NVIDIA AI端到端应用开发实践
通过云 API 快速验证想法 -> 必要时使用 AI Workbench 进行低成本的 LoRA 微调 -> 依赖 NIM 内置的 TensorRT-LLM 完成极致优化 -> 选择匹配业务需求的部署模式。收集一批高质量的私房菜谱数据,用 LoRA 微调模型,使其风格更独特。构建一个 RAG 系统,将庞大的美食知识库作为模型的外部参考,让生成的食谱更精准、可溯源(例如,准确指出“宫保鸡丁”的正宗做
NVIDIA NIM平台食谱生成的具体实现
🧠 理解NVIDIA NIM平台
NVIDIA NIM平台,是NVIDIA推出的一套推理微服务,旨在简化生成式AI模型的部署和应用。它的核心特点包括:
| 部署方式 | 适用场景 | 关键特点 | 复杂度 |
|---|---|---|---|
| NVIDIA NIM API | 快速原型开发、学习和测试 | 通过云API调用,无需本地硬件;简单快捷 | 低 |
| 自托管容器 | 数据安全敏感、离线运行或生产环境 | 将容器部署在自己的服务器或工作站上,数据完全本地控制 | 中 |
| 集成于企业平台 (如Kubernetes) | 大规模、可扩展的生产级部署 | 与Kubernetes、KServe等集成,支持动态扩缩容和高可用性 | 高 |
🍳 生成DIY食谱:实现步骤与代码
文章中的食谱生成示例,核心是使用Python通过NVIDIA NIM提供的、与OpenAI兼容的API来调用大语言模型。其主要步骤与简化后的代码如下:
-
环境准备:安装必要的Python库,主要是OpenAI客户端。
pip install openai -
获取API密钥:在NVIDIA官网注册并获取API密钥。
-
调用API生成食谱:核心是利用模型根据用户输入的食材生成回复。
from openai import OpenAI # 1. 初始化客户端,指向NVIDIA NIM的API端点 client = OpenAI( base_url="https://integrate.api.nvidia.com/v1", api_key="YOUR_NVIDIA_API_KEY" # 请替换为你的真实密钥 ) # 2. 获取用户输入(例如:西红柿、鸡蛋) ingredients = input("请输入食材(用顿号、逗号或空格分隔):") # 3. 向指定的模型(如Phi-3-mini)发起请求 response = client.chat.completions.create( model="microsoft/phi-3-mini-4k-instruct", # 可替换为其他NIM支持的模型 messages=[{ "role": "user", "content": f"请根据这些食材:{ingredients},生成一份详细的食谱,包括菜名、所需材料和烹饪步骤。" }], max_tokens=500 # 控制回复长度 ) # 4. 打印AI生成的食谱 print(response.choices[0].message.content)
🚀 如何进一步开发与实践
掌握了基础调用后,您可以考虑以下几个方向来深化应用:
- 探索不同的部署方式:除了使用云端API,如果您有NVIDIA GPU,可以研究如何在本地部署NIM容器,或使用NIM Operator在Kubernetes集群中进行规模化部署。
- 提升应用交互性:将核心代码与Web框架(如Gradio、Streamlit)结合,快速构建一个用户友好的图形界面。
- 构建复杂AI应用:食谱生成本质上是“提示工程”的典型应用。您可以将其扩展为更复杂的AI智能体(Agent),例如:
- 结合RAG(检索增强生成):连接一个包含详细烹饪技巧或营养知识的数据库,让生成的食谱更专业。
- 打造“厨房助手”智能体:除了生成食谱,还能根据用户冰箱里已有的食材进行推荐、规划一周菜谱,甚至估算热量。
总而言之,利用NVIDIA NIM进行AI应用开发提供了一个非常实用的起点。通过API调用可以快速验证想法,而平台提供的多种部署选项又能支持您将想法发展为安全、稳定、可扩展的生产级应用。
初步系统性地拆解基于 NVIDIA NIM 平台的 AI 应用开发、微调、优化和部署全流程。
