达梦数据库 对象操作管理、DM_SQL 语言的功能及语句
按照所实现的功能,DM_SQL。<SPLIT 子句 1>::=SPLIT PARTITION <分区名> AT (<表达式>{,<表达式>}) INTO ({PARTITION <分区名><引用约束> ::= [FOREIGN KEY] REFERENCES [PENDANT] [<模式名>.]<表名>[(<列名>{[,<列名>]})][<表空间子句>] [<STORAGE 子句>]}, {PAR
数据库对象操作概要:
DM_SQL 语言是一种介于关系代数与关系演算之间的语言,其功能主要包括数据定义、查询、操纵和控制四个方面,通过各种不同的 SQL 语句来实现。按照所实现的功能,DM_SQL
语句分为以下几种:
1. 用户、模式、基表、视图、索引、序列、全文索引、存储过程、触发器等数据库对
象的定义和删除语句,数据库、用户、基表、视图、索引、全文索引等数据库对象
的修改语句;
2. 查询(含全文检索)、插入、删除、修改语句;
3. 数据库安全语句。包括创建角色语句、删除角色语句,授权语句、回收权限语句,
修改登录口令语句,审计设置语句、取消审计设置语句等。
安装完成启动数据库,使用sysdba用户登录操作数据库
1、创建、修改和删除表空间
和表空间相关的视图 v$datafile 、v$tablespace、dba_data_files
CREATE TABLESPACE [IF NOT EXISTS] <表空间名> <数据文件子句>[<数据页缓冲池子句>][<存储加密
子句>][<HUGE 路径子句>][<STORAGE 子句>]
<STORAGE 子句> ::=
STORAGE (ON <RAFT 组名>) |
STORAGE (ON <BP 组名>)
<数据文件子句> ::= DATAFILE <文件说明项>{,<文件说明项>}
<文件说明项> ::= <文件路径> [ MIRROR <文件路径>] SIZE <文件大小>[<自动扩展子句>]
<自动扩展子句> ::= AUTOEXTEND <ON [<每次扩展大小子句>][<最大大小子句>] |OFF>
<每次扩展大小子句> ::= NEXT <扩展大小>
<最大大小子句> ::=
MAXSIZE <文件最大大小> |
UNLIMITED
<数据页缓冲池子句> ::= CACHE = <缓冲池名>
<存储加密子句> ::= ENCRYPT WITH <加密算法> <密码子句>
<密码子句>::=BY <加密密码> |
BY WRAPPED <加密密码密文>
<HUGE 路径子句> ::= WITH HUGE PATH <HUGE 数据文件路径>
参数 :
1. <表空间名> 表空间的名称,最大长度 128 字节;
2. <文件路径> 指明新生成的数据文件在操作系统下的路径+新数据文件名。数据文
件的存放路径符合 DM 安装路径的规则,若指定目录不存在则自动创建相应目录。若路径是
相对路径,仅支持路径起始位置的当前目录的相对路径“./”。例如:支持“./data/TS.DBF”,
不支持“../data/TS.DBF”、“/./TS.DBF”等;
3. MIRROR 数据文件镜像,用于在数据文件出现损坏时替代数据文件进行服务;
MIRROR 数据文件的<文件路径>必须是绝对路径。要使用数据文件镜像,必须在建库时开
启页校验的参数 PAGE_CHECK;
4. <文件大小> 整数值,指明新增数据文件的大小,单位 MB,取值范围 4096*页大
小~2147483647*页大小;存在特殊情况:若控制系统中为表空间提前预留的簇个数的 INI
参数 TS_RESERVED_EXTENTS 取缺省值 64,且数据库初始化时指定簇大小 EXTENT_SIZE
为 64,此时表空间预留簇个数占用空间大小正好等于表空间大小的理论最小值(4096*页
大 小 ); 而 新 创 建 的 表 空 间 至 少 要 占 用 1 个 簇 , 由 于 当 前 剩 余 的 空 间 不 满 足
TS_RESERVED_EXTENTS 参 数 指 定 的 预 留 簇 个 数 要 求 , 系 统 会 按 照 INI 参 数
TS_AUTO_EXTEND_SIZE 的值,自动扩展表空间大小直至满足预留簇个数所需的空间要
求;
5. <每次扩展大小子句>指明数据库文件每次扩展的大小,单位 MB,取值范围为
1~2048。如果不指定此子句,数据库文件也会自动扩展,每次扩展的大小由 INI 参数
TS_AUTO_EXTEND_SIZE 控制;
6. <最大大小子句>指明数据库文件的最大大小,单位 MB,如果不指定此子句,则为
无限制;
7. <缓冲池名> 系统数据页缓冲池名 NORMAL 或 KEEP。缓冲池名 KEEP 是 DM 的保
留关键字,使用时必须加双引号;
8. <加密算法> 可以是系统内置的加密算法也可以是第三方加密算法,详情请参考手
册『DM8 安全管理』;
9. <加密密码> 必须满足长度大于等于 INI 参数 PWD_MIN_LEN 设置的值,同时不超
过 32,且包含大写、小写、数字。若未指定,由 DM 随机生成。
<加密密码密文>提供一种创建和现有的加密表/表空间一样密钥的表/表空间的语法,
和 WRAPPED 关键词搭配使用。加密密码密文可通过查看现有的加密表/表空间定义语句获
取。例如:select dbms_metadata.get_ddl('TABLESPACE','TS03');查看到的 CREATE
TABLESPACE "TS03" DATAFILE '/data/sdb/DAMENG/ts03.dbf' SIZE 32 AUTOEXTEND
ON NEXT 0 MAXSIZE 16777215 CACHE = "NORMAL" ENCRYPT WITH
OPENSSL_SM4_OFB_V1 BY WRAPPED
'0xDEFBACCB9F0D15FB420717215C138B3D55E83D2A72B528751EF40D0B4719B54016
0A90456BACB7A225BE040AB4FCF84E36BD58C30C708607' COPY 0 MICRO WITH
HUGE PATH '/data/sdb/DAMENG/ts03' MICRO; 。 则
'0xDEFBACCB9F0D15FB420717215C138B3D55E83D2A72B528751EF40D0B4719B54016
0A90456BACB7A225BE040AB4FCF84E36BD58C30C708607'即为加密密码密文。
10. <HUGE 路径子句> 用于创建一个混合表空间。HUGE 数据文件存储在<HUGE 路径
子句>指定的路径中,普通(非 HUGE)数据文件存储在<数据文件子句>指定的路径中。
11. <STORAGE 子句> DMDPC 专用,对单节点如果使用了<STORAGE 子句>会直接忽
略。通过<RAFT 组名>或<BP 组名>指定一个 RAFT 组作为表空间的存储位置。RAFT 组名或
BP 组名必须是已存在的组名。<表空间名>、<RAFT 组名> 、 <BP 组名>三者不能同名。
若指定的是<RAFT 组名>,则为明确指定 RAFT 组名。若指定的是<BP 组名>,则系统会从
指定的 BP 组中随机挑选一个 RAFT 组。如果<STORAGE 子句>缺省,即<RAFT 组名>和<BP
组名>均未指定,则系统会从现有的 BP RAFT 组中随机挑选一个作为表空间的存储位置。
使用案例:
|
测试使用案例 |
|
CREATE TABLESPACE DM_DATA DATAFILE '/app/dmDB8/data/DM_DATA01.dbf' SIZE 128 AUTOEXTEND ON NEXT 1 MAXSIZE UNLIMITED; |

修改表空间:
ALTER TABLESPACE <表空间名> [ONLINE|OFFLINE|CORRUPT|<表空间重命名子句>|<数据
