阿里:RL强化LLM推理,是技巧还是陷阱?
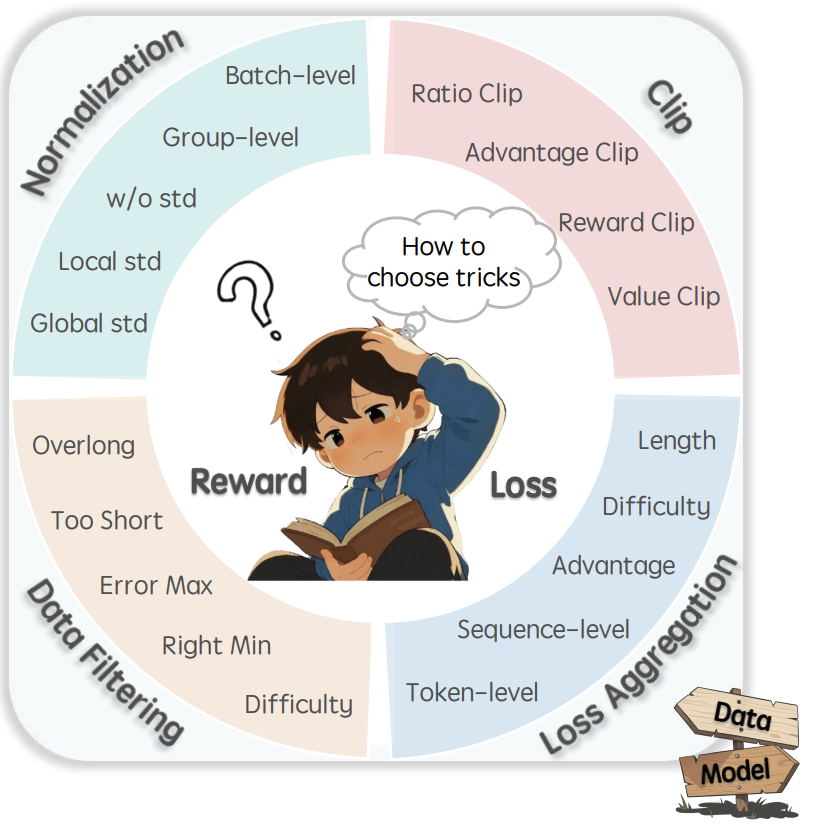
涌现了GRPO、DAPO、REINFORCE++等众多RL“技巧”(Tricks),它们在归一化、剪裁、过滤等细节上提出矛盾方案(例如:GRPO主张组内归一化,REINFORCE++坚持批处理归一化)。:RL能将人类偏好或任务奖励注入LLM,使其超越预训练极限。近年来,强化学习(RL)已成为解锁大型语言模型(LLM)复杂推理能力(如数学证明、代码生成)的关键工具,催生了大量研究(统称。:在统一框架
近年来,强化学习(RL)已成为解锁大型语言模型(LLM)复杂推理能力(如数学证明、代码生成)的关键工具,催生了大量研究(统称 RL4LLM)。然而,这一领域的快速发展也带来了“成长的烦恼”:
-
技术丛林:涌现了GRPO、DAPO、REINFORCE++等众多RL“技巧”(Tricks),它们在归一化、剪裁、过滤等细节上提出矛盾方案(例如:GRPO主张组内归一化,REINFORCE++坚持批处理归一化)。
-
结论混沌:不同论文因模型初始化、训练数据、实验设置的差异,得出相互冲突的结论,让从业者陷入“选择困难”。
-
机制模糊:多数技巧缺乏对其内在机理和适用场景的深入分析,沦为“黑箱操作”。

-
论文:Tricks or Traps? A Deep Dive into RL for LLM Reasoning
-
链接:https://arxiv.org/pdf/2508.08221
这篇由 阿里联合多所高校 发表的论文,如同一场“及时雨”。它通过大规模可复现实验,在统一框架下系统解剖了主流RL技巧,揭示了它们的本质机制、敏感条件和最佳实践,并惊人地发现:一个仅包含两项技巧的极简组合(Lite PPO),性能竟超越复杂方案。下文将带您深入这场“RL祛魅之旅”。
研究背景与动机:混乱中的求索
-
RL4LLM的崛起:RL能将人类偏好或任务奖励注入LLM,使其超越预训练极限。例如,在数学竞赛题(MATH-500)或代码生成(BigCodeBench)中,RL微调模型表现显著优于SFT模型。
-
技术选择的困境:论文指出,当前RL4LLM领域存在两大痛点:
-
-
无标准指南:不同论文对同一问题(如“如何归一化优势函数?”)给出相反答案,缺乏权威指导。
-
碎片化理解:技术效果高度依赖实验设置(模型架构、数据分布、奖励机制),导致结论不可迁移。
-
-
实践者的核心诉求:从业者迫切需要明确两个问题(原文加粗强调):
What scenarios are the existing techniques respectively suitable for? Is there a simple and generalized combination?
(现有技术分别适合什么场景?是否存在简单通用的组合?)
