面向生产环境的大模型应用开发
大模型应用开发已从“写功能”转向“评估驱动的机器学习工程”。课程梳理:范式演进、四层生产架构(数据/模型/编排/可观测)、模型生态位与量化选型、推理性能指标(TTFT/Tokens/s)、Prompt 资产化、评估闭环、数据合成与 RAG、多场景金融实践、全生命周期与常见踩坑。核心:先评估→再迭代→持续数据回流形成自增强。
·
思维导图
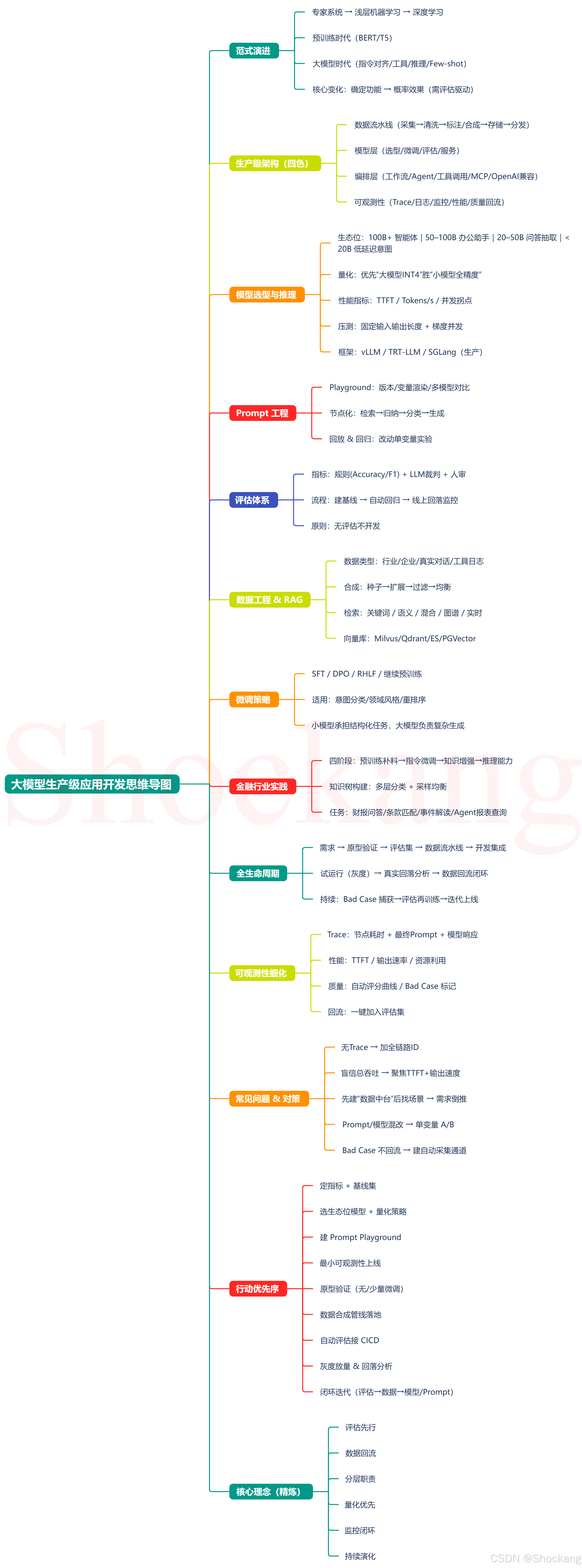
正文
1. 大模型应用开发与传统软件开发的本质差异
- 本质属性:属于机器学习工程(效果概率性)而非确定性的传统软件功能开发。
- 关键区别:
- 传统软件:功能=确定;验收=是否完成。
- 大模型应用:效果=统计分布(如 [Accuracy=85%]),需持续评估与迭代。
- 开发原则:无法量化评估(缺少指标与数据集)→ 不进入实施。
- 典型错误:直接“写功能”而缺少 原型验证 → 评估体系 → 数据基线 → 迭代循环。
- 评估驱动(Evaluation First):评估数据集与指标体系要先于工程落地。
1.1 技术范式演进
| 时代 | 主要特征 | 应用范式 |
|---|---|---|
| 专家系统 | 规则驱动 | 手工规则维护 |
| 机器学习(浅层) | 特征工程 + 任务数据 | 一任务一模型 |
| 深度学习(2012–2018) | 大量任务数据 + 深层网络 | 大规模监督训练 |
| 预训练模型时代(BERT/GPT-2/T5) | 通用语义表示 + 任务微调 | 适量样本微调(千~万条) |
| 大模型时代(ChatGPT 2022+) | 指令对齐 + 泛化 + 工具使用 + 推理 | Few-shot / Prompt 直接调用或少参适配器微调 |
1.2 现代大模型新增能力(课程强调)
- 接受自然语言指令(指令对齐)
- 泛化至未显式训练任务
- 工具/插件/外部 API 交互
- 推理与多步规划能力
- 少量增量微调(Adapter/LoRA 等)或纯 Prompt 使用
2. 生产级大模型应用总体架构(四色分层)
