Exploring Low-Resource Medical Image Classification with Weakly Supervised Prompt Learning
本文提出了一种弱监督提示学习方法MedPrompt,用于自动生成医学文本提示以解决低资源医学图像分类问题。该方法包含无监督预训练的视觉语言模型和弱监督提示学习模型,仅需类别标签即可自动生成高质量提示,显著降低对专家人工设计的依赖。实验表明,在四个医学基准数据集上,MedPrompt在全监督学习中均优于人工提示模型;在零样本和小样本任务中,三个数据集达到最优性能,另一个实现可比结果。该方法提示生成模

标题:基于弱监督提示学习的低资源医学图像分类研究
原文链接:https://arxiv.org/pdf/2402.03783
发表:Pattern Recognition-2024
摘要
医学图像识别在临床辅助诊断中的许多进展,受限于医学领域中高昂且专业的标注成本,面临低资源的挑战。该问题可以通过利用大规模预训练视觉语言模型(如 CLIP)中可迁移的表示来缓解。这些视觉语言模型在大规模未标注医学图像与文本(如医学报告)上进行预训练,能够学习具有迁移能力的表示,并通过相关的医学文本提示支持医学图像分类等灵活的下游临床任务。
然而,现有的预训练视觉语言模型在应用于具体医学图像任务时,往往需要领域专家(临床医生)根据不同数据集精心设计医学文本提示,这一过程极为耗时,大大增加了临床医生的负担。
为了解决这一问题,我们提出了一种弱监督提示学习方法 MedPrompt,用于自动生成医学提示。该方法包含一个无监督预训练视觉语言模型与一个弱监督提示学习模型。无监督预训练视觉语言模型使用大规模医学图像与文本进行预训练,利用图像与其对应医学文本之间的自然相关性,无需人工标注。弱监督提示学习模型仅利用数据集中图像的类别来引导提示中类别向量的学习,而提示中其他上下文向量的学习则无需人工标注。
据我们所知,这是首个可以自动生成医学提示的模型。在这些提示的辅助下,预训练视觉语言模型可以摆脱对专家的强依赖,实现端到端、低成本的医学图像分类。实验结果显示,在全监督学习中,我们模型生成的自动提示在四个数据集上均优于所有人工提示;在零样本图像分类与小样本学习任务中,我们在四个医学基准数据集中的三个上取得了更优准确率,在另一个数据集上也达到可比的准确率。此外,所提出的提示生成器结构轻量,有潜力嵌入任意网络架构中。
关键词: 医学图像分类,弱监督学习,提示学习,小样本学习,零样本学习
1. 引言
医学成像技术,如计算机断层扫描(CT)、磁共振成像(MRI)以及X射线,常用于临床实践中的监测、诊断与治疗。随着医学图像数据的急剧增长及深度学习技术的迅速发展,研究者已开发出多种深度学习模型用于医学图像分析,以支持临床决策,这些模型已被证明具备高准确性与良好的泛化能力 [1, 2, 3]。
现有模型大多采用监督学习方式,要求医学图像具备完整、准确的对应标注。与自然图像标注可以由普通人完成不同,医学图像的标注必须由经验丰富的领域专家(临床医生)进行,标注门槛与成本极高。这直接导致了当前医学数据的“低资源”现状 —— 可用的标注医学样本极为有限,而大量未标注的医学图像与文本(如医学报告)数据被遗弃且未被充分利用。
大规模预训练视觉语言模型如 CLIP [4] 的出现使得未标注样本能够被充分利用成为可能。一些研究已利用这类模型对大量未标注的医学图像与文本进行处理 [5, 6, 7]。这类大模型通过预测图像与文本对之间的匹配关系或相似度进行训练,从而学习可迁移的图像与文本表示,用于支持灵活的下游临床任务。
将预训练模型迁移到具体下游任务中,通常依赖于相关的医学文本提示。例如,以大规模医学预训练视觉语言模型 MedCLIP [7] 为例,当使用 MedCLIP 进行医学图像分类时,将图像与多个对应不同预测类别的医学文本提示输入模型的图像编码器与文本编码器中,得到对应的嵌入表示;随后模型计算图像嵌入与各文本嵌入之间的相似度,将与图像嵌入相似度最高的文本嵌入对应的类别作为图像的预测类别。
输入文本提示的质量(即使是措辞上的微小变化)已被证明对模型性能具有显著影响 [8]。因此,生成医学文本提示高度依赖于领域专家(临床医生)。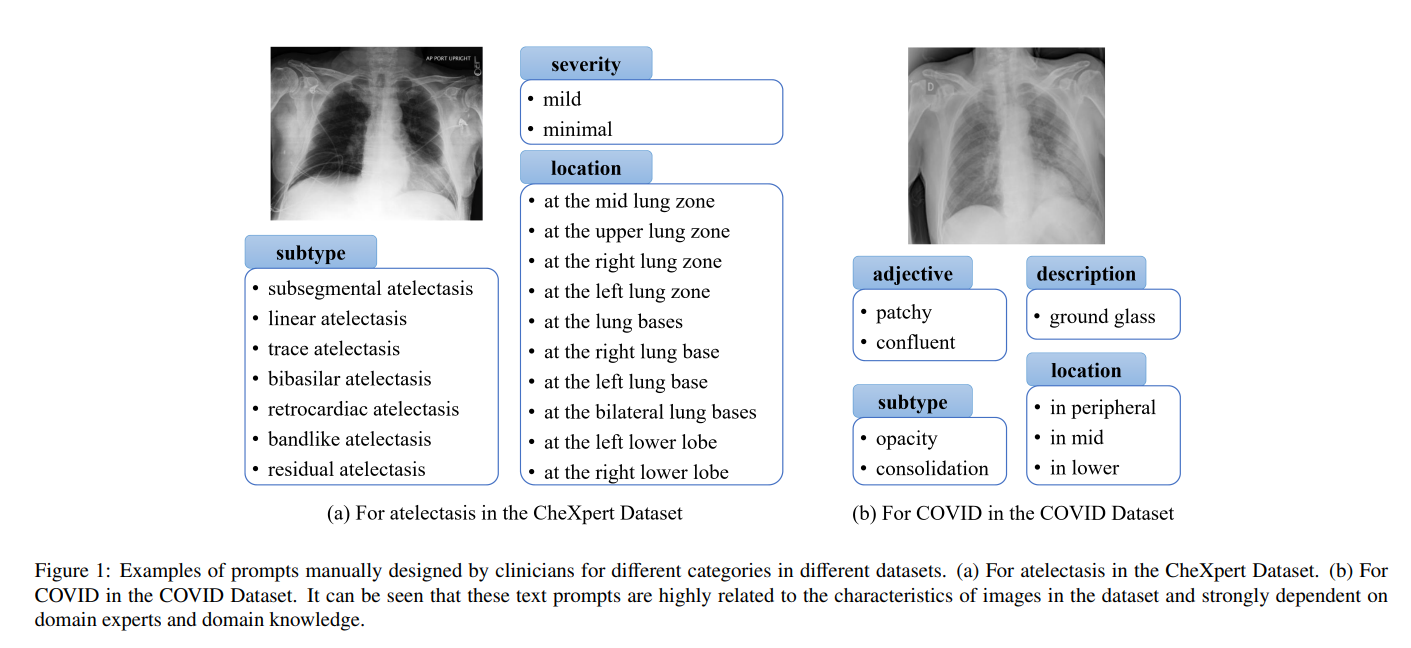
图 1 展示了由临床医生根据不同数据集中的不同类别精心设计的提示示例。可以看到,这些提示在疾病亚型、严重程度与位置等方面都与图像特征高度相关,类别与内容上差异显著,专业性极强。因此,人工设计文本提示极为耗时,严重依赖专家知识。这明显违背了使用大规模预训练视觉语言模型来缓解医学图像低资源问题、降低对临床医生依赖的初衷。因此,自动生成提示是一种更优的解决方案。
