AI视觉大模型学习笔记
学习路线大模型演进路线:视觉大模型趋势特征基于前置任务学习基于对比学习基于掩码重建学习核心驱动人为设计的代理任务区分正负样本对根据上下文重建被掩码的数据主要目标解决特定代理任务拉近正样本,推远负样本最小化重建误差关键操作预测伪标签计算对比损失 (InfoNCE 等)掩码输入,预测被掩部分信息利用任务定义所需的信息样本间(对)的相似/不相似关系数据内部的上下文依赖关系优点设计灵活,直观表示判别性强,
学习笔记来源于B站课程:https://www.bilibili.com/video/BV1hwLEzZEnS
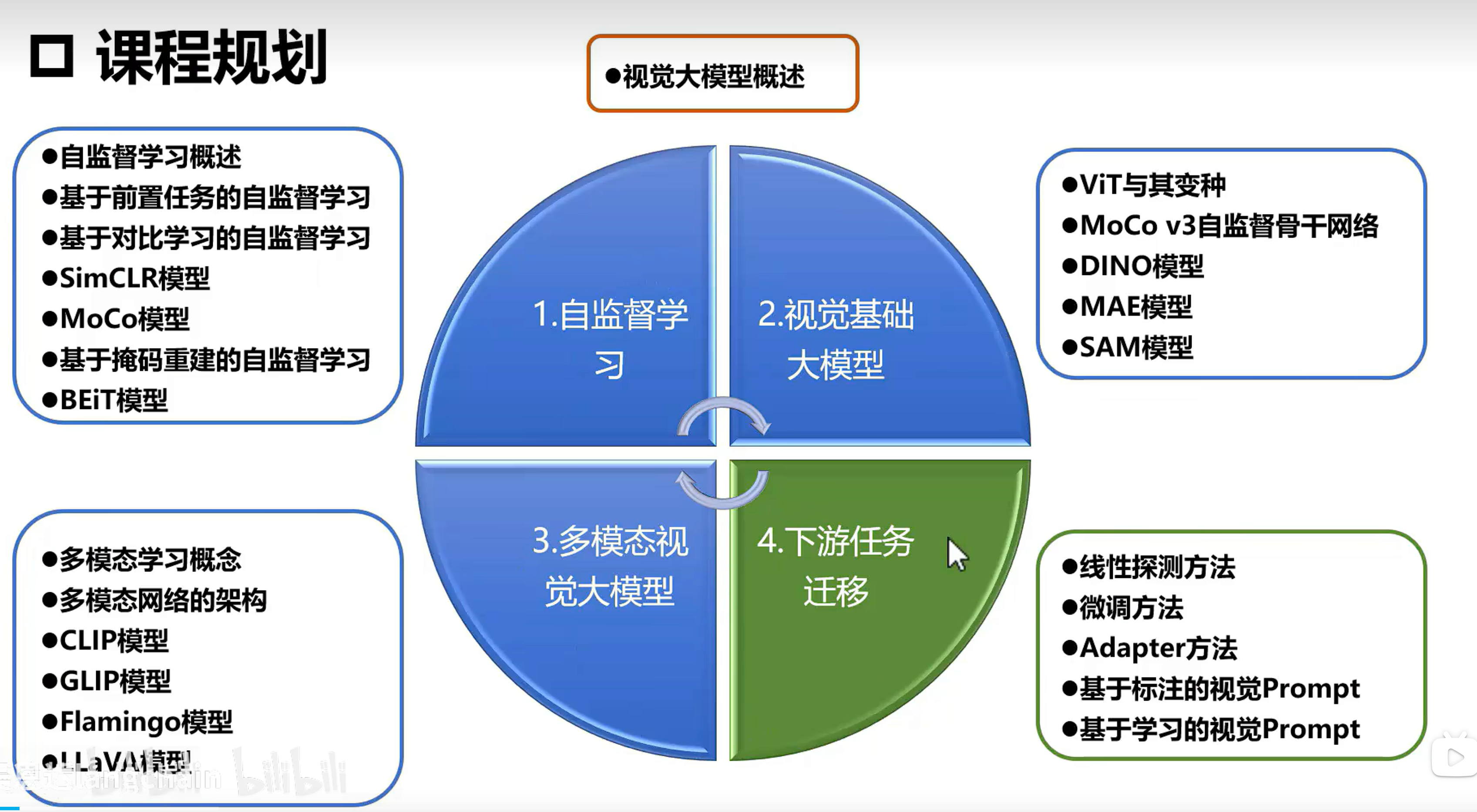
1. 概述
学习路线
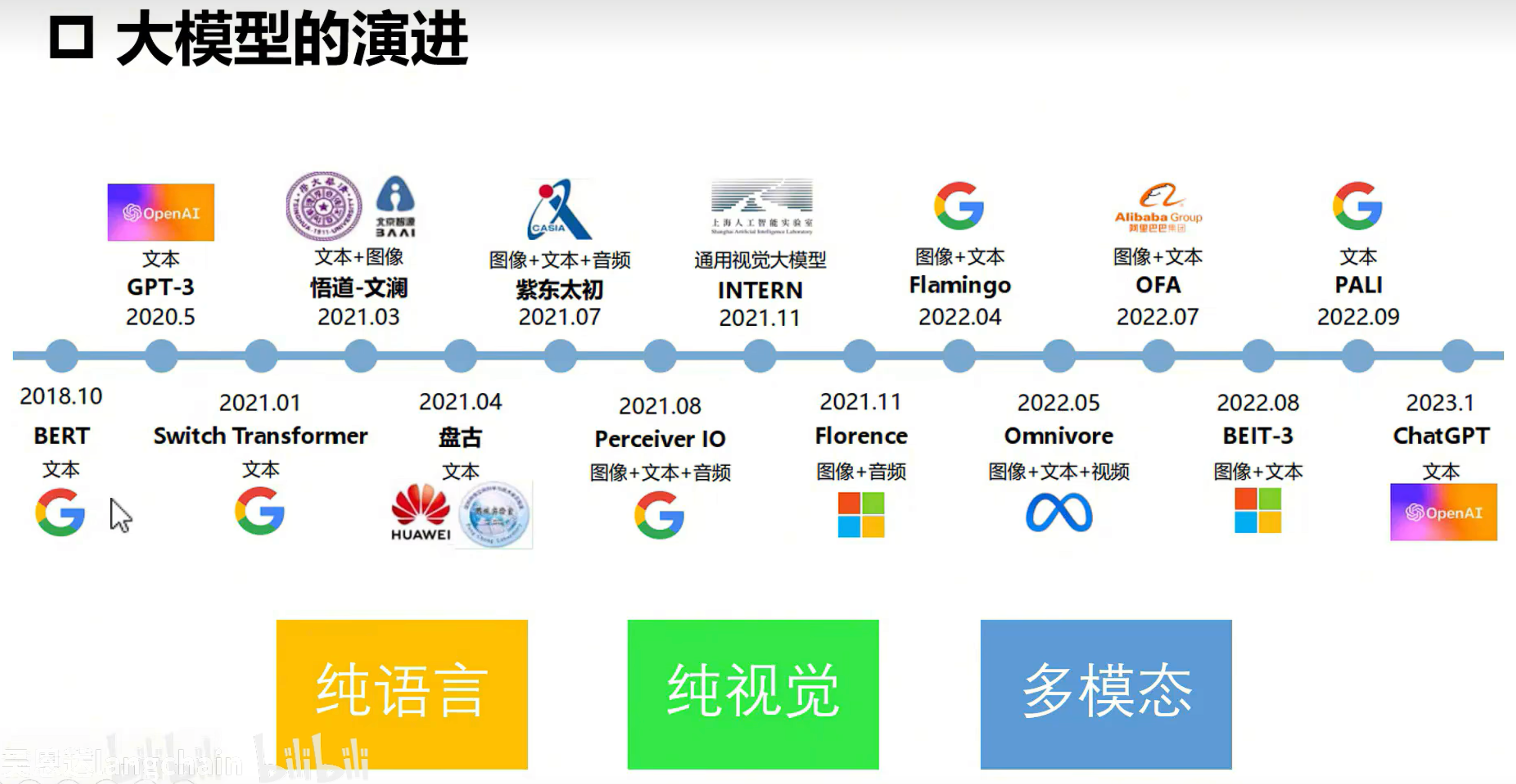
大模型演进路线:
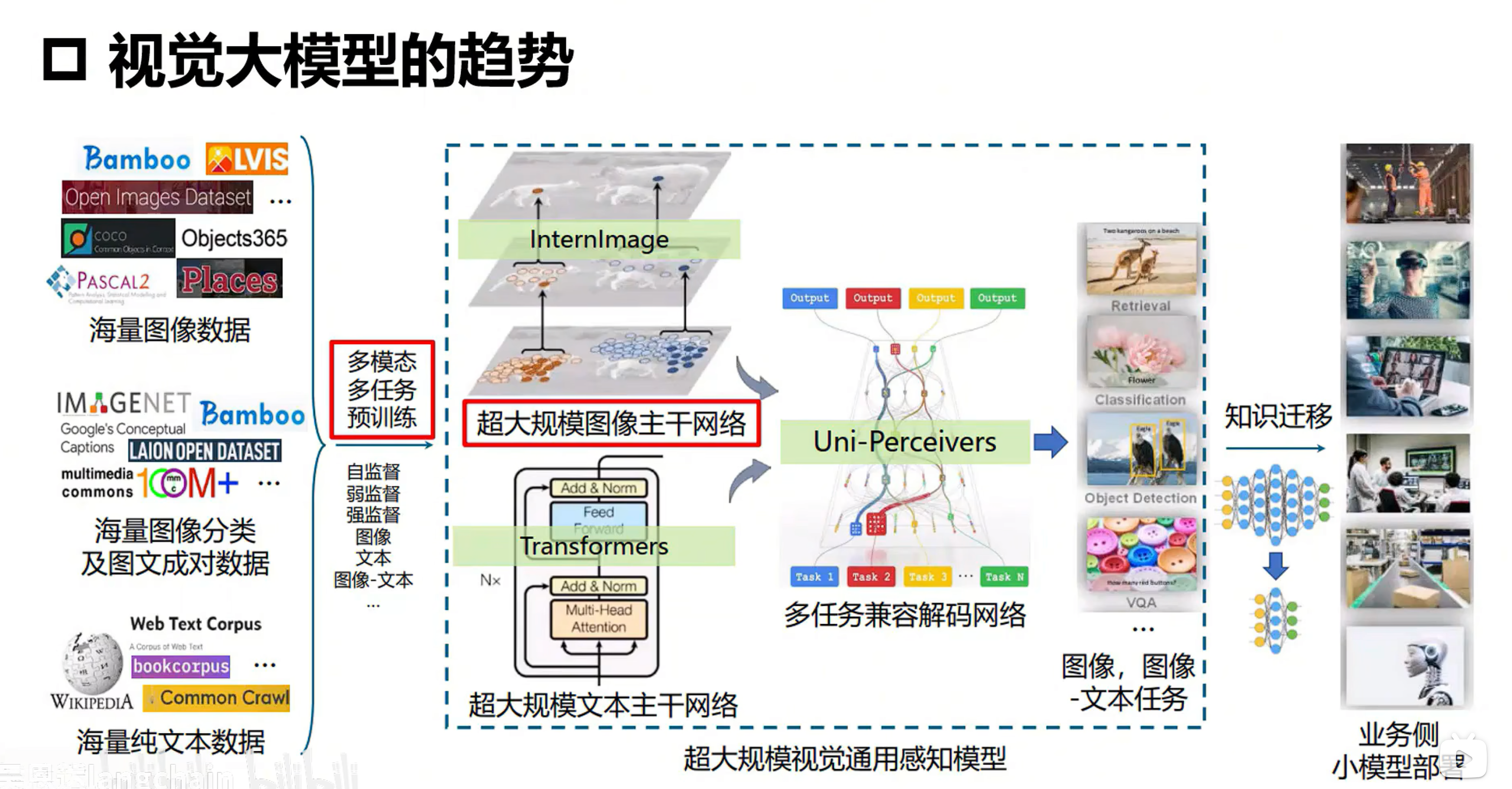
视觉大模型趋势
2. 自监督学习
自监督学习(Self-Supervised Learning, SSL)是机器学习的一种范式,它通过从数据自身生成标签来训练模型,无需人工标注数据。其核心思想是:利用数据的隐含结构自动构造监督信号,让模型学习有意义的表示(Representation Learning)。
和其他机器学习范式的区别:
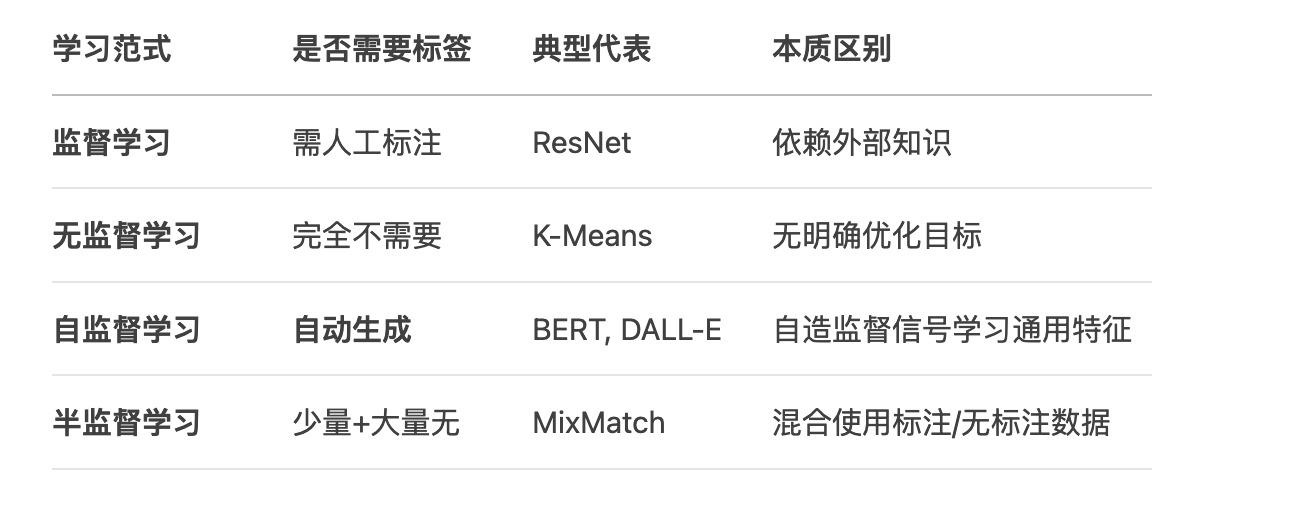
2.1. 三种学习范式
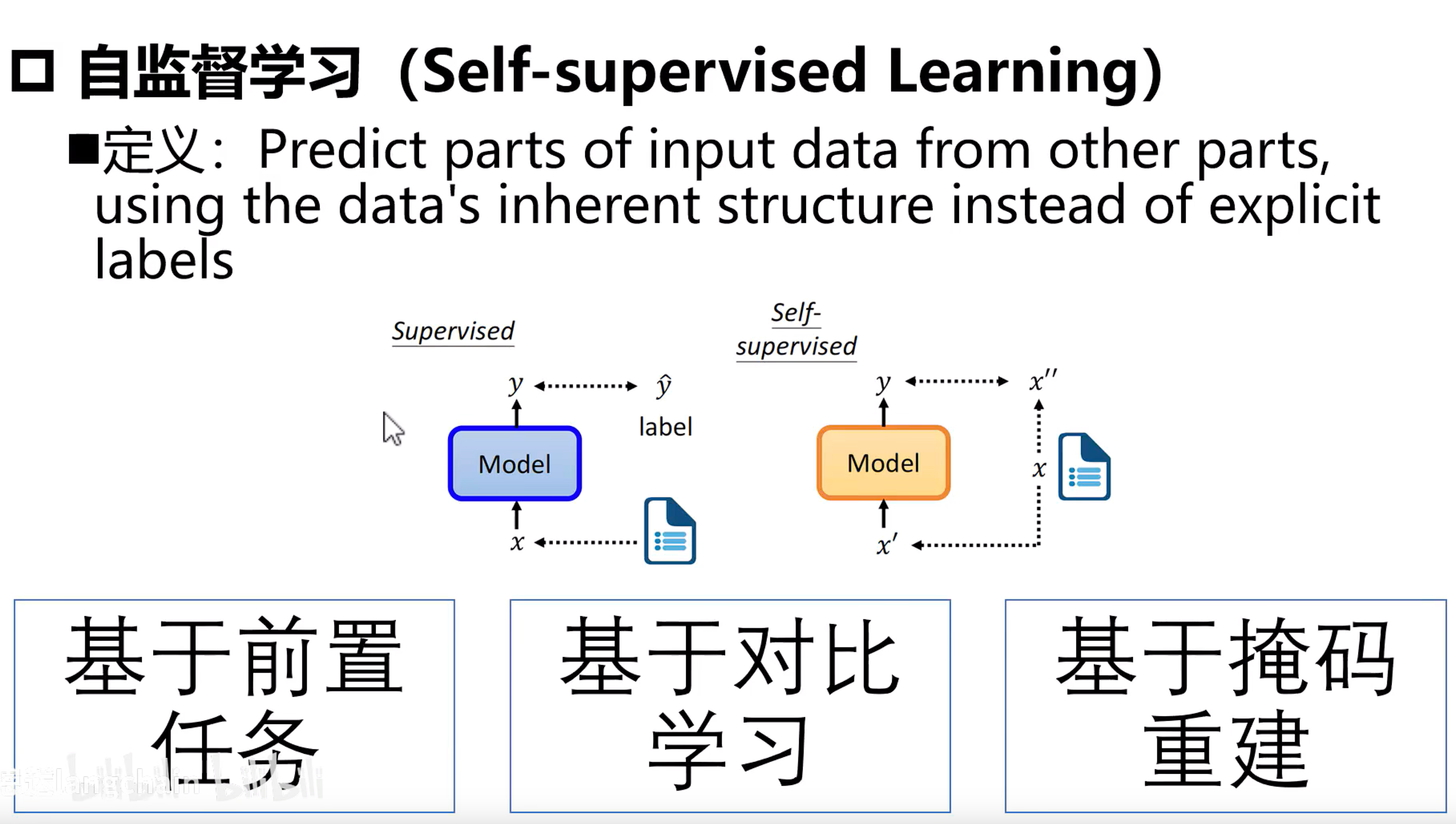
自监督的三种学习范式,所有方法都旨在从未标注的多模态数据(如图像-文本对、视频-音频等)中学习强大的、通用的跨模态表示,避免昂贵的人工标注。
这三种方法都是让机器“无师自通”理解多模态信息的强大工具,只是路径不同,各有千秋。现在最厉害的模型往往是融合了其中两种甚至三种方法的优点。
2.2. 总结对比表

|
特征 |
基于前置任务学习 |
基于对比学习 |
基于掩码重建学习 |
|
核心驱动 |
人为设计的代理任务 |
区分正负样本对 |
根据上下文重建被掩码的数据 |
|
主要目标 |
解决特定代理任务 |
拉近正样本,推远负样本 |
最小化重建误差 |
|
关键操作 |
预测伪标签 |
计算对比损失 (InfoNCE 等) |
掩码输入,预测被掩部分 |
|
信息利用 |
任务定义所需的信息 |
样本间(对)的相似/不相似关系 |
数据内部的上下文依赖关系 |
|
优点 |
设计灵活,直观 |
表示判别性强,对齐效果好 |
通用性强,学习丰富上下文,无需负样本 |
|
主要缺点 |
任务设计敏感,信息瓶颈 |
负样本需求大(计算/假阴性) |
