从零开始写RAG - OneRAG (三)
这里我想重点强调一部分,也就是这里对注册表不存在的文件后缀该怎么处理。这里我的想法是用LLM根据将该模块下的所有代码作为 Prompt, 来自动化生成代码,也就是用Agent的思想来自动化自我迭代代码。这一部分主要是考虑文件在一个文件夹里面,这个场景下需要程序自动化检索目录下所有的待向量化的文件。在这里,我把需要向量化的文件分为[文本]文件与[图像文件]。在文本的基础上,其实需要考虑的最多的是图像
OneRAG系列 [求Star ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐]
OneRAG, Github传送链接:https://github.com/Hlufies/OneRAG.git
从零开始写RAG - OneRAG (三)
忙了两周的实验室事情,今天终于有时间更新demo。
更新的几个功能:
-
递归处理数据
-
多模态数据处理
递归处理数据
1. 自动化处理本地知识库
这一部分主要是考虑文件在一个文件夹里面,这个场景下需要程序自动化检索目录下所有的待向量化的文件。在这里,我把需要向量化的文件分为[文本]文件与[图像文件]。
def _get_data_processor(self, file_path: str) -> List:
# auto load processor by suffix
if os.path.isdir(file_path) :
results = []
for filename in os.listdir(file_path):
if filename.startswith('.'):
continue
full_path = os.path.join(file_path, filename)
try:
results += self._get_data_processor(full_path)
except ValueError as e:
print(f"Skipped {full_path}: {str(e)}")
continue
return results
else:
ext = Path(file_path).suffix.lower()
loader_mapping = LOADER_MAPPING.get(ext)
loader_mapping_counter = 0
while loader_mapping is None and loader_mapping_counter < 10:
# # start LLMs' Agent
loader_mapping_counter += 1
return []
processor, loader_args = loader_mapping
# 返回处理后的文件 + 后缀用来表示是图像还是文本
return [(processor(**loader_args).process(file_path), file_path.split('.')[-1])]同时,为了支持自动化加载不同数据,所以我们需要再注册表面加入一点信息
LOADER_MAPPING = {
".pdf": (PdfProcessor, {}),
".txt": (TxtProcessor, {"encoding": "utf8"}),
".jpg": (ImgProcessor, {}),
".jpeg": (ImgProcessor, {}),
".png": (ImgProcessor, {}),
}这里我想重点强调一部分,也就是这里对注册表不存在的文件后缀该怎么处理。这里我的想法是用LLM根据将该模块下的所有代码作为 Prompt, 来自动化生成代码,也就是用Agent的思想来自动化自我迭代代码。目前还在测试中。
while loader_mapping is None and loader_mapping_counter < 10:
# # start LLMs' Agent
loader_mapping_counter += 1
return [] 2. 增加metadata
在做rag的时候,一些meta data非常重要。在我的理解里面,meta信息可以用两部分来做,第一就是做hard search,第二就是做soft search。做法如下:
- hard search就是在做检索的时候,首先根据关键词和meta信息做比对,如果匹配就加入候选。
- soft search就是将meta信息加入chunk块里一起被向量化。
在做检索的时候,可以考虑给这两步同时进行,且给不同的权重(还没做~)。
class PdfProcessor(DataProcessor):
def process(self, file_path: str) -> Union[str, List[str], List[Document]]:
# rand_num = random.randint(1, 3)
rand_num = 1
try:
if rand_num == 1:
loader = PyPDFLoader(file_path)
documents = [doc.page_content for doc in tqdm(loader.load())]
text = ''
for document in documents:
text += clean_text(document)
return text
elif rand_num == 2:
def get_pdf_metadata(file_path):
reader = PdfReader(file_path)
metadata = reader.metadata
return {k : v for k, v in metadata.items() if v != ''}
metadata = get_pdf_metadata(file_path)
documents = [Document(page_content=doc["text"], metadata=metadata) for doc in tqdm(loader.load())]
return documents
else:
loader = PyPDFLoader(file_path)
documents = [doc["text"] for doc in tqdm(loader.load())]
return documents
except Exception as e:
raise ValueError(f"PdfProcessor error: {e}")多模态数据处理
在文本的基础上,其实需要考虑的最多的是图像。我这里主要实现了一个基于BLIP的检索实例
1. Indexer
def index(self, file_path: str) -> List:
datas = self._get_data_processor(file_path)
chunks = []
images = []
# 这里主要是为了区分文本和图像
for (data, type) in datas:
if type in ['jpg', 'jpeg', 'png']:
images.append(data)
else:
chunks += self.Chunker.chunk(data)
return self.DocEmbedder.embed(chunks), chunks, self.ImgEmbedder.embed(images), images,
2. 在DataProcessor上加入图像处理模块。
class ImgProcessor(DataProcessor):
def process(self, file_path: str):
return Image.open(file_path)
2. ImgEmbedder
def _get_Embedder(self, config: dict) -> Embedder:
docEmbedder_config = config.get("docEmbedder", {})
imgEmbedder_config = config.get("imgEmbedder", {})
