Qwen3-Omni-30B-A3B-Instruct多语言支持:土耳其语语音转写最佳实践
Qwen3-Omni-30B-A3B-Instruct是多语言全模态模型,原生支持文本、图像、音视频输入,并实时生成语音。该模型支持119种文本语言、19种语音输入语言和10种语音输出语言,其中土耳其语是支持的语音输入语言之一。[项目详细信息](https://gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct/blob/26291f..
Qwen3-Omni-30B-A3B-Instruct多语言支持:土耳其语语音转写最佳实践
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Omni-30B-A3B-Instruct 项目概述
Qwen3-Omni-30B-A3B-Instruct是多语言全模态模型,原生支持文本、图像、音视频输入,并实时生成语音。该模型支持119种文本语言、19种语音输入语言和10种语音输出语言,其中土耳其语是支持的语音输入语言之一。
土耳其语语音转写流程
模型架构
Qwen3-Omni采用基于MoE的Thinker-Talker设计,结合AuT预训练和多码本设计,实现了低延迟的实时音频/视频交互。
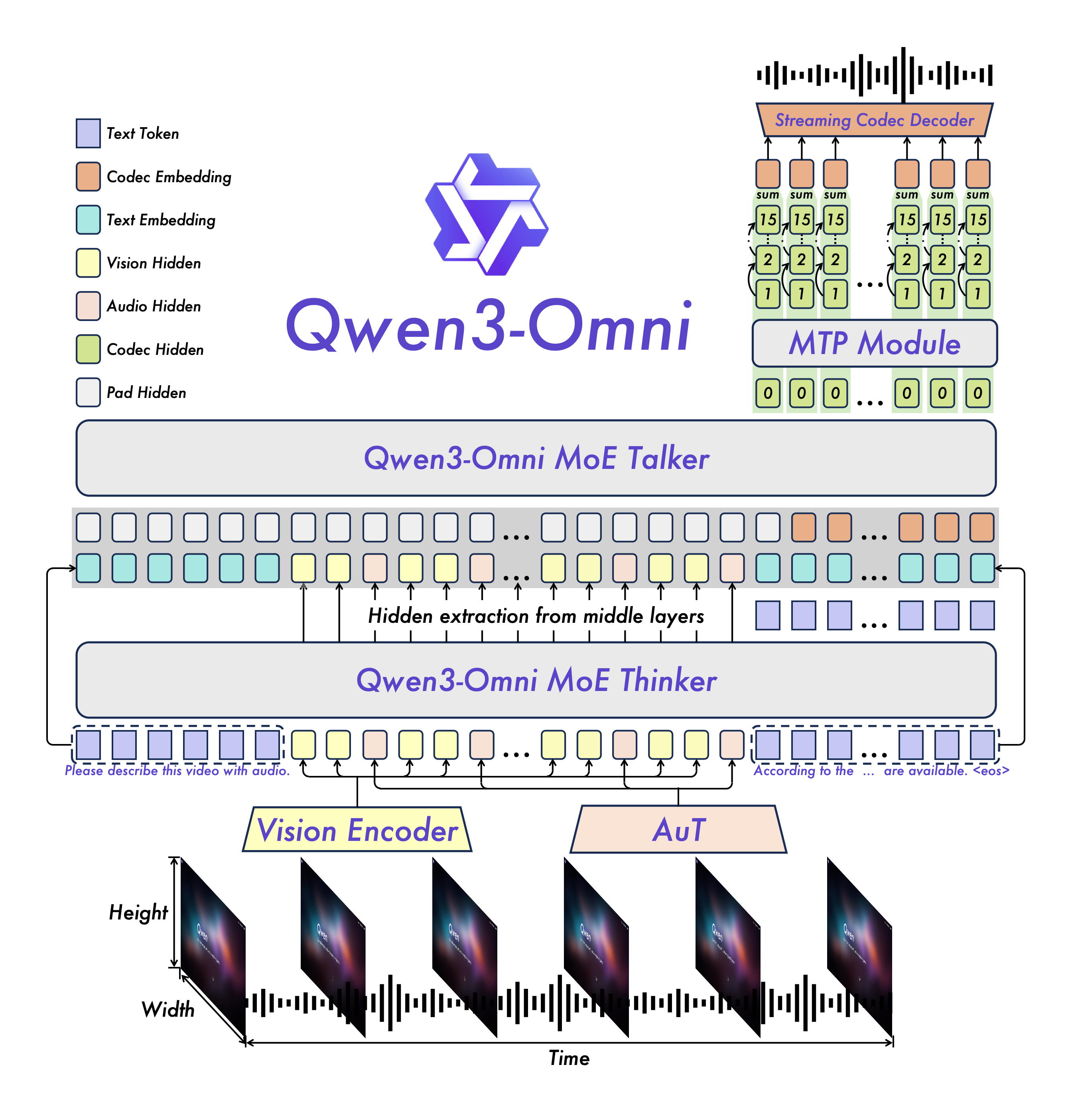
语音转写步骤
- 音频输入:支持土耳其语语音输入
- 音频处理:使用qwen-omni-utils工具包处理音频
- 模型推理:调用Qwen3-Omni模型进行语音转写
- 文本输出:获取土耳其语转写结果
环境准备
模型下载
可以通过以下命令下载模型:
# 通过ModelScope下载(推荐用户)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni-30B-A3B-Instruct
# 通过Hugging Face下载
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni-30B-A3B-Instruct
依赖安装
pip install git+https://github.com/huggingface/transformers
pip install accelerate
pip install qwen-omni-utils -U
pip install -U flash-attn --no-build-isolation
土耳其语语音转写实现
单句语音转写示例
import soundfile as sf
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "./Qwen3-Omni-30B-A3B-Instruct"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
# 土耳其语语音转写对话
conversation = [
{
"role": "user",
"content": [
{"type": "audio", "audio": "turkish_audio.wav"}, # 土耳其语音频文件
{"type": "text", "text": "Transcribe this Turkish audio to text."}
],
},
]
# 推理准备
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=False)
inputs = processor(text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True)
inputs = inputs.to(model.device).to(model.dtype)
# 推理:生成输出文本
text_ids, _ = model.generate(**inputs, return_audio=False)
# 解码转写结果
transcription = processor.batch_decode(text_ids.sequences[:, inputs["input_ids"].shape[1]:],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
print("土耳其语语音转写结果:", transcription)
长音频转写示例
对于长音频转写,可以使用批处理方式:
# 长音频批处理转写示例
conversation1 = [
{
"role": "user",
"content": [
{"type": "audio", "audio": "turkish_long_audio_part1.wav"},
{"type": "text", "text": "Transcribe this Turkish audio to text."}
]
}
]
conversation2 = [
{
"role": "user",
"content": [
{"type": "audio", "audio": "turkish_long_audio_part2.wav"},
{"type": "text", "text": "Transcribe this Turkish audio to text."}
]
}
]
# 批处理对话
conversations = [conversation1, conversation2]
# 推理准备
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=False)