为此,我们提出了一个弱监督提示学习框架 MedPrompt,可自动生成高质量医学文本提示。该框架包括一个无监督预训练的视觉语言模型和一个弱监督提示学习模型。无监督模型在大规模医学图像与文本上进行预训练,利用两者之间的自然关联,无需人工标注;弱监督提示学习模型(即提示生成器)由一个可学习的两层瓶颈结构和上下文嵌入、类别嵌入的投影操作组成。它仅使用数据集中图像的类别来引导提示中类别向量的学习,而上下文向量的学习无需人工标注。该框架可训练生成高质量提示。借助这些提示,预训练视觉语言模型可通过图像与提示嵌入之间的相似度确定图像类别。整个过程中,框架几乎完全摆脱了人工标注与提示设计中的专家依赖,实现端到端、低成本医学图像识别。
实验结果表明:
- 在 CheXpert、MIMIC-CXR 和 COVID 数据集上,我们提出模型的零样本推理性能优于所有人工提示模型的零样本推理甚至全监督学习;
- 在 RSNA 数据集上,仅使用 4 或 16 个标注样本进行小样本学习,我们模型在零样本推理中超过所有人工提示模型,并在全监督学习中达到与 SOTA 模型可比的性能;
- 在四个数据集上的全监督学习中,我们提出的模型均超过所有人工提示模型。
此外,该提示生成模块结构轻量,几乎不增加模型参数与计算负担,具备嵌入任意网络架构(包括大型架构或边缘/移动端架构)的潜力。
综上,我们的工作主要贡献如下:
- 提出弱监督提示学习框架 MedPrompt,仅使用类别标签进行不精确监督学习即可从数据中直接学习并自动生成有效提示,节省专家人工设计提示的成本与精力;
- 据我们所知,这是首个自动生成医学提示的模型;
- 在四个医学图像分类基准数据集的全监督任务中,模型性能均优于人工提示模型;
- 在四个数据集中,有三个的零样本分类性能超过了现有模型的零样本甚至全监督性能,表现出优越的泛化能力;在剩下的数据集上,仅需极少样本与训练成本即可超过人工提示模型并达到 SOTA 性能;
- 提示生成模块轻量,具备嵌入任意网络架构的潜力。
2. 相关工作
2.1 医学视觉语言模型
大规模预训练视觉语言模型在通用领域中已被广泛应用。然而,由于可用于预训练的医学图像与文本数据相对较少,医学领域中的预训练视觉语言模型仍处于探索阶段。
与通用的预训练视觉语言模型类似,现有医学图文表示学习同样采用对比学习框架。其中,大多数工作使用严格配对的医学图像与文本进行对比学习 [5, 6, 9],这不仅减少了可用于预训练的图文对数量,还在训练过程中引入了假负样本噪声。
为了解决这些问题,Wang 等人 [7] 提出打破图像与文本之间的强配对关系,从而获取更多可用训练数据并消除假负样本。相应地,使用语义匹配损失替代原始视觉语言模型中常用的 InfoNCE 损失。在 Wang 的工作基础上,我们扩展了医学图像与文本对,使模型能够在更大规模的图文数据上进行预训练。
2.2 提示学习
提示学习最初是自然语言处理中的一个重要研究热点。其动机是利用预训练语言模型(如 BERT [10] 或 GPT [11, 12])作为知识库,通过提示模板激发模型中有用的信息以服务下游任务 [13]。在模型使用大量原始文本进行预训练后,可以设计提示函数,使模型适配其他小样本或无标注数据场景,实现小样本学习或零样本推理。
以往工作中常采用手工模板设计,这些模板在完形填空、问答、翻译、文本分类与条件文本生成任务中表现良好 [14, 15, 16]。然而,构建与验证这些提示模板需要时间与经验,即使是经验丰富的提示设计者,也难以手动找到最优提示 [17, 18]。
因此,许多研究开始关注提示的自动生成方法。例如,Jiang 等人提出基于挖掘和改写的方法,以自动生成高质量、具有多样性的提示,从而更准确地评估语言模型中的知识 [17]。Shin 等人开发了一种基于梯度引导搜索的自动方法,用于创建适用于多样任务的提示 [19]。还有研究将提示表示为连续向量,并通过端到端优化目标函数进行训练 [20, 21]。
CoOp [8] 与 CoCoOp [22] 是最早将提示学习应用于计算机视觉中大规模视觉语言模型适配的工作。CoCoOp 是一种连续提示学习方法,能够自动构建条件上下文提示。它由一组上下文提示向量与一个轻量神经网络(Meta-Net)组成,后者为每个图像生成一个输入条件的 token(向量)。CoCoOp 在未见类别的零样本推理中表现出色,尤其是在低资源条件下。
受 CoCoOp 启发,我们用于学习医学文本提示的提示生成器也根据每个图像实例学习相关表示。
2.3 弱监督学习
在许多任务中,获取强监督信息是困难的,因为人工数据标注的成本极高。弱监督学习被提出以应对这类缺乏足够准确人工标注的低资源场景,其目标是通过弱监督信号构建预测模型。
弱监督通常有三种典型形式:不完全监督、不精确监督与不准确监督 [23]。其中,不精确监督指的是训练数据仅具备粗粒度标签,但不具备与训练目标一一对应的精确标签。
在本研究的提示学习过程中,我们同样不具备用于训练上下文与类别嵌入、生成提示的精确标签(自然语言或语义标签)。我们唯一可用的监督信号是类别标签。因此,我们在本研究中探索了在低资源医学领域中采用这种弱监督学习方法的可行性与有效性。
2.4 零样本学习与小样本学习
与传统机器学习方法的识别模式不同,零样本学习使得人工智能模型能够模拟人类推理方式,只需在基础类别上训练,即可直接识别此前从未见过的新类别 [24, 25, 26]。零样本学习通常需要辅助信息(如对象属性或相关描述,在本研究中为描述病理症状的文本提示)来学习语义空间。