计算开销大,可能过分关注低层细节 |
|
模态对齐 |
任务相关(如匹配任务强制对齐) |
非常直接(在共享空间拉近表示) |
通过跨模态上下文重建隐含学习 |
|
代表模型 |
早期跨模态匹配模型,VATT |
CLIP, ALIGN, FILIP |
BEiT-3, FLAVA, MAE, Data2Vec |
3. 视觉大模型
3.1. VIT (基础网络架构)
ViT (Vision Transformer),这是一个革命性的视觉模型,它成功地将原本在自然语言处理(NLP)领域大放异彩的 Transformer 架构引入了计算机视觉(CV)领域,并取得了与甚至超越传统卷积神经网络(CNN)的性能。
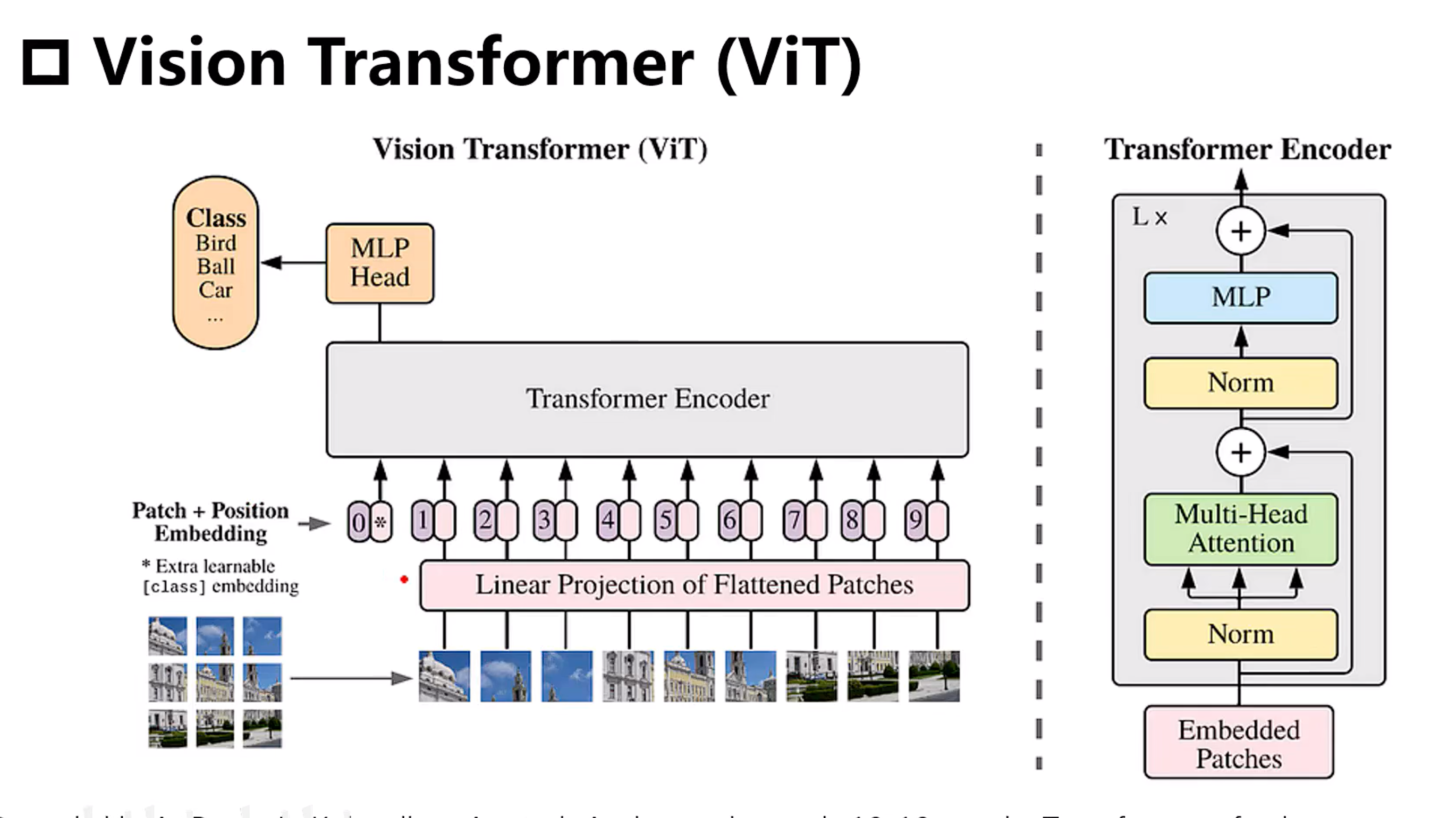
详细拆解步骤图

1. 输入图像(224x224x3)
┌───────────────────────────────────┐
│ ██ ▒▒ ░░ ▒▒ │
│ ▒▒▒▒ ░░ ██ ▒▒ ██ ░░ │
│ ░░░░ ██ ▒▒ ▒▒ ██ │
│ ▒▒ ░░ ██ ░░ │
└───────────────────────────────────┘
2. 图像分块(拆成 16x16 的小块)
┌───┬───┬───┬───┐
│ ██│▒▒ │░░ │▒▒ │ → 共 14x14=196 个块