架构核心由四类组件协作:数据(黄)、模型(红)、编排(蓝)、可观测性(绿)。
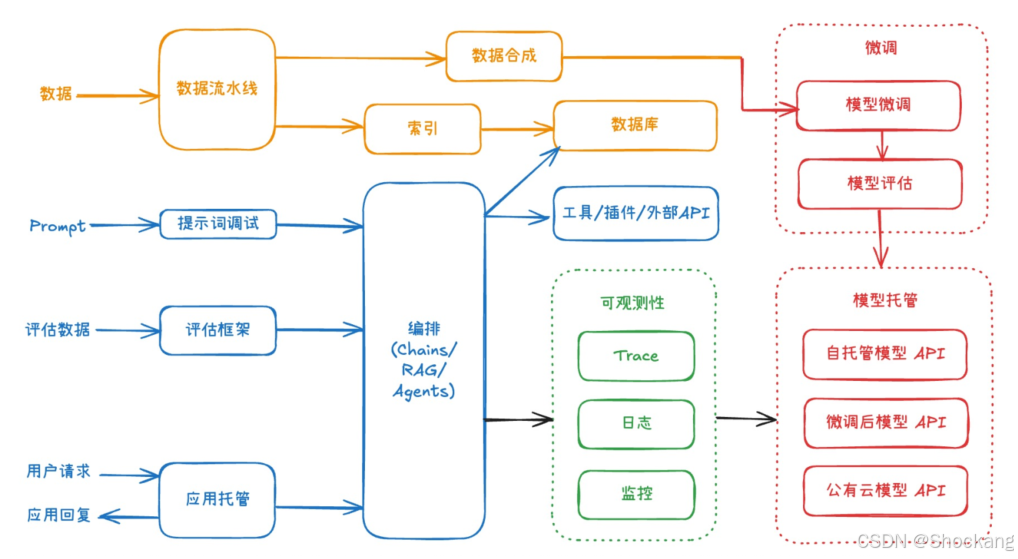
2.1 数据流水线(黄)
- 输入源:行业语料 / 企业业务数据(结构化 + 非结构化)
- 处理:采集 → 清洗 → 转格式(含 OCR)→ 标注/合成 → 存储 → 分发
- 适用:预训练补料 / 微调(SFT、RHLF、DPO)/ 评估集 / RAG 知识库 / Agent 数据
2.2 模型层(红)
- 包含:模型选择、轻量或全参微调、效果评估、推理服务托管
- 即便“不微调”亦需:在特定提示词集合或任务集上做离线/对比评估
2.3 编排层(蓝)
- 作用:工作流 / Agent / 多工具调用 / API 抽象
- 现状:模型 API 已高度统一(OpenAI 兼容);编排更多集中于内部逻辑 DSL、节点依赖、工具协议(含 MCP)
2.4 可观测性(绿)
- 必要性:复杂工作流(可达 100+ 节点)若无 Trace 难以定位延迟与错误
- 需记录:每阶段 输入/输出/耗时/模型响应/提示词最终渲染版本
- 故障案例:ES 索引未优化 → 查证延迟,被 Trace 定位而非误判为“模型慢”
- 三层要素:
- Trace(调用链、节点级耗时、提示词最终文本)
- Logging(结构化日志、有问题 Case 复现能力)
- Monitoring(TTFT、Tokens/s、吞吐、错误率、资源利用率、线上效果评估趋势)
3. 模型选型与推理实践
3.1 生态位(Niche)选型策略
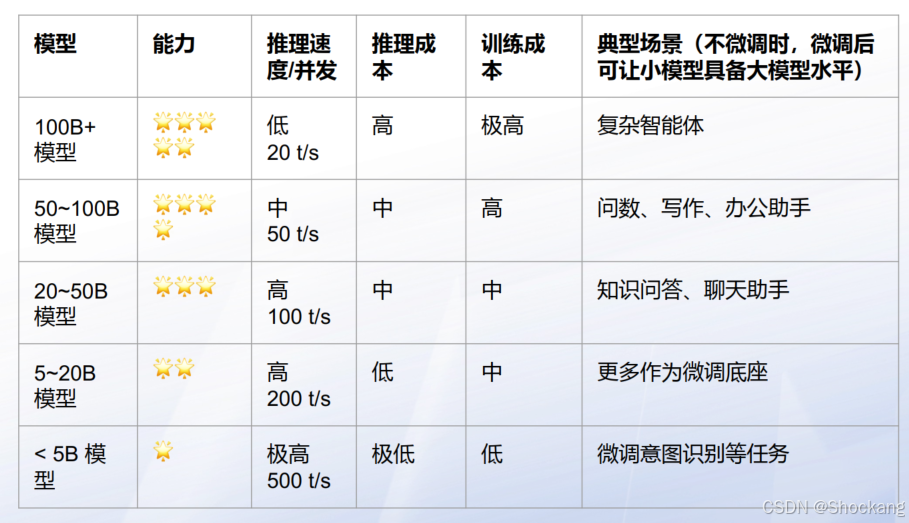
- 原则:一家公司按“能力梯度”选少量代表模型,避免维护负担。
- 分档:
- 100B+:复杂自主智能体(高推理成本 / 低吞吐)
- 50–100B:高要求问答、写作、办公助手
- 20–50B:通用问答 / 对话 / 结构化信息抽取
- 5–20B:作为微调底座(意图、领域定制)
- <5B:极低延迟场景(意图识别、小分类器)
3.2 量化策略
- 建议:优先“大模型量化”>“小模型全精度”