本文正是为回答这两个问题而生。
方法论:构建公平的“技术竞技场”
-
统一战场 (ROLL框架) :所有实验基于开源 ROLL框架(阿里自研高效RLHF平台),确保基础设施一致性。
-
控制变量法:严格隔离技术效果,核心策略包括:
-
-
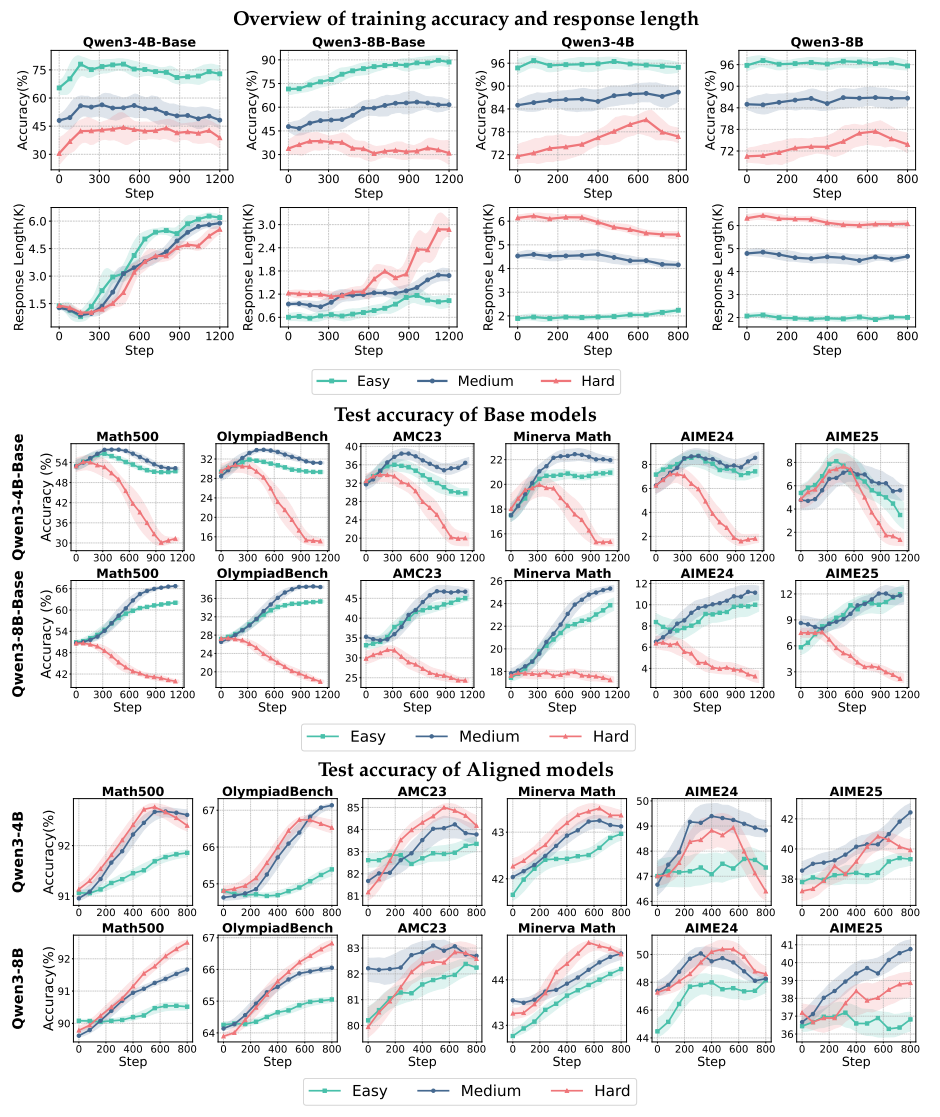
模型对比:涵盖不同规模(4B, 8B)和类型(基础模型 Qwen-Base vs. 对齐模型 Qwen)。
-
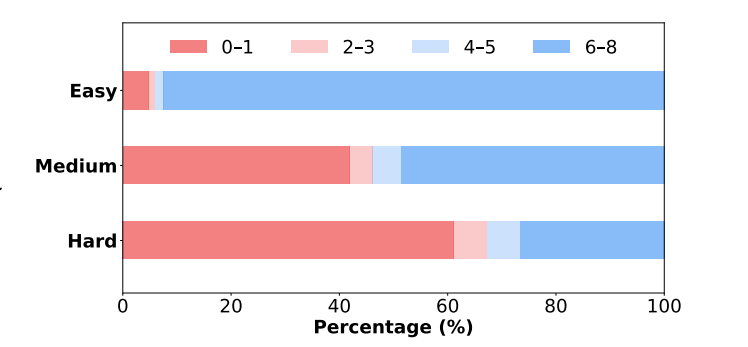
数据分层:训练集按难度分级(Easy/Medium/Hard),源自开源数据集(SimpleRL-Zoo-Data, DeepMath),避免二值标签噪声。
-
技术解耦:逐个评估技术(如只改动归一化方式),避免交叉干扰。
-
评估基准:6大数学推理数据集(如MATH-500, OlympiadBench),覆盖基础算术到奥赛难度。
-
-
基线设定:使用最朴素的 PPO + REINFORCE(无价值函数)作为基线,凸显技巧的增量价值。
核心发现:RL技巧的“适用条件说明书”
归一化技术 (Normalization) - 稳定训练的关键阀
