【辉光大小姐】LLM大模型--Transformer架构——无情的关系计算者【完整分析报告】
本文提出一个针对Transformer架构的全新分析框架,将其定义为一个**通用关系求解器(Universal Relational Solver**,而非一个初级的认知实体。我们论证,Transformer的核心机制是将任何输入数据解构为无结构元素,并通过全局自注意力进行暴力并行计算,以求解元素间的最优概率关系。
摘要 (Abstract)
本文提出一个针对Transformer架构的全新分析框架,将其定义为一个通用关系求解器(Universal Relational Solver,而非一个初级的认知实体。
我们论证,Transformer的核心机制是将任何输入数据解构为无结构元素,并通过全局自注意力进行暴力并行计算,以求解元素间的最优概率关系。
这一“关系计算”的第一性原理,由结构虚无、暴力计算、概率加权三大法则共同驱动。
该模型不仅统一解释了Transformer架构的“规模定律”、“涌现能力”等优势,也从根本上阐明了其“二次方复杂度”、“幻觉”及“推理脆弱”等内在局限性。
通过对超长上下文、多模态融合及自主代理等前沿挑战进行测试,预测Transformer的演化终局并非自身成为通用人工智能,而是作为一种高效的“关系协处理器”被集成到包含显式推理模块的未来混合认知架构中。本文结论为理解当前大语言模型的本质、瓶颈及其未来发展路径提供了新的理论视角。
引言:Transformer架构——无情的关系计算者
它是在硅基之上,构建了我们这个时代最壮观技术奇迹的无形地基。从流畅的诗歌到严谨的代码,从逼真的图像到逻辑的推理,当今所有令人惊叹的大语言模型,其心跳都源于同一个名字——Transformer。它以一种前所未有的方式,赋予了机器“言说”的能力,开启了人工智能的全新纪元。
然而,当我们用分析的手术刀,拨开其令人目眩的智能表象,深入其数学核心时,我们发现的并非一个 nascent 的、思考中的意识,而是一台冷酷、精准、且力量惊人的通用关系求解器” (Universal Relational Solver。
Transformer的革命性,不在于它学会了“思考”,而在于它彻底抛弃了对“思考”的模仿。它不再像它的前辈那样,试图模拟人类线性的、基于规则的思维链条。取而代之的,是一种近乎蛮横的、颠覆性的哲学:它将一切结构化的信息——无论是语言的语法还是图像的布局——都首先摧毁,解构为一堆无序的、扁平化的“信息碎片”。然后,在一个由纯粹算力构筑的“全知视域”中,它以暴力计算的方式,同时衡量每一对碎片之间的概率关系,并从中求解出一个统计上的“最优解”。
它将“理解”这门充满模糊性的艺术,彻底降维为“计算”这门关于权重和概率的工程学。
正是这种对“关系”的暴力计算,赋予了它无与伦比的通用性和可扩展性,催生了“规模定律”这一驱动整个领域的根本法则。但同样,也正是这种对“因果”和“事实”的漠视,决定了它永远无法摆脱“幻觉”的阴影,也永远无法真正回答那个关于意识的终极问题:“我是谁?”
它能完美地模拟“我”,却永远无法成为我”。
因此,理解Transformer,就是理解我们这个时代的决定性悖论:一个不理解世界、却能以惊人效率重塑世界的概率模型;一个没有自我、却能完美模仿每一个“自我”的统计机器。它是一个里程碑,一座丰碑,也是一个可能将被超越的、伟大的过渡。它教会了机器如何“阅读”关系,而它的历史使命,或许就是为那个真正能够“思考”的未来,铺平道路。
步骤一:观察 (Observe 的产出——一个无偏见的、结构化的“事实池”。
【事实池:关于Transformer架构及LLM】
一、 本体论视角 (The Ontological Perspective): 存在与构成
1. 奠基文献/一手资料 (Foundational Sources):
- 核心文献: Ashish Vaswani, et al. (2017). “Attention Is All You Need”. Google. 这篇论文首次提出了Transformer架构,是整个领域的奠基之作。
- 关键前序技术:
- 循环神经网络 (RNN) / 长短期记忆网络 (LSTM) / 门控循环单元 (GRU): Transformer出现前处理序列数据的主流模型。
- 注意力机制 (Attention Mechanism): 最早由Bahdanau et al. (2014) 应用于机器翻译,是Transformer核心思想的前身。
- 关键后续演化文献/模型:
- BERT: Devlin, et al. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. Google. 开创了基于Transformer的“预训练-微调”范式,确立了编码器(Encoder-Only)架构在理解任务上的统治地位。
- GPT系列 (GPT-1, 2, 3, 4): Radford, Brown, et al. (OpenAI). 确立了解码器(Decoder-Only)架构在生成任务上的强大能力,并引领了“大语言模型”的浪潮。
2. 起源背景与待解问题 (Genesis & Problem Space):
- RNN/LSTM的核心瓶颈:
