CS336笔记1-Tokenization&&Pytorch, Resource Accounting
1994年提出用于数据的压缩,适用于nlp的神经机器翻译(此前一直用的是word-based),gpt-2使用了bpe的分词方法。
本帖记录cs336学习过程的笔记,以及作业内容。
timeline:
- 10月27日开始第一课的学习~
- 11月4日完成第二次课程的学习
Part 1:Tokenization
1.背景
1994年提出用于数据的压缩,适用于nlp的神经机器翻译(此前一直用的是word-based),gpt-2使用了bpe的分词方法。
Part 2:Pytorch, Resource Accounting
Motivation:效率是训练的关键
关键指标:浮点计算量。
(暂未考虑激活函数->其取决于批量大小、序列长度)
这里公式中6倍的原理,见下文“compute accounting”的”6:gradient_flops“的推导。


Memory accounting
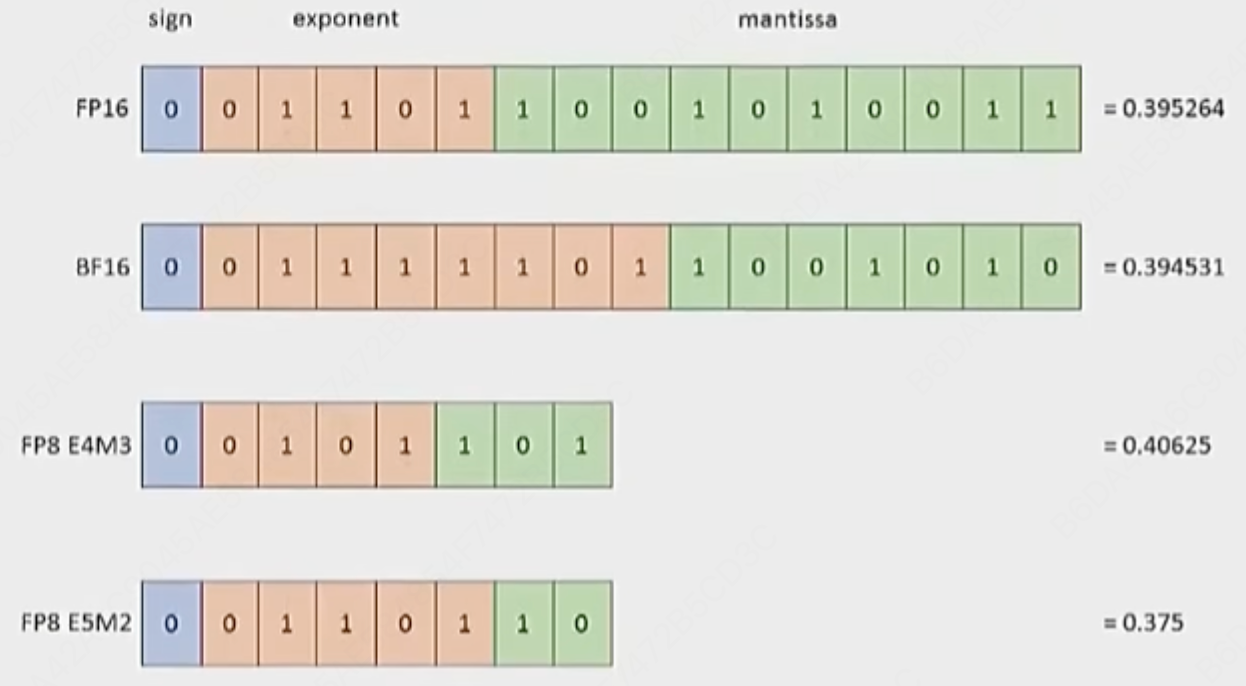
(1)float32(tensor默认)
单/全精度(float32,通常是1个符号位,8个指数位,23个小数位)。
内存占用取决于:①值的个数 ②每个数值的数据类型。
这里内存的使用量就是 元素数量 乘以 每个元素的大小(128字节 )。
(2)float16(半精度)
float16不太适合表示非常小的数字或非常大的数字。用于小模型的训练没问题,但对于大模型来说,当你有很多矩阵时,可能会遇到不稳定、下溢or上溢
Q:这里举的例子有点疑惑?为什么1e-8就会发生下溢?明明指数有5位二进制来表示,表示范围可以覆盖8?
A:
具体的讲解分析链接:
(3)bfloat16
和fp16相同的内存占用,但是和fp32相同的动态范围
精度fraction会差一些,但对于dl来说并不是太重要。
给bf16类型的变量赋值为1e-8就不会下溢。
查看不同type的动态范围和内存占用:
总的来说,bf16是通常用来计算的数据类型。但是,对于存储“优化器状态和参数”仍然float32,否则会出问题。
Q:优化器状态和主参数必须保持float32精度,主要有三个核心原因:
A:①float16的数值范围和精度都很有限,当学习率乘以梯度得到的更新量很小时,比如0.0001这个量级,用float16表示可能直接被舍入为0,导致参数根本无法更新。
②像Adam这类优化器需要维护动量和方差等状态,这些是长期累积的统计量,如果用float16存储,每次累积都会产生舍入误差,经过几千几万次迭代后误差会严重放大,最终导致训练不稳定甚至崩溃。
(4)fp8
下图展示了fp8的两种变体。h100是支持的,但上一代不支持。
综上:
一般来说,对于参数和优化器状态(这种会长期累积的东西),会采用fp32;但对于简单的矩阵乘法过程(短期,不需要长期维护的量),可以采用bf16。