这个流程的核心思想是:NVIDIA NIM 通过提供标准化的“容器化微服务”,将复杂的 AI 工程过程(开发-优化-部署)变得像搭积木一样清晰和可重复。
以下是整个流程的详细说明,您可以参考这个框架来实践您的食谱应用或任何其他AI项目。
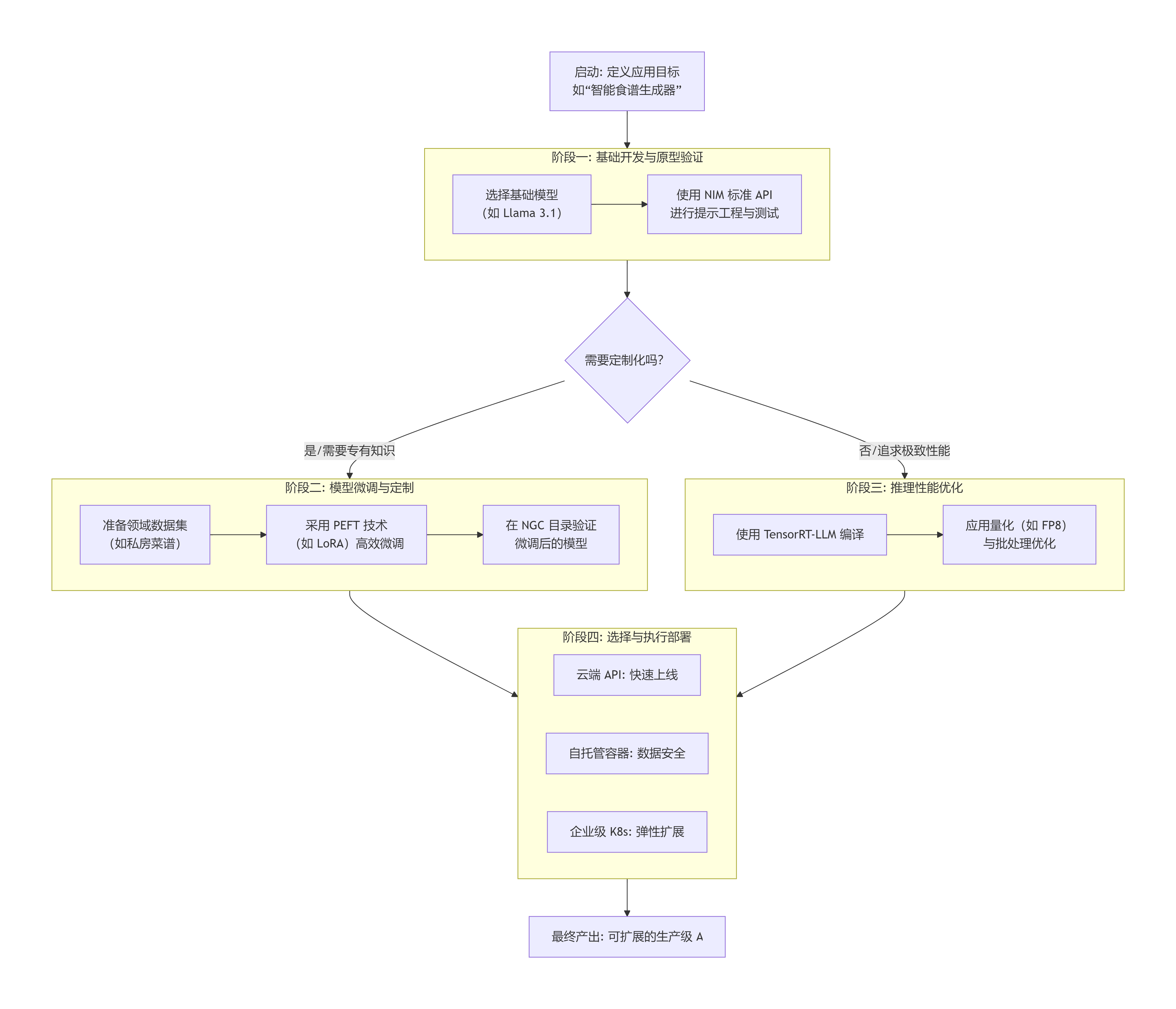
flowchart TD
A[启动: 定义应用目标<br>如“智能食谱生成器”] --> B
subgraph B [阶段一: 基础开发与原型验证]
B1[选择基础模型<br>(如 Llama 3.1)] --> B2
B2[使用 NIM 标准 API<br>进行提示工程与测试]
end
B --> C{需要定制化吗?}
C -- 是/需要专有知识 --> D
subgraph D [阶段二: 模型微调与定制]
D1[准备领域数据集<br>(如私房菜谱)] --> D2
D2[采用 PEFT 技术<br>(如 LoRA)高效微调] --> D3
D3[在 NGC 目录验证<br>微调后的模型]
end
C -- 否/追求极致性能 --> E
subgraph E [阶段三: 推理性能优化]
E1[使用 TensorRT-LLM 编译] --> E2
E2[应用量化(如 FP8)<br>与批处理优化]
end
D --> F
E --> F
subgraph F [阶段四: 选择与执行部署]
F1[云端 API: 快速上线]
F2[自托管容器: 数据安全]
F3[企业级 K8s: 弹性扩展]
end
F --> G[最终产出: 可扩展的生产级 AI 微服务]
第一阶段:AI 应用开发与原型验证
此阶段的目标是快速验证想法,比如构建食谱生成器的雏形。
- 选择基础模型:访问 NVIDIA NGC 目录 或
build.nvidia.com,根据任务选择模型。例如:- 创意生成类(如食谱、故事):可选择
Meta/Llama-3.1-8B-Instruct。 - 代码生成类:可选择
deepseek-ai/deepseek-coder-v2-instruct。
- 创意生成类(如食谱、故事):可选择
- 调用 NIM API 进行验证:就像您在食谱 Demo 中做的那样,使用标准 OpenAI SDK 或直接 REST API 调用云端的 NIM 服务,通过提示工程快速测试模型效果。
- 关键优势:无需管理任何基础设施,分钟级即可开始与最先进的模型交互。
第二阶段:模型微调与定制
如果预训练模型对专业领域(如特定菜系、营养学搭配)知识掌握不足,或您希望它遵循特定的输出格式,就需要进行微调。
- NVIDIA 的微调策略:NVIDIA 强烈推荐使用 PEFT(参数高效微调)方法,特别是 LoRA,而非全参数微调。这能以极小的计算成本(通常只需调整 <1% 的参数),达到媲美全量微调的效果。
- NVIDIA AI Workbench:这是执行微调的推荐工具。它是一个统一的开发环境,可以:
- 连接数据源:轻松接入您的专有食谱数据集。
- 自动化流程:提供可视化界面和代码模板,自动化完成 LoRA 适配器的训练。
- 直接推送到 NGC:训练完成后,可将微调后的模型(基础模型 + LoRA 适配器)直接推送至您的私有 NGC 目录,无缝衔接下一阶段。
第三阶段:推理优化(核心价值所在)
这是 NIM 的核心。为了让模型在生产中达到低延迟、高吞吐、低成本的目标,必须进行推理优化。
- 优化引擎:TensorRT-LLM:NVIDIA 使用其高性能推理 SDK TensorRT-LLM 对所有 NIM 模型进行编译优化。
- 关键技术:
- 内核融合与量化:将多个计算步骤融合,减少内存读写;使用 FP8/INT4 量化,在不显著损失精度的情况下,将模型大小减小 2-4 倍,速度提升 1-3 倍。
- In-Flight Batching:也称为连续批处理。它能动态地将不同用户的请求(如同时生成川菜和甜点食谱)组合在一起进行并行计算,显著提升 GPU 利用率,这是降低成本的关键。
- Attention 优化:对 KV Cache 进行高效管理,优化长文本生成(如生成包含历史渊源的复杂菜谱)时的内存和速度。
第四阶段:部署与扩展
优化后的模型通过 NIM 被封装为一个标准的、生产就绪的微服务,可通过多种方式部署。
| 部署方式 | 核心特点 | 适用场景 | 您的食谱应用示例 |