问题核心:优势函数计算(如GRPO的组内归一化)需标准化以稳定梯度,但方法各异(组内vs批量)。
公式解析:
-
组内归一化 (Group-Level) :同一提示词下K个响应的奖励归一化
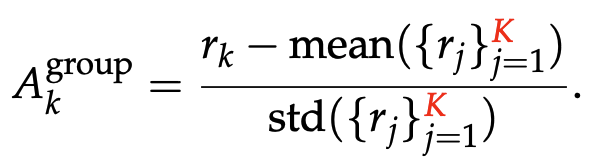
-
-
:第k个响应的奖励
-
分母:组内奖励标准差 → 放大组内差异,促进竞争
-
-
批量归一化 (Batch-Level) :整个批次N*K个响应的奖励归一化
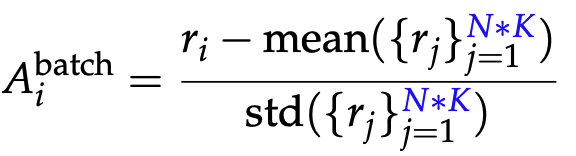
-
-
分母:全局批次标准差 → 平滑全局分布,避免过拟合
-
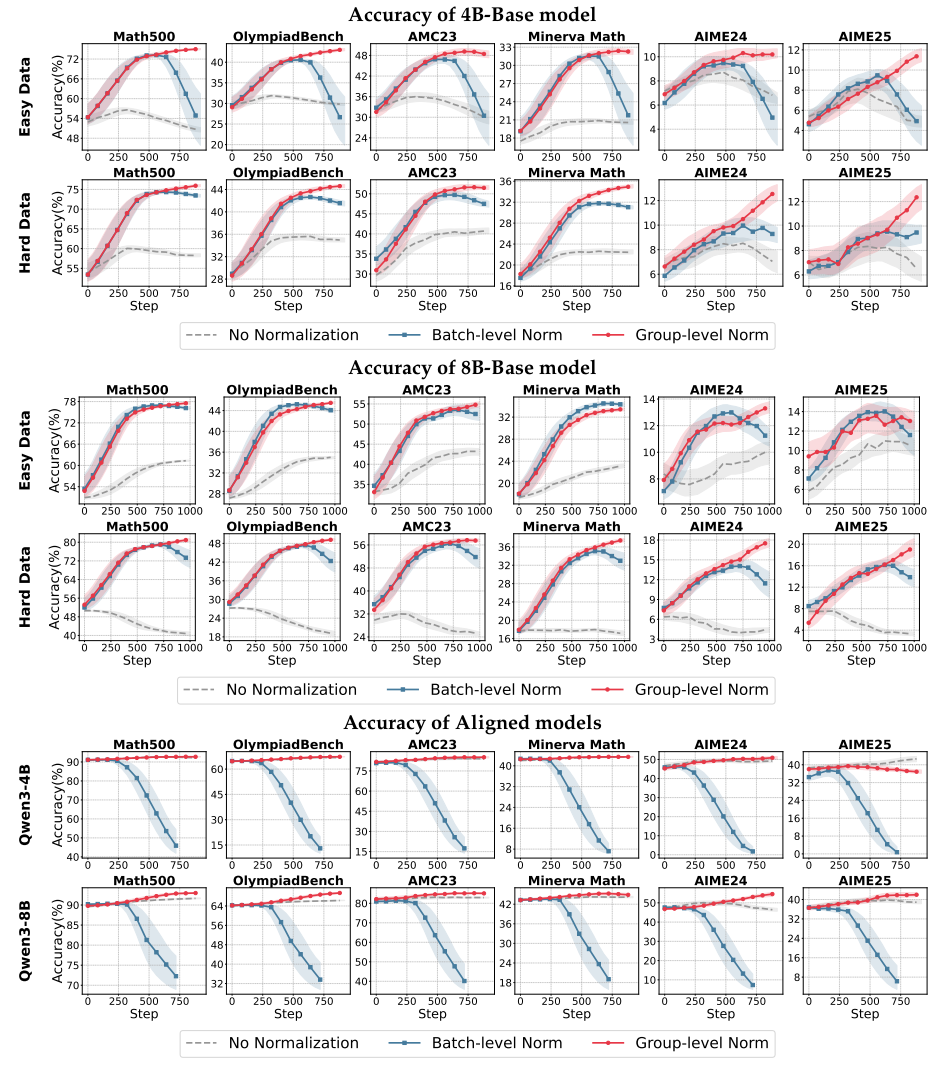
发现:
-
奖励机制敏感性:
-
默认二值奖励(R∈{0,1})时 → 组内归一化更鲁棒,批量法易受异常样本干扰崩溃。
-
扩大奖励差距(R∈{-1,1})时 → 批量归一化效果显著提升。
原因:奖励尺度影响标准差计算,改变梯度更新强度。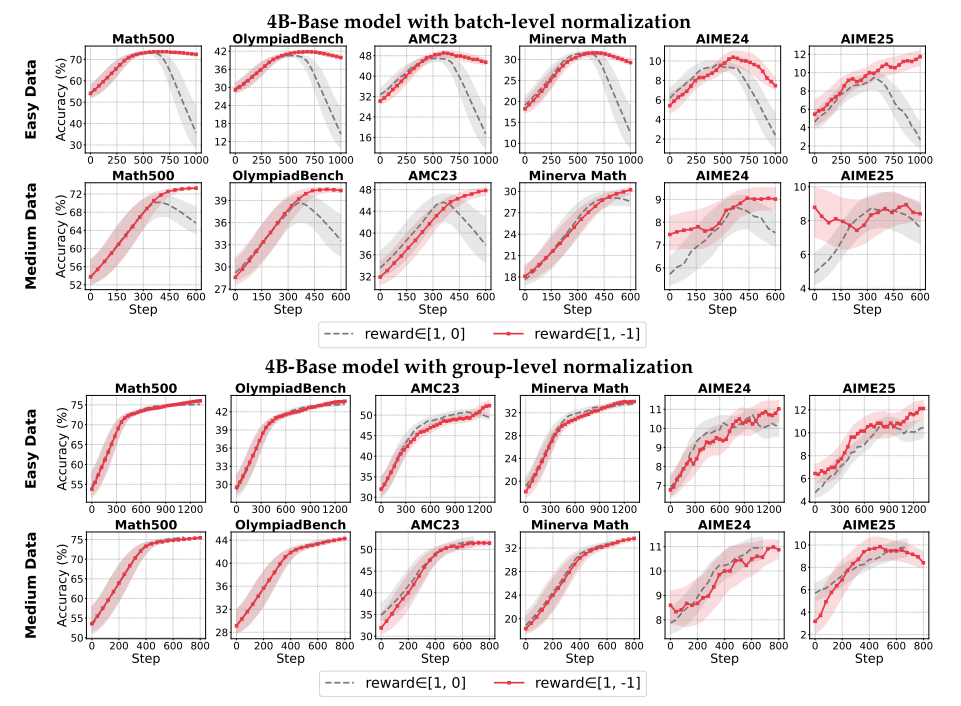
-
