【CVPR2025】基于离散扩散时间步令牌的生成式多模态预训练
近期在多模态大型语言模型(MLLMs)领域的研究致力于通过结合大型语言模型(LLM)与扩散模型(分别在各自任务中处于最先进水平),实现视觉理解与生成的统一。然而,我们指出,空间令牌缺乏语言中固有的递归结构,因此形成了一种大型语言模型难以掌握的“不可学习语言”。在本文中,我们通过利用扩散时间步来学习离散的、递归的视觉令牌,从而构建了一种合适的视觉语言。这一方法使我们能够有效整合大型语言模型在自回归推

来源:专知
本文约1000字,建议阅读5分钟
我们通过利用扩散时间步来学习离散的、递归的视觉令牌,从而构建了一种合适的视觉语言。
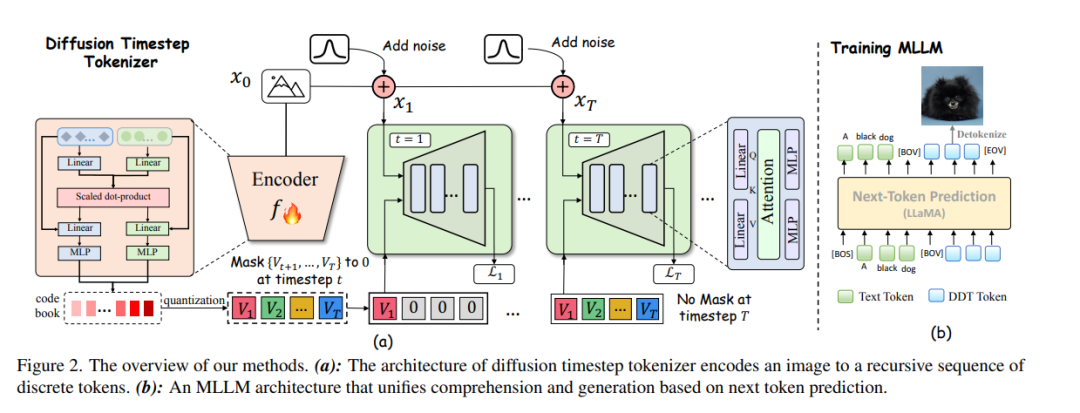
近期在多模态大型语言模型(MLLMs)领域的研究致力于通过结合大型语言模型(LLM)与扩散模型(分别在各自任务中处于最先进水平),实现视觉理解与生成的统一。现有方法通常依赖于空间视觉令牌,即将图像块编码后按照空间顺序(例如光栅扫描顺序)排列。然而,我们指出,空间令牌缺乏语言中固有的递归结构,因此形成了一种大型语言模型难以掌握的“不可学习语言”。
在本文中,我们通过利用扩散时间步来学习离散的、递归的视觉令牌,从而构建了一种合适的视觉语言。我们提出的视觉令牌能够递归地补偿在噪声图像中随时间步增加而逐步丧失的属性,使扩散模型能够在任意时间步重建原始图像。这一方法使我们能够有效整合大型语言模型在自回归推理方面的优势与扩散模型在精确图像生成方面的优势,在统一框架内实现无缝的多模态理解与生成。
大量实验表明,我们在多模态理解与生成任务上同时达到了优于其他MLLMs的方法性能。项目页面:https://DDTLLaMA.github.io/
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)