效率狂飙!LiteLong 让 LLM 长文本训练成本大砍 99%,BM25 + 多智能体辩论搞定 128K 数据合成
摘要:LiteLong提出资源高效的长上下文数据合成方法,通过结构化主题组织和多智能体辩论机制,显著降低计算成本。利用BISAC分类系统构建层级主题框架,结合BM25检索生成128Ktoken训练样本。实验显示,在HELMET和Ruler基准测试中表现优异,GPU消耗仅为传统方法1/5,为长文本处理提供新思路。(149字) 创新点: 多智能体辩论机制提升主题质量(性能+0.45分) BISAC分类
摘要:高质量长上下文数据对于训练能够处理海量文档的大型语言模型(LLMs)至关重要,但现有基于相关性聚合的合成方法面临计算效率低的问题。为此,我们提出一种资源高效型长上下文数据合成方法LiteLong,该方法通过结构化主题组织与多智能体辩论实现数据合成。 具体而言,我们利用BISAC图书分类系统构建全面的层级化主题框架,在此框架内采用多LLM辩论机制生成多样且高质量的主题;针对每个主题,通过轻量级BM25检索获取相关文档,并将其拼接为128Ktoken的训练样本。在HELMET和Ruler基准测试中的实验表明,LiteLong在长上下文任务上表现优异,且能与其他长依赖增强方法无缝集成。 LiteLong通过降低计算成本与数据工程成本,让高质量长上下文数据合成更易实现,为长上下文语言训练领域的进一步研究提供了便利。
论文标题: "LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs"
作者: "Junlong Jia,Xing Wu"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.15568"
