Local Patterns Generalize Better for Novel Anomalies
视频异常检测(VAD)旨在识别训练中未见过的新动作或事件。现有的主流VAD技术通常关注包含冗余细节的全局模式,难以泛化到未见过的样本。在本文中,我们提出了一个框架,该框架能够识别可泛化到新样本的局部模式,并对局部模式的动态进行建模。提取空间局部模式的能力通过包含图像-文本对齐和跨模态注意力的两阶段过程实现。我们通过聚焦语义相关的组件来构建可泛化的表示,这些组件可以重新组合以捕捉新异常的本质,减少不

ICLR '25
https://openreview.net/pdf?id=4ua4wyAQLm
GitHub - AllenYLJiang/Local-Patterns-Generalize-Better
ABSTRACT
视频异常检测(VAD)旨在识别训练中未见过的新动作或事件。现有的主流VAD技术通常关注包含冗余细节的全局模式,难以泛化到未见过的样本。在本文中,我们提出了一个框架,该框架能够识别可泛化到新样本的局部模式,并对局部模式的动态进行建模。提取空间局部模式的能力通过包含图像-文本对齐和跨模态注意力的两阶段过程实现。我们通过聚焦语义相关的组件来构建可泛化的表示,这些组件可以重新组合以捕捉新异常的本质,减少不必要的视觉数据差异。为了用时间线索增强局部模式,我们提出了一个状态机模块(SMM),该模块利用早期的高分辨率文本标记来指导后续低分辨率观测的精确字幕生成。此外,时间运动估计补充了空间局部模式,以检测具有新空间分布或独特动态特征的异常。在流行的基准数据集上进行的大量实验表明,该框架实现了最先进的性能。代码可在https://github.com/AllenYLJiang/Local-Patterns-Generalize-Better/获取。
1 INTRODUCTION
视频异常检测(VAD)的任务是从视频中定位偏离常规模式的事件,如暴力、事故和其他意外事件。如今,闭路电视(CCTV)和无人机(UAV)等众多平台在监控领域发挥着越来越重要的作用。然而,鉴于海量的视频数据和异常事件的低发生概率,人工手动检测这些事件并不现实。此外,正常事件与异常事件之间的视觉数据差异和领域差异也会影响检测方法的有效性。因此,视频异常检测已成为弱监督或无监督学习领域的重要研究课题[Gong等人,2019;Shi等人,2023b;Chalapathy等人,2017;Lu等人,2020;Pang等人,2020;Lv等人,2021;Georgescu等人,2021a;Zaheer等人,2020b;Ristea等人,2021;Acsintoae等人,2021]。
现有主流的视频异常检测工作[Li等人,2022c;Luo等人,2021a;Georgescu等人,2021a]可分为四类:
1. **第一类方法**通过利用独特的时空特征检测异常,包括基于预测的方法[Luo等人,2021a;Lv等人,2021;Lu等人,2020;Park等人,2020]和基于重建的方法[Yang等人,2023b;Lv等人,2023;Chang等人,2020;Liu等人,2021]。为增强表示能力,部分方法结合多粒度时空表示[Zhang等人,2024]以提升判别力,或融合多特征[Georgescu等人,2021a;Cho等人,2023]以更好地对齐未见过的样本[Liu等人,2022b]。
2. **第二类方法**采用多实例学习(MIL)迭代识别有用数据段并微调异常检测模型[Cho等人,2023;Wang等人,2022a;Li等人,2022a;Zhu等人,2022;Liu等人,2023c]。例如,动态聚类技术使模型表示适应实时观测[Wu等人,2022;Yang等人,2022],提示增强的MIL[Chen等人,2024]则将语义先验与视觉特征结合以改进异常建模。然而,由于背景噪声导致视觉数据差异下的表示不一致,其泛化能力仍不足(如图1所示)。
3. **第三类方法**[Liu等人,2023c]侧重于生成真实异常样本以优化正常与异常样本的决策边界。基于提示的方法[Wu等人,2024a]也被用于生成伪异常,但生成的异常依赖先验假设,无法覆盖现实场景中多样且意外的异常样本。
4. **第四类方法**[Zanella等人,2024]利用大型模型的视觉-语言知识和推理能力[Yang等人,2024a]生成文本描述或自训练伪标签[Yang等人,2024b],从而提升对异常事件的判别力[Micorek等人,2024]。
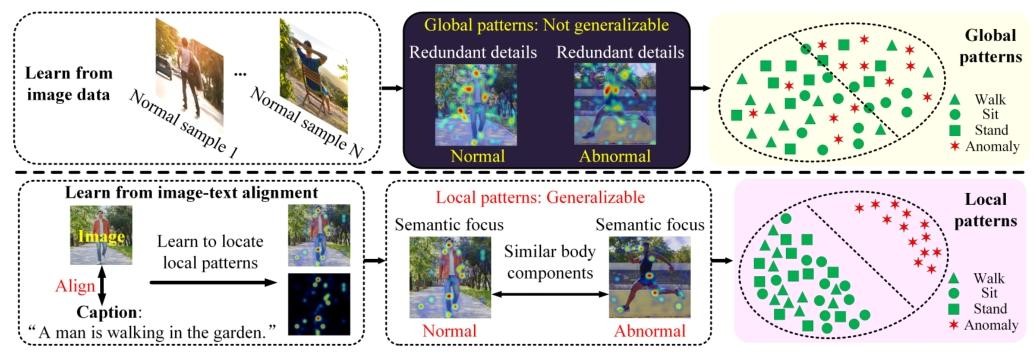
