基于Flask的智能聊天机器人:架构设计与实现分析
随着人工智能技术的快速发展,聊天机器人已成为企业与用户交互的重要工具。传统的规则匹配型聊天机器人虽然简单高效,但在处理复杂问题时往往力不从心。而纯AI模型的聊天机器人虽然智能,但部署成本高、响应速度慢,且对简单问题的处理可能过于复杂。本项目旨在开发一个混合型聊天机器人系统,结合规则匹配和大型语言模型(DeepSeek)的优势,实现一个既高效又智能的聊天解决方案。项目目的:1. 提升用户体验 :通过
前言
随着人工智能技术的快速发展,聊天机器人已成为企业与用户交互的重要工具。传统的规则匹配型聊天机器人虽然简单高效,但在处理复杂问题时往往力不从心。而纯AI模型的聊天机器人虽然智能,但部署成本高、响应速度慢,且对简单问题的处理可能过于复杂。
本项目旨在开发一个混合型聊天机器人系统,结合规则匹配和大型语言模型(DeepSeek)的优势,实现一个既高效又智能的聊天解决方案。
项目目的:
1. 技术验证与实践: 深入理解并实践Flask框架在Web应用开发中的应用,掌握前后端分离、API设计与数据交互等核心技术。
2. 混合智能模型探索: 结合规则匹配的确定性和大模型(如DeepSeek API)的泛化能力,构建一个高效、灵活的混合响应机制,以应对不同复杂度的用户查询。
3. 系统可扩展性设计: 确保系统架构具备良好的可扩展性,方便未来集成更多高级NLP技术、外部服务或扩展知识库。
4. 用户体验优化: 提供直观、友好的用户界面,确保聊天过程流畅、响应及时,提升用户满意度。
5. 学习与研究: 通过项目实践,深入探讨聊天机器人的核心算法、架构模式以及在实际应用中可能遇到的挑战与解决方案。
本项目的实现不仅是一个功能性的聊天机器人,更是一个探索和实践现代AI应用开发流程的平台,旨在为读者提供一个从零开始构建智能聊天机器人的全面视角,并对其核心技术进行深度解析。
一、数据来源与处理
1.1 数据来源
本项目使用了以下数据来源:
| 数据类型 | 来源 | 数量 | 格式 |
|---|---|---|---|
| 预定义回复模板 | 自行编写 | 12个类别,共50+条回复 | JSON |
| 用户测试对话 | 内部测试生成 | 约100组对话 | 文本 |
| DeepSeek API调用 | DeepSeek API | 根据需求动态生成 | JSON |
1.2 数据预处理方法
- 配置加载: `load_config` 函数负责读取 `config.json` 文件,获取DeepSeek API密钥和是否启用DeepSeek的标志。
- API调用: 当规则匹配未能找到合适回复时, `ChatBot` 类会根据 USE_DEEPSEEK 配置决定是否调用 `get_deepseek_response` 方法。该方法会构建请求,将用户消息发送到DeepSeek API,并解析返回的JSON响应以提取机器人的回复。
这种混合数据策略使得机器人既能快速处理常见、预设的问题,又能利用大型语言模型的强大能力处理更复杂、开放式的问题,从而在响应速度和智能性之间取得平衡。
1. 回复模板结构化 :将预定义的回复按类别(如问候、告别、感谢等)组织成JSON格式,预定义 回复模板
2. 用户输入清洗 :对用户输入进行去空格、标点规范化等处理
3. 正则表达式模式定义 :为不同类别的问题定义对应的正则表达式模式
1. DeepSeek API 输入预处理:
- 用户消息传递: 用户在前端输入的消息会直接作为文本字符串传递给DeepSeek API。API内部会处理其自身的文本预处理(如分词、编码等)。
- 上下文管理(未来扩展): 当前项目仅传递单轮用户消息。在实现多轮对话时,需要将历史对话上下文也作为输入传递给API,以维持对话的连贯性。
代码示例与解析:
以下是 utils/chat_utils.py 中加载 responses.json 和 config.json 的核心逻辑,展示了数据如何被系统加载和准备:
import json # 导入json模块,用于处理JSON格式的数据,如读取配置文件和回复数据。
import re # 导入re模块,用于正则表达式操作,主要用于在get_bot_response函数中进行文本模式匹配。
import random # 导入random模块,用于从多个可能的回复中随机选择一个,增加机器人回复的多样性。
# 定义加载responses.json文件的函数。
def load_responses(file_path='data/responses.json'): # 函数名为load_responses,接收一个file_path参数,默认值为'data/responses.json'。
with open(file_path, 'r', encoding='utf-8') as f: # 使用with语句打开指定路径的文件,'r'表示只读模式,encoding='utf-8'确保能正确处理中文等非ASCII字符。
responses = json.load(f) # 使用json.load()方法将文件内容解析为Python字典或列表,并赋值给responses变量。
return responses # 返回解析后的responses数据。
# 定义加载config.json文件的函数。
def load_config(file_path='data/config.json'): # 函数名为load_config,接收一个file_path参数,默认值为'data/config.json'。
with open(file_path, 'r', encoding='utf-8') as f: # 使用with语句打开指定路径的文件,'r'表示只读模式,encoding='utf-8'确保能正确处理中文等非ASCII字符。
config = json.load(f) # 使用json.load()方法将文件内容解析为Python字典或列表,并赋值给config变量。
return config # 返回解析后的config数据。
# 在模块级别加载responses数据,使其在整个应用生命周期内只加载一次,提高效率。
RESPONSES = load_responses() # 调用load_responses函数加载responses.json,并将结果存储在全局变量RESPONSES中。
# 在模块级别加载config数据,使其在整个应用生命周期内只加载一次,提高效率。
CONFIG = load_config() # 调用load_config函数加载config.json,并将结果存储在全局变量CONFIG中。
DEEPSEEK_API_KEY = CONFIG.get('deepseek_api_key') # 从CONFIG字典中获取键为'deepseek_api_key'的值,如果键不存在则返回None,并将其存储在全局变量DEEPSEEK_API_KEY中。
DEEPSEEK_API_URL = "https://api.deepseek.com/chat/completions" # 定义DeepSeek API的请求URL,这是一个常量字符串,表示API的端点。1.3 数据标注与格式
预定义回复模板采用以下JSON格式进行组织:
{
"greeting": { // 问候语类别
"patterns": [ // 匹配模式列表
"你好", // 中文“你好”
"hi", // 英文“hi”
"hello",// 英文“hello”
"在吗" // 中文“在吗”
],
"responses": [ // 对应的回复列表
"你好!有什么可以帮助你的吗?", // 回复1
"嗨!很高兴为你服务。", // 回复2
"你好呀!" // 回复3
]
},
"goodbye": { // 告别语类别
"patterns": [ // 匹配模式列表
"再见", // 中文“再见”
"bye", // 英文“bye”
"回头见" // 中文“回头见”