├───┼───┼───┼───┤
│ ▒▒│ ░░│ ██│ ▒▒│
├───┼───┼───┼───┤
│ ░░│ ██│ ▒▒│ │
└───┴───┴───┴───┘
3. 线性嵌入(每个块展平为向量)
[16x16x3=768像素] → 线性投影 → [D=768维向量]
██块 → [0.2, 1.7, -0.9, ..., 0.5] (长度768)
▒▒块 → [0.8, -2.1, 0.3, ..., -1.2]
4. 添加位置编码 + [CLS] Token
┌───────┬───────────────┐
│ [CLS] │ 块1 块2 ... 块196 │ ← 序列长度=197
└───────┴───────────────┘
│ │ │
│ └──▶ + 位置编码向量 │ (标记空间位置)
└──▶ 可学习的分类向量 │
5. Transformer 编码器(核心)
┌───────────────────────┐
│ 多头自注意力 → 层归一化 │
│ ↓ │
│ 前馈神经网络 → 层归一化 │ × L层(例:L=12)
└───────────────────────┘
▲
输入序列: [CLS] + (块1+位置1) + ... + (块196+位置196)
6. 输出分类结果
┌───────────┐
│ 取[CLS]向量 │ → MLP分类头 → "猫: 0.95"
└───────────┘3.2. 自监督训练框架
|
范式 |
代表模型 |
关键技术 |
突破点 |
|
对比学习 |
SimCLR |
大批量+非线性投影头 |
简化对比学习框架 |
|
MoCo v1/v2/v3 |
动量编码器+队列内存库 |
解耦批量与负样本数量 |
|
|
BYOL |
非对称网络+动量教师 |
无需负样本 |
|
|
掩码重建 |
MAE |
高掩码率+非对称编解码 |
ViT高效预训练方案 |
|
BEiT v1/v2/v3 |
视觉Token预测 |
语义级重建 |
|
|
蒸馏自训练 |
DINO |
教师-学生网络+中心化/锐化 |
自蒸馏防坍塌 |
|
iBOT |
掩码重建+自蒸馏联合 |
多任务协同优化 |
|
|
聚类驱动 |
SwAV |
在线聚类+多视角交换 |
替代负样本对比 |
|
非对称架构 |
SimSiam |
预测头+停止梯度 |
极简自监督框架 |
|
多模态 |
CLIP/ALIGN |
图文对比学习 |
跨模态语义对齐 |
3.3. 关键关系图示
┌──────────────┐
│ 基础架构 │
│ (ViT) │◄─────┐
└──────┬───────┘ │
│ │