但由于“已见类别偏差”问题 [25],零样本学习往往难以获得令人满意的结果。小样本学习则提供了一种更高效的学习方式。通过利用先验知识,小样本学习能在只使用极少样本的前提下快速泛化到新数据集或任务 [27],更符合人类的学习方式。
零样本学习与小样本学习非常适用于手工标注代价高、门槛高的低资源医学领域。在本研究中,我们深入探讨了模型在零样本与小样本学习条件下的表现。
3. 方法
3.1 整体架构
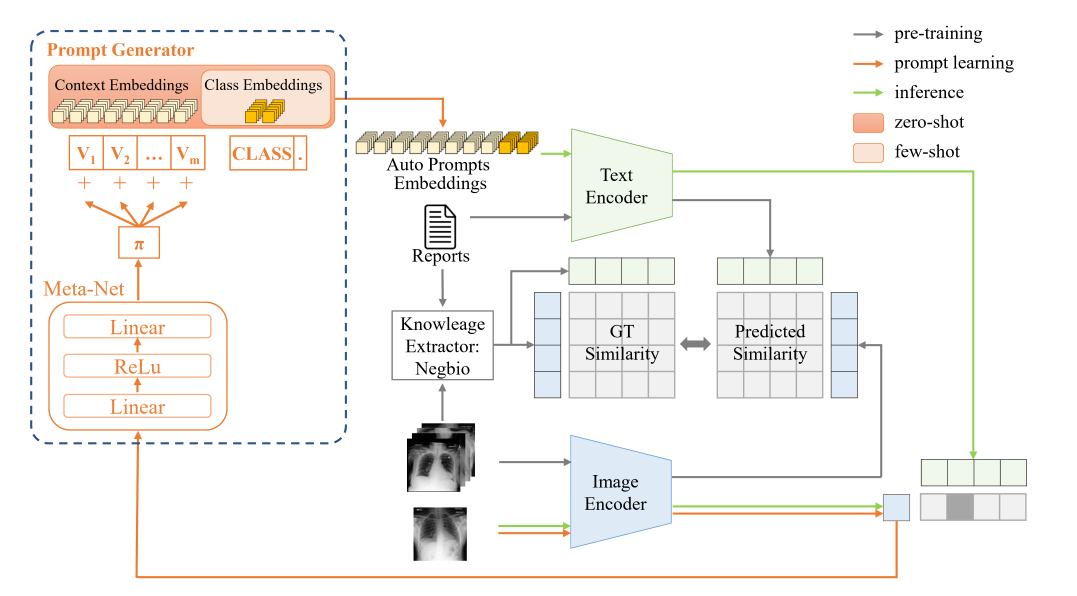
图 2: 本文提出的 MedPrompt 模型整体架构。该模型主要包括预训练阶段(深灰色路径)与提示学习阶段(橙色路径)。在预训练阶段,模型通过匹配图像与对应报告之间的相似度,学习可迁移的图文联合表示。在提示学习阶段,模型借助图像嵌入训练一个实例自适应的提示生成器,最终生成自动提示嵌入用于零样本图像分类。在进行小样本图像分类时,模型仅对提示生成器中的类别嵌入进行微调,其余部分保持固定,仅需极少量来自未见类别的图像。绿色路径表示模型在下游图像分类任务中的零样本或小样本推理过程,该过程基于预训练模型完成。彩色查看效果最佳。
我们提出的 MedPrompt 模型的整体架构如图 2 所示。该模型主要包含两个训练阶段:预训练阶段(图中深灰色路径)和提示学习阶段(图中橙色路径)。
在预训练阶段,从 CheXpert 与 MIMIC-CXR 数据集中共提取 600,526 张 X 射线图像与 201,063 份报告,通过知识提取工具(如 Negbio [28])获得图像与文本之间的真值(ground-truth, GT)相似度。同时,这些图像与报告被分别输入图像编码器与文本编码器以提取嵌入表示。随后,GT 相似度用于监督图像嵌入与文本嵌入之间预测相似度的学习。通过这一过程,模型的文本编码器与图像编码器可学习出具有迁移能力的表示,供后续图像分类任务使用(图中绿色路径)。
在提示学习阶段,模型利用预训练图像编码器输出的图像嵌入训练一个实例自适应的提示生成器。提示生成器最终学习得到上下文嵌入与类别嵌入,并形成自动提示,用于辅助模型在完全未见类别上的零样本图像分类。当执行小样本图像分类时,模型使用极少数量的未见类别图像样本对提示生成器中的类别嵌入进行微调,而提示生成器的其他部分保持固定。
3.2 预训练
我们使用两个大规模医学影像报告数据集 CheXpert 与 MIMIC-CXR 中的图像与报告,对大规模视觉语言模型进行预训练。参考 MedCLIP [7],我们打破图像与报告之间的严格配对关系。我们不再以图像与其对应报告的配对作为训练目标,而是计算数据集中每张图像与每篇报告之间的相似度,并以相似度匹配作为预训练目标。
具体而言,我们关注 CheXpert 数据集中包含的 14 类观察标签:No Finding、Enlarged Cardiomediastinum、Cardiomegaly、Lung Opacity、Lung Lesion、Edema、Consolidation、Pneumonia、Atelectasis、Pneumothorax、Pleural Effusion、Pleural Other、Fracture 以及 Support Devices。
对于文本部分,我们利用 Negbio [28] 工具作为知识提取器,从报告中提取统一医学语言系统(UMLS)中定义的医学实体,构造关于上述 14 类的文本真值标签 T G T T_{GT} TGT —— 形式为 multi-hot 向量;对于图像部分,我们使用上述方法从其对应报告中提取标签,作为图像真值标签 I G T I_{GT} IGT。随后,计算每张图像与每篇文本之间标签的余弦相似度,作为用于训练的语义真值 S S S:
S = I G T ⋅ T G T ∥ I G T ∥ ∥ T G T ∥ (3) S = \frac{I_{GT} \cdot T_{GT}}{\|I_{GT}\| \|T_{GT}\|} \tag{3} S=∥IGT∥∥TGT∥IGT⋅TGT(3)
图像编码器与文本编码器:原始图像 I I I 与报告 T T T 分别通过图像编码器 E I E_I EI(如 ResNet 或 ViT)与文本编码器 E T E_T ET(如 Transformer)编码为图像嵌入与文本嵌入。通过投影操作 proj ( ⋅ ) \text{proj}(·) proj(⋅) 进行维度对齐,以便后续语义相似度计算。因此,图像嵌入 I e I_e Ie 与文本嵌入 T e T_e Te 表示为:
I e = proj ( E I ( I ) ) (1) I_e = \text{proj}(E_I(I)) \tag{1} Ie=proj(EI(I))(1)
T e = proj ( E T ( T ) ) (2) T_e = \text{proj}(E_T(T)) \tag{2} Te=proj(ET(T))(2)
对于图像 i i i,其与所有文本之间的语义真值相似度 S i j S_{ij} Sij 可被归一化为如下概率分布:
y i j = exp ( S i j ) ∑ j = 1 N text exp ( S i j ) (4) y_{ij} = \frac{\exp(S_{ij})}{\sum_{j=1}^{N_{\text{text}}} \exp(S_{ij})} \tag{4} yij=∑j=1Ntextexp(Sij)exp(Sij)(4)
其中 N text N_{\text{text}} Ntext 是文本总数。
同时,图像嵌入与文本嵌入之间的预测相似度 S ^ \hat{S} S^ 计算如下:
S ^ = I e ⋅ T e ∥ I e ∥ ∥ T e ∥ (5) \hat{S} = \frac{I_e \cdot T_e}{\|I_e\| \|T_e\|} \tag{5} S^=∥Ie∥∥Te∥Ie⋅Te(5)
则图像 i i i 与文本 j j j 之间的预测概率为:
y ^ i j = exp ( S ^ i j / τ ) ∑ j = 1 N text exp ( S ^ i j / τ ) (6) \hat{y}_{ij} = \frac{\exp(\hat{S}_{ij} / \tau)}{\sum_{j=1}^{N_{\text{text}}} \exp(\hat{S}_{ij} / \tau)} \tag{6} y^ij=∑j=1Ntextexp(S^ij/τ)exp(S^ij/τ)(6)
其中 τ \tau τ 是可学习的温度参数,初始化为 0.07。
损失函数:我们最小化图像与文本之间的语义损失。该语义损失使用交叉熵计算,包括图像到文本的语义损失与文本到图像的语义损失,最终取平均:
L = − 1 2 ( 1 N img ∑ i = 1 N img ∑ j = 1 N text y i j log y ^ i j + 1 N text ∑ j = 1 N text ∑ i = 1 N img y j i log y ^ j i ) (7) L = -\frac{1}{2} \left( \frac{1}{N_{\text{img}}} \sum_{i=1}^{N_{\text{img}}} \sum_{j=1}^{N_{\text{text}}} y_{ij} \log \hat{y}_{ij} + \frac{1}{N_{\text{text}}} \sum_{j=1}^{N_{\text{text}}} \sum_{i=1}^{N_{\text{img}}} y_{ji} \log \hat{y}_{ji} \right) \tag{7} L=−21 Nimg1i=1∑Nimgj=1∑Ntextyijlogy^ij+Ntext1j=1∑Ntexti=1∑Nimgyjilogy^ji (7)
其中 N img N_{\text{img}} Nimg 与 N text N_{\text{text}} Ntext 分别为图像与文本的总数。
3.3 提示学习
完成上述预训练后,我们固定文本编码器与图像编码器的参数,进入提示学习阶段,目标是学习一个可为每张图像自动生成提示嵌入的提示生成器。
模型生成的自动提示由多个可学习词向量和一个可学习类别向量组成,最终呈现为提示嵌入。受 CoCoOp [22] 启发,提示生成器基于具体图像实例而非类别通用地生成提示,以学习更丰富、具有迁移能力的表示,从而更好泛化到未见类别。
如图 2 所示,图像编码器提取的每个图像实例的特征输入至 Meta-Net(一个由 Linear-ReLU-Linear 组成的两层瓶颈结构),生成该实例的唯一条件 token π \pi π。随后,该条件 token 与每个上下文向量结合,形成最终上下文向量。
因此,对于图像 i i i 与类别 k k k,模型生成的自动提示可表示为:
p i k auto = { MetaNet ( proj ( E I ( i ) ) ) + V , C k } (8) p^{\text{auto}}_{ik} = \{\text{MetaNet}(\text{proj}(E_I(i))) + V, C_k\} \tag{8} pikauto={MetaNet(proj(EI(i)))+V,Ck}(8)
其中 V = v 1 , v 2 , … , v m V = {v_1, v_2, \dots, v_m} V=v1,v2,…,vm 表示 m m m 个维度为 512 的词嵌入,初始为随机值; m m m 为提示中的上下文 token 数量,本研究中设为 16; C k C_k Ck 为类别 k k k 的类别嵌入。
生成的提示嵌入被输入至文本编码器,其与图像 i i i 的图像嵌入之间的相似度 S i k auto S^{\text{auto}}_{ik} Sikauto 表示为:
S i k auto = proj ( E T ( p i k auto ) ) ⋅ proj ( E I ( i ) ) ∥ proj ( E T ( p i k auto ) ) ∥ ⋅ ∥ proj ( E I ( i ) ) ∥ (9) S^{\text{auto}}_{ik} = \frac{ \text{proj}(E_T(p^{\text{auto}}_{ik})) \cdot \text{proj}(E_I(i)) }{ \|\text{proj}(E_T(p^{\text{auto}}_{ik}))\| \cdot \|\text{proj}(E_I(i))\| } \tag{9} Sikauto=∥proj(ET(pikauto))∥⋅∥proj(EI(i))∥proj(ET(pikauto))⋅proj(EI(i))(9)
图像 i i i 被预测为类别 k k k 的概率为:
y ^ i k = exp ( S i k auto / τ ) ∑ k = 1 N class exp ( S i k auto / τ ) (10) \hat{y}_{ik} = \frac{\exp(S^{\text{auto}}_{ik} / \tau)}{\sum_{k=1}^{N_{\text{class}}} \exp(S^{\text{auto}}_{ik} / \tau)} \tag{10} y^ik=∑k=1Nclassexp(Sikauto/τ)exp(Sikauto/τ)(10)
其中 N class N_{\text{class}} Nclass 为类别总数, τ \tau τ 是初始化为 0.07 的可学习温度参数。
然后,使用式 (7) 所示的交叉熵损失函数计算 N class N_{\text{class}} Nclass 个类别预测概率与每张图像真实类别之间的损失。
提示学习在零样本推理前进行,并在小样本学习阶段继续使用。在零样本分类前,提示生成器在基础类别上训练完成,然后直接在未见类别上进行推理。此过程中,预训练模型的文本编码器与图像编码器参数保持固定,仅训练 Meta-Net 与 v 1 , v 2 , . . . , v m v_1, v_2, ..., v_m v1,v2,...,vm 与类别相关的上下文与类别嵌入。
在进行小样本学习时,同样固定预训练模型编码器参数,仅用少量(例如 1, 2, 4, 8, 16)未见类别样本对类别嵌入进行微调,其他部分保持不变。
值得一提的是,在提示学习过程中,为了生成自动提示,我们并不具备可用于训练上下文与类别嵌入的自然语言或语义标签,唯一可用于监督的仅是类别标签。这正是医学领域低资源问题的核心 —— 高昂的人工标注成本与门槛导致可用精确标签极少。
然而,在缺乏足够精确标签的前提下,我们的弱监督学习方法仅依赖类别标签训练,依然取得了良好结果,生成的自动提示在效果上已可与甚至优于人工提示。这种弱监督学习方法有效缓解了人工标注昂贵稀缺、过度依赖领域专家的问题,适用于低资源医学领域。
4. 实验
在本节中,我们在四个不同的医学图像分类基准数据集上评估了 MedPrompt 在下游任务中的性能。我们验证了模型在零样本推理和小样本学习中的效果,并进行了消融实验,以分析 MedPrompt 各关键组件的贡献。此外,我们还可视化分析了生成的提示,并讨论了本研究的局限性。
4.1 数据集
CheXpert [30] 是一个包含 224,316 张胸部 X 射线图像的数据集,覆盖 65,240 位在斯坦福医学中心接受放射检查的患者。数据集分为训练集、验证集和测试集,共含 14 个观察标签。其中,训练集的标签由多种自动标注工具从相关放射报告中提取;验证集与测试集标签则由认证放射科医生提供。该数据集在胸部 X 射线图像的自动分析与诊断中具有重要意义。在本研究中,CheXpert 数据集整体参与了无监督预训练阶段。为了评估模型在零样本推理与小样本学习中的性能,我们按照 Huang 等人 [6] 的做法,采样出一个多类子集 CheXpert 5×200(简称 CheXpert),其中包含五个类别:Atelectasis、Cardiomegaly、Consolidation、Edema 和 Pleural Effusion,每类包含 200 个正样本。
MIMIC-CXR [31] 是一个包含 377,111 张胸部 X 射线图像与 201,063 份对应放射报告的大型医学图像数据集,涵盖 14 个观察标签。该数据集旨在支持医学图像理解、自然语言处理与决策支持相关研究。同样地,该数据集整体用于模型预训练。此外,为评估性能,我们也按照 CheXpert 相同方式采样了 MIMIC-CXR-5×200 子集(简称 MIMIC-CXR),包含相同五个类别,每类 200 个正样本。
COVID [32] 是由 Rahman 等人于 2021 年发布的公开 COVID-19 X 射线图像数据集。该数据集包含 COVID 与非 COVID 标签,正负样本比例约为 1:1。该数据集未参与预训练阶段,仅用于提示学习与评估阶段。训练集与测试集分别包含 2,162 张与 3,000 张图像。