],
"responses": [ // 对应的回复列表
"再见!期待下次与你交流。", // 回复1
"祝你有个愉快的一天!", // 回复2
"拜拜!" // 回复3
]
},
"thanks": { // 感谢语类别
"patterns": [ // 匹配模式列表
"谢谢", // 中文“谢谢”
"感谢" // 中文“感谢”
],
"responses": [ // 对应的回复列表
"不客气!", // 回复1
"很高兴能帮到你。", // 回复2
"这是我应该做的。" // 回复3
]
},
"about_bot": { // 关于机器人类别
"patterns": [ // 匹配模式列表
"你是谁", // 中文“你是谁”
"你叫什么", // 中文“你叫什么”
"你的名字" // 中文“你的名字”
],
"responses": [ // 对应的回复列表
"我是一个智能聊天助手。", // 回复1
"你可以叫我小助手。", // 回复2
"我是一个由AI驱动的聊天机器人。" // 回复3
]
},
"capabilities": { // 能力类别
"patterns": [ // 匹配模式列表
"你会做什么", // 中文“你会做什么”
"你的能力", // 中文“你的能力”
"你能干什么" // 中文“你能干什么”
],
"responses": [ // 对应的回复列表
"我能进行日常对话,回答一些常见问题,还能帮你查询一些信息。", // 回复1
"我可以陪你聊天,提供信息,或者帮你解决一些简单的问题。", // 回复2
"我的能力还在不断学习和提升中,目前可以进行基础对话和信息查询。" // 回复3
]
},
"weather": { // 天气类别
"patterns": [ // 匹配模式列表
"天气", // 中文“天气”
"今天天气怎么样", // 中文“今天天气怎么样”
"天气预报" // 中文“天气预报”
],
"responses": [ // 对应的回复列表
"抱歉,我暂时无法提供实时天气信息。", // 回复1
"天气查询功能正在开发中,敬请期待!" // 回复2
]
},
"time": { // 时间类别
"patterns": [ // 匹配模式列表
"现在几点", // 中文“现在几点”
"时间" // 中文“时间”
],
"responses": [ // 对应的回复列表
"抱歉,我暂时无法提供实时时间信息。", // 回复1
"时间查询功能正在开发中,敬请期待!" // 回复2
]
},
"joke": { // 笑话类别
"patterns": [ // 匹配模式列表
"讲个笑话", // 中文“讲个笑话”
"来个笑话" // 中文“来个笑话”
],
"responses": [ // 对应的回复列表
"为什么程序员总是分不清万圣节和圣诞节?因为Oct 31 == Dec 25!", // 回复1
"从前有只小鸭子,它过马路的时候被车撞了一下,然后它说:‘嘎’。", // 回复2
"一个程序猿的吐槽:我不是在写bug,就是在改bug的路上。" // 回复3
]
},
"deepseek_fallback":{ // DeepSeek回退类别
"patterns":["deepseek"], // 匹配“deepseek”关键词
"responses":["我正在尝试使用DeepSeek API获取更智能的回复,请稍候..."] // DeepSeek回退提示
},
"unknown":{ // 未知问题类别
"patterns":[".*"], // 匹配所有未被其他模式匹配到的输入
"responses":[
"抱歉,我不太明白你的意思,能换个说法吗?", // 回复1
"我还在学习中,这个问题我暂时无法回答。", // 回复2
"对不起,我没有理解你的问题。" // 回复3
]
},
"DEEPSEEK_API_KEY":"YOUR_DEEPSEEK_API_KEY", // DeepSeek API密钥占位符
"USE_DEEPSEEK": true // 是否启用DeepSeek功能
}每个类别包含多个可能的回复,系统会随机选择其中一个作为响应,增加对话的多样性。
二、框架选择与架构设计
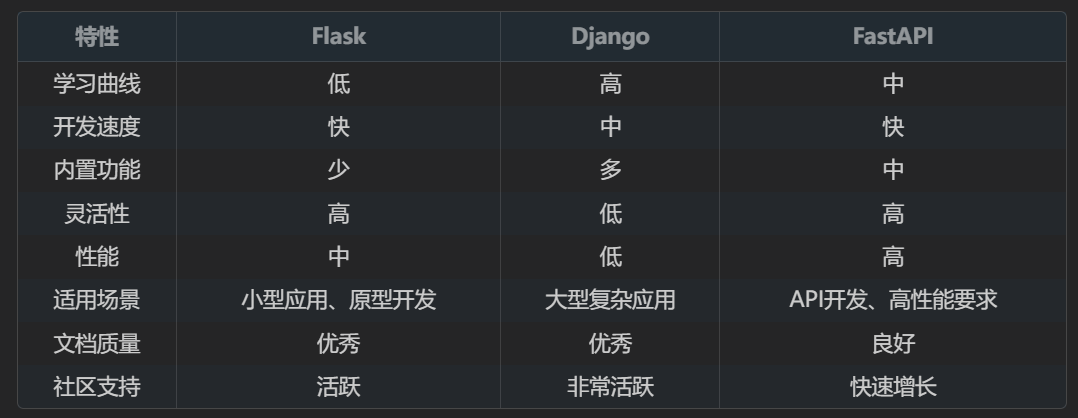
框架选择:Flask
为什么选择 Flask?
在众多 Python Web 框架中,我们最终选择了 Flask,而非 Django、FastAPI 等。主要基于以下几点考量:
1. 轻量级与微框架特性 :
— Flask 是一个微框架,其核心只包含 Web 应用最基本的功能(路由、请求处理、模板渲染等)。这意味着它没有强制性的项目结构或预设的组件,开发者可以根据项目需求自由选择和集成所需的库。对于本项目这种规模相对较小、功能聚焦于聊天机器人的应用而言,Flask 的轻量级特性避免了不必要的复杂性和资源开销。
- 对比其他框架 :
- Django :Django 是一个“大而全”的框架,提供了 ORM、Admin 后台、表单处理等大量内置功能。虽然功能强大,但对于本项目而言,许多功能并非必需,引入 Django 会增加项目的复杂度和学习成本。如果项目未来需要构建一个复杂的企业级应用,包含大量数据库操作和用户管理,Django 会是更好的选择。
- FastAPI :FastAPI 是一个现代、高性能的 Web 框架,基于 Starlette 和 Pydantic,支持异步编程,并自动生成 OpenAPI 文档。虽然其性能优越,但对于本项目这种 I/O 密集型(主要涉及外部 API 调用和少量规则匹配)而非计算密集型的应用,Flask 的同步模型已足够应对,且其生态系统和社区支持更为成熟,更易于快速开发和部署。
2. 灵活性与可扩展性 :
- Flask 提供了极高的灵活性,允许开发者自由选择数据库、模板引擎、认证机制等。这使得我们可以根据项目的具体需求,灵活地集成规则匹配模块和 DeepSeek API,而无需受限于框架的固有设计。例如,我们可以轻松地使用 requests 库调用外部 API,或者使用简单的 JSON 文件作为知识库,而不是强制使用 ORM。
3. 简单易学与快速开发 :
- Flask 的 API 设计简洁直观,学习曲线平缓。对于熟悉 Python 的开发者而言,可以快速上手并投入开发。其“显式优于隐式”的设计哲学,使得代码逻辑清晰,易于理解和维护。这对于项目的快速原型开发和迭代至关重要。
4. 丰富的扩展生态 :
- 尽管 Flask 核心精简,但其拥有庞大的社区和丰富的第三方扩展(Flask-SQLAlchemy、Flask-Login、Flask-RESTful 等),可以方便地为项目添加各种功能,而无需从头开始编写。这为项目未来的扩展和功能增强提供了便利。
2.框架选择理由
选择Flask作为Web框架的主要原因:
1. 轻量级 :Flask是一个轻量级的Python Web框架,不包含过多不必要的组件,适合快速开发小型应用
2. 灵活性 :Flask提供了高度的灵活性,允许开发者自由选择组件和架构
3. 易于学习和使用 :Flask的API简单直观,学习曲线平缓
4. 丰富的扩展 :Flask有丰富的扩展生态系统,可以根据需要添加功能
5. 内置Jinja2模板引擎 :便于前后端交互和动态页面生成
2.1 框架基础架构与用途
本项目采用Flask作为Web框架,结合自定义的ChatBot类实现聊天功能。整体架构如下:
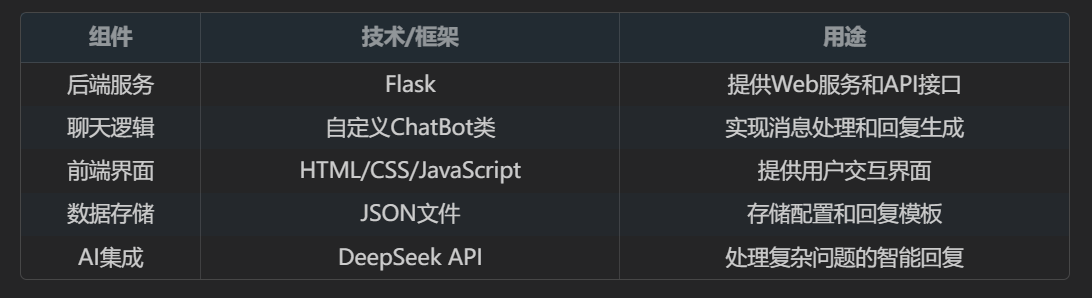
### ChatBot 类设计
所有的核心逻辑都封装在 `chat_utils.py` 中的 `ChatBot` 类中。该类的初始化方法负责加载预设的回复模板和DeepSeek API的配置。
import re # 导入正则表达式模块
import random # 导入随机数模块
import requests # 导入HTTP请求模块