文件重命名子句>|<增加数据文件子句>|<修改文件大小子句>|<修改文件自动扩展子句>|<数据页缓冲池
子句>|<DSC 集群表空间负载均衡子句>|<增加 HUGE 路径子句>|<删除表空间文件>|<缩减表空间大小>]
<表空间重命名子句> ::= RENAME TO <表空间名>
<数据文件重命名子句>::= RENAME DATAFILE <文件路径>{,<文件路径>} TO <文件路径>{,<文件路径>}
<增加数据文件子句> ::= ADD <数据文件子句>
<数据文件子句> ::= 参考 3.4.1 表空间定义语句中的<数据文件子句>
<修改文件大小子句> ::= RESIZE DATAFILE <文件路径> TO <文件大小> [ON RAFT_NAME]
<修改文件自动扩展子句> ::= DATAFILE <文件路径>{,<文件路径>}[<自动扩展子句>]
<自动扩展子句> ::= 参考 3.4.1 表空间定义语句中的<自动扩展子句>
<数据页缓冲池子句> ::= CACHE = <缓冲池名>
<DSC 集群表空间负载均衡子句> ::= OPTIMIZE <DSC 集群节点号>
<增加 HUGE 路径子句> ::= ADD HUGE PATH <HUGE 数据文件路径>
<删除表空间文件>::=DROP DATAFILE <文件路径>
|
使用测试案例: |
|
例1将表空间 TS1 名字修改为 TS2。 |
|
ALTER TABLESPACE TS1 RENAME TO TS2; |
|
例 2 增加一个路径为 d:\TS1_1.dbf,大小为 128M 的数据文件到表空间 TS1。 |
|
ALTER TABLESPACE TS1 ADD DATAFILE 'd:\TS1_1.dbf' SIZE 128; |
|
例 3 修改表空间 TS1 中数据文件 d:\TS1.dbf 的大小为 200M。 |
|
ALTER TABLESPACE TS1 RESIZE DATAFILE 'd:\TS1.dbf' TO 200; |
|
例 4 重命名表空间 TS1 的数据文件 d:\TS1.dbf 为 e:\TS1_0.dbf。 |
|
ALTER TABLESPACE TS1 OFFLINE; |
|
ALTER TABLESPACE TS1 RENAME DATAFILE 'd:\TS1.dbf' TO 'e:\TS1_0.dbf'; |
|
ALTER TABLESPACE TS1 ONLINE; |
|
例 5 修改表空间 TS1 的数据文件 d:\TS1.dbf 自动扩展属性为每次扩展 10M,最大文件大小为 1G。 |
|
ALTER TABLESPACE TS1 DATAFILE 'd:\TS1.dbf' AUTOEXTEND ON NEXT 10 MAXSIZE 1000; |
|
例 6 修改表空间 TS1 缓冲池名字为 KEEP。 |
|
ALTER TABLESPACE TS1 CACHE="KEEP"; |
|
例 7 修改表空间为 CORRUPT 状态,注意只有在表空间处于 OFFLINE 状态或表空间损 |
|
坏的情况下才允许使用。 |
|
ALTER TABLESPACE TS1 CORRUPT; |
|
例 8 为表空间 TS1 添加 HUGE 数据文件路径 |
|
ALTER TABLESPACE TS1 ADD HUGE PATH 'D:\dmdbms\data\DAMENG\TS1\HUGE2'; |
删除表空间:
1. 删除不存在的表空间会报错。若指定 IF EXISTS 关键字,删除不存在的表空间,不
会报错;
2. SYSTEM、RLOG、ROLL 和 TEMP 表空间不允许删除;
3. 系统处于 SUSPEND 或 MOUNT 状态时不允许删除表空间,系统只有处于 OPEN 状
态下才允许删除表空间。
测试使用案例:
|
测试使用案例 |
| DROP TABLESPACE [IF EXISTS] DM_DATA; |

2、创建、修改和删除模式
每个用户有一个默认的同名的模式名,访问自己模式下的表、视图等,不需要加模式名,访问其他模式下的对象需要拥有访问权限,访问时还需加上模式名
语法:
<模式定义子句 1> | <模式定义子句 2>
<模式定义子句 1> ::=
CREATE SCHEMA <模式名> [AUTHORIZATION <用户名>][<DDL_GRANT 子句> {< DDL_GRANT
子句>}];
<模式定义子句 2> ::=
CREATE SCHEMA AUTHORIZATION <用户名> [<DDL_GRANT 子句> {< DDL_GRANT 子句>}];
<DDL_GRANT 子句> ::=
<表定义> | <域定义>| <基表修改> | <索引定义> | <视图定义> | <序列定义> | <存储过程定义> | <
存储函数定义> | <外部函数定义> |<触发器定义> | <特权定义> | <全文索引定义> | <同义词定义> | <包定
义> | <包体定义> | <类定义> | <类体定义> | <外部链接定义>] | <物化视图定义> | <物化视图日志定义> |
<注释定义> | <自定义运算符定义>
|
测试使用案例 |
| 创建用户模式例 用户 SYSDBA 创建模式 SCHEMA1,建立的模式属于 SYSDBA。 CREATE SCHEMA SCHEMA1 AUTHORIZATION SYSDBA; |
设置用户模式:
SET SCHEMA 模式名>;
|
测试使用案例 |
| 例 SYSDBA 用户将当前的模式从 SYSDBA 换到 SALES 模式。 SET SCHEMA SALES; |
删除用户模式:
DROP SCHEMA [IF EXISTS] <模式名> [RESTRICT | CASCADE];
|
测试使用案例 |
| 例子:以 SYSDBA 身份登录数据库后,删除 BOOKSHOP 库中模式 SCHEMA1。 DROP SCHEMA SCHEMA1 CASCADE; |
3、创建、修改和删除用户
CREATE USER [IF NOT EXISTS] <用户名> IDENTIFIED <身份验证模式> [PASSWORD_POLICY <口令策
略>][<锁定子句>][<存储加密密钥>][<只读标志>][<资源限制子句>][<密码过期子句>][<允许 IP 子句>
][<禁止 IP 子句>][<允许时间子句>][<禁止时间子句>][<TABLESPACE 子句>][<INDEX_TABLESPACE 子
句>][<表空间配额子句>];
<身份验证模式> ::=
<数据库身份验证模式>|
<外部身份验证模式>
<数据库身份验证模式> ::= BY <口令> [<散列选项>]
<散列选项> ::= HASH WITH [<密码引擎名>.]<散列算法> [<加盐选项>]
<加盐选项> ::= [NO] SALT
<外部身份验证模式> ::=
EXTERNALLY |
EXTERNALLY AS <用户 DN>
<锁定子句> ::=
ACCOUNT LOCK |
ACCOUNT UNLOCK
<存储加密密钥> ::= ENCRYPT BY <口令>
<只读标志> ::= [NOT] READ ONLY
<资源限制子句> ::=
DROP PROFILE |
PROFILE <profile 名> |
LIMIT <资源设置>
<资源设置> ::=
<资源设置项>{,<资源设置项>} |
<资源设置项>{ <资源设置项>}
<资源设置项> ::=
GOLBAL_SESSION_PER_USER<参数设置> |
SESSION_PER_USER <参数设置> |
CONNECT_IDLE_TIME <参数设置> |
CONNECT_TIME <参数设置> |
CPU_PER_CALL <参数设置> |
CPU_PER_SESSION <参数设置> |
MEM_SPACE <参数设置> |
READ_PER_CALL <参数设置> |
