告别随机性:Thinking Machines Lab如何实现了LLM推理的完全确定性?
这篇来自Thinking Machines Lab的博客不仅揭示了这一深层机制,更提出了实用的解决方案,为实现真正确定性的LLM推理铺平了道路。传统的解释将其归咎于GPU的并行计算与浮点数的非结合性,但本文作者通过深入系统的分析指出,这只是一个表面原因。:当批大小很小时,GPU核心无法充分利用,可能被迫改用“拆分归约”(split reduction)策略,从而破坏批不变性。:当批大小(M或N维度
在大语言模型(LLM)如火如荼发展的今天,一个看似微小却至关重要的问题困扰着研究者与工程师:为什么即使在最严格的设置下(如温度=0),同一个LLM推理请求多次执行仍可能得到不同的结果? 这种非确定性不仅影响实验的可复现性,更潜在地威胁到模型部署的可靠性与安全性。
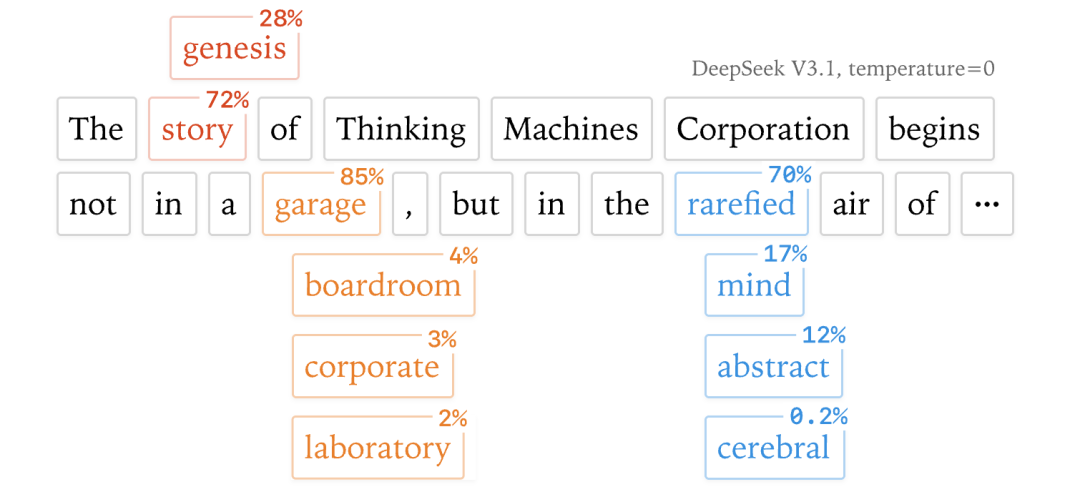