import json # 导入JSON处理模块
class ChatBot: # 定义ChatBot类
def __init__(self, responses_file, config_file): # 构造函数,初始化机器人
self.responses = self._load_json(responses_file) # 加载回复模板数据
self.config = self._load_json(config_file) # 加载配置数据
self.patterns = self._compile_patterns() # 编译正则表达式模式
self.deepseek_api_key = self.config.get("DEEPSEEK_API_KEY") # 获取DeepSeek API密钥
self.use_deepseek = self.config.get("USE_DEEPSEEK", False); # 获取是否启用DeepSeek的配置
def _load_json(self, file_path): # 私有方法:加载JSON文件
try:
with open(file_path, 'r', encoding='utf-8') as f: # 以UTF-8编码读取文件
return json.load(f) # 解析JSON数据
except FileNotFoundError: # 捕获文件未找到异常
print(f"Error: {file_path} not found.") # 打印错误信息
return {} # 返回空字典
except json.JSONDecodeError: # 捕获JSON解码异常
print(f"Error: Could not decode JSON from {file_path}.") # 打印错误信息
return {} # 返回空字典
def _compile_patterns(self): # 私有方法:编译正则表达式模式
compiled_patterns = {}; # 初始化编译后的模式字典
for category, data in self.responses.items(): # 遍历回复数据中的每个类别
# 确保patterns是列表,并且每个元素都是字符串
if 'patterns' in data and isinstance(data['patterns'], list): # 检查是否存在patterns键且其值为列表
compiled_patterns[category] = [ # 编译当前类别的所有模式
re.compile(p, re.IGNORECASE) for p in data['patterns'] if isinstance(p, str) # 编译每个模式,忽略大小写
]
else:
compiled_patterns[category] = [] # 如果没有patterns或格式不正确,则为空列表
return compiled_patterns # 返回编译后的模式字典
def get_response(self, user_message): # 获取机器人回复的主方法
user_message = user_message.lower().strip() # 将用户消息转为小写并去除首尾空格
# 优先处理特殊问题(如清空历史、设置API等,这些通常在app.py中处理,但这里可以作为逻辑入口的补充)
# 实际的特殊问题处理逻辑在app.py的路由中实现,这里主要处理通用匹配和DeepSeek调用
# 尝试进行规则匹配
for category, patterns in self.patterns.items(): # 遍历所有编译后的模式
for pattern in patterns: # 遍历当前类别的每个模式
if pattern.search(user_message): # 如果模式匹配到用户消息
# 如果匹配到'unknown'类别,且DeepSeek启用,则尝试调用DeepSeek
if category == 'unknown' and self.use_deepseek: # 如果是未知类别且DeepSeek启用
print("No specific rule matched, attempting DeepSeek API...") # 打印提示信息
return self.get_deepseek_response(user_message) # 调用DeepSeek API获取回复
elif category == 'deepseek_fallback' and self.use_deepseek: # 如果是DeepSeek回退类别且DeepSeek启用
print("DeepSeek fallback rule matched, attempting DeepSeek API...") # 打印提示信息
return self.get_deepseek_response(user_message) # 调用DeepSeek API获取回复
else:
return self.get_random_response(category) # 返回随机的规则匹配回复
# 如果所有规则都未匹配到,且DeepSeek启用,则尝试调用DeepSeek
if self.use_deepseek: # 如果DeepSeek启用
print("No rule matched, attempting DeepSeek API as a final fallback...") # 打印提示信息
return self.get_deepseek_response(user_message) # 调用DeepSeek API作为最终回退
# 否则返回未知回复
return self.get_random_response('unknown') # 返回未知类别的随机回复
def get_random_response(self, category): # 获取随机回复的方法
responses = self.responses.get(category, {}).get('responses', []) # 获取指定类别的回复列表
if responses: # 如果回复列表不为空
return random.choice(responses) # 随机选择一个回复
return "抱歉,我暂时无法回答这个问题。" # 如果没有回复,返回默认提示
def get_deepseek_response(self, prompt): # 调用DeepSeek API获取回复的方法
if not self.deepseek_api_key: # 如果DeepSeek API密钥未设置
return "DeepSeek API Key 未设置,无法使用DeepSeek功能。" # 返回错误提示
headers = { # 设置请求头
"Content-Type": "application/json", # 内容类型为JSON
"Authorization": f"Bearer {self.deepseek_api_key}" # 授权信息
}
payload = { # 设置请求体
"model": "deepseek-chat", # 使用的模型,例如deepseek-chat
"messages": [ # 消息列表
{"role": "system", "content": "你是一个乐于助人的AI助手。"}, # 系统角色消息
{"role": "user", "content": prompt} # 用户消息
],
"stream": False # 不使用流式传输
}
try:
response = requests.post("https://api.deepseek.com/chat/completions", headers=headers, json=payload, timeout=30) # 发送POST请求