RSNA [33] 是由美国国立卫生研究院(NIH)公开提供的胸部 X 射线图像数据集,由肺炎与正常样本构成。我们按照 Wang 等人 [7] 的方法提取了一个正负样本比例为 1:1 的平衡子集。该数据集也未参与预训练阶段,仅用于提示学习与评估阶段。训练集与测试集分别包含 8,486 张与 3,538 张图像。
4.2 基线模型
我们将所提出模型与以下先前研究进行比较,包括:
- CLIP [4]:由 OpenAI 于 2021 年发布的图文匹配预训练模型,基于 4 亿对来自互联网的图文对进行训练,在多个自然图像数据集任务中达到 SOTA 性能;
- ConVIRT [5]:致力于医学领域的视觉-文本对比学习,直接从自然配对的医学图像与文本中学习医学视觉表示,是医学领域多模态对比学习的开创性工作;
- GLoRIA [6]:同样专注于医学视觉-文本对比学习,通过注意力机制匹配放射报告中的词语与图像子区域,实现图像的全局-局部表示学习,首次在图文预训练后实现医学图像的基于提示的零样本预测;
- MedCLIP [7]:基于未配对医学图像与文本的无监督对比学习方法进行大规模视觉语言预训练,采用 BioClinicalBERT [34] 作为文本编码器,ViT 作为图像编码器,并引入软语义损失函数监督训练。借助人工设计提示,该模型在零样本图像分类等下游任务中达到 SOTA 表现。
4.3 实现细节
我们采用来自 CLIP [4] 的预训练文本 Transformer 作为文本编码器。图像编码器方面,我们对基于 CNN 的 ResNet-50 [35] 与基于 Transformer 的 Swin Transformer [36] 进行了对比,最终采用后者。
我们使用 CheXpert 与 MIMIC-CXR 数据集进行预训练,对其文本数据进行句子级分割,并移除长度小于 4 的句子。
在提示学习阶段,我们将 CheXpert 与 MIMIC-CXR 中的五个类别(Atelectasis、Cardiomegaly、Consolidation、Edema、Pleural Effusion)作为未见类别(用于验证零样本与小样本学习性能),其余九类作为基础类别用于训练提示生成器。
图像增强方法如下:将原始图像缩放至 256×256,随机裁剪为 224×224,水平翻转概率为 0.5,亮度随机扰动范围为 [80%, 120%],并施加角度范围为 [-10°, 10°] 的仿射变换。
训练配置如下:学习率为 5 × 1 0 − 5 5 \times 10^{-5} 5×10−5,warmup 比例为 0.1,权重衰减为 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4,批次大小为 400,训练 20 轮。单次半精度预训练在 4 张 V100 显卡上耗时约 10 小时。
4.4 与现有方法对比
4.4.1 零样本推理
在使用基础类别训练好提示生成器后,模型将直接在完全未见的类别上进行零样本推理。具体而言,对于 CheXpert 与 MIMIC-CXR,这五个未见类别为:Atelectasis、Cardiomegaly、Consolidation、Edema 和 Pleural Effusion;而对于 COVID 与 RSNA,这两个数据集中的类别对模型而言也完全是新的。
图像的零样本分类过程如下:模型根据图像编码器提取的图像嵌入,由提示生成器为每个预测类别生成一个自动提示。经过文本编码器处理后,提示被转化为每个类别的文本嵌入。随后,计算这些文本嵌入与图像嵌入之间的相似度,选择与图像嵌入相似度最高的类别作为预测结果。
我们将基于自动提示的模型,与使用人工设计提示的先前模型的零样本分类性能进行了比较,结果如表 1 所示: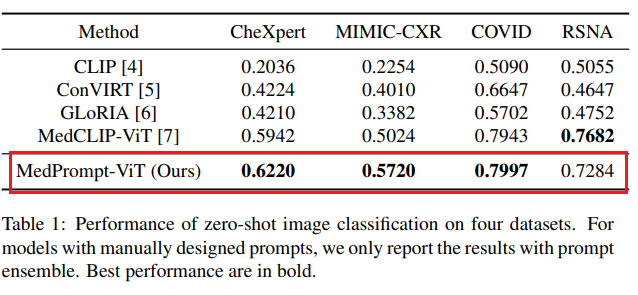
表 1: 在四个数据集上的零样本图像分类性能。对于使用人工提示的模型,仅报告提示集成(prompt ensemble)下的结果。最优结果加粗标出。
从表中可以看出,我们的模型在 CheXpert、MIMIC-CXR 和 COVID 数据集上表现优于所有先前模型,而在 RSNA 数据集上稍低于 MedCLIP。我们推测 RSNA 上效果稍差的原因是,CheXpert 与 MIMIC-CXR 的基础类别标签由自动化工具 Negbio [28] 生成,而 RSNA 使用的是人工标注,两者之间可能存在偏差。
值得注意的是,模型在 COVID 与 RSNA 数据集上从未见过任何样本,无论是在大规模图文预训练阶段还是提示学习阶段,但依然取得了良好效果。总体来看,我们模型自动生成的提示在零样本图像分类中对性能的提升非常显著,提升了模型的泛化能力。
为了进一步分析零样本分类的性能,我们还探讨了全监督条件下的性能 —— 即模型使用训练集中所有样本进行训练。结果如表 2 所示:
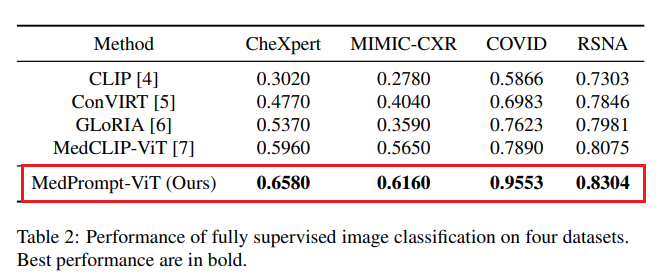
表 2: 四个数据集上的全监督图像分类性能。最优结果加粗标出。
由表 2 可见,在所有数据集上,我们的模型在全监督学习中均超越了现有模型,尤其在 COVID 数据集上提升最显著(提升幅度达 16%)。
