Python爬虫实战:百度搜索数据抓取代码全解析(Selenium自动化,后附完整代码)
本文介绍了利用Python爬取百度搜索关于GPT-5数据的方法。该爬虫程序能自动翻页采集搜索结果,包含页码、标题、链接和简介等字段,适合用于数据分析。代码采用多种异常处理机制确保稳定性,适合Python爬虫学习者参考。
·
前言:
前两天OpenAI正式发布第五代模型,引起了广泛关注。正好前几天写了份百度搜索数据抓取的代码,我就想正好可以爬一下百度搜索上有关它的一些谈论,同时把代码分享给各位的小伙伴们!
话不多说,直接开干!
一:数据展示

数据的字段是页码,标题,链接还有对应的简介。数据很直观清晰,便于后续进行数据分析,也很方便大家进行直观的分析。
二:代码解析
一:浏览器初始化模块
def init_browser():
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--start-maximized")
chrome_options.add_argument("user-agent=Mozilla/5.0...")
service = Service(r"C:\Program Files\Google\Chrome\Application\chromedriver.exe")
driver = webdriver.Chrome(options=chrome_options, service=service)
return driver
该模块配置Chrome浏览器驱动参数:
- 禁用GPU加速提升稳定性
- 设置浏览器启动时最大化窗口
- 添加用户代理伪装成普通浏览器
- 指定chromedriver路径并返回浏览器实例
二:URL关键词提取模块
def extract_keyword_from_url(url):
pattern = r'wd=([^&]+)'
match = re.search(pattern, url)
if match:
keyword = match.group(1).replace('+', ' ')
return keyword
return "未知关键词"
功能实现逻辑:
- 使用正则表达式匹配URL中的
wd=参数 - 解码URL编码的空格字符
- 返回提取后的关键词或默认值
三:Excel导出模块
def export_results_to_excel(results, file_name=None):
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
file_name = file_name or f"百度搜索结果_{timestamp}.xlsx"
df = pd.DataFrame(results)
os.makedirs('search_results', exist_ok=True)
file_path = os.path.join('search_results', file_name)
df.to_excel(file_path, index=False)