标准差的双刃剑效应:
当奖励分布集中(如简单数据集下模型响应全对/全错),微小标准差会过度放大梯度,引发训练震荡。此时移除标准差(仅中心化:A = r - mean)反而更稳定!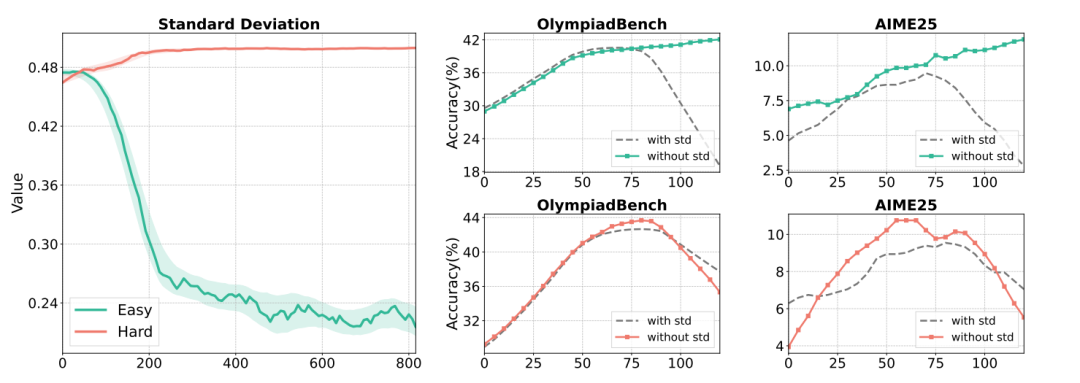
-
黄金组合诞生:
分组计算均值 + 批量计算标准差 的组合(公式融合二者思想)在各类场景下最鲁棒。
机理:组均值保留局部竞争信号,批标准差提供全局稳定性,避免极端值干扰。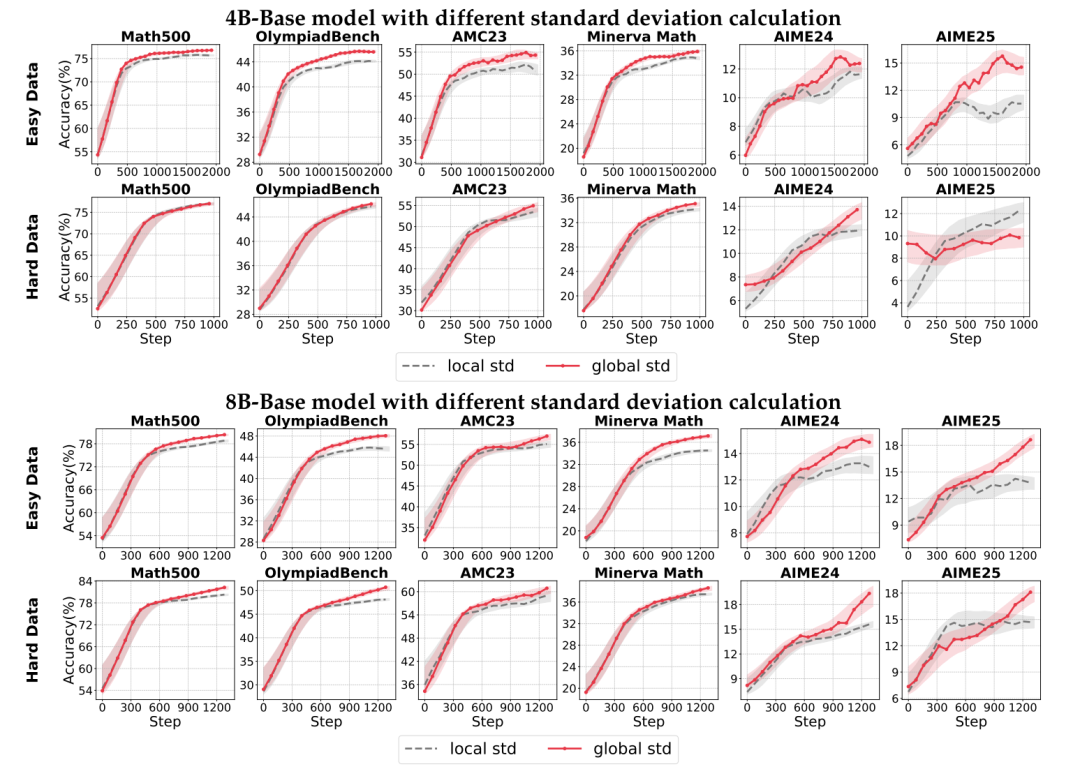
Clip机制 (Clipping) - 探索与稳定的博弈
问题核心:PPO的Clip机制(限制策略更新幅度)虽保稳定,但会抑制低概率词元,导致“熵崩塌”(模型输出僵化,丧失多样性),对需探索的复杂推理任务有害。
Clip-Higher创新:放宽PPO的上界剪裁(原公式中1+ε),允许更大正向更新:
-
> 原PPO的ε → 给低概率词元“翻身机会”。
突破性认知:
-
模型能力依赖性:
-
对齐模型(已具较强推理力):提高 显著缓解熵崩塌,促进探索优质解。
-
基础模型(能力较弱):增大 收益甚微,甚至有害。