图1:上图:现有方法依赖包含冗余细节的全局模式,这些模式在视觉数据变化时表现不一致,限制了其对新样本的泛化能力。因此,正常样本与异常样本难以有效区分。下图:我们的方法聚焦于捕捉语义有意义特征(如人体关节)的局部模式,这些模式在不同域之间保持一致且泛化能力强。这些局部模式的空间分布突出了差异。
为了使模型表示能够泛化到新异常,我们提出了一个用于识别局部模式的两阶段框架。在第一阶段,图像-文本对齐用于定位在视觉数据变化中保持一致的文本信息丰富的局部模式。第二阶段使用跨模态注意力进一步细化局部模式,生成更紧凑的局部模式。最后,空间局部模式通过时间线索增强,以更好地判定异常。
综上所述,所提出的框架由图像-文本对齐模块(ITAM)和跨模态注意力模块(CMAM)组成,通过两个阶段识别局部模式。ITAM 选择文本信息丰富的区域,将高维视觉数据转换为高效的图像标记(image tokens)。这些标记由时间句子生成模块(TSGM)转换为文本,CMAM 利用这些文本细化图像标记的选择,将其作为局部模式。时间线索通过两种方式增强局部模式:TSGM 通过考虑多时刻上下文生成用于跨模态注意力的句子,而时间运动估计则通过时间动态丰富空间局部模式。该方法的有效性在多个基准数据集(包括 ShanghaiTech、Ubnormal 等)上得到了验证。主要贡献如下:
- 本文提出了一种新颖的两阶段方法,用于识别在视觉数据变化中保持一致并可泛化到新型异常样本的局部模式。第一阶段利用图像-文本对齐来识别语义有意义的组件,从而构建可泛化的表示。跨模态注意力进一步细化这些组件,既发挥了文本在泛化能力上的优势,又保留了视觉特征在细节表示上的长处。
- 采用时间解决方案来增强空间局部模式。首先,时间句子生成通过整合不同时刻的上下文来生成连贯的事件描述。此外,时间运动估计通过对动态进行建模来补充局部模式。
- 所提出的框架在多个基准测试中实现了最先进的性能。
2 RELATED WORKS
2.1 UNSUPERVISED VIDEO ANOMALY DETECTION
由于监控视频的不平衡性,大多数训练数据集缺乏异常标注,因为标注成本高昂[Li等人,2022b;Liu等人,2023b;Deng等人,2023]。基于重建的方法[Astrid等人,2024;Yang等人,2023b;Fang等人,2020;Li等人,2020a;Gong等人,2019;Asad等人,2021;Abati等人,2019;Sabokrou等人,2018]在遇到训练数据中不存在的不规则特征时会产生更大的误差[Ramachandra等人,2020;Madan等人,2023;Yu等人,2023]。例如,Zaheer等人(2022a)的方法学习不重建异常。Gong等人(2019)和Gao等人(2022)通过增强编码器来提高重建误差对异常的敏感性。Madan等人(2021)、Chang等人(2020)、Singh等人(2023)、Yu等人(2022b)和Shi等人(2023a)融合了多模态特征[Ding等人,2021],而Huang等人(2022)则集成了概率决策模型。Zaheer等人(2022b)通过评估重建质量来提高稳定性。基于预测的方法[Luo等人,2021b;Morais等人,2019;Luo等人,2021a;Liu等人,2018;Nguyen & Meunier,2019;Zeng等人,2021]利用潜在空间[Zhang等人,2020]或混合注意力[Zhang等人,2022b]评估正常和异常时间依赖关系的差异。
为了更好地区分异常,Lv等人(2021);Lu等人(2020);Liu等人(2021);Park等人(2020);Li等人(2021a)将预测与重建相结合。Sato等人(2023);Wu等人(2023);Luo等人(2019)研究了正常样本的分布并提出了新特征[Arad & Werman,2023]。类似地,Yan等人(2023)提出了去噪扩散模块。Flaborea等人(2023)利用扩散概率模型增强的模式覆盖能力。为了提高表示能力,Chang等人(2021);Fan等人(2024)提出了片段级注意力。Liu等人(2023a);Yu等人(2022a);Purwanto等人(2021)引入金字塔变形和条件随机场(CRFs)来学习时空依赖关系[Bertasius等人,2021;Cho等人,2022]。Wang等人(2021)结合多尺度特征以增强预测。Stergiou等人(2024)将插值与外推结合用于预测。Wang等人(2022b)提出了一种具有判别性深度神经网络的自监督方案。我们提出可泛化的局部模式以更好地表示未见样本。
2.2 WEAKLY SUPERVISED ANOMALY DETECTION
