大模型入门第一课:彻底搞懂Token,大模型入门到精通,收藏这篇就足够了!
朋友们,欢迎来到我的大模型学习之旅第一站!今天我们要攻克的,是那个无处不在却又常常让人困惑的概念——Token。
从零开始,用10分钟掌握大模型世界的“基础货币”
朋友们,欢迎来到我的大模型学习之旅第一站!今天我们要攻克的,是那个无处不在却又常常让人困惑的概念——Token。
作为一个新手,我深知初学者的痛点。所以这篇文章,我会用最直白的语言,带你从零开始,一步步搞懂Token到底是什么,为什么它如此重要。
图示:就像把一盒糖果分装成小包,Tokenization 将文本切分为模型可处理的基本单元
一、初识Token:从“分糖果”说起
想象一下,你面前有一盒五彩斑斓的糖果,现在要把它们分装成小包装。
原始糖果:我爱学习人工智能技术
分装后的糖果包:["我", "爱", "学习", "人工", "智能", "技术"]
在这个比喻中:
-
整句话
就像那盒完整的糖果
-
每个小包装
就是一个Token
-
分装过程
就是Tokenization(分词)
看到这里,你可能恍然大悟:“哦,Token就是词语嘛!”
别急,事情没那么简单。让我们继续深入…
二、Token的真面目:不只是词语
在实际的大模型中,Token的划分要比简单的“按词分”复杂得多。让我们看看真实情况:
英文例子:
- 输入:
"I'm learning AI." - Token化:
["I", "'", "m", " learning", " AI", "."]
中文例子:
- 输入:
"我正在学习人工智能" - Token化:
["我", "正在", "学习", "人工", "智能"]
发现了吗?Token可以是:
-
完整的词(如“学习”)
-
词的一部分(如“人工”、“智能”)
-
标点符号(如句号)
-
甚至单词的一部分(如英文中的"'m")
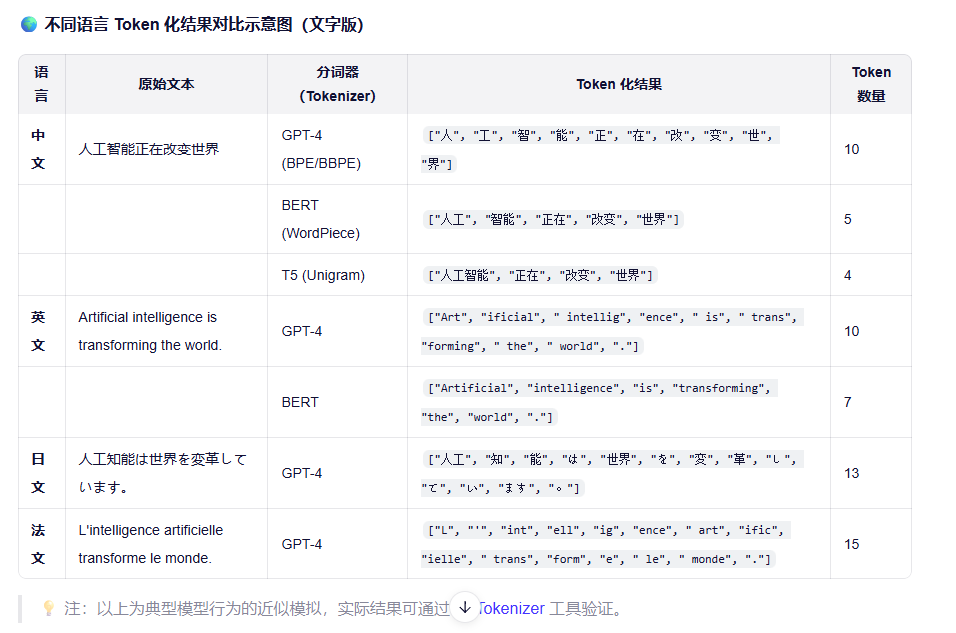
图示:不同语言的Token化结果对比
三、为什么需要Token?三大核心原因
-
解决词汇表爆炸问题
如果每个词都单独处理,模型需要记住数百万个词。通过将词拆分成更小的Token,只需要几千个Token就能组合出几乎所有的词。
-
处理未知词汇
当模型遇到没见过的词时,如果是基于Token的,它可以用已知的Token来“拼凑”理解。比如遇到“深度学习”,即使没学过这个词,也知道“深度”和“学习”这两个Token。
-
统一多语言处理
不同语言的词汇结构差异很大,但通过Token化,可以建立统一的方式来处理各种语言。
四、Token的“价格体系”:成本与限制
理解Token的另一个重要角度是:Token是计算成本的单位。
在大多数大模型中:
-
输入和输出都按Token计数
-
计算资源与Token数量直接相关
-
模型有最大Token限制
(上下文窗口)
举个例子:
用户输入:32个Token模型回复:45个Token本次对话总计:77个Token
这就解释了为什么:
- 长文档处理成本更高