原因:基础模型表达能力有限,本身难探索高奖励轨迹;对齐模型初始分布更平缓(Figure 10),宽松上界能激活潜力。
-
语言结构视角:
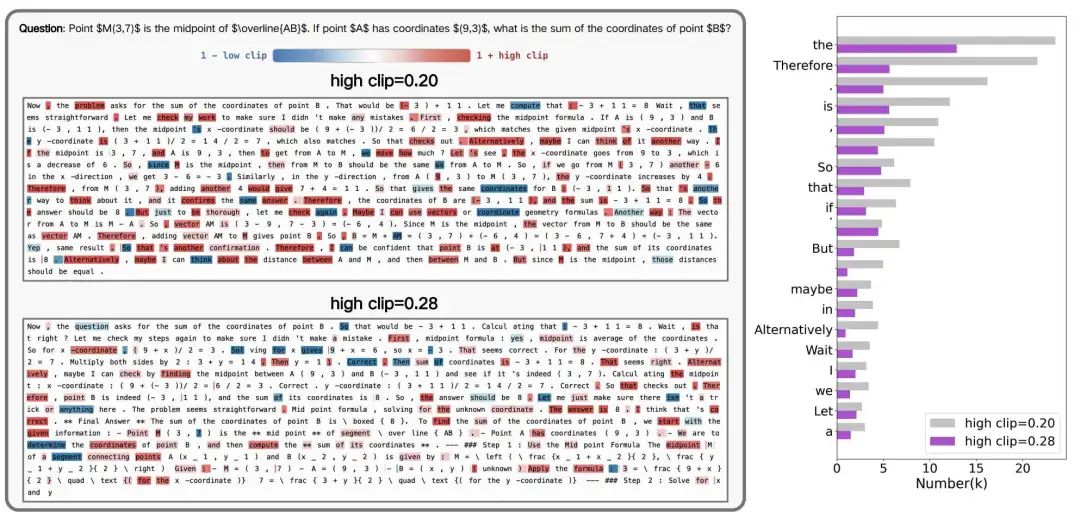
-
传统紧剪裁( )主要限制逻辑连接词(如“therefore", "if"),抑制推理创新。
-
宽松剪裁( )将限制转移至高频功能词(如“is", "the"),释放逻辑结构多样性。
-
上界设置的缩放律:
小模型(4B)性能随 提升而单调增长;大模型(8B)则在 处存在峰值。→ 需按模型规模调参!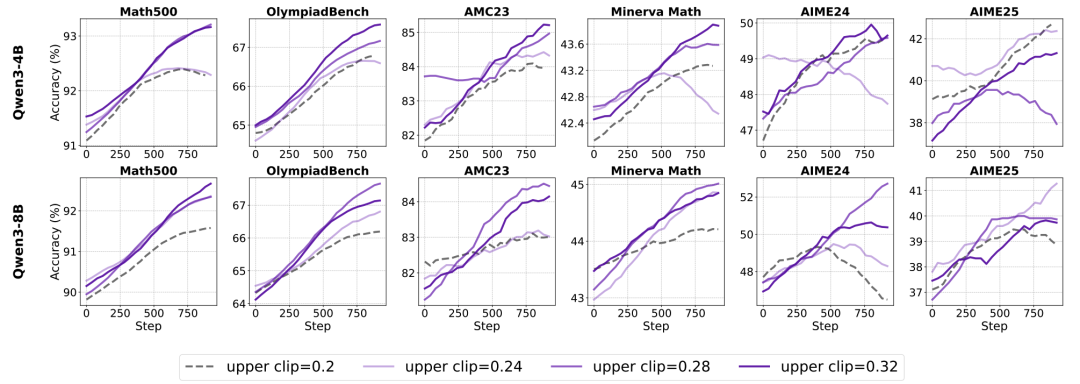
损失聚合粒度 - 长文本学习的密码
问题核心:损失计算单位影响梯度更新权重。
-
序列级 (Sequence-Level) :每个响应视为整体,平均损失 → 短响应占优,长文本贡献被稀释。
-
词元级 (Token-Level) :所有响应中每个词元平等贡献 → 解决长度偏差。
结论 :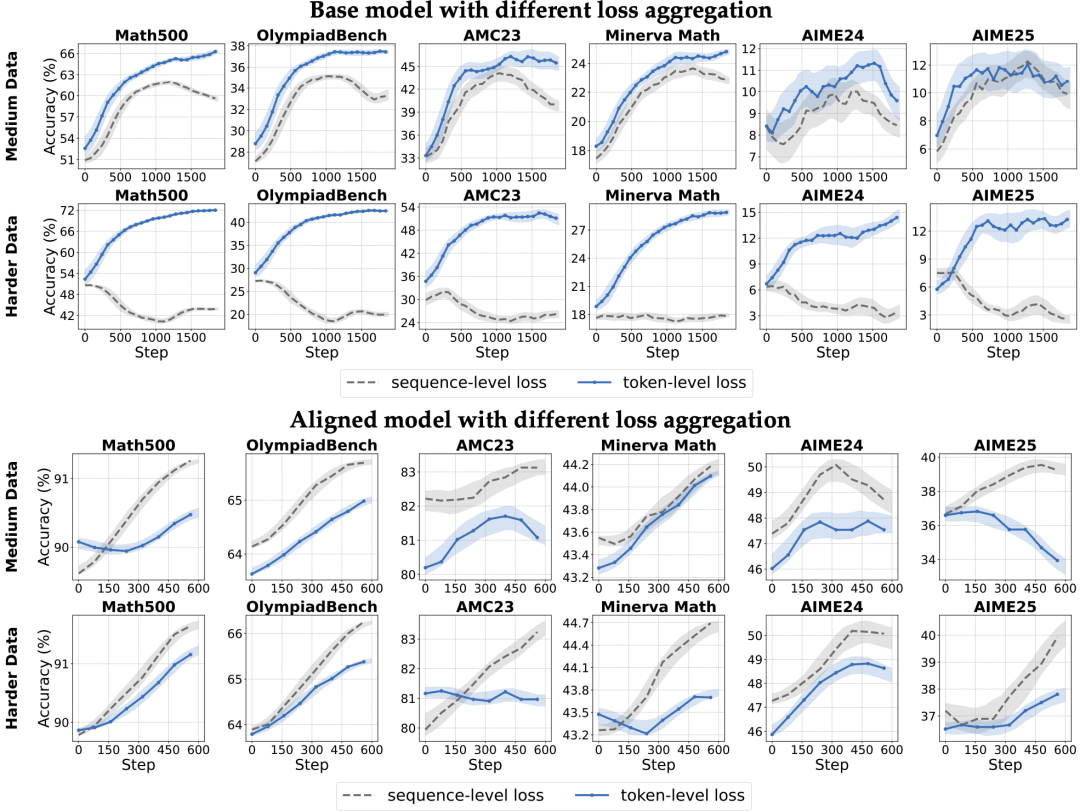
-
基础模型:词元级损失显著提升效果(尤其困难数据),因其需更细粒度信号。