多实例学习(MIL)将视频视为“包”(bags)、视频片段视为“实例”(instances),将视频级标签转化为实例级标签[Feng等人,2021]。这类方法通过迭代定位异常片段,并利用与正常片段不同的异常片段对模型进行微调[Zhang等人,2023a]。为了收集异常片段,研究者基于时空相似性评估样本间距离[Lu等人,2022;Ionescu等人,2019],相关工作包括Dhiman & Vishwakarma(2020)、Lv等人(2023)、Chang等人(2020)、Markovitz等人(2020)。Li等人(2021b)提出了一种概率框架。Sun等人(2020)和Li等人(2020b)构建图表示并整合集体属性以度量相似性。Sapkota & Yu(2022)进行动态非参数聚类。为提高鲁棒性,Zhang等人(2023b)提出解释MIL的脆弱性,Wu & Liu(2021)引入因果关系增强MIL[Tian等人,2021],Yang等人(2023a)提出二元网络增强策略。与上述方法不同,我们提出可泛化表示,以促进已见和未见事件之间的相似性度量。
2.3 METHODS WITH DATA AUGMENTATION
为了在微调阶段生成伪异常样本,Liu等人(2023c)、Lin等人(2022)、Kim等人(2022)、Liu等人(2022a)和Astrid等人(2021)提出了基于正常样本训练的伪异常片段合成器[Yu等人,2021]。Zaheer等人(2020a)使用未充分训练的生成器创建异常样本。Chen等人(2022)通过条件生成对抗网络(GAN)生成类别平衡的训练数据。Lim等人(2018)在生成过程中利用新型采样策略,聚焦于罕见正常样本。除了帧级分析[Zaheer等人,2020b],目标级方法[Sun & Gong,2023;Ionescu等人,2019;Luo等人,2021a]提供了细粒度分析。Acsintoae等人(2022)引入了包含多样化异常的新数据集。然而,生成数据缺乏真实世界模式,凸显了可泛化模式的必要性。
2.4 METHODS EXPLORING THE REPRESENTATION OF UNSEEN CATEGORIES
为了使模型表示适应不断变化的异常并在其下工作,基于元学习的方法[Lu等人,2020;Park等人,2020]、基于迁移学习的方法[Doshi & Yilmaz,2020;Perini等人,2022]、持续学习[Doshi & Yilmaz,2020]和自监督方法[Pang等人,2020;Degardin & Proença,2021]引入了可适应的特征表示。基于注意力的方法[Sultani等人,2018;Guo等人,2023;Li等人,2021c;Luo等人,2017]在处理未见样本时关注领域不变特征。为了更好地与异常检测对齐,Georgescu等人(2021a)集成了多个子任务。Zhou等人(2023a)引入层次图来表示视频并最大化类间间隔。不同的是,我们的方法定位可泛化到未见事件的文本信息丰富的局部模式。
2.5 PROMPTING METHODS
基于提示的方法已在异常检测中得到广泛应用[Du等人,2022;Liu等人,2023c;Sato等人,2023]。例如,Zhou等人(2023b)学习与物体无关的文本提示以实现广义异常识别。Yang等人(2024a)提出基于规则的推理来实现少样本正常数据提示。与使用直接提示的方法不同,我们探索视觉语言模型(VLM)中连接图像和文本的局部模式。
3 METHODOLOGY
为了使用可泛化的表示来刻画未知异常,我们构建了一个能够识别文本信息丰富的局部模式的框架。该框架通过图像-文本对齐模块(ITAM)和跨模态注意力模块(CMAM)分两个阶段定位空间局部模式,如图2(a)所示。为了利用时间线索增强局部模式,我们研究了时间句子生成和时间运动估计方法。首先,时间句子生成模块(TSGM)对前序文本标记与后续图像标记之间的依赖关系进行建模,为CMAM提供增强的输入句子,如图2(b)所示。然后从视频压缩中提取跨帧运动向量。最后,空间和时间线索在重建模块(RM)中结合以检测异常。在接下来的部分中,我们将讨论每个模块。
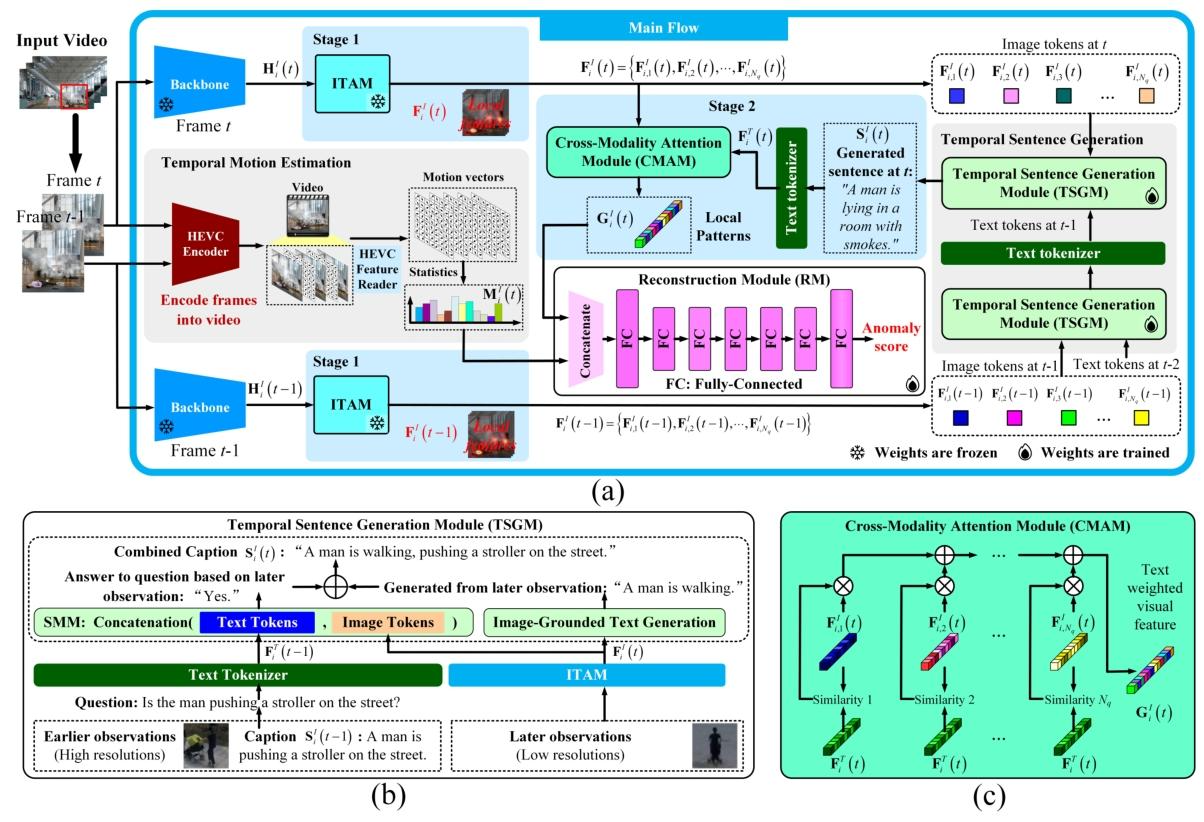
图2:方法结构示意图。 (a)主要流程:使用主干网络和图像-文本对齐模块(ITAM)提取视觉特征,ITAM将文本信息丰富的局部特征识别为图像标记(image tokens)。基于图像标记,时间句子生成模块(TSGM)生成句子,随后通过跨模态注意力模块(CMAM)将句子与图像标记结合,以突出关键模式。HEVC编码器通过视频压缩估计帧间运动。空间局部模式和运动特征通过重建模块联合分析以检测异常。 (b)TSGM利用状态机模块(SMM)基于图像标记和前序句子生成句子。 (c)CMAM基于图像-文本相似度实现。
3.1 CROPPING OF IMAGE REGIONS