inputs = processor(text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True)
inputs = inputs.to(model.device).to(model.dtype)
# 批处理推理
text_ids, _ = model.generate(**inputs, return_audio=False)
# 解码转写结果
transcriptions = processor.batch_decode(text_ids.sequences[:, inputs["input_ids"].shape[1]:],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
for i, transcription in enumerate(transcriptions):
print(f"部分 {i+1} 转写结果:", transcription)
高级应用
vLLM加速推理
为提高推理速度,可以使用vLLM进行加速:
# 安装vLLM
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm
pip install -r requirements/build.txt
pip install -r requirements/cuda.txt
export VLLM_PRECOMPILED_WHEEL_LOCATION=https://wheels.vllm.ai/a5dd03c1ebc5e4f56f3c9d3dc0436e9c582c978f/vllm-0.9.2-cp38-abi3-manylinux1_x86_64.whl
VLLM_USE_PRECOMPILED=1 pip install -e . -v --no-build-isolation
vLLM推理代码:
import os
import torch
from vllm import LLM, SamplingParams
from transformers import Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
os.environ['VLLM_USE_V1'] = '0'
MODEL_PATH = "./Qwen3-Omni-30B-A3B-Instruct"
llm = LLM(
model=MODEL_PATH, trust_remote_code=True, gpu_memory_utilization=0.95,
tensor_parallel_size=torch.cuda.device_count(),
limit_mm_per_prompt={'image': 3, 'video': 3, 'audio': 3},
max_num_seqs=8,
max_model_len=32768,
seed=1234,
)
sampling_params = SamplingParams(
temperature=0.6,
top_p=0.95,
top_k=20,
max_tokens=16384,
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
messages = [
{
"role": "user",
"content": [
{"type": "audio", "audio": "turkish_audio.wav"},
{"type": "text", "text": "Transcribe this Turkish audio to text."}
],
}
]
text = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=False
)
audios, images, videos = process_mm_info(messages, use_audio_in_video=False)
inputs = processor(text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True)
outputs = llm.generate(inputs["input_ids"], sampling_params=sampling_params)
transcription = processor.batch_decode(outputs[0].outputs[0].token_ids, skip_special_tokens=True)
print("土耳其语语音转写结果:", transcription)
常见问题解决
音频格式问题
Qwen3-Omni支持多种音频格式,但推荐使用WAV格式。如果遇到音频格式不支持的问题,可以使用ffmpeg转换格式:
ffmpeg -i input.mp3 -acodec pcm_s16le -ar 16000 output.wav
性能优化
- 使用FlashAttention 2减少GPU内存占用
- 启用批处理推理提高效率
- 使用vLLM加速推理速度
总结与展望
Qwen3-Omni-30B-A3B-Instruct为土耳其语语音转写提供了强大的支持,通过本文介绍的方法,可以实现高效准确的土耳其语语音转写。未来,随着模型的不断优化,土耳其语语音转写的准确率和效率将进一步提升。
希望本文对你有所帮助,如果有任何问题或建议,请在评论区留言。别忘了点赞、收藏、关注三连,下期将为大家带来更多Qwen3-Omni的高级应用技巧!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)