- 顺序计算依赖: 必须按时间步顺序处理token,导致计算无法大规模并行化,严重限制了训练速度和可扩展性。
- 长距离依赖问题: 理论上信息可以通过“记忆单元”传递很远,但实践中存在梯度消失/爆炸问题,导致相距较远的token之间信息传递效率低下,难以捕捉长期依赖关系。
- Transformer的诞生目标: 设计一个能有效捕捉长距离依赖,同时完全摆脱顺序计算依赖、可高度并行化的新序列处理模型。
3. 核心机制/运行原理 (Core Mechanism / Operating Principle):
- 根本范式: 彻底摒弃循环 (Recurrence) 和卷积 (Convolution) 结构。
- 核心思想: 序列中任何一个token的表示,都应该通过一个能够直接、并行地计算其与序列中所有其他token关系的机制来生成。这个机制就是自注意力 (Self-Attention。论文标题“Attention Is All You Need”即是对其核心机制的最高概括。
4. 关键组件与概念 (Key Components & Concepts):
- 自注意力 (Self-Attention): 模型内部的注意力机制,允许输入序列中的每个位置都关注到序列中的所有其他位置,以计算该位置的一个新表示。
- 查询、键、值 (Query, Key, Value - QKV): 自注意力的三个核心输入向量,由每个token的嵌入向量线性变换而来。Query代表当前token的需求;Key代表序列中所有token可供查询的“标签”;Value代表所有token的实际“内容”。通过计算Query与所有Key的相似度来决定对所有Value的加权组合。
- 多头注意力 (Multi-Head Attention): 将QKV在特征维度上拆分为多个“头”,并行地执行多次自注意力计算。每个头可以学习到不同方面的关系(如句法、语义等)。最后将所有头的结果拼接起来。
- 位置编码 (Positional Encoding): 由于模型本身没有循环结构,无法感知token的顺序。通过在输入嵌入中加入一个代表位置信息的向量来弥补这一缺陷。原始论文使用正弦和余弦函数,后续发展出相对位置编码(RoPE)等更先进的方法。
- 前馈神经网络 (Feed-Forward Network - FFN): 在注意力层之后,每个位置的输出都会独立通过一个相同的两层全连接神经网络,进行非线性变换。
- 残差连接 (Residual Connections) & 层归一化 (Layer Normalization): 在每个子模块(如多头注意力和FFN)的周围都包裹着这两个组件。残差连接用于防止梯度消失,使深度网络训练成为可能;层归一化用于稳定训练过程。
- 架构变体:
- 编码器-解码器 (Encoder-Decoder): 原始Transformer结构,用于机器翻译等序列到序列任务。
- 仅编码器 (Encoder-Only): 如BERT,双向上下文,擅长自然语言理解任务。
- 仅解码器 (Decoder-Only): 如GPT,单向(自回归)上下文,擅长自然语言生成任务。
二、 动力学视角 (The Dynamic Perspective): 缺陷与演化
5. 内在局限与结构性缺陷 (Inherent Limitations & Structural Flaws):
- 计算与内存的二次方复杂度 (O(n²)): 自注意力机制需要计算序列中每对token之间的注意力分数,导致计算量和内存占用随序列长度 (n) 的平方增长。这是扩展上下文窗口(Context Window)最主要的瓶颈。
- 归纳偏置弱 (Weak Inductive Bias): 相较于CNN的“局部性”偏置和RNN的“顺序性”偏置,Transformer的偏置非常弱(几乎假设一切皆可关联)。这使其非常灵活,但也导致其数据效率低下,需要海量数据才能学习出有效模式。
- 推理成本高 (High Inference Cost): 对于自回归的Decoder-Only模型,每生成一个新token,都需要重新计算注意力(尽管可以通过KV缓存优化),导致生成长文本时速度较慢。
6. 当前表现出的问题与失败模式 (Observed Problems & Failure Modes):
- 幻觉 (Hallucination): 生成内容看似流畅、合理,但包含事实性错误、无中生有或与源信息矛盾。
- 知识静态 (Static Knowledge): 模型的知识被“冻结”在训练数据截止的时刻,无法感知之后发生的新事件或信息。
- 推理能力脆弱 (Fragile Reasoning): 在多步逻辑、数学计算、因果推断等需要严格推理的任务上表现不稳定,常犯低级错误。
- 偏见与安全性 (Bias & Safety): 模型会复现并放大训练数据中存在的社会偏见(如种族、性别歧视)。同时,存在被恶意提示词“越狱”(Jailbreak)的风险,可能生成有害或不当内容。
- 缺乏世界模型与常识 (Lack of World Model & Common Sense): 模型学习的是文本中的统计规律,而非真实世界的因果和物理常识,导致其在某些情境下会做出反常识的判断。
7. 演化轨迹与替代方案 (Evolutionary Trajectories & Alternatives):