Compute accounting
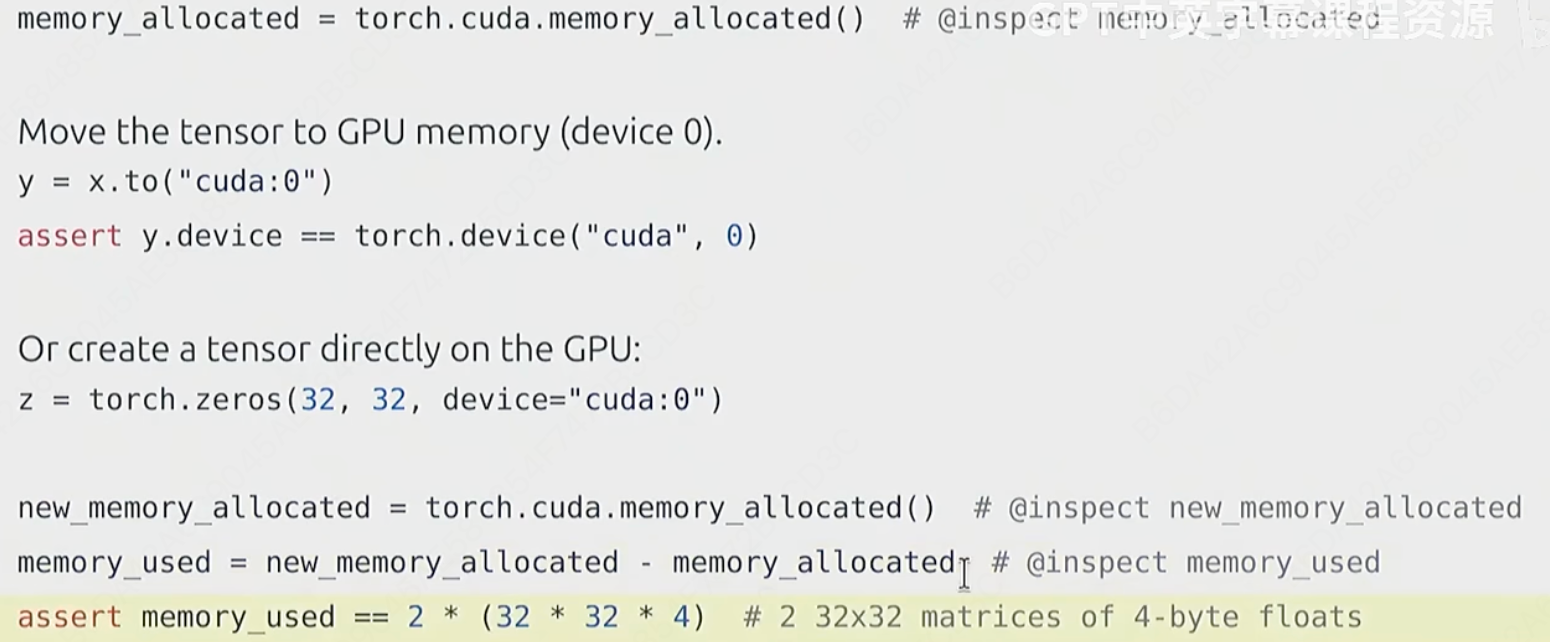
1:确保张量tensor在GPU上
习惯,经常使用assert来确保tensor的位置在gpu上(默认cpu)。
查看gpu的信息:
移动x到gpu上,查询cuda显存占用是不是多了这一个tensor的值(32*32个float32,即4byte)
2:tensor的常用操作
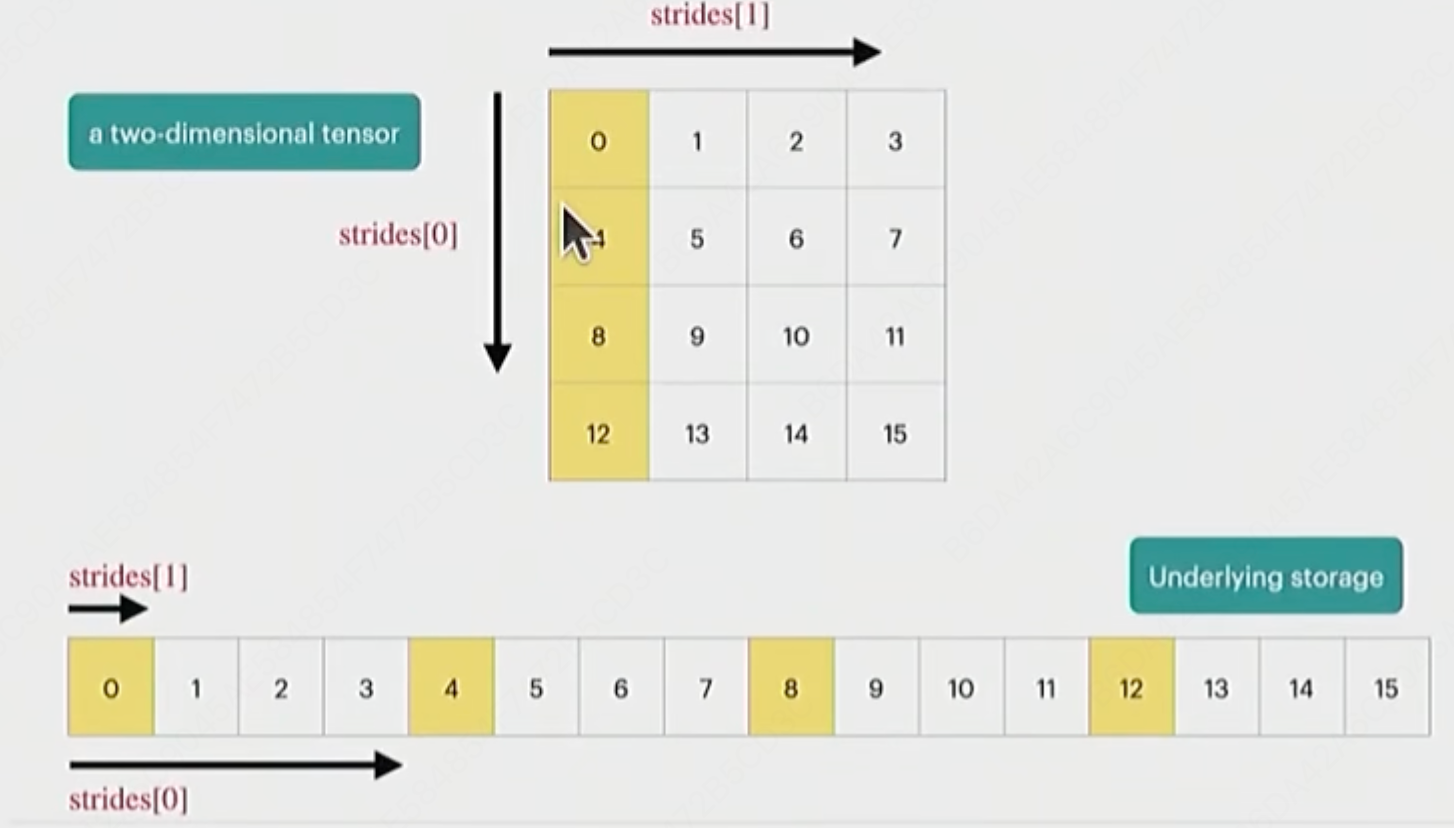
(1)tensor storage 张量的底层工作原理
dim0的维度步幅是跳一行。
(2)tensor slicing 切片
下面的操作只是创建了不同的视图(没有深拷贝)。
从列的角度考虑,也是同理。
view的视图机制也是同理。
transpose也是同理:
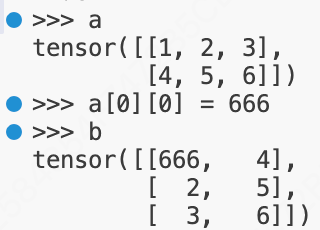
当修改数据a的内容时,b变量也会被修改。因为a和b本质上就是指向同一块内存的指针
“连续”的概念。部分操作会让张量tensor处于非连续的状态(比如转置等,会改变张量的维度顺序,但不会在内存中重新排列数据。)
非连续张量不能直接使用
view()方法来改变形状,因为view()方法要求张量在内存中是连续存储的。如果需要对非连续张量进行重塑,可以通过contiguous()方法将其转为连续张量,然后再应用view()。
使用了contiguous函数,本质上是复制了一份。view不会产生额外的内存和计算。注意:会深拷贝的函数(contiguous和reshape)
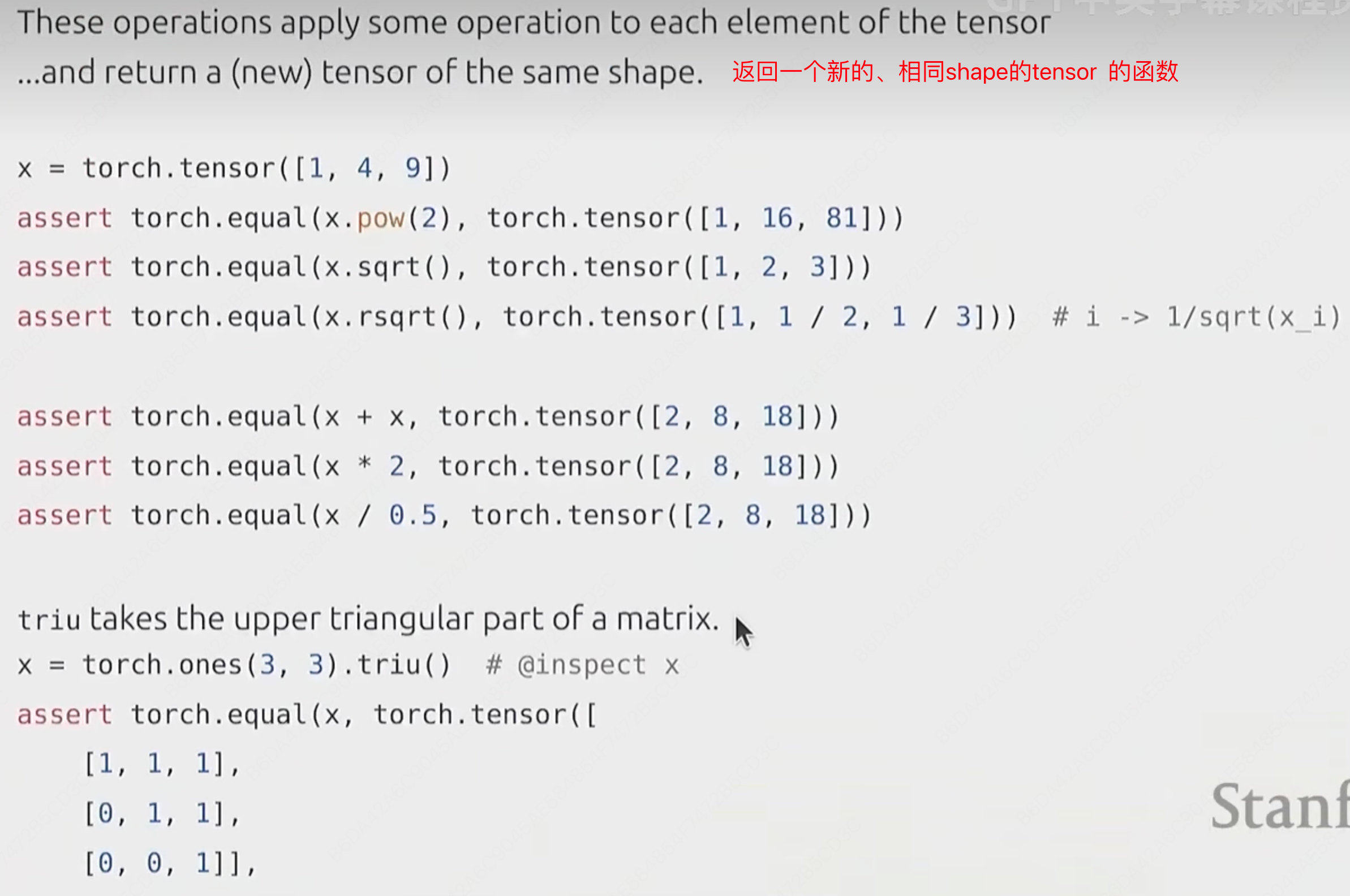
(3)tensor_elementwise
triu创建上三角矩阵(在创建因果注意力掩码时很有用)
(4)tensor_matmul
基础的矩阵乘法
3:tensor_einops
(1)einops的动机
(2)jax typing
einops的思想是为所有的维度命名,而不是依赖索引。
(3)einops_einsum
einsum基本上是一个带有良好记录的加强版矩阵乘法。
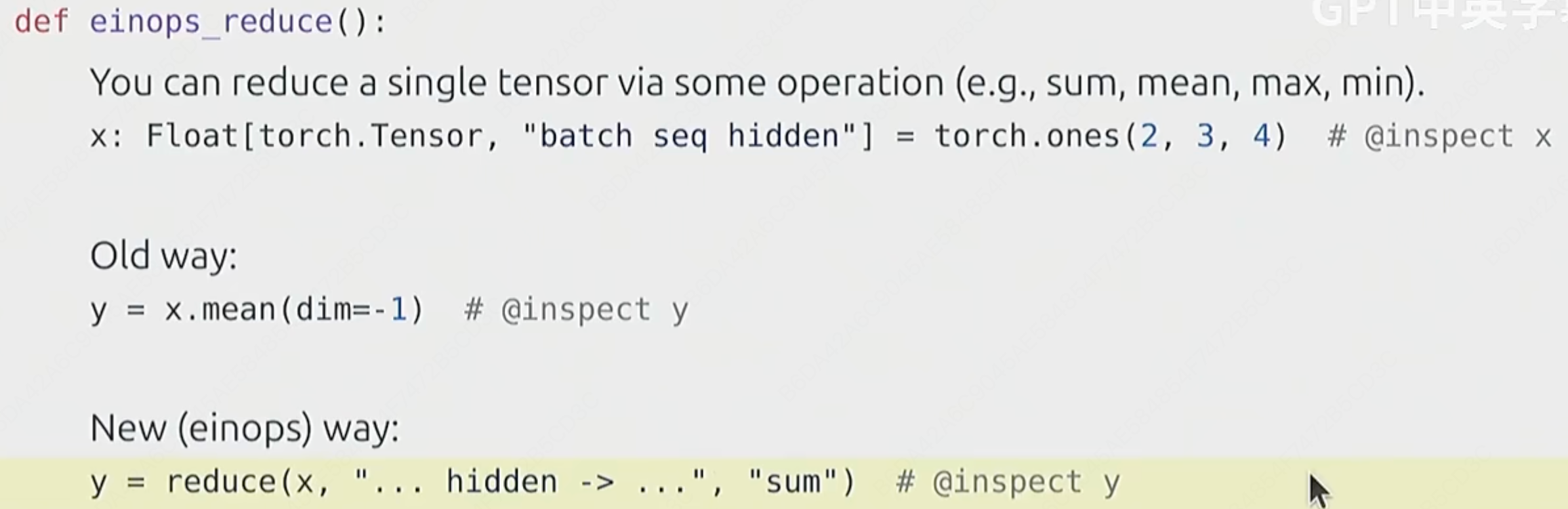
(4)einops_reduce
(5)einops_rearrange
典型的应用场景就是多头注意力机制的拼接那一块
4:tensor_operations_flops
(1)flop的含义
(2)建立对flops的直觉
8张h100在一周的计算量大约是4.788e21。
(3)Linear model
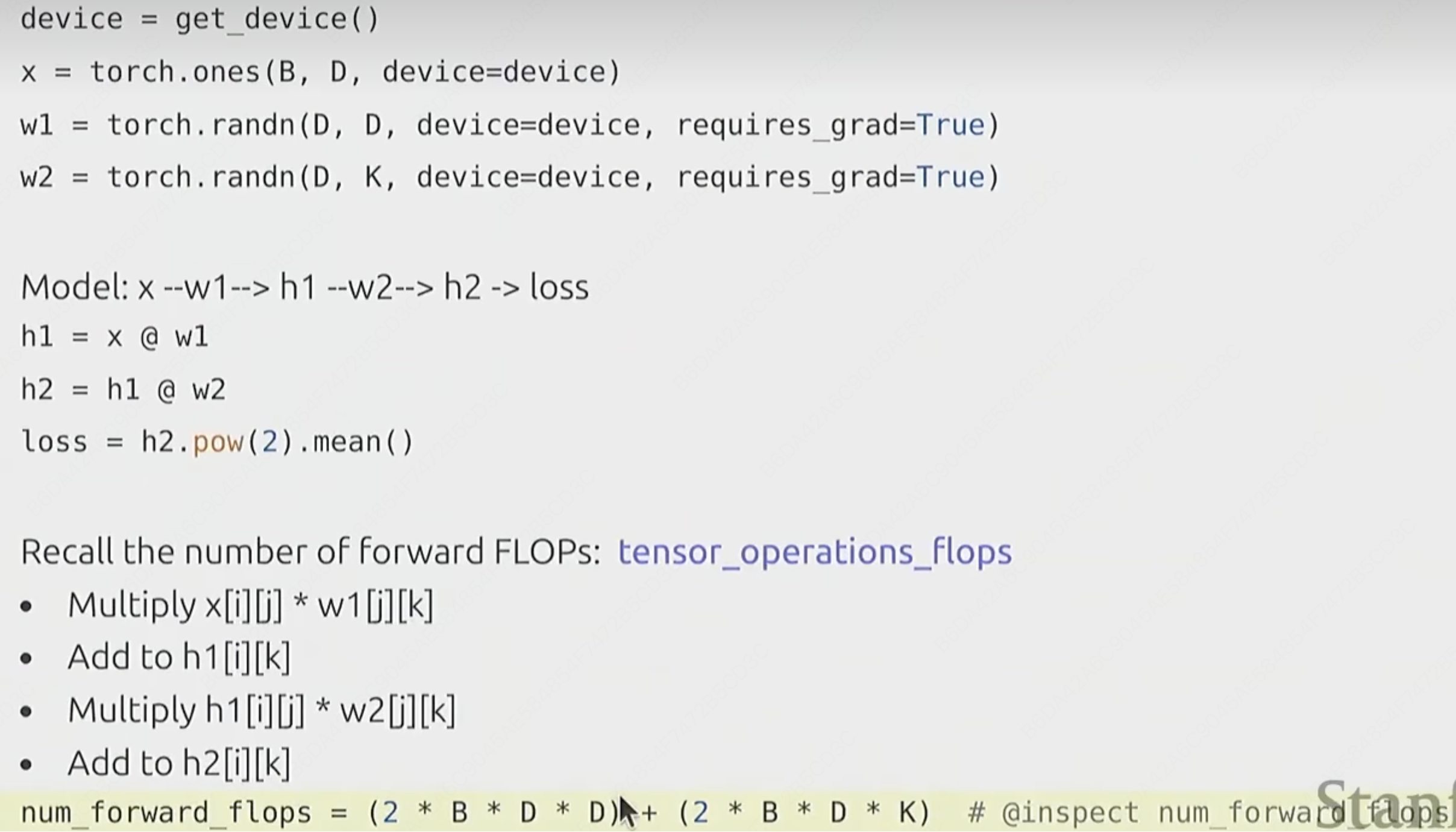
在执行矩阵乘法的时候,必须将x[i][j]和w[j][k]相乘,同时还要将总和加入到total。具体的总计算量原因参考如下:
记住这个结论,线性模型的总计算量 = 2 * B * D * K。
(4)FLOPs of other operations
尽管 Transformer 模型结构复杂,有多个层和模块(如多头注意力、残差连接、LayerNorm 等),但其绝大部分计算量(通常超过 99%)都集中在矩阵乘法上(线性层和注意力机制)。因此,使用这种基于 总令牌数 和 参数量 的简化 FLOPs 估计方法,能够快速且相对准确地估算整个模型的前向传播计算开销。
(5)Model Flops utilization(MFU)
总结:
5:gradients_basics
loss.backward()当在一个标量(如
loss)上调用.backward()时,PyTorch 会沿着计算图反向传播,并根据链式法则(Chain Rule) 计算loss相对于所有requires_grad=True的张量(即“叶子节点”)的梯度。
- 现在我们来逐个分析为什么这些
assert语句会成立:
assert loss.grad is None&&assert pred_y.grad is None
- PyTorch 的
autograd引擎在默认情况下只会在叶子节点(Leaf Tensors)上累积梯度。- 什么是叶子节点? 就是那些由用户直接创建并设置了
requires_grad=True的张量。在这个例子中,只有w是叶子节点。loss和pred_y都是计算过程中产生的中间节点(non-leaf tensors)。PyTorch 在计算完它们的梯度后,默认会立即释放这些梯度值以节省内存。因此,它们的.grad属性是None。- assert x.grad is None:PyTorch 认为
x是固定的输入数据,不是需要优化的参数,因此根本不会为它计算梯度。计算图从x这里就开始“剪枝”了。原因:
assert torch.equal(w.grad, torch.tensor([1, 2, 3]))w是我们唯一关心的叶子节点。loss.backward()的主要目的就是计算 loss对于w的偏导数,并将其累积到w.grad属性中。- 梯度推导过程:
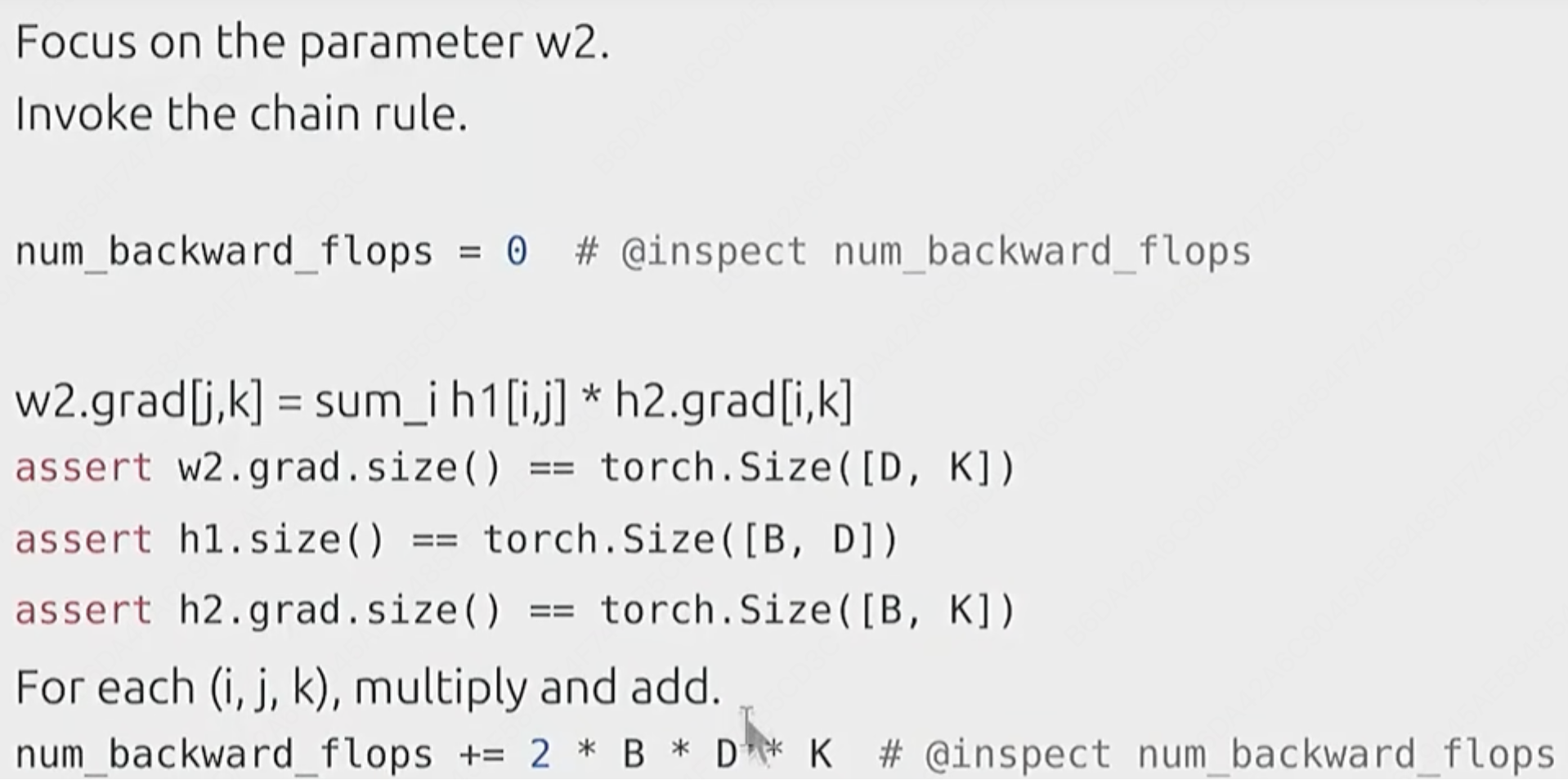
6:gradients_flops
案例:简单的两层线性网络(没有激活函数或偏置项)
前向传播
反向传播:
再结合公式:h2[i][k] = h1[i][j] * w2[j][k](求解w2的grad是通过h2传播过来的。)
总结一下:
最常用、最重要的经验法则(Rule of Thumb),用于估算 Transformer 模型单次训练步骤的总计算量(FLOPs)。这个公式 flops = 6 * B * num_parameters 是对我们之前课程中结论的直接应用:Total FLOPs = 6 * (# data points) * (# parameters)
