3分钟带你搞清 LSTM 的计算过程和计算图
LSTM(长短时记忆网络)通过创新的门控机制解决了RNN的长时依赖问题。其核心在于三个关键门控单元:遗忘门决定保留哪些历史信息,输入门筛选新的重要信息,输出门控制当前记忆的输出。记忆单元通过加法更新而非RNN的乘法运算,有效避免了信息稀释。这种"记忆单元+三门控"的设计使LSTM能够精准控制信息流,既能保存长期依赖关系,又能灵活更新短期记忆,在自然语言处理、语音识别等序列任务中
在深度学习的技术版图中,有两大 “明星选手” 始终占据重要地位:卷积神经网络(CNN)凭借强大的空间特征提取能力成为图像领域的标杆,而长短时记忆网络(LSTM)则凭借独特的时序信息处理能力,在自然语言处理、语音识别、时间序列预测等依赖序列数据的任务中大放异彩。今天,我们就来一步步拆解 LSTM 的核心原理和计算过程,揭开它如何让 AI 拥有 “长效记忆” 的奥秘。
一、LSTM为何诞生?—— 解决RNN的 “健忘症”
简单的循环神经网络(RNN)虽然能处理时序数据(如文字、语音等按顺序出现的数据),但存在一个致命缺陷:长时依赖问题。就像人类在听超长故事时容易忘记开头的细节,RNN 在处理长序列时,早期的关键信息会随着网络层数增加逐渐 “稀释”,最终导致模型无法捕捉远距离的依赖关系(比如一句话中开头的 “他” 和结尾的 “小明” 其实是同一个人)。
而 LSTM(Long Short-Term Memory,长短时记忆网络)的诞生,正是为了攻克这一难题。它通过设计专门的记忆存储单元和 “门控机制”,让模型既能记住重要的长时信息,又能灵活更新短期信息,完美解决了 RNN 的 “健忘症”。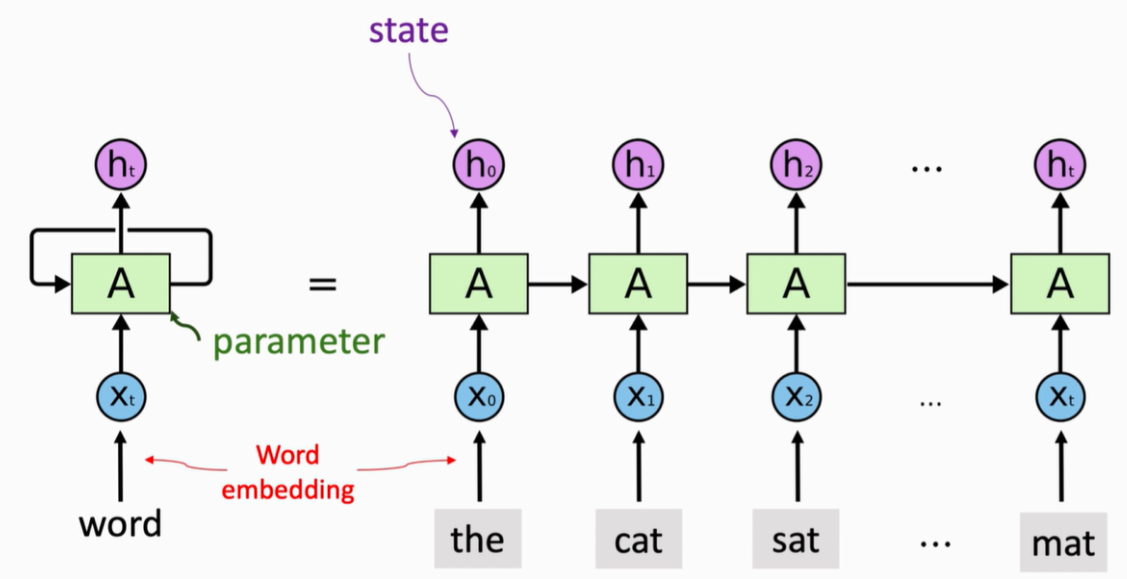
二、LSTM的核心要素:3个关键 “角色”
想要理解 LSTM 的工作原理,首先要记住三个核心要素,它们就像构成 LSTM 的 “基本零件”:
输入 xt:当前时刻的输入数据(比如一句话中的某个词、一段语音中的某个片段)。
- 输出 ht:当前时刻的模型输出(比如对当前词的语义编码、对当前语音片段的识别结果)。
- 记忆单元 ct:LSTM 的 “核心记忆库”,专门用于存储和传递时序信息,也是它能记住长时依赖的关键。
三、LSTM的 “智能闸门”:3道门控机制
LSTM 的 “聪明之处” 在于它通过三个 “门控单元” 对记忆进行精准控制,就像人类大脑会主动筛选 “该记什么、该忘什么、该输出什么”。这三道门分别是:
1. 遗忘门(Forget Gate):决定 “该忘记什么”
遗忘门的作用是筛选上一时刻的记忆,过滤掉无关紧要的信息。它就像一个 “过滤器”,通过计算决定对上一时刻的记忆 ct−1 保留多少、丢弃多少。
- 计算方式:结合当前输入 xt 和上一时刻输出 ht−1,通过权重矩阵 Wf 和偏置 bf 转换后,再经过 sigmoid 激活函数 处理,输出一个 0~1 之间的值(0 表示完全遗忘,1 表示完全保留)。
公式:ft=σ(Wf⋅[ht−1,xt]+bf)
2. 输入门(Input Gate):决定 “该记住什么新信息”
输入门负责筛选当前时刻的新信息,决定哪些内容值得存入记忆单元。同时,它还会生成当前输入的 “候选记忆”,供后续更新记忆库使用。
- 计算方式:
① 输入门控制值:通过当前输入 xt 和上一时刻输出 ht−1 经权重 Wi、偏置 bi 和 sigmoid 激活函数计算,输出 0~1 之间的控制值。
公式:it=σ(Wi⋅[ht−1,xt]+bi)
② 候选记忆:当前输入经权重 Wc、偏置 bc 和 双曲正切(tanh)激活函数 处理,生成范围在 -1~1 之间的候选记忆。