由于某些帧的视野较广,包含众多物体,即使是GPT-4 [Achiam等人,2023]也难以同时关注所有物体。因此,我们将局部区域裁剪作为流程的第一步。我们尝试了使用YOLOv7 [Wang等人,2023]和Qwen-7B [Bai等人,2023]基于提示裁剪边界框区域。具体来说,将“有多少人?”和“第i个物体的边界框”依次提供给Qwen-7B,该模型会返回相应的边界框。相关比较将包含在附录D中。
3.2 STAGE 1 FOR IDENTIFYING SPATIAL LOCAL PATTERNS
这一阶段识别裁剪图像区域中与文本对齐的特征。这些文本描述通用的运动属性(例如,“一个人正在摆动双臂和双腿行走”)。当遇到未见过的动作(如跑步)时,模型可以重新组合已知组件(如手臂和腿部)来生成描述性语言,捕捉动作的本质而无需显式命名。如图1所示,热图显示了对局部组件的关注,突出了共享属性的相似语义区域。更多可视化结果见图表4。
为了识别与文本对齐的局部模式,我们分别采用冻结的图像编码器Li等人(2023)和BLIP-2中的Q-Former图像转换器Li等人(2023)作为主干网络和ITAM模块。主干网络输出\(H_{i}^{I}(t) \in \mathbb{R}^{S_{d} ×V_{d}}\),Q-Former包含图像转换器和文本转换器以对齐跨模态特征,其图像转换器的输出为\(F_{i}^{I}(t) \in \mathbb{R}^{N_{q} ×H_{d}}\),包含\(N_{q}\)个图像标记\(F_{i, 1}^{I}(t), ..., F_{i, N_{q}}^{I}(t)\),这些标记表征图像区域i的文本描述信息,并在视觉数据变化中保持一致性(如图4的热图所示)。详细结构见附录C,算法1展示了第一阶段和第二阶段的工作流程。

算法1 用于识别空间局部模式的两阶段流程
1: 输入:输入图像、主干网络、图像-文本对齐模块(ITAM)、跨模态注意力模块(CMAM)、时间句子生成模块(TSGM)和文本标记器
2: 输出:表示空间局部模式的跨模态嵌入 \(G^I_i(t)\)
3: 阶段1:图像标记提取
4: 使用主干网络提取特征图 \(H^I_i(t)\)
5: 将 \(H^I_i(t)\) 输入ITAM,获取与文本对齐的图像标记 \(\{F^I_{i,j}(t)\}_{j=1}^{N_q}\)
6: 阶段2:跨模态注意力
7: 将图像标记 \(\{F^I_{i,j}(t)\}_{j=1}^{N_q}\) 输入TSGM,获取文本标记 \(F^T_i(t)\)
8: CMAM根据图像标记与 \(F^T_i(t)\) 的相似度,对 \(\{F^I_{i,j}(t)\}_{j=1}^{N_q}\) 进行加权求和
9: 返回:返回加权和 \(G^I_i(t)\),即表示跨模态特征的结果
3.3 STAGE 2 FOR IDENTIFYING LOCAL PATTERNS
该阶段通过基于图像标记生成句子并根据图像标记与生成句子的相似度进行加权求和,进一步突出局部模式。如图2(a)所示,TSGM利用第一阶段的图像标记\(F_{i, 1}^{I}(t), ..., \tilde{F_{i, N_{q}}^{I}}(t)\)为图像区域i生成句子。TSGM采用SMM(状态机模块)进行跨帧字幕增强,并使用冻结的Q-Former模型[Li等人,2023]进行图像 grounding 文本生成。SMM用于判断先前事件是否仍存在于当前帧中,而Q-Former负责对当前帧进行字幕描述。SMM和Q-Former的输出相结合,形成增强后的句子\(S_{i}^{I}(t)\)。即使在时刻t的观测不完整,只要先前事件仍存在,\(S_{i}^{I}(t)\)仍能从当前帧中识别出这些事件。
句子\(S_{i}^{I}(t)\)的嵌入\(F_{i}^{T}(t) \in \mathbb{R}^{S_{l} ×H_{d}}\)(其中\(S_{l}=32\)表示单句中标记的最大数量)被输入到跨模态注意力模块(CMAM)。如图2(c)和公式(1)所示,CMAM使用\(F_{i}^{T}(t)\)的第一个元素作为查询(query),并将图像标记作为键(keys)和值(values)进行注意力操作:
\[G_{i}^{I}(t)=\left(F_{i}^{T}(t)[0] F_{i}^{I}(t)^{\top}\right) F_{i}^{I}(t), G_{i}^{I}(t) \in \mathbb{R}^{H_{d}}\] \(F_{i}^{T}(t)\)