a)
num_parameters(模型参数量,P):就是您模型(例如 GPT-2, LLaMA)中所有可训练权重的总和。例如,对于 LLaMA 7B,num_parameters≈ 7 亿。b)
6(关键的 1:2:3 比例)
总和:
2 + 4 = 6。因此,一次完整训练步骤(FWD+BWD)的总 FLOPs 大约是 6 乘以参数量,再乘以输入 token 数。
c)
B(批次大小) —— ⚠️ 这是最容易混淆的地方!这张幻灯片上的
B是一个简写,这导致了很大的歧义。
在之前的 DataLoader 笔记中,我们定义的批次是
[B, L](Batch Size*Sequence Length)。在 Transformer 中,真正的“数据点”不是一个序列,而是一个 Token。因此,
data points(数据点总数)不是B,而是批次中的 Token 总数,即B * L。这个公式 flops = 6 * B * num_parameters 是一个不严谨的简写。
严谨的、在 CS336 中(以及 OpenAI "Scaling Laws" 论文中)使用的标准公式应该是:
其中:
B=Batch Size(序列的数量)
L=Sequence Length(每条序列的长度)
num_parameters=P(模型参数量)















































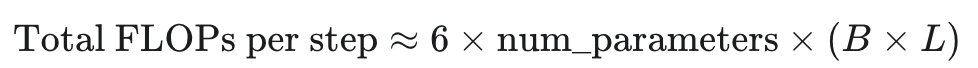
Models
1:module_parameters
初始化参数:
Q:为什么“朴素”初始化会失败?
w = torch.randn(input_dim, hidden_dim)。即从标准正态分布(均值为 0,方差为 1)中采样。考虑一个矩阵乘法output = x @ w。output中的每一个元素都是input_dim个(x的元素)与input_dim个(w的一行)的点积 (dot product)。A:
假设输入
x和权重w的方差都是 1。当您将input_dim个方差为 1 的随机变量(x_i * w_i)相加时,它们的结果(output)的方差会累积为input_dim。这将导致灾难性后果:
梯度爆炸 (Exploding Gradients): 正如讲义所说,
output的值变得非常大。在反向传播中,这些大数值会相互乘积(根据链式法则),导致梯度迅速增长到Inf(无穷大) 或NaN(Not a Number),训练瞬间崩溃。梯度消失 (Vanishing Gradients): 即使梯度不爆炸,这些巨大的
output值在通过激活函数(如tanh或GeLU)时,会立即进入“饱和区”(例如tanh的 -1 或 1)。在饱和区,函数的导数(梯度)几乎为 0,导致模型无法学习解决办法:Kaiming / Xavier 初始化
