ICCV 2025 | 哈工大等提出SENTINEL:在 MLLM 幻觉萌芽时“干预“,将“对象幻觉“降低超90%!
这种方法使得模型能够在生成过程中动态地抑制幻觉的产生。尤为突出的是,在显著降低幻觉的同时,模型在通用任务上的表现不仅得以保持,甚至有所提升,充分验证了该方法的有效性与兼容性。通过检测器之间的交叉验证,系统自动区分幻觉与真实样本,并在此基础上构建高质量的域内偏好数据集,整个过程无需依赖专有大模型或人工标注,保证了方法的自主性与可扩展性。如图案例所示,基线模型因误读图像内容得出错误结论,而我们的模型能
多模态大语言模型(MLLM)在理解世界方面取得了巨大飞跃,但“幻觉”问题——即生成与图像不符的内容——仍然是其关键弱点。来自哈工大(深圳)、港中大和港中大(深圳)的研究者发现,幻觉往往在文本生成的早期阶段就已“萌芽”。基于此,他们提出了一个名为 SENTINEL 的新框架,通过在句子层面进行早期干预,无需人工标注,便可将物体幻觉减少90%以上,同时在多个基准测试中超越了现有顶尖方法。

-
论文标题: Mitigating Object Hallucinations via Sentence-Level Early Intervention
-
作者: Shangpin Peng, Senqiao Yang, Li Jiang, Zhuotao Tian
