数据处理方式
本文摘要: PatchTST通过将多变量时间序列分解为单变量序列并分块处理,提升Transformer效率。TimeMixer采用多尺度序列生成和移动平均分解,自底向上传递季节性信息,自顶向下传递趋势信息,通过PDM模块实现特征混合。WPMixer引入小波分解,保留多级细节系数以捕捉突发特征,通过PatchMixer和EmbeddingMixer分别在时间和特征维度混合信息,最后重建预测结果。两种
PatchTST:
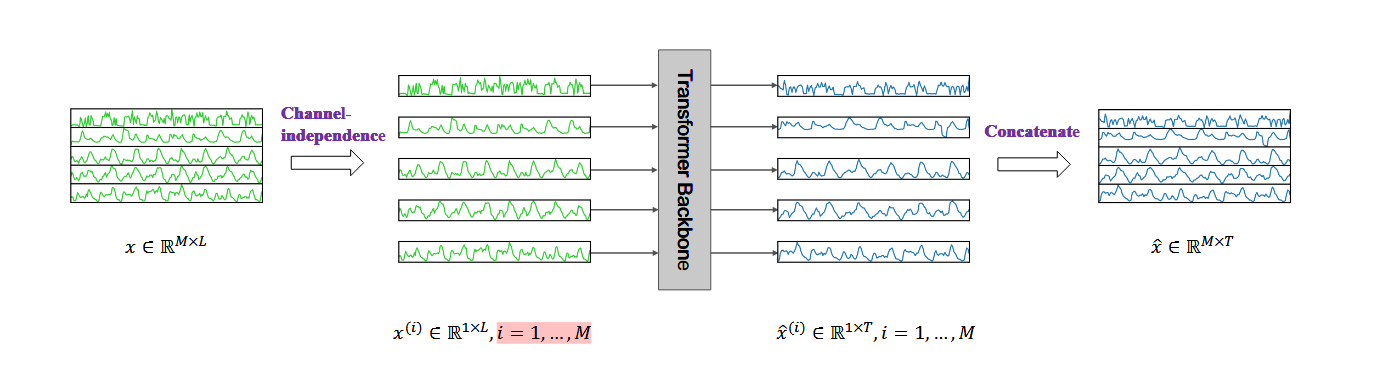
多变量时间序列被认为是一个多通道信号,一个多变量的时间序列是如何被分离成单个序列的,并且每个序列作为一个输入标记被送入Transformer主干网。然后,对每个系列进行预测,并将结果串联起来以获得最终的预测结果。
相比较于之前,之前是单个时间点进行计算,单个时间点计算
数据关系的重构:从“冗长序列”到“紧凑摘要”
-
之前(点级输入):
-
对于长度为L的历史序列,模型需要处理L个token。序列非常冗长,且相邻token之间信息高度冗余(9:00的温度和9:01的温度几乎一样)。
-
问题:Transformer需要在这L个高度相似、冗长的点中寻找关系,效率低下,且容易受到噪声点的干扰。
-
-
PatchTST(分块Patch):
-
通过分块,将长序列压缩为数量少得多的Patch序列。例如,1024个点可以被压缩成64个Patch。
-
提升:
-
去冗余:一个Patch内部包含了原始信息,但Patch与Patch之间是更高级的、摘要性的信息。这消除了相邻点之间的冗余。
-
抗噪声:单个点的异常值(噪声)会在一个Patch中被“稀释”,因为模型关注的是整个Patch所代表的趋势,而不是某一个孤立的点。这使得模型对数据噪声更不敏感,更加鲁棒
-
-
通过patch获取局部信息,
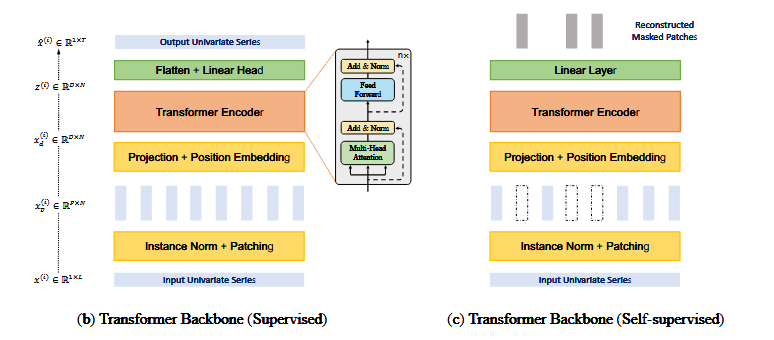
X输入M x L (L为数据长度,M为变量数目)---->分出M份每份维度为 1 x L , ---->经patch分块,为P x N
![]()
分块之后遇到问题?