这里为什么是根号dk?利用方差的性质:var(ax) = a²* var(x)
类似的问题:为什么注意力机制的qk分母是根号dk而不是其他数字?
ans:简单来说,q和k的方差虽然是1,但是矩阵乘法qk是维度为dk的向量作点积然后累加求到一个元素的,所以方差var(qk)实际上是dk。所以目前是var(qk) = dk,我们希望最后的方差控制在1,所以我们对qk除以根号dk,此时var(qk/根号dk) = (1/sqrt(dk))² *var(qk) = (1 / dk) * dk = 1,成功达成目标。
https://blog.csdn.net/suibianshen2012/article/details/122141294
其他优化:截断正态分布初始化 (Truncated Normal Initialization)。
2:custom model
构建一个简单的模型。
占坑补充:randomness
3:data_loading
np.array: 将 Python 列表转换为 NumPy 数组。NumPy 数组是C 语言级别的、连续的内存块,没有 Python 对象的开销,速度极快。
tofile(): 这是最关键的一步。这个函数不会创建 .npy 文件(np.save才会)。
它会将 NumPy 数组中的**原始字节(Raw Bytes)**直接、原封不动地“倾倒”到一个二进制文件(
.bin文件)中。
为什么这个“原始二进制”格式是最好的?是因为它允许我们使用一项关键技术:内存映射 (Memory Mapping)。
海量数据集: 我们的 Token 序列可能非常大(例如 100GB)。我们不能(也不想)在训练开始时把 100GB 的数据全部读入内存(RAM)。
np.memmap: 在训练的数据加载器 (DataLoader) 中,我们将使用np.memmap来“打开”这个data.npy(或data.bin)文件。工作原理:
memmap会创建一个看起来像 NumPy 数组的对象,但它并没有真正加载数据。它只是在内存中创建了一个“指针”,指向磁盘上的文件。即时加载: 当我们的训练循环需要第 1,000,000 到 1,002,048 号 token(一个 batch)时,
memmap会告诉操作系统:“请只从磁盘加载这一小块数据”。好处: 这使我们能够以接近 RAM 的速度,随机访问一个比 RAM 大几百倍的数据集,而几乎不占用任何内存。
1. 核心问题:数据 > 内存
我们的训练数据集(如 LLaMA 的 2.8TB)远远大于我们机器的 RAM(例如 512GB)。
这意味着我们绝对不能使用
np.load()或np.fromfile()这种一次性加载所有数据的函数。这会导致内存溢出(OOM),使机器崩溃。2. 核心解决方案:
np.memmap(内存映射)
什么是
memmap?