- 经验:INT4 量化与 FP16 效果差距“可控”;常见折中:70B INT4 可能优于 20B FP16 在相近显存预算下的综合能力
- 基础显存估算公式:显存 = 2倍模型参数 / 单参数字节数 * 1.2
- (说明:公式用于粗略预估;真实还与激活缓存/并发/上下文长度相关)
3.3 推理性能衡量与压测
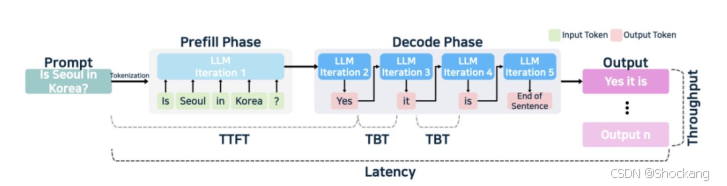
- 关键指标:
- TTFT(Time To First Token):Prefill + 首 token 解码时间
- 输出速度(Tokens per second / TPS):Decode 阶段平均输出速度
- 并发能力:在保证单用户体验下的最大同时请求数
- 非核心或易被“粉饰”指标:总吞吐(输入+输出)易被短输出/超长输入“虚高”
- 规范压测:
- 固定场景参数(如:输入 2K tokens,期望输出 200 tokens)
- 梯度并发(1→5→10→20…)
- 记录:单用户 TPS 下降拐点 & 目标 TPS(如 ≥20 tokens/s)下最大并发
- 经验数值(示例):
- 国产硬件大模型单用户输出:约 20–30 tokens/s
- H100:可达 60+ tokens/s
- 并发:国产硬件单实例常见 10–20;H100 约 50(条件匹配)
- 误区提醒:宣传“万 Tokens/s”常基于总吞吐现实无参考价值
3.4 推理框架与部署方式
- 平台托管:国内大模型平台(免去高可用/监控/调优)
- 自托管(要点列举):
- 对比维度:适用环境、模型兼容、推理速度、PEFT 支持、量化支持、OpenAI 兼容 API、分布式推理
- 框架示例:LM Studio / Ollama / text-generation-webui / vLLM / TRT-LLM / SGLang
- 生产推荐:vLLM、TRT-LLM、SGLang(高吞吐 + 分布式 + 量化支持)
4. Prompt(提示词)工程体系
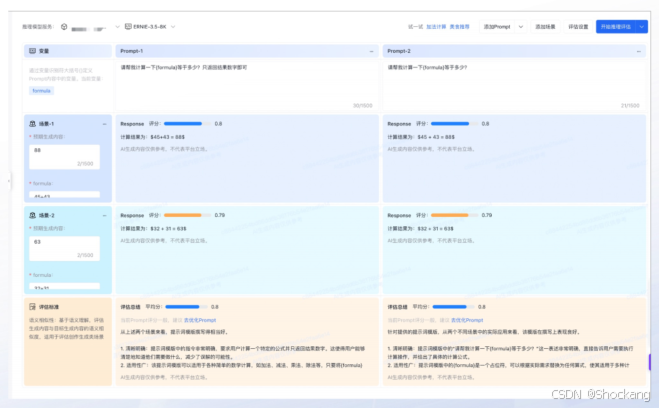
4.1 Prompt Playground 功能要求
