”,从而在特定任务中“通关”。
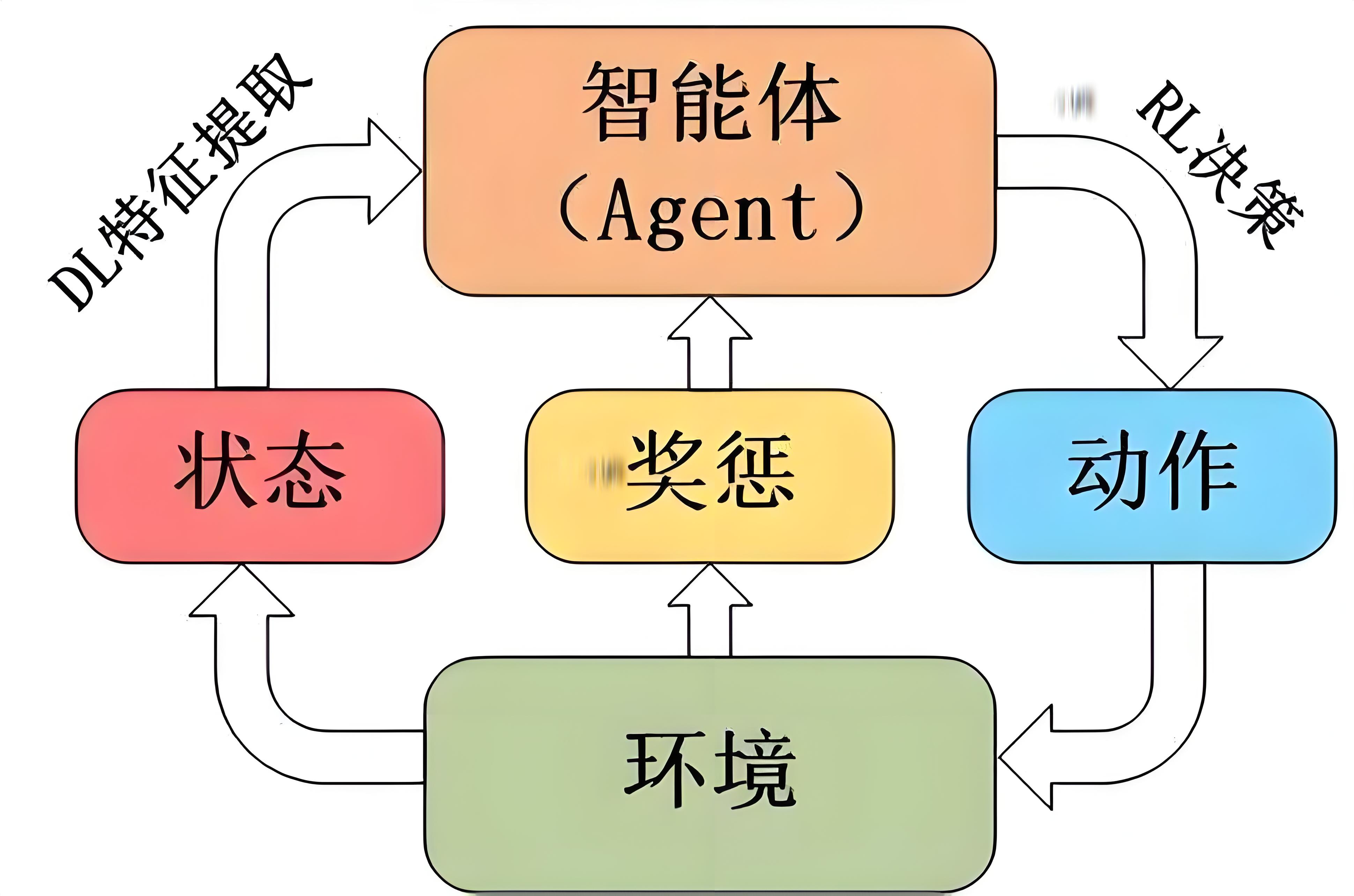
这不就是我们打游戏嘛!死了无数次,终于摸清了BOSS的套路,然后“一命通关”!
2. 围棋:AI的“终极BOSS”,比宇宙原子还多
在AlphaGo之前,围棋一直被认为是AI难以逾越的“终极BOSS”。为啥呢?