patch之间的关系问题如何解决
TimeMixer
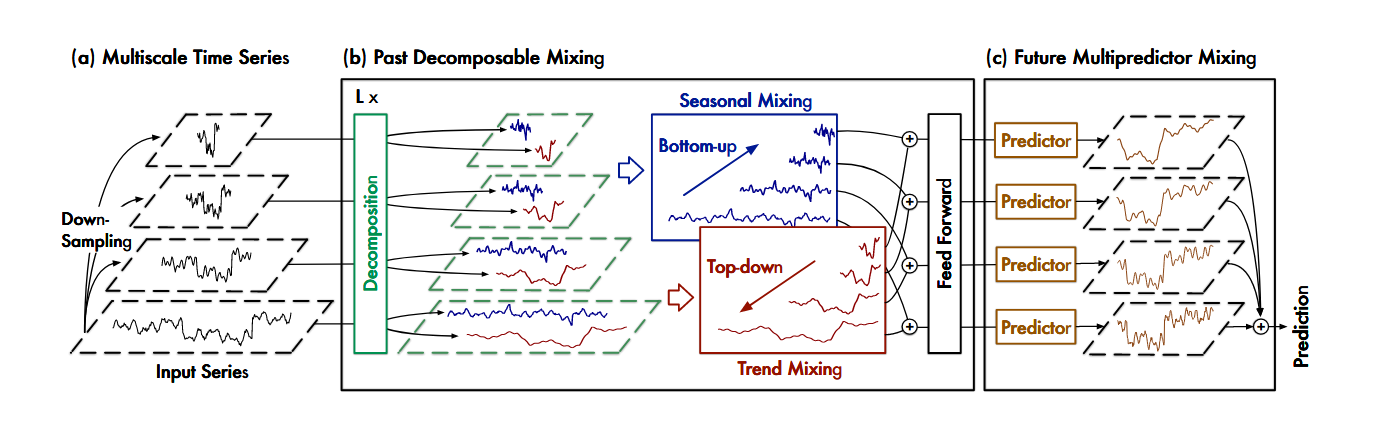
1、多尺度序列生成
原始序列 X:P x C, 使用平均池化(average pooling)对输入序列进行下采样,生成 M+1 个不同尺度的序列: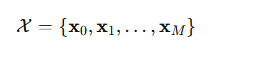
![]() ,Mxpxc
,Mxpxc
优点:产生的新序列包含的多尺度信息(包含粗粒度、细粒度信息),在具体的时序预测中,预测依据中包含了两中趋势:
-
细尺度(如小时)捕捉微观变化(如日内波动);
-
粗尺度(如天、周)捕捉宏观趋势(如周期性、长期趋势)。
捕获更多时间内部和宏观变化。
2、嵌入层

想象在二维平面上有一堆红点和蓝点交织在一起(线性不可分),如果把这些点映射到三维空间,可能就能找到一个平面把它们分开(线性可分)。
时间序列数据在原始空间(低维)中往往是非线性和高度纠缠的,映射到高维空间后:
-
复杂的时序模式变得更容易被线性模型捕捉
-
季节性和趋势性成分在高维空间中可能分布在不同的子空间
3、PDM(过去可分解混合模块)
对输入的多尺度特征![]() 进行操作
进行操作
(1)序列分解
对![]() 进行移动平均分解