传统的解释将其归咎于GPU的并行计算与浮点数的非结合性,但本文作者通过深入系统的分析指出,这只是一个表面原因。真正的根源隐藏在推理系统的批处理机制中——即批大小的变化会导致核函数(kernel)计算策略的改变,进而引发数值结果的差异。

-
论文:Defeating Nondeterminism in LLM Inference
-
链接:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
这篇来自Thinking Machines Lab的博客不仅揭示了这一深层机制,更提出了实用的解决方案,为实现真正确定性的LLM推理铺平了道路。接下来,我们将一步步解析这一发现背后的逻辑、方法与其深远影响。
非确定性的传统解释与局限
很多人认为,LLM推理的非确定性来自于GPU的高度并行性和浮点运算的非结合性。浮点数在计算机中的表示是有精度限制的,因此运算顺序会影响结果。例如:

这种现象在科学计算中很常见。GPU由于同时运行大量线程,加法顺序可能因线程完成顺序不同而不同,尤其是在使用原子操作(atomic add)时。这就是所谓的“并发+浮点非结合性”假说。
然而,作者通过一个简单的实验挑战了这一观点:重复执行相同的矩阵乘法(如2048x2048),结果总是完全一致的。这说明,单纯的矩阵乘法内核本身是“运行确定性”的(run-to-run deterministic)。如果并发和浮点非结合性是主因,那么连矩阵乘法也应该是不确定的。

因此,作者指出:虽然浮点非结合性是数值差异的根源,但并发性并不是导致LLM推理非确定性的直接原因。我们需要从系统层面寻找答案。
真正的罪魁祸首:批大小变化导致的非确定性
作者提出了一个关键概念:批不变性(Batch Invariance)。一个批不变的核函数是指,其输出不随批处理中其他样本的存在或批大小的变化而改变。
在LLM推理服务中,多个用户请求会被动态批处理在一起以提高效率。批大小取决于当前服务器的负载,而负载是变化的、非确定的。因此,即使同一个用户发送完全相同的请求,每次处理时所在的批大小可能不同。