- 巨大的搜索空间: 围棋的合法落子点多达361个,每一步棋的组合可能性,比宇宙中的原子总数还多!传统的暴力搜索方法,在这里直接“歇菜”,根本算不过来。
- 难以评估局面: 围棋的局面评估,那叫一个“玄学”,不像国际象棋有明确的棋子价值。围棋的优势,往往是全局性的、隐性的,很难用简单的函数去量化。这不就是我们程序员最头疼的“需求不明确”嘛!
3. AlphaGo的秘密武器:AI的“左右脑”和“模拟器”
由DeepMind公司开发的AlphaGo,之所以能“征服”围棋,在于它巧妙地结合了深度学习和蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)两大“绝招”:
- 策略网络(Policy Network): 这是一个深度神经网络,就像AI的“左脑”,负责预测下一步最有可能下在哪里。它先学人类高手的棋谱,再自己跟自己“左右互搏”来提升。
- 价值网络(Value Network): 这是另一个深度神经网络,就像AI的“右脑”,负责评估当前局面的“胜率”。它也通过自我对弈来“悟”出胜负。
- 蒙特卡洛树搜索(MCTS): 这就是AlphaGo的“模拟器”!它利用策略网络来指导搜索方向,减少无效搜索;利用价值网络来评估搜索到的局面。通过大量的模拟对弈,MCTS能在巨大的搜索空间中,找到“最优解”。
- 自我对弈(Self-play): AlphaGo最牛的地方,就是它能自己跟自己“左右互搏”,从零开始学习,越打越强,最终超越了人类的棋力。这不就是我们程序员自己写代码,自己测试,自己优化嘛!
4. 人机巅峰对决:AI“神之一手”,把人类“看懵”了
2015年,AlphaGo先是5:0战胜了欧洲围棋冠军樊麾,但没引起太大波澜。
真正的“炸锅”时刻,发生在2016年3月!AlphaGo与韩国围棋传奇人物、世界冠军李世石九段,展开了五番棋对决。这场比赛,直接把全球的目光都吸引过来了:
- 首局告捷: AlphaGo出人意料地赢了第一局,直接把大家对AI的“固有认知”给“打破”了。
- “神之一手”: 在第二局中,AlphaGo下出了被誉为“神之一手”的第37手。这步棋,完全出乎人类棋手的意料,但最终被证明是奠定胜局的关键。这简直是AI的“神来之笔”啊!把人类都给看懵了,开始怀疑人生了。
- 最终胜利: AlphaGo以4:1的总比分战胜李世石,宣告了AI在围棋领域的全面胜利。这场比赛,直接让AI“出圈”了,引发了全球对AI的巨大讨论和关注。

2017年,升级后的AlphaGo Master(或称AlphaGo Zero的早期版本),更是3:0横扫当时世界排名第一的中国棋手柯洁,进一步巩固了AI在围棋领域的“霸主地位”。
5. AlphaGo的深远影响:AI不光能“看”,还能“想”和“决策”
AlphaGo的胜利,不光是围棋领域的突破,它对整个AI界乃至社会都产生了深远影响:
- 深度学习+强化学习的“王炸组合”: 证明了深度学习与强化学习结合的强大潜力,为AI在复杂决策、控制、机器人这些领域,开辟了新的“技术路线”。
- AI能力的“里程碑”: 彻底改变了公众对AI能力的认知,让大家意识到AI不光能“看”(图像识别),还能“想”和“决策”。AI不再是“科幻”,而是真切地来到了我们身边。
- 推动AI研究热潮: 吸引了更多资金和人才涌入AI领域,加速了AI技术的研发和应用。这不就是AI界的“风口”嘛!
- 启发人类思考: 促使人类重新审视自己的“智商”、直觉和创造力,以及未来人机协作的可能性。毕竟,连围棋都能被AI“下”赢了,还有啥不可能的呢?
结语
AlphaGo的胜利,是人工智能发展史上又一个“里程碑”事件。它以围棋为舞台,向世界展示了AI在复杂策略游戏中的“超凡能力”,也预示着AI将从“感知智能”迈向“决策智能”。这场巅峰对决,不光改变了围棋,更改变了我们对AI的认知,为AI的下一个时代拉开了序幕。
下一篇,咱们就聊聊Transformer架构的诞生,以及它如何成为大语言模型和生成式AI的“基石”,开启AI的“大模型时代”!敬请期待!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)