进行移动平均分解



AutoFormer
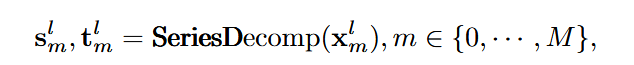
(2)季节性&趋势性混合
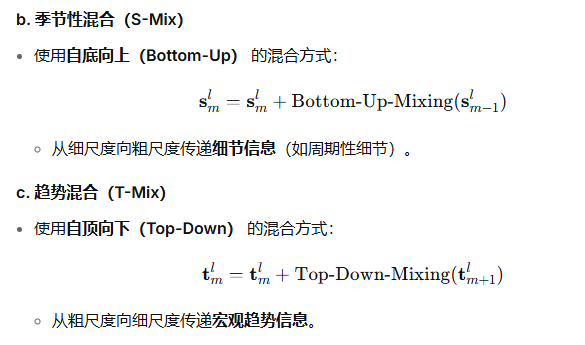
PART01 季节性即由小周期组成大周期
细节的季节性信息(如早晚高峰)在细尺度中更清晰
-
小时波动 → 日周期
-
日周期 → 周周期
-
周周期 → 月周期
细尺度s₀ → 中尺度s₁ → 粗尺度s₂
↓ ↓ ↓
小时细节 → 日模式 → 周模式
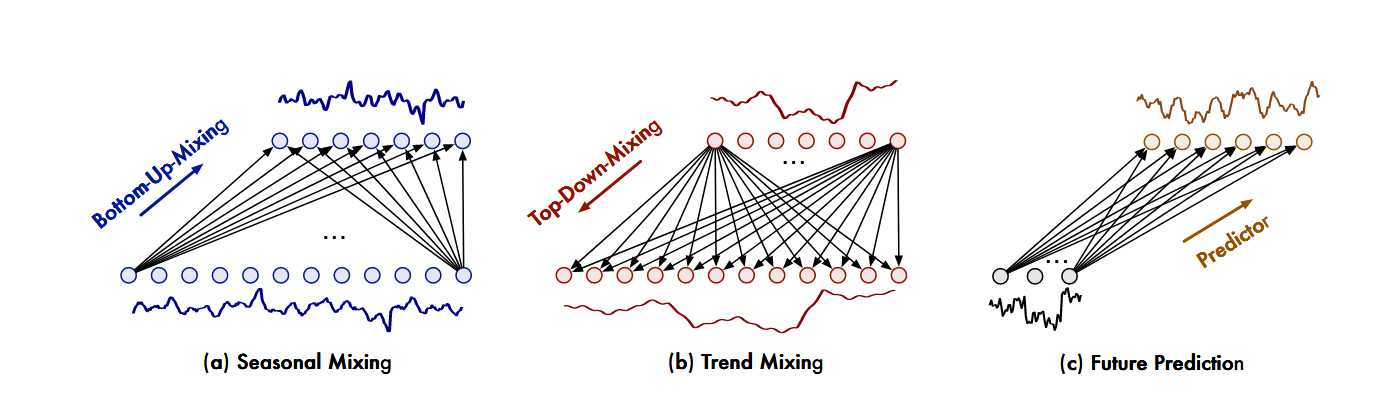
采用自底向上传递季节信息,
采用自底向上的原因:如果从粗尺度向细尺度传递季节性:
-
会丢失重要的细节信息
-
粗尺度已经平滑掉了精细的周期性变化
PART02
-
趋势是宏观的、长期的变化
-
粗尺度能更清晰地展现真正的趋势方向
# 自顶向下传递趋势信息
粗尺度t₂ → 中尺度t₁ → 细尺度t₀
↓ ↓ ↓
宏观趋势 → 中期趋势 → 指导短期趋势
采用自上向下的原因:如果从细尺度向粗尺度传递趋势:
-
噪声会逐级传播和放大
-
宏观趋势会被微观波动污染
为什么不直接选用最宏观或者最微观的数据来代表t 和s?