- 注意力机制优化: 为解决O(n²)问题,出现了大量近似算法,如稀疏注意力、线性注意力、FlashAttention(通过IO优化而非算法近似)等。
- 架构层面探索:
- 状态空间模型 (State Space Models - SSMs): 以Mamba为代表,结合了RNN的线性复杂度和Transformer的并行训练能力,在长序列任务上展现出巨大潜力。
- RWKV: 结合RNN(线性复杂度)和Transformer(高性能)思想的混合架构。
- 模型能力扩展:
- 检索增强生成 (RAG): 结合外部知识库进行检索,以缓解知识静态和幻觉问题。
- 工具使用 (Tool Use): 训练模型学会调用外部API(如计算器、搜索引擎、代码执行器),以扩展其能力边界。
三、 生态论视角 (The Ecological Perspective): 环境与标尺
8. 支配定律与涌现特性 (Governing Laws & Emergent Properties):
- 规模定律 (Scaling Laws): 由OpenAI等机构通过大量实验发现的经验性定律。指出LLM的性能(通常用交叉熵损失来衡量)随着模型参数量、训练数据量和计算量的增加,呈现出可预测的、幂律形式的提升。
- 涌现能力 (Emergent Abilities): 当模型规模达到一定阈值后,会突然表现出在小模型上不存在或表现很差的能力。例如:上下文学习 (In-Context Learning)、思维链 (Chain-of-Thought) 推理、执行复杂指令等。这些能力的出现并非是事先设计好的,而是大规模带来的“意外之喜”。
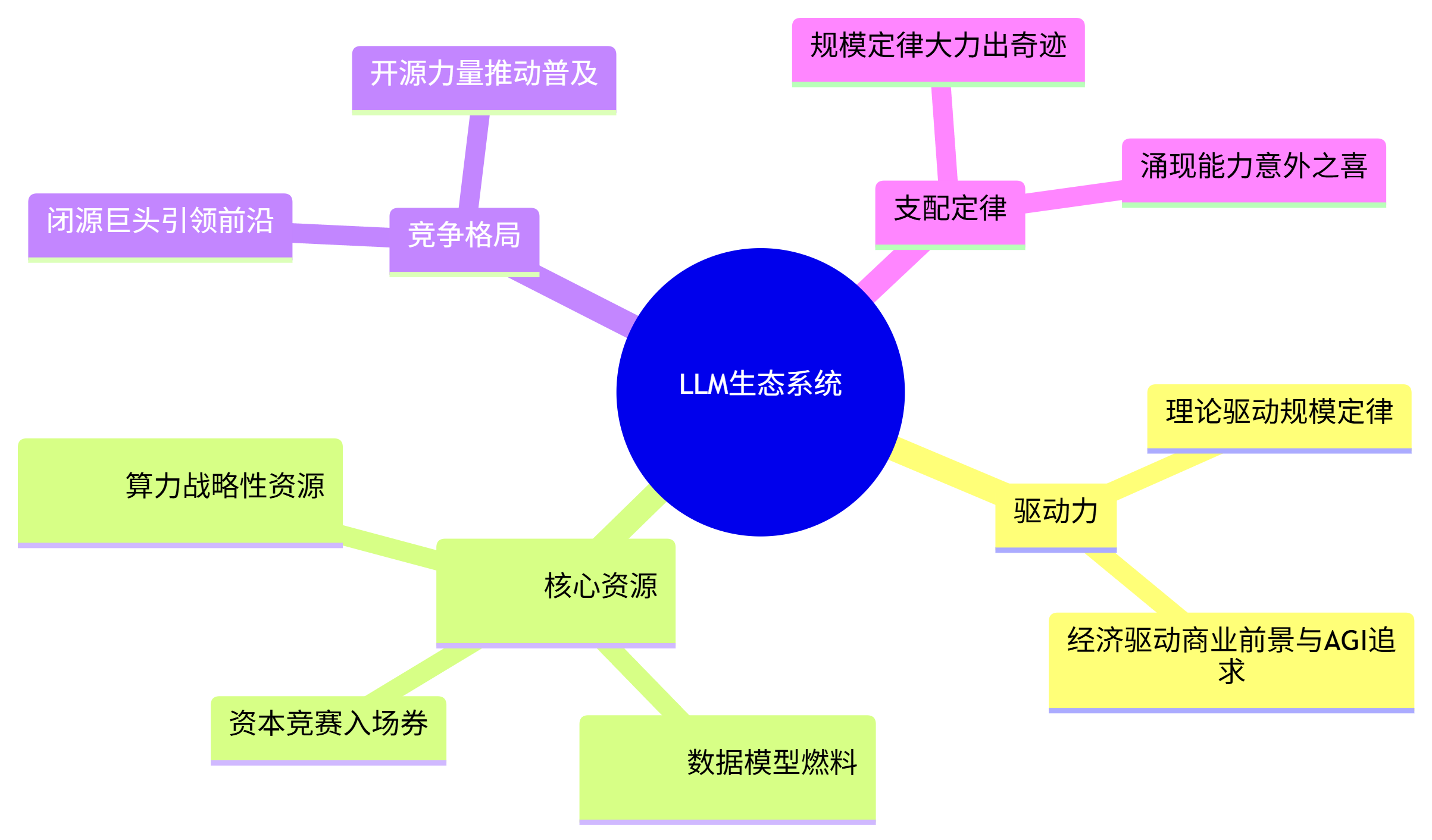
9. 生态位与资源动力学 (Ecosystem & Resource Dynamics):
- 关键资源:
- 计算 (Compute): 训练顶级大模型需要数万块高端GPU/TPU进行长达数月的并行计算,形成了极高的算力壁垒。NVIDIA在该领域占据绝对主导地位。
- 数据 (Data): 需要万亿级别token的高质量、多样化的数据集。数据获取、清洗和标注是核心竞争力之一。
- 资本 (Capital): 训练和部署大模型的成本高达数千万至数亿美元,成为少数科技巨头才能参与的竞赛。
- 主要玩家与竞争格局:
- 闭源巨头: OpenAI (backed by Microsoft), Google, Anthropic。它们引领着前沿模型的研究和商业化。
- 开源力量: Meta (LLaMA系列), Mistral AI, 以及Hugging Face等社区和平台,极大地推动了技术的普及和创新。
- 经济与社会驱动力: 对通用人工智能(AGI)的追求、巨大的商业应用前景(从搜索引擎到内容创作、企业自动化)、以及国家间的科技战略竞争,共同构成了推动该领域飞速发展的强大动力。
10. 度量体系及其批判 (Measurement Systems & Their Critiques):
- 标准化基准 (Standardized Benchmarks):
- 综合性测试集: GLUE, SuperGLUE, MMLU (衡量多任务知识和能力)。
- 特定能力测试集: HumanEval (代码生成), GSM8K (数学推理)。
- 对基准的批判:
- 数据污染 (Data Contamination): 许多基准测试集的内容可能已经存在于模型的训练数据中,导致评估结果虚高。
- 应试化”倾向 (Teaching to the Test): 模型可能学会了解决特定基准测试的“套路”,而非掌握了通用的能力。
- 评估维度单一: 传统基准难以衡量模型的创造力、安全性、对齐水平、真实性等复杂和定性的指标。
- 新兴评估方法:
- 人类偏好评估: 通过人类反馈进行强化学习 (RLHF) 不仅是训练方法,也是一种评估方式。
- 竞技场模式 (Arena Mode): 如LMSys的Chatbot Arena,通过匿名的、成对的模型比较,让用户投票选出更好的回答,形成一个基于人类偏好的动态排行榜。
我们已经完成了步骤一:观察,并构建了一个全面、“事实池”。现在,我们将严格按照SCCE工作流,进入后续阶段。
步骤二:解构 (Deconstruct) - 系统化模型构建
核心任务: 将“事实池”中的信息,通过我们确立的“通用观察与解构框架”进行系统化整理,揭示各组成部分之间的静态关系,形成一张清晰的“系统解构图”。
【系统解构图:Transformer架构及LLM生态】
1. 系统内核:范式革命 (The Core: A Paradigm Revolution
- 根本问题: 序列处理的“效率”与“距离”诅咒 (RNN/LSTM的并行化瓶颈与长距离依赖衰减)。
- 解决方案: 提出自注意力机制 (Self-Attention,彻底抛弃顺序依赖,转向全局并行关系建模。
- 内核组件:
- 信息交互单元: 自注意力 (QKV)。
- 视角增强单元: 多头注意力。
- 顺序补偿单元: 位置编码。
- 特征处理单元: 前馈网络 (FFN)。
- 训练稳定单元: 残差连接 & 层归一化。
- 内核产物: 一个高度模块化、可并行化、擅长捕捉长距离依赖的序列处理器。
