TinyLLM创造一个专业微型大模型
TinyLlama-1.1B是新加坡科技设计大学开发的轻量级开源语言模型,仅1.1B参数却通过3万亿token训练实现高性能。它采用Transformer架构,支持2048token上下文,量化后仅550MB,可在移动端和边缘设备运行。在常识推理、代码生成等任务中表现优于同类模型,兼容主流AI工具链并允许商用。适用于物联网、离线助手等场景,GitHub星标超4.7K,展现了"小而强&qu
·
TinyLlama-1.1B 是一个轻量级高性能的开源大语言模(LLM),由新加坡科技设计大学(SUTD)的研究团队开发,旨在探索小型语言模型(SLM)在大规模数据训练下的潜力。
应用场景:
1、训练专业微型小模型
2、移动端微型小模型应用
3、物联网终端微型小模型应用
核心特点:
- 轻量化设计
- 仅 1.1B 参数,远小于主流大模型(如 GPT-3 的 175B),但通过大规模数据训练(3万亿 token)优化性能。
- 量化后模型可小至 550MB,能在消费级显卡(如 RTX 3060)甚至手机端运行。
- 高性能表现
- 在常识推理、代码生成等任务中超越同规模模型(如 Pythia-1.4B)。
- 支持 2048 token 上下文长度,适合长文本生成。
- 开源与生态友好
- 采用 Apache 2.0 许可证,允许商用和修改。
- 兼容 Hugging Face、llama.cpp 等工具链,提供多种量化版本(GPTQ、GGUF 等)。
- 应用场景
- 边缘设备(如树莓派)、离线助手、低成本 AI 开发。
- 微调后可用于聊天机器人(如 TinyLlama-1.1B-Chat)。
模型对比:
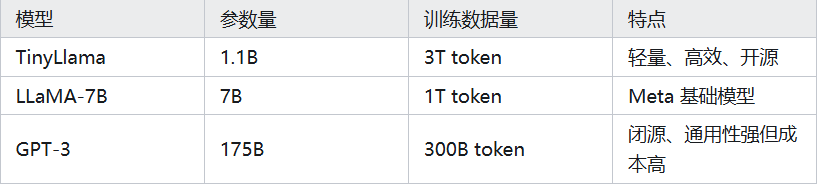
TinyLlama 是 “小而强” 的典范,通过数据规模和架构优化,在低资源场景下提供接近大模型的能力。其名称直观体现了设计目标——在轻量化与性能间取得平衡
1. 模型架构与参数
- 参数规模:1.1亿(1.1B)参数,基于纯解码器(Decoder-only)的Transformer架构,与Meta的Llama 2保持一致,兼容Llama生态。
- 结构优化:采用组查询注意力(GQA)机制,22层网络,每层32个注意力头和4个查询组,嵌入维度为2048,序列长度支持2048 tokens。
2. 训练数据与效率
- 训练数据量:在约3万亿token的混合数据集(SlimPajama-627B、StarCoder等)上预训练,远超传统小模型的数据规模。
- 训练效率:通过Flash Attention 2、FSDP(全分片数据并行)、xFormers等技术优化,单卡A100-40G训练速度达24k tokens/秒,仅需16块GPU在90天内完成训练。
3. 性能表现
- 下游任务:在常识推理、代码生成等任务中超越同规模模型(如OPT-1.3B、Pythia-1.4B),部分任务接近大模型水平。
- 推理速度:量化后可在消费级硬件(如RTX 3090/4090)高效运行,实测GTX 3060上生成速度达136 tokens/秒。
4. 应用场景
- 边缘计算:4-bit量化版本仅需550MB内存,适合物联网设备、离线翻译等场景。
- 辅助开发:支持代码生成、推测解码(Speculative Decoding)以加速大模型推理。
- 对话与创作:提供微调的聊天版本(如TinyLlama-1.1B-Chat),遵循Zephyr提示模板,适用于聊天机器人和内容生成。
5. 开源与生态
- 许可证:Apache 2.0开源,提供多种量化版本(GPTQ、GGUF等),兼容Hugging Face、llama.cpp等框架。
- 社区热度:GitHub项目星标超4.7K,衍生出更小模型如LiteLlama-460M
参考:
模型下载

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)