没有哪个尺度是"完美"的,每个尺度都有其局限性和价值,
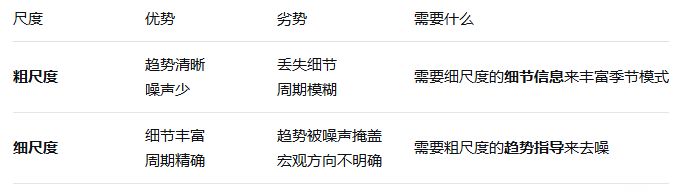
类比1:城市规划
-
国家层面(粗尺度):知道要发展经济(趋势)
-
城市层面(细尺度):知道具体如何建设(细节)
-
需要双向沟通:
-
城市向国家汇报具体需求(自底向上)
-
国家向城市传达发展方向(自顶向下)
-
TimeMixer选择让各尺度协作,
最终趋势 = 各尺度趋势信息的智能融合 最终季节性 = 各尺度季节性信息的智能融合
(3)合并与前馈网络
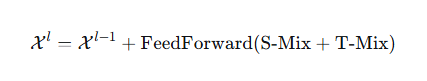
季节混合结果 + 趋势混合结果 → 相加 → FeedForward → 残差连接 → 输出
将得到的季节性和趋势性的信息直接相加,再经过FFN网络传递再经过残差连接。
FFN结构示意:
线性层(升维)------->激活函数(GELU)-------------->线性层(降维)
季节性和趋势性相加只是线性组合,但现实中两者的关系可能很复杂,FFN学习这种复杂交互。
若无FFN只是原始信息 + 季节趋势混合,缺乏深度特征学习
4、FMM(未来多预测器混合模块)
preditor仅仅采用一个单一的线性层

预测过程展示:
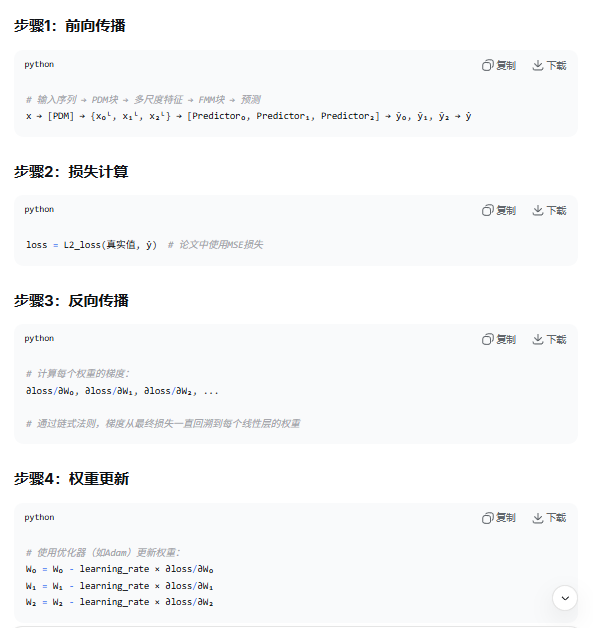
WPMixer
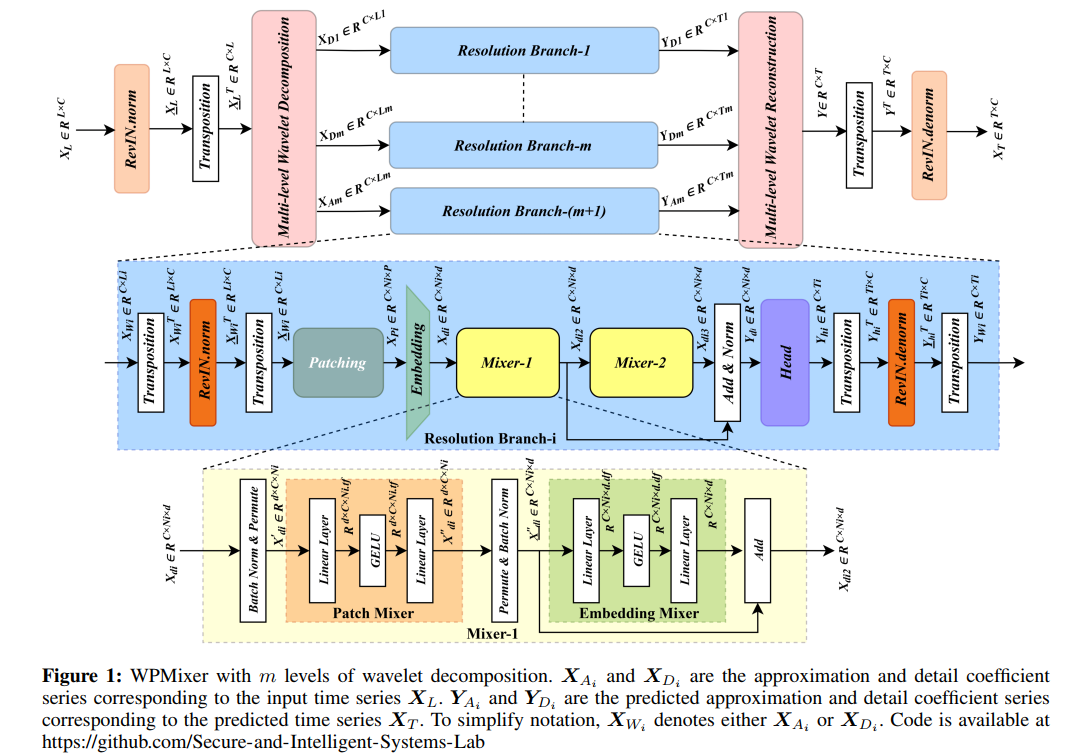
(1)原始输入数据:![]()
(2)预处理:RevIN归一化,归一化后序列为:![]()
(3)小波分解:
m为小波分解层数。
一次分解产生:XA1、XD1
-
近似系数系列 XA1∈RC×L1:由低通滤波器产生,捕捉信号的低频趋势或轮廓。L1≈L/2L1≈L/2。
-
细节系数系列 XD1∈RC×L1:由高通滤波器产生,捕捉信号的高频细节或突变。
多级迭代分解:
-
将上一级得到的近似系数 XA1 作为新的输入,重复步骤2的分解过程。
-
经过 mm 级分解后,我们得到一组系数系列:
-
1个最终级的近似系数系列:XAm
-
mm 个不同级别的细节系数系列:XDm,XDm−1,…,XD1
-
为什么近似系数仅保留XAm,而精确系数却都要?