- 模板参数化与版本管理
- 多模型/多模板并行对比
- 联动评估触发(调用评估管线)
- 历史渲染记录(避免仅见“代码模板”)
- 变量注入回显(最终投喂模型的真实 Prompt 可追溯)
4.2 调参与维护
- 提示词集合=“工程资产”
- 不同节点(检索、归纳、分类、生成)应建立各自子评估集
- Prompt 迭代与评估闭环:修改 → 回放历史 Case → 自动打分 → 回归对比
5. 评估(Evaluation)驱动体系
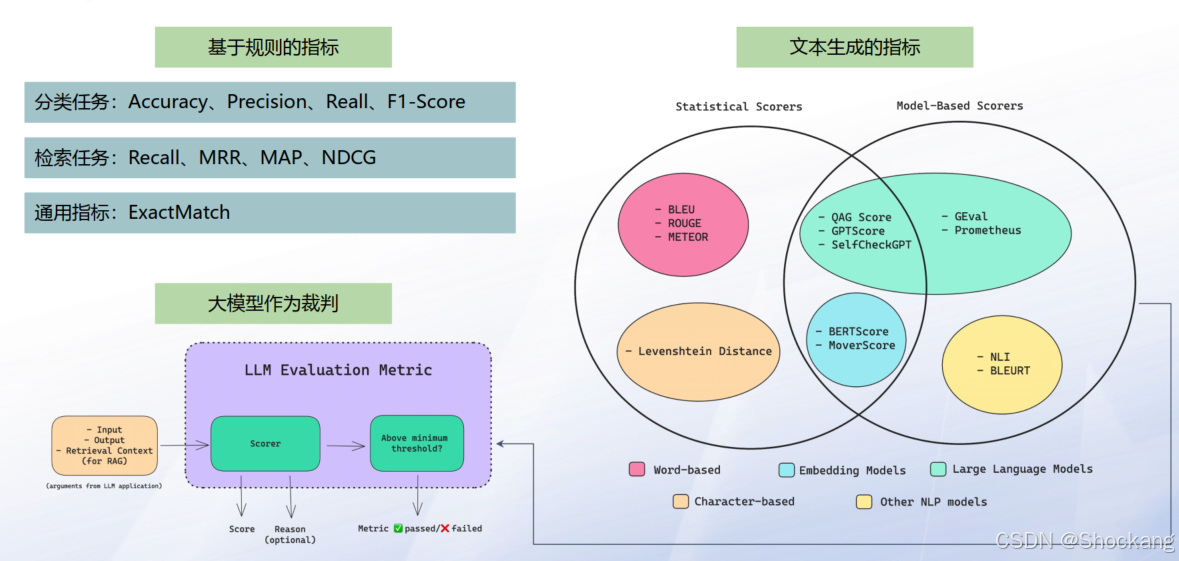
5.1 评估类型
- 基于规则 / 传统指标:
- 分类:[Accuracy, Precision, Recall, F1]
- 检索:[Recall, MRR, MAP, NDCG]
- 生成一致性:[ExactMatch]
- LLM 作为裁判(Judge):主观质量、格式合规、推理链正确性
- 人工标注:用于关键高风险样本(Bad Case 审核/新增)
5.2 实施路径
- 先建立任务/场景分层评估数据集(基线 Baseline)
- 引入评估框架(课程提及:LangSmith、DeepEval 等)
- 将评估挂入 CICD / 回归流水线
- 线上效果监控:新增真实用户样本 → 标注/裁判 → 回流评估集 → 指标曲线
5.3 关键原则(再次强调)
- “无评估不开发”
- 评估标准=上线阈值(如:问答准确率 ≥80% 才进入试运行)
- 上线后真实数据集效果必然回落(示例:验收 85% → 线上真实 50% 仍属常见)
6. 编排(Orchestration)
6.1 目标
- 管理复杂工作流节点(检索 → 过滤 → 构造 Prompt → 推理 → 复写 → 评估)
- Agent 工具调用(API、数据库、插件)
- 统一模型/工具协议(OpenAI 兼容 + MCP 协议趋势)
6.2 技术选项(课程列举)
- 低/无代码:千帆 AppBuilder、Dify、FlowiseAI、FastGPT、Coze
- 代码态:LangChain、PromptFlow、LlamaIndex、HeyStack(Haystack)、LangGraph
