最短路问题——单源最短路
是的,所以我们上面也说了: Bellman-Ford算法是比较暴力的把所有的边都更新(即先后对所有的顶点的相邻顶点进行松弛),而不像Dijkstra算法的贪心那样每次选的都是最短的,也因此它一遍过后可能得不出最短的路径,可能需要进行多次迭代。
目录
三. 存在负权边——bellman-ford算法,spfa算法
题目一——P3371 【模板】单源最短路径(弱化版) - 洛谷
题目二——P4779 【模板】单源最短路径(标准版) - 洛谷
一 . 单源最短路问题
1.1.最短路问题
最短路问题是图论中的一个基本问题。给定一个带权图(有向图或者无向图),图中的每条边都有一个权值(可以表示距离、时间、费用等),最短路问题就是要在这个图中找到从一个指定的起点到一个指定的终点之间的一条路径,使得这条路径上所有边的权值之和最小。
例如,在一个交通网络中,权值可以表示道路的长度,我们想找到从一个城市到另一个城市的最短行驶距离的路线,这就是最短路问题的一个实际应用场景。
总而言之,最短路问题描述的就是从图中的顶点沿着边走,走到另一个顶点的权值总和最小值(每条边都有权值)
如下无向图:
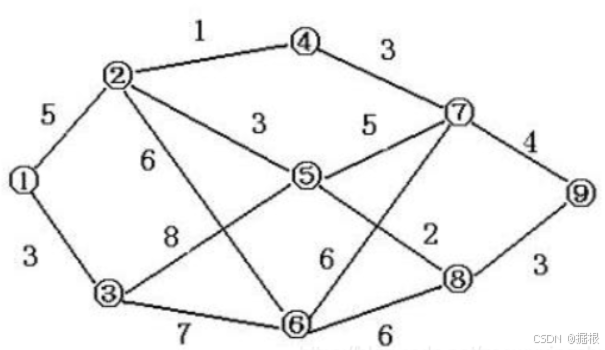
最短路问题的问法比如说:从顶点1到顶点5的最短路是多少,肉眼观察很容易看出1->2->5是最短路,权值=5+3 = 8
1.2.单源最短路问题
什么是单源最短路?
实际上就是求解出从一个结点出发到其他结点的最短距离
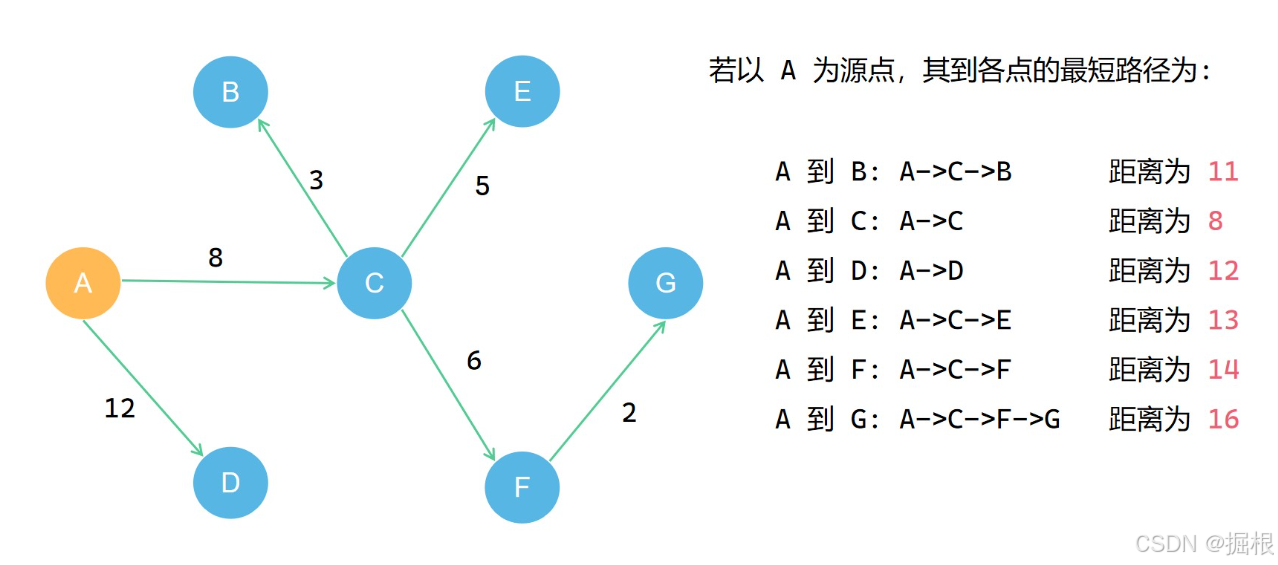
我们看个例子,例如下面是一个连通图,
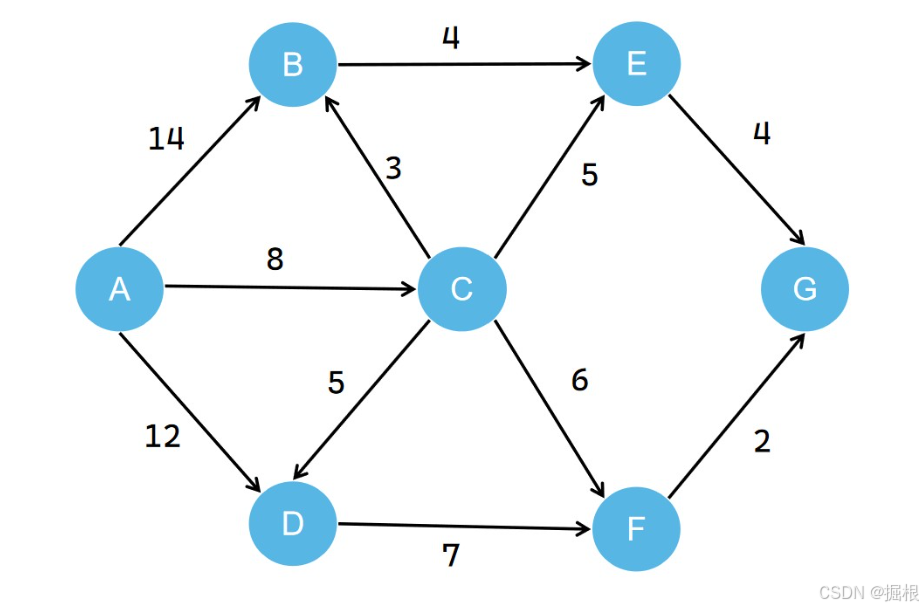
我们现在需要以A为起点,去寻找A点到其他结点的最短路径
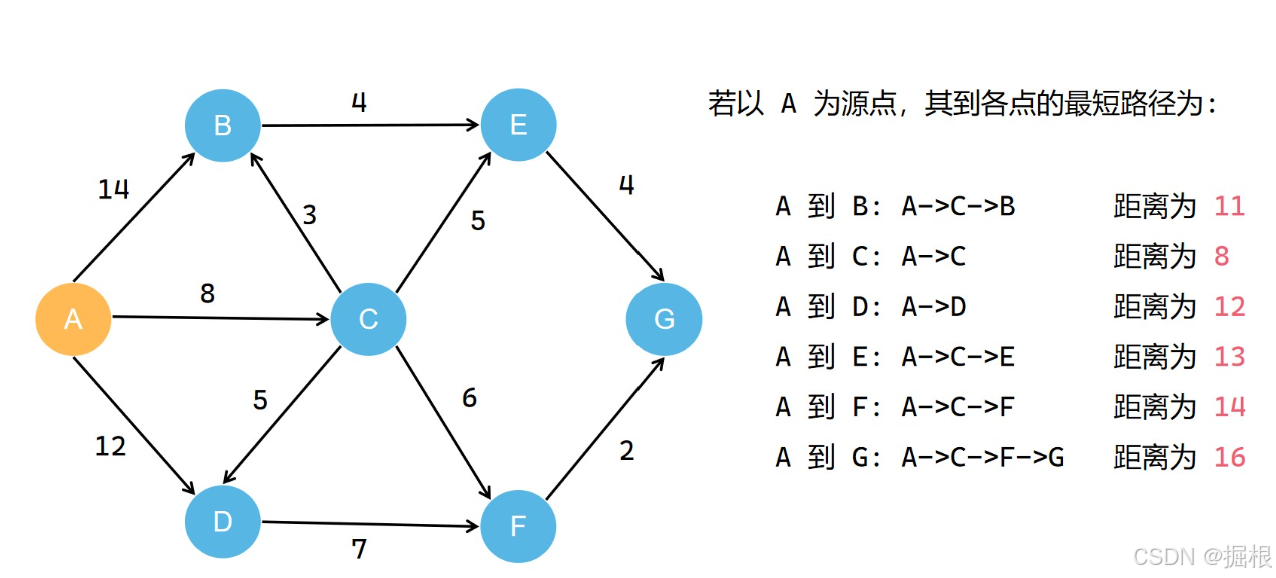
我们可以把源点到各点最短路径用绿色标记一下
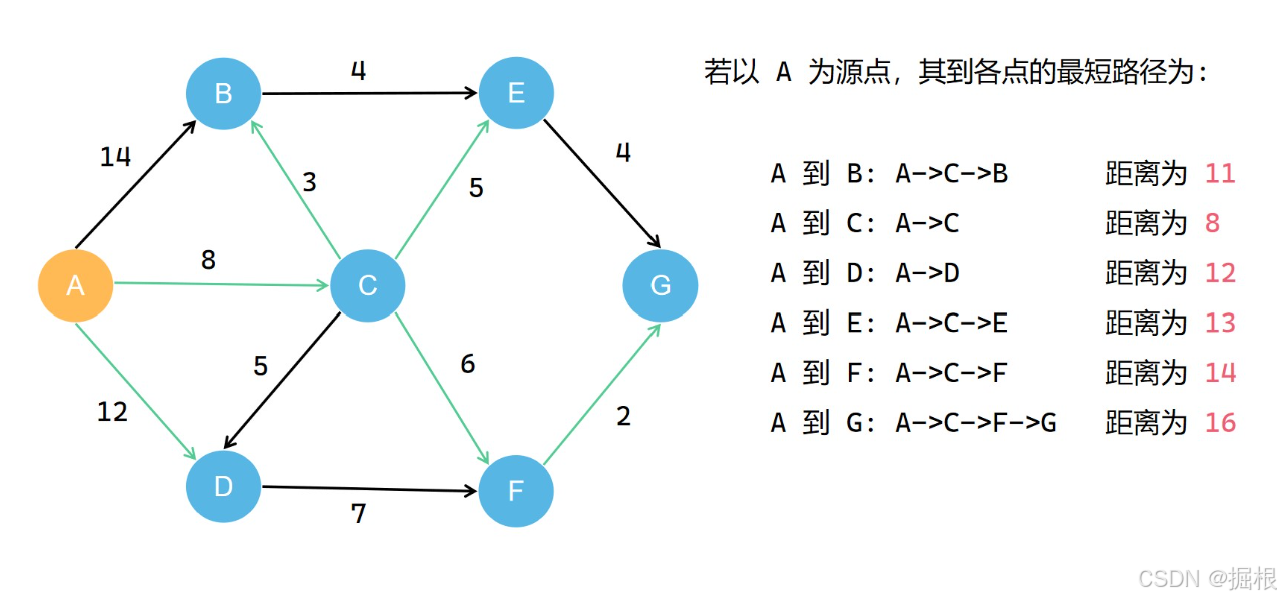
我们可以看出所有的最短路径构成了一个最短路径树
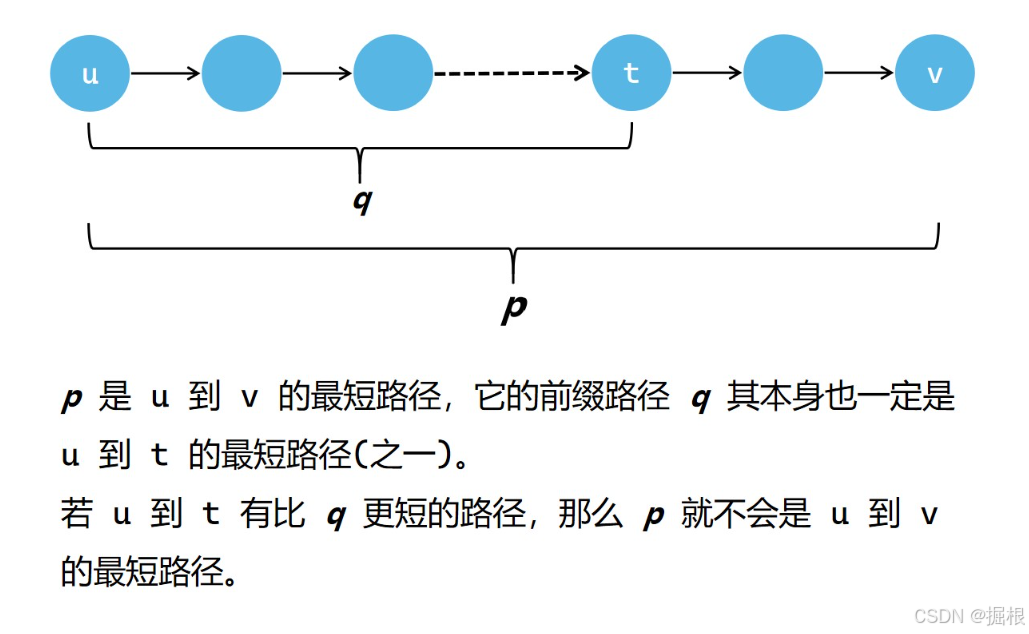
单调性
在上面的图中,我们不难发现,当我们确定了源点 u 到某个其它的点 v 的最短路径时,在这个最短路径的具体路线中,若有一个中转点 t,那么在这个最短路径中从源点 u 到 t 的路径也一定是 u 到 t 的最短路径(之一)。也就是说,假设源点 u 到 v 的最短路径为 p,那么p任意的前缀路径 q 一定是最优的(最短路径之一)。如果 q 不是最优的,那么就会存在另一个更短的路径比 p 更短。