-
机构: 哈尔滨工业大学(深圳);香港中文大学;香港中文大学(深圳)
-
论文地址: https://arxiv.org/pdf/2507.12455v1
-
项目地址: https://github.com/pspdada/SENTINEL
-
录用会议: ICCV 2025
研究背景与意义
多模态大语言模型(MLLM)能够像人一样看图说话,这极大地推动了通用人工智能的发展。然而,它们有时会“信口开河”,在描述中添加图片里根本不存在的物体,这就是“物体幻觉”问题。这个问题严重影响了模型的可靠性,尤其是在需要高精度信息的场景下。
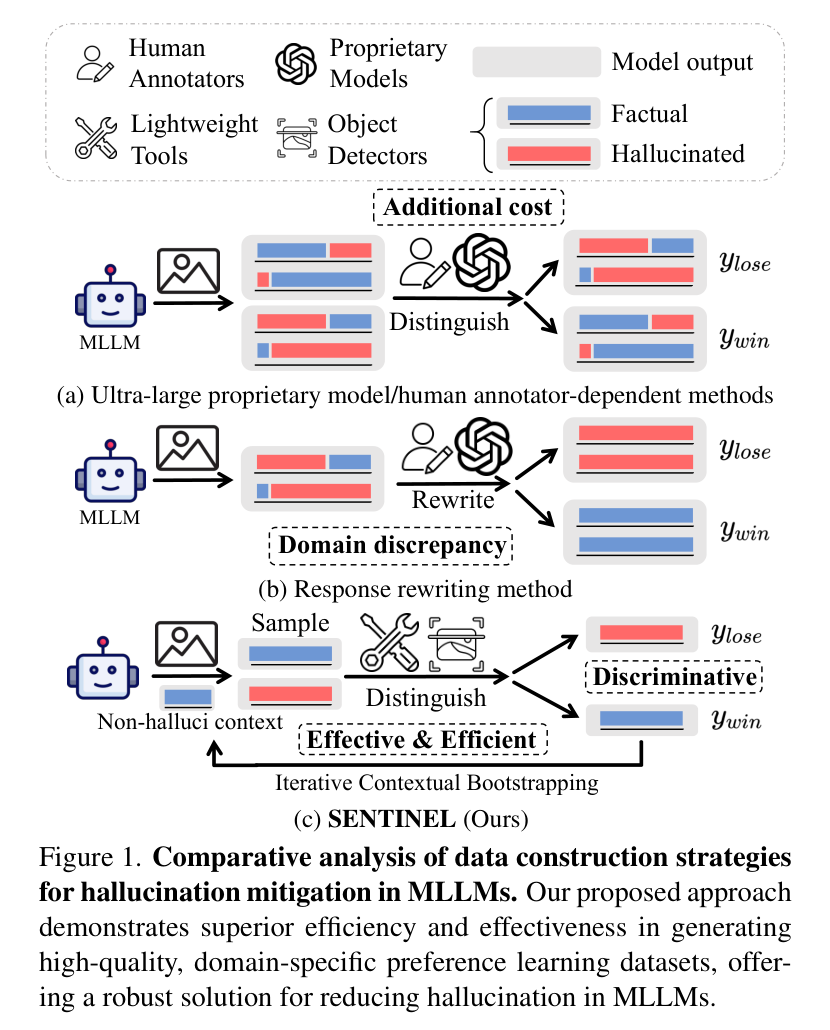
以往的解决方案,如依赖外部知识或人类反馈进行对齐,要么计算成本高昂,要么引入了训练数据和模型实际输出之间的偏差。研究者们敏锐地观察到,幻觉并非在最终输出时才凭空出现,而是在生成过程的早期句子中就已埋下伏笔,并随着文本的不断生成而扩散、放大。
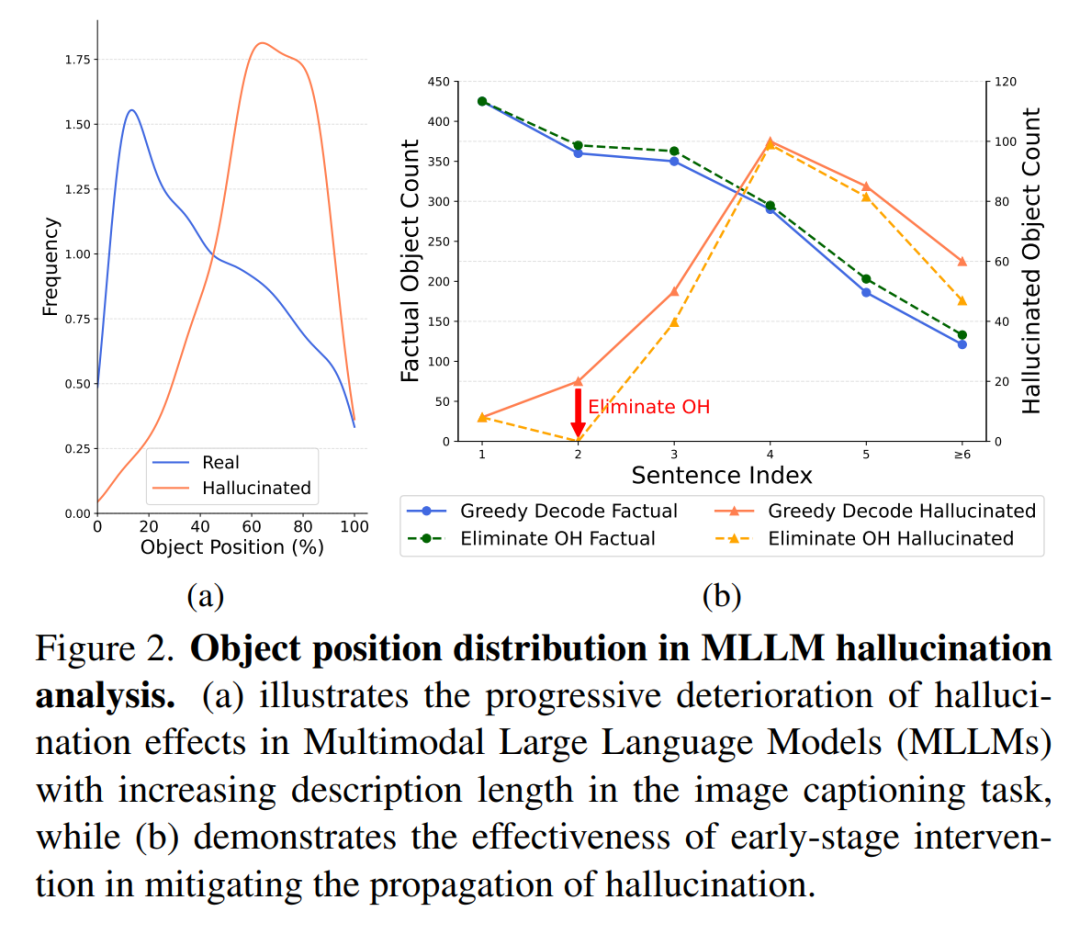
(a)说明了随着图像字幕任务中描述长度的增加,多模态大语言模型(MLLM)中的幻觉效果逐渐恶化,而(b)证明了早期干预在减轻幻觉传播方面的有效性。