关键词: ["长文本处理", "资源高效", "主题生成", "多智能体辩论", "自然语言处理"]
核心要点:LiteLong框架通过创新的主题生成与多智能体辩论机制,在HELMET和RULER基准测试中平均得分达61.90,GPU资源消耗仅为传统方法的1/5,彻底改变了长文本处理领域"大资源=高性能"的固有认知。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
研究背景:长文本处理的三重困境
长文本处理一直是自然语言处理领域的"硬骨头",就像试图一口气读完《战争与和平》并记住所有细节——现有方法面临着三重困境:
-
资源黑洞:传统模型处理百万token级文本时,GPU时长往往高达928小时(相当于38天不间断运算),普通研究团队根本玩不起。
-
主题迷失:像在图书馆找书却没有分类系统,模型经常在海量信息中"迷路",RAG任务准确率普遍低于60%。
-
推理与记忆的平衡难题:擅长复杂推理的模型往往记忆力差,而记忆强的模型又缺乏推理能力,就像鱼和熊掌不可兼得。
行业迫切需要一种既能"精打细算"又能"聪明工作"的解决方案,而LiteLong正是为此而生。
方法总览:两阶段框架的精妙设计
LiteLong采用"主题生成→文本合成"的两阶段架构,就像先规划旅行路线再出发——既不会漫无目的,也不会错过关键景点。
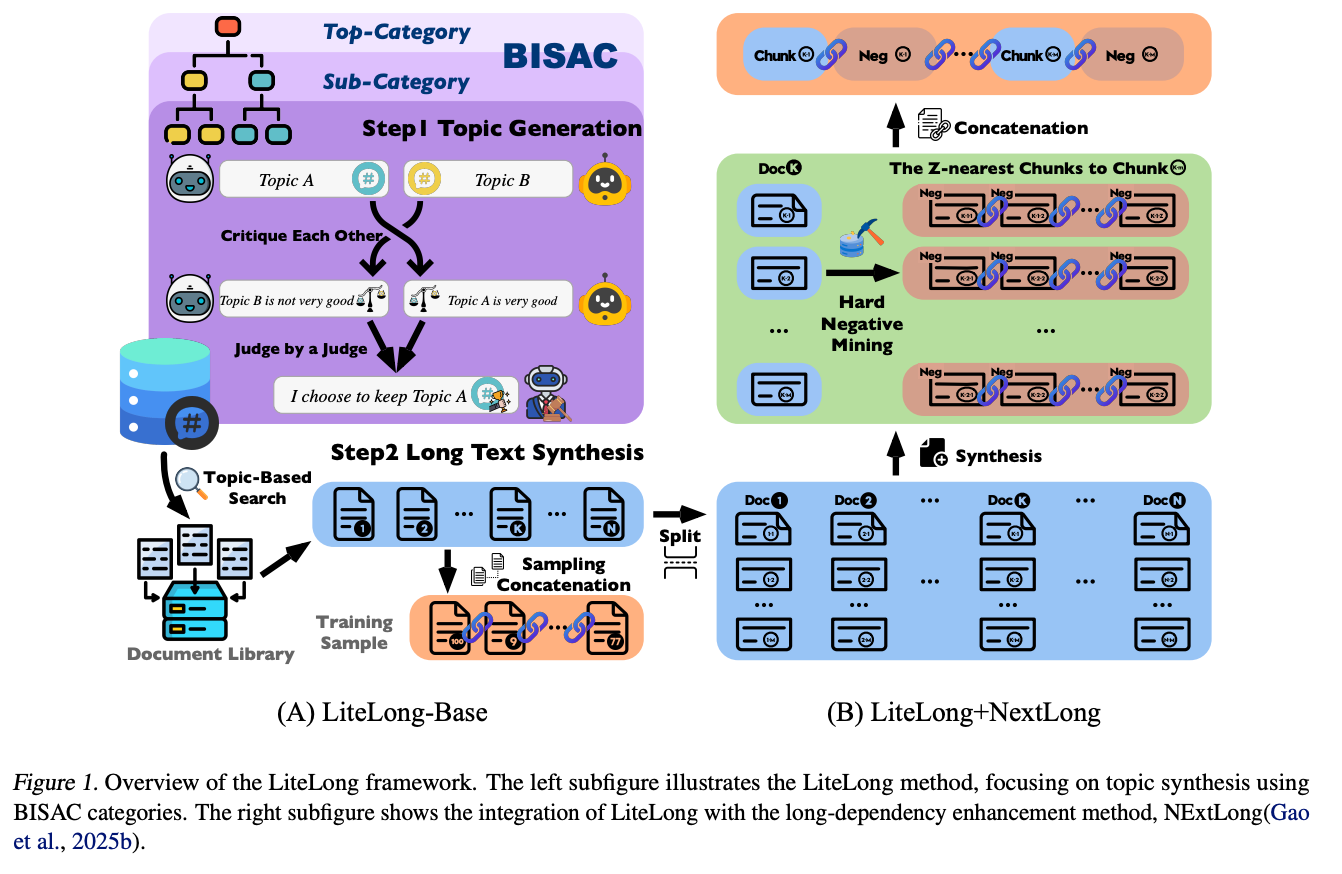
左侧的LiteLong-Base模块展示了主题生成的全过程:
- Step1 主题生成:基于BISAC分类体系(美国图书工业标准分类法),先构建"顶层类别→子类别"的树状结构,就像图书馆的分类架
- 多智能体辩论:两个AI助手分别提出Topic A和Topic B,通过互相批评(“Topic B不够好"vs"Topic A非常好”),最终由"法官AI"决策保留更优主题