由Q-Former中的文本转换器生成[Li等人,2023],其第一个元素\(F_{i}^{T}(t)[0]\)代表整个句子。公式(1)根据图像标记与\(F_{i}^{T}(t)\)的余弦相似度对图像标记进行加权求和。通过这种方式,既实现了图像标记在刻画视觉细节方面的优势,又发挥了文本特征在视觉数据变化中泛化的优势。消融实验将对比\(G_{i}^{I}(t)\)与单模态特征的性能差异。
3.4 TEMPORAL SENTENCE GENERATION IN STAGE 2
在第二阶段,字幕生成会受到低分辨率等视觉数据变化的影响。如图2(b)所示,用于图像关联文本生成的模块[Li等人,2023]在后续低分辨率观测中仅能提供粗略的字幕(如“一个人在行走”),尽管与早期字幕“一个人在街上推婴儿车”描述的是同一事件,但其精确性较低。因此,TSGM中的状态机模块(SMM)会判断早期高分辨率事件是否在后续图像标记中有所体现。该模块捕捉帧间依赖关系并优化句子连贯性,利用早期文本标记为低分辨率观测生成精确字幕。连续帧中的物体通过边界框的交并比(IoU)相似性进行关联。
具体来说,状态机模块(SMM)通过将早期字幕\(S_{i}^{I}(t-1)\)从陈述句转换为疑问句来增强图像标记\(F_{i}^{I}(t)=\{F_{i, 1}^{I}(t), ..., F_{i, N_{q}}^{I}(t)\}\)。例如,“The man is pushing a stroller.”(该男子正在推婴儿车)会被转换为“Is the man pushing a stroller?”(该男子是否在推婴儿车?),其文本标记为\(F_{i}^{T}(t-1)=\{F_{i, 1}^{T}(t-1), ..., F_{i, S_{l}}^{T}(t-1)\}\)。这种转换的细节将在附录G中展示[Hardeniya等人,2016]。如图2(b)所示,SMM将\(F_{i}^{T}(t-1)\)与\(F_{i}^{I}(t)\)结合作为输入。SMM中的状态机沿输入序列维度演化: \[V_{i}(t)=[F_{i, 1}^{T}(t-1) ; ... ; F_{i, S_{l}}^{T}(t-1) ; F_{i, 1}^{I}(t) ; ... ; F_{i, N_{q}}^{I}(t)]^{\top} \in \mathbb{R}^{H_{d} \times(S_{l}+N_{q})}\] 其中\(L=S_{l}+N_{q}\)为序列长度,每个标记的维度为\(H_{d}\)。SMM基于该序列预测二元决策(“是”或“否”),判断\(\hat{S}_{i}^{I}(t-1)\)中的事件是否仍存在于\(F_{i}^{I}(t)\)中。\(V_{i}(t)\)被视为\(H_{d}\)个一维信号的组合,每个信号长度为\(L\)。序列中的依赖关系使用\(o\)个长度为\(L\)的勒让德多项式表示[Arfken等人,2011]: \[[g_{o}(1), ..., g_{o}(L)], \quad o \in[1, O]\] 如附录A的图6所示。输入张量\(V_{i}(t)\)通过\(o\)个固定多项式的加权和进行近似。为简化起见,以下沿任意时刻\(t\)输入张量列维度进行的分析中省略时间索引\(t\)。特征空间编码器生成: \[U_{i}(t)=[u_{i}(l-L+1) ; ... ; u_{i}(l)]^{\top} \in \mathbb{R}^{O ×L}\] 其中\(u_{i}(l')=[u_{i, 1}(l'), ..., u_{i, O}(l')]\),\(l' \in(l-L, l]\)。此处\(l\)沿\(V_{i}(t)\)和\(U_{i}(t)\)的列维度变化,\((l-L, l]\)是由\(c_{i}(l)\)共同编码的列窗口。
为了更好地对\(H_{d}\)维信号的多模态序列进行建模,状态机模块(SMM)中堆叠了\(N_{SMM}\)个状态机,每个状态机预测未来\(\Delta l / N_{SMM}\)步的信息,如图3所示。消融研究将展示这一设计的优势。公式(2)展示了使用基函数表示的\(U_{i}(t)\):
\[u_{i, o}\left(l'\right)=c_{i, o}(l) g_{o}\left(l'-l+L\right), o \in[1, O], l' \in(l-L, l]\]
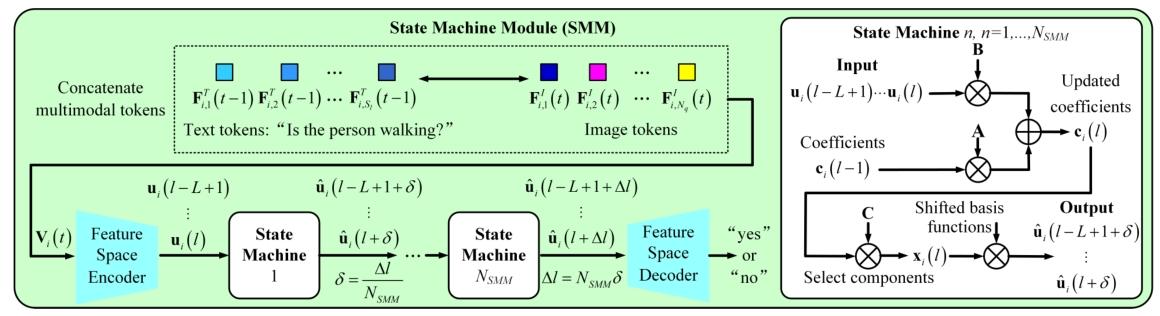
图3:状态机模块(SMM)的结构,该模块堆叠了\(N_{SMM}\)个状态机,每个状态机预测提前δ步的信息。
在状态机模块(SMM)中,状态向量\(c_{i}(l)=[c_{i, 1}(l) ; ... ; c_{i, O}(l)]^{\top}\)通过\(o\)个权重对\(V_{i}(t)\)中文本与视觉标记之间的依赖关系进行编码,这些依赖关系被分解到加权勒让德基函数上。状态向量的演化过程为预测(“是”或“否”)提供信息。