公式:c~t=tanh(Wc⋅[ht−1,xt]+bc)
3. 输出门(Output Gate):决定 “该输出什么记忆”
输出门控制当前时刻的记忆单元 ct 中哪些信息会被输出为 ht,同时 ht 会作为下一时刻的输入继续传递。
计算方式:
① 输出门控制值:通过当前输入 xt 和上一时刻输出 ht−1 经权重 Wo、偏置 bo 和 sigmoid 激活函数计算,输出 0~1 之间的控制值。
公式:ot=σ(Wo⋅[ht−1,xt]+bo)
② 当前输出:将记忆单元 ct 经 tanh 激活函数处理后,与输出门控制值相乘,得到当前输出 ht。
公式:ht=ot⋅tanh(ct)
四、LSTM 的完整计算流程:记忆如何更新与传递?
结合上述三个门控单元,LSTM 某一时刻的计算流程可以总结为以下步骤(配合计算图更易理解):
-
更新记忆单元:
用遗忘门过滤上一时刻的记忆 ct−1,再加上输入门筛选后的新候选记忆,得到当前时刻的记忆 ct。
公式:ct=ft⋅ct−1+it⋅c~t -
生成当前输出:
用输出门控制当前记忆 ct 的输出比例,得到当前输出 ht,同时 ht 和 ct 会传递到下一时刻,继续参与计算。
五、LSTM 计算图:直观理解门控交互关系
为了更清晰地展示 LSTM 的工作流程,我们可以通过计算图直观呈现各元素的交互关系:
plaintext
[上一时刻输出 h_{t-1}] ───┬─────────────────────────────────┐
│ │
[当前输入 x_t] ─────────────┼─────────────────────────────────┼───→ [拼接输入 [h_{t-1}, x_t]]
│ │
▼ ▼
遗忘门计算 f_t = σ(...) 输入门计算 i_t = σ(...)
│ │
▼ ▼
[上一时刻记忆 c_{t-1}] ───→ [× f_t] 候选记忆 ã_c_t = tanh(...) ─→ [× i_t]
│ │
└───────────────┬─────────────────┘
▼
当前记忆 c_t = 相加结果
│
▼
tanh(c_t)
│
[拼接输入 [h_{t-1}, x_t]] ───→ 输出门计算 o_t = σ(...) ─→ [× o_t] ─→ 当前输出 h_t
从图中可以看出,LSTM 始终围绕 “记忆单元 ct” 展开,通过遗忘门、输入门、输出门的协同作用,实现对时序信息的精准筛选、更新和传递。
六、为什么 LSTM 能处理长序列?
LSTM 之所以能解决 RNN 的长时依赖问题,核心在于:
- 记忆单元 ct 的持续传递:记忆信息通过加法直接更新,避免了 RNN 中 “乘法稀释” 导致的信息丢失。
- 门控机制的精准控制:遗忘门和输入门可以动态调整记忆的保留与更新,让重要信息能跨越更长的时间步传递。
例如在机器翻译任务中,一句话开头的 “主语” 可以通过记忆单元被长期保留,直到翻译到结尾需要呼应时再通过输出门提取,确保语义连贯。
总结
LSTM 作为处理时序数据的核心模型,通过 “记忆单元 + 三门控机制” 的设计,完美弥补了 RNN 的 “健忘” 缺陷。其核心逻辑可以概括为:用遗忘门清理旧记忆,用输入门存储新信息,用输出门控制输出内容,最终实现对长时序信息的有效捕捉。
理解 LSTM 的计算过程不仅能帮助我们更好地应用模型,更能启发我们思考 “如何让 AI 像人类一样高效记忆与学习”。下次再遇到涉及序列数据的任务,不妨试试用 LSTM 来解锁 “长效记忆” 的能力吧!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)