这个性质还是很重要的,是解决单源最短路径问题的核心
我们画个图来理解一下
歧义性
在上面的阐述中也稍微提到一点,就是最短路径其实不一定是唯一的,有可能存在两个路径,它们的路径距离一样且都是最短的,那么此时我们二选其一就可以啦。还有一个问题就是,我们的边权都应当是正数,如果边权存在非正数,那么我们是无法定义这个图中的最短路径的(距离确实不能是非正数呀,除了自己到自己🤔)。
无环性
这个性质其实很好理解,既然我们得到的所有最短路径构成的是一个 最短路径树,那么作为一个树,它必不会存在环。也可以由之前的 单调性 得出这个性质。
1.3.最短路问题解决方案
单源最短路问题我们可以进一步划分,划分如下:
- 所有边权都是正数
- 存在负权边
对于所有边权都是正数的情况,我们有两种解决算法:朴素Dijkstra算法、堆优化版的Dijkstra算法
对于存在负权边的情况,我们也有两种解决算法:Bellman-Ford、SPFA
朴素Dijkstra算法 vs 堆优化版的Dijkstra算法
先讨论两者的时间复杂度,设图中顶点的数量为n,边的数量为m
- 朴素Dijkstra算法的时间复杂度是O(n^2)
- 堆优化版Dijkstra算法的时间复杂度是O(mlogn)
从表面上看,朴素Dijkstra算法好像没堆优化版优秀,但其实不然,两个算法都有它们所适用的场景
朴素Dijkstra算法适用于稠密图,堆优化版Dijkstra算法适用于稀疏图。
假设有一个完全图有n个顶点,则边的数量是n(n-1),我们近似成n^2。在这种情况下朴素Dijkstra算法的时间复杂度依旧是O(n^2),而堆优化版的Dijkstra算法的时间复杂度是O(n^2logn)
Bellman-Ford vs SPFA
先讨论两者的时间复杂度,设图中顶点的数量为n,边的数量为m
- Bellman-Ford算法的时间复杂度是O(nm)
- SPFA算法的时间复杂度一般情况下是O(m),最坏情况是O(nm)
时间复杂度上看,SPFA显然是更优秀一些的。但这并不意味着Bellman-Ford算法一无是处
适用场景:
- 若题目中对形成最短路的边数有着特殊的限制,例如边数必须小于k。那么此时只能采用Bellman-Ford算法
- 相反,若题目中没对最短路的边数有着限制,那么SPFA算法是更好的!