┌───────▼───────┐ ┌───▼───────┐
│ 训练框架 │ │ 训练框架 │
│ (MAE) │ │ (DINO) │
└───────┬───────┘ └───┬───────┘
│ │
┌───────▼───────┐ ┌───▼───────┐
│ 掩码重建任务 │ │ 自蒸馏任务 │
└───────────────┘ └───────────┘注:SimCLR/MAE/DINO 是训练方法论,ViT 是模型骨架。
3.4. 典型组合案例
|
实际模型 |
架构 |
训练方法 |
代表作 |
|
ViT-Base |
ViT |
监督学习 |
原始ViT论文 |
|
MAE-ViT-Huge |
ViT |
MAE |
Facebook AI 2021 |
|
DINO-vit-small |
ViT |
DINO |
Meta AI 2021 |
|
SimCLR-ResNet |
ResNet |
SimCLR |
Google 2020 |
4. 多模态网络架构
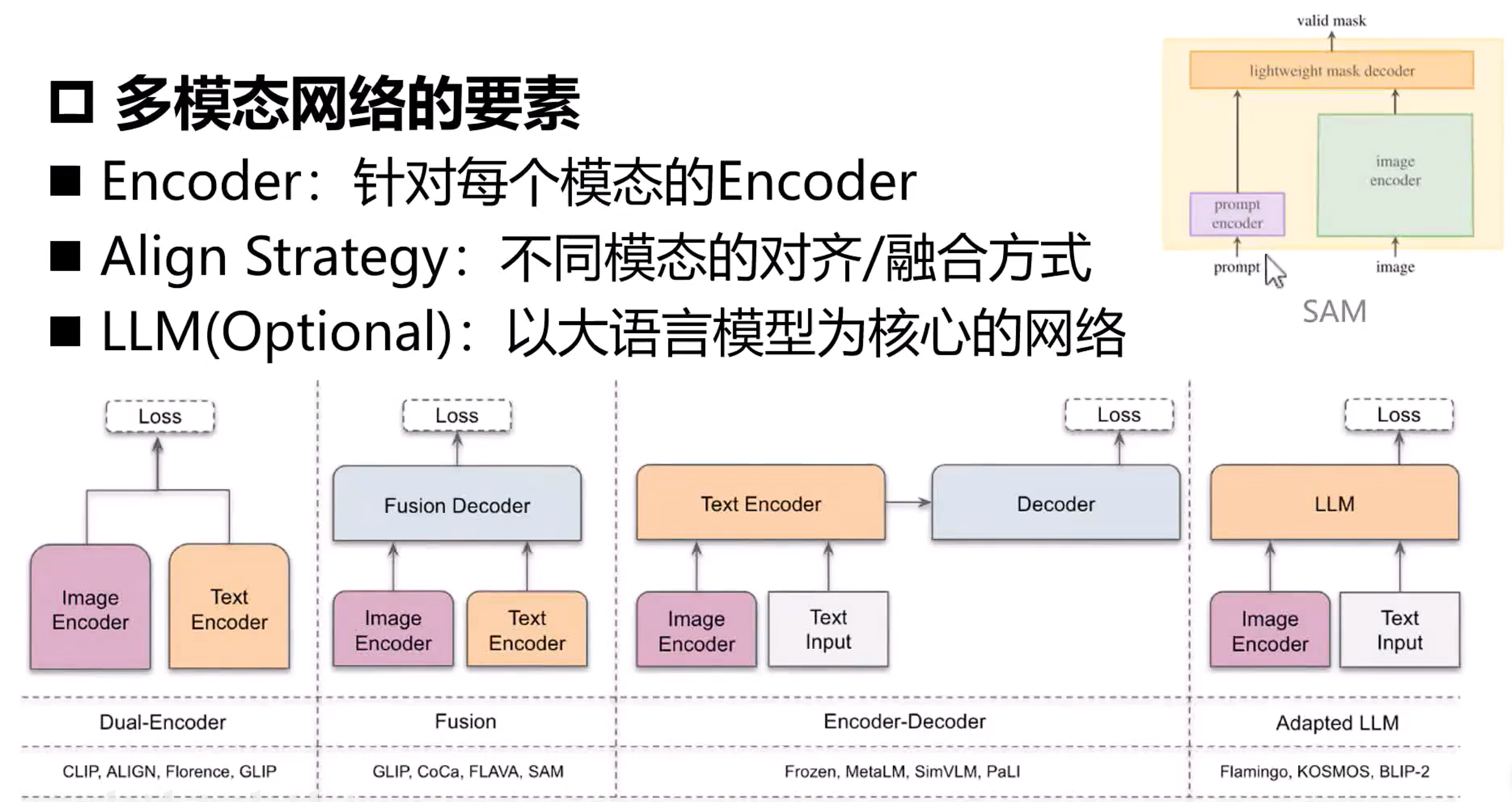
4.1. 多模态网络要素
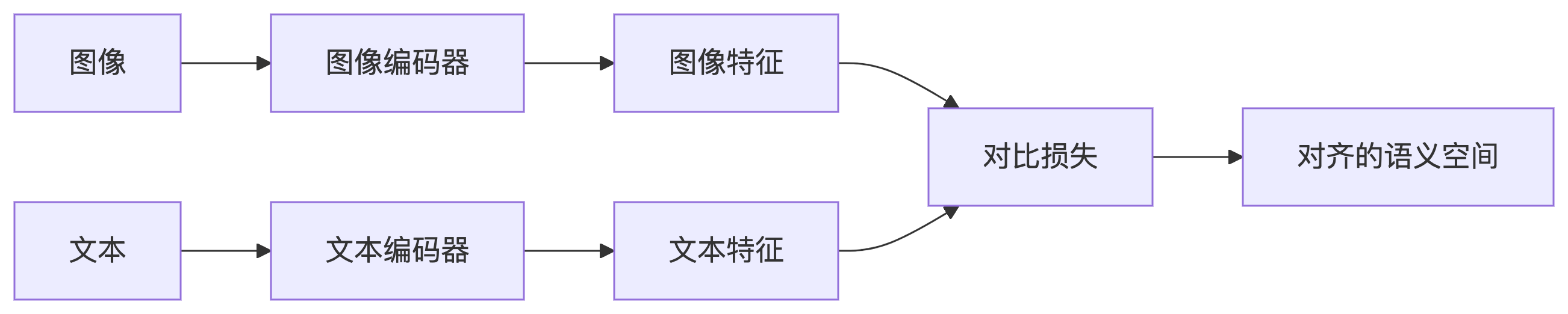
4.2. CLIP (对比语言-图像预训练)