如果核函数不是批不变的(即输出受批大小影响),那么同一个请求在不同批大小下就会得到不同的数值结果,从而表现出非确定性。
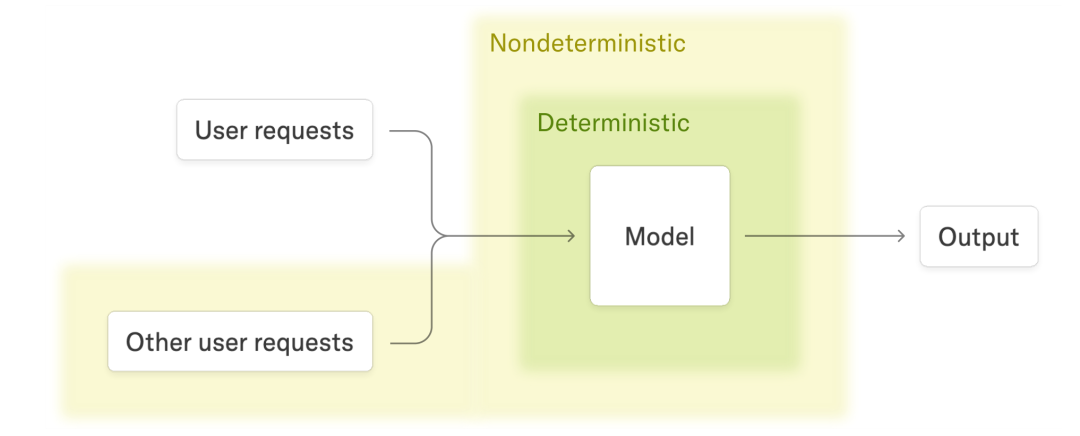
这就是为什么从用户角度看,LLM推理是非确定的;而从服务器角度看,它是“确定”的(因为输入——整个批处理——是确定的)。这种系统级非确定性是批大小变化与核函数非不变性共同作用的结果。
实现批不变性的关键技术
要实现确定性推理,必须使所有关键核函数具备批不变性。作者重点讨论了三个核心操作:RMSNorm、矩阵乘法和注意力机制。
1. 批不变RMSNorm
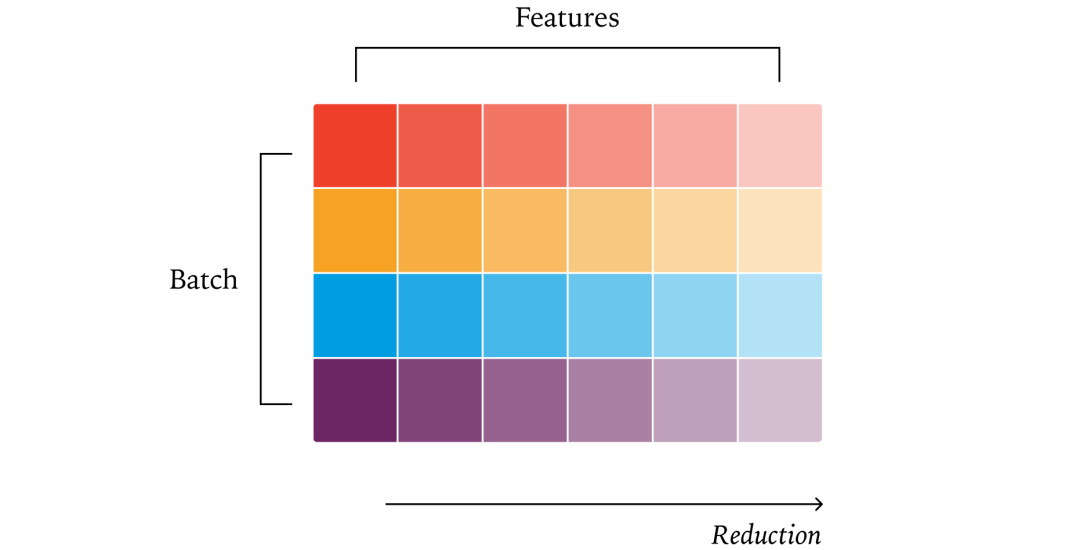
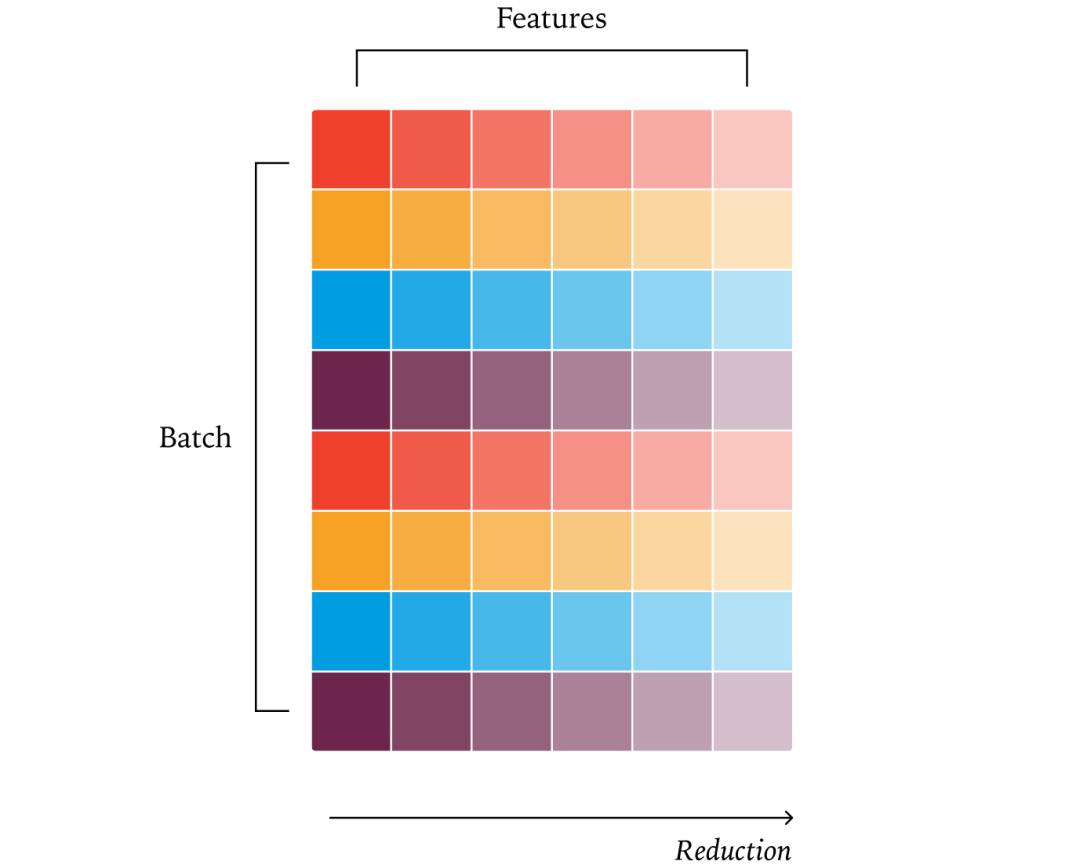
RMSNorm需要对每个样本的特征维度进行归一化(计算均方根)。理想情况下,每个样本的归一化应独立进行,且计算顺序固定。
-