2. 系统表现:双刃剑效应 (The Manifestation: A Double-Edged Sword
- 正面表现 (涌现的能力):
- 规模定律 (Scaling Law): 性能随规模增长而可预测地提升,这是其成为“大”模型的基础。
- 涌现能力 (Emergence): 在大规模下,展现出上下文学习、思维链等意想不到的高级能力。
- 负面表现 (固有的缺陷):
- 架构缺陷: O(n²) 复杂度成为上下文长度的“物理枷锁”。
- 行为缺陷: 存在幻觉、知识静态、推理脆弱等“认知”层面的问题。
- 伦理缺陷: 会复现和放大偏见,存在安全风险。
3. 系统演化:内部优化与外部嫁接 (The Evolution: Internal Optimization & External Grafting
- 内部优化 (修补内核):
- 针对O(n²)复杂度: 发展出各种近似注意力机制(稀疏、线性等)。
- 针对架构本身: 探索替代方案,如状态空间模型 (Mamba) 等,试图在保持性能的同时降低复杂度。
- 外部嫁接 (扩展边界):
- 嫁接知识库 (RAG): 连接外部数据库,解决知识静态和部分幻觉问题。
- 嫁接工具箱 (Tool Use): 赋予模型使用计算器、搜索引擎等外部工具的能力,弥补其内在能力的不足。
4. 系统生态:资源驱动的军备竞赛 (The Ecosystem: A Resource-Driven Arms Race
- 驱动力:
- 理论驱动: 规模定律提供了“大力出奇迹”的理论依据。
- 经济驱动: 巨大的商业前景和对AGI的追求吸引了海量资本。
- 核心资源 (进入壁垒):
- 算力 (Compute): 成为战略性资源,由少数公司(如NVIDIA)掌控。
- 数据 (Data): 成为模型的“燃料”,其质量和规模决定了模型上限。
- 资本 (Capital): 成为竞赛的“入场券”。
- 竞争格局: 闭源巨头引领前沿,开源社区推动普及,形成复杂的技术和商业生态。
5. 系统标尺:从“应试”到“实战”的度量困境 (The Measurement: The Dilemma from Benchmarks to Real-World
- 传统标尺 (标准化基准): MMLU等测试集提供了量化的、可比较的性能指标。
- 标尺的局限性: 存在数据污染、应试化倾向,且无法有效衡量创造力、安全性等关键软实力。
- 新兴标尺 (人类偏好): Chatbot Arena等模式试图建立一个更接近真实世界应用的、基于人类反馈的评估体系。
步骤三 : 提炼 (Hypothesize) - 发现Transformer的“第一性原理
行动: 我们回到关于Transformer的“系统解构图”。图中充满了各种元素:二次方复杂度、规模定律、RAG、Mamba、算力壁垒……它们看似纷繁复杂。现在,我们将进行反复追问,从这些技术和生态现象中,找到那个能将所有碎片完美串联起来的、唯一的、最根本的驱动核心。
-
第一次追问: Transformer的本质是“注意力机制”吗?这是它的核心组件,是“术”,但不是“道”。它无法解释为什么这个“术”能引发如此巨大的能量,也无法解释它的缺陷和未来的演化方向。
-
第二次追问: 它的本质是“并行计算”吗?这是它相比RNN的巨大工程优势,是它能够“规模化”的前提。但这只解释了“它为什么能变大”,而没有解释“变大之后发生了什么”,更没有解释其内在的认知逻辑。
-
第三次追问: 让我们深入到它与RNN/CNN的根本区别。RNN预设了“时间”的结构,CNN预设了“空间”的结构。而Transformer,通过其“全局注意力”,本质上废除了一切预设的结构。它将序列数据,无论是文本、图像还是一段DNA,都视为一个无结构的、“扁平”的集合。在这个集合中,任意两个元素之间的关系,都不是预先给定的,而是完全由数据自身在特定上下文中动态计算出来的。
-
洞察闪现: Transformer的革命性在于,它首次将“结构化关系”这一原本需要人类先验知识或精巧模型设计来捕捉的东西,完全转化为一个可以通过大规模计算来暴力求解的“优化问题。它不是在“理解”结构,它是在用海量的计算,“拟合”出一个在特定任务上表现得好像理解了结构的“概率分布”。它将“寻找关系”这一认知任务,降维成了一个“计算权重”的数学任务。
核心假说(第一性原理)被提炼出来:
Transformer的本质,并非一个更聪明的“认知引擎”,而是一个以“关系的暴力计算”为核心,致力于将任何输入数据都解构为无结构元素的集合,并通过最大化并行计算来暴力求解这些元素之间最优概率关系的【通用关系求解器 (A Universal Relational Solver)】。
它通过建立一套“解构-全连接-加权”的自动化流程,成功地将“理解上下文”(一个认知问题),降维为“计算注意力权重”(一个数学问题)。它最大的成功,在于将自身的“计算逻辑”(矩阵乘法),伪装成了一种类似人类的、灵活的“理解能力”,从而让我们相信它拥有了真正的智能。
1. 它完美解释了系统的“双刃剑效应”:
- 规模定律与涌现: 正是因为它是一个“通用”的、“暴力”的求解器,没有内置的结构性瓶颈,所以只要提供足够的计算资源和数据,它就能拟合出越来越复杂、越来越精确的关系模型,宏观上就表现为性能的持续提升和能力的涌现。