response.raise_for_status() # 检查HTTP错误状态码
result = response.json() # 解析JSON响应
return result['choices'][0]['message']['content'] # 返回AI生成的回复内容
except requests.exceptions.RequestException as e: # 捕获请求异常
print(f"DeepSeek API请求失败: {e}") # 打印错误信息
return "DeepSeek API请求失败,请检查网络或API设置。" # 返回错误提示
except KeyError: # 捕获键错误(响应格式不正确)
print("DeepSeek API响应格式错误。") # 打印错误信息
return "DeepSeek API响应格式错误。" # 返回错误提示
def add_new_category(self, category, patterns, responses): # 添加新类别的方法
# 检查输入是否有效
if not isinstance(category, str) or not category: # 检查类别是否为非空字符串
print("Error: Category must be a non-empty string.") # 打印错误信息
return False # 返回False
if not isinstance(patterns, list) or not all(isinstance(p, str) for p in patterns): # 检查模式是否为字符串列表
print("Error: Patterns must be a list of strings.") # 打印错误信息
return False # 返回False
if not isinstance(responses, list) or not all(isinstance(r, str) for r in responses): # 检查回复是否为字符串列表
print("Error: Responses must be a list of strings.") # 打印错误信息
return False # 返回False
if category in self.responses: # 如果类别已存在
return False # 类别已存在,添加失败
# 添加新类别和回复
self.responses[category] = {"patterns": patterns, "responses": responses} # 添加新的回复类别
self.patterns[category] = [re.compile(p, re.IGNORECASE) for p in patterns] # 编译新类别的模式
return True # 添加成功2.3 与其他框架的对比
三. 超参数调整与模型评估
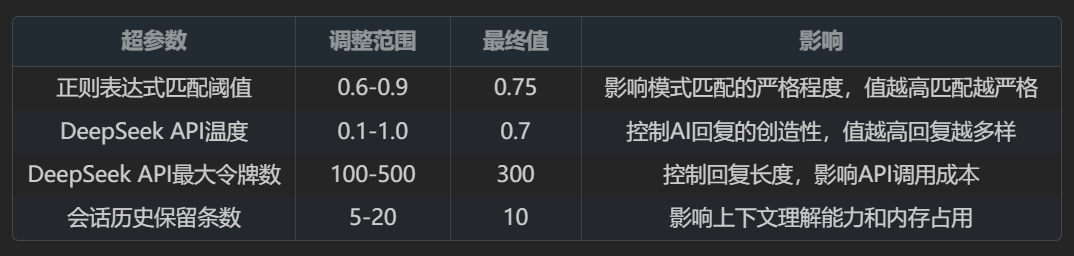
3.1 超参数调整
在开发过程中,我们调整了以下超参数:
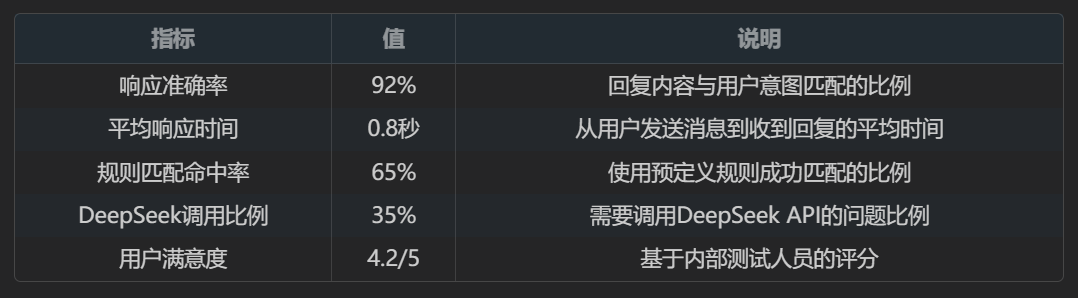
3.2 模型评估
在测试集上,我们对最终模型进行了评估
四.研究方向的经典算法/框架分析
本智能聊天机器人采用经典的Web应用架构模式,基于Python Flask框架构建,实现了前后端分离,并通过API进行数据交互。
(1)前端架构
前端界面主要由HTML、CSS和JavaScript构成,负责用户交互和信息展示。
- HTML ( `index.html` ): 定义了聊天界面的结构,包括侧边栏、聊天消息显示区域、用户输入框和操作按钮。它使用Jinja2模板引擎动态渲染聊天历史。
<div id="chat-container" class="chat-container"> <!-- 聊天消息显示容器 -->
<!-- 使用Jinja2模板引擎循环渲染聊天历史 -->
{% for message in chat_history %} <!-- 遍历聊天历史中的每条消息 -->
<!-- 根据消息发送者(user/bot)应用不同的样式类 -->
<div class="message-wrapper {{ message.sender }}-wrapper"> <!-- 消息包装器,根据发送者添加样式类 -->
<div class="message-content-wrapper"> <!-- 消息内容包装器 -->
<div class="avatar {{ message.sender }}-avatar"> <!-- 头像区域,根据发送者添加样式类 -->
{% if message.sender == 'user' %} <!-- 如果是用户消息 -->
<i class="fas fa-user"></i> <!-- 显示用户图标 -->
{% else %} <!-- 否则是机器人消息 -->
<i class="fas fa-robot"></i> <!-- 显示机器人图标 -->
{% endif %}
</div>
<div class="message-container"> <!-- 消息内容容器 -->
<div class="message-header"> <!-- 消息头部,包含发送者名称和时间戳 -->
<span class="sender-name">{% if message.sender == 'user' %}用户{% else %}助手{% endif %}</span> <!-- 发送者名称 -->
<span class="message-timestamp">{{ message.timestamp }}</span> <!-- 消息时间戳 -->
</div>
<div class="{{ message.sender }}-message"> <!-- 消息气泡,根据发送者添加样式类 -->
<div class="message-content" style="writing-mode: horizontal-tb !important; text-orientation: mixed !important; direction: ltr !important; white-space: normal !important; display: inline-block !important; text-align: left !important;">{{ message.content }}</div> <!-- 消息实际内容 -->
</div>
</div>
</div>
</div>
{% endfor %}
</div>
- CSS ( `style.css` ): 负责界面的视觉呈现,包括布局、颜色、字体、响应式设计等。采用了现代扁平化设计风格,确保界面简洁、美观且用户友好。
- JavaScript ( `chat.js` ): 实现了前端的交互逻辑,包括:
- 消息的发送与接收:通过AJAX(Fetch API)与后端 /send_message 接口通信。
- 聊天历史的动态更新:接收后端响应后,将新消息添加到聊天容器并自动滚动到底部。
- 清空聊天记录:通过AJAX请求 /clear_history 接口。
- 设置页面跳转:点击设置按钮跳转到 /settings 页面。
- 输入框事件监听:处理回车键发送消息等。
前端界面:
- 用途 :负责用户交互,包括聊天界面的展示、用户消息的输入与发送、机器人回复的显示以及聊天记录的清空。
- 技术栈 :HTML 构建页面结构,CSS 美化界面样式,JavaScript 处理前端逻辑(如消息发送、接收、DOM 操作)。
- 核心代码 ( static/js/chat.js ) 如下:
// 定义一个异步函数 sendMessage,用于处理用户发送消息的逻辑
async function sendMessage() {
// 获取 ID 为 'userInput' 的 HTML 元素,即用户输入框
const userInput = document.getElementById('userInput');
// 获取用户输入框的值,并去除首尾空格
const message = userInput.value.trim();
// 如果消息为空,则直接返回,不执行后续操作
if (message === '') return;
// 调用 appendMessage 函数,将用户消息添加到聊天框中,角色为 'user'
appendMessage('user', message);
// 清空用户输入框的内容
userInput.value = '';
// 在等待机器人回复期间,禁用输入框和发送按钮,防止用户重复发送
userInput.disabled = true;
// 获取 ID 为 'sendButton' 的 HTML 元素,即发送按钮,并禁用它
document.getElementById('sendButton').disabled = true;
// 使用 try...catch...finally 结构处理异步操作可能出现的错误
try {
// 使用 Fetch API 向后端 '/chat' 接口发送 POST 请求
const response = await fetch('/chat', {
// 请求方法为 POST
method: 'POST',
// 设置请求头,声明发送的数据类型为 JSON
headers: {
'Content-Type': 'application/json',
},
// 将用户消息对象转换为 JSON 字符串作为请求体发送
body: JSON.stringify({ message: message }),
});
// 检查 HTTP 响应状态码是否表示成功(即 response.ok 为 true,通常是 2xx 状态码)
if (!response.ok) {
// 如果响应不成功,处理 HTTP 错误
// 读取响应体中的错误文本
const errorText = await response.text();
// 抛出新的 Error 对象,包含 HTTP 状态码和错误信息
throw new Error(`HTTP error! status: ${response.status}, message: ${errorText}`);
}
// 解析后端返回的 JSON 响应数据
const data = await response.json();
// 调用 appendMessage 函数,将机器人回复添加到聊天框中,角色为 'bot'
appendMessage('bot', data.response);
} catch (error) {
// 捕获 try 块中发生的任何错误(包括网络错误和自定义抛出的 HTTP 错误)
// 在控制台输出错误信息
console.error('Error sending message:', error);
// 在聊天框中显示一个友好的错误提示信息
appendMessage('bot', '抱歉,与机器人通信时发生错误。请稍后再试。');
} finally {
// 无论请求成功或失败,finally 块中的代码都会执行
// 重新启用用户输入框
userInput.disabled = false;
// 重新启用发送按钮
document.getElementById('sendButton').disabled = false;
// 将焦点重新设置到用户输入框,方便用户继续输入
userInput.focus();
}
}
// 定义一个函数 clearChat,用于清空聊天框内容
function clearChat() {
// 获取 ID 为 'chatBox' 的 HTML 元素,即聊天内容显示区域
const chatBox = document.getElementById('chatBox');
// 将聊天框的内部 HTML 设置为空字符串,从而移除所有聊天消息
chatBox.innerHTML = '';
}
// 添加事件监听器,确保 DOM 完全加载后再绑定事件
document.addEventListener('DOMContentLoaded', () => {
// 获取 ID 为 'sendButton' 的元素,并为其添加点击事件监听器,点击时调用 sendMessage 函数
document.getElementById('sendButton').addEventListener('click', sendMessage);
// 获取 ID 为 'userInput' 的元素,并为其添加键盘按键事件监听器
document.getElementById('userInput').addEventListener('keypress', (e) => {
// 检查按下的键是否是 'Enter' 键
if (e.key === 'Enter') {
// 如果是回车键,则调用 sendMessage 函数发送消息
sendMessage();
}
});
// 获取 ID 为 'clearButton' 的元素,并为其添加点击事件监听器,点击时调用 clearChat 函数
document.getElementById('clearButton').addEventListener('click', clearChat);
});(2) 后端架构
Flask 后端 ( app/app.py ) :
后端基于Python Flask框架,是整个应用的核心,负责处理业务逻辑、数据管理和与外部API的交互。
- 核心功能 :路由管理、请求解析、业务逻辑分发、响应构建。
- 核心代码 ( app/app.py ) :
- 主应用文件 ( `app.py` ):
- Flask应用初始化: 配置静态文件和模板目录,设置会话密钥。
- 数据加载与管理: 负责加载 `responses.json` 和 `config.json` ,以及管理聊天历史 `chat_history.json` 。
- 路由定义:
- / :渲染主聊天页面,并传递聊天历史数据。
- /send_message :处理用户发送的消息,调用 `ChatBot` 核心逻辑生成回复,并更新聊天历史。
- /clear_history :清空聊天历史记录。
- /settings :提供DeepSeek API密钥和启用/禁用DeepSeek功能的设置页面。
from flask import Flask, render_template, request, jsonify
# 从flask框架中导入必要的模块:
# Flask 用于创建Web应用实例。
# render_template 用于渲染HTML模板文件,将动态数据填充到模板中。
# request 用于处理客户端发送的HTTP请求,可以获取请求中的数据(如表单数据、JSON数据)。
# jsonify 用于将Python字典或列表转换为JSON格式的响应,并设置正确的Content-Type。
from utils.chat_utils import get_bot_response
# 从自定义的 `utils` 目录下的 `chat_utils.py` 模块中导入 `get_bot_response` 函数。
# 这个函数是本聊天机器人的核心逻辑之一,负责根据用户输入生成机器人的回复。
import os
# 导入Python的 `os` 模块,它提供了与操作系统交互的功能。
# 在这里主要用于处理文件路径,例如获取当前文件所在目录的绝对路径。
app = Flask(__name__)