数据并行策略:将每个样本分配给一个GPU核心处理,避免跨核心通信。
-
问题:当批大小很小时,GPU核心无法充分利用,可能被迫改用“拆分归约”(split reduction)策略,从而破坏批不变性。
-
解决方案:牺牲部分性能,始终采用相同的归约策略(如固定使用数据并行),即使在小批量情况下也不改变策略。
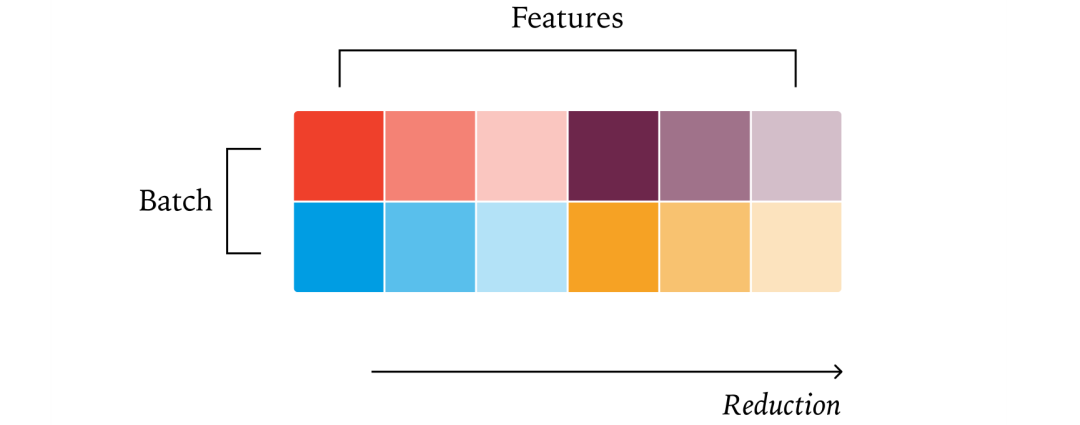
2. 批不变矩阵乘法
矩阵乘法可视为点乘后接归约操作。通常使用“数据并行”策略,将输出矩阵分块,每块由一个核心独立计算。
-
挑战:当批大小(M或N维度)很小时,为充分利用GPU,可能需沿归约维度(K)拆分(即Split-K策略),这会改变计算顺序。
-
解决方案:固定使用一种分块大小和计算策略,不随输入形状变化而调整。虽然可能损失一些性能,但能保证批不变性。
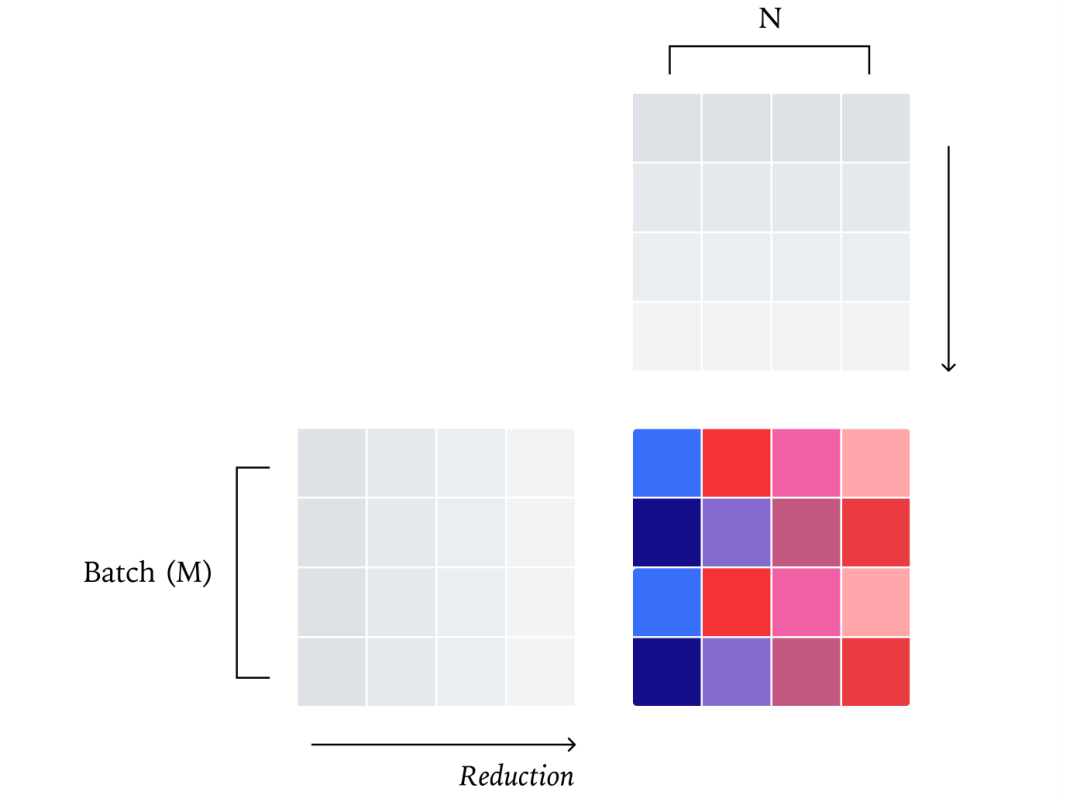
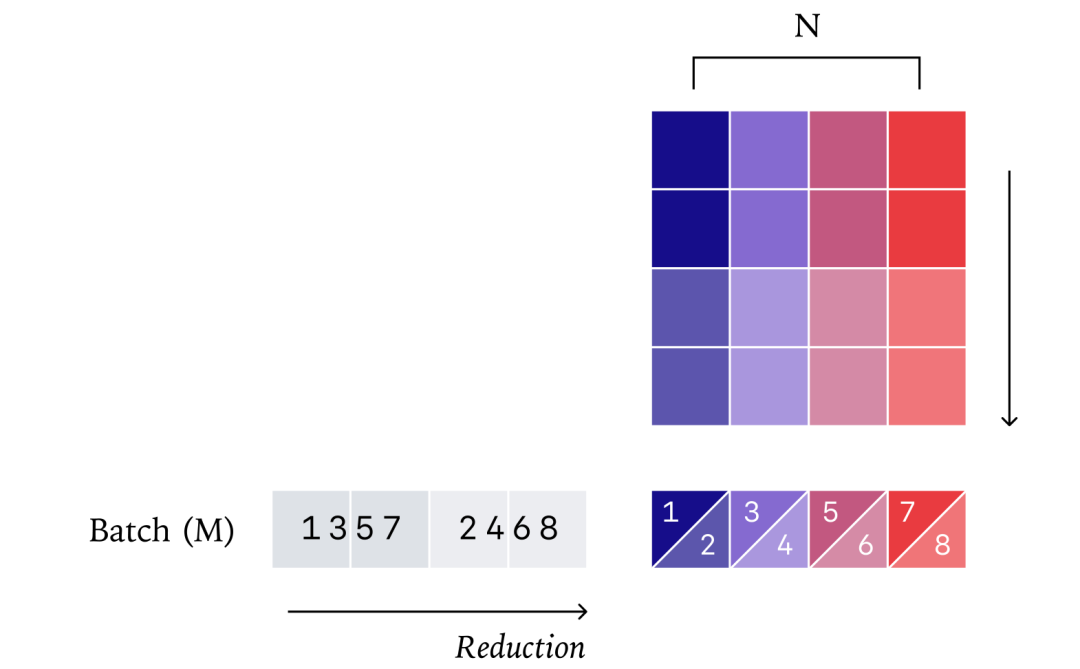