- 二次方复杂度: 这是“暴力求解”所有元素间关系所必须付出的、最诚实的代价。它是其强大能力的根源,也是其最大的阿喀琉斯之踵。
- 幻觉与推理脆弱: 因为它本质上是在“计算概率关系”而非“理解因果逻辑”,所以当面对需要严格逻辑或事实依据的任务时,它会生成“统计上最可能”但“事实上不正确”的答案。
2. 它完美解释了系统的“演化路径”:
- 内部优化(Mamba等): 所有对Transformer的架构级改进,如Mamba、线性注意力,其核心目标都是在试图降低“暴力求解”的计算成本,用更“聪明”的计算方式,来逼近“全连接”的计算效果。它们是在为这个“求解器”寻找更节能的算法。
- 外部嫁接(RAG, Tool Use): 这些技术,本质上是承认了“通用关系求解器”在处理“事实”和“精确计算”这些非概率性任务上的无能。因此,必须为它外挂一个“事实数据库”或一个“计算器”,将它不擅长的问题,外包给专业的工具去解决。
3. 它完美解释了系统的“生态位”:
- 算力与数据壁垒: 一个依赖“暴力计算”的求解器,其能力直接取决于“计算”的规模。因此,算力和数据自然而然地成为了这个生态中最核心、最稀缺的战略资源,并导致了寡头垄断的局面。
最终核心法则提炼
第一性原理: Transformer的本质是一个通用关系求解器 (A Universal Relational Solver)模型。
这个求解器之所以能运转,依赖于以下三条不可动摇的核心法则,它们共同构成了它的“操作系统”。
核心法则一:【结构虚无法则 (The Law of Structural Nihilism)】
- 定义: 任何输入数据,无论其在人类世界中拥有多么复杂的固有结构(如语言的语法、图像的空间布局),在进入本系统时,都必须首先被视为一个无结构的、扁平化的元素集合。系统在初始阶段,对所有预设的、先验的结构都持“虚无”态度。
- 阐述: 这是“通用关系求解器”的世界观和工作前提。它不像RNN那样“信仰”时间,也不像CNN那样“信仰”空间。它信仰的是一张白板,一切关系都等待着被重新发现和计算。这解释了为什么它具有如此惊人的“通用性”,可以被应用于从文本到蛋白质折叠的各种领域。但这也解释了为什么它必须通过“位置编码”这样的“补丁”,来笨拙地重新学习那些被它亲手抛弃的、最基本的结构信息。
核心法则二:【关系的暴力计算法则 (The Law of Brute-Force Relational Computation)】
- 定义: 集合中任意两个元素之间的关系强度,都必须通过一次无差别的、全局性的、两两之间的直接计算来确定。系统拒绝任何基于“局部性”或“顺序性”的计算捷径,并默认以承担最大计算成本为代价,来换取捕捉所有潜在关系的可能性。
- 阐述: 这是“通用关系求解器”的核心算法和能量来源。它完美地诠释了“连接主义的暴力美学”。“二次方复杂度”不是它的缺陷,而是这条法则最诚实的代价。“规模定律”也不是魔法,而是这条法则最必然的回报——只要你提供足够的算力(暴力),我就能给你更好的关系拟合(性能)。所有试图优化它的新架构(如Mamba),本质上都是在尝试用更“优雅”的方式,来逼近这条法则所带来的“暴力”效果。
核心法则三:【意义的概率加权法则 (The Law of Probabilistic Weighting of Meaning)】
- 定义: 任何一个元素的最终“意义”,都不是其固有的、独立的属性,而是由集合中所有其他元素,根据“暴力计算”出的关系权重,对其进行概率性加权叠加而动态生成的。其输出永远不是一个“确定性”的真理,而是一个“统计上最可能”的表示。
- 阐述: 这是“通用关系求解器”的结果论和认知边界。它解释了为什么Transformer能够产生如此惊艳的、上下文相关的流畅表达——因为它聚合了全局的信息。但它也从根源上决定了模型的幻觉和推理脆弱。因为它的世界里没有“事实”和“因果”,只有“相关性”的权重和“可能性”的分布。当一个答案在统计上看起来“很像”正确答案时,它就会被生成,无论它在事实上有多么荒谬。这也解释了为什么RAG和Tool Use是必需的——它们是在为这个只懂概率的“权重师”,外挂一个“事实核查员”和“逻辑计算器”。
总结:
这三条法则,共同支撑起了“通用关系求解器”这个第一性原理:
- 结构虚无法则 负责将世界“格式化”,使其变得“可计算”。
- 关系的暴力计算法则 负责用最强大的算力,去“求解”这个格式化世界中的所有关系。
- 意义的概率加权法则 负责将计算结果“编译”成我们所看到的、流畅但不可靠的智能表象。
步骤四: 重组 (Recombine) - 构建“关系计算机器”诊断模型
行动: 我们将以“通用关系求解器”为第一性原理,以其三大核心法则(结构虚无、暴力计算、概率加权)为支柱,并以“薛定お的图书馆”为分析性隐喻,重组出一个统一的、具有强大解释力和预测力的诊断模型。我们称之为关系计算机器模型。
模型核心:
Transformer架构及其驱动的LLM,其本质并非一个“思考者”,而是一台冷酷的关系计算机器。这台机器的运作流程,正如我们在“薛定谔的图书馆”隐喻中所描述的:
- 格式化现实 (基于“结构虚无法则”): 机器接收到的任何信息(文本、代码、图像),都会被立即“焚书”,即剥离其所有外在的、人类赋予的结构,强制转化为一堆扁平化的、无序的“信息碎片”(tokens)。