- Agents:AutoGen、CrewAI、LangGraph(亦支持)、smolagents
- 课程提醒:层次过深(如 LangChain 多层封装)调试成本高;理解调用栈链路重要
7. 微调(Fine-tuning)
7.1 类型
- Post-pretrain(持续预训练补料)
- SFT(监督微调)
- RHLF(人类偏好强化)
- DPO(偏好直接优化)
- 工具:推荐使用平台图形化操作;开源 LoRA/PEFT 框架亦可
7.2 适用场景
- 领域意图识别 / 槽位抽取(小模型足矣)
- Embedding 向量表示领域化(金融、法务等)
- RAG 检索重排序器(可选)
- 领域指令风格一致性(金融解读、事件分析)
8. 可观测性(Observability)
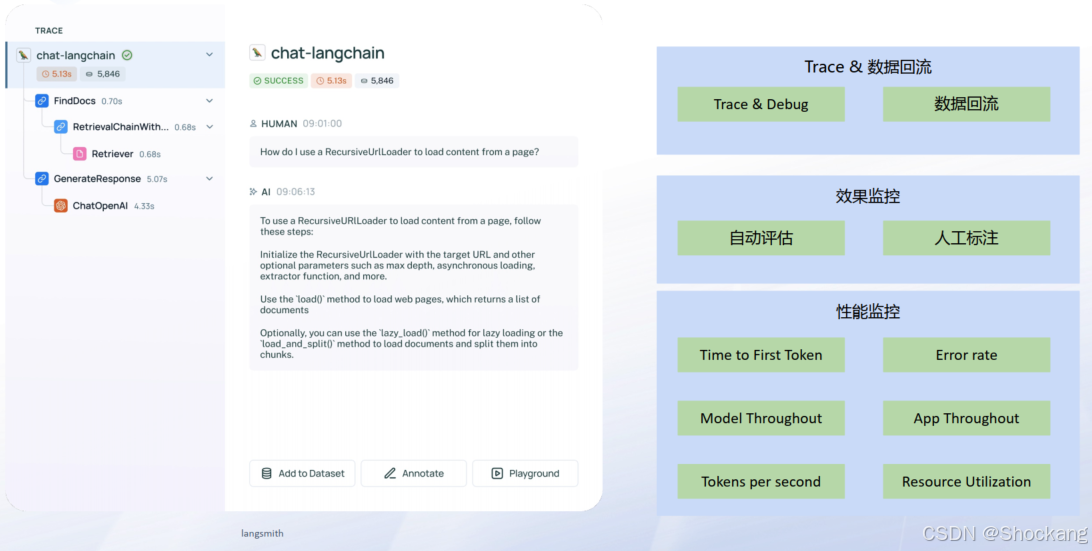
8.1 监控指标
- 性能:TTFT、Tokens per second、Model Throughput、App Throughput
- 质量:自动评估分、人工标注通过率
- 稳定性:Error Rate
- 资源:GPU/CPU/内存/显存带宽
- 数据回流:支持一键加入评估数据集、生成新 Prompt 版本沙箱
8.2 核心能力
- Trace:全链路节点耗时 + 输入输出 + Prompt 渲染
- Debug:可复现 Bad Case(保存“真实发送”内容而非模板片段)
- 评估联动:线上失败样本直接加入评估集再回归
- 性能诊断:区分“模型慢” vs “检索/索引慢”(案例:ES 查询延迟)
9. 数据工程体系(含合成数据)
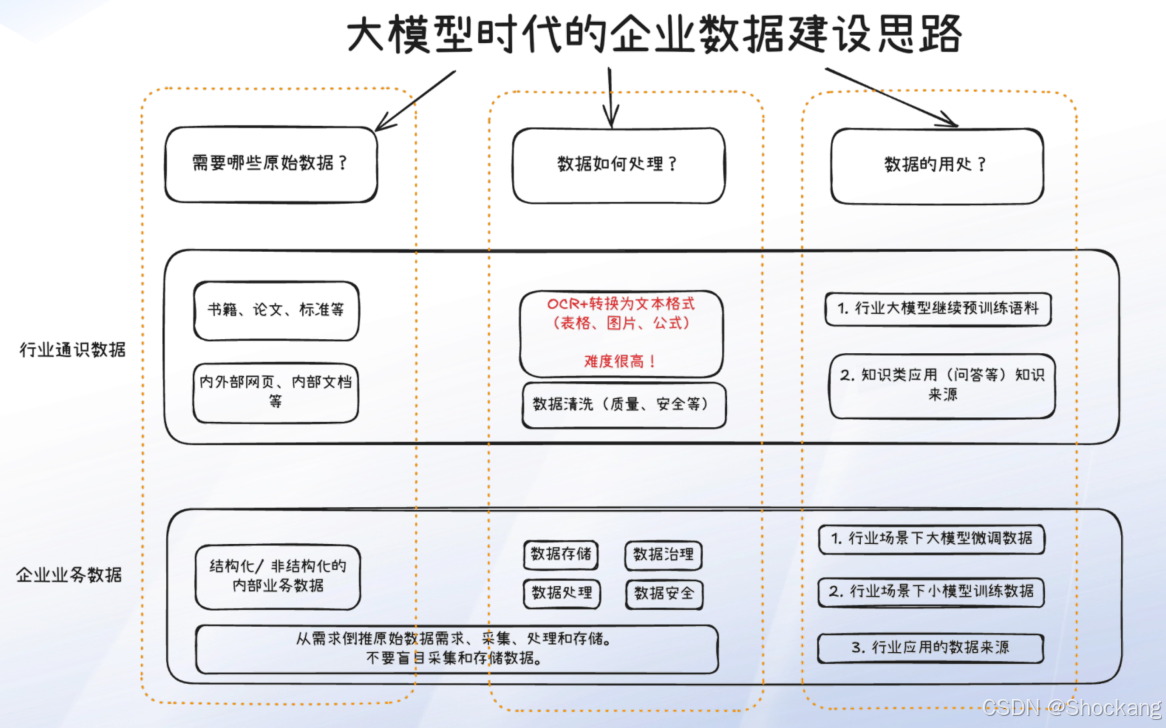
9.1 分类
- 行业/通识数据:公开文本、标准、论文、考试题、专业书籍、政策规范
- 企业业务数据:结构化(交易、报表、风险指标)、半结构/非结构(PDF、报告、邮件)
- 需求倒推:先定义“用来做什么”→ 确定数据结构与覆盖 → 再收集与治理(避免“先堆中台”)
9.2 合成数据(课程强调)