一个直观的比喻:阅读一篇精读文章
想象你在精读一篇长文:
-
第一遍(Level 1):你读完全文,掌握了主干思想(A1) 和一些核心细节(D1)。
-
第二遍(Level 2):你不再读全文,而是专注于之前得到的主干思想(A1)。你把主干思想进一步提炼为核心论点(A2),并发现了支撑核心论点的关键论据(D2)。
-
第三遍(Level 3):你继续专注于核心论点(A2),提炼出中心思想(A3),并分析了其深层次含义(D3)。
-
最终的概括(Am):最精炼的核心。
-
所有级别的细节(Dm,Dm−1,...,D1):从深到浅的所有支撑信息。
为什么采用小波分解?
1.现实世界的时间序列(如电力负荷、交通流量)不仅包含平滑的趋势和固定的周期(季节性),还包含突发的 spikes(尖峰)和 dips(骤降)。这些突变在时域上局部化,在频域上表现为高频分量。
以往已有的预测模型在处理时间序列信息的季节性和趋势性特征时,例如TimeMixer采用的移动平均,本质为一个低通滤波器,会滤掉这些信息,小波分解同时提供了时间定位和频率定位的能力:细节系数 Di 清晰地告诉我们 “什么频率的事件” 发生在 “什么时候”。
2.TimeMixer将不同尺度的信息进行混合,如直接采用FFN进行处理,会导致不同频率的信息混合干扰、丢失。
WPMixer通过高频、低频独立的分支处理,不会因为同时处理所有频率的信息而产生“认知混淆”。
3、真正的多分辨率分析,
-
每一级分解都对应一个特定的“分辨率”或“尺度”。
-
深层近似系数(如 A3):视野宏观,关注长期、缓慢变化的趋势。
-
浅层细节系数(如 D1):视野微观,关注短期、快速变化的细节。
-
-
这种结构让模型自然地具备了同时捕捉长期依赖和短期动态的能力,而无需像Transformer那样依赖复杂的注意力机制或像其他模型那样进行复杂的手工多尺度设计。
(4)分块与嵌入
无论![]() 或者
或者![]() ,以下均视为
,以下均视为![]() ,(共m+1个)
,(共m+1个)
分块:![]() :C x Li进行patch分解,块长为P,步长为S------>
:C x Li进行patch分解,块长为P,步长为S------>![]()
嵌入:

为什么要从P维转成D维?