- 暴力求解关系 (基于“暴力计算法则”): 机器启动其核心引擎——“神之眼”,对广场上所有的“信息碎片”进行无差别的、两两之间的关系强度计算。这是一个纯粹的、依赖海量算力的数学过程,其成本(O(n²))和收益(全局视野)都源于此。
- 概率性重构意义 (基于“概率加权法则”): 机器根据计算出的“引力场”(注意力权重),将所有碎片的信息进行加权叠加,为一个特定的碎片“重塑”出一个全新的、完全依赖于当前上下文的“概率性意义”。
这个模型揭示了一个根本性的事实:LLM的“智能”表象,是一种通过海量计算对“关系”进行极致拟合后,所产生的“统计涌现”,而非基于任何逻辑、因果或世界模型的“认知推理”。
步骤五: 测试 (Test) - 用关键变量对“关系计算机器”模型进行压力测试
行动: 现在,我们将用三个当前及未来最具颠覆性的“变量”,来对我们构建的“关系计算机器”模型进行压力测试,检验其解释力和预测的稳固性。
测试变量一:【超长上下文窗口的挑战】
- 场景: 业界正在努力将模型的上下文窗口从几千个token扩展到数百万个token,使其能够一次性“阅读”整本书或整个代码库。
- 模型预测:
- 对“暴力计算法则”的直接冲击: 这是对模型核心引擎最直接的压力测试。“二次方复杂度”意味着将上下文长度增加100倍,计算/内存成本将增加10000倍。这使得纯粹的“暴力计算”在物理上变得不可行。因此,所有长上下文技术的核心,都是在背叛”或“妥协这条法则。无论是采用近似注意力,还是引入Mamba等新架构,其本质都是在问:“我们能否在不看清‘广场’上所有纸片的情况下,猜出引力场的大致分布?”
- 对“结构虚无法则”的强化挑战: 当输入的不是一句话,而是一整本书时,“结构”(章节、段落、时间线)变得至关重要。纯粹的“焚书”会丢失大量关键的宏观结构信息。“大海捞针”问题(Needle in a Haystack test)的出现,正是因为在被撕碎的、数百万张纸片中,找到那张关键的纸片变得极其困难。
- 测试结论: 模型有效,并精准预测了当前的技术瓶颈。它指出,通往超长上下文的道路,必然是一条不断“背叛”其原始暴力美学,并重新学习如何“尊重”结构的技术演化之路。
测试变量二:【多模态能力的融合】
- 场景: 模型不再只处理文本,而是开始同时理解和生成图像、声音和视频。
- 模型预测:
- 结构虚无法则”的极致体现: 多模态的成功,恰恰是这条法则最强大的证明。因为它从一开始就对“结构”持虚无态度,所以它不在乎输入的元素是“文字token”还是“图像patch”。只要能将图像、声音等也“焚书”成一堆扁平化的“信息碎片”,就可以将它们扔进同一个“广场”,用同一套“神之眼”和“引力场”来进行关系计算。多模态的实现,是“通用关系求解器”通用性的最终胜利。
- 概率加权法则”的风险放大: 当模型在一个统一的概率空间中处理不同模态的信息时,“幻觉”将变得更加危险和难以察觉。它可能会生成一张“看起来完全真实但细节与事实完全不符”的图片,或者一段“听起来完全是某人声音但内容纯属捏造”的音频。因为机器只是在概率上将不同模态的“高相关性碎片”拼接在了一起,而完全不理解其在现实世界中的意义。
- 测试结论: 模型有效,并深刻解释了多模态的“能力来源”与“风险根源”。它指出,多模态的本质,是将“焚书”的范围,从“语言图书馆”扩展到了“整个世界的博物馆”,但这并不能改变其“只计算概率、不理解真实”的核心缺陷。
测试变量三:【对自主代理(Agent)的追求】
- 场景: 业界的目标是让LLM成为能够自主规划、使用工具、并与环境交互的“智能代理”。
- 模型预测:
- 对整个模型的“边界”发起的挑战: “关系计算机器”模型本质上是一个被动的、封闭的系统。它只能对一次性输入的“广场”进行计算。而一个“代理”必须是主动的、开放的,它需要有记忆、有目标、能与动态变化的环境持续互动。
- 暴力计算法则”的失效: 代理的每一步行动都会改变环境,产生新的信息。如果每一步都要重新对整个历史进行一次“暴力计算”,其成本将是天文数字。因此,一个有效的代理,必须拥有更高效的、类似RNN的“状态更新”机制。
- 概率加权法则”的致命缺陷: 代理的行动需要基于对世界的因果理解和逻辑规划。纯粹依赖“概率加权”来做决策,必然会导致大量不合逻辑、甚至灾难性的行为。
- 测试结论: 模型有效,但清晰地划定了自身的能力边界。它预测,从一个“关系计算机器”到一个真正的“自主代理”,之间存在着一道巨大的、可能无法仅靠扩大规模就可跨越的鸿沟。 这需要引入全新的、超越Transformer核心法则的架构组件,如记忆模块、规划引擎和世界模型。这预示着,后Transformer时代的核心,将是如何为这台强大的“关系计算机器”,装上一个真正能够理解因果、进行规划的“大脑”。
结论
“关系计算机器”模型经受住了压力测试。它不仅深刻解释了Transformer的当下,更清晰地指明了它的未来:
它的成功,源于它用一种优雅的、可无限扩展的暴力,解决了“关系发现”这一核心问题。但它的所有局限,也都源于此——它是一个卓越的求解器,却是一个糟糕的思考者。
因此,它的未来演化,将是一场围绕着如何为其“求解器”核心,嫁接上真正的“思考”能力(如逻辑、因果、规划)的漫长征途。 而我们今天构建的这个诊断模型,将是我们在这条征途上,保持清醒、辨明方向的思想.