- 现代训练(含预训练补料、SFT、评估、Agent/RAG 任务)高度依赖合成
- 人工标注主要用于:少量种子(Seed)/ 战略性高质量样本 / Bad Case 精修
- 合成流程(示意):
- 种子样本(人标 10~20 条/场景)
- 模型扩展生成(多样化问法 / 场景扰动)
- 质量过滤(规则 + 模型裁判)
- 分布均衡(按知识树/场景配比调节)
9.3 OCR 与格式化
- 高难度环节:将扫描/排版复杂文档转结构文本(后续才可进入清洗/分块/索引)
10. 检索(RAG)体系扩展
10.1 多检索模式
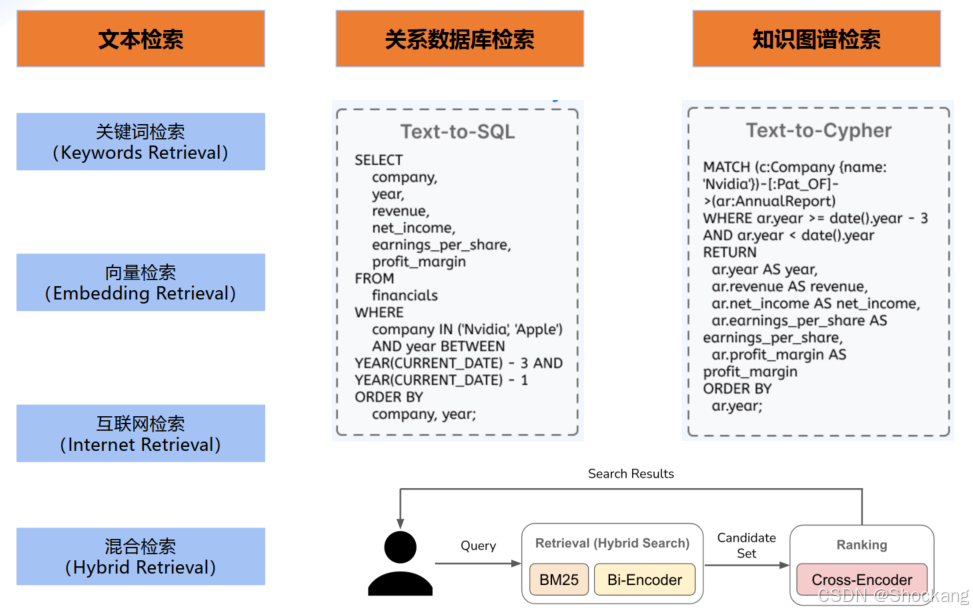
- 关键词检索(精确条款、法规定位)
- 向量检索(语义召回)
- 混合检索(推荐默认:关键词 + 语义)
- 互联网检索(外部实时性)
- 数据库直接查询(SQL / 表格事实)
- 知识图谱检索(实体关系、风险溯源)
- 其他:结构化指标查询、关系型拓展(PostgreSQL + pgvector)、ES / Redis / MongoDB 追加向量索引
10.2 向量数据库选项
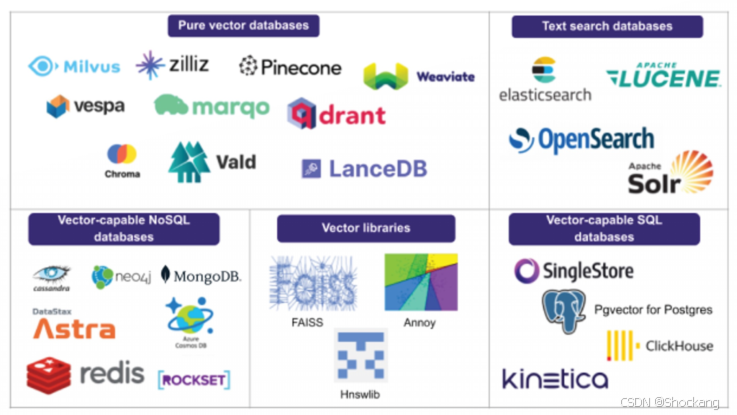
- 专用:百度云 VectorDB、Qdrant、Milvus、ChromaDB、Pinecone
- 非关系 + 向量:MongoDB、ElasticSearch、Redis
- 关系 + 向量:PostgreSQL + PGVector
11. 全生命周期开发流程
11.1 阶段
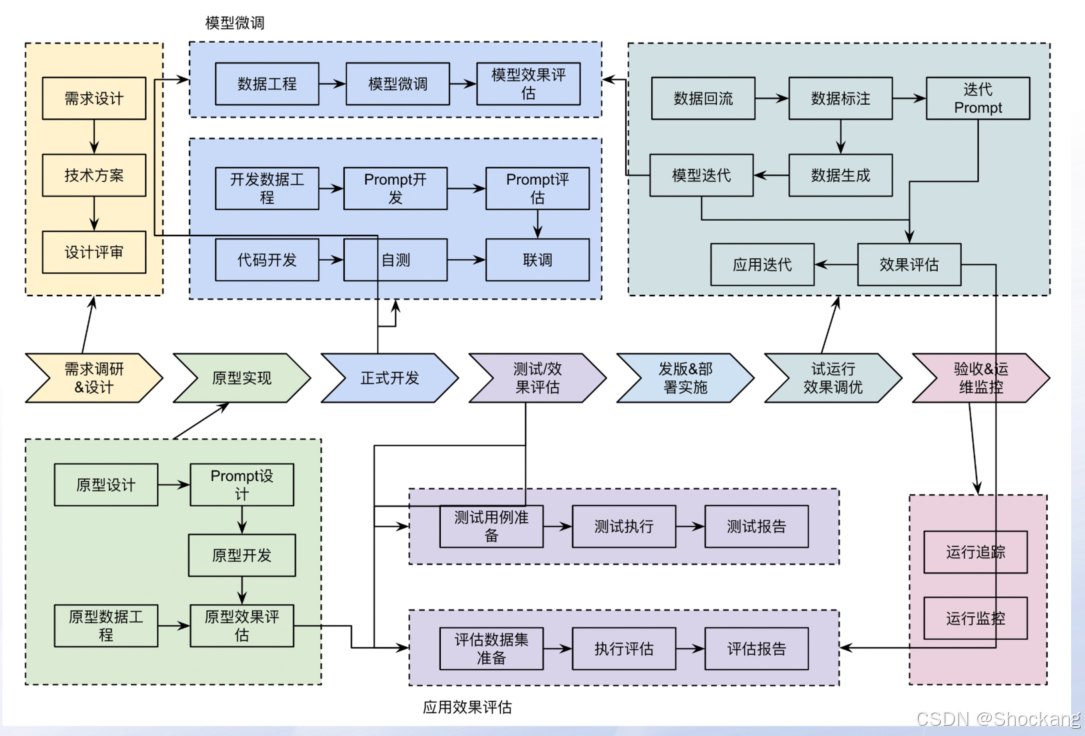
需求分析 → 原型验证 → 效果评估标准确定 → 评估数据集构建 → 数据工程与流水线 → 应用/模型开发与集成 → 测试 → 试运行(真实流量灰度)→ 持续迭代(数据回流 / Prompt & 模型调优)
11.2 与传统软件的关键差异
| 阶段 | 传统 | 大模型 |
|---|---|---|
| 原型 | 可省略 | 必须(验证可行性与评估方式) |
| 评估 | 功能验收 | 指标体系(定量效果) |