“CLIP 的本质是将语言作为视觉任务的统一接口” —— OpenAI 团队
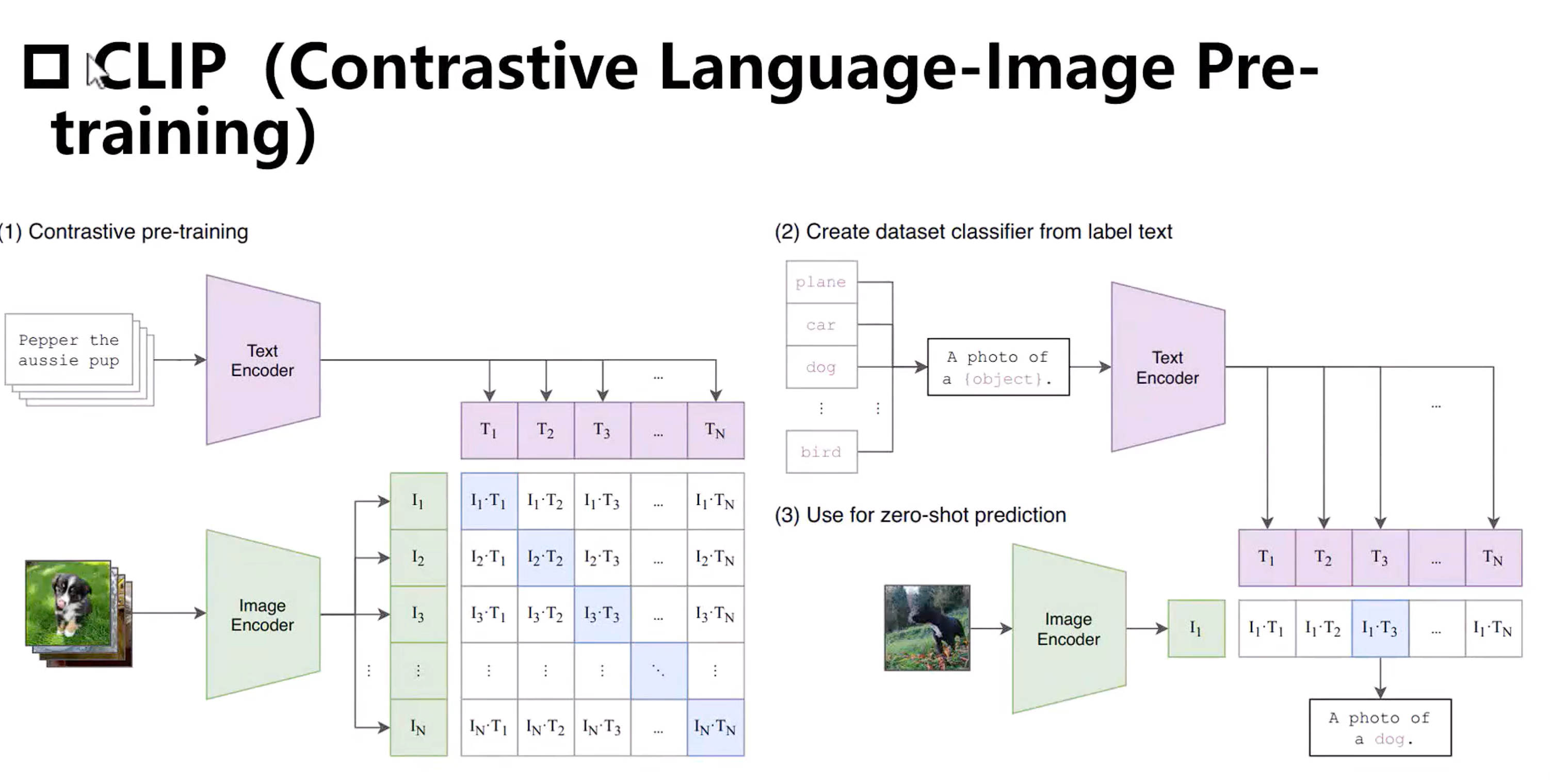
用对比学习对齐图文语义空间
- 目标:让模型学会判断「任意图像」与「任意文本描述」是否匹配
- 方法:
-
- 图像编码器(如 ViT/ResNet)提取视觉特征
- 文本编码器(Transformer)提取语言特征
- 通过对比损失拉近匹配图文对,推开不匹配对
|
组件 |
架构选择 |
输出维度 |
|
图像编码器 |
ViT-B/32 或 ResNet-50x64 |
512 维向量 |
|
文本编码器 |
Transformer |
512 维向量 |
交互方式:仅通过特征向量的余弦相似度交互,不设计跨模态融合模块
5. 下游任务迁移
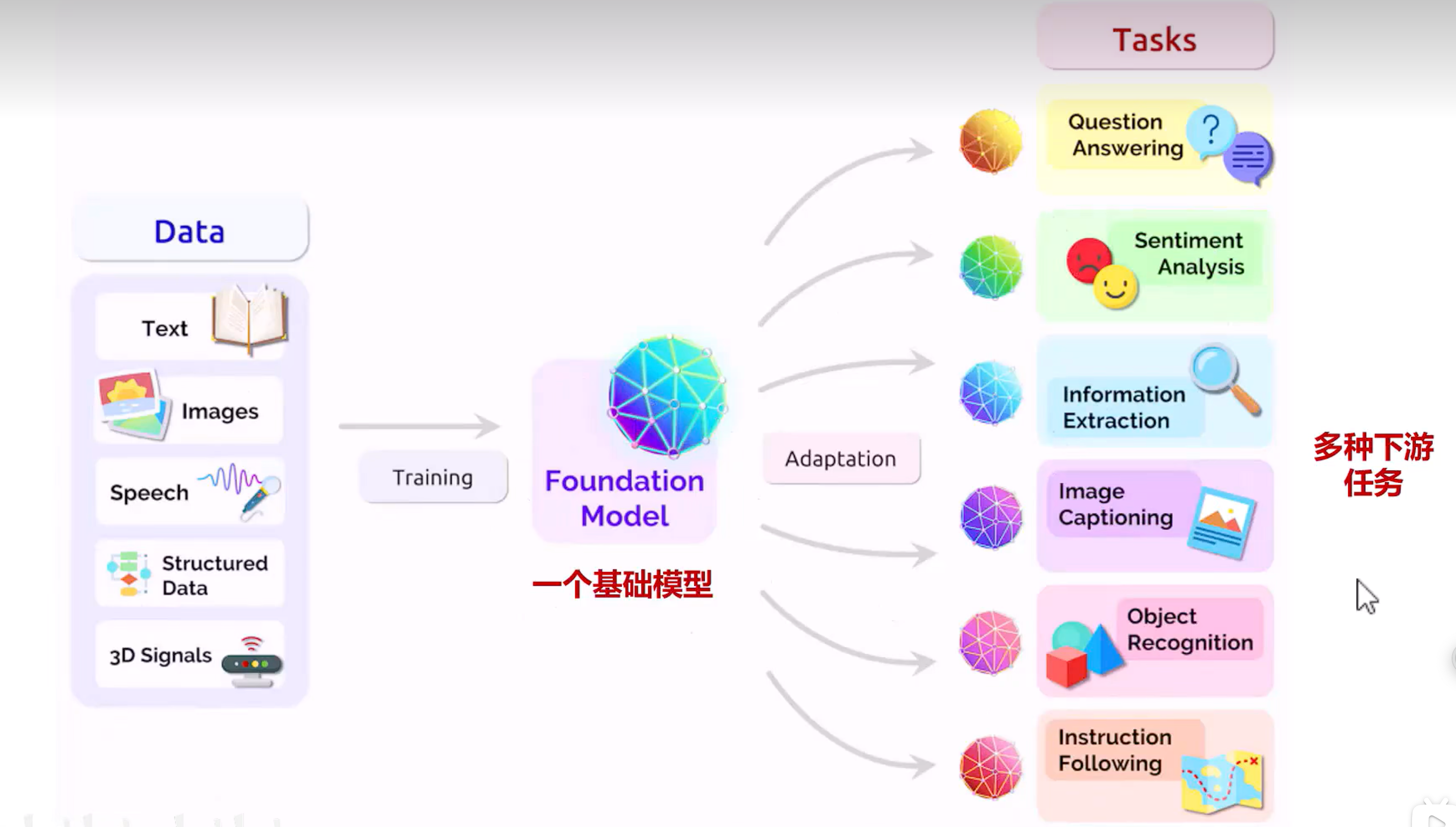
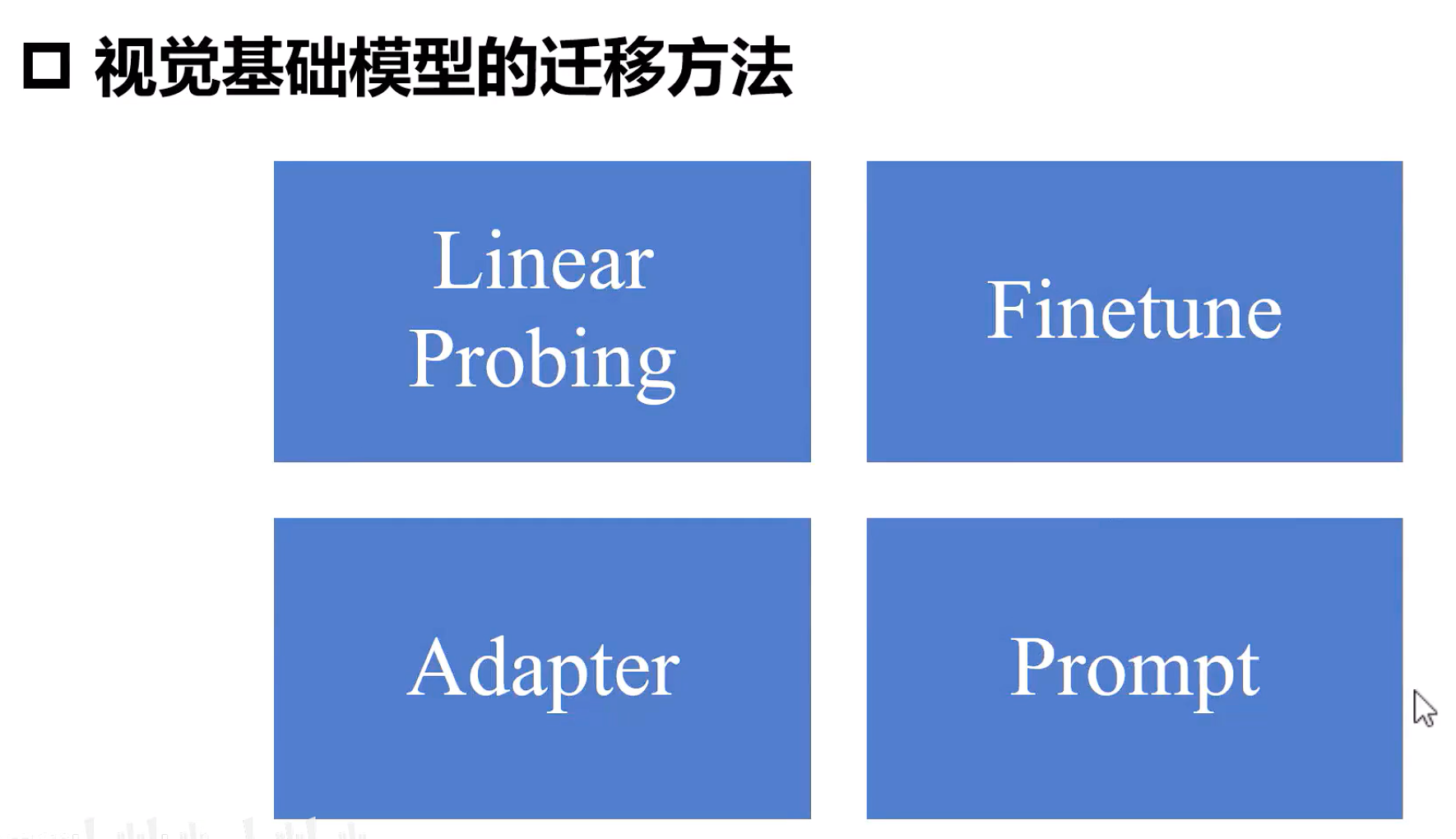
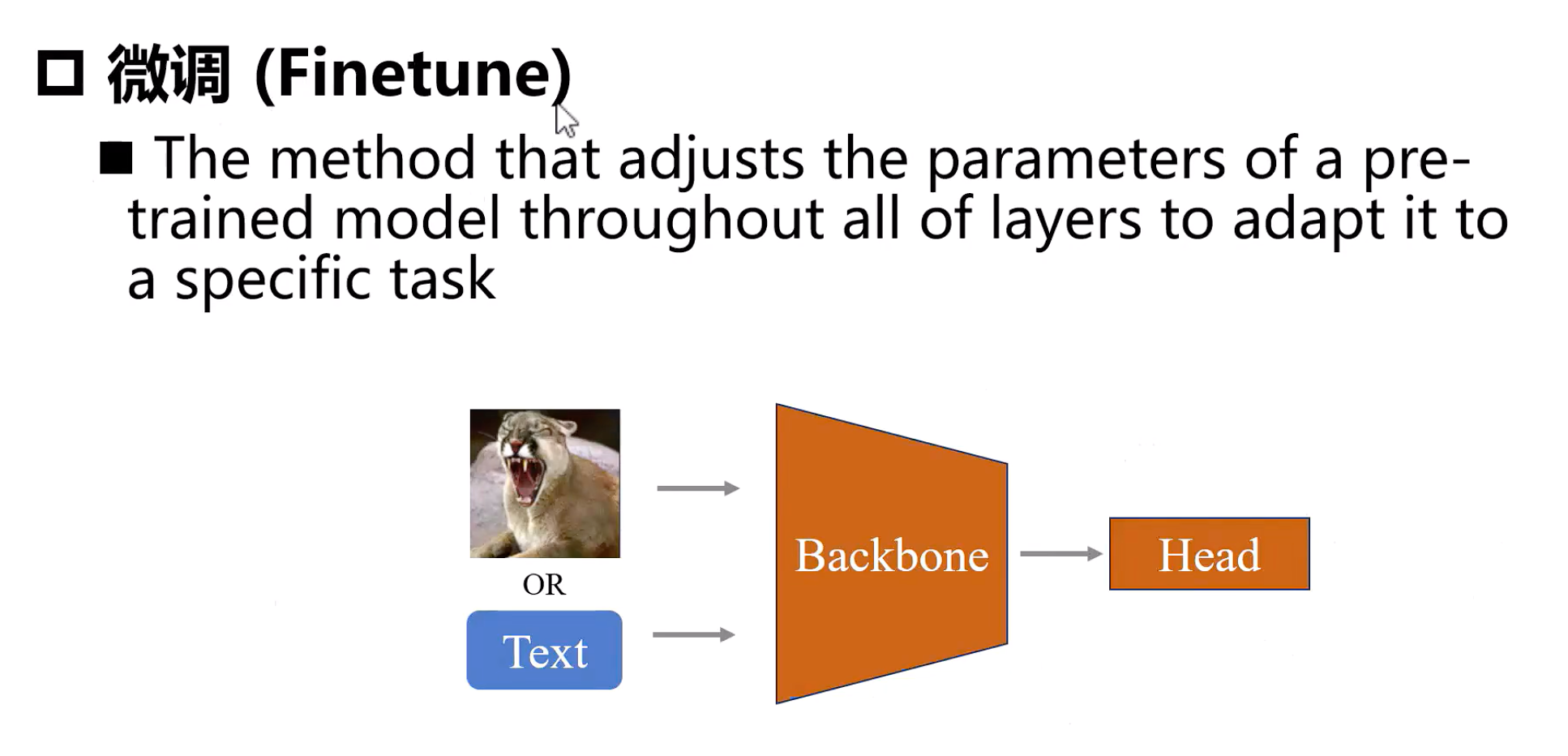
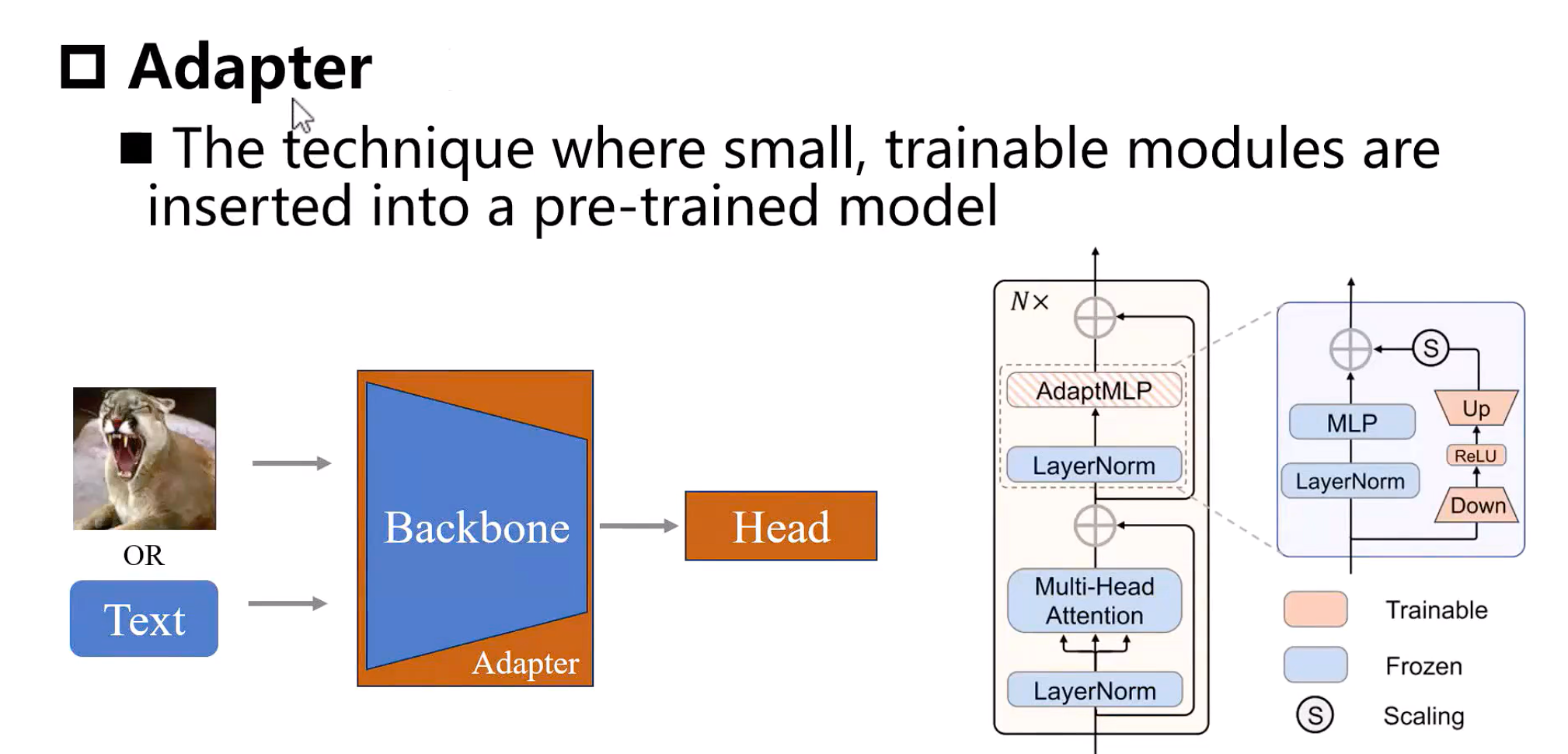
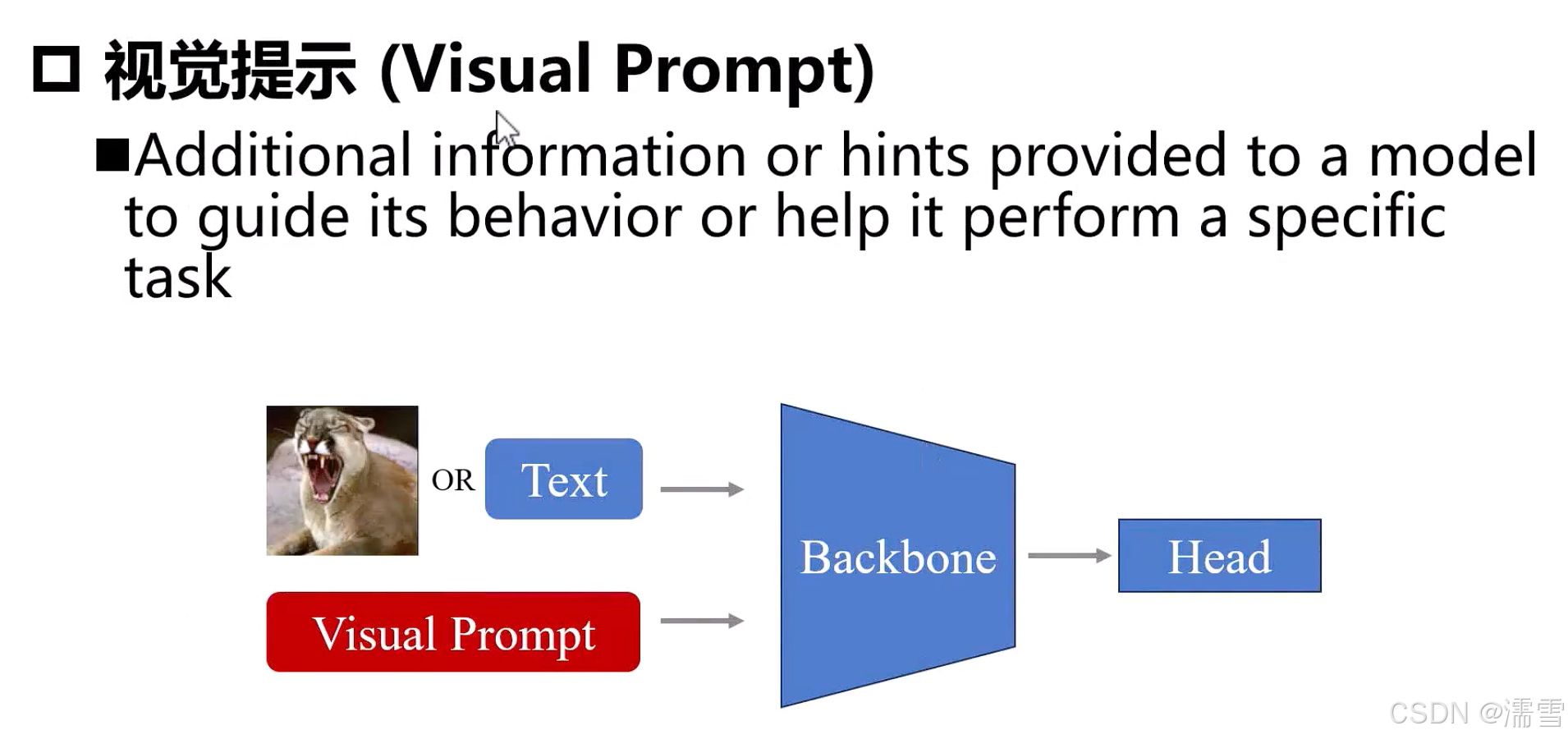
5.1. 四大迁移方法核心区别
|
方法 |
修改位置 |