\[c_{i}(l+1)=Ac_{i}(l)+B\sum _{o=1}^{O}u_{i,o}(l+1) \ (3)\]
该公式 \(c_{i}(l+1) = A c_{i}(l) + B \sum_{o=1}^{O} u_{i,o}(l+1)\) 是状态机模块(SMM)中状态向量的递归更新规则,用于捕捉多模态序列(文本 + 视觉标记)中的时序依赖关系,核心作用是:
- 通过历史状态 \(c_{i}(l)\) 与当前输入 \(u_{i,o}(l+1)\) 的线性组合,动态更新模型对序列依赖的 “记忆”;
- 最终基于更新后的状态 \(c_{i}(l+1)\) 预测事件是否存在(“是 / 否”)。
其中\(A=A(O, L) \in \mathbb{R}^{O ×O}\)和\(B=B(O, L) \in \mathbb{R}^{O ×1}\)由勒让德多项式推导而来[Gu等人,2020]。随着\(o\)的增大,更多样化的基函数可以表示更复杂的依赖关系。假设\(c_{i}(l)\)对\(u_{i}(l-L+1), ..., u_{i}(l)\)进行编码,并基于此预测\(u_{i}(l+1)\),其中\(u_{i}(l+1)\)表示“是”或“否”。\(c_{i}(l+1)\)则对\(u_{i}(l-L+2), ..., u_{i}(l+1)\)进行编码。公式(3)的推导过程将在附录A中给出。在图3所示的SMM中,变换\(x_{i}(l)=C c_{i}(l)\)(其中\(C \in \mathbb{R}^{O ×O}\)为可学习矩阵)用于突出重要分量,此时公式(3)可转换为:
\[x_{i}(l)=C A^{L-1} B \sum_{o=1}^{O} u_{i, o}(l-L+1)+...+C B \sum_{o=1}^{O} u_{i, o}(l)\]
最后,将\(x_{i}(l)\)的元素与移位基函数\([g_{o}(1+\delta), ..., g_{o}(L+\delta)]\)(其中\(o \in [1, O]\),\(\Delta l=1\),\(\delta=\Delta l / N_{SMM}\))相乘,生成移位加权基函数:
\[ \hat{u}_{i, o}\left(l'+\delta\right)=x_{i, o}(l) g_{o}\left(l'-l+L+\delta\right), \ o \in[1, O], \ l' \in(l-L, l] \]
该公式是状态机模块(SMM)中实现时序移位预测的关键方程,用于生成 “提前 δ 步” 的特征表示,支持多状态机堆叠时的细粒度时序建模。其核心作用是:
- 通过当前状态特征 \(x_{i,o}(l)\) 与移位后的勒让德多项式 \(g_o(\cdot)\) 相乘,将序列依赖关系映射到未来时间点(\(l'+\delta\)),实现亚步长(sub-step)预测;
- 配合 \(N_{SMM}\) 个状态机的堆叠设计(每个预测 \(\delta = 1/N_{SMM}\) 步),提升时序依赖建模的精度。
特征空间解码器将\(\hat{u}_{i}(l+\delta)=[\hat{u}_{i, 1}(l+\delta), ..., \hat{u}_{i, O}(l+\delta)]\)投影到预测结果(“是”或“否”),如图3所示。我们采用交叉熵损失函数。在每个批次中,\(B_{s}\)张图像对应\(B_{s}\)个陈述句,这些陈述句被转换为\(B_{s}\)个疑问句。每张图像的标记与对应疑问句的标记在输入到SMM之前进行拼接。
\[L_{S M M}=-\sum_{i=0}^{B_{s}-1} \sum_{j=0}^{B_{s}-1} y_{i, j} \log \left(\frac{\operatorname{Sim}(P(i, j), \operatorname{Emb}(“yes”))}{\operatorname{Sim}(P(i, j), \operatorname{Emb}(“yes”))+\operatorname{Sim}(P(i, j), \operatorname{Emb}(“no”))}\right)\]
强制 SMM 的输出嵌入 \(P(i,j)\) 与真实标签 \(y_{i,j}\) 对齐,确保模型在低分辨率或视觉变化场景中准确判断历史事件是否持续存在。
其中,当Qwen-Chat模型[Bai等人,2023]接收疑问句3和图像i并返回“是”时,真实标签\(y_{i, j}\)为1,否则为0。\(\operatorname{Sim}(P(i, j), \operatorname{Emb}(“yes”))\)表示SMM输出的嵌入\(P(i, j)\)与“是”的嵌入之间的余弦相似度。