data = np.memmap("data.npy", dtype=np.int32)这个函数是解决“数据 > 内存”问题的关键。
它创建了一个
data对象,这个对象看起来、用起来都像一个完整的 NumPy 数组(assert np.array_equal(data, orig_data)),但它的实际内容仍然在磁盘上。它本质上是在内存中创建了一个指向磁盘文件的**“视图”或“指针”**。“Lazy Load”(惰性加载)的含义:
memmap实现了**“惰性加载”:操作系统(OS)只会在您真正访问(切片)数组的某一部分时,才“懒洋洋”地**将磁盘上对应的那一小块数据加载到 RAM 中。3.
get_batch函数(数据加载器)
目标: 我们的模型(如 Transformer)需要以
[B, L](Batch Size, Sequence Length)形状的小批量数据进行训练。
get_batch的工作:
从巨大的
data(memmap数组)中随机选择B个起始索引(例如idx = [100, 5000])。从每个起始索引开始,切片
L个 token(例如data[100 : 100+L]和data[5000 : 5000+L])。(关键时刻!) 只有在执行这个切片操作时,
memmap才会触发 OS,真正从磁盘读取这B * L个整数。
get_batch将这些小切片堆叠 (stack) 成一个[B, L]的 PyTorch 张量,并将其发送到device(例如 GPU)。
assert x.size() == torch.Size([B, L]): 确认了我们的加载器成功地从海量数据集中,提取出了模型所需的[2, 4]形状的训练批次。总结:
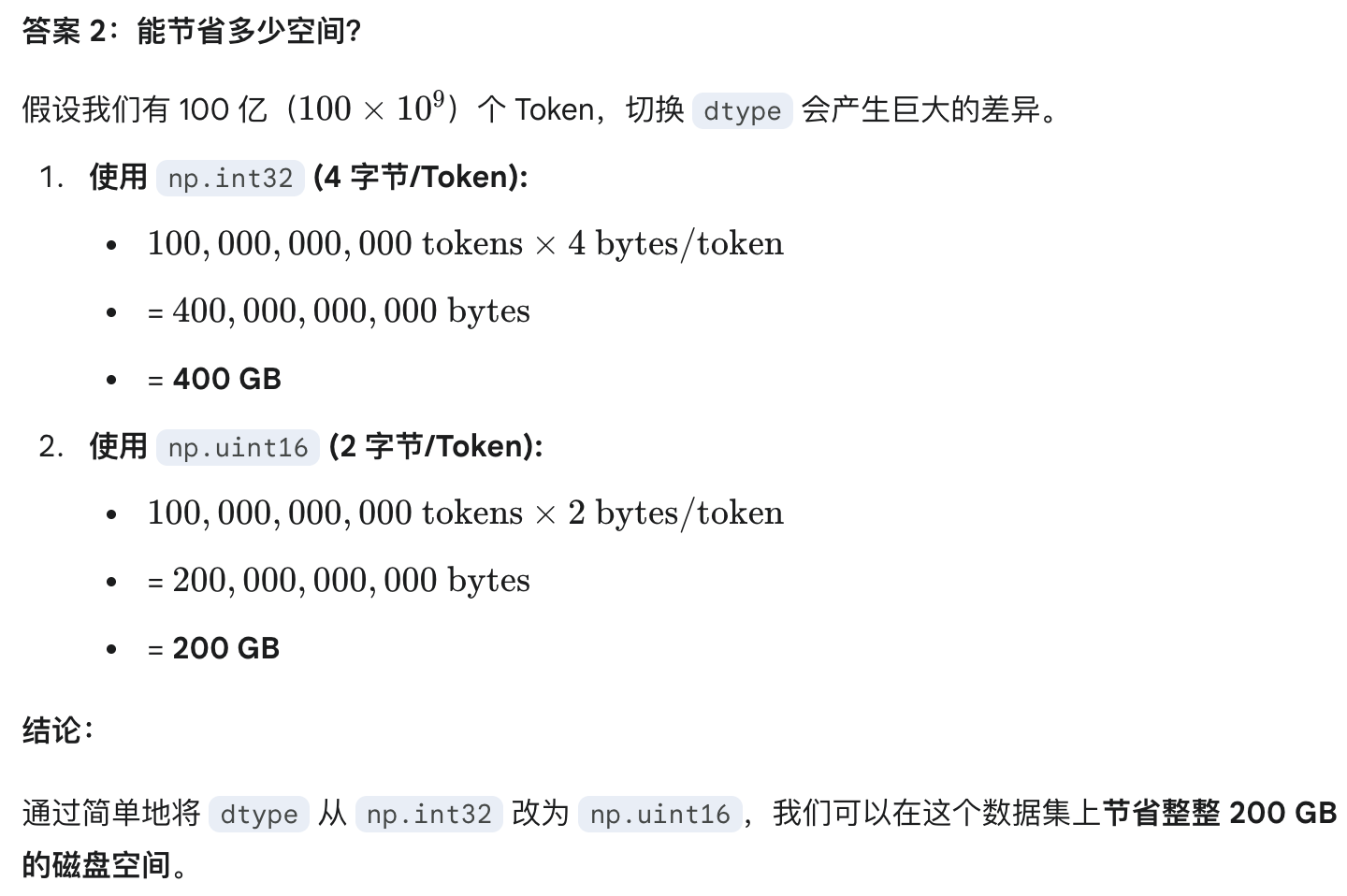
memmap是 性能基石。它允许我们用几乎为零的 RAM 占用,来随机访问一个比内存大几千倍的数据集,只在需要时(get_batch)才产生极小的磁盘 I/O 开销。思考题:在实践中,一个典型的 Tokenizer(如 GPT-2 的)的词汇表大小(
vocab_size)大约是 50,257。
为了存储 0 到 50,256 之间的整数,
np.int32是最高效的选择吗?如果我们换一个更高效的
dtype,假设我们的数据集有 100 亿个 Token,这能为我们节省多少磁盘空间?