二. 所有边权都是正数——Dijkstra算法
- 算法简介
Dijkstra 算法是由荷兰计算机科学家 Edsger Wybe Dijkstra 在1956年提出的,一般解决的是 带权有向图 的 单源最短路径问题。
接下来介绍如何用 Dijkstra 算法求解 单源最短路径问题。
- 算法思路
Dijkstra 算法将会充分利用 最短路径树 的 单调性 这一性质。先定下源点 u,然后采用 贪心 的策略,不断去访问与源点 u 相接且之前未被访问过的最近的顶点 v(这句话里相接的意思是指可以从 u 到达 v),使得当前的最短路径树得到扩充,一直到所有顶点都在当前的最短路径树中,那么就得到了源点 u 到其他所有顶点 v 的最短路径。
我们将当前最短路径树所有的顶点所构成的集合称为 集合S,而不在当前最短路径树中的顶点所构成的集合称为集合V-S。
2.1.常规版dijkstra算法
- 算法步骤
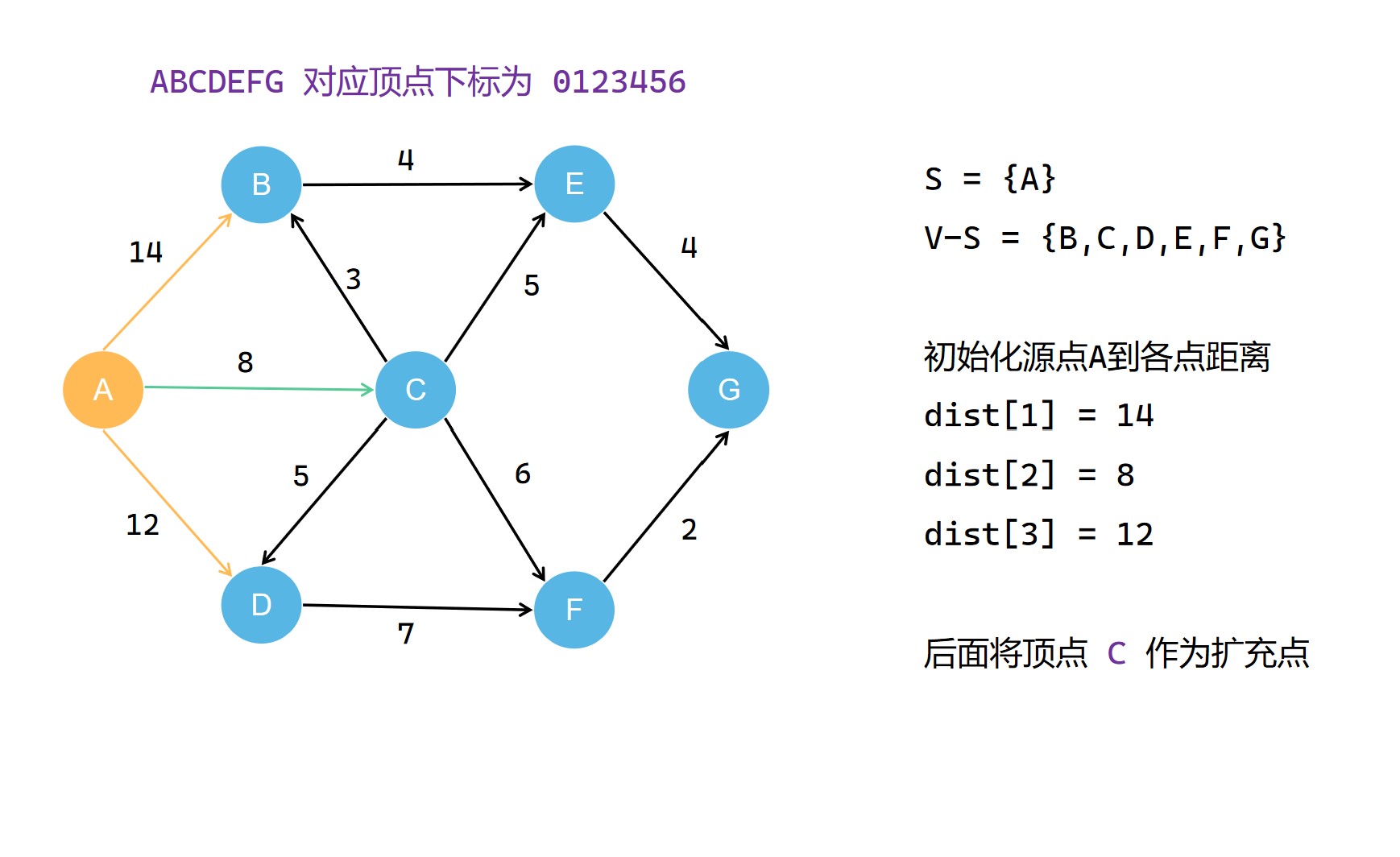
1、首先需要定义一个辅助数组 check[],用于标记每个顶点是否处于当前的 最短路径树 中,后续我们将 最短路径树 称为 集合S。在初始情况下,我们会先将源点 u 划入 集合S;
2、然后我们需要再定义一个数组 dist[],用于记录当前从源点 u 到 v (v∈V-S)的最短路径距离,比如dist[vi]就表示 u 到 vi 的当前最短路径距离。
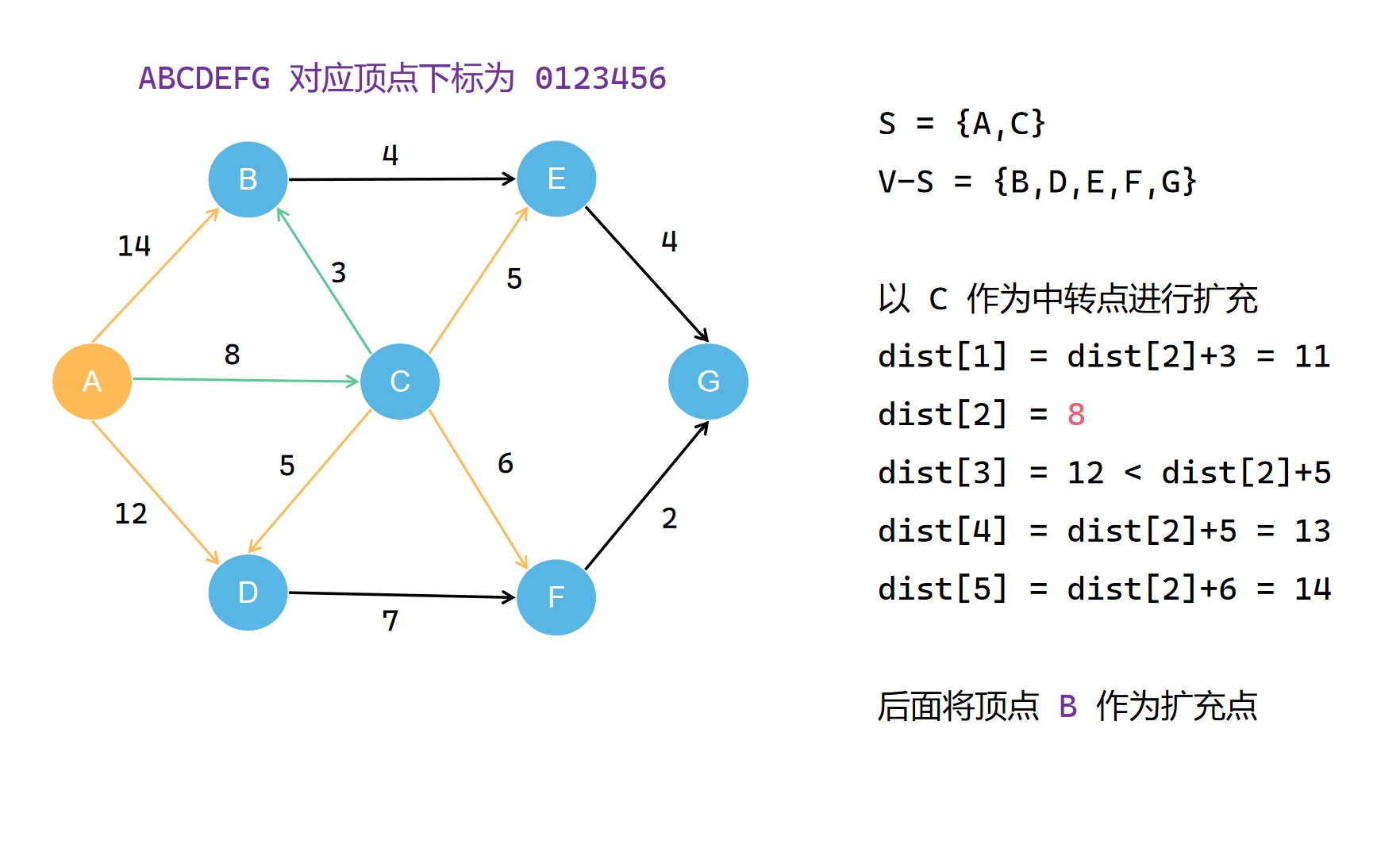
集合S每一次扩充都需要选择当前不在集合S中且到源点 u 最短距离的顶点 t 作为扩充点,并且将其划入集合S。之后的扩充操作中,就以这个 t 作为中转点对 dist[v] 进行更新,使其记录的距离减小。在不断扩充集合S的过程中,dist[v]的记录的距离大小不断减小(可能不变),直到最后,其记录的便是整个图中u 到 v* 的最短的距离;
另外,一开始我们要先初始化源点 u 到其邻接的顶点的距离。
动态演示

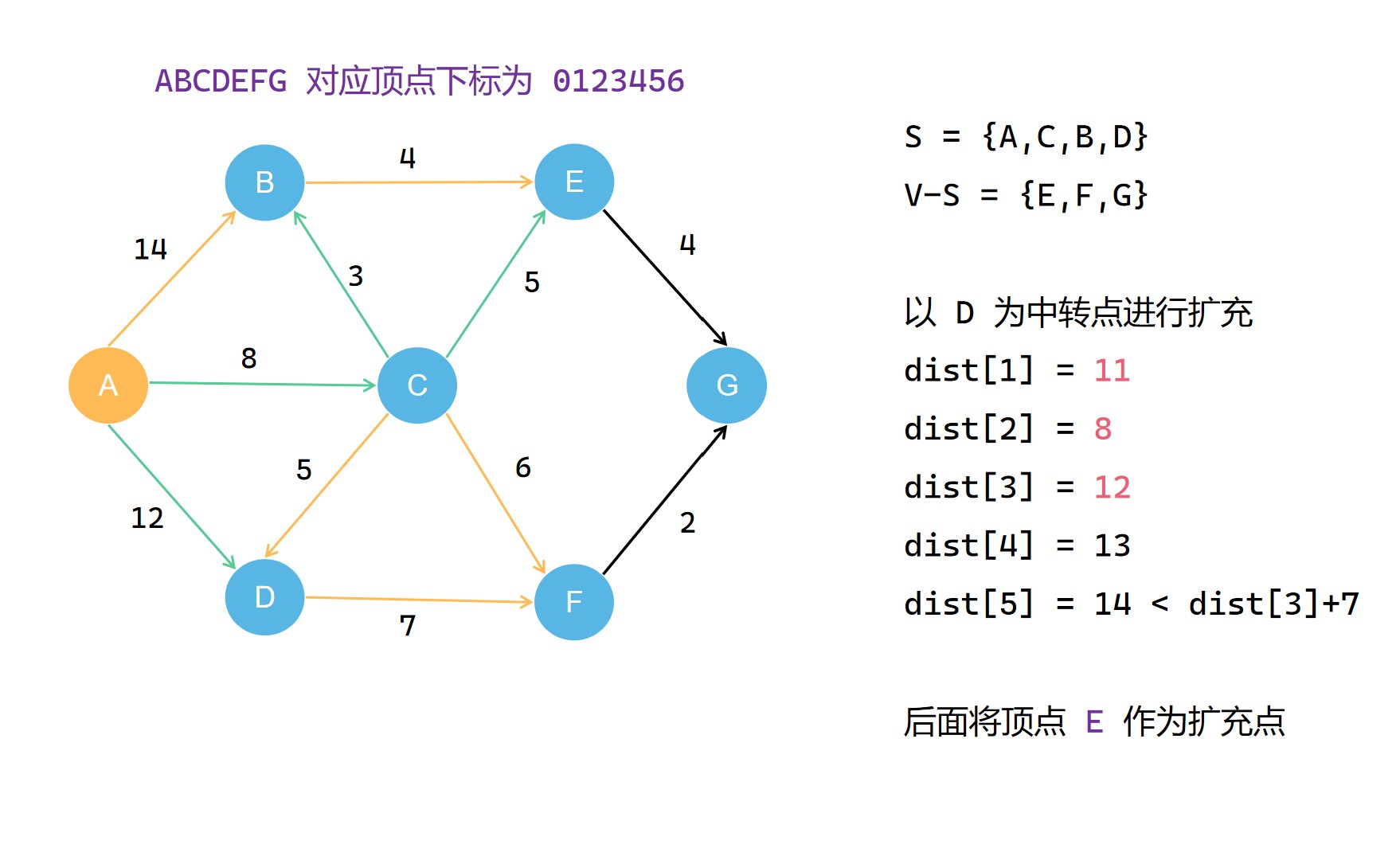
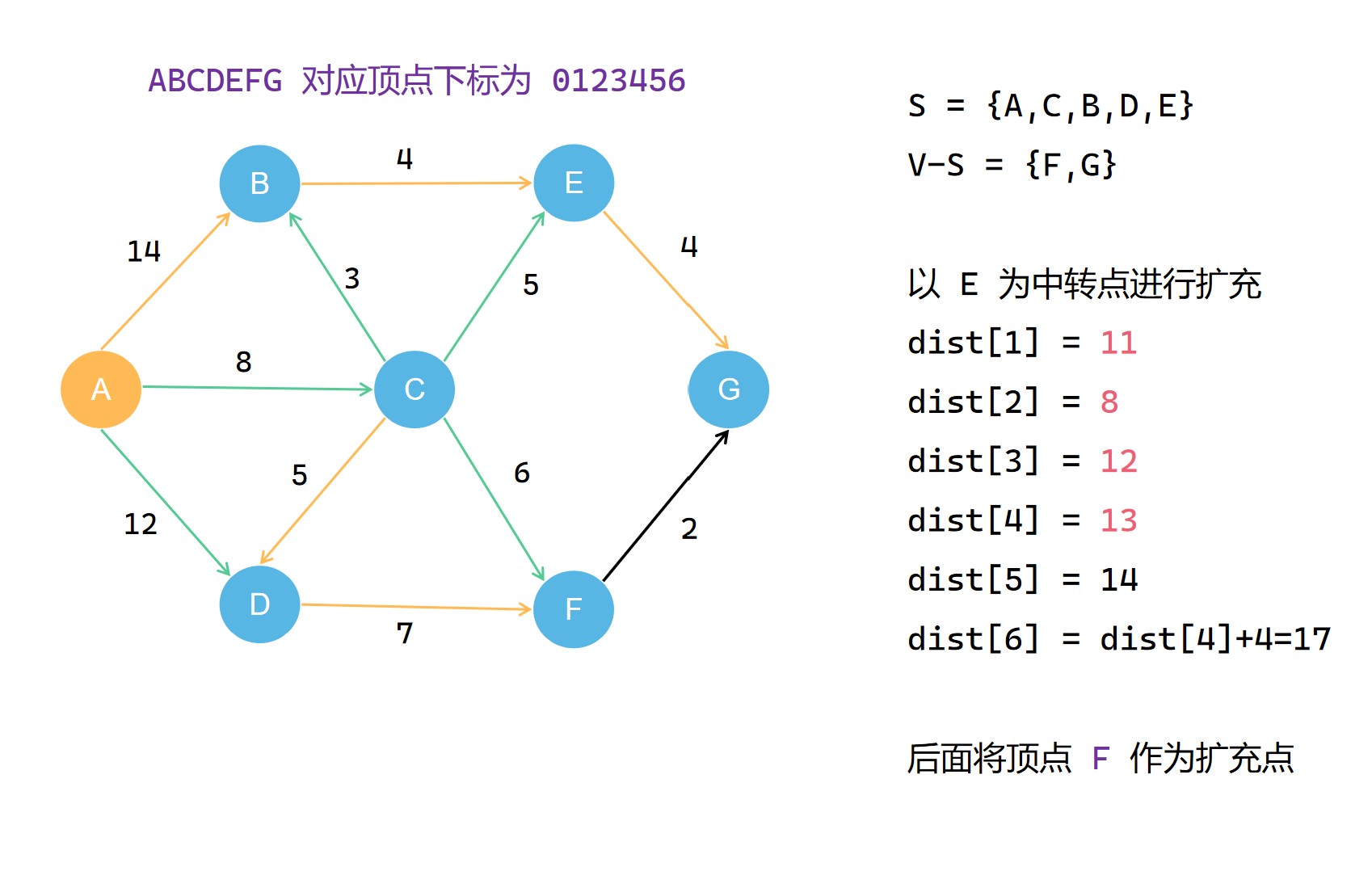
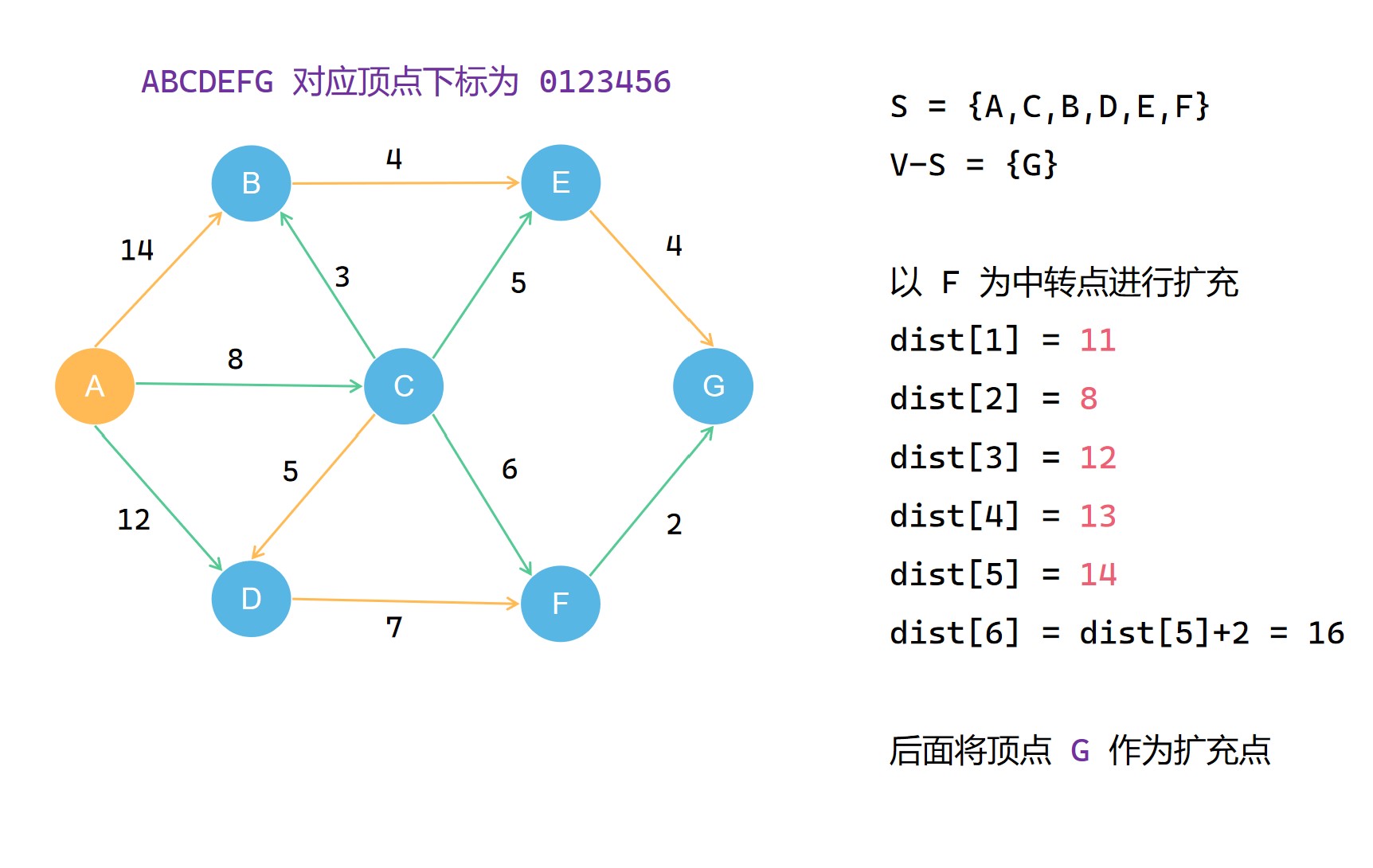

我来实现一下这个代码
邻接表实现
#include<iostream>
#include<cstring>
#include<vector>
#include<cmath>
using namespace std;
const int N = 1e4 + 10, INF = 2147483647;
typedef long long LL;
typedef pair<int, int> PII;
vector<PII>edges[N];
LL dist[N];
bool check[N];
int n, m, s;//n代表有n个结点,m代表有m条边,s代表起点
void dj()
{
for (int i = 0; i <= n; i++) dist[i] = INF;
dist[s] = 0;
for (int i = 1; i <= n; i++)
{
int minnode = 0;
for (int j = 1; j <= n; j++)
{
if (check[j] == false && dist[j] < dist[minnode])
minnode = j;
}
check[minnode] = true;
for (auto& tmp : edges[minnode])
{
int y = tmp.first, w = tmp.second;
dist[y] = min(dist[y], dist[minnode] + w);
}
}
for (int i = 1; i <= n; i++)
{
cout << dist[i] << " ";
}
}
int main()
{