3.5 TEMPORAL MOTION ESTIMATION AND SPATIO-TEMPORAL ANOMALY DETECTION
为了增强从第二阶段获得的空间局部模式,本文提出使用FFmpeg将帧编码为H.265(HEVC)视频[Zeng等人,2016]。如图2(a)所示,从编码视频中提取运动向量,每个运动向量与一个8×8宏块相关联。每个运动向量的方向通过\(atan2(y, x)\)计算,并量化为\(D_m=8\)个等距区间,其中x和y分别为水平和垂直分量。这些区间内运动向量的平均幅度生成一个\(D_m\)维直方图\(M_i^I(t)\),用于表示区域i。为了增强从第二阶段获得的空间局部模式,本文提出使用FFmpeg将帧编码为H.265(HEVC)视频[Zeng等人,2016]。如图2(a)所示,从编码视频中提取运动向量,每个运动向量与一个8×8宏块相关联。每个运动向量的方向通过\(atan2(y, x)\)计算,并量化为\(D_m=8\)个等距区间,其中x和y分别为水平和垂直分量。这些区间内运动向量的平均幅度生成一个\(D_m\)维直方图\(M_i^I(t)\),用于表示区域i。
为了检测具有异常局部模式或不规则动态的异常事件,本文使用7层全连接的重建模块(RM)在正常的空间和时间数据上进行训练。如图2(a)所示,第一层接收局部模式\(G_{i}^{I}(t)\)和动态特征\(M_{i}^{I}(t)\)的拼接,将\(H_{d}+D_{m}\)个输入通道映射到\(D_{h}\)个输出通道,而最后一层将\(D_{h}\)个输入通道映射回\(H_{d}+D_{m}\)个输出通道。中间5个隐藏层均具有\(D_{h}\)个输入和输出通道。空间特征与时间特征的重建同步进行,使两者的重建过程能够相互依赖。重建误差用于确定异常分数。
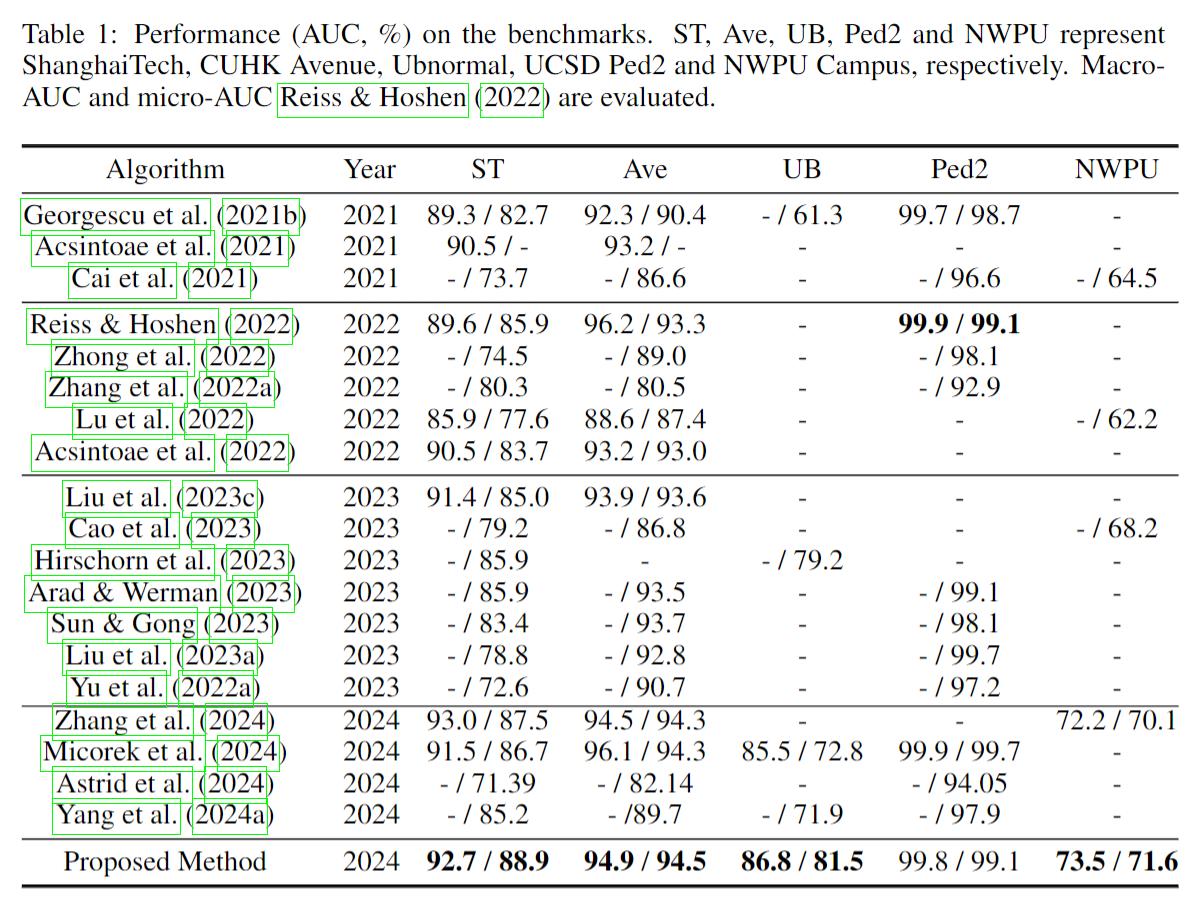
4 EXPERIMENTS AND RESULTS
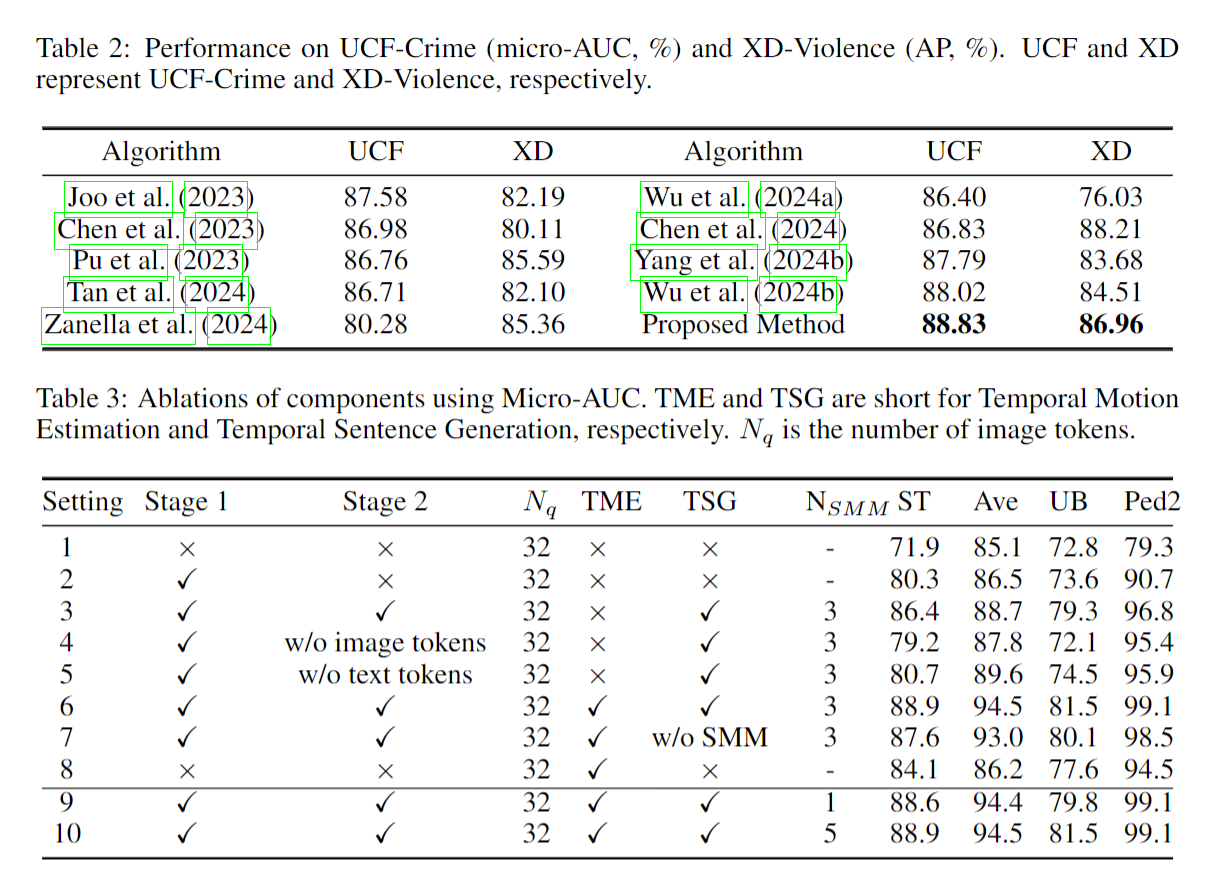
5 DISCUSSION AND CONCLUSION
局限性:我们工作的局限性在于对目标检测器的依赖,因为使用视觉语言模型(VLM)直接处理包含许多物体的图像可能导致上下文被忽略。更多潜在的改进方向请参考附录J。
结论:在本文中,我们建立了一个视频异常检测框架,通过图像-文本对齐和跨模态注意力定位局部模式。该框架的核心是识别可泛化到新型异常的文本信息丰富的局部模式,确保在新型视觉数据中表示的一致性。此外,时间句子生成和运动估计分别增强了跨模态注意力并补充了空间局部模式。大量实验表明,该框架超越了现有的最先进方法。
C: 图像 - 文本对齐与图像锚定文本生成模块的架构
ITAM是Q-Former的图像转换器[Li等人,2023],如图8所示。它输出\(F_{i}^{I}(t) \in \mathbb{R}^{N_{q} ×H_{d}}\),在训练过程中与文本转换器的输出对齐[Li等人,2023],以学习提取与文本对齐的特征。图2中的文本标记器是Q-Former文本转换器的一部分[Li等人,2023]。在我们的工作中,ITAM和文本标记器是冻结的。
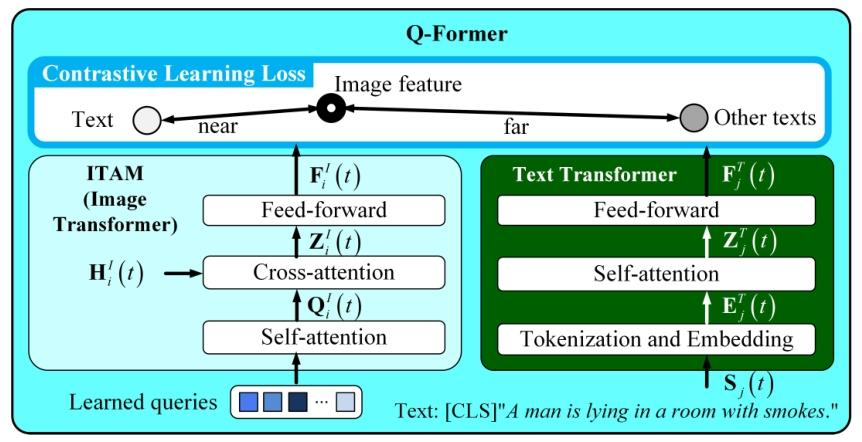
图8:ITAM是Q-Former中的图像转换器[Li等人,2023],其通过将图像转换器的视觉特征与文本转换器的文本特征对齐来识别局部特征。
图像转换器 为了从\(H_{i}^{I}(t)\)中筛选出包含文本描述信息的局部模式,该模块由自注意力层、交叉注意力层和前馈层构成,如图8所示。首先,\(N_{q}\)个可学习的查询嵌入在自注意力层中相互作用,随后通过交叉注意力层与\(\dot{H}_{i}^{I}(t)\)交互。每个查询嵌入的维度为\(H_{d}\)。图像注意力模块包含6个连续的Transformer层,每层均包含一个自注意力层、一个交叉注意力层和一个前馈层。\(H_{i}^{I}(t)\)作为所有Transformer层中交叉注意力层的静态输入。这些Transformer层通过学习到的查询逐步优化对\(H_{i}^{I}(t)\)的理解与整合。 每个自注意力层按Vaswani等人(2017)的方法实现,包含12个头,生成输出\(Q_{i}^{I}(t) \in \mathbb{R}^{N_{q} \times H_{d}}\)。每个交叉注意力层同样包含12个头,以\(H_{i}^{I}(t)\)作为键和值,通过将\(H_{i}^{I}(t)\)与\(Q_{i}^{I}(t)\)结合实现特征融合,生成\(Z_{i}^{I}(t) \in \mathbb{R}^{N_{q} \times H_{d}}\)。\(Z_{i}^{I}(t)\)经全连接前馈层投影得到\(F_{i}^{I}(t) \in \mathbb{R}^{N_{q} \times H_{d}}\)。