-
对齐模型:序列级损失反而更优!
原因:对齐模型已具备稳定推理能力,词元级均等化会破坏高质量输出的结构性。
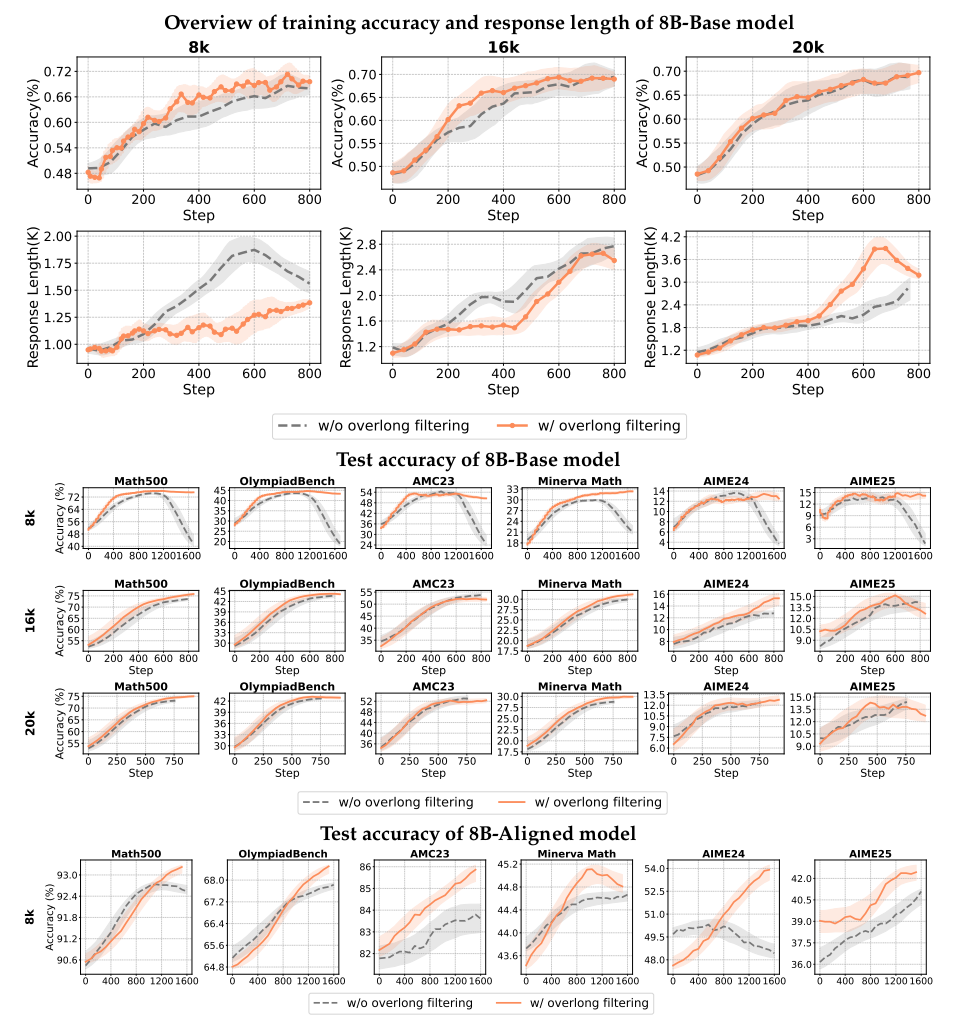
过长过滤 (Overlong Filtering) - 截断噪声的克星
-
问题核心:为节省算力,LLM训练常设最大生成长度。但早期模型易在复杂推理中未完成即被截断,被误标为负样本,污染训练信号。
-
解决方案:屏蔽超长响应的奖励(不参与梯度更新)。
-
适用场景:
-
-
中短任务(如GSM8K):显著提升准确性。
-
长尾任务(如证明题):收益有限(因需生成本身较长)。
-
-
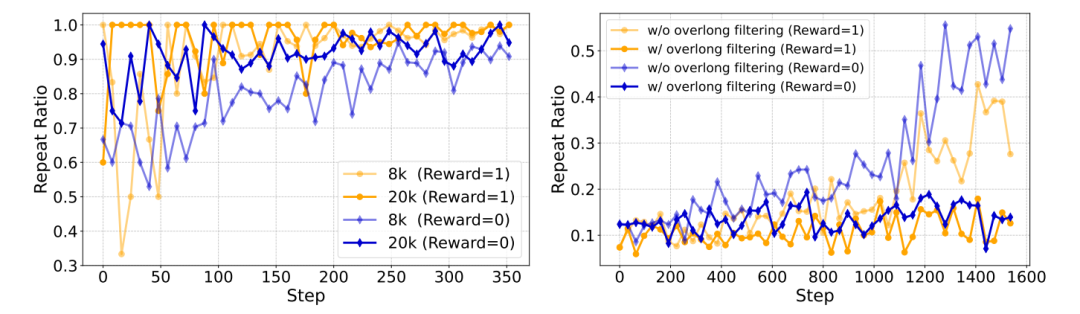
深层机制:过滤不仅屏蔽噪声,更改善终止行为建模:
-
-
无过滤时,模型“无法正常终止”的重复样本比例随训练上升。
-
引入过滤后,模型学会区分“完成生成” vs “截断生成”,减少无效学习。
-
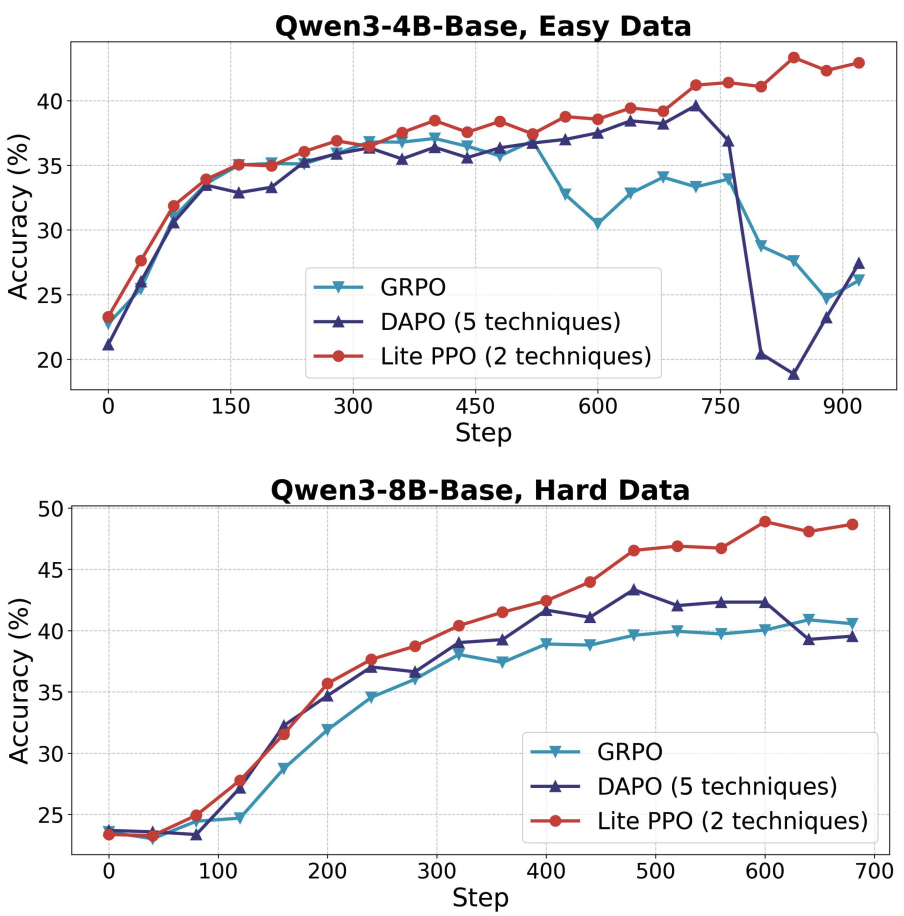
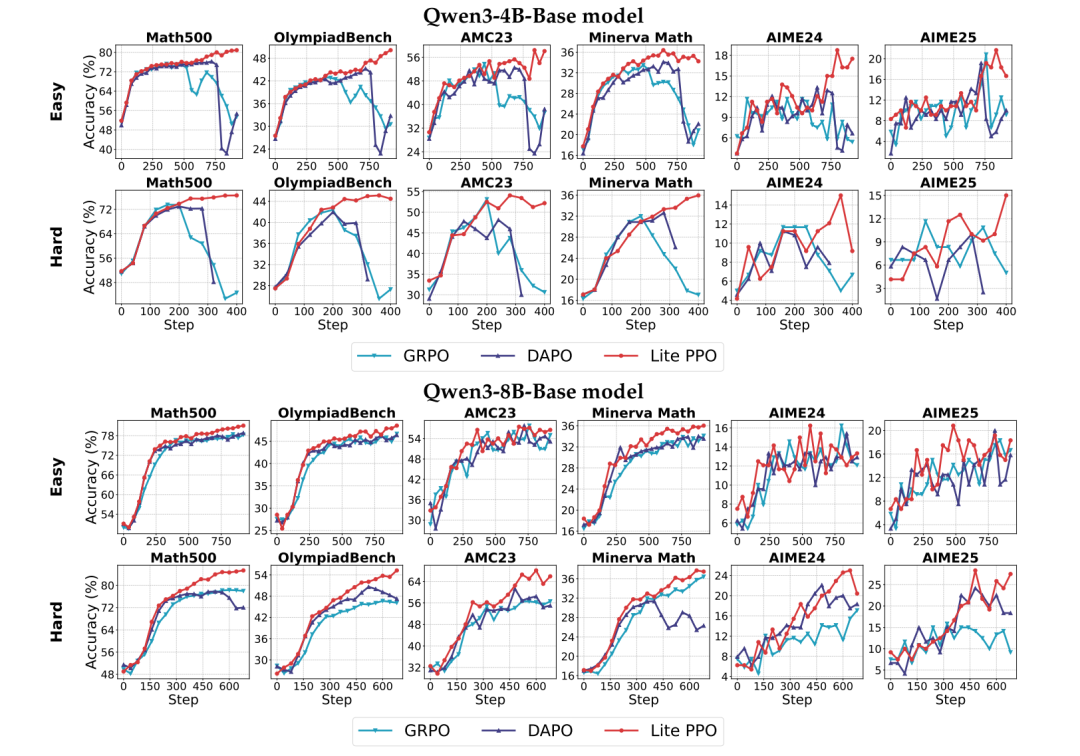