训练参数量 |
计算成本 |
适用场景 |
|
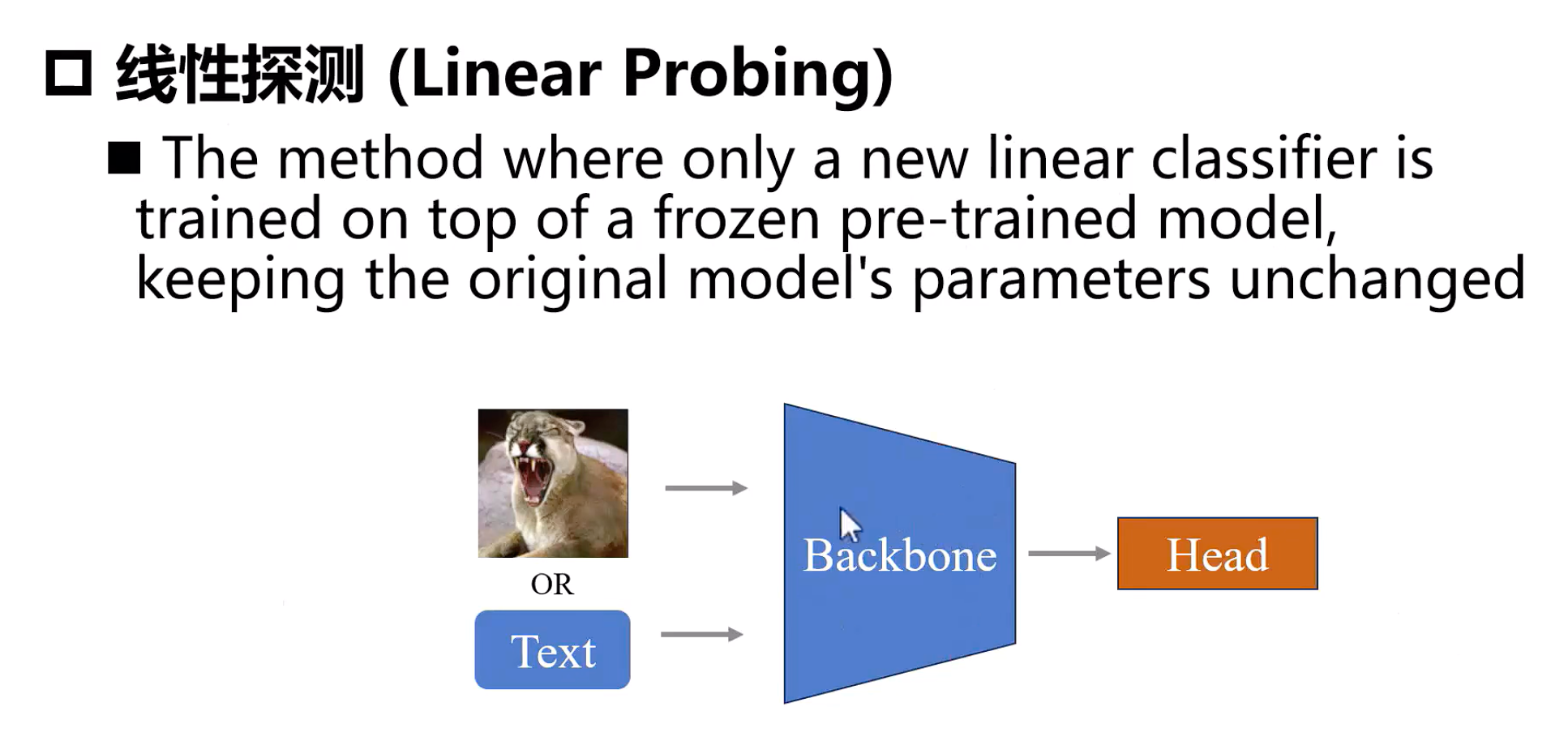
Linear Probing |
仅最后一层分类头 |
极少(<1%) |
极低 |
特征质量极高时快速部署 |
|
Full Finetune |
全部模型参数 |
100% |
极高 |
数据充足且任务差异大 |
|
Adapter |
插入轻量模块 |
0.5%-5% |
中低 |
平衡效果与效率的通用场景 |
|
Prompt Tuning |
修改输入(提示词) |
0.1%-1% |
最低 |
少样本/零样本学习 |
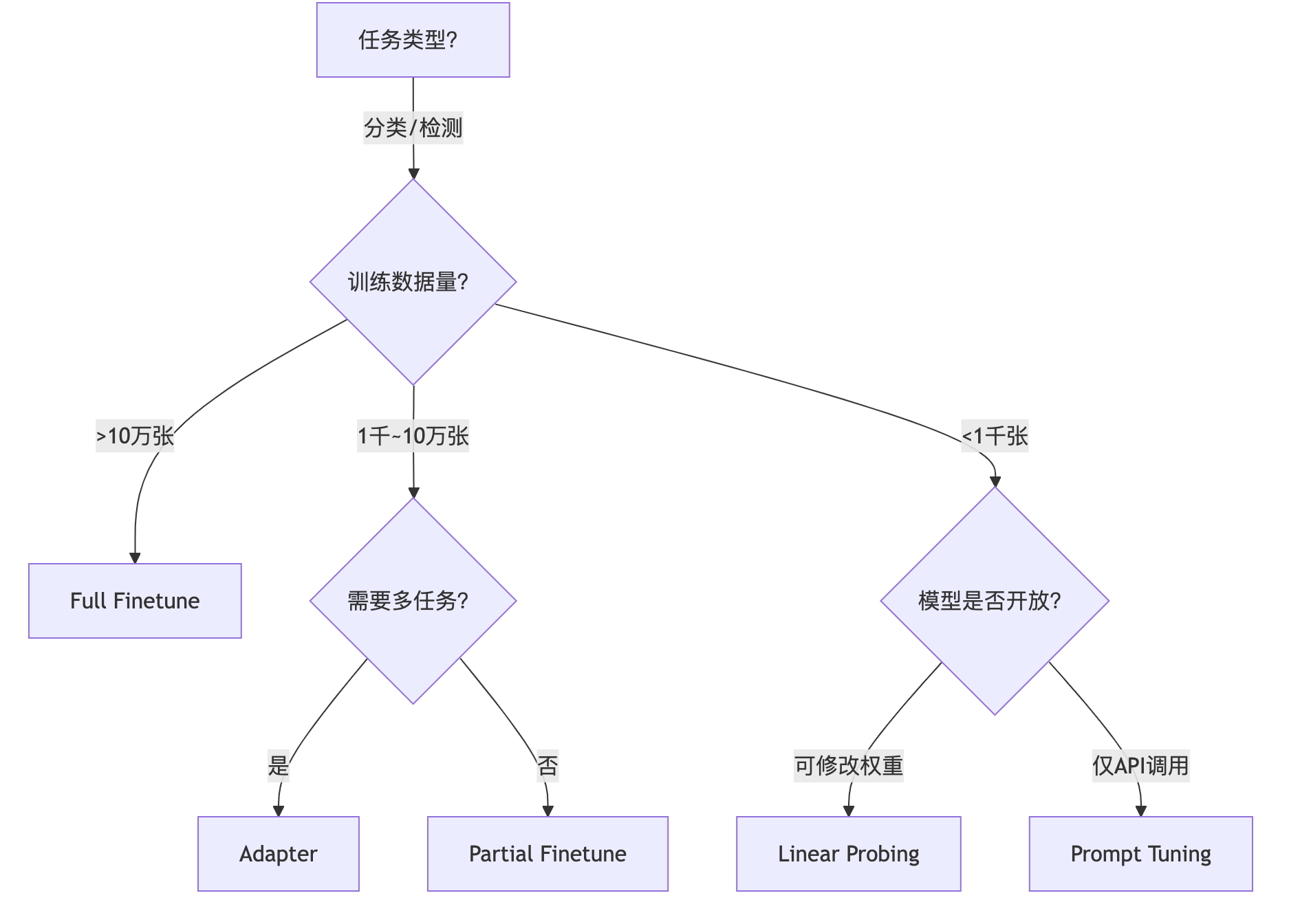
5.2. 多模态任务迁移方案选择指南
|
场景 |
推荐方法 |
案例说明 |
|
数据极少(<50样本) |
Prompt Tuning |
博物馆文物图文匹配 |
|
数据适中(1k-10k) |
Adapter |
电商产品描述生成 |
|
数据充足(>100k) |
Full Finetune |
短视频内容安全审核 |
|
实时推理要求高 |
Linear Probing |
智能相册自动打标 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)