文本转换器 为了对文本描述进行编码,该模块由自注意力层和前馈层构成,如图8所示。自注意力层和前馈层由图像注意力模块与文本注意力模块共享。在自注意力模块中,最大长度为\(S_l\)的句子中的文本标记\(E_{j}^{I}(t)=[E_{j,1}^{I}(t), E_{j,2}^{I}(t), ..., E_{j,S_l}^{I}(t)] \in \mathbb{R}^{S_l \times H_d}\)之间相互进行注意力计算。其中\(S_l = N_q\),且\(E_{j,1}^{I}(t) \in \mathbb{R}^{H_d}\)、\(E_{j,2}^{I}(t) \in \mathbb{R}^{H_d}\)、…、\(E_{j,S_l}^{I}(t) \in \mathbb{R}^{H_d}\)。
为了缩短整个序列的嵌入,我们遵循Devlin等人(2018)的方法,在输入序列开头添加特殊标记[CLS],以便基于所有标记相互关注的特性来聚合信息。由于第一个标记包含整个序列的信息,因此我们仅保留文本转换器输出\(F_{i}^{T}(t) \in \mathbb{R}^{S_{t} ×H_{d}}\)的第一个元素\(F_{i}^{T}(t)[0] \in \mathbb{R}^{H_{d}}\)。
图像锚定文本生成模块 在视觉特征\(F_{i}^{I}(t)\)的条件下,该模块迭代生成新的文本标记,直至产生最大长度为\(S_{l}\)的完整句子。遵循Radford等人(2018)和Devlin等人(2018)的方法(其中标记“[BOS]”表示文本生成的开始),我们将句子初始化为“[BOS]”后接\(S_{l}-1\)个零占位符。如图9所示,在每次迭代中,模块会生成一个新的文本标记并替换一个零占位符。
在第\(k\)次迭代中,输入序列包含先前生成的标记\(S_{i, 1}(t), S_{i, 2}(t), ..., S_{i, k}(t)\),其后跟随\(S_{l}-k\)个零占位符,生成嵌入表示\(E_{i, 1}^{T}(t), E_{i, 2}^{T}(t), ..., E_{i, S_{l}}^{T}(t)\)。视觉嵌入与文本标记连接后,生成\(X=[F_{i, 1}^{I}(t), F_{i, 2}^{I}(t), ..., F_{i, N_{q}}^{I}(t), E_{i, 1}^{T}(t), E_{i, 2}^{T}(t), ..., E_{i, S_{l}}^{T}(t)]^{T}\),作为自注意力层的输入。如图9所示,自注意力层中的掩码使视觉标记之间能够相互关注,并促使\(S_{l}\)个文本标记中的每个标记都能关注所有视觉标记和先前的文本标记。具体而言,给定查询、键和值\(Q=X W^{Q}\)、\(K=X W^{K}\)和\(V=X W^{v}\)(其中\(W^{Q}\)、\(W^{K}\)和\(W^{v}\)为可学习权重),自注意力通过以下公式实现:
\[Z_{i}^{T}(t)=\text{Softmax}\left(\frac{Q K^{T}}{\sqrt{H_{d} / h}}+M\right) V\]
其中掩码\(M\)中的值由图9中的黑白矩形表示。\(h=12\)表示注意力头的数量。\(Z_{i}^{T}(t)=[Z_{i, 1}^{T}(t), ..., Z_{i, N_{q}+S_{l}}^{T}(t)]^{T} \in \mathbb{R}^{(N_{q}+S_{l}) ×H_{d}}\)。由于最后一个标记包含完整序列的信息,因此仅将最后一个标记\(Z_{i, N_{q}+S_{i}}^{T}(t)\)输入前馈层。前馈层具有\(H_{d}\)个输入通道和\(N_{\text{vocabulary }}\)个输出通道,生成\(N_{\text{vocabulary }}=30,523\)个概率值,表示候选标记的可能性。根据BERT标记器[Devlin等人,2018],\(N_{\text{vocabulary}}\)为词汇表大小。最佳候选标记\(S_{i, k+1}(t)\)被添加到序列\(S_{i, 1}(t), S_{i, 2}(t), ..., S_{i, k}(t)\)的末尾,然后开始下一次迭代。当生成长度为\(S_{l}\)的完整序列\(S_{i}(t)\)时,迭代终止。该模块使用交叉熵损失进行训练。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)