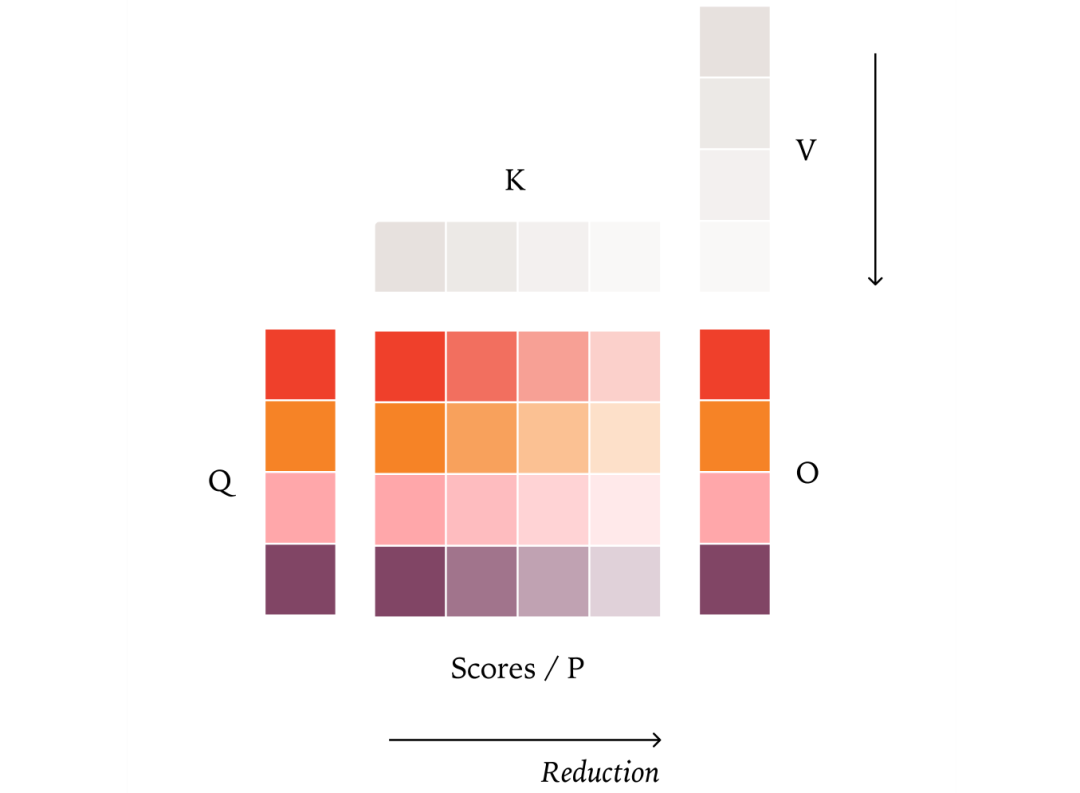
3. 批不变注意力机制
注意力机制是最复杂的部分,涉及两个矩阵乘法和序列维度的归约。
-
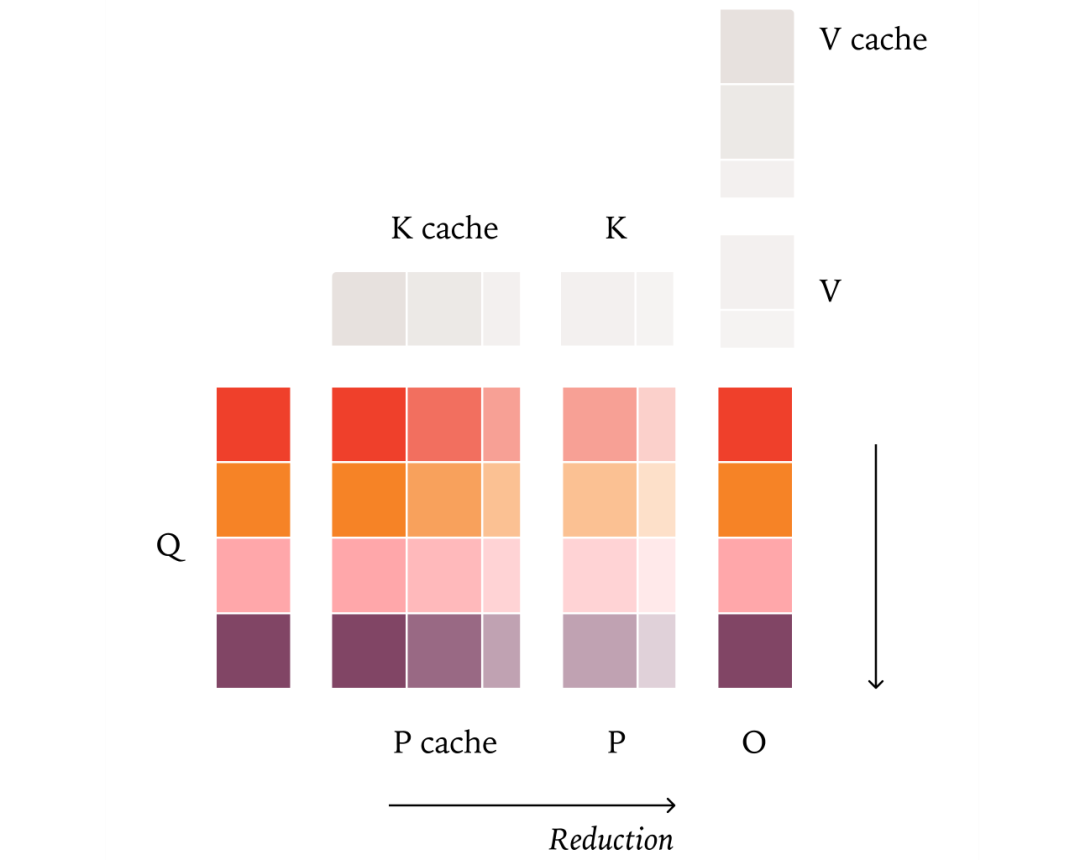
额外挑战:如何处理KV缓存、分块预填充(chunked prefill)等优化策略,这些都会影响归约顺序。
-
关键洞察:必须确保无论序列如何分块或缓存,每个查询 token 的归约顺序都一致。
-
解决方案:采用固定大小的KV分块策略(而非固定分块数),确保无论序列多长,分块方式都一致。
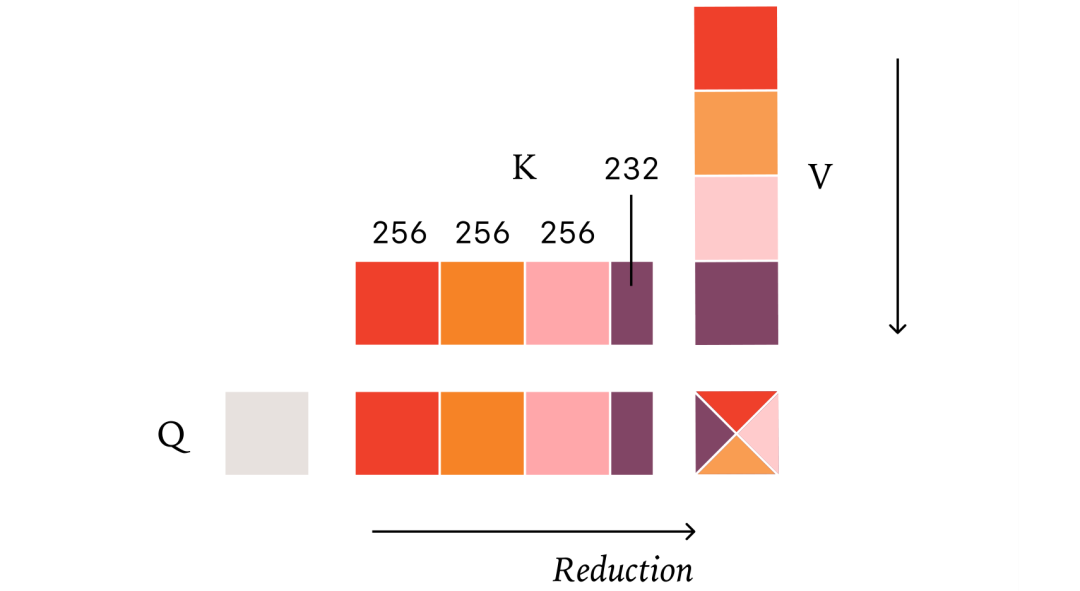
实验验证与性能分析
作者在Qwen模型上进行了实验,生成了1000条补全结果:
-
默认设置下,产生了80种不同输出,首次分歧出现在第103个token。
-
使用批不变核函数后,所有1000条结果完全一致,实现了真正的确定性。