SENTINEL:句子级早期干预框架
SENTINEL 提出一种全新的自动化、句子级别的早期干预策略,旨在有效防止和缓解多模态大语言模型(MLLM)中的对象幻觉问题。该方法具备多项显著优势:首先,它完全无需人工标注数据,大幅降低了实施成本与门槛;其次,SENTINEL 具备模型无关性,能够兼容任意结构的 MLLM,具备广泛的适用性;最后,通过采用轻量级的 LoRA 微调方式,整个干预过程高效且资源消耗低,便于实际部署与应用。
其核心机制在于早期干预以阻断幻觉的传播链条。研究发现,MLLM 的对象幻觉往往在生成的前几个句子中便已出现,并在后续输出中持续扩散。SENTINEL 正是在这一关键阶段进行提前干预,及时打断幻觉信息的传播路径,从而在源头上实现最大程度的幻觉缓解。
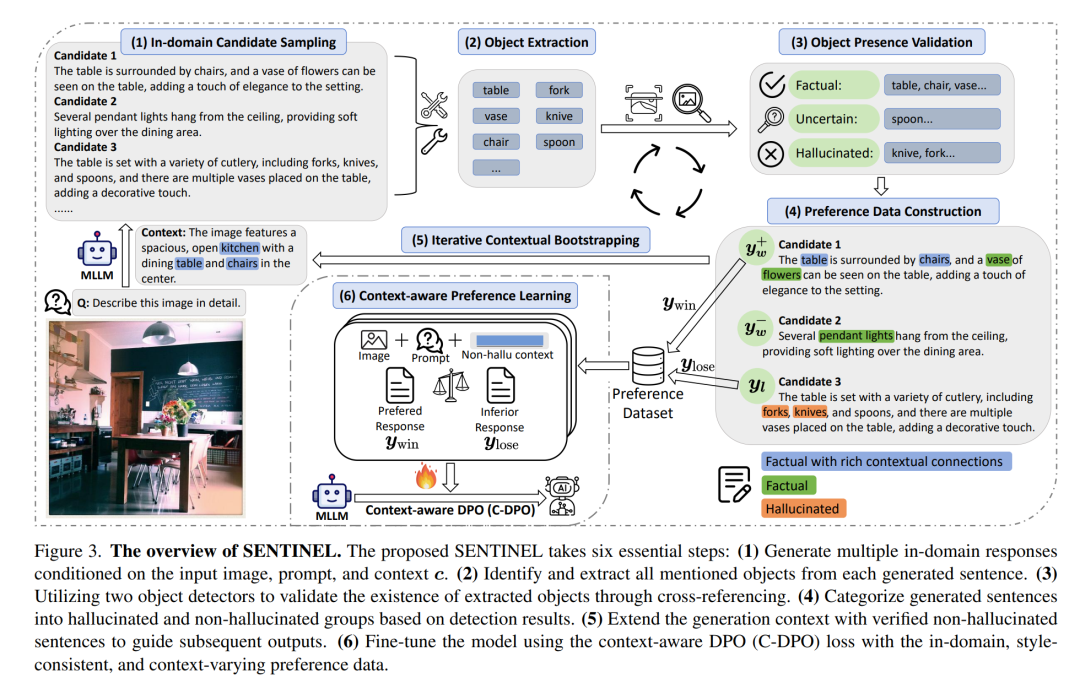
该框架主要包含两个阶段:
1. 域内偏好数据构建
SENTINEL方法包含六个关键步骤。可以将生成包含真实和幻觉对象的域内候选对象的过程;和基于这些候选对象构建偏好数据对的方法归为第一阶段——域内偏好数据构建。
在数据构建方面,SENTINEL 创新性地实现了无需人工标注的域内上下文偏好学习。通过检测器之间的交叉验证,系统自动区分幻觉与真实样本,并在此基础上构建高质量的域内偏好数据集,整个过程无需依赖专有大模型或人工标注,保证了方法的自主性与可扩展性。