READ_PER_SESSION <参数设置> |
FAILED_LOGIN_ATTEMPTS <参数设置> |
PASSWORD_LIFE_TIME <参数设置> |
PASSWORD_REUSE_TIME <参数设置> |
PASSWORD_REUSE_MAX <参数设置> |
PASSWORD_LOCK_TIME <参数设置> |
PASSWORD_GRACE_TIME <参数设置>|
INACTIVE_ACCOUNT_TIME<参数设置>
<参数设置> ::=
<参数值> |
UNLIMITED |
DEFAULT
<密码过期子句> ::= PASSWORD EXPIRE
<允许 IP 子句> ::=
ALLOW_IP NULL |
ALLOW_IP <IP 项>{,<IP 项>}
<禁止 IP 子句> ::=
NOT_ALLOW_IP NULL |
NOT_ALLOW_IP <IP 项>{,<IP 项>}
<IP 项> ::=
<具体 IP> |
<网段>
<允许时间子句> ::= ALLOW_DATETIME <时间项>{,<时间项>}
<禁止时间子句> ::= NOT_ALLOW_DATETIME <时间项>{,<时间项>}
<时间项> ::=
<具体时间段> |
<规则时间段>
<具体时间段> ::= <具体日期> <具体时间> TO <具体日期> <具体时间>
<规则时间段> ::= <规则时间标志> <具体时间> TO <规则时间标志> <具体时间>
<规则时间标志> ::=
MON |
TUE |
WED |
THURS |
FRI |
SAT |
SUN
<TABLESPACE 子句> ::= DEFAULT TABLESPACE <表空间名>
<INDEX_TABLESPACE 子句> ::= DEFAULT INDEX TABLESPACE <表空间名>
<表空间配额子句> ::=
QUOTA UNLIMITED |
QUOTA 0 |
QUOTA <配额大小> ON <表空间名>{ QUOTA <配额大小> ON <表空间名>}
<配额大小> ::=
UNLIMITED |
<空间大小> [K|M|G|T]
使用命令行方式创建用户 TEST ,密码 “Dameng@123”,使用散列算法 SHA512 ,使用存储加密密钥为 “123456”,指定表空间为 TEST,索引表空间为 TEST,授予 “PUBLIC” 和 “SOI” 权限。示例参考如下:
|
测试使用案例 |
| create user "TEST" identified by "Dameng@123" hash with SHA512 salt encrypt by "123456" default tablespace "TEST" default index tablespace "TEST"; grant "PUBLIC","SOI" to "TEST"; |
| 例 1 创建用户名为 BOOKSHOP_USER、口令为 DMsys_123、会话超时为 30 分钟的用 户。 |
| CREATE USER BOOKSHOP_USER IDENTIFIED BY DMsys_123 LIMIT CONNECT_TIME 30; |
| 例 2 设置创建 user1,设置密码为过期。需进行重设才能使用。 |
|
//使用 SYSDBA 登录 CREATE USER user1 IDENTIFIED BY DMsys_123456 PASSWORD EXPIRE; //使用 SYSDBA 登录。重设密码 ALTER USER user1 IDENTIFIED BY DMsys_123456; |
修改:
语法:
ALTER USER <用户名> [<修改用户子句>] | [<用户代理功能子句>];
<修改用户子句> ::= [IDENTIFIED <身份验证模式>] [REPLACE <口令>] [PASSWORD_POLICY <口令策
略>] [<锁定子句>] [<存储加密密钥>] [<只读标志>][<资源限制子句>][<密码过期子句>][DISCARD
OLD PASSWORD] [<允许IP子句>][<禁止IP子句>][<允许时间子句>][<禁止时间子句>][<TABLESPACE
子句>][<INDEX_TABLESPACE 子句>][<SCHEMA 子句>][<表空间配额子句>]
<身份验证模式> ::= <数据库身份验证模式>|<外部身份验证模式>
<数据库身份验证模式> ::= BY <口令> [RETAIN CURRENT PASSWORD][<散列选项>]
<散列选项> ::= 参考 3.2.1 用户定义语句中的<散列选项>
<外部身份验证模式> ::= 参考 3.2.1 用户定义语句中的<外部身份验证模式>
<锁定子句> ::= ACCOUNT <LOCK | UNLOCK>
<存储加密密钥> ::= ENCRYPT BY <口令>
<只读标志> ::= [NOT] READ ONLY
<资源限制子句> ::= 参考 3.2.1 用户定义语句中的<资源限制子句>
<密码过期子句> ::= PASSWORD EXPIRE
<允许 IP 子句> ::=
ALLOW_IP NULL |
ALLOW_IP <IP 项>{,<IP 项>}
<禁止 IP 子句> ::=
NOT_ALLOW_IP NULL |
NOT_ALLOW_IP <IP 项>{,<IP 项>}
<IP 项> ::= <具体 IP> | <网段>
<允许时间子句> ::= ALLOW_DATETIME <时间项>{,<时间项>}
<禁止时间子句> ::= NOT_ALLOW_DATETIME <时间项>{,<时间项>}
<时间项> ::= 参考 3.2.1 用户定义语句中的<时间项>
<TABLESPACE 子句> ::=DEFAULT TABLESPACE <表空间名>
<INDEX_TABLESPACE 子句> ::= DEFAULT INDEX TABLESPACE <表空间名>
<SCHEMA 子句> ::= ON SCHEMA <模式名>
<表空间配额子句> ::= 参考 3.2.1 用户定义语句中的<表空间配额子句>
<用户代理功能子句> ::= <GRANT | REVOKE> CONNECT THROUGH <代理用户名>
|
测试使用案例 |
| 例 1 修改用户 BOOKSHOP_USER,会话空闲期为无限制,最大连接数为 10。 |
| ALTER USER BOOKSHOP_USER LIMIT SESSION_PER_USER 10, CONNECT_IDLE_TIME UNLIMITED; |
| 例 2 赋予用户 USER2 代理权限,使用户 USER2 可以认证登录用户 USER1。 |
| ALTER USER USER1 GRANT CONNECT THROUGH USER2; |
删除:
语法:
DROP USER [IF EXISTS] 用户名> [RESTRICT | CASCADE];
|
测试使用案例 |
| DROP USER BOOKSHOP_USER; |
4、创建、修改和删除表
创建:
语法:
CREATE [[GLOBAL] TEMPORARY] TABLE [IF NOT EXISTS] <表名定义> <表结构定义>;
<表名定义> ::= [<模式名>.] <表名>
<表结构定义>::=<表结构定义 1> | <表结构定义 2>
<表结构定义 1>::= (<列定义> {,<列定义>} [,<表级约束定义>{,<表级约束定义>}])[<属性子句>] [<延
迟段分配子句>] [<压缩子句>][表并行度子句][<高级日志子句>] [<add_log 子句>] [<DISTRIBUTE 子
句>][<AUTO_INCREMENT 子句>]
<表结构定义 2>::= [<属性子句>] [<延迟段分配子句>] [<压缩子句>][表并行度子句]AS <不带 INTO 的