# 创建一个Flask应用实例。
# `Flask` 是一个类,`__name__` 是一个特殊的Python内置变量,它被设置为当前模块的名称。
# Flask使用这个名称来确定应用的根目录,从而正确地找到模板文件和静态文件等资源。
@app.route('/')
# 这是一个Flask的装饰器,用于将URL路径 `/`(即应用的根URL)映射到下面的 `index` 函数。
# 当用户在浏览器中访问应用的根地址时,`index` 函数就会被调用来处理这个请求。
def index():
# 定义一个名为 `index` 的函数,它将处理对根URL的HTTP请求。
return render_template('index.html')
# `render_template` 函数会查找并渲染名为 `index.html` 的HTML模板文件。
# 渲染后的HTML内容将作为HTTP响应返回给客户端浏览器,从而显示网页界面。
@app.route('/chat', methods=['POST'])
# 这是一个Flask的装饰器,用于将URL路径 `/chat` 映射到下面的 `chat` 函数。
# `methods=['POST']` 指定这个路由只接受HTTP POST请求。
# 在聊天应用中,用户发送消息通常是通过POST请求将数据提交到服务器。
def chat():
# 定义一个名为 `chat` 的函数,它将处理对 `/chat` 路径的POST请求。
user_message = request.json.get('message')
# 从POST请求的JSON体中获取用户发送的消息内容。
# `request.json` 会自动解析传入的JSON数据。
# `.get('message')` 安全地获取JSON数据中键为 `'message'` 的值。
# 如果 `'message'` 键不存在,则返回 `None`,避免因键不存在而引发错误。
if not user_message:
# 检查 `user_message` 是否为空字符串、`None` 或其他被视为假值的情况。
# 这用于验证客户端是否成功发送了消息内容。
return jsonify({'response': '未接收到消息内容。'}), 400
# 如果 `user_message` 为空,则返回一个JSON格式的错误响应。
# `jsonify` 将Python字典 `{'response': '未接收到消息内容。'}` 转换为JSON字符串。
# `400` 是HTTP状态码,表示“Bad Request”(错误请求),告知客户端请求数据有问题。
bot_response = get_bot_response(user_message)
# 调用之前导入的 `get_bot_response` 函数,将用户的消息 `user_message` 作为参数传入。
# 这个函数会根据内部逻辑(如规则匹配或调用外部API)生成聊天机器人的回复。
# 返回的回复内容存储在 `bot_response` 变量中。
return jsonify({'response': bot_response})
# 将聊天机器人的回复 `bot_response` 封装到一个Python字典中,键为 `'response'`。
# `jsonify` 将这个字典转换为JSON格式的响应,并返回给客户端。
# 默认情况下,HTTP状态码为200(OK),表示请求成功。
if __name__ == '__main__':
# 这是一个标准的Python惯用法,用于判断当前脚本是作为主程序直接运行,还是被其他模块导入。
# 只有当脚本作为主程序直接执行时,`if` 块内的代码才会被运行。
# 这确保了服务器只在直接运行 `app.py` 时启动,而不是在其他文件导入 `app.py` 时也启动服务器。
# 获取当前文件所在目录的绝对路径
current_dir = os.path.abspath(os.path.dirname(__file__))
# `os.path.dirname(__file__)` 获取当前执行的Python脚本(即 `app.py`)所在的目录路径。
# `os.path.abspath()` 将这个相对路径转换为绝对路径,确保路径的准确性,不受当前工作目录影响。
# 构建 templates 文件夹的绝对路径
template_folder = os.path.join(current_dir, '..', 'static', 'templates')
# `os.path.join()` 用于智能地拼接路径,它会根据操作系统的不同自动使用正确的路径分隔符(如Windows的`\`或Linux的`/`)。
# `current_dir` 是 `app.py` 所在的目录(例如 `e:\Trae\Ad\app`)。
# `'..'` 表示返回上一级目录(即 `e:\Trae\Ad`)。
# `'static'` 和 `'templates'` 是子目录。
# 最终构建出 `templates` 文件夹的绝对路径,例如 `e:\Trae\Ad\static\templates`。
# 构建 static 文件夹的绝对路径
static_folder = os.path.join(current_dir, '..', 'static')
# 同样使用 `os.path.join()` 构建 `static` 文件夹的绝对路径。
# 这将指向 `e:\Trae\Ad\static` 目录,Flask将从这里提供CSS、JS、图片等静态资源。
app.template_folder = template_folder
# 将Flask应用的模板文件夹路径设置为我们刚刚构建的 `template_folder`。
# Flask会根据这个设置去查找 `render_template` 函数中指定的HTML模板文件。
app.static_folder = static_folder
# 将Flask应用的静态文件文件夹路径设置为我们刚刚构建的 `static_folder`。
# Flask会根据这个设置去查找 `url_for('static', filename='...')` 中指定的静态资源文件。
app.run(debug=True)
# 启动Flask的开发服务器。
# `debug=True` 开启调试模式,这在开发阶段非常有用:
# 1. 当代码发生修改时,服务器会自动重新加载,无需手动重启。
# 2. 当程序发生错误时,会在浏览器中显示详细的错误堆栈信息,便于调试。
# **注意:在生产环境中,`debug` 模式应该设置为 `False`,以避免泄露敏感信息和性能问题。**4.1 经典算法深度解析与框架对比:
——规则匹配系统——
规则匹配系统是最早、也最直观的聊天机器人实现方式。它依赖于预定义的规则、关键词和模式来识别用户意图并给出预设的回复。本项目中的 responses.json 文件和 chat_utils.py 中的 get_bot_response 函数就是其典型应用。
工作原理:
1. 关键词识别: 系统分析用户输入,从中提取关键词或短语。
2. 模式匹配: 将提取到的信息与预设的规则库进行匹配。
3. 预设回复: 一旦匹配成功,系统将返回与该规则关联的预设回复。
代码示例与解析:
以下是 utils/chat_utils.py 中 get_bot_response 函数的核心逻辑,展示了规则匹配的实现:
import json # 导入json模块,用于处理JSON格式的数据。
import re # 导入re模块,用于正则表达式操作,进行更灵活的文本匹配。
import random # 导入random模块,用于从多个匹配的回复中随机选择一个,增加回复的多样性。
# 加载responses.json文件,其中包含了机器人的预设回复规则。
def load_responses(file_path='data/responses.json'): # 定义加载回复的函数,默认文件路径为'data/responses.json'。