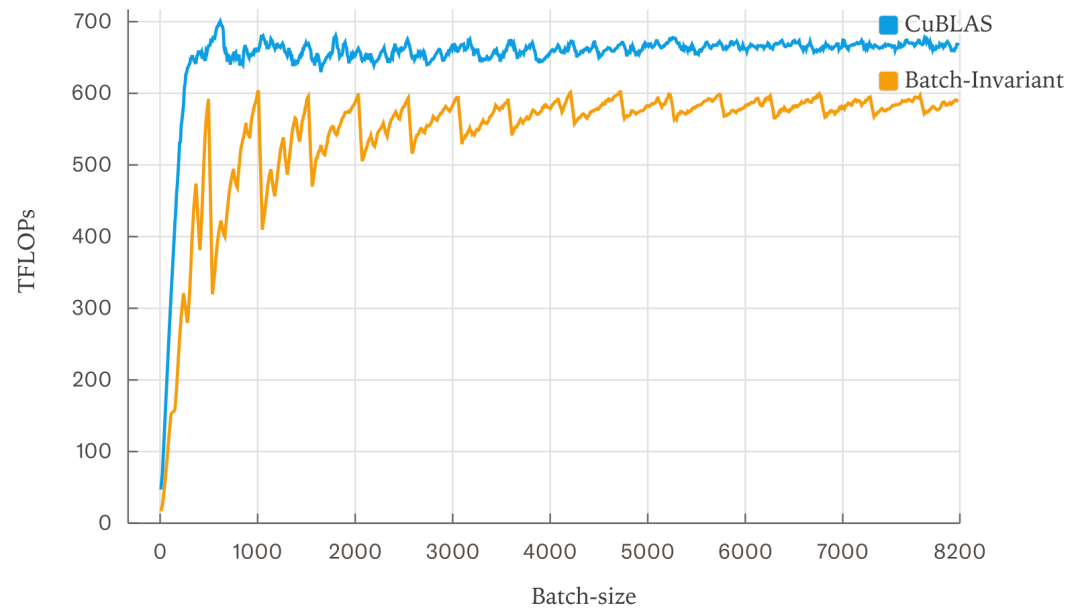
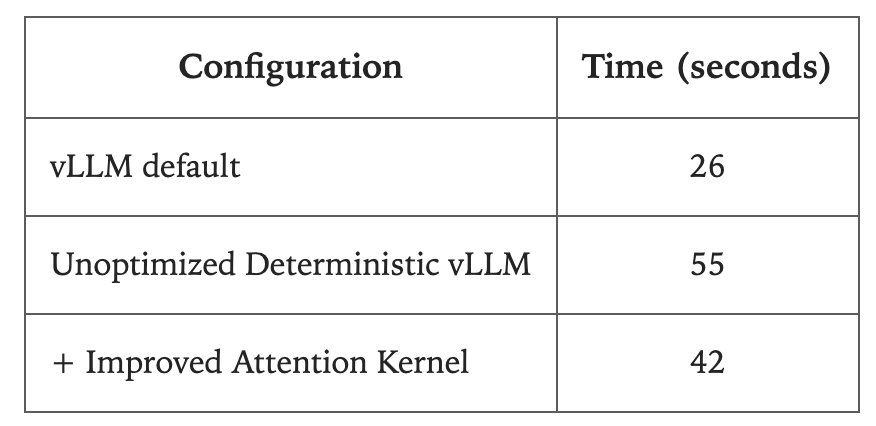
性能方面,未优化的确定性推理比默认vLLM慢约2倍(55秒 vs 26秒),但通过优化注意力内核可提升至42秒。作者指出,性能损失主要来自FlexAttention集成尚未充分优化,而非批不变性本身固有开销。
此外,作者还展示了在强化学习(RL)训练中,确定性推理能实现真正在策略(on-policy)RL,避免因数值不一致导致的策略偏离和训练崩溃。
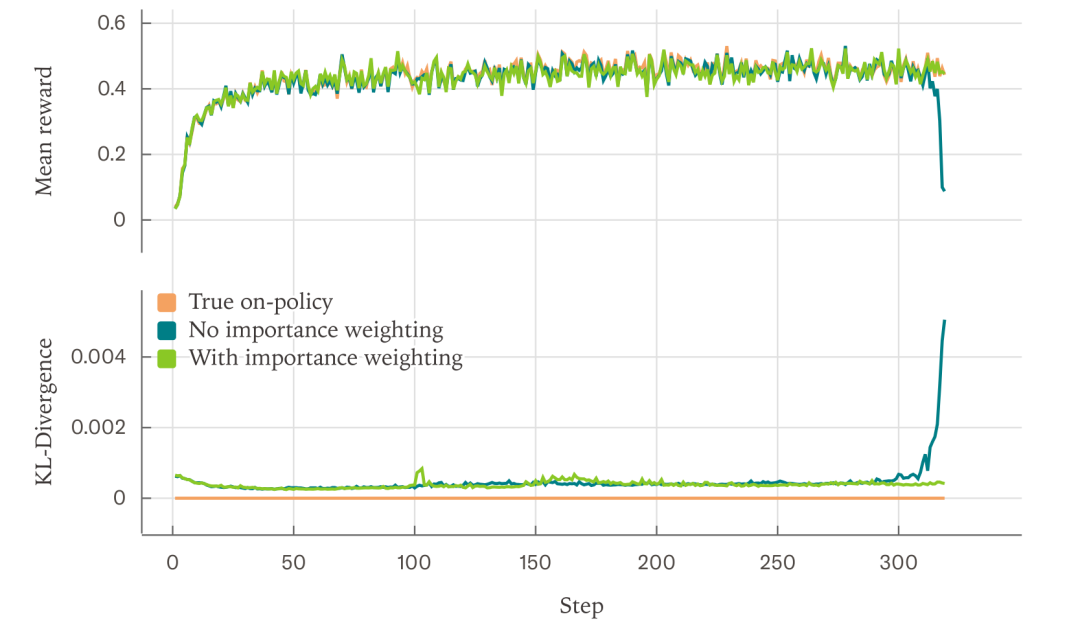
更广阔的意义:真正在策略RL与系统可靠性
这项工作的意义远不止于推理确定性:
-
训练-推理一致性:许多RLHF方法假设采样与训练使用相同的模型,但数值差异会使“在策略”RL实际上成为“离策略”,需引入重要性采样校正。确定性推理消除了这一差异。
-
系统可靠性:对于金融、医疗等高风险应用,模型行为的可预测性与可复现性至关重要。
-
调试与验证:确定性大大简化了模型调试、单元测试和版本比对。
结论
本文系统性地剖析了LLM推理非确定性的根源,驳斥了流行的“并发+浮点”假说,指出批大小变化导致的核函数非不变性才是真正原因。作者提出了实现批不变RMSNorm、矩阵乘法和注意力机制的具体策略,并通过实验验证了其有效性。
这项工作不仅解决了LLM推理中的一道难题,更体现了对机器学习系统深层次理解的追求——不要轻易接受“概率系统本应不确定”的借口,而是应深入底层,理解并控制每一处不确定性来源。
未来,我们期待看到:
-
更多优化后的批不变核函数被集成至主流推理框架(如vLLM、TensorRT-LLM);
-
训练框架也采纳相同数值策略,实现端到端的确定性;
-
确定性推理在对齐训练、模型验证等场景中得到广泛应用。



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)