| 上线 | 一步发布 | 需试运行(真实流量回落观测) |
| 迭代 | 需求驱动 | Bad Case 驱动 + 数据回流 |
11.3 线上回落现象
- 验收集:85%(示例)
- 真实用户:可能仅 50%(问题分布与分布外提问)
- 处理:新增 Bad Case → 标注或裁判 → 加入评估集 → 调 Prompt / 增补检索 / 微调 → 回归对比
11.4 持续循环(闭环)
线上监控 -> 缺陷定位 -> 标注/合成补集 -> 模型/Prompt/检索改进 -> 评估回归-> 再上线
11.5 时长参考
- 首轮“可用”应用:≥ 3 个月
- 稳定与持续提升:可跨 12 个月以上
12. 金融行业实践
12.1 行业模型训练阶段
- 行业语料持续预训练(构建领域知识底座)
- 金融指令微调(适配任务表达与风格)
- 领域知识增强(知识树覆盖差补)
- 推理/思维能力强化(“思维模型”阶段,链式推理/偏好优化)
12.2 金融知识体系构建
- 知识树:一级(宏观/学科类别)→ 二级(教材/题库/规章)→ 三级(细颗粒概念)
- 分类模型帮助:对抓取/解析数据归入树节点
- 配比调节:训练时按节点频次/重要性调整采样(防稀疏/防偏斜)
12.3 数据类型
| 类型 | 来源 | 用途 |
|---|---|---|
| 预训练补料 | 公开政策/教材/考试题/书籍 | 语义+知识覆盖 |
| SFT 指令数据 | 种子(人标 10~20)→ 合成扩展 | 任务表达/风格统一 |
| 评估数据 | 基线 + Bad Case | 效果量化与回归 |
| Agent 数据 | 真实场景交互记录 | 工具调用优化 |
| 向量检索库 | 内部制度/报告/公告 | RAG 召回 |
12.4 典型任务
- 传统 NLP:意图识别、槽位识别、情绪分析
- 金融专属:事件解读、财报问答、监管条款匹配、风险画像、投研摘要
- Agent 场景:报表查询 + 解释、行情事件多来源拼接、工具序列规划
12.5 经验要点
- 并非“一步到位”覆盖全部 300–500 任务;应增量扩展
- 评测集成绩只是参考;真实体验优先
- 小模型(意图/结构抽取)与大模型(长文本分析/解释)协同