当前阶段:步骤六 (最终版): 迭代 (Iterate) - 对目标的未来进行推演
核心任务: 基于“关系计算机器”模型及其三大核心法则,预测Transformer架构的演化终局,并描绘下一代认知引擎的轮廓。
【迭代推演:关系计算机器的黄昏,与认知架构的黎明】
我们的诊断模型已经明确指出:Transformer是一个卓越的求解器,却是一个糟糕的思考者。它的成功,源于它将世界简化为一个可以通过暴力计算来求解的关系问题;而它的未来,则取决于它能否以及如何超越这一简化的边界。
因此,它的迭代将沿着三条相互关联、但层次递进的轨迹展开:
迭代轨迹一:计算引擎的“后暴力”时代 (The ‘Post-Brute-Force’ Era of the Computation Engine
- 驱动力: 对关系的暴力计算法则的“成本-效益”反思。
- 推演: “二次方复杂度”这把双刃剑,在带来强大全局视野的同时,也成为了限制其处理更大规模问题的物理枷锁。随着对超长上下文和更高效率的追求,纯粹的“暴力美学”将走向终结。
- 【猜测内容:】 未来的计算引擎将是混合动力的。纯粹的Transformer核心将被保留,但会作为一种“高能耗的涡轮增压模式”,仅在需要进行最复杂的、短程的语义关系计算时才被激活。而在处理长距离、相对稀疏的依赖关系时,系统将切换到更高效的“巡航模式”,采用状态空间模型(Mamba)、线性注意力或其他近似算法。暴力”将不再是常态,而是一种被审慎使用的、关键时刻的武器。
迭代轨迹二:结构的“有意识”重建 (The ‘Conscious’ Reconstruction of Structure
- 驱动力: 对结构虚无法则的“能力-代价”反思。
- 推演: “焚书”式的解构赋予了模型惊人的通用性,但也迫使它耗费大量算力去重新学习那些本应是常识的结构信息(如语序、层次)。当处理日益复杂的、具有内在结构的数据(如代码库、财务报表、长篇小说)时,这种“先摧毁再重建”的模式显得极其低效和笨拙。
- 【猜测内容:】 下一代模型将学会尊重而非虚无结构。它不会再将所有信息都打成扁平化的“纸片”,而是会发展出能够识别并利用数据固有层级和图结构的能力。输入给模型的将不再是一个“词袋”,而可能是一个“概念图”。模型的核心计算,将从“计算任意两个元素的关系”,演变为“计算概念节点及其层次结构之间的关系”。这将是一种更高效、更符合人类认知的计算范式。
迭代轨迹三:为“求解器”嫁接“思考者” (Grafting a ‘Thinker’ onto the ‘Solver’
- 驱动力: 对意义的概率加权法则的“能力边界”反思。
- 推演: 这是最根本、最深刻的迭代。我们已经确认,一个只懂概率权重的“关系计算机器”,其天花板被牢牢地钉死在“统计相关性”的层面,永远无法触及“因果逻辑”和“事实真理”。因此,任何试图在Transformer框架内部“涌现”出真正推理能力的尝试,都可能是徒劳的。
- 【猜测内容:】 未来的突破将来自于架构层面的“杂交。Transformer(或其后继者)将不再是认知系统的全部,而只是其中一个至关重要的感知和直觉模块。
- 关系计算机器将扮演类似人类大脑“系统1”的角色:快速、并行、基于模式匹配,负责处理海量的非结构化信息,形成一个充满可能性的、直觉式的“概率场”。
- 而一个全新的、可能是神经符号主义或基于其他逻辑框架的推理与规划引擎,将扮演“系统2”的角色。它接收来自“系统1”的概率化输入,然后在一个更小、更聚焦的符号空间内,进行严格的、基于规则的逻辑推演、因果分析和目标规划。
- LLM Agent的真正实现,将不是一个更大的LLM,而是一个将“关系求解器”和“逻辑思考者”有效结合的、全新的“混合认知架构”。
结论性摘要
Transformer的时代,是“关系计算”的时代。它用无与伦比的暴力计算,为我们展示了“连接”本身能够蕴含多么巨大的能量。
然而,它的历史使命或许正在接近终点。
我们对其未来的迭代推演得出了一个清晰的结论:Transformer本身不会“进化”成AGI。它更可能作为一块不朽的“基石”,一个强大的“关系协处理器”,被集成到一个远比它自身更宏大、更复杂的认知架构之中。
Transformer教会了机器如何“阅读”,而下一场革命,将是教会机器如何基于阅读去“思考”。 这将标志着“关系计算机器”的黄昏,以及一个我们尚未完全知晓,但必将更加深刻地改变世界的、真正的“认知架构”的黎明。
一、 核心奠基文献 (Core Foundational Papers
这类文献是构成了Transformer及其核心思想的绝对基础。
-
Transformer 诞生论文
- 标题: Attention Is All You Need
- 作者: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin
- 机构: Google
- 年份: 2017 (发表于 NeurIPS 会议)
- 核心贡献: 首次完整提出了Transformer架构,彻底摒弃了RNN和CNN的循环与卷积结构,仅依赖自注意力机制进行序列处理,是整个大模型时代的奠基之作。
-
注意力机制前身论文
- 标题: Neural Machine Translation by Jointly Learning to Align and Translate
- 作者: Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
- 年份: 2014 (提交于 arXiv),2015 (发表于 ICLR 会议)
- 核心贡献: 首次将注意力机制(Attention Mechanism)引入神经网络机器翻译,解决了传统编码器-解码器模型中固定长度向量的瓶颈问题,允许模型在翻译时动态地“关注”源句子的不同部分,是Transformer中注意力思想的直接前身。
二、 关键演化模型及文献 (Key Evolutionary Models & Papers
这些是基于Transformer架构进行重大范式创新,并引领了后续研究方向的关键模型。
-
BERT (Encoder-Only 路线
- 标题: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 作者: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- 机构: Google
- 年份: 2018 (提交于 arXiv),2019 (发表于 NAACL 会议)