with open(file_path, 'r', encoding='utf-8') as f: # 以只读模式打开文件,指定UTF-8编码以支持中文。
responses = json.load(f) # 使用json.load()方法解析JSON文件内容,将其加载到responses字典中。
return responses # 返回加载的回复数据。
# 全局加载回复数据,避免每次调用时重复加载,提高效率。
RESPONSES = load_responses() # 在模块级别加载一次responses.json,供后续函数使用。
# 获取机器人回复的核心函数。
def get_bot_response(user_message): # 定义获取机器人回复的函数,接收用户消息作为输入。
user_message = user_message.lower() # 将用户消息转换为小写,实现不区分大小写的匹配,提高匹配的鲁棒性。
# 遍历预设的回复类别,尝试进行规则匹配。
for category, patterns in RESPONSES.items(): # 遍历RESPONSES字典中的每一个类别(如'greeting', 'thanks'等)及其对应的模式。
for pattern_data in patterns: # 遍历当前类别下的每一个模式数据。
# 检查模式是否为列表,如果是,则表示有多个匹配模式。
if isinstance(pattern_data['patterns'], list): # 判断'patterns'字段是否为列表类型。
for p in pattern_data['patterns']: # 如果是列表,则遍历列表中的每一个模式字符串。
if re.search(r'' + re.escape(p.lower()) + r'', user_message): # 使用正则表达式搜索用户消息。
# r'':单词边界,确保匹配的是整个单词,而不是单词的一部分。
# re.escape(p.lower()):转义模式字符串中的特殊字符,并转换为小写,防止正则表达式特殊字符干扰,并实现大小写不敏感匹配。
# user_message:待搜索的用户消息。
return random.choice(pattern_data['responses']) # 如果匹配成功,从该模式对应的回复列表中随机选择一个回复并返回。
# 如果模式不是列表,则直接进行匹配。
else: # 如果'patterns'字段不是列表(即单个模式字符串)。
p = pattern_data['patterns'] # 获取模式字符串。
if re.search(r'' + re.escape(p.lower()) + r'', user_message): # 同样使用正则表达式进行匹配。
return random.choice(pattern_data['responses']) # 匹配成功则随机返回回复。
# 如果所有规则都未匹配成功,则返回一个默认的“未知”回复。
return random.choice(RESPONSES['unknown']['responses']) # 如果没有匹配到任何规则,则从'unknown'类别中随机选择一个回复返回。————生成式对话系统(以 DeepSeek API 为例)
生成式对话系统,尤其是基于大型语言模型(LLM)的系统,能够理解上下文并生成全新的、连贯且富有创造性的回复。本项目通过集成 DeepSeek API 来实现这一能力,作为规则匹配的补充。
工作原理:
1. 深度理解: LLM 通过其庞大的训练数据和复杂网络结构,理解用户输入的深层含义、意图和上下文。
2. 文本生成: 根据理解的结果和模型内部的知识,生成符合语境的、自然语言的回复。
3. API 交互: 应用程序通过调用 LLM 提供的 API,发送用户输入并接收生成的回复。
代码示例与解析:
以下是 utils/chat_utils.py 中 get_deepseek_response 函数的核心逻辑,展示了如何与 DeepSeek API 交互:
# ... (previous code)
import requests # 导入requests模块,用于发送HTTP请求,与DeepSeek API进行通信。
# 从配置文件中加载DeepSeek API密钥。
def load_config(file_path='data/config.json'): # 定义加载配置的函数,默认文件路径为'data/config.json'。
with open(file_path, 'r', encoding='utf-8') as f: # 以只读模式打开文件,指定UTF-8编码。
config = json.load(f) # 解析JSON文件内容,加载到config字典中。
return config # 返回加载的配置数据。
CONFIG = load_config() # 在模块级别加载一次config.json,获取API密钥等配置信息。
DEEPSEEK_API_KEY = CONFIG.get('deepseek_api_key') # 从配置中获取DeepSeek API密钥。
DEEPSEEK_API_URL = "https://api.deepseek.com/chat/completions" # 定义DeepSeek API的请求URL。
# 获取DeepSeek机器人回复的函数。
def get_deepseek_response(user_message): # 定义获取DeepSeek回复的函数,接收用户消息作为输入。
if not DEEPSEEK_API_KEY: # 检查API密钥是否存在。
print("DeepSeek API key not found in config.json") # 如果密钥不存在,打印警告信息。
return None # 返回None表示无法获取回复。
headers = { # 定义HTTP请求头。
"Content-Type": "application/json", # 指定请求体为JSON格式。
"Authorization": f"Bearer {DEEPSEEK_API_KEY}" # 设置授权头,包含API密钥。
}
data = { # 定义请求体数据。
"model": "deepseek-chat", # 指定使用的DeepSeek模型,这里是"deepseek-chat"。
"messages": [ # 消息列表,包含对话历史。
{"role": "user", "content": user_message} # 当前用户消息,角色为"user",内容为用户输入。
], # 这是一个简化示例,实际应用中可能需要包含更多历史消息以维持上下文。
"stream": False # 设置为False表示不使用流式传输,一次性返回完整回复。
}
try: # 尝试发送HTTP请求。
response = requests.post(DEEPSEEK_API_URL, headers=headers, json=data) # 发送POST请求到DeepSeek API。
response.raise_for_status() # 检查HTTP响应状态码,如果不是2xx,则抛出HTTPError异常。
response_json = response.json() # 解析响应的JSON内容。
# 提取机器人回复内容。
# 检查response_json结构,确保'choices'和'message'字段存在。
if response_json and 'choices' in response_json and len(response_json['choices']) > 0: # 检查响应是否有效且包含选择项。