docEmbedder_type = docEmbedder_config.get("type", "BAAIEmbedder")
docParams = docEmbedder_config.get("params", {})
docEmbedder = EMBEDDER_MAPPING.get(docEmbedder_type)
if docEmbedder is None:
raise ValueError(f"Indexer_get_Embedder -> Unknown embedder type: {docEmbedder_type}")
imgEmbedder_type = imgEmbedder_config.get("type", "")
imgParams = imgEmbedder_config.get("params", {})
imgEmbedder = EMBEDDER_MAPPING.get(imgEmbedder_type)
if imgEmbedder is None:
raise ValueError(f"Indexer_get_Embedder -> Unknown embedder type: {imgEmbedder_type}")
# 实例化
return docEmbedder(**docParams), imgEmbedder(**imgParams)3. BLIPEmbedder
class BLIPEmbedder(Embedder):
def __init__(self, model_name="blip2-opt-2.7b"):
super().__init__()
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.processor = AutoProcessor.from_pretrained(model_name)
self.model = Blip2ForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16, # 半精度节省显存
device_map="auto" # 自动分配设备(CPU/GPU)
)
def embed(self, imgs):
embedder = []
for img in imgs:
img = self.processor(images=img, return_tensors="pt").to(self.device, torch.float16)
with torch.no_grad():
embedding = self.model.vision_model(**img)[:, 0, :].cpu().numpy()
embedder.append(embedding)
embedder = np.array(embedder)
dimension = embedder.shape[1]
index = faiss.IndexFlatIP(dimension)
index.add(embedder)
return index
4. 添加Config
{
"chunker": {
"type": "SemanticNLTKChunker",
"params": {
"chunk_size": 512,
"chunk_overlap" : 64,
"language" : "english",
"use_jieba" : false
}
},
"embedder": {
"docEmbedder" : {
"type": "BAAIEmbedder",
"params": {"model_name": "xxx/bge-small-zh-v1.5"}
},
"imgEmbedder" : {
"type": "Salesforce/blip2-opt-2.7b",
"params": {"model_name": "Salesforce/blip2-opt-2.7b"}
}
},
"retriever": {
"type": "CosinRetriever",
"params": {}
},
"generator": {
"type": "DeepseekOllamaGenerator",
"params": {}
}
}
这里提供一个小技巧,即使从huggingface下载模型到本地,可以用镜像+指定路径
export OLLAMA_MODELS=xxx # ollama models
export OLLAHF_ENDPOINT=https://hf-mirror.com # 镜像
export HF_HOME=xxx # huggingface
export TRANSFORMERS_CACHE=xxx # huggingface
BLIP
BLIP是一个多模态模型,可以进行多模态QA问答。这里写一个简单的用法。
1. BLIP2问答-多模态输入
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
from PIL import Image
# 加载模型和处理器
device = "cuda:0"
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16, # 半精度节省显存
device_map=device # 自动分配设备(CPU/GPU)
)
# 图像和文本输入
image = Image.open("/newdata/HJQ/Cultural_Tourism_Program/RAGDemo/OneRAG/Tutorial/NativeRag/dataset/imgs/R0000019.png")
question = "Question: What is the cat doing? Answer:"
# 处理并生成回答
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
out = model.generate(**inputs, max_new_tokens=50)
answer = processor.decode(out[0], skip_special_tokens=True)
print("多模态问答结果[输入图像+文本]:")
print(answer)
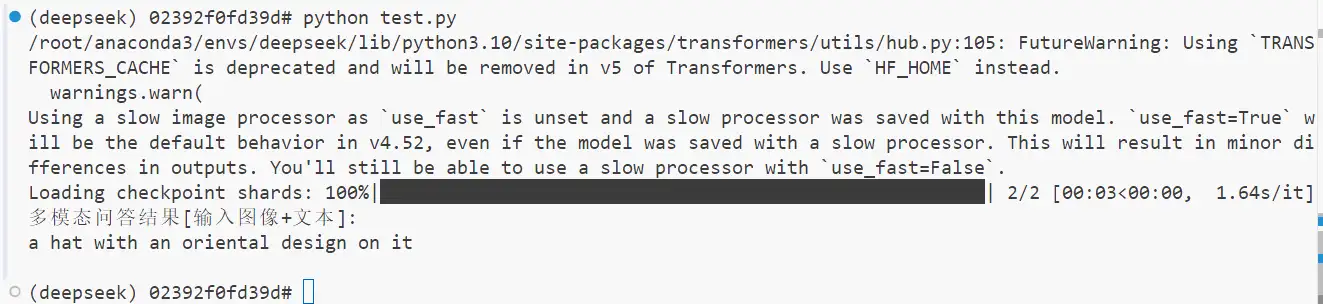
BLIP2问答-多模态输入
2. BLIP2特征抽取
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
from PIL import Image
device = "cuda:0"
# 加载模型和处理器
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16,
device_map=device
).eval() # 设置为评估模式
# 图像预处理
image = Image.open("xxx.png")
inputs = processor(images=image, return_tensors="pt").to(model.device, torch.float16)
# 提取图像特征
with torch.no_grad():
# 通过视觉编码器获取特征
vision_outputs = model.vision_model(**inputs)
image_embeds = vision_outputs.last_hidden_state
print(image_embeds.shape)
# 池化处理(示例:取CLS令牌)
image_features = image_embeds[:, 0, :].cpu().numpy()
print("图像特征维度:", image_features.shape) # 输出示例: (1, 1408)

BLIP2做特征抽取

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)