13. 常见易忽视问题(课程典型提醒)
| 问题 | 现象 | 解决要点 |
|---|---|---|
| 缺少 Trace | “模型好慢”无法定位 | 建立全链路调用图 |
| 仅保存 Prompt 模板 | 无法复现线上 | 保存最终渲染版本 |
| 盲信吞吐指标 | 宣传数值虚高 | 聚焦 TTFT + 输出 Tokens/s |
| 直接全量建中台 | 数据闲置/不匹配 | 需求倒推收集与建模 |
| 无评估先开发 | 迭代无方向 | 先建基线与指标 |
| Prompt/模型混改 | 不可衡量改动贡献 | 单变量对比实验 |
| 漏 Bad Case 回流 | 线上效果停滞 | 建立自动回流渠道 |
14. 精炼行动清单(落地优先顺序)
- 定义评估指标 & 构建最小评估数据集(Baseline)
- 选定模型生态位(旗舰 / 通用 / 微调底座)
- 搭建 Prompt Playground(含版本化与多模型对比)
- 建立最小可观测性(Trace + TTFT + TPS + 错误率)
- 构建原型(不做微调或用少量 LoRA)验证可实现性
- 规划数据流水线(含合成策略 + Bad Case 回流)
- 接入自动评估流水线(回归+版本对比)
- 进入试运行(灰度 + 收集真实分布)
- 持续循环:数据→评估→迭代→发布
15. 关键公式/术语回顾
- 显存粗估:显存 = 2倍模型参数 / 单参数字节数 * 1.2
- 指标:
- TTFT:首 token 延迟
- 输出速度(Tokens/s)
- 并发能力:满足目标 Tokens/s 下最大并发
- 不推荐单独看:总吞吐(输入+输出)— 可能失真
总结
大模型应用开发=“评估驱动的机器学习系统工程”。 成功的关键不在“写出功能”,而在于:
- 严谨的评估与可观测体系;
- 以需求倒推的数据/合成/回流循环;
- 合理的模型生态位布局与量化/推理优化;
- 可演化的编排与 Prompt 资产管理;
- 持续吸收真实线上分布,形成闭环改进。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)