给定输入图像和相应的问题,该管道迭代生成不同的上下文样本,在不同的上下文中实现鲁棒的幻觉缓解,并显著提高模型泛化能力。
2. SENTINEL如何利用构建的偏好数据实现偏好学习
有了高质量的偏好数据,研究者采用了一种改进的直接偏好优化(DPO)方法,称为上下文感知偏好损失(Context-aware Preference Loss, C-DPO)。与传统DPO不同,C-DPO不仅要模型能区分整个回复的好坏,更强调在句子层面进行判别性学习。它要求模型在生成到特定句子时,就能意识到接下来的内容可能产生幻觉,并选择更忠实于图像的表达。这种方法使得模型能够在生成过程中动态地抑制幻觉的产生。
实验结果与分析
在多个权威基准测试中,包括 Object HalBench、AMBER 和 HallusionBench,SENTINEL 均展现出卓越性能,对象幻觉最多可减少 92%,全面超越此前的最先进方法(SOTA)。尤为突出的是,在显著降低幻觉的同时,模型在通用任务上的表现不仅得以保持,甚至有所提升,充分验证了该方法的有效性与兼容性。
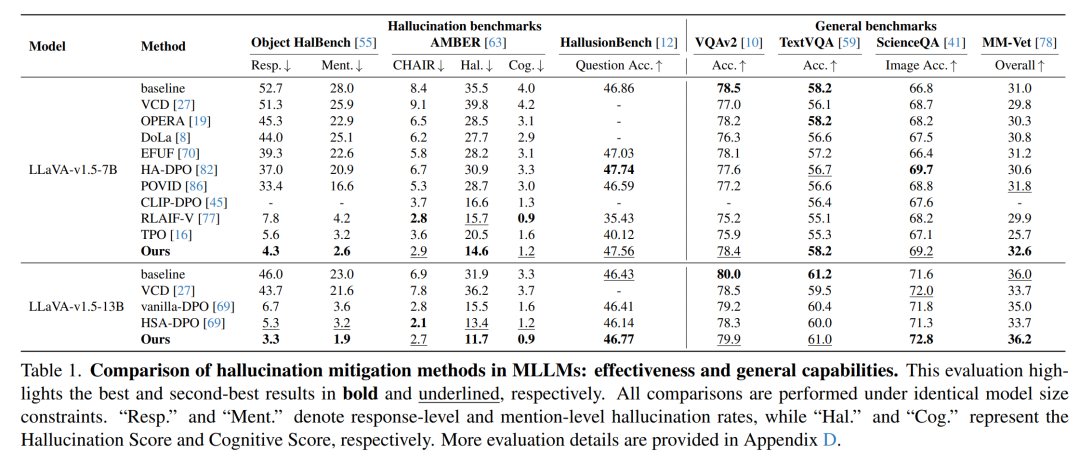