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int x, y, z;
cin >> x >> y >> z;
edges[x].push_back({ y,z });
}
dj();
}这个代码,我写了十遍才写正确,所以大家要好好理解里面的内容。
2.2.堆优化版dijkstra算法
我们仔细看上面这个代码
int minnode = 0;
for (int j = 1; j <= n; j++)
{
if (check[j] == false && dist[j] < dist[minnode])
minnode = j;
}这一段就是在寻找dist数组的最小值,寻找最小值?我们可以使用优先级队列来实现啊!!!
注意if(check[j]==false)要放到外面来啊!!!!
#include<iostream>
#include<cstring>
#include<queue>
#include<vector>
using namespace std;
const int N = 1e5+10;
typedef pair<int, int> PII;
vector<PII>edges[N];
int dist[N];
bool check[N];
int n, m,s;//n个节点,m条边,s作为起点
void dijkstra()
{
memset(dist, 0x3f, sizeof(dist));
priority_queue<PII,vector<PII>,greater<PII>>heap;
dist[s] = 0;//s作为起点
heap.push({ dist[s],s });//注意这个顺序不能变
while (heap.size())
{
int minnode = heap.top().second;//堆顶的就是dist数组里面的最小的
heap.pop();
if (check[minnode] == true)//如果确定好了最短路径,就直接进入下一轮循环
{
continue;
}
check[minnode] = true;
for (auto& tmp : edges[minnode])//更新与minnode相连的那些节点到起点的最短路径
{
int i = tmp.first, w = tmp.second;
if (dist[i] > dist[minnode] + w)
{
dist[i] = dist[minnode] + w;
heap.push({ dist[i],i});
}
}
}
for (int i = 1; i <= n; i++)
{
cout << dist[i] << " ";
}
}
int main()
{
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int x, y, z;
cin >> x >> y >> z;
edges[x].push_back({ y,z });
}
dijkstra();
}事实上,这里有一个非常容易出错的点!!!看下面
heap.push({ dist[s],s });//注意这个顺序不能变上面这个不能写成下面这个
heap.push({ s, dist[s]});这个是非常致命的!!因为我们这个优先级队列比较的是pair里面的first成员,而我们要的是dist数组的最小值。所以我们只能将dist[s]放到第一个来。
事实上,我建议大家自己去使用结构体来实现一下这个,我下面给大家实现了一个