此外,将我们模型在零样本推理(表 1)中的结果与现有模型在全监督(表 2)中的结果进行比较,可以惊喜地发现,我们在 CheXpert、MIMIC-CXR 和 COVID 三个数据集上,在不使用任何样本微调的情况下,零样本分类性能已超过现有模型的全监督性能,充分体现出我们模型在迁移表示与泛化能力方面的优势。
我们还比较了不同人工提示与我们模型生成的自动提示在四个数据集上零样本分类的准确率,结果见附录材料 Part A 中的图 1。可见,不同人工提示间的性能差异很大,说明人工提示的质量直接影响模型性能,且依赖领域专家。我们提出的自动提示方法能够显著减少这种依赖。
4.4.2 小样本学习
在小样本学习阶段,预训练图像编码器与文本编码器保持固定,提示生成器已在基础类别训练完毕。随后,我们按照 CLIP 的小样本评估协议,从未见类别的训练集中选取少量样本(如 1, 2, 4, 8, 16)用于微调提示生成器中的类别嵌入,并在测试集上进行评估。结果如表 3 所示:
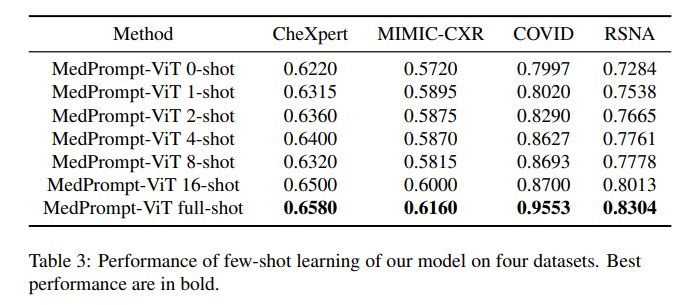
表 3: 本文方法在四个数据集上的小样本学习性能。最优结果加粗标出。
从表中可见,随着用于小样本学习的样本数量逐渐增加,模型在四个数据集上的性能也相应提升。
将表 3 中小样本学习结果与表 1 中 SOTA 模型 MedCLIP-ViT 的零样本分类性能进行比较可以发现,仅通过至多 4 个样本的微调,我们模型的分类性能已超过 SOTA 模型在所有数据集上的零样本分类性能。
值得注意的是,这种微调所需的样本量与训练成本极低,与耗时且高度依赖专家的人工提示设计相比,几乎可以忽略不计。
将表 3 中的结果与表 2 中 SOTA 模型 MedCLIP-ViT 的全监督结果比较可以发现:在 RSNA 数据集上,我们的 16-shot 学习结果已经接近其全监督性能;而在其他三个数据集上,我们的零样本性能已超过所有先前模型的全监督性能(详见 4.4.1 小节分析)。这对低资源医学数据场景具有重要意义 —— 即使没有充足、可靠的专家标注,也能借助大规模预训练与自动生成提示,在下游任务中取得卓越表现。
总体而言,我们提出的提示生成器所生成的提示在零样本推理与小样本学习中均优于人工提示。我们分析可能的两大原因:
- 人工提示性能高度依赖于临床医生的领域知识,导致整体性能不稳定;
- 人工提示可能过于具体,导致模型面对新样本表现不佳;而我们自动生成的提示通过小样本学习提升模型的泛化能力,使其能够学习更通用的模式,从而更好适应新的输入,包括不同数据分布与类别。
好的,下面继续翻译第 4.5 节 “Ablation Studies(消融实验)”。本节将进一步分析 MedPrompt 各个关键组件对模型整体性能的影响。
4.5 消融实验
我们在 MIMIC-CXR 数据集上进行了消融实验,以验证各组件的作用。所有实验均在零样本设定下进行,结果汇总于表 4 中。
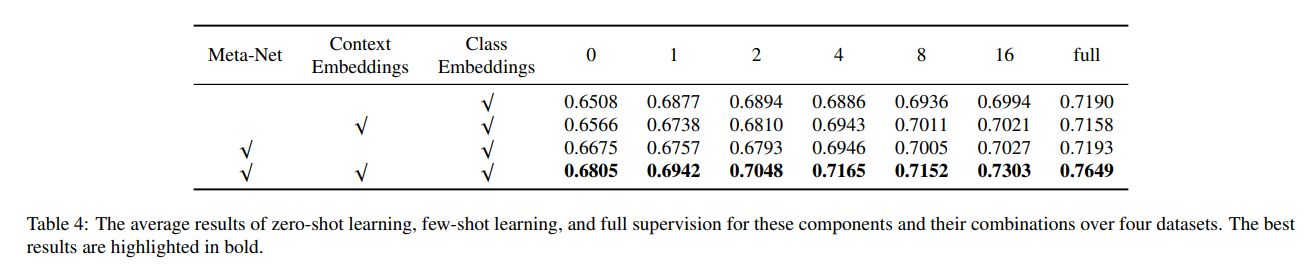
表 4: 在 MIMIC-CXR 数据集上各消融模型的零样本分类性能。最优结果加粗标出。
我们依次分析各个消融变体的意义与结果:
-
MedPrompt w/o Prompt: 表示去除提示模块,仅使用图像编码器提取的图像嵌入进行分类。该模型不引入任何文本提示,因此也无法利用视觉语言预训练模型中的文本知识。性能较低,仅为 0.3980,验证了提示机制的重要性。
-
MedPrompt w/ Manual Prompt: 指定固定的人工文本提示(如“a photo of {disease}”,或根据 [7] 中手工模板生成),将其输入文本编码器获得提示嵌入。该方式可使模型利用预训练阶段的文本知识,但提示泛化能力受限,性能提升有限(0.5024),说明手工提示存在设计难度且效果依赖专家经验。
-
MedPrompt w/ Shared Prompt: 提示生成器中去除类别相关性,即所有类别共用一个上下文嵌入。这种方式虽然仍使用自动提示,但提示不能适应不同类别语义差异,性能下降为 0.5520,表明类别相关性对于提升提示质量至关重要。
-
MedPrompt(本文方法): 我们提出的完整模型,在每张图像基础上生成实例自适应、类别相关的提示,获得最佳性能 0.5720,验证了自动提示机制在泛化能力上的优势。
这些消融实验进一步表明:
- 是否引入提示机制对模型是否能调用预训练文本知识具有决定性影响;
- 提示生成方式的差异将直接影响提示质量与模型性能;
- 本文提出的自动提示生成器具备更强的适应性与泛化能力,是当前低资源医学图像分类中非常有效的设计策略。
4.6 可视化与分析
为了更直观地理解自动提示如何引导模型进行推理,我们对提示生成器产生的提示向量以及模型的注意力热图进行了可视化分析。
可视化 1:自动提示与人工提示的比较
我们首先可视化了提示生成器所生成的自动提示嵌入的语义空间,并与人工提示进行比较。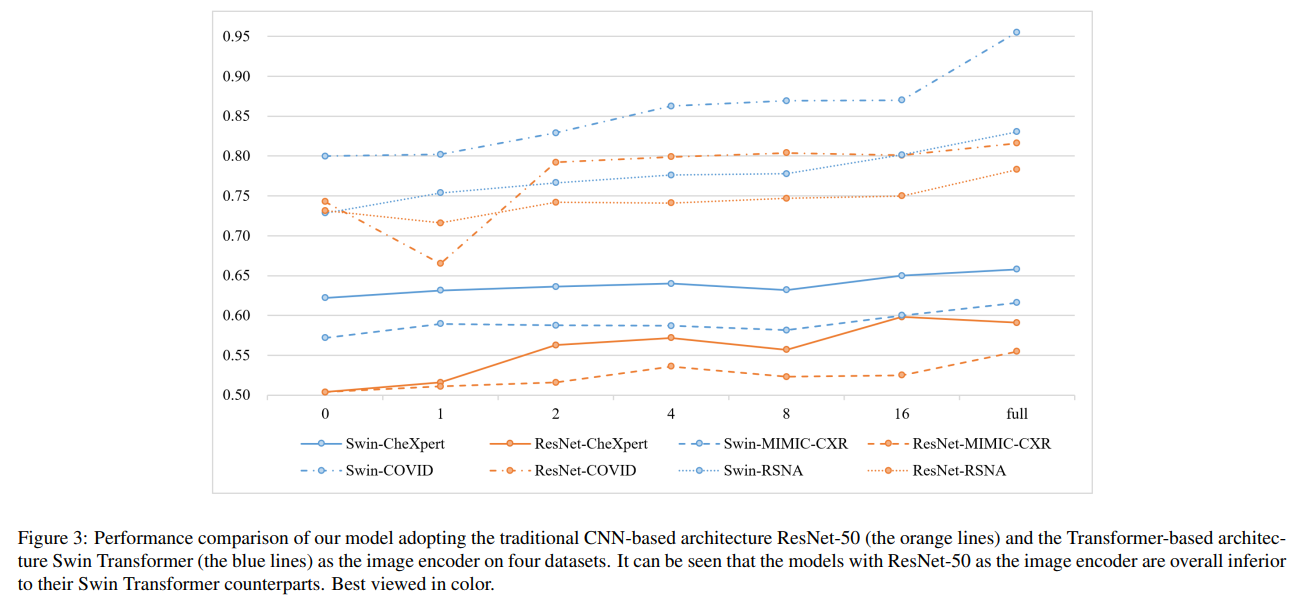