|---|---|---|---|
| 1. NIM 云 API | 开箱即用,无需运维,按需付费。 | 快速原型、MVP 验证、流量波动的应用。 | 快速上线一个公开的食谱生成网站。 |
| 2. 自托管容器 | 将 nvcr.io 上的 NIM 容器拉取到本地,在自有数据中心或工作站运行。数据完全不出域。 |
对数据隐私、合规性要求高的企业应用。 | 为高端连锁餐厅开发内部菜品创新系统。 |
| 3. 企业级平台 | 通过 NIM Operator 在 Kubernetes 集群中部署,实现自动扩缩容、蓝绿部署。 | 大规模、高可用的生产系统。 | 面向百万用户的“厨房 AI 助手” App 后端。 |
流程的统一性:无论采用哪种部署方式,您访问的API接口是完全一致的。这意味着您可以在开发阶段使用云API,在生产阶段无缝切换为自托管或K8s集群,无需修改任何应用代码。
总结与实践建议
利用 NVIDIA NIM 进行 AI 应用开发的核心路径是:通过云 API 快速验证想法 -> 必要时使用 AI Workbench 进行低成本的 LoRA 微调 -> 依赖 NIM 内置的 TensorRT-LLM 完成极致优化 -> 选择匹配业务需求的部署模式。
对于您的“DIY食谱生成器”,一个自然的进阶路线是:
- 收集一批高质量的私房菜谱数据,用 LoRA 微调模型,使其风格更独特。
- 构建一个 RAG 系统,将庞大的美食知识库作为模型的外部参考,让生成的食谱更精准、可溯源(例如,准确指出“宫保鸡丁”的正宗做法)。
- 使用 NIM 容器在本地部署,保护您的独家食谱数据。
- 利用 NIM 的流式输出和持续批处理能力,支撑一个高并发的美食社区应用。
下面我将详细介绍如何在 NVIDIA NIM 生态中进行 LoRA 微调的具体操作。整个过程可以概括为:“准备数据 -> 配置环境与参数 -> 启动训练 -> 验证与部署”,核心是使用 NVIDIA AI Workbench 来简化流程。
第一步:环境与数据准备
在进行微调前,您需要准备两样东西:一个统一的开发环境和一份格式正确的数据集。
-
选择开发环境:NVIDIA AI Workbench(推荐)
这是 NVIDIA 为 AI 开发者提供的免费工具,它能一键配置好所有复杂的依赖(如 PyTorch、相关库、CUDA),并直接集成 NGC 模型和数据集。您可以从 NVIDIA 官网 下载安装。当然,您也可以在任何配置了 NVIDIA GPU 和驱动的 Linux 环境中,通过 pip 安装nvidia-modelopt等工具包手动操作。 -
准备数据集
LoRA 微调通常使用指令遵循格式的数据。对于您的“DIY食谱生成器”,数据集应该是一个JSONL文件,其中每一行都是一个 JSON 对象,包含一个“指令”和对应的“理想输出”。- 示例 (
recipe_data.jsonl):{"instruction": "根据'番茄、鸡蛋、葱花'这些食材,生成一份家常菜谱。", "output": "菜名:番茄炒蛋。材料:番茄2个、鸡蛋3个、葱花少许...步骤:1. 鸡蛋打散炒熟备用..."} {"instruction": "我想做一道低卡路里的快手早餐,有'燕麦、牛奶、蓝莓'。", "output": "菜名:蓝莓牛奶燕麦粥。材料:即食燕麦50克、牛奶200毫升、蓝莓一小把...步骤:1. 将燕麦和牛奶放入碗中..."} - 关键点:数据质量至关重要。准备 500-1000 条高质量、多样化的样本,通常能对模型行为产生显著改善。
- 示例 (
第二步:配置与启动微调任务
在 AI Workbench 中,您可以通过图形界面或代码模板启动任务。以下是使用 PyTorch 和 peft 库进行微调的核心代码逻辑与参数说明。
- 核心代码框架:
代码关键解释:from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments from peft import LoraConfig, get_peft_model, TaskType from trl import SFTTrainer import torch # 1. 加载基础模型和分词器(从NGC或Hugging Face) model_name = "nvcf/meta/llama-3.1-8b-instruct" # 示例:NGC上的模型ID model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_name) tokenizer.pad_token = tokenizer.eos_token # 设置填充token # 2. 配置LoRA参数 lora_config = LoraConfig( task_type=TaskType.CAUSAL_LM, # 因果语言模型任务 r=8, # LoRA秩(Rank)。决定可训练参数数量,值越小越高效,通常从8开始尝试。 lora_alpha=32, # 缩放因子。通常设为r的2-4倍。 lora_dropout=0.1, # Dropout概率,用于防止过拟合。 target_modules=["q_proj", "v_proj"] # 针对LLaMA等Transformer模型,通常作用于注意力层的查询和值投影矩阵。 ) # 3. 将基础模型转换为PEFT模型 model = get_peft_model(model, lora_config) model.print_trainable_parameters() # 应显示只有<1%的参数可训练 # 4. 配置训练参数 training_args = TrainingArguments( output_dir="./lora_recipe_model", # 输出目录 num_train_epochs=3, # 训练轮次,通常3-5轮足够 per_device_train_batch_size=4, # 根据GPU内存调整 gradient_accumulation_steps=4, # 梯度累积,模拟更大批次 learning_rate=2e-4, # LoRA典型学习率(1e-4 到 5e-4) fp16=True, # 使用混合精度训练,节省显存并加速 logging_steps=10, save_strategy="epoch" ) # 5. 创建Trainer并开始训练 trainer = SFTTrainer( model=model, args=training_args, train_dataset=your_dataset, # 您加载好的数据集 tokenizer=tokenizer, dataset_text_field="instruction" # 数据集中包含指令文本的字段名 ) trainer.train()target_modules:指定在模型的哪些层插入LoRA适配器。对于不同架构的模型(如LLaMA、Mistral),这个参数需要调整。您可以通过查看模型结构来确定。r(秩):这是最重要的超参数之一。从r=8开始尝试,如果效果不佳再尝试16。更大的r带来更多可训练参数,可能效果更好但也更容易过拟合。learning_rate:LoRA的学习率通常比全量微调大(例如2e-4),因为只训练一小部分参数。
第三步:验证、保存与部署
训练完成后,需要对模型进行验证,并准备将其部署到NIM。
-
验证模型效果:
# 加载微调后的模型(包含基础模型和LoRA权重) model.load_adapter("./lora_recipe_model") # 切换到推理模式 model.eval() # 使用与开发阶段相同的NIM API调用方式,测试新的食谱生成指令 test_prompt = "用豆腐和肉末做一道川菜。" inputs = tokenizer(test_prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=200) print(tokenizer.decode(outputs[0], skip_special_tokens=True)) -
保存与整合模型:
LoRA训练只会保存一个很小的适配器权重文件(如adapter_model.safetensors,通常几MB到几十MB)。您需要将基础模型和LoRA适配器打包。# 合并LoRA适配器到基础模型(可选,但简化部署) merged_model = model.merge_and_unload() # 保存完整模型 merged_model.save_pretrained("./merged_recipe_model") tokenizer.save_pretrained("./merged_recipe_model") -