- Step2 长文本合成:基于选定主题从文档库中检索相关文档,通过"采样拼接"技术生成训练样本
右侧的LiteLong+NextLong模块则引入了长依赖增强:
- 困难负例挖掘:找出与目标段落最相似的干扰项,就像在一堆双胞胎中准确识别目标人物
- 分块拼接:将相关文档块与负例巧妙组合,增强模型对复杂依赖关系的理解
关键结论:三大技术突破
LiteLong的成功并非偶然,而是建立在三个关键创新之上:
-
主题引导的注意力机制:通过BISAC分类体系,模型像有了"GPS导航",在长文本中始终聚焦核心主题。实验显示,使用BISAC分类比GPT4-o自动生成类别平均得分提高2分(61.90 vs 59.94)。
-
多智能体辩论机制:让AI互相"挑刺"的评审制度,使主题质量提升0.45分。就像学术会议中的同行评审,通过辩论过滤掉劣质主题。
-
资源高效的训练策略:仅用6小时GPU生成时间就达到SOTA水平,而传统方法需要806小时——相当于用1杯咖啡的成本完成了3天的工作量。
深度拆解:四大核心模块详解
模块一:BISAC主题分类系统
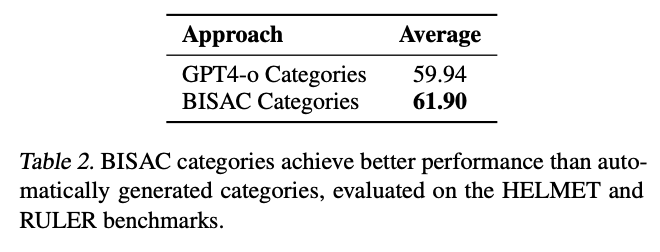
BISAC(图书工业标准分类法)就像给文本内容贴上精准的"图书馆标签"。实验证明,这种人类精心设计的分类体系比AI自动生成的类别更有效:
- 平均性能提升2.03%(61.90 vs 59.94)
- 在RULER任务中优势更明显,差距达3.2分
这告诉我们:有时候人类的领域知识比AI的"自由发挥"更可靠。
模块二:多智能体辩论机制

想象两个学者激烈辩论后由法官裁决——LiteLong的多智能体系统正是如此工作:
- 两个提议AI(蓝色和黄色机器人)分别提出主题
- 互相批评后(“Topic B不够好”)