#include<iostream> #include<cstring> #include<queue> #include<vector> using namespace std; const int N = 1e5+10; struct node { int md; int dis;//实际上存储dist[md] bool operator<(const node& b)const//注意这里 { return dis > b.dis; } }; vector<pair<int,int>>edges[N]; int dist[N]; bool check[N]; int n, m,s;//n个节点,m条边,s作为起点 void dijkstra() { memset(dist, 0x3f, sizeof(dist)); priority_queue<node>heap; dist[s] = 0;//s作为起点 heap.push({ s,dist[s]});//注意这个顺序不能变 while (heap.size()) { int minnode = heap.top().md;//堆顶的就是dist数组里面的最小的 heap.pop(); if (check[minnode] == true)//如果确定好了最短路径,就直接进入下一轮循环 { continue; } check[minnode] = true; for (auto& tmp : edges[minnode])//更新与minnode相连的那些节点到起点的最短路径 { int i = tmp.first, w = tmp.second; if (dist[i] > dist[minnode] + w) { dist[i] = dist[minnode] + w; heap.push({ i,dist[i]}); } } } for (int i = 1; i <= n; i++) { cout << dist[i] << " "; } } int main() { cin >> n >> m >> s; for (int i = 1; i <= m; i++) { int x, y, z; cin >> x >> y >> z; edges[x].push_back({ y,z }); } dijkstra(); }
三. 存在负权边——bellman-ford算法,spfa算法
3.1.负权边对dijkstra算法的影响
如果有一个复杂的图,比如节点A到B权2,A到C权3,B到D权1,C到B权-4。这时候,假设要找A到D的最短路径。正确的路径应该是A->C->B->D,总权3 + (-4) +1 =0。
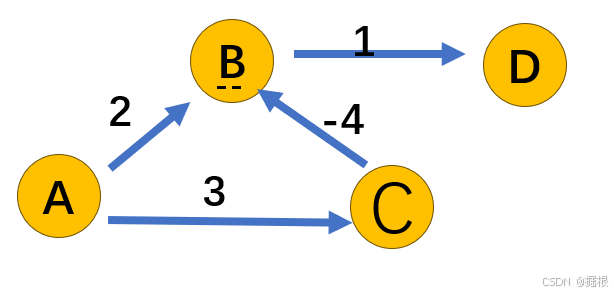
而Dijkstra的处理过程:
初始S={A},距离B=2,C=3,D=无穷。选择B加入S,此时松弛B的邻居D,得到2+1=3。此时D的距离是3。然后下一步,剩下的未加入S的节点是C和D,其中C的距离是3,所以选C加入S。然后松弛C的邻居B,此时C到B的权是-4,所以从A到C再到B的距离是3+(-4)=-1,这比B原来的距离2更短。但此时B已经被加入S了,所以Dijkstra不会处理这种情况,所以B的距离仍然保持为2,而不会更新到-1。这导致后续的D的距离也无法得到正确的更新。
这时候,问题出现了。因为Dijkstra在将B加入S之后,认为B的最短距离已经确定,不会再考虑其他路径到B的可能更短的路径。例如,当处理C的时候,发现A->C->B的路径总权更小,但由于B已经在S中,所以不会再次处理B的邻居。这时候,如果B被错误地认为已经找到最短路径,那么后续从B出发的边(比如到D)的松弛可能没有考虑到更短的路径。
所以在这个例子中,正确的路径应该是A->C->B->D,总权3-4+1=0。但Dijkstra的处理过程会是:
1. S={A}, d[A]=0,d[B]=2,d[C]=3,d[D]=∞。
2. 选B(d=2)加入S。现在S={A,B}。然后松弛B的邻居D,d[D]=2+1=3。
3. 现在剩下的节点是C(3)和D(3)。选C加入S。S={A,B,C}。松弛C的邻居B,此时新的距离是3+(-4)=-1,但B已经在S中,所以这一步不会被执行,或者即使执行了,B的距离会被更新吗?根据Dijkstra的步骤,第四步是更新相邻点的d[y],不管是否在S中吗?