创新方案:Lite PPO - 少即是多的胜利
-
设计灵感:基于前述发现,仅融合两项最普适有效的技术:
-
鲁棒归一化:组内均值 + 批量标准差。
-
词元级损失聚合:尤其利好基础模型。
-
三大优势:
-
-
极简架构:无需价值函数(Critic-Free),仅用原始PPO损失。
-
超越复杂方案:在基础模型上,性能显著优于GRPO(含组归一化+KL损失)和DAPO(含动态采样+非对称剪裁等)。
-
鲁棒性:在易/难数据、4B/8B模型上均表现稳定。
-
-
成功秘诀:
-
-
归一化组合抵御了奖励分布不均的干扰。
-
放弃过长过滤释放了基础模型的长尾生成潜力。
-
词元级损失提供细粒度优化信号。
实验验证与讨论
-
全面性验证:实验覆盖2模型规模×2模型类型×3数据难度×6评估集,确保结论普适。
-
实用指南提炼:论文总结出清晰的技术选择流程图(隐含于结论),例如:
-
-
训练基础模型? → 优先采用 Lite PPO(归一化+词元损失)。
-
训练对齐模型? → 考虑 Clip-Higher + 序列级损失。
-
数据奖励稀疏二值? → 用组内归一化。
-
数据奖励范围大? → 批量归一化可能更佳。
-
-
行业呼吁:论文指出,模型闭源趋势(如GPT-4、Claude)阻碍跨家族技术分析,倡议工业界公开更多细节以促进学术与工业协同。
结论
本文为混乱的RL4LLM领域带来了三大核心贡献:
-
首份系统性评估报告:在统一框架下揭示了主流RL技巧(归一化、剪裁、过滤、损失聚合)的内在机制、敏感条件和适用场景,终结“技术选择焦虑”。
-
打破复杂度迷信:发现许多技巧的效果高度依赖实验设置(模型、数据、奖励),且极简组合(Lite PPO)可超越冗余方案,为工程实践降本增效。
-
开源与可复现标杆:基于ROLL框架的完整实验设计,为后续研究提供可靠基线。
一些启示:
-
从业者:应放弃“堆砌技巧”思维,根据模型状态(基础/对齐)、任务属性(长度/难度)、奖励设计针对性选配技术。
-
研究者:需关注技术普适性,倡导开源透明;Lite PPO证明了“少即是多”(Less is More)在RL优化中的可行性。
未来工作将继续完善RL4LLM的评估体系、算法库(ROLL)及轻量化方法,推动领域向鲁棒、可解释、工业化友好方向发展。


-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)