4:optimizer
思考题: 原始的 Adam 和我们现在用的 AdamW,唯一的区别在哪里?(提示:思考 Adam 如何处理 L2 正则化,即“权重衰减 Weight Decay”)。
// 分析adagrad的实现代码。
占坑5:memory
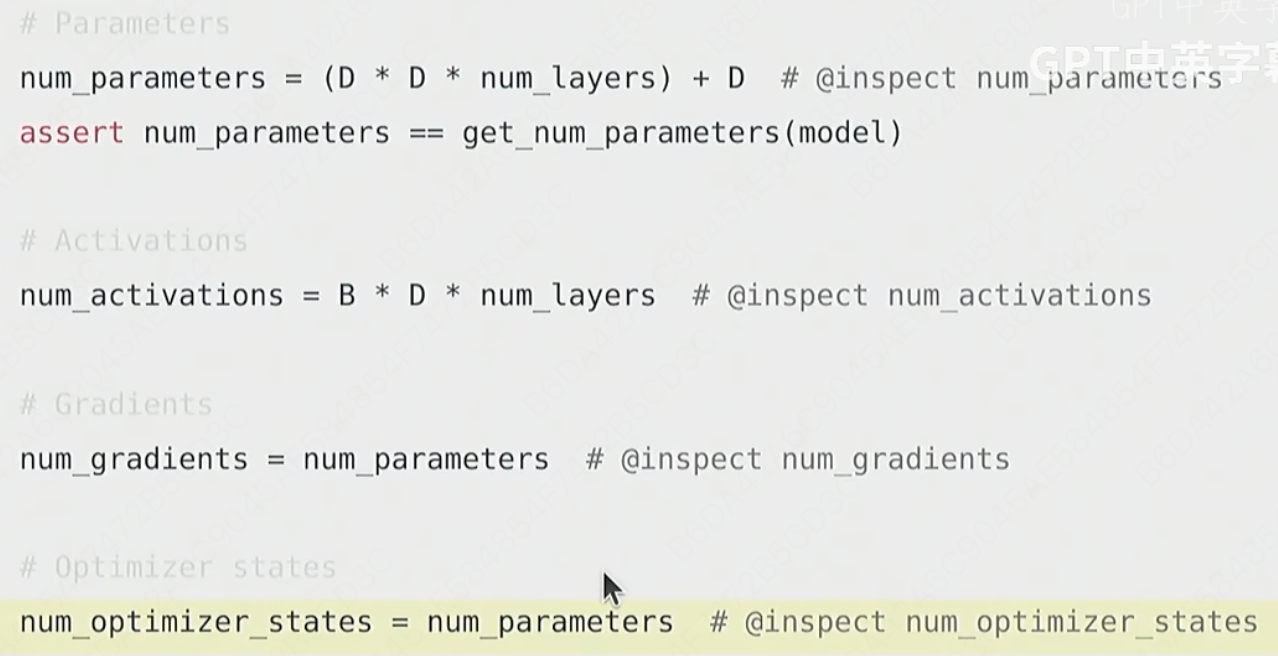
①Parameters (模型参数)
num_parameters = (D * D * num_layers) + D含义: 这是模型本身的权重(Weights)和偏置(Biases)。
它们是模型在训练过程中需要学习的东西(即
nn.Parameter)。这个公式
(D * D * num_layers) + D只是一个高度简化的示例(例如,一个有num_layers层、输入输出维度都是D的简单 MLP)。关键点:
参数占用的显存是固定不变的。它只取决于你的模型架构(深度、宽度),与批量大小
B或序列长度L无关。内存占用:
num_parameters * 4字节(假设使用 FP32 精度)。②Activations (激活)
num_activations = B * D * num_layers含义: 这是 VRAM 中最主要、最动态的开销。
“激活”是指在前向传播(Forward Pass)中计算出的所有中间结果(例如
h1,h2,attention_scores等)。为什么必须保存它们? 因为反向传播(Backward Pass)需要根据链式法则(如
W.grad = X.T @ Y.grad)使用它们来计算梯度。关键点:
B(Batch Size)在这里是关键。这个公式同样被简化了(它假设序列长度L=1)。对于 Transformer,一个更真实的估算是:
num_activations ≈ B * L * D * num_layers * (常数)。这清楚地表明,激活占用的 VRAM 与B和L成正比。这就是为什么增大B或L会导致 OOM (Out-of-Memory) 错误!③Gradients (梯度)
num_gradients = num_parameters含义:
loss.backward()的计算结果。关键点:
这是一个基本恒等式。对于模型中的每一个参数(例如
w1),Autograd 引擎都会计算出一个对应的梯度值(w1.grad)。因此,存储梯度所需的 VRAM 与存储参数所需的 VRAM 完全相同。
内存占用:
num_parameters * 4字节(假设使用 FP32 精度)。④Optimizer States (优化器状态)
num_optimizer_states = num_parameters含义: 优化器(如 Adam)为了执行其算法而需要额外存储的“历史信息”。
⚠️ 这是一个需要特别澄清的关键点!
这个公式 (即 1:1 的关系)仅适用于像 SGD with Momentum 或 RMSProp 这样的优化器,只为每个参数存储一个状态(
m动量 或v方差)。在 CS336 中,我们几乎总是使用 Adam 或 AdamW。Adam 是“集大成者”,它同时存储两个状态:
m(动量,第 1 矩估计)、v(方差,第 2 矩估计)因此,对于 Adam/AdamW:
num_optimizer_states = 2 * num_parameters内存占用:
2 * num_parameters * 4字节(假设 Adam 的m和v状态都用 FP32 存储)。总结:VRAM 总估算 (以 AdamW 为例)
Total VRAM ≈[(num_parameters * 4)](Parameters)+ [(num_parameters * 4)](Gradients)+ [(2 * num_parameters * 4)](Optimizer States)+ [(B * L * D * ... * 4)](Activations)这揭示了一个重要结论:在 FP32 下,仅“模型本身”(参数+梯度+Adam状态)的 VRAM 静态开销,就是模型参数文件(
model.pth)大小的至少 4 倍!(
model.pth只存了num_parameters,而训练需要Params + Grads + Adam_m + Adam_v)思考题:当切换到混合精度训练时:
这 4 个组件(Parameters, Activations, Gradients, Optimizer States)中,哪些可以(或必须)被存储为 FP16 (2 字节) 来节省 VRAM?
哪些组件通常必须保持为 FP32 (4 字节) 来保证训练的稳定性和准确性?
答案:哪些可以/必须降为 FP16 (2 字节) 来节省 VRAM?
①Activations (激活):
这是最大的 VRAM 节省来源。在前向传播(Forward Pass)中,
torch.autocast上下文管理器会自动将您的nn.Linear、@等操作切换到 FP16 (或 BF16) 精度。因此,所有计算出的中间结果(激活)都会以 FP16 (2 字节) 格式被存储下来,等待反向传播使用。VRAM 节省:
B * L * D * ...这部分内存开销直接减半。②Gradients (梯度):
这是第二大 VRAM 节省来源。在反向传播(Backward Pass)中,当 Autograd 引擎使用 FP16 的激活和 FP16 的权重(工作副本)来计算梯度时,它自然会产生FP16 格式的梯度。因此,
num_gradients(即num_parameters)这部分内存开销也直接减半。答案:哪些必须保持为 FP32 (4 字节) 来保证稳定性?