部署到NIM:
这是最关键的一步。您需要将微调后的模型构建成NIM标准的容器。- 最佳路径:使用 NVIDIA AI Workbench 或
nvidia-modelopt工具,将保存的模型目录(./merged_recipe_model)直接推送(Push)到您NGC目录的私有仓库中。推送时,工具会自动为其生成一个符合NIM标准的容器镜像。 - 随后,您可以在NIM的部署界面中,直接从您的NGC私有仓库选择这个新模型镜像,以自托管容器或云API的方式启动它。启动后,其API调用方式与原始模型完全一致,但已具备了您的专业知识。
- 最佳路径:使用 NVIDIA AI Workbench 或
关键注意事项与排错
- 过拟合:如果模型在训练数据上表现完美,但在新指令上表现怪异,说明过拟合了。请尝试:减少训练轮次、增加
lora_dropout、检查并提升数据集的多样性和质量。 - 效果不显著:首先检查数据质量。然后可以尝试缓慢增加
r的值(如从8到16),或调整target_modules(对于LLaMA系列,尝试加入k_proj, o_proj)。 - GPU内存不足:减少
per_device_train_batch_size,增加gradient_accumulation_steps来补偿。确保开启了fp16。
总结来说,在NVIDIA生态中进行LoRA微调,核心是利用好AI Workbench等工具来绕过环境配置的复杂性,专注于高质量的数据准备和关键超参数的调试,最后通过NGC目录实现从训练到NIM部署的无缝流转。如果您的食谱数据集已经就绪,可以从创建一个AI Workbench项目开始实践。
从零开始,在 NVIDIA AI Workbench 中创建一个实际的食谱模型 LoRA 微调项目。请严格按照以下步骤操作。
第一步:安装与环境准备
-
下载与安装
- 访问 NVIDIA AI Workbench 官网,点击“Download Now”。
- 根据您的操作系统(Windows/Linux)下载安装包并完成安装。
-
首次启动与认证
- 启动 AI Workbench 应用。
- 系统将自动打开浏览器,提示您登录 NVIDIA NGC 账户。如果您没有,请在此页面免费注册。
- 登录后,完成授权。这是访问 NGC 上的模型、数据集和计算资源的关键。
第二步:创建您的第一个微调项目
-
创建新项目
- 在 AI Workbench 主界面,点击 “Create New Project”。
- 项目名称:例如
Recipe-LoRA-Finetune。 - 项目路径:使用默认路径或选择您的工作目录。
- 选择“Foundation Model Fine-Tuning”模板:AI Workbench 提供了预配置的微调模板,这是最快的方式。
-
配置项目环境
- 项目创建后,系统会自动生成一个结构化的目录和必要的配置文件。
- 核心目录通常包括:
Recipe-LoRA-Finetune/ ├── data/ # 存放您的训练数据 ├── scripts/ # 存放训练和推理脚本 ├── models/ # 存放微调后的模型 ├── config.yaml # 项目配置文件 └── README.md
第三步:准备与放置数据集
这是最关键的一步。您需要将之前准备的 recipe_data.jsonl 文件放入项目中。
-
数据格式确认:确保您的
recipe_data.jsonl格式正确。一个简单的检查脚本check_data.py:import json with open('./data/recipe_data.jsonl', 'r', encoding='utf-8') as f: for i, line in enumerate(f): try: data = json.loads(line) # 检查必需的字段 assert 'instruction' in data, f"第{i+1}行缺少 'instruction'" assert 'output' in data, f"第{i+1}行缺少 'output'" # 可选:打印第一条数据作为样本 if i == 0: print("数据样本检查通过,第一条数据示例:") print(json.dumps(data, ensure_ascii=False, indent=2)) except json.JSONDecodeError as e: print(f"第{i+1}行JSON格式错误:{e}") break print("数据格式检查完成。")- 在 AI Workbench 的终端中,导航到项目目录并运行