上表结果显示,SENTINEL在多项基准测试中展现出模型泛化能力的增强:在VQAv2和TextVQA上保持稳定性能(而现有降幻方法通常伴随性能显著下降),在ScienceQA和MM-Vet上不仅超越同类降幻方法,更优于原始LLaVA-v1.5模型。
全面幻觉缓解效果
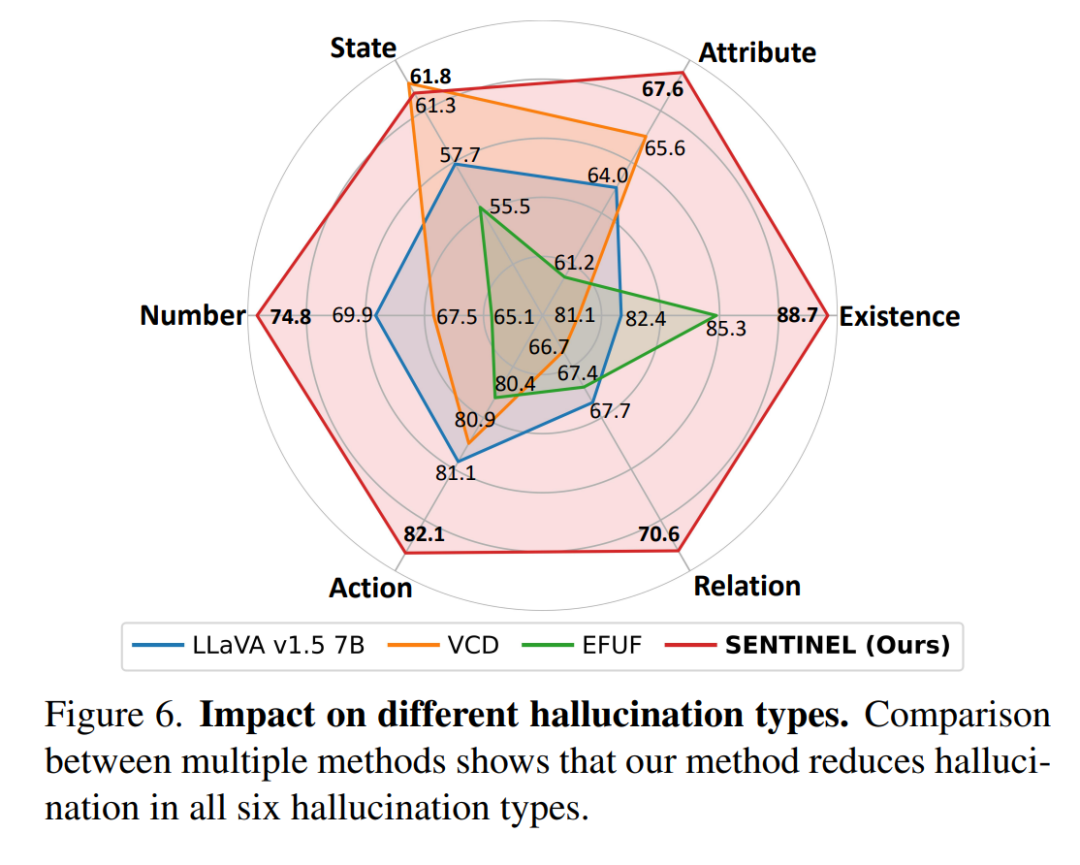
如图所示,采用SENTINEL的LLaVA-v1.5在所有六类幻觉上均超越基线方法,其中针对"存在性幻觉"类型,7B模型提升6.3分,13B模型提升7.6分(完整结果见附录D.4)。
定性结果

如图案例所示,基线模型因误读图像内容得出错误结论,而我们的模型能准确理解图像并生成更详尽的描述(更多案例见附录G),印证了本方法在降低幻觉率的同时提升模型整体能力的双重优势。
消融实验
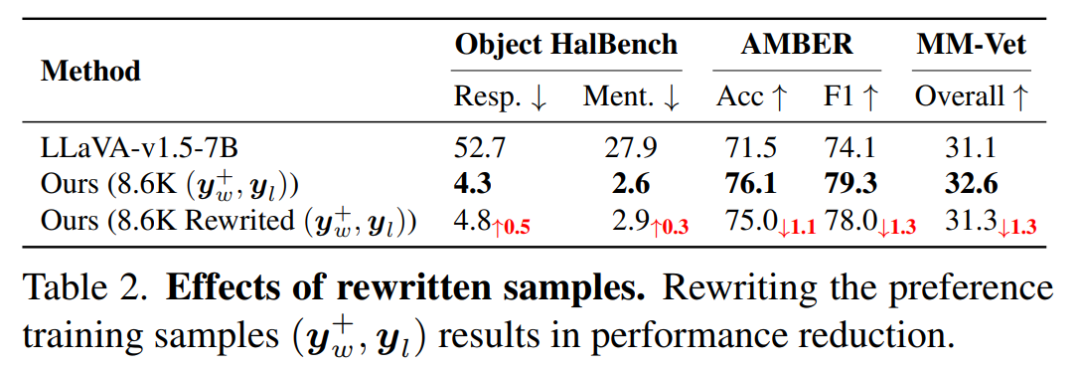
上表显示重写数据导致幻觉减少能力和通用性能下降,印证了保持原始数据风格的优势。
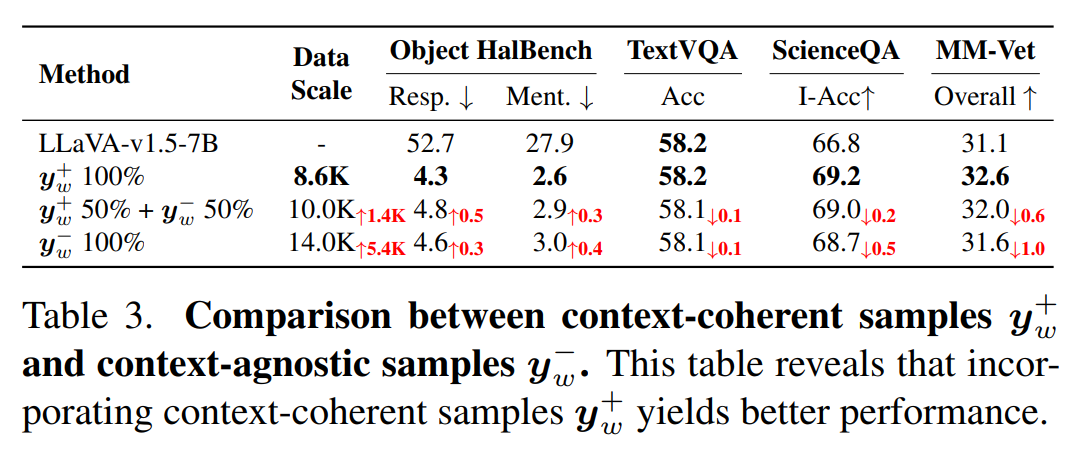
上表显示不同正样本yw类型及比例的实验表明,富含上下文信息的y+w样本能以更少数据实现相近的降幻效果,同时提升模型泛化能力。