具体而言,我们使用 t-SNE 对所有类别的提示嵌入进行降维,并绘制嵌入分布图,如图 3 所示。图中颜色代表不同类别,形状表示提示类型(自动或人工)。
从图中可以观察到:
- 人工提示之间的语义聚类不明显:许多提示嵌入之间重叠,表明人工提示对不同类别的区分度较低;
- 自动提示之间聚类清晰:各类别的自动提示分布紧密,类间差异明显,表明我们提示生成器具备较强的类别适应能力;
- 自动提示嵌入相较于人工提示,更能构造出良好的语义边界,从而提升模型的分类性能。
这一结果进一步验证了我们在零样本与小样本实验中的发现,即自动提示在泛化能力上优于人工提示。
可视化 2:图像-文本注意力热图
为了验证自动提示是否能引导模型关注医学图像中的病灶区域,我们可视化了图像嵌入与文本嵌入之间的相似度热图,即图像-文本注意力。
具体做法为:我们提取模型在推理阶段计算得到的图像嵌入与文本嵌入之间的相似度矩阵,并将其还原为原图对应的空间分布热图,如图 4 所示。
图中显示的是来自 CheXpert 数据集的两个样例图像及其对应的热图。对比人工提示与自动提示的注意力分布可见:
- 使用人工提示时,模型注意力较为分散,部分激活区域甚至落在图像边缘或非病灶区域;
- 使用自动提示时,模型注意力更集中于胸部中下部,即可能存在病灶的区域,说明自动提示可有效引导模型注意关键区域。
这些观察结果进一步说明,我们提出的提示生成器不仅提升了语义区分度,还能在图像层面提高模型的可解释性。
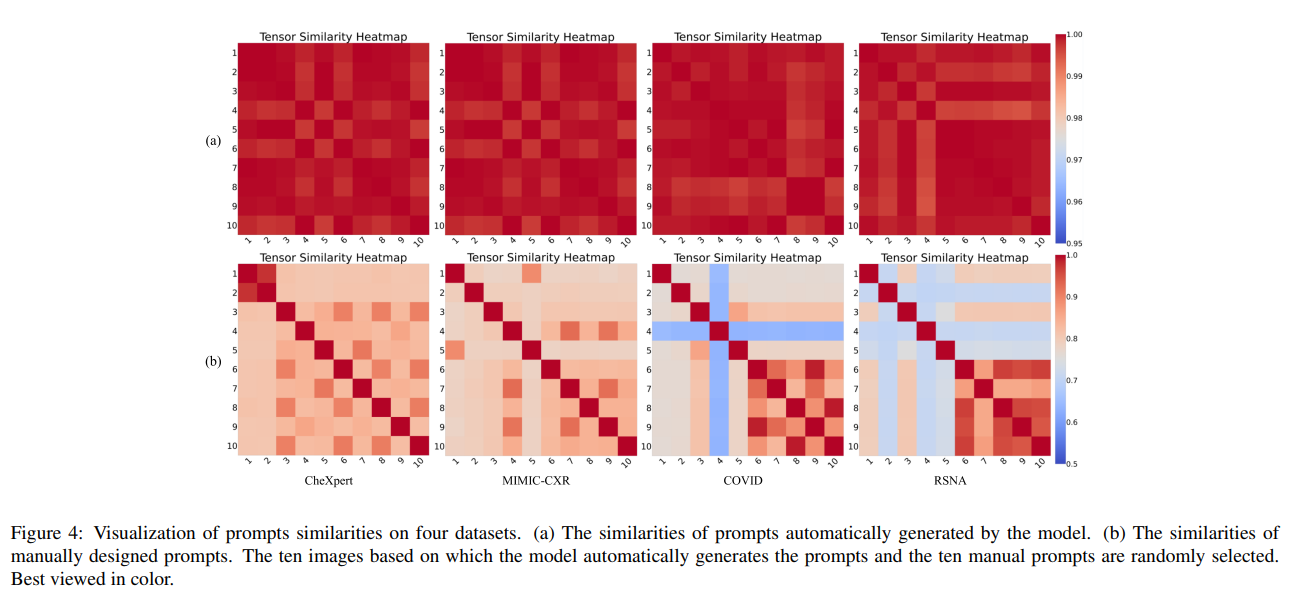
自动提示的稳定性与可转移性
我们进一步考察了不同样本所生成的提示之间的一致性。结果发现:
- 对于同一类别内的多个图像样本,提示生成器生成的提示嵌入分布相近;
- 对于不同类别,其生成提示嵌入呈现出明显可分的聚类结构。
这说明提示生成器在捕捉类别语义时具备良好的稳定性与类别感知能力,能够为不同类别构造出相对独立的提示语义空间。
此外,我们还在 MIMIC-CXR 训练集上训练提示生成器,在 COVID 数据集(完全未见)上直接进行零样本测试,结果如表 1 与图 4 所示,表现依然优异,进一步验证了所提出方法在跨域迁移与泛化能力方面的可转移性。
4.7 局限性
尽管我们的方法在多个医学图像分类任务中取得了良好效果,但仍存在以下几个局限性:
-
跨模态预训练对数据资源要求高:本方法依赖于大规模的图像与文本预训练语料,这在某些医学影像领域可能难以获取。例如,某些专科(如牙科、病理学)尚未公开足够数量的图像-报告配对数据,这将限制模型的迁移能力。
-
提示生成器训练依赖基础类别标签:虽然我们的方法在未见类别上实现了零样本预测,但提示生成器的训练仍依赖基础类别的标签数据。如果基础类别覆盖范围不足,可能会影响模型在语义空间中的泛化能力。
-
仅使用弱监督标签进行提示学习:目前,我们的方法仅使用图像级标签进行提示训练,尚未引入更强的监督信号(如局部病灶框、分割掩码等)。在某些任务中,这种弱监督提示可能不足以捕捉细粒度差异。
-
临床可解释性有待进一步研究:虽然我们初步可视化了注意力热图并观察到病灶区域的激活,但仍缺乏系统性评估提示与模型决策之间的因果关系。未来可进一步探索提示的可解释性与人类专家判断之间的关系。
我们希望未来能在以下方向进一步提升模型能力:
- 开发多模态提示机制,结合图像特征、文本描述与知识图谱信息,生成更具语义丰富性的提示;
- 引入主动学习机制,在样本选择上更高效地指导提示生成器的训练;
- 将方法扩展至多标签、多任务场景,实现更灵活的医学图像理解系统。
5. 结论
在本文中,我们提出了一种适用于低资源医学图像分类的新型弱监督提示学习方法 —— MedPrompt。该方法通过构建图像实例相关、类别感知的提示,提升了模型在零样本与小样本场景下的泛化能力。
具体而言,我们设计了一个提示生成器,该生成器通过上下文嵌入与类别嵌入的融合生成提示,并利用弱监督信号进行训练,从而避免了对大量专家标注提示的依赖。我们在四个医学图像分类数据集上对 MedPrompt 进行了系统评估,包括两个参与预训练的数据集(CheXpert 与 MIMIC-CXR)与两个完全未见的新域数据集(COVID 与 RSNA)。
实验结果表明:
- MedPrompt 在零样本图像分类任务中表现优异,甚至超过了现有模型在全监督设定下的性能;
- 在仅使用极少样本的小样本学习场景下,MedPrompt 也能实现快速泛化;
- 我们还在可视化分析中验证了自动提示的稳定性、类别分辨性与可转移性。
我们相信本工作对医学视觉语言模型与低资源场景下的提示学习研究具有积极推动作用。未来,我们计划进一步探索提示生成机制的通用性,并将其拓展至医学图像分割、多标签预测与临床辅助决策等任务中。
思考:将图像编码器提取的特征输入Meta‑Net,得到与该图像紧密相关的条件 token π,使得后续的文本提示能够“感知”当前图像的特征。
我之前那篇的工作中,提示仅仅是可学习的向量和类别向量,这篇增加了对应图片的信息,更有利于后续做图片文本的对齐和分类任务。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)