python check_data.py。
- 在 AI Workbench 的终端中,导航到项目目录并运行
-
放置数据:将检查无误的
recipe_data.jsonl文件放入项目的data/目录下。
第四步:配置与启动微调任务
我们将修改项目模板提供的配置文件来适配您的食谱任务。
-
编辑配置文件:打开项目根目录下的
config.yaml或fine-tuning-config.yaml(取决于模板),找到并修改关键部分:model: base_model: "nvcr.io/nvidia/llama-3.1-8b-instruct:latest" # 从NGC拉取基础模型 # 或者使用Hugging Face ID: "meta-llama/Meta-Llama-3.1-8B-Instruct" data: train_file: "./data/recipe_data.jsonl" # 指向您的数据 format: "instruction" # 指定数据格式为指令遵循 peft: # LoRA配置 enabled: true r: 8 lora_alpha: 32 lora_dropout: 0.1 target_modules: ["q_proj", "v_proj"] # 对于LLaMA模型 training: num_epochs: 3 per_device_train_batch_size: 2 # 根据您的GPU显存调整 (例如,RTX 4090 可设为4) gradient_accumulation_steps: 8 # 模拟更大批次大小:2 * 8 = 16 learning_rate: 2e-4 output_dir: "./models/recipe_lora_adapter" # 适配器输出路径 logging_steps: 10 -
启动训练:
- 在 AI Workbench 的 “Project Details” 页面,找到 “Compute” 部分。
- 选择运行时:您可以选择“Local”使用您自己的GPU,或连接到云端的“NVIDIA DGX Cloud”等远程资源(如果已配置)。
- 点击 “Start” 启动运行时环境。系统会自动根据
config.yaml拉取Docker镜像并配置好所有依赖。 - 环境就绪后,在终端中运行模板提供的训练命令,例如:
python scripts/train.py --config config.yaml - 训练开始后,您可以在终端中看到损失值下降的日志。
第五步:验证与使用微调后的模型
训练完成后,您需要验证模型效果并将其打包。
-
加载并测试模型:创建一个测试脚本
test_lora.py:from transformers import AutoModelForCausalLM, AutoTokenizer from peft import PeftModel import torch # 1. 加载原始基础模型 base_model_name = "meta-llama/Meta-Llama-3.1-8B-Instruct" model = AutoModelForCausalLM.from_pretrained(base_model_name, torch_dtype=torch.float16, device_map="auto") tokenizer = AutoTokenizer.from_pretrained(base_model_name) # 2. 加载训练好的LoRA适配器 adapter_path = "./models/recipe_lora_adapter" model = PeftModel.from_pretrained(model, adapter_path) # 3. 准备提示词 prompt = "Instruction: 请用冰箱里常见的鸡蛋、西红柿和午餐肉,设计一份创意早餐食谱。