或者,Dijkstra的松弛步骤是否会在每次加入节点后,对所有相邻的节点进行松弛,不管它们是否在S中?
比如,当处理节点C时,松弛它的邻居B,此时B已经在S中了,这时候是否还会比较d[B]和d[C]+边的权?
根据Dijkstra的标准实现,一旦节点加入S,它的d值不再被更新。因此,当处理C的时候,虽然C到B的边权为-4,导致d[C]+(-4)=3-4=-1,比当前的d[B]=2更小,但是B已经在S中,所以不会更新,也不会触发任何操作。因此,D的d值仍然是3,而正确的路径应该经过C->B之后得到更小的d[B],进而导致d[D]可以更小。
所以,在这个例子中,Dijkstra算法会错误地计算A到D的最短路径为3(通过A->B->D),而实际上正确的路径是0(A->C->B->D)。
这说明,当存在负权边时,已经加入集合S的节点的最短距离可能被后续的松弛操作更新,但由于Dijkstra算法不会处理这种情况,导致结果错误。
因此,Dijkstra算法的前提条件是没有负权边,这样一旦节点被加入S,其最短路径已经确定,后续的松弛操作不会影响它。而存在负权边时,这个条件不成立,导致算法失效。
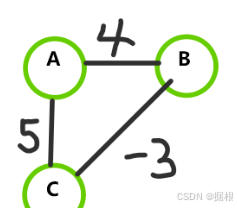
这里有一个简单的例子:
从A到B的最短路。
用Dijkstra算法,第一步就能得到所谓的最短路径长度4,不会去考虑边(C,B)。
而实际上最短路径却需要加入边(C, B),长度是2。
3.2. bellman-ford算法
Dijkstra算法无法解决存在存在负向边的图中最短路径问题。
为了解决此问题,美国应用数学家Richard Bellman (理查德.贝尔曼, 动态规划的提出者)于1958 年发表了该算法。
Bellman-Ford算法是一种基于逐次逼近思想进行最短路径求解的算法。其可以被应用在带负权的有向图中,Bellman-ford 算法比dijkstra算法更具普遍性,因为它对边没有要求,可以处理负权边与负权边回路。缺点是时间复杂度过高,高达O(VE), V为顶点数,E为边数。
其核心思想为:对于任意一个具有n个节点的图 G ,任意两点之间的最短路径至多包含 n−1 条边。因此我们可以反复通过对边的松弛来得到当前图的最短路径。
那下面我们还是对照着图再给大家走一遍Bellman-Ford算法的过程
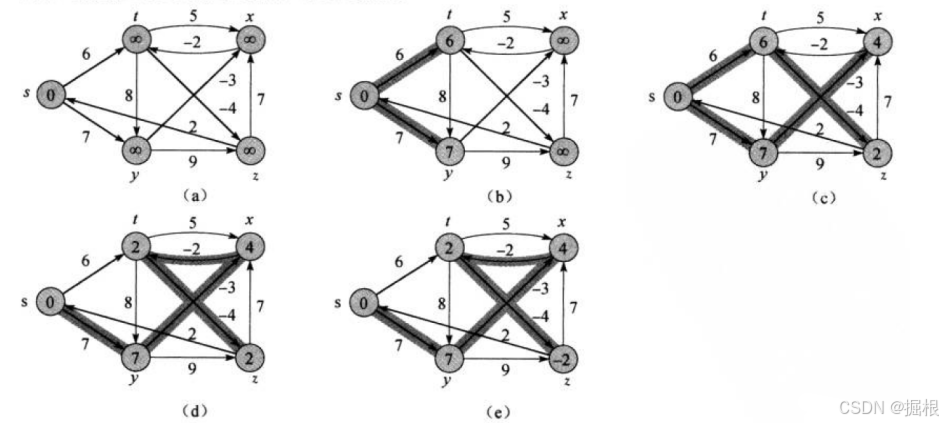
就以这个图为例,我们来走一遍整个过程,当然上面这个图可能没有每一步都画出来,不是特别详细
那我们来走一个详细的:
这是起始状态,s位为源点
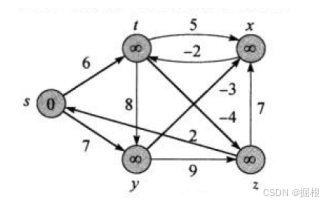
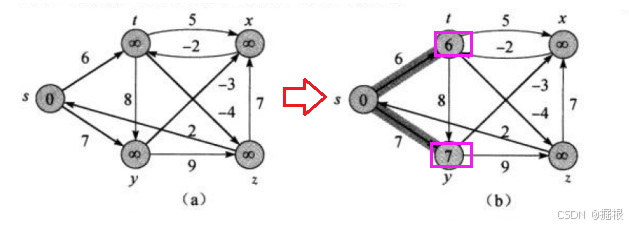
那首先对s的相邻顶点进行松弛, 那对于顶点s的话,这里有以s为起点的两条边(s->t,s->y)分别连接着顶点t和y,所以dist[t]和dist[y]肯定都会更新(因为注意dist[y]和diat[t]目前是INF,dist[y]>dist[s]+7,dist[t]>dist[s]+6) ,那第一次松弛之后就是这样:
那然后对y的相邻顶点进行松弛,那对于顶点y的话,这里有以y为起点的两条边(y->x,y->z)分别连接着顶点x和z,所以dist[x]和dist[z]肯定都会更新(因为注意dist[x]和diat[z]目前是INF,dist[x]>dist[y]-3=4,dist[z]>dist[y]+9=16)