-
P 维块(转换前):是一个包含 PP 个连续时间点标量值的小窗口。它只是一个短序列的数值。
-
D 维嵌入(转换后):是一个单个的、高维的特征向量。这个向量的每个维度都代表了从原始 P个点中提取出来的某种抽象特征,模型可以创建一个更高维、更具判别性的特征空间
-
为后续的MLP混合器提供合适的“语言”,MLP(多层感知机)在处理高维、密集的特征向量时效率最高。
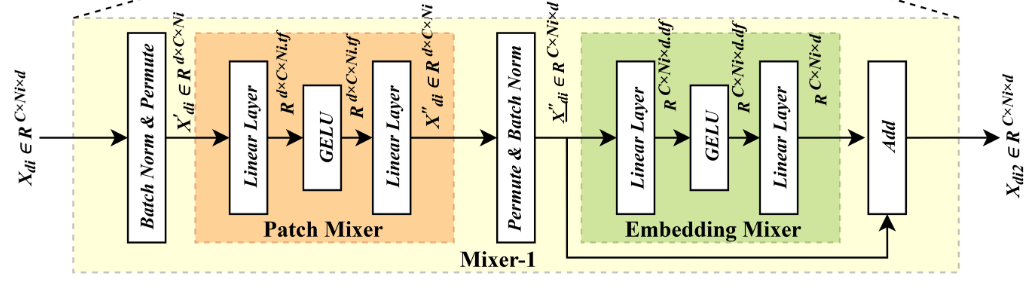
(4)混合模块
PatchMixer:在块维度(即时间维度)上进行信息混合
过程简述:2D批归一化,第一个线性层升维,GELU激活,第二个线性层降维,返回维度: C x Ni x d。
对Ni进行操作,乘tf
![]()
为什么PATCHMixer?
-
跨块信息交流:每个块最初只包含局部信息。Patch Mixer让所有块之间进行信息交换,使得每个块都能感知到序列中其他块的信息。
-
时间混合:捕获全局时间依赖
Embedding Mixer(嵌入混合器):在嵌入维度(即特征维度)上进行信息混合。
过程简述:将PatchMixer的输出再次进行归一化,进行一个线性层升维,GELU激活,线性层降维
返回维度:C x Ni x d。
对d进行操作:乘df
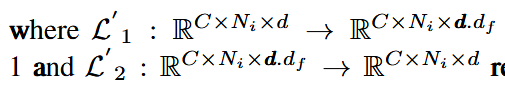
为什么Embedding Mixer?
-
特征重新校准:不同的嵌入维度可能捕获了不同的时间模式。Embedding Mixer让这些特征之间进行交互,学习如何重新加权和组合这些特征。
-
类比:就像在烹饪时,你不仅要有各种食材(特征),还要知道如何调配它们的比例才能做出美味佳肴。
-
特征混合:学习特征交互
-
具体作用:
-
可能发现"早晨高峰"特征和"雨天"特征组合时,交通流量会显著增加
-
学习到某些特征组合比单个特征更能预测未来值
-
残差连接确保不会丢失原始信息,同时获得特征交互的好处
-
(5)头部模块
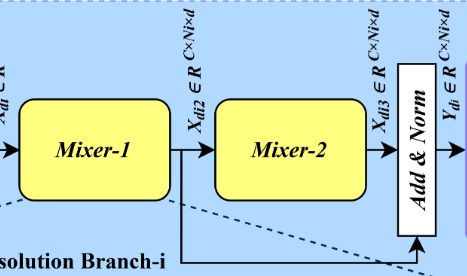
![]() 上图为其又来,是经过了有一次Mixer而来,
上图为其又来,是经过了有一次Mixer而来,

得到YWi,同上述定义将Y的近似系数和细节系数军由YW表示,共m+1个。
(6)重建模块

采用近似系数和细节系数重建时间序列。再经过IRevIN得到预测XT。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)