\n\nOutput:" inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # 4. 生成 with torch.no_grad(): outputs = model.generate(**inputs, max_new_tokens=300, temperature=0.7) print(tokenizer.decode(outputs[0], skip_special_tokens=True))- 观察生成的食谱是否比基础模型更具创意、更符合您的指令风格。
-
(可选)合并模型:为简化部署,可以将LoRA权重合并回基础模型。
# 接上段代码 merged_model = model.merge_and_unload() # 合并 merged_model.save_pretrained("./models/recipe_merged_model") tokenizer.save_pretrained("./models/recipe_merged_model") print("模型已合并并保存。")
第六步:为NIM部署做准备
要将您微调好的模型部署到 NVIDIA NIM,需要将其构建成标准容器。
-
在NGC上创建模型仓库:
- 登录 NGC 目录。
- 点击右上角您的头像,进入“My Org > Models”。
- 点击“Create Model Repository”,命名为
recipe-llama-8b-finetuned。
-
使用
nvcr.io工具打包模型(AI Workbench 环境中通常已预装):- 确保您的模型目录(如
./models/recipe_merged_model)包含必要的文件:config.json,model.safetensors,tokenizer.json等。 - 在终端中运行(替换为您自己的NGC团队名和标签):
# 登录NGC docker login nvcr.io # 使用NVIDIA提供的工具打包 nim pack \ --model ./models/recipe_merged_model \ --output ./recipe-model-pack \ --name "my-recipe-model" \ --version 1.0 # 将打包好的模型推送到您的NGC仓库 docker tag my-recipe-model:1.0 nvcr.io/<YOUR_NGC_TEAM>/recipe-llama-8b-finetuned:1.0 docker push nvcr.io/<YOUR_NGC_TEAM>/recipe-llama-8b-finetuned:1.0
- 确保您的模型目录(如
-
在NIM中部署:
- 登录 NVIDIA NIM 控制台。
- 在“Models”页面,选择“Deploy a Custom Model”。
- 从您的NGC私有仓库中,选择刚刚推送的
recipe-llama-8b-finetuned:1.0镜像。 - 选择部署方式(云端点、自托管容器或Kubernetes),配置资源,然后启动。
- 部署完成后,您将获得一个专属的API端点,其调用方式与原始NIM API完全一致,但模型已经是您专属的“食谱大师”。
关键检查点与排错
- GPU内存不足:在
config.yaml中降低per_device_train_batch_size,增加gradient_accumulation_steps。确保使用torch.float16。 - 训练损失不下降:检查数据质量;尝试稍微提高
learning_rate(如到 3e-4);确认target_modules设置正确。 - NGC认证失败:在AI Workbench中,通过
ngc config set命令重新配置您的API密钥。 - 模型生成效果不佳:确保您的训练数据足够多样化(覆盖不同菜系、食材、指令风格)。可以尝试增加
num_epochs到5。
总结:您现在拥有了一个端到端的实操指南。从创建项目、准备数据、配置训练,到验证模型并为其部署到NIM做好准备。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)