数据处理特点:
- 自动生成时间戳文件名
- 创建search_results目录确保路径存在
- 使用pandas转换数据为Excel格式
- 返回文件绝对路径便于后续操作
四:页面爬取核心模块
search_results = driver.find_elements(By.CSS_SELECTOR, '.result.c-container, .result-op.c-container')
if not search_results:
search_results = driver.find_elements(By.CSS_SELECTOR, '[mu], .t')
for result in search_results:
title_elem = result.find_element(By.CSS_SELECTOR, 'h3 a, h3.t a')
abstract_elems = result.find_elements(By.CSS_SELECTOR, '.c-abstract, .content-right_8Zs40')
元素定位策略:
- 主选择器定位标准结果容器
- 备用选择器应对页面结构变化
- 异常处理确保单条失败不影响整体采集
五:数据存储
results.append({
"页码": page,
"标题": title,
"链接": link,
"简介": abstract
})
每处理完一个搜索结果,就会将信息以字典形式添加到结果列表。
六:分页处理逻辑
next_button = driver.find_element(By.LINK_TEXT, "下一页 >")
if next_button.is_displayed():
driver.execute_script("arguments[0].scrollIntoView();", next_button)
driver.execute_script("arguments[0].click();", next_button)
尝试定位并点击"下一页"按钮,使用JavaScript执行点击确保可靠性。
三:使用流程
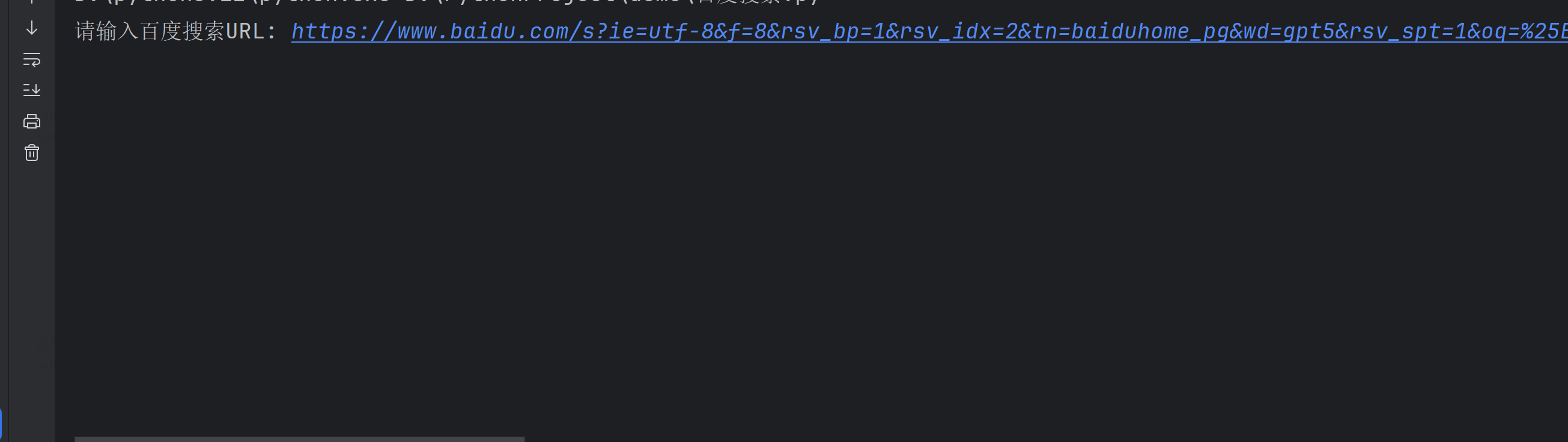
运行代码后直接可以输入你想要爬取的链接。
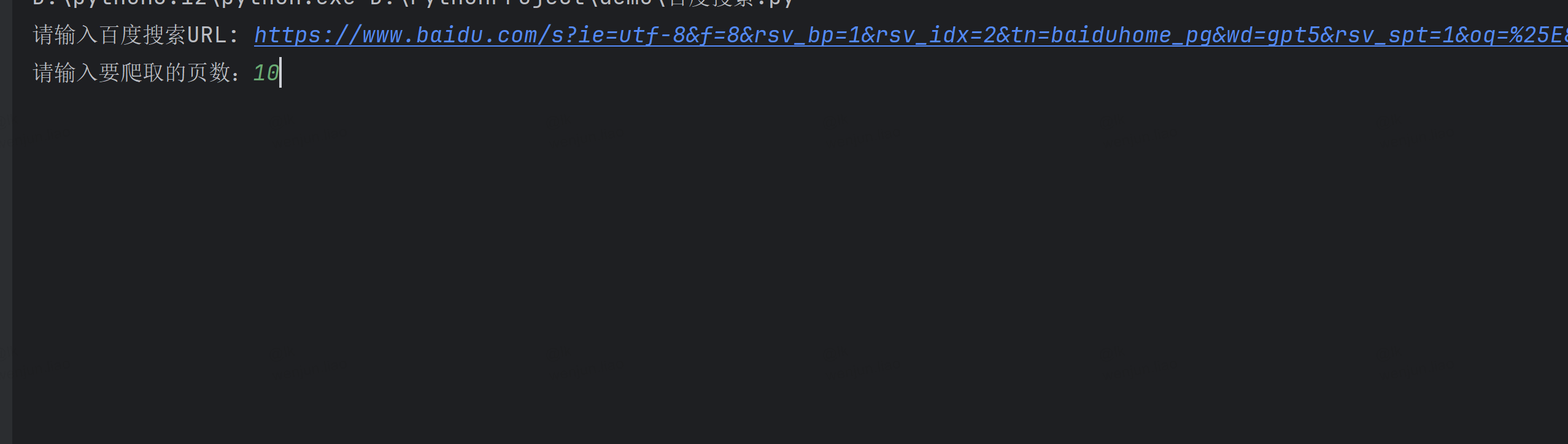
这里可以设置能爬取的页数,这里指定爬取10页。

接下来会打开浏览器窗口,自动获取数据,自动翻页。这里使用的谷歌浏览器。
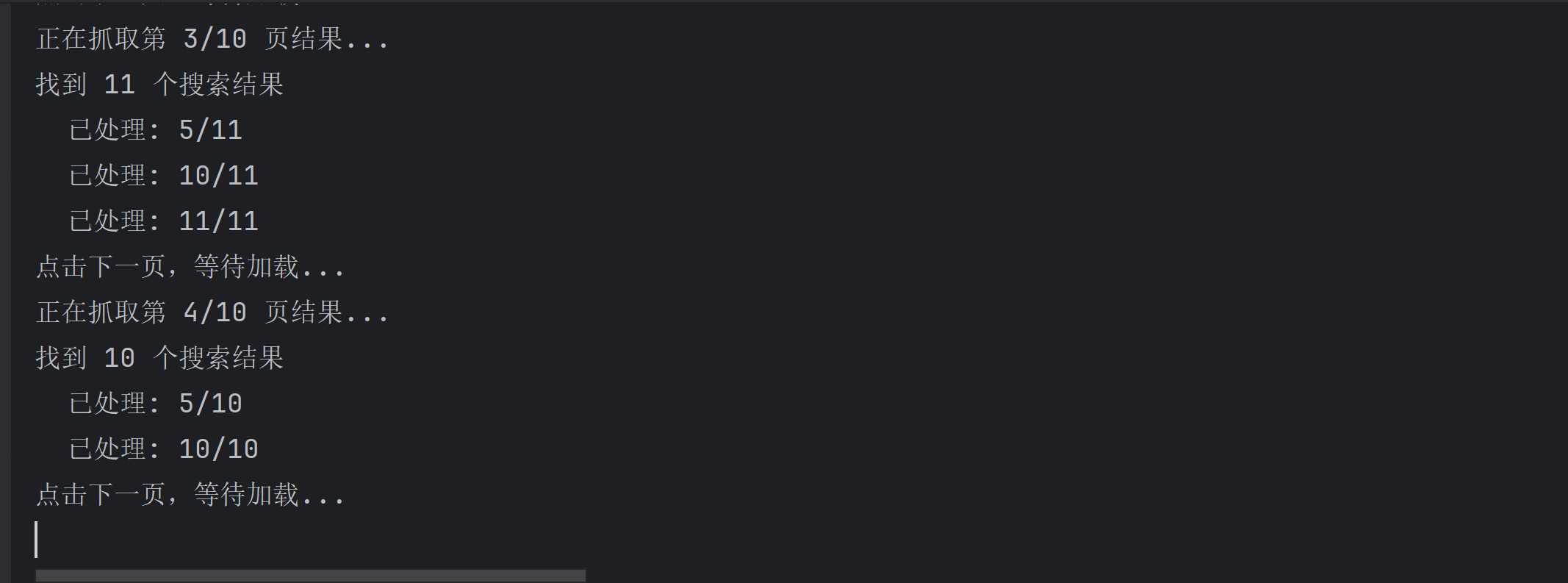
这是运行过程中的图。
四:结语
以上就是全部内容啦,如果你感兴趣的话欢迎关注我,我还会写更多对大家有帮助的代码,帮助大家学习python爬虫,欢迎大家交流学习。若要获取完整的代码,为方便大家,请在公重微号找 python副业星球,关键词回复在评论区领取。下期再见!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)