①Optimizer States (优化器状态):
这是绝对的、最关键的必须保持 FP32 的组件。
以 AdamW 为例,
m(动量)和v(方差)状态是“累加器”。它们在数千个步骤中不断累积(平均)微小的梯度信息。为什么 FP16 会失败? FP16 的精度(尾数位)非常低。当一个梯度更新值 $g$ 非常小(例如 1e-5)时,它在 FP16 中可能会被“舍入”为 0(称为Underflow,下溢)。
灾难性后果:如果 m和v状态是 FP16,它们将无法累积这些微小的更新,导致优化器完全失效,模型无法收敛。因此,
m和v必须保持在 FP32 (4 字节) 以维持足够的精度。② Parameters (模型参数) —— “主副本”
混合精度训练会为您的参数维护两个副本:
1)FP32 主副本 (Master Copy): 这是Optimizer唯一关心的副本。它存储在 FP32 中,以确保可以接收并累积那些来自 FP32 优化器状态的微小、精确的更新。2)FP16 工作副本 (Working Copy): 这是一个临时的、用于计算的副本。在每次前向传播开始时,AMP 会自动将 FP32 主副本“转换”为一个 FP16 副本。这个 2 字节的副本随后被用于所有的 Matmul 运算(以利用 Tensor Core 的速度),并产生 FP16 的激活和梯度。结论: 尽管我们在计算中使用了 FP16 的“工作副本”,但为了训练的稳定性,那份“主参数(以及 Adam 状态)始终必须是 FP32 (4 字节)。
思考题:为什么我们需要激活值?
答案:因为在反向传播的时候,比如说,第一层的梯度依赖于激活值。当然也可以不存储这些激活值,在需要用到的时候,重新计算。这就是”激活检查点技术“。后面的课程会讲解。
6:train loop
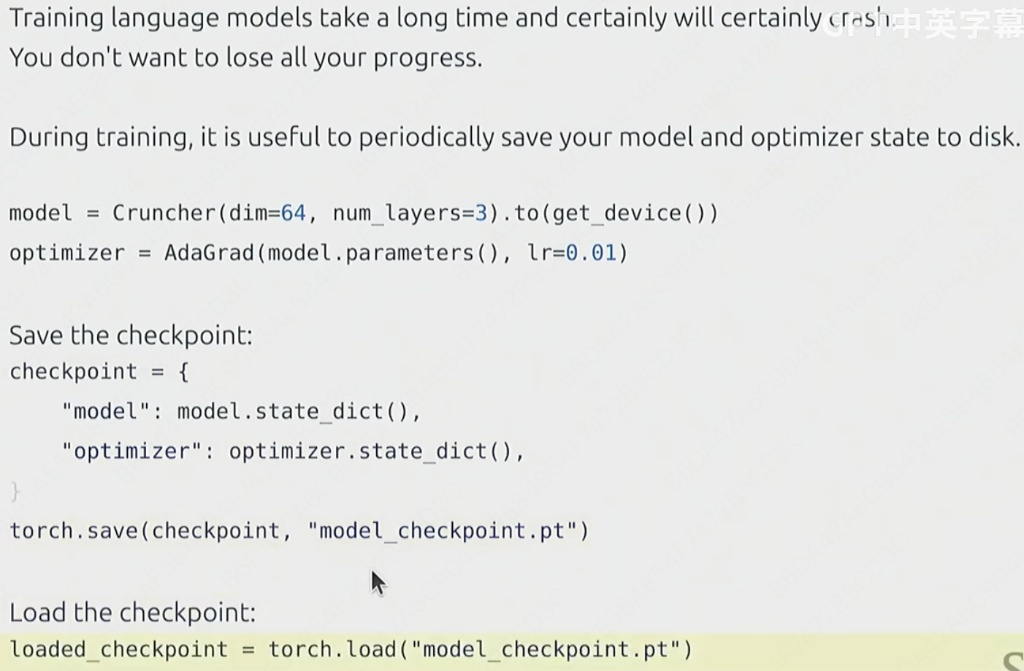
train_loop代码占坑7:checkpointing
# 1. 重新创建模型和优化器 model = Crunched(...) optimizer = AdaGrad(model.parameters(), ...) # 2. 从磁盘加载字典 loaded_checkpoint = torch.load("model_checkpoint.pt") # 3. 将状态应用回模型和优化器 model.load_state_dict(loaded_checkpoint['model']) optimizer.load_state_dict(loaded_checkpoint['optimizer']) # 4. (可选) 将模型移到 GPU model.to(get_device()) # 5. 现在可以安全地继续训练了... # train_loop(...)思考题:假设我们正在运行一个带有“学习率衰减计划”(LR Scheduler)(例如,余弦衰减)的训练,该计划要求在第 500,000 步时将学习率降至 0。
如果我们只恢复了
model和optimizer,当训练在第 400,000 步崩溃并重启时,会发生什么?为了实现“完美”的恢复,我们的checkpoint字典中还应该保存哪些其他关键的“元数据”(Metadata)?答案:“完美”的 Checkpoint 必须包含什么?
为了实现“完美”的、无缝的恢复(即 Loss 曲线完全接得上,训练动态不变),
checkpoint字典中至少还应该包含以下元数据:
'scheduler': scheduler.state_dict()
(必须) 这和优化器一样重要。PyTorch 的
scheduler也有state_dict(),它会保存其内部的_step_count(步数计数器)。恢复它,scheduler就会准确地知道“哦,我现在在第 400,001 步”,并计算出正确的(非常低的)学习率。
'step': 400000(或'epoch': ...)
(必须) 您的训练循环本身也需要知道它在哪里。
您需要保存当前的全局步数(global step)。
为什么?
日志记录: 否则您的日志(TensorBoard/W&B)会从 step 0 重新开始,曲线就“断”了。
DDP(分布式训练): 分布式采样器(Sampler)需要
sampler.set_epoch(epoch)来确保 shuffle 的随机性,您必须恢复epoch。停止条件: 您的
for循环需要知道它应该从 400,001 步开始,而不是从 0 开始,否则您会多训练 400,000 步。
'best_val_loss': 0.123(或 'best_accuracy')
(强烈推荐) 您的训练脚本通常会跟踪“迄今为止最好的验证集损失”,并据此保存一个
best_model.pt。如果您不保存这个值,重启后best_val_loss可能会被重置为float('inf')。如果重启后的 Loss(因为各种抖动)暂时高于 0.123,您可能会错误地覆盖掉您真正最好的 Checkpoint。
'config': model_config_dict
(高级实践) 保存用于启动此次训练的完整配置(例如
d_model,n_layers,lr等)。为什么? 这可以防止一个“致命”的错误:您在重启脚本前,不小心修改了
n_layers = 13(原来是 12)。如果您不保存config,load_state_dict会因为“键不匹配”而直接崩溃。通过在恢复时首先加载config,您可以确保您创建了与 Checkpoint 完全相同架构的模型。总结: 一个“完美”的 Checkpoint 应该是整个训练状态的快照,而不仅仅是模型权重。
Python# 一个更健壮的 Checkpoint checkpoint = { 'model': model.state_dict(), 'optimizer': optimizer.state_dict(), 'scheduler': scheduler.state_dict(), # 必须 'step': global_step_count, # 必须 'best_val_loss': best_val_loss, # 推荐 'config': model_args_dict, # 推荐 }8:mixed_precision_training
通常我们会使用更合理的浮点数格式来训练模型,但是在inference阶段,可以使用非常激进的量化手段提速。
















中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)