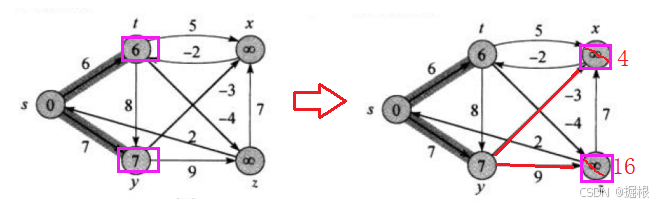
接着是z,那对于顶点z的话,这里有以z为起点的2条边(z->s,z->x)分别连接着顶点s和x,所以dist[s]不更新(因为注意dist[s]目前是0,dist[s]<dist[z]+2=16,所以不更新),dist[z]也不更新(因为注意dist[x]目前是4,dist[x]<dist[z]+7=23,所以不更新)
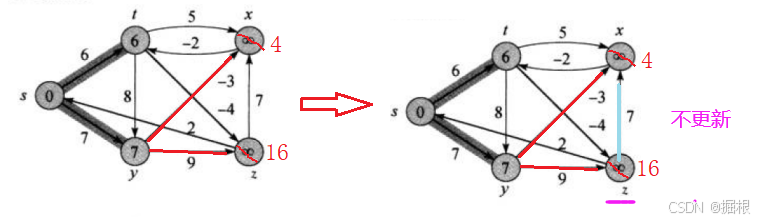
接着是t,那对于顶点t的话,这里有以t为起点的2条边(t->z,t->x)分别连接着顶点z和x,所以dist[x]不更新(因为注意dist[x]目前是4,dist[x]<dist[t]+5=11,所以不更新),dist[z]肯定会更新(因为注意dist[z]目前是16,dist[z]>dist[t]-4=2)
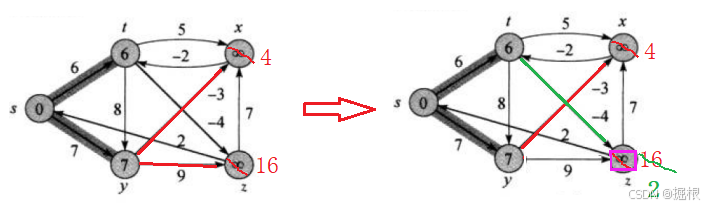
最后是x,那对于顶点x的话,这里有以x为起点的1条边(x->t)连接着顶点t,所以dist[t]更新(因为注意dist[t]目前是6,dist[t]<dist[x]-2=2,所以更新)
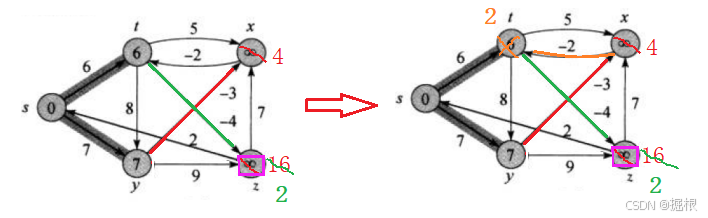
那现在其实一趟迭代就完成了,所有顶点的相邻顶点都完成了一次松弛
我们现在得到的是这样一个样子:
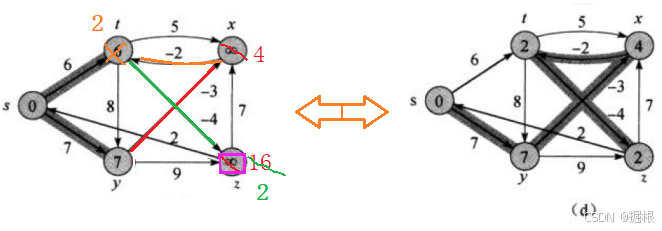
其实就是最开始给大家看的图里面倒数第二个
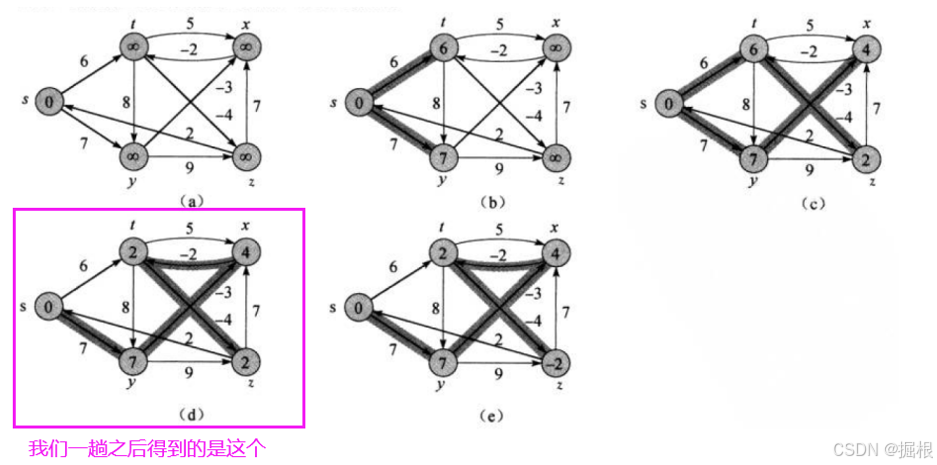
可是最后一幅才是最终结果啊:
是的,所以我们上面也说了: Bellman-Ford算法是比较暴力的把所有的边都更新(即先后对所有的顶点的相邻顶点进行松弛),而不像Dijkstra算法的贪心那样每次选的都是最短的,也因此它一遍过后可能得不出最短的路径,可能需要进行多次迭代
那我们就继续进行第二遍迭代:
第二遍起始状态就是这样的
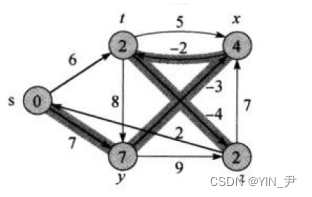
首先第一个还是s顶点,那这里没有边需要更新; 然后是y,也没有边更新; 接着z,也没有更新; 再下面t,那对于顶点t的话,这里有以t为起点的2条边(t->z,t->x)分别连接着顶点z和x,所以dist[x]不更新(因为注意dist[x]目前是4,dist[x]<dist[t]+5=11,所以不更新),dist[z]肯定会更新(因为注意dist[z]目前是2,dist[z]>dist[t]-4=-2),所以z的最短路径更新为-2
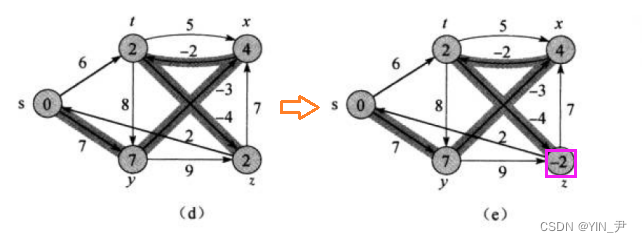
我们看到这次边并没有变化,只是权值更新了; 因为上一轮z的最短路径确定为s->t->z:2(此时t的最短路径是s->t:6),而在第二轮 t的最短路径又被更新成了s->y->x->t:2 (此时t的最短路径是s->y->x:2),
t的最短路径变了,导致z的最短路径也变了,但是在第二轮才更新出来
最后顶点x,也没有边更新
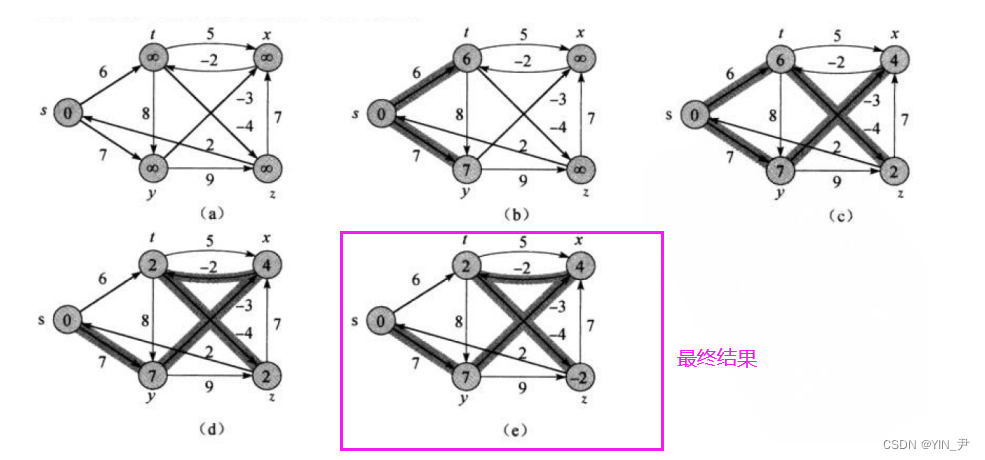
此时就得到了最终结果,所以我们看到这里这个图起始更新了两轮(后面代码写出来我们也可以验证一下是不是两轮)就得到了最终结果,后续即使再进行迭代,也不会有新的路径更新了。 所以我们说了可以提前结束,不一定非要迭代V-1 次, V 是图中顶点的数量
那我们也来说一下,为什么最多要迭代V-1次呢?
