《红楼梦RAG问答系统》:一次传统文学与AI技术的融合实验
在和鲸社区,创作者 @Blues 分享了一个极具想象力的项目《红楼梦RAG问答系统》。它不是简单的代码演示,而是一次“传统文化 × 人工智能”的结合实践:
通过检索增强生成(RAG)技术,这个系统能像一位《红楼梦》研究专家一样,回答你提出的问题。无论是人物关系、情节梳理,还是书中的细节描写,都能即时生成答案。
💻系统预览体验地址:https://readrag.streamlit.app/
红楼梦rag问答系统
10s效果演示👆
用户只需输入问题,就能得到 AI 生成的解答,还能查看答案来源,保证可追溯性。这种“边问边学”的交互体验,本身也体现了 RAG 的核心优势:答案是基于真实文本的检索与推理。
fork项目:https://www.heywhale.com/u/1dc0a7(复制至浏览器打开)
推荐理由
这个项目是一次把古典文学与现代AI融合的精彩尝试,验证了 RAG 技术在 “知识型文本”→“智能问答” 转换上的可行性。从学习者的角度,这个项目的价值主要体现在三点:
-
完整的RAG框架实践:包括文档加载、分词、向量化、检索、Prompt设计、API调用,几乎涵盖了RAG的全部关键环节。
-
中文场景下的优化思路:比如jieba分词、停用词过滤、中文标点处理,这些都是中文NLP开发不可回避的问题。
-
代码可读性强:采用类的方式封装,注重依赖注入、路径抽象、组件分离,具备良好的可维护性和扩展性。
对于想学习如何从零搭建一个RAG智能问答系统的同学,这个项目比看原理介绍更直观,更具操作性。
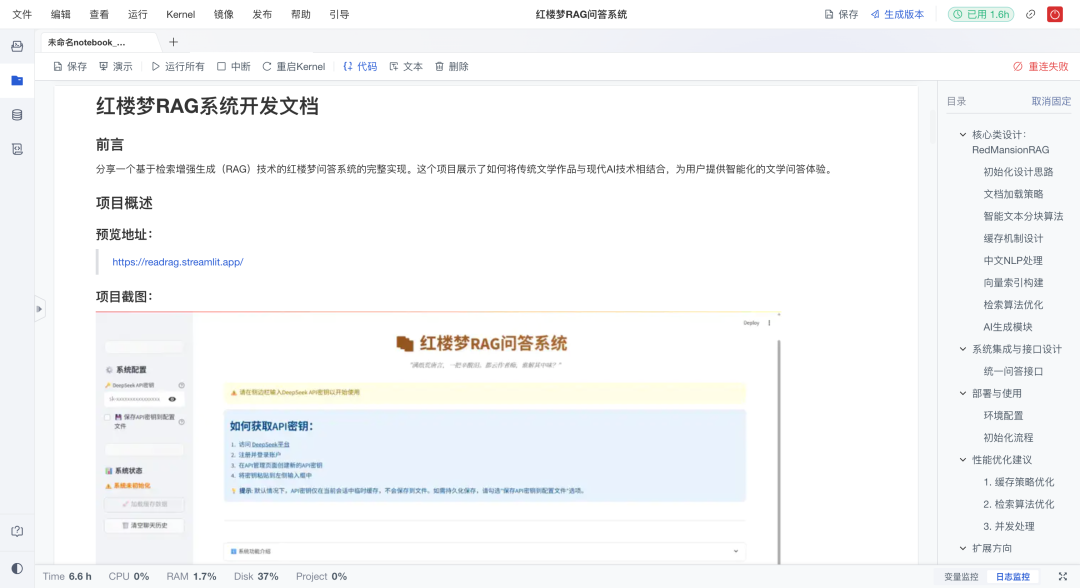
技术路线一览
系统的实现思路很清晰,整体流程是:用户问题 → 文本预处理 → 向量化 → 相似度检索 → 上下文构建 → AI生成答案。
-
核心框架:Python 3.11
-
模型调用:DeepSeek API
-
向量化:TF-IDF(平衡部署成本与效果)
-
分词:jieba(结合停用词与标点处理)
-
缓存:pickle序列化(避免重复计算,提高性能)
-
架构核心类:
RedMansionRAG
这里有几个亮点:
-
文本分块算法:不是简单按长度切割,而是按语义边界(标点符号)来保持语义完整。
-
缓存策略:同时缓存分词结果与向量索引,避免每次重复运算,在大规模文档上能显著提速。
-
检索优化:设定相似度阈值,先过滤无效结果,再排序,提高效率。
-
Prompt工程:在生成环节,AI 会被明确设定为“红楼梦专家”,并按照严格格式返回答案,保证专业性与一致性。
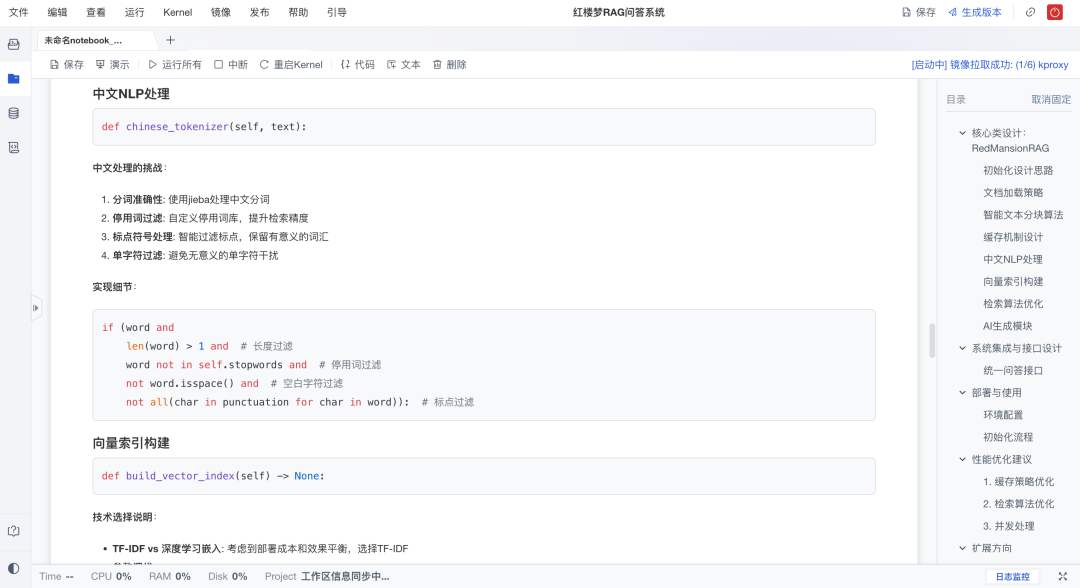
从可用性到可扩展性
除了功能实现,项目还提供了大量可扩展的思路:
-
性能优化:建议未来引入Faiss向量检索库、异步并发、Redis缓存等手段。
-
多模态拓展:不仅限于文字,未来可扩展到人物关系图谱、剧情时间线,甚至图像与音频问答。
-
个性化推荐:通过用户兴趣建模,实现更贴近用户的问答与知识推荐。
这些扩展方向,实际上为中文RAG应用提供了一个可迁移的范式。无论未来你要做的是企业知识库,还是教育问答系统,都能从中找到借鉴价值。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 6
6 0
0- 0


 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)