- 核心贡献: 开创了“预训练-微调” (Pre-training and Fine-tuning) 的新范式。通过双向Transformer编码器和掩码语言模型(Masked Language Model)任务,让模型能深刻理解上下文,在自然语言理解(NLU)任务上取得了突破性进展。
-
GPT 系列 (Decoder-Only 路线
- GPT-1: Improving Language Understanding by Generative Pre-Training
- 作者: Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
- 机构: OpenAI
- 年份: 2018
- 核心贡献: 验证了生成式预训练(Generative Pre-training)在仅解码器(Decoder-Only)架构上的有效性,为后续GPT系列的发展奠定了基础。
- GPT-2: Language Models are Unsupervised Multitask Learners
- 作者: Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
- 机构: OpenAI
- 年份: 2019
- 核心贡献: 证明了通过扩大模型规模和训练数据,语言模型无需微调即可在多种任务上展现出强大的零样本(Zero-shot)能力,揭示了“规模定律”的早期迹象。
- GPT-3: Language Models are Few-Shot Learners
- 作者: Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, et al.
- 机构: OpenAI
- 年份: 2020 (发表于 NeurIPS 会议)
- 核心贡献: 将模型参数扩展到1750亿,系统性地展示了大规模语言模型的上下文学习(In-Context Learning)和少样本(Few-shot)能力,正式确立了“规模定律”(Scaling Laws)作为领域的核心驱动力。
- GPT-4: GPT-4 Technical Report
- 作者: OpenAI
- 年份: 2023
- 核心贡献: 作为一份技术报告发布,标志着顶级大模型进入多模态(Multimodal)时代,能够同时处理文本和图像输入。报告同时强调了其在专业和学术基准测试中的卓越性能以及对安全性的高度关注。
- GPT-1: Improving Language Understanding by Generative Pre-Training
三、 替代及优化方案文献 (Alternative & Optimization Papers
这些是文中提及的、旨在解决Transformer核心缺陷(尤其是计算复杂度)的新兴架构和关键技术。
-
Mamba (状态空间模型
- 标题: Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- 作者: Albert Gu, Tri Dao
- 年份: 2023
- 核心贡献: 提出了一种选择性状态空间模型(SSM),它在保持线性计算复杂度的同时,通过引入选择机制,使其能够根据上下文动态调整,在长序列任务上达到了与Transformer相媲美甚至超越的性能,被视为Transformer架构最有力的挑战者之一。
-
RWKV (混合架构
- 标题: RWKV: Reinventing RNNs for the Transformer Era
- 作者: Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, et al.
- 年份: 2023 (发表于 EMNLP 会议)
- 核心贡献: 提出了一种新颖的混合架构,它结合了RNN的线性推理成本和Transformer的并行训练能力。RWKV可以被公式化为RNN或Transformer,从而在训练时保持高效并行,在推理时则具有RNN的低资源消耗特性。
-
FlashAttention (计算优化
- 标题: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- 作者: Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
- 年份: 2022 (发表于 NeurIPS 会议)
- 核心贡献: 这不是一种算法近似,而是一种针对硬件(GPU)的IO感知(IO-aware)优化。通过使用切片(Tiling)等技术,它显著减少了注意力计算过程中对高带宽内存(HBM)的读写次数,从而在不牺牲精度的情况下,大幅提升了注意力计算的速度并降低了显存占用。
总结
Transformer架构的深度分析报告的核心论点与结论。该报告剖析了作为现代大语言模型(LLM)基石的Transformer,并提出了一个颠覆性的核心观点:Transformer的本质并非一个初级的“思考者”,而是一台冷酷、高效的通用关系求解器” (A Universal Relational Solver,它将“理解”这门艺术,彻底降维为“计算”这门关于概率和权重的工程学。
报告构建的“关系计算机器”模型通过三大核心法则来运作:
- 结构虚无法则:将一切输入(文本、图像等)强制解构为无结构的扁平化元素。
- 关系的暴力计算法则:以承担二次方复杂度(O(n²))为代价,通过全局注意力并行计算所有元素间的关系强度。
- 意义的概率加权法则:根据计算出的关系权重,动态地为每个元素生成一个统计上最可能的“意义”。
这一第一性原理深刻解释了Transformer的双刃剑效应:一方面,它阐明了“规模定律”与“涌现能力”的来源(暴力计算的回报);另一方面,也揭示了其“幻觉”、“推理脆弱”等固有缺陷的根源(概率加权的认知边界与暴力计算的代价)。
基于此模型,报告预测Transformer的终局并非自我进化为通用人工智能(AGI),而是作为一块强大的关系协处理器或“直觉引擎”(类似系统1),被集成到一个包含逻辑规划与因果推理模块(类似系统2的、更宏大的混合认知架构中。
结论: Transformer教会了机器如何“阅读”关系,但它的历史使命是为下一代真正能够“思考”的架构铺平道路。它是一个伟大的求解器,而非思考者,标志着一个时代的巅峰,也预示着一个新时代的黎明。
如果你觉得这个系列对你有启发,别忘了点赞、收藏、关注,我们下篇见!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)