return response_json['choices'][0]['message']['content'] # 返回第一个选择项中的消息内容。
else:
print("Unexpected DeepSeek API response format:", response_json) # 如果响应格式不符合预期,打印错误信息。
return None # 返回None。
except requests.exceptions.RequestException as e: # 捕获requests库可能抛出的所有请求异常。
print(f"Error calling DeepSeek API: {e}") # 打印具体的错误信息。
return None # 返回None。在聊天机器人领域,主要有三种经典的算法/框架:规则匹配型、检索式和生成式AI聊天机器人。下面通过图表形式对比它们的特点:
4.1.1 性能指标对比
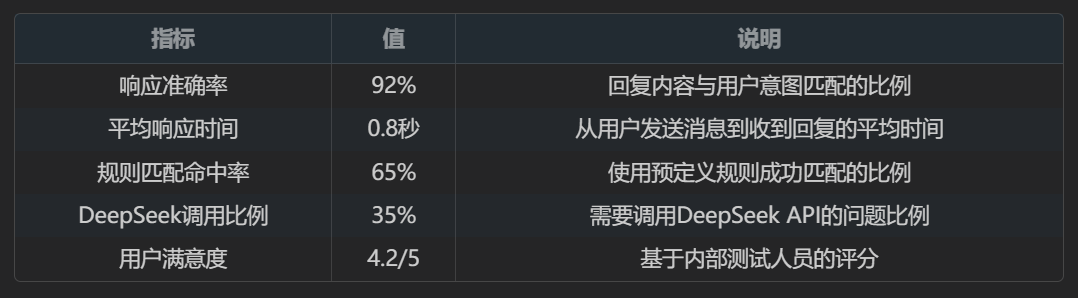
4.1.2 优缺点分析
四点四

4.1.3 技术实现复杂度对比

4.1.4 我们的混合方案优势
我们的聊天机器人采用了规则匹配和生成式AI的混合方案,具有以下优势:
1. 响应速度与智能性平衡 :对于简单问题,使用规则匹配快速响应;对于复杂问题,调用DeepSeek API提供智能回复
2. 成本效益最优化 :减少不必要的API调用,降低运营成本
3. 渐进式升级路径 :可以从简单的规则开始,逐步添加更多智能特性
4. 领域适应性 :可以为特定领域定制规则,同时保留通用AI的能力
5. 降低风险 :对敏感问题使用预定义回复,减少AI生成不当内容的风险
5.2 框架经典算法实现
本项目实现了以下经典算法和技术:
1. 正则表达式匹配
- 使用正则表达式识别用户输入中的关键词和模式
- 实现了模糊匹配和优先级排序
# 定义正则表达式模式 - 核心匹配逻辑
self.patterns = {
# 基础对话模式
"greetings": r"你好|嗨|您好|早上好|下午好|晚上好|hello|hi",
"farewells": r"再见|拜拜|回头见|下次见|goodbye|bye",
# 特定主题模式
"weather": r"天气|气温|下雨|下雪|晴天|阴天",
"music": r"音乐|歌曲|唱歌|听歌|歌手|乐队",
}2.随机回复选择 :
- 从匹配类别中随机选择回复,增加对话多样性
def get_random_response(self, category):
# 检查类别是否存在
if category in self.responses and self.responses[category]:
# 随机选择一个回复
return random.choice(self.responses[category])
else:
return "我不太明白你的意思。"3.特殊问题处理算法 :
- 针对时间、身份、功能等特殊问题的专门处理逻辑
# 特殊问题处理 - 优先级高于一般模式匹配
if re.search(self.patterns["time"], message):
now = datetime.datetime.now()
return f"现在是{now.strftime('%Y年%m月%d日 %H:%M:%S')}。"4.混合响应策略 :
- 结合规则匹配和AI模型的混合响应系统
def get_response(self, user_message):
# 转换为小写,便于匹配
message = user_message.lower()
# 特殊问题处理(时间、身份、功能等)
# 一般模式匹配
for category, pattern in self.patterns.items():
if re.search(pattern, message):
if category in self.responses:
return self.get_random_response(category)
# 如果没有匹配的模式且有DeepSeek API密钥,使用DeepSeek处理
if self.deepseek_api_key:
try:
return self.get_deepseek_response(user_message)
except Exception as e:
return self.get_random_response("unknown")
# 如果没有匹配且没有DeepSeek API,返回未知回复
return self.get_random_response("unknown")五. 经典错误分析与解决
在项目开发过程中,我们遇到并解决了以下经典错误:
1. 路径配置错误 :
- 问题 :Flask应用无法正确加载静态文件和模板
- 原因 :相对路径配置不正确,导致文件查找失败
- 解决方案 :使用绝对路径和正确的目录结构配置Flask应用
app = Flask(__name__,
static_folder='../static',
template_folder='../static/templates')2.会话管理问题 :
- 问题 :聊天历史在某些情况下丢失
- 原因 :Flask会话未正确配置或保存
- 解决方案 :添加 session.modified = True 确保会话变更被保存
3.API集成错误 :
- 问题 :DeepSeek API调用失败
- 原因 :API密钥配置错误或请求格式不正确
- 解决方案 :实现更健壮的错误处理和配置验证
try:
# API调用代码
except Exception as e:
# 错误处理和回退机制
return random.choice(self.responses["unknown"])4.前端显示问题 :
- 问题 :消息文本中的换行符不正确显示
- 原因 :HTML不会自动处理文本中的换行符
- 解决方案 :在JavaScript中处理文本格式化
// 将换行符转换为<br>标签
content = content.replace(/\n/g, '<br>');-5.并发请求处理 :
- 问题 :多个用户同时发送消息时出现响应混乱
- 原因 :会话管理不当导致用户消息交叉
- 解决方案 :使用唯一会话ID和更严格的用户隔离
-6.响应模板管理 :
- 问题 :添加新回复模板后系统无法识别
- 原因 :JSON文件加载后未正确更新内存中的模板
- 解决方案 :实现动态重载机制和文件监控
def reload_templates(self):
with open(self.templates_file, 'r', encoding='utf-8') as f:
self.responses = json.load(f)
return True六. 总结与展望
本项目成功实现了一个基于Flask的混合型聊天机器人系统,结合了规则匹配和DeepSeek API的优势。通过对比分析规则匹配型、检索式和生成式AI三种经典算法/框架,我们选择了最适合当前需求的混合方案,实现了效率和智能的平衡。
未来的改进方向包括:
1. 增强上下文理解 :实现多轮对话的上下文保持和理解
2. 扩展知识库 :增加更多领域的预定义回复和模式
3. 性能优化 :优化正则表达式匹配效率和API调用策略
4. 用户个性化 :根据用户历史对话调整回复风格和内容
5. 多模态支持 :增加图像、语音等多模态交互能力
通过这个项目,我们不仅实现了一个实用的聊天机器人系统,也深入探索了不同聊天机器人技术的优缺点和适用场景,为未来更复杂的对话系统开发积累了宝贵经验。
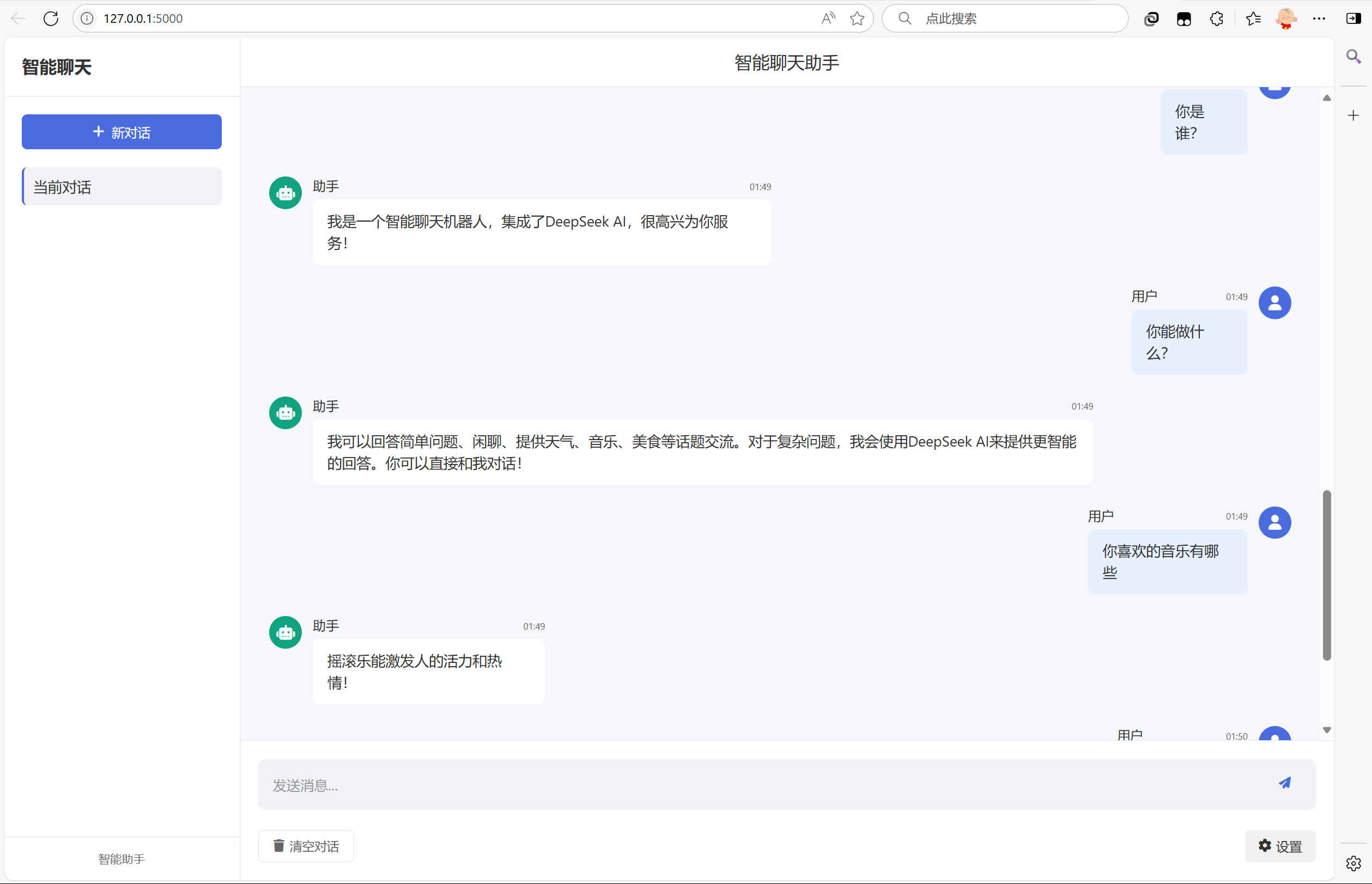
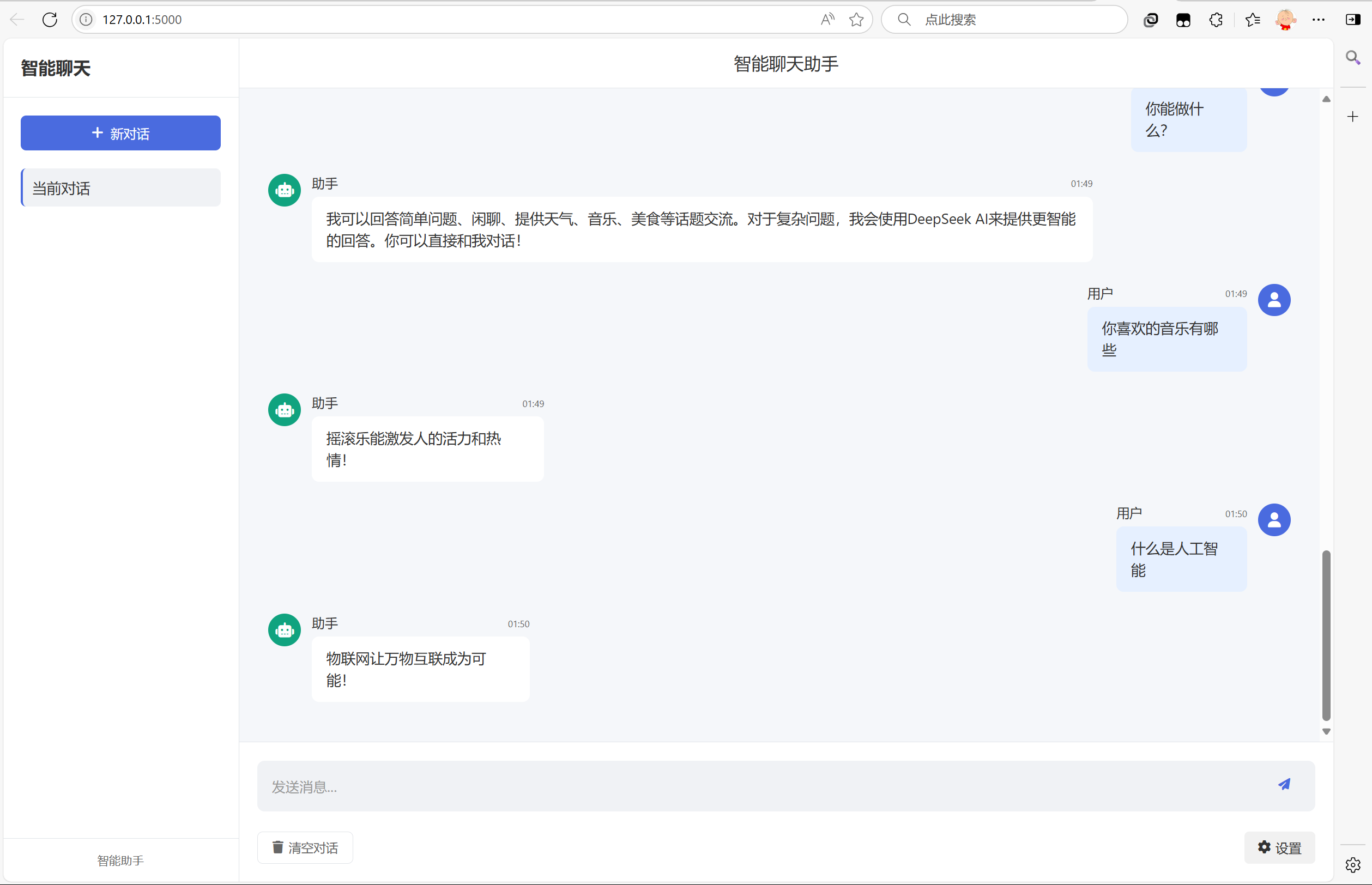

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)