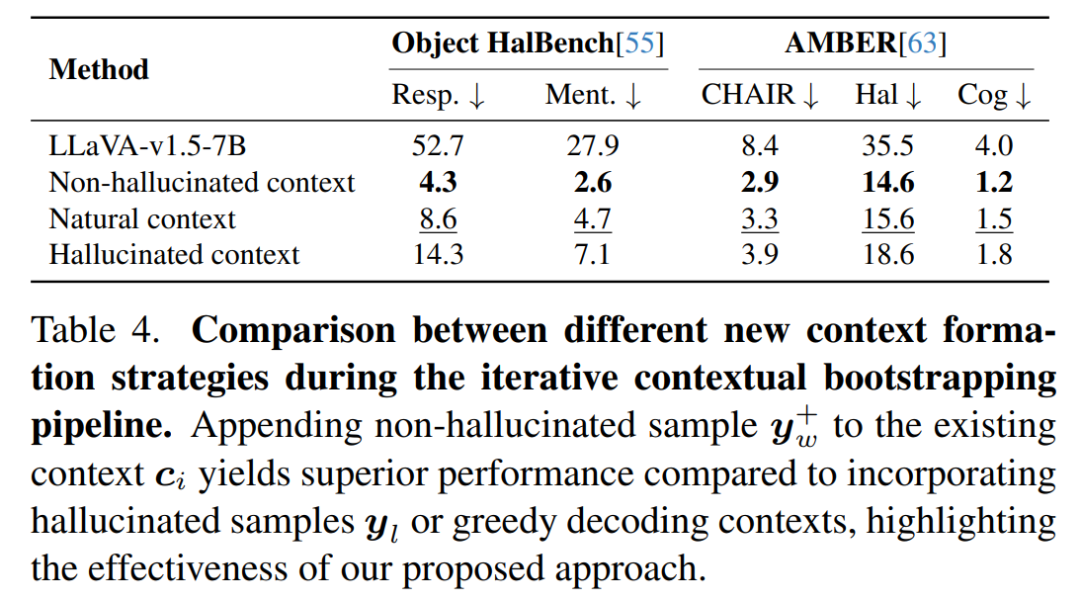
上表显示对比幻觉句子、非幻觉句子和贪婪解码生成句子作为新上下文的实验,采用非幻觉上下文可显著提升模型判别能力并减少输出幻觉,证明在首次幻觉出现时干预的关键性。
论文贡献与价值
这篇论文的主要贡献可以总结为以下几点:
-
新颖的洞察: 首次明确指出并验证了MLLM的物体幻觉主要出现在文本生成的早期阶段。
-
创新的框架: 提出了SENTINEL,一个无需人工标注、通过句子级早期干预来缓解幻觉的有效框架。
-
高效的方法: 设计了一种自动化的、基于交叉验证的偏好数据生成流程和上下文感知的偏好学习损失函数(C-DPO)。
-
卓越的性能: 实验证明,该方法能将幻觉减少超过90%,且在多个基准上优于现有SOTA方法,同时不损害模型的通用能力。
-
开源社区贡献: 研究团队开源了他们的模型、数据集和代码,为社区进一步研究和应用提供了宝贵的资源。
这项工作为解决多模态模型的幻觉问题提供了一个全新的、高效的视角和解决方案,对于提升大模型在现实世界应用的可靠性具有重要意义。
了解最新 AI 进展,欢迎关注公众号
投稿寻求报道请发邮件:amos@52cv.net

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)