- 对话有长度限制
- 精简的Prompt能节省资源
图示:API调用中Token的计费方式(来源:OpenAI)
五、亲手实验:看看真实Token长什么样
理论说再多,不如亲手试试。你可以在以下平台直观看到文本是如何被Token化的:
推荐工具:
-
OpenAI Tokenizer
:https://platform.openai.com/tokenizer
-
Hugging Face Tokenizer
:各种模型的在线演示
试着输入一些文本,观察它们是如何被拆分的。这个练习会让你对Token有更直观的感受。
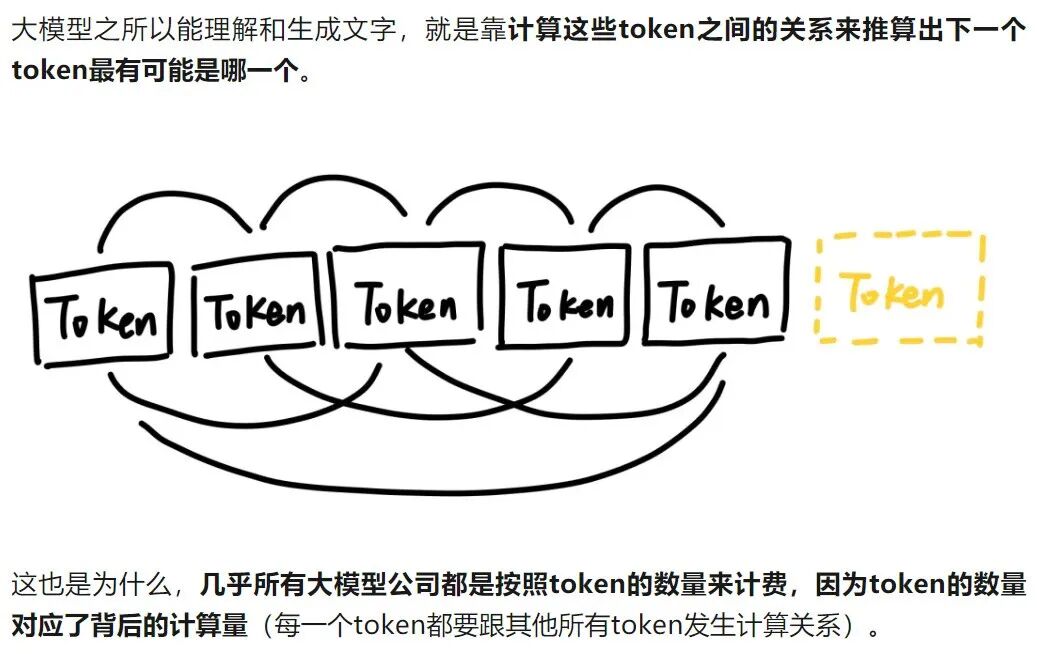
六、Token在大模型中的核心作用
现在,让我们从更高视角看Token的重要性:
-
模型理解的“原材料”
大模型并不直接理解文字,它们理解的是Token的数字表示。每个Token都被转换成一个数字ID,模型基于这些ID进行计算。
-
训练的基础单元
在模型训练时,它学习的是Token之间的概率关系。“今天天气很”后面很可能接“好”,而不是“香蕉”。
-
生成文本的“积木”
当模型生成文本时,它实际上是在预测下一个最可能的Token,然后基于新的Token继续预测下一个,如此循环。
七、进阶知识:不同模型的Token差异
当你深入使用时,会发现不同模型有不同的Token化策略:
-
GPT系列
:使用Byte Pair Encoding (BPE)
-
BERT系列
:使用WordPiece
-
SentencePiece
:用于多语言模型
不过作为初学者,你只需要知道:不同模型对同一文本可能产生不同数量的Token,这会影响使用成本和效果。
实践小贴士
基于对Token的理解,这里有些实用建议:
-
优化Prompt
:删除不必要的词语,减少Token消耗
-
处理长文本
:意识到长文档需要分段处理
-
成本估算
:在调用API前,先用Tokenizer工具估算Token数量
-
中文特性
:中文字符通常1个汉字=1-2个Token,英文单词可能被拆分成多个Token
结语
恭喜!现在你已经不再是Token小白了。我们来回顾一下今天的重点:
- ✅ Token是文本的基本处理单元,不完全是词语
- ✅ Token化让模型能高效处理各种语言和新词
- ✅ Token是计算成本和资源限制的计量单位
- ✅ 理解Token有助于优化使用大模型
学习大模型就像学一门新语言,而Token就是这门语言的字母表。掌握了它,你就打开了理解整个AI世界的大门。
PS: 在下一篇文章中,我们将探索另一个核心概念——Embedding(嵌入),看看模型是如何把文字变成数字向量的。相信我,那会是另一个“原来如此”的美妙时刻!
觉得有收获吗?欢迎收藏这篇文章,在实践过程中有任何关于Token的问题,都可以回来温习。学习路上,我们一起进步!
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献476条内容
已为社区贡献476条内容

所有评论(0)