SELECT 语句>[<add_log 子句>] [<DISTRIBUTE 子句>];
<列定义> ::= <不同类型列定义> [<列定义子句>] [<STORAGE 子句>][<存储加密子句>][COMMENT '<
列注释>']
<不同类型列定义> ::=<普通列列定义>|<虚拟列列定义>
<普通列列定义>::= <列名> <数据类型>
<虚拟列列定义> ::= <列名>[<数据类型>] [GENERATED ALWAYS]AS (<虚拟列定义>) [VIRTUAL]
[VISIBLE]
<列定义子句> ::=
DEFAULT [ON NULL] <列缺省值表达式> |
<自增列子句> |
<列级约束定义> |
DEFAULT [ON NULL] <列缺省值表达式> <列级约束定义> |
<自增列子句> <列级约束定义> |
<列级约束定义> DEFAULT [ON NULL] <列缺省值表达式> |
<列级约束定义> <自增列子句>
<自增列子句> ::=
IDENTITY [(<种子>,<增量>)]|
AUTO_INCREMENT
<列级约束定义> ::= <列级完整性约束>{ <列级完整性约束>}
<列级完整性约束> ::= [CONSTRAINT <约束名>] <column_constraint_action> [<失效生效选项>]
<column_constraint_action>::=
[NOT] NULL |
<唯一性约束选项> [USING INDEX TABLESPACE {<表空间名> | DEFAULT}]|
<引用约束> |
CHECK (<检验条件>)|
NOT VISIBLE
<唯一性约束选项> ::=
PRIMARY KEY |
[NOT] CLUSTER PRIMARY KEY |
CLUSTER [UNIQUE] KEY |
UNIQUE
<引用约束> ::= [FOREIGN KEY] REFERENCES [PENDANT] [<模式名>.]<表名>[(<列名>{[,<列名>]})]
[MATCH <FULL|PARTIAL|SIMPLE>][<引用触发动作>] [WITH INDEX]
<引用触发动作> ::=
<UPDATE 规则> [<DELETE 规则>] |
<DELETE 规则> [<UPDATE 规则>]
<UPDATE 规则> ::= ON UPDATE <引用动作>
<DELETE 规则> ::= ON DELETE <引用动作>
<引用动作> ::= CASCADE | SET NULL | SET DEFAULT | NO ACTION
<失效生效选项>::=ENABLE | DISABLE
<STORAGE 子句> ::= STORAGE(<STORAGE 项> {,<STORAGE 项>})
<STORAGE 项> ::=
INITIAL <初始簇数目> |
NEXT <下次分配簇数目> |
MINEXTENTS <最小保留簇数目> |
ON <表空间名> |
FILLFACTOR <填充比例> |
BRANCH <BRANCH 数> |
BRANCH (<BRANCH 数>, <NOBRANCH 数>) |
NOBRANCH |
CLUSTERBTR |
WITH COUNTER |
WITHOUT COUNTER |
USING LONG ROW|
DISABLE USING LONG ROW
<存储加密子句>::= <透明存储加密子句>|<半透明存储加密子句>
<透明存储加密子句>::= <透明存储加密子句 1>|<透明存储加密子句 2>
<透明存储加密子句 1>::= ENCRYPT [<透明加密用法>]
<透明存储加密子句 2>::= ENCRYPT <透明加密用法><散列选项>
<透明加密用法> ::=
WITH <加密算法> [<透明加密选项>] |
<透明加密选项>
<透明加密选项> ::= <透明加密选项 1> |<透明加密选项 2> |<透明加密选项 3>
<透明加密选项 1> ::= AUTO
<透明加密选项 2> ::= AUTO BY <列存储密钥>
<透明加密选项 3> ::= AUTO BY WRAPPED <列存储密钥的密文>
<半透明存储加密子句> ::= ENCRYPT [WITH <加密算法>] MANUAL [<半透明加密选项>][<散列选项>]
<半透明加密选项> ::= <半透明加密选项 1> | <半透明加密选项 2> | <半透明加密选项 3>
<半透明加密选项 1> ::= <可见用户列表>
<半透明加密选项 2> ::= BY <列存储密钥> [<可见用户列表>]
<半透明加密选项 3> ::= BY WRAPPED <列存储密钥的密文> [<可见用户列表>]
<可见用户列表> ::= USER ([<用户名> {,<用户名>}])
<散列选项> ::= HASH WITH <散列算法> [<加盐选项>]
<加盐选项> ::= [NO] SALT
<表级约束定义>::=[CONSTRAINT <约束名>] <表级约束子句>[<失效生效选项>][<VALIDATE 选项>]
<表级约束子句>::=<表级完整性约束>
<表级完整性约束> ::=
<唯一性约束选项> (<列名> {,<列名>}) [USING INDEX TABLESPACE{ <表空间名> | DEFAULT}]|
FOREIGN KEY (<列名>{,<列名>}) <引用约束> |
CHECK (<检验条件>)
<属性子句>::= <表空间子句>|
ON COMMIT <DELETE | PRESERVE> ROWS|
<空间限制子句>|
<STORAGE 子句>
<表空间子句>::=TABLESPACE <表空间名>
<空间限制子句> ::=
DISKSPACE LIMIT <空间大小>|
DISKSPACE UNLIMITED
<延迟段分配子句> ::=
SEGMENT CREATION IMMEDIATE |
SEGMENT CREATION DEFERRED
<压缩子句> ::=
COMPRESS |
COMPRESS (<列名> {,<列名>}) |
COMPRESS EXCEPT (<列名> {,<列名>})
<表并行度子句> ::=
PARALLEL|
PARALLEL<并行度>|
NO PARALLEL
<高级日志子句> ::= WITH ADVANCED LOG
<add_log 子句>::= ADD LOGIC LOG
<DISTRIBUTE 子句> ::=
DISTRIBUTED [RANDOMLY | FULLY]|
DISTRIBUTED BY [<HASH>](<列名> {,<列名>})|
DISTRIBUTED BY RANGE (<列名> {,<列名>})(<范围分布项> {,<范围分布项>})|
DISTRIBUTED BY LIST (<列名> {,<列名>})(<列表分布项> {,<列表分布项>})
<范围分布项> ::=
VALUES LESS THAN (<范围表达式>{,<范围表达式>}) ON <实例名>|
VALUES EQU OR LESS THAN (<范围表达式>{,<范围表达式>}) ON <实例名>
<范围表达式> ::= MAXVALUE | <表达式>
<列表分布项> ::= VALUES (DEFAULT | <表达式>{,<表达式>}) ON <实例名>
<AUTO_INCREMENT 子句>::= AUTO_INCREMENT [=] <起始边界值>
<不带 INTO 的 SELECT 语句> ::= <查询表达式>|<带参数查询语句>
<带参数查询语句>::=<子查询> | (<带参数查询语句>)
<VALIDATE 选项>::=[NOVALIDATE | VALIDATE]
|
测试使用案例 |
|
例 2 建表时指定存储信息,表 PERSON 建立在表空间 FG_PERSON 中,初始簇大小为 例 3 在 MPP 集群环境下建立如下范围分布表后,表 PRODUCT_INVENTORY 将按照
例 5 在 MPP 集群环境下建立如下复制分布表后,表 LOCATION 被分布到 MPP 各个站
|
修改:
语法:
ALTER TABLE [<模式名>.]<表名> <修改表定义子句>
<修改表定义子句> ::=
MODIFY <列定义>|
ADD [COLUMN] [IF NOT EXISTS] <列定义>|
ADD [COLUMN] [IF NOT EXISTS] (<列定义> {,<列定义>})|
REBUILD COLUMNS|
DROP [COLUMN] [IF EXISTS] <列名> [RESTRICT | CASCADE] |
ADD [CONSTRAINT [<约束名>] ] <表级约束子句> [<失效生效选项>] [<VALIDATE 选项>]|
ADD [CONSTRAINT [<约束名>] ] <唯一性约束选项> (<列名> {,<列名>}) USING INDEX <索引名>
[<失效生效选项>]|
RENAME CONSTRAINT <约束名 1> TO <约束名 2> |
RENAME COLUMN <列名 1> TO <列名 2> |
DROP CONSTRAINT <约束名> [RESTRICT | CASCADE] |
DROP CONSTRAINT <约束名> [CASCADE] {[DROP|KEEP] INDEX}|
ALTER [COLUMN] <列名> SET DEFAULT [ON NULL] <列缺省值表达式>|
ALTER [COLUMN] <列名> DROP DEFAULT |
ALTER [COLUMN] <列名> RENAME TO <列名> |
ALTER [COLUMN] <列名> SET <NULL | NOT NULL>|
ALTER [COLUMN] <列名> SET [NOT] VISIBLE|
ALTER [COLUMN] <列名> ADD USER (<用户名> {,<用户名>})|
ALTER [COLUMN] <列名> DROP USER (<用户名> {,<用户名>})|
RENAME TO <表名> |
ENABLE ALL TRIGGERS |
DISABLE ALL TRIGGERS |
MODIFY <空间限制子句>|
MODIFY CONSTRAINT <约束名> TO <表级约束子句> [<VALIDATE 选项>] [RESTRICT | CASCADE]|
MODIFY CONSTRAINT <约束名> ENABLE [<VALIDATE 选项>]|
MODIFY CONSTRAINT <约束名> DISABLE [<VALIDATE 选项>] [RESTRICT | CASCADE] |
WITH COUNTER |
WITHOUT COUNTER |
MODIFY PATH <外部表文件路径> |
DROP IDENTITY|
DROP AUTO_INCREMENT|
ADD [COLUMN] <列名> <自增列子句>|
AUTO_INCREMENT [=] <起始边界值>|
ENABLE CONSTRAINT <约束名> [<VALIDATE 选项>]|
DISABLE CONSTRAINT <约束名> [<VALIDATE 选项>] [RESTRICT | CASCADE] |
DEFAULT DIRECTORY <目录名>|
LOCATION ('<文件名>')|
ENABLE USING LONG ROW|
DISABLE USING LONG ROW|
ADD LOGIC LOG |
DROP LOGIC LOG |
WITHOUT ADVANCED LOG |
TRUNCATE ADVANCED LOG |
TRUNCATE PARTITION <分区名> [DROP STORAGE | REUSE STORAGE] |
TRUNCATE PARTITION (<分区名>) [DROP STORAGE | REUSE STORAGE] |
TRUNCATE SUBPARTITION <子分区名> [DROP STORAGE | REUSE STORAGE] |
TRUNCATE SUBPARTITION (<子分区名>) [DROP STORAGE | REUSE STORAGE] |
MOVE TABLESPACE <表空间名>|
PARALLEL|
PARALLEL<并行度>|
NO PARALLEL|
DROP PRIMARY KEY [RESTRICT | CASCADE]|
READ WRITE |
READ ONLY
<列定义>、<空间限制子句>、<表级约束子句>::=请参考 3.5.1.1 定义数据库基表
<VALIDATE 选项>::=[NOVALIDATE | VALIDATE]
ALTER TABLE [<模式名>.]<表名> <修改表定义子句>
<修改表定义子句> ::=
MODIFY <增加多级分区子表>|
<删除一级分区子表>|
<删除多级分区子表>|
MODIFY <修改 LIST 分区子表>|
ADD PARTITION [IF NOT EXISTS] <水平分区项子句>|
EXCHANGE <PARTITION| SUBPARTITION > <分区名> WITH TABLE [<模式名.>]<表名>|
<SPLIT 子句>|
MERGE PARTITIONS <分区编号>,<分区编号> INTO PARTITION <分区名>|
MERGE PARTITIONS <分区名>,<分区名> INTO PARTITION <分区名>|
SET SUBPARTITION TEMPLATE <分区模板描述项> |
TRUNCATE PARTITION <分区名> [DROP STORAGE | REUSE STORAGE] |
TRUNCATE PARTITION (<分区名>)[DROP STORAGE | REUSE STORAGE] |
TRUNCATE PARTITION FOR (<分区列值>) |
TRUNCATE SUBPARTITION <子分区名> [DROP STORAGE | REUSE STORAGE] |
TRUNCATE SUBPARTITION (<子分区名>) [DROP STORAGE | REUSE STORAGE] |
TRUNCATE SUBPARTITION FOR (<分区列值>) |
ENABLE ROW MOVEMENT |
DISABLE ROW MOVEMENT |
RENAME <修改分区子表名> |
MOVE PARTITION <分区名> TABLESPACE <表空间名> |
MOVE SUBPARTITION <子分区名> TABLESPACE <表空间名>|
LOCK PARTITIONS |
LOCK ROOT
<增加多级分区子表>::= <PARTITION | SUBPARTITION> <分区名> ADD SUBPARTITION [IF NOT EXISTS]
<<RANGE 子分区项子句>|<LIST 子分区项子句>>
<删除一级分区子表>::=
DROP PARTITION [IF EXISTS] <分区名> |
DROP PARTITION FOR [IF EXISTS] (<分区列值>)
<删除多级分区子表>::=
DROP SUBPARTITION [IF EXISTS] <分区名> |
DROP SUBPARTITION FOR [IF EXISTS] (<分区列值>)
<修改 LIST 分区子表>::=<PARTITION | SUBPARTITION> <分区名> <ADD|DROP> VALUES(分区值[,分区
值])
<SPLIT 子句>::=
<SPLIT 子句 1> |
<SPLIT 子句 2> |
<SPLIT 子句 3> |
<SPLIT 子句 4>
<SPLIT 子句 1>::=SPLIT PARTITION <分区名> AT (<表达式>{,<表达式>}) INTO ({PARTITION <分区名>
[<表空间子句>] [<STORAGE 子句>]}, {PARTITION <分区名> [<表空间子句>] [<STORAGE 子句>]})
<SPLIT 子句 2>::=SPLIT PARTITION <分区名> VALUES (<表达式>{,<表达式>}) INTO ({PARTITION <分
区名> [<表空间子句>] [<STORAGE 子句>]}, {PARTITION <分区名> [<表空间子句>] [<STORAGE 子
句>]})
<SPLIT 子句 3>::=SPLIT PARTITION <分区名> INTO (<RANGE 分区项> {,<RANGE 分区项>}, PARTITION <
分区名> [<表空间子句>] [<STORAGE 子句>])
<SPLIT 子句 4>::=SPLIT PARTITION <分区名> INTO (<LIST 分区项> {,<LIST 分区项>}, PARTITION <分区
名> [<表空间子句>] [<STORAGE 子句>])
<修改分区子表名>::=
<修改一级分区子表名> |
<修改多级分区子表名>
<修改一级分区子表名>::=PARTITION <分区名> TO <新名称>
<修改多级分区子表名>::=SUBPARTITION <分区名> TO <新名称>
<分区列值>::=<常量|计算表达式{,常量|计算表达式}>
<水平分区项子句>::=<RANGE 分区项子句>|<HASH 分区项子句>|<LIST 分区项子句>
<RANGE 分区项>、<HASH 分区项>、<LIST 分区项>请参考 3.5.1.4 定义水平分区表
<RANGE 分区项子句>、<HASH 分区项子句>、<LIST 分区项子句>请参考 3.5.1.4 定义水平分区表
<RANGE 子分区项>、<HASH 子分区项>、<LIST 子分区项>请参考 3.5.1.4 定义水平分区表
<RANGE 子分区项子句>、<HASH 子分区项子句>、<LIST 子分区项子句>请参考 3.5.1.4 定义水平分区表
<表空间子句>请参考 3.5.1.4 定义水平分区表
<STORAGE 子句>请参考 3.5.1.4 定义水平分区表
<分区模板描述项>::= ([<分区模板描述项 1>])|<分区模板描述项 2>
<分区模板描述项 1>::=
<RANGE 子分区项> {,<RANGE 子分区项>} |
<HASH 子分区项> {,<HASH 子分区项>} |
<LIST 子分区项> {,<LIST 子分区项>}
<分区模板描述项 2>::= [SUBPARTITIONS] <子分区数> <STORAGE HASH 子句>
<STORAGE HASH 子句>请参考 3.5.1.4 定义水平分区表
|
测试使用案例 |
|
例 1 合并分区表,修改分区表。 例 2 使用<SPLIT 子句>拆分水平分区表。 例 3 增加,删除分区子表。 例 4 交换分区子表。 INSERT INTO PARTITION_T1 VALUES (1,1);
|


删除:
语法:
DROP USER [IF EXISTS] 用户名> [RESTRICT | CASCADE];
|
测试使用案例 |
|
例 1 用户 SYSDBA 删除 PERSON 表。 |
5、创建、修改和删除视图
创建:
语法:
CREATE [OR REPLACE] [FORCE] VIEW [IF NOT EXISTS]
[<模式名>.]<视图名>[(<列名> {,<列名>})]
AS <查询说明>
[WITH [LOCAL|CASCADED]CHECK OPTION]|[with read only];
<查询说明>::=<表查询> | <连接表>
<表查询>::=<子查询表达式>[ORDER BY 子句]
<连接表>::= 请参考第 4 章 数据查询语句
|
测试使用案例 |
|
例 1 对 VENDOR 表创建一个视图,名为 VENDOR_EXCELLENT,保存信誉等级为 1 的供
用户可以在该表上作数据库的查询、插入、删除、修改等操作。在建好的视图之上还可 例 2 视图也可以建立在多个基表之上。构造一视图,名为 SALESPERSON_INFO,用来
例 3 在 PRODUCT_VENDOR 上建立一视图,用于统计数量。
|
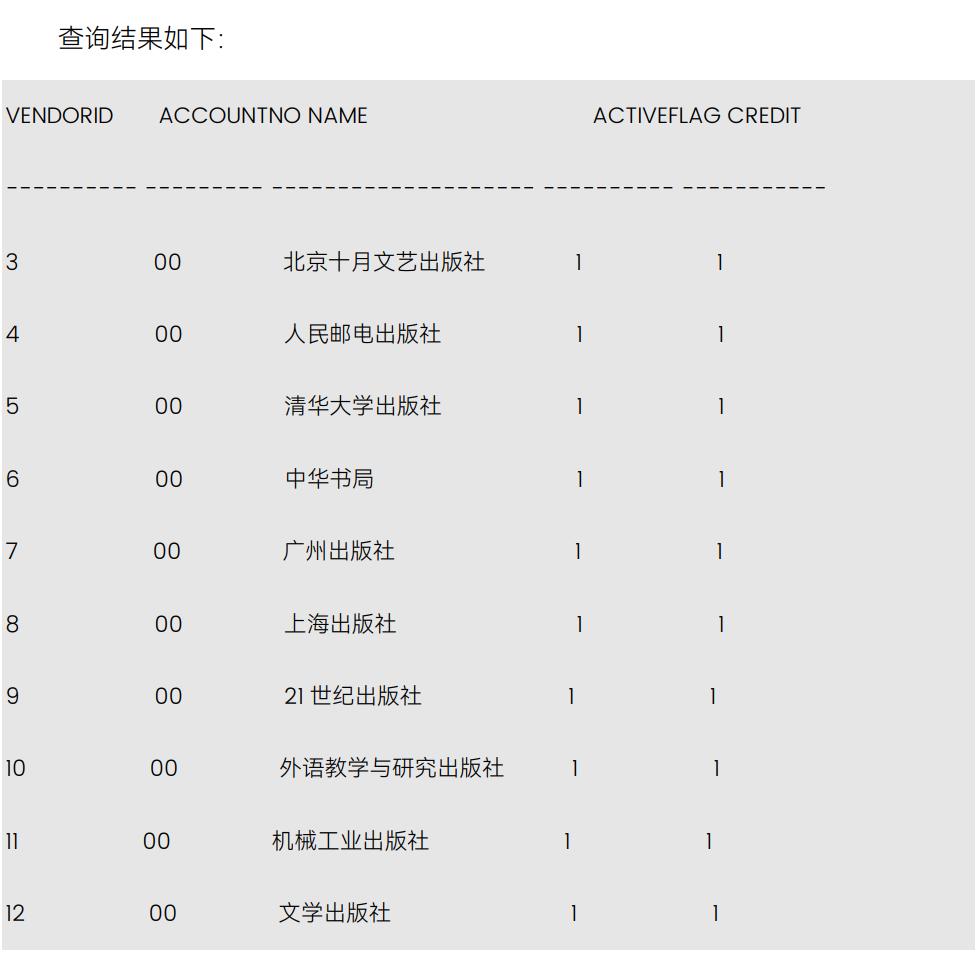


更新:
视图数据的更新包括插入(INSERT)、删除(DELETE)和修改(UPDATE)三类操作。由于 视图是虚表,并没有实际存放数据,因此对视图的更新操作均要转换成对基表的操作。在 SQL 语言中,对视图数据的更新语句与对基表数据的更新语句在格式与功能方面是一致的。
|
测试使用案例 |
|
例 1 从视图 VENDOR_EXCELLENT 中将名称为人民邮电出版社的 ACTIVEFLAG 改为 0。 UPDATE PURCHASING.VENDOR_EXCELLENT |
删除:
语法:
DROP VIEW [IF EXISTS] [模式名>.]视图名> [RESTRICT | CASCADE];
|
测试使用案例 |
|
例 1 删除视图 VENDOR_EXCELLENT,可使用下面的语句: DROP VIEW SALES.SALESPERSON_INFO CASCADE; |
6、创建、修改和删除索引
创建:
语法:
CREATE [OR REPLACE] [CLUSTER|NOT PARTIAL][UNIQUE | BITMAP| SPATIAL] INDEX [IF NOT EXISTS] <
索引名> ON [<模式名>.]<表名>(<索引列定义>{,<索引列定义>}) [GLOBAL] [<PARTITION 子句>] [<
表空间子句>] [<STORAGE 子句>] [NOSORT] [ONLINE] [REVERSE] [UNUSABLE] [<PARALLEL 项>];
<索引列定义>::= <索引列表达式>[ASC|DESC]
<表空间子句>::= TABLESPACE <表空间名>
<STORAGE 子句>::=<STORAGE 子句 1>|<STORAGE 子句 2>
<STORAGE 子句 1>::= STORAGE(<STORAGE1 项> {,<STORAGE1 项>})
<STORAGE1 项> ::=
[INITIAL <初始簇数目>] |
[NEXT <下次分配簇数目>] |
[MINEXTENTS <最小保留簇数目>] |
[ON <表空间名>] |
[FILLFACTOR <填充比例>]|
[BRANCH <BRANCH 数>]|
[BRANCH (<BRANCH 数>, <NOBRANCH 数>)]|
[NOBRANCH ]|
[CLUSTERBTR]|
[SECTION (<区数>)]|
[STAT NONE]
<STORAGE 子句 2>::= STORAGE(<STORAGE2 项> {,<STORAGE2 项>})
<STORAGE2 项> ::= [ON <表空间名>]|[STAT NONE]
<PARALLEL 项> ::=
NOPARALLEL |
PARALLEL [<并行数>]
<PARTITION 子句> ::=请参考 3.5.1.4 定义水平分区表
|
测试使用案例 |
| 例 1 假设具有 DBA 权限的用户在 VENDOR 表中,以 VENDORID 为索引列建立索引 S1, 以 ACCOUNTNO,NAME 为索引列建立唯一索引 S2。 CREATE INDEX S1 ON PURCHASING.VENDOR (VENDORID); CREATE UNIQUE INDEX S2 ON PURCHASING.VENDOR (ACCOUNTNO, NAME); 例 2 假设具有 DBA 权限的用户在 SALESPERSON 表中,需要查询比去年销售额超过 20 万的销售人员信息,该过滤条件无法使用到单列上的索引,每次查询都需要进行全表扫描, 效率较低。如果在 SALESTHISYEAR-SALESLASTYEAR 上创建一个函数索引,则可以较大程 度提升查询效率。 CREATE INDEX INDEX_FBI ON SALES.SALESPERSON(SALESTHISYEAR-SALESLASTYEAR); 例 3 创建空间索引。 //创建空间数据类型包 DMGEO SP_INIT_GEO2_SYS(1); //删除 DMGEO 全局同义词,并创建 DMGEO 全局同义词 DMGEO.ST_CREATE_GEO2_SYNONYMS(); //创建含空间索引类型的表 DROP TABLE testgeo; CREATE TABLE testgeo (id int, name varchar(20) , geo ST_polygon); //创建空间索引 CREATE SPATIAL INDEX spidx ON testgeo (geo); //删除空间索引 spidx DROP INDEX spidx; 例 4 创建反向索引。 //创建含反向索引类型的表 DROP TABLE t1; CREATE TABLE t1(c1 int, c2 raw(100), c3 timestamp, c4 date, c5 float, c6 interval day to second, c7 interval year to month); //创建反向索引 CREATE INDEX i1 ON t1(c1) REVERSE; CREATE INDEX i2 ON t1(c2) REVERSE; CREATE INDEX i3 ON t1(c3) REVERSE; CREATE INDEX i4 ON t1(c4) REVERSE; CREATE INDEX i5 ON t1(c5) REVERSE; CREATE INDEX i6 ON t1(c6) REVERSE; CREATE INDEX i7 ON t1(c7) REVERSE; 例 5 创建无效索引。 //创建含无效索引类型的表 DROP TABLE t2; CREATE TABLE t2(c1 int, c2 varchar); //创建无效索引 CREATE INDEX uidx ON t2(c1) UNUSABLE; 例 6 在 DMDPC 环境中创建全局分区索引。 //创建表空间 create tablespace ts1 datafile 'd:\ts\ts01.dbf' size 128 storage (on raft_1); create tablespace ts2 datafile 'd:\ts\ts02.dbf' size 128 storage (on raft_2); //创建表 drop table t1; create table t1(c1 int, c2 int, c3 int) partition by range(c1) ( partition p1 values less than(100), partition p2 values less than(200) ); //创建全局分区索引 create index idx1111 on t1(c2) global partition by range(c2) ( partition p1 values less than(10) storage(on ts2) , partition p2 values less than(1000) storage(on ts1), partition p3 values less than(maxvalue) ); //使用索引 idx111 查询 select * from t1 where c2 = 130; |
修改:
语法:
ALTER INDEX [<模式名>.]<索引名> <修改索引定义子句>
<修改索引定义子句> ::=
RENAME TO [<模式名>.]<索引名> |
INVISIBLE |
VISIBLE |
UNUSABLE |
REBUILD [NOSORT][ONLINE][ <重建方式>] |
<MONITORING | NOMONITORING> USAGE
<重建方式>::=
SHARE |
SHARE ASYNCHRONOUS [<异步任务数>] |
EXCLUSIVE
|
测试使用案例 |
例 1 具有 DBA 权限的用户需要重命名 S1 索引可用以下语句实现。 ALTER INDEX PURCHASING.S1 RENAME TO PURCHASING.S2; 例 2 当索引为 VISIBLE 时,查询语句执行计划如下: DROP TABLE TEST; CREATE TABLE TEST (C1 INT, C2 INT); CREATE INDEX INDEX_C1 ON TEST (C1); explain select c1 from test; 执行计划如下: 1 #NSET2: [1, 1, 16] 2 #PRJT2: [1, 1, 16]; exp_num(2), is_atom(FALSE) 3 #SSCN: [1, 1, 16]; INDEX_C1(TEST); btr_scan(1); is_global(0) 修改索引为 INVISIBLE 后,查询语句执行计划。 alter index index_C1 INVISIBLE; explain select c1 from test; 执行计划如下: 1 #NSET2: [1, 1, 16] 2 #PRJT2: [1, 1, 16]; exp_num(2), is_atom(FALSE) 3 #CSCN2: [1, 1, 16]; INDEX33555472(TEST); btr_scan(1) 例 3 使用 UNUSABLE 将索引置为无效状态。 DROP TABLE TEST; CREATE TABLE TEST (C1 INT, C2 INT); CREATE INDEX INDEX_C1 ON TEST (C1); ALTER INDEX INDEX_C1 UNUSABLE; 此时系统将不维护 INDEX_C1,与此相关的计划均失效。 例 4 并发重建索引。 //创建含无效索引类型的表 DROP TABLE TEST; CREATE TABLE TEST(C1 INT, C2 INT); //创建无效索引 CREATE INDEX INDEX_C1 ON TEST(C1) UNUSABLE; CREATE INDEX INDEX_C2 ON TEST(C2) UNUSABLE; //插入数据 INSERT INTO TEST SELECT LEVEL, LEVEL FROM DUAL CONNECT BY LEVEL <= 30000000; //会话 1 并发重建索引 INDEX_C1 ALTER INDEX INDEX_C1 REBUILD SHARE; //会话 2 并发重建索引 INDEX_C2 ALTER INDEX INDEX_C2 REBUILD SHARE; //在上述两个索引重建过程中,会话 3 执行如下语句 SELECT SQL_TEXT,STATE FROM V$SESSIONS WHERE TRX_ID IN (SELECT WAIT_FOR_ID FROM V$TRXWAIT); //会话 3 上的查询结果如下 未选定行 由查询结果可以知道,并未有线程处于等待状态,会话 1 和会话 2 正在并发重建 TEST 表上的索引。 例 5 并行重建分区表上的索引。 //创建含无效索引类型的分区表 DROP TABLE TEST; CREATE TABLE TEST(C1 INT, C2 INT) PARTITION BY HASH(C1) PARTITIONS 3; //创建无效索引 CREATE INDEX INDEX_C1 ON TEST(C1) UNUSABLE; //并行重建分区表上的索引 ALTER INDEX INDEX_C1 REBUILD SHARE ASYNCHRONOUS 3; 例 6 排他重建索引。 DROP TABLE TEST; CREATE TABLE TEST(C1 INT, C2 INT); CREATE INDEX INDEX_C1 ON TEST(C1) UNUSABLE; CREATE INDEX INDEX_C2 ON TEST(C2); //排他重建索引 ALTER INDEX INDEX_C1 REBUILD EXCLUSIVE; ALTER INDEX INDEX_C2 REBUILD EXCLUSIVE; |
删除:
语法:
DROP INDEX [IF EXISTS] [模式名>.]索引名>;
|
测试使用案例 |
| 例 具有 DBA 权限的用户需要删除 S2 索引可用以下语句实现。 DROP INDEX PURCHASING.S2; |
7、创建、修改和删除序列
创建:
语法:
CREATE SEQUENCE [IF NOT EXISTS] [<模式名>.] <序列名> [<序列选项列表>];
<序列选项列表> ::= <序列选项>{<序列选项>}
<序列选项> ::=
INCREMENT BY <增量值>|
START WITH <初值>|
MAXVALUE <最大值>|
NOMAXVALUE|
MINVALUE <最小值>|
NOMINVALUE|
CYCLE|
NOCYCLE|
CACHE <缓存值>|
NOCACHE|
ORDER |
NOORDER |
GLOBAL |
LOCAL
|
测试使用案例 |
| 例 创 建 序 列 SEQ_QUANTITY , 将 序 列 的 前 两 个 值 插 入 表 PRODUCTION.PRODUCT_INVENTORY 中。 (1)创建序列 SEQ_QUANTITY CREATE SEQUENCE SEQ_QUANTITY INCREMENT BY 10; (2)将序列的第一个值插入表 PRODUCT_INVENTORY 中 INSERT INTO PRODUCTION.PRODUCT_INVENTORY VALUES(1,1, SEQ_QUANTITY.NEXTVAL); SELECT * FROM PRODUCTION.PRODUCT_INVENTORY; 查询结果为:表 PRODUCT_INVENTORY 增加一行,列 QUANTITY 的值为 1。 (3)将序列的第二个值插入表 PRODUCT_INVENTORY 中 INSERT INTO PRODUCTION.PRODUCT_INVENTORY VALUES(1,1, SEQ_QUANTITY.NEXTVAL); SELECT * FROM PRODUCTION.PRODUCT_INVENTORY; 查询结果为:表 PRODUCT_INVENTORY 增加两行,列 QUANTITY 的值分别为 1,11。 |
修改:
语法:
ALTER SEQUENCE [ <模式名>.] <序列名> {<序列修改选项列表> | <序列重命名选项>};
<序列选项列表> ::= <序列修改选项> {<序列修改选项>}
<序列修改选项> ::=
INCREMENT BY <增量值>|
MAXVALUE <最大值>|
NOMAXVALUE|
MINVALUE <最小值>|
NOMINVALUE|
CYCLE|
NOCYCLE|
CACHE <缓存值>|
NOCACHE|
ORDER|
NOORDER |
CURRENT VALUE <当前值>
<序列重命名选项> ::=
RENAME TO <新序列名>
|
测试使用案例 |
| 例1 创建完序列后直接修改序列的步长 CREATE SEQUENCE SEQ1 INCREMENT BY 1000 START WITH 5 MAXVALUE 1000000 MINVALUE 1 CACHE 10; ALTER SEQUENCE SEQ1 INCREMENT BY 1 ; SELECT SEQ1.NEXTVAL FROM DUAL; 查询结果为:-994 由于-994小于序列最小值1,因此将-994作为新的序列最小值,序列取值范围变成 -994~1000000。但是该序列不支持导出,导出时将报错。 例2 创建序列后使用NEXTVAL访问了序列,然后修改步长。 CREATE SEQUENCE SEQ2 INCREMENT BY 1000 START WITH 5 NOMAXVALUE NOMINVALUE NOCACHE ; SELECT SEQ2.NEXTVAL FROM DUAL; ALTER SEQUENCE SEQ2 INCREMENT BY 1 ; SELECT SEQ2.NEXTVAL FROM DUAL; 查询结果为:6 例3 修改序列的最小值。 CREATE SEQUENCE SEQ3 INCREMENT BY 1 START WITH 100 MINVALUE 3 ; ALTER SEQUENCE SEQ3 MINVALUE 2; 例4 修改序列的当前值。 CREATE SEQUENCE SEQ4 INCREMENT BY 1 START WITH 100 MINVALUE 3 ; ALTER SEQUENCE SEQ4 CURRENT VALUE 300; SELECT SEQ4.NEXTVAL FROM DUAL; 查询结果为:300 例5 重命名序列SEQ5为SEQ6。 CREATE SEQUENCE SEQ5 INCREMENT BY 1 START WITH 100 MINVALUE 3 ; ALTER SEQUENCE SEQ5 RENAME TO SEQ6; SELECT SEQ6.NEXTVAL FROM DUAL; 查询结果为:100 |
删除:
语法:
DROP SEQUENCE [IF EXISTS] [ 模式名>.]序列名>;
|
测试使用案例 |
|
例 用户 SYSDBA 需要删除序列 SEQ_QUANTITY,可以用下面的语句: DROP SEQUENCE SEQ_QUANTITY; |
8、创建、修改和删除全文索引
创建:
语法:
CREATE CONTEXT INDEX [IF NOT EXISTS] <索引名> ON [<模式名>.] <表名> (<索引列定义>) [<表空
间子句>] [<STORAGE 子句>] [LEXER <分词参数>] [<SYNC 子句>];
<索引列定义>、<表空间子句>、[<STORAGE 子句>] 请参考本章 3.6.1 索引定义语句相关内容
<SYNC 子句> ::= SYNC [TRANSACTION]
|
测试使用案例 |
| 例 用户 SYSDBA 需要在 PERSON 模式下的 ADDRESS 表的 ADDRES1 列上创建全文索 引,可以用下面的语句: CREATE CONTEXT INDEX INDEX0001 ON PERSON.ADDRESS(ADDRESS1) LEXER CHINESE_LEXER; |
修改:
语法:
ALTER CONTEXT INDEX <索引名> ON [<模式名>.] <表名> <REBUILD | INCREMENT | OPTIMIZE>[ONLINE]
[LEXER <分词参数>];
|
测试使用案例 |
|
例 用户 SYSDBA 需要在 PERSON 模式下的 ADDRESS 表的 ADDRES1 列上完全填充全 |
删除:
语法:
DROP CONTEXT INDEX [IF EXISTS] 索引名> ON [模式名>.] 表名>;
|
测试使用案例 |
| 例 用户 SYSDBA 需要删除在 PERSON 模式下 ADDRESS 表的全文索引,可以用下面的 语句: DROP CONTEXT INDEX INDEX0001 ON PERSON.ADDRESS; |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)