因为如果一个图有V个顶点,那图中路径最多也只经过V-1条边,所以V-1次迭代可以保证所有顶点的最短路径被正确地计算更新。 当然我们可以通过判断提前结束。
好了,到现在,我们就可以写代码了
#include <iostream>
#include <vector>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e4 + 10, INF = 2147483647;
int n, m, s;
vector<PII> edges[N];
int dist[N];
void bf()
{
for (int i = 0; i <= n; i++) dist[i] = INF;
dist[s] = 0;
bool flag = false;
for (int i = 1; i < n; i++)
{
flag = false; //flag是用来判断是否进⾏了松弛操作
for (int u = 1; u <= n; u++)
{
if (dist[u] == INF) continue;
for (auto& t : edges[u])
{
int v = t.first, w = t.second;
if (dist[u] + w < dist[v])
{
dist[v] = dist[u] + w;
flag = true;
}
}
}
if (flag == false) break;
}
for (int i = 1; i <= n; i++) cout << dist[i] << " ";
}
int main()
{
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int u, v, w; cin >> u >> v >> w;
edges[u].push_back({ v, w });
}
bf();
return 0;
}3.3 . spfa算法
SPFA算法是求解单源最短路径问题的一种算法,由理查德·贝尔曼(Richard Bellman) 和 莱斯特·福特 创立的。有时候这种算法也被称为 Moore-Bellman-Ford 算法,因为 Edward F. Moore 也为这个算法的发展做出了贡献。它的原理是对图进行V-1次松弛操作,得到所有可能的最短路径。其优于迪科斯彻算法的方面是边的权值可以为负数、实现简单,缺点是时间复杂度过高,高达 O(VE)。但算法可以进行若干种优化,提高了效率。
算法的思路:
我们用数组dis记录每个结点的最短路径估计值,用邻接表或邻接矩阵来存储图G。我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止。
下面我们采用SPFA算法对下图求v1到各个顶点的最短路径,通过手动的方式来模拟SPFA每个步骤的过程
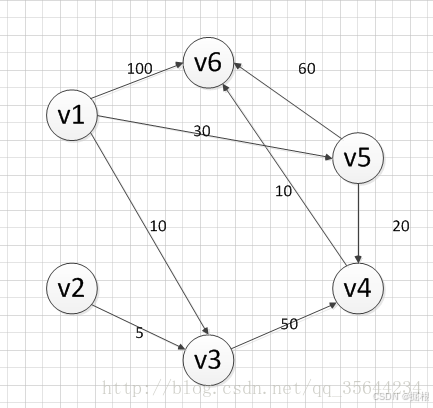
初始化:
首先我们先初始化数组dis如下图所示:(除了起点赋值为0外,其他顶点的对应的dis的值都赋予无穷大,这样有利于后续的松弛)

此时,我们还要把v1加入队列:{v1}
现在进入循环,直到队列为空才退出循环。
- 第一次循环:
首先,队首元素出队列,即是v1出队列,然后,对以v1为弧尾的边对应的弧头顶点进行松弛操作,可以发现v1到v3,v5,v6三个顶点的最短路径变短了,更新dis数组的值,得到如下结果:

我们发现v3,v5,v6都被松弛了,而且不在队列中,所以要他们都加入到队列中:{v3,v5,v6}
- 第二次循环
此时,队首元素为v3,v3出队列,然后,对以v3为弧尾的边对应的弧头顶点进行松弛操作,可以发现v1到v4的边,经过v3松弛变短了,所以更新dis数组,得到如下结果:

此时只有v4对应的值被更新了,而且v4不在队列中,则把它加入到队列中:{v5,v6,v4}
- 第三次循环
此时,队首元素为v5,v5出队列,然后,对以v5为弧尾的边对应的弧头顶点进行松弛操作,发现v1到v4和v6的最短路径,经过v5的松弛都变短了,更新dis的数组,得到如下结果:

我们发现v4、v6对应的值都被更新了,但是他们都在队列中了,所以不用对队列做任何操作。队列值为:{v6,v4}
- 第四次循环
此时,队首元素为v6,v6出队列,然后,对以v6为弧尾的边对应的弧头顶点进行松弛操作,发现v6出度为0,所以我们不用对dis数组做任何操作,其结果和上图一样,队列同样不用做任何操作,它的值为:{v4}
- 第五次循环
此时,队首元素为v4,v4出队列,然后,对以v4为弧尾的边对应的弧头顶点进行松弛操作,可以发现v1到v6的最短路径,经过v4松弛变短了,所以更新dis数组,得到如下结果:

因为我修改了v6对应的值,而且v6也不在队列中,所以我们把v6加入队列,{v6}
- 第六次循环
此时,队首元素为v6,v6出队列,然后,对以v6为弧尾的边对应的弧头顶点进行松弛操作,发现v6出度为0,所以我们不用对dis数组做任何操作,其结果和上图一样,队列同样不用做任何操作。所以此时队列为空。
OK,队列循环结果,此时我们也得到了v1到各个顶点的最短路径的值了,它就是dis数组各个顶点对应的值,如下图:

#include<iostream>
#include<queue>
#include<vector>
#include<cstring>
using namespace std;
const int N = 2e3 + 10,INF=0x3f3f3f3f;
typedef pair<int, int> PII;
vector<PII>edges[N];
int dist[N];
bool check[N];//标记哪些节点在队列里面
int n, m, s;
void spfa()
{
memset(dist, INF, sizeof(dist));
queue<int>heap;
heap.push(s);
dist[s] = 0;
check[s] = true;//u入队列了,所以要设置为true
while (heap.size())
{
int u = heap.front();
heap.pop();
check[u] = false;//u出队列了,所以要设置为false
for (auto& tmp : edges[u])
{
int y = tmp.first, w = tmp.second;
if (dist[y] > dist[u] + w)
{
dist[y] = dist[u] + w;
if (check[y] == false)
{
heap.push(y);
check[y] = true;
}
}
}
}
for (int i = 1; i <= n; i++)
cout << dist[i] << " ";
}
int main()
{
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int x, y, z;
cin >> x >> y >> z;
edges[x].push_back({ y,z });
}
spfa();
}注意:虽然大多数情况下spfa跑的好快,但其最坏情况下的时间复杂度为O(nm)。将其卡到这个复制度也是不难的,所以在没有负边权的情况最好使用dijkstra算法。
题目一——P3371 【模板】单源最短路径(弱化版) - 洛谷
我们注意到这个权值是大于0的,所以我们优先使用dijkstra算法来解决。
这题实际上使用常规版本的dijkstra算法就能解决。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10,INF=2147483647;
typedef long long LL;
typedef pair<int, int> PII;
vector<PII>edges[N];
LL dist[N];
bool check[N];
int n,m,s;
void dijkstra()
{
for(int i=0;i<=n;i++) dist[i]=INF;
dist[s]=0;
for(int i=1;i<=n;i++)
{
int minnode=0;
for(int j=1;j<=n;j++)
{
if(check[j]==false&&dist[j]<dist[minnode])
{
minnode=j;
}
}
check[minnode]=true;
for(auto&tmp:edges[minnode])
{
int y=tmp.first,w=tmp.second;
dist[y]=min(dist[y],dist[minnode]+w);
}
}
for(int i=1;i<=n;i++)
{
cout<<dist[i]<<" ";
}
}
int main()
{
cin>>n>>m>>s;
for(int i=1;i<=m;i++)
{
int x,y,z;
cin>>x>>y>>z;
edges[x].push_back({y,z});
}
dijkstra();
}
实际上这题也是可以使用优化版本的dijkstra算法来解决的。非常简单,我这里给大家列一下吧
#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10,INF=2147483647;
typedef long long LL;
typedef pair<int, int> PII;
vector<PII>edges[N];
LL dist[N];
bool check[N];
int n,m,s;
void dijkstra()
{
for(int i=0;i<=n;i++) dist[i]=INF;
priority_queue<PII,vector<PII>,greater<PII>>heap;
dist[s]=0;
heap.push({dist[s],s});
while(heap.size())
{
int minnode=heap.top().second;
heap.pop();
if(check[minnode]==true) continue;
check[minnode]=true;
for(auto&tmp:edges[minnode])
{
int y=tmp.first,w=tmp.second;
if(dist[y]>dist[minnode]+w)
{
dist[y]=dist[minnode]+w;
heap.push({dist[y],y});
}
}
}
for(int i=1;i<=n;i++)
{
cout<<dist[i]<<" ";
}
}
int main()
{
cin>>n>>m>>s;
for(int i=1;i<=m;i++)
{
int x,y,z;
cin>>x>>y>>z;
edges[x].push_back({y,z});
}
dijkstra();
}
题目二——P4779 【模板】单源最短路径(标准版) - 洛谷
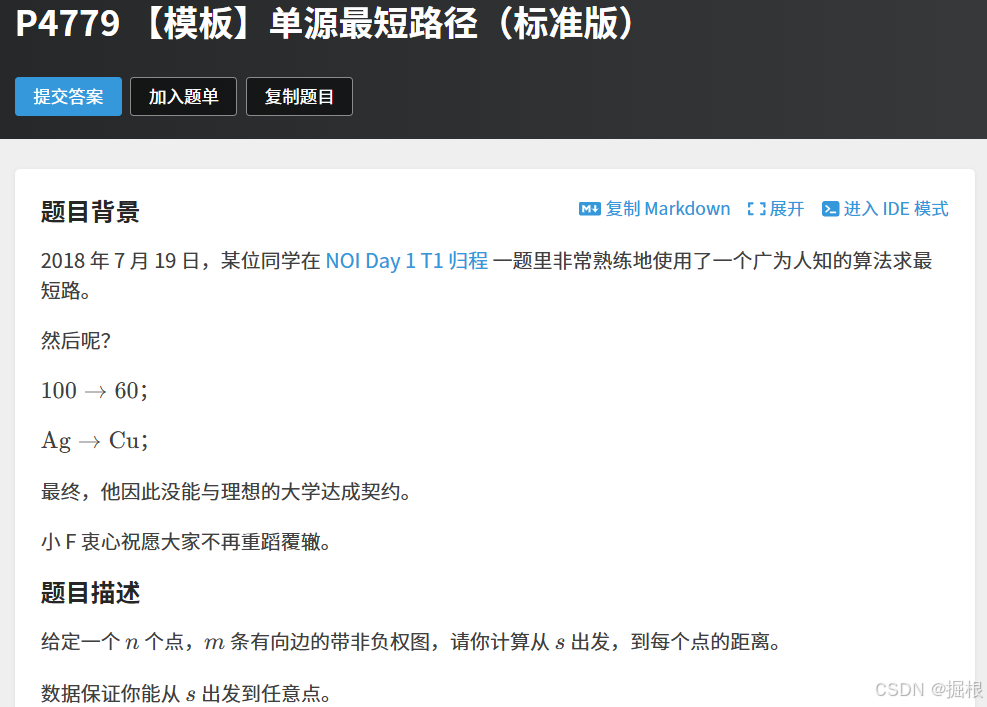