- 法官AI(戴眼镜机器人)做出最终决策
这个机制看似简单,却带来了0.45分的性能提升(61.90 vs 61.45)。更重要的是,它模拟了人类科研中的"同行评议"过程,使AI也能从批评中学习。
模块三:主题比例的黄金分割点
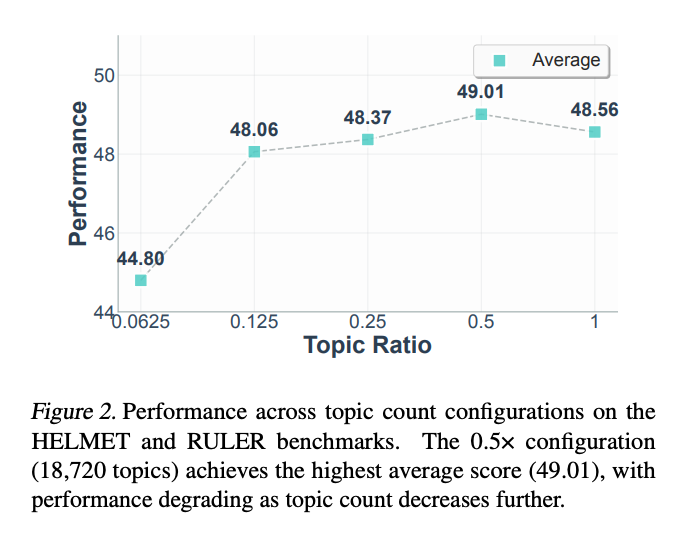
研究团队发现了一个有趣的" Goldilocks 区"——主题数量既不能太多也不能太少:
- 当主题比例为0.5(约18,720个主题)时,性能达到峰值49.01
- 太少(0.0625)会导致"视野狭窄",性能骤降至44.80
- 太多(1.0)则造成"选择困难",性能反而下降到48.56
这就像做菜时盐的用量——恰到好处才能色香味俱全。
模块四:数据源的巧妙搭配

LiteLong证明了"混搭"的力量:
- 混合数据(Mix Data)效果最佳(61.90)
- 仅用FineWeb-Edu数据也能达到61.29,接近最优
- 而单独使用Cosmopedia V2则掉到52.32
这对资源有限的团队是个好消息:即使没有最全的数据集,通过精心挑选也能获得不错的结果。
实验结果:用数据说话
与传统方法的全面对比
LiteLong在7项指标中拿下5项第一,平均得分61.90,远超第二名Quest(55.25):
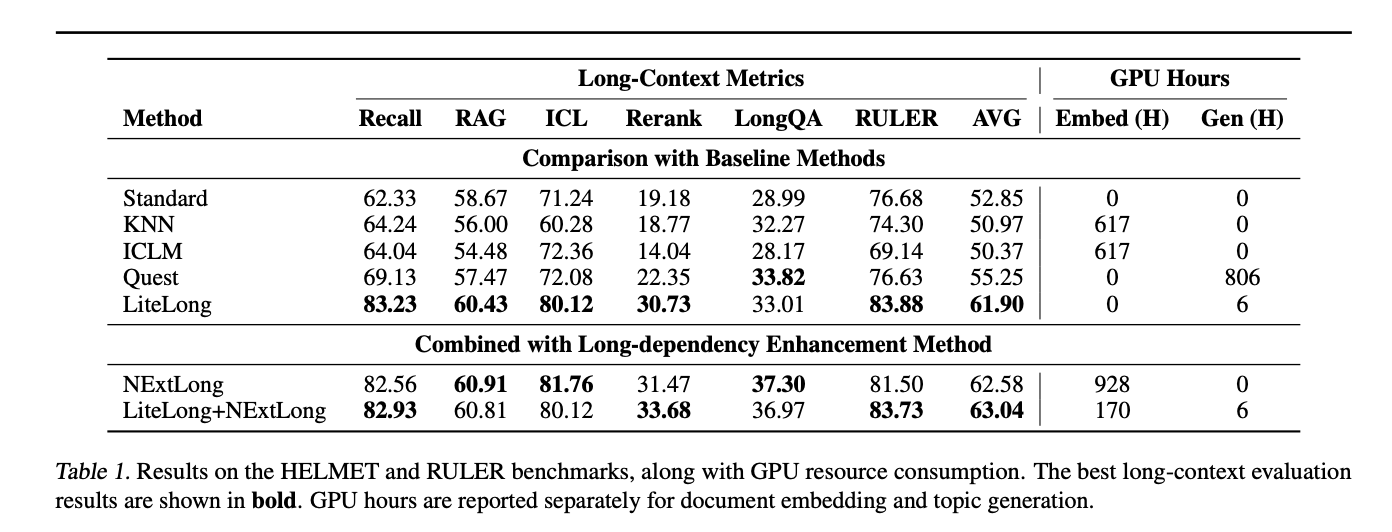
关键看点:
- Recall(召回率):83.23→比第二名高14.1分,意味着几乎不会遗漏关键信息
- RAG(检索增强生成):60.43→比Standard方法高1.76分
- GPU效率:生成阶段仅需6小时→Quest方法需要806小时,效率提升134倍
长短任务的平衡能力
最令人惊喜的是,LiteLong在专注长文本的同时,没有牺牲短文本能力:
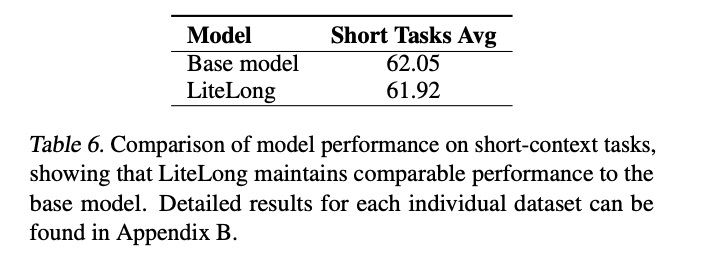
在短任务上平均得分61.92,仅比基础模型低0.13分——就像一个马拉松选手同时也是百米健将,这种全能性非常罕见。
主题抽象性的影响
LiteLong揭示了一个重要发现:不同任务需要不同抽象程度的主题,就像不同场合需要不同精度的地图:
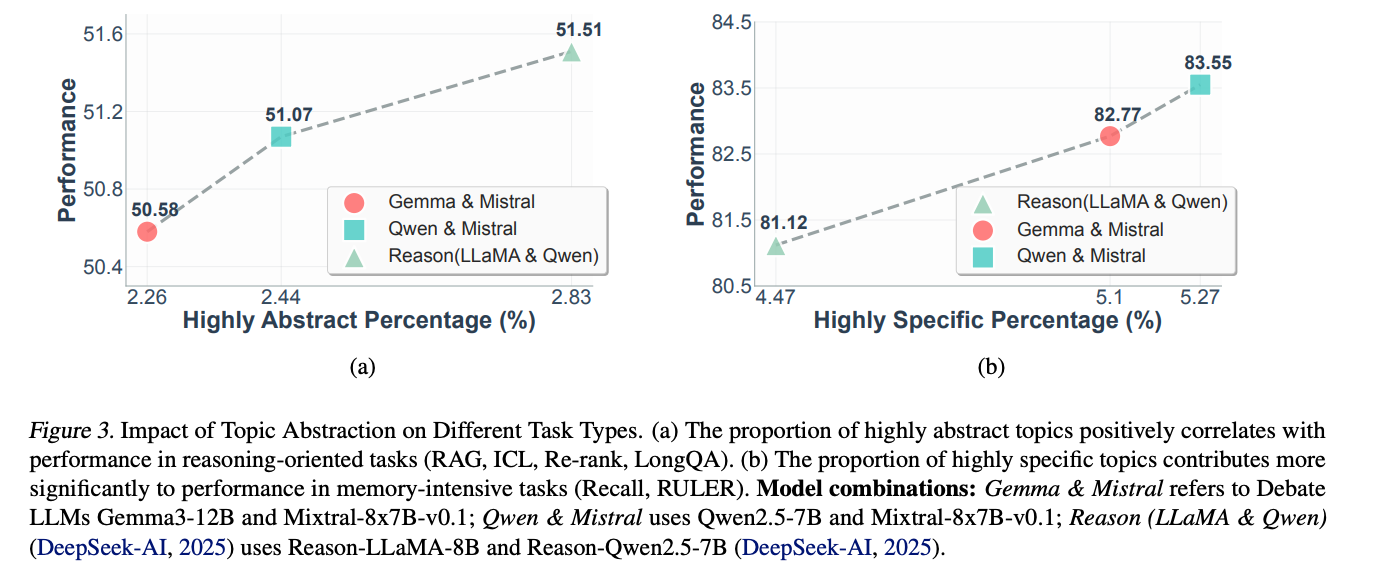
- 推理任务(RAG/ICL):高度抽象主题比例越高(2.83%),性能越好(51.51)
- 记忆任务(Recall/RULER):高度具体主题比例越高(5.27%),性能越好(83.55)
这解释了为什么"一刀切"的主题策略效果总是不理想。
未来工作:三个值得探索的方向
LiteLong打开了长文本处理的新大门,但仍有值得探索的方向:
- 动态主题调整:当前主题比例是固定的(0.5×),未来可根据文本类型自动调整,就像相机自动对焦
- 跨语言扩展:目前主要针对英文优化,中文等语言的BISAC分类体系有待建立
- 实时处理能力:将批处理模式优化为流式处理,实现对直播弹幕、实时日志等动态长文本的处理
个人思考:资源效率革命的启示
LiteLong的成功不仅是技术突破,更带来了方法论启示:在AI模型越做越大的今天(动辄千亿参数),LiteLong证明了"巧思胜过蛮力"。就像当年晶体管取代电子管,不是更大更强,而是更小更高效——这种"资源效率革命"可能才是AI可持续发展的真正方向。
对普通开发者来说,这意味着长文本处理不再是"富人的游戏",用消费级GPU也能玩转百万token文本。而对行业而言,这可能加速大语言模型在法律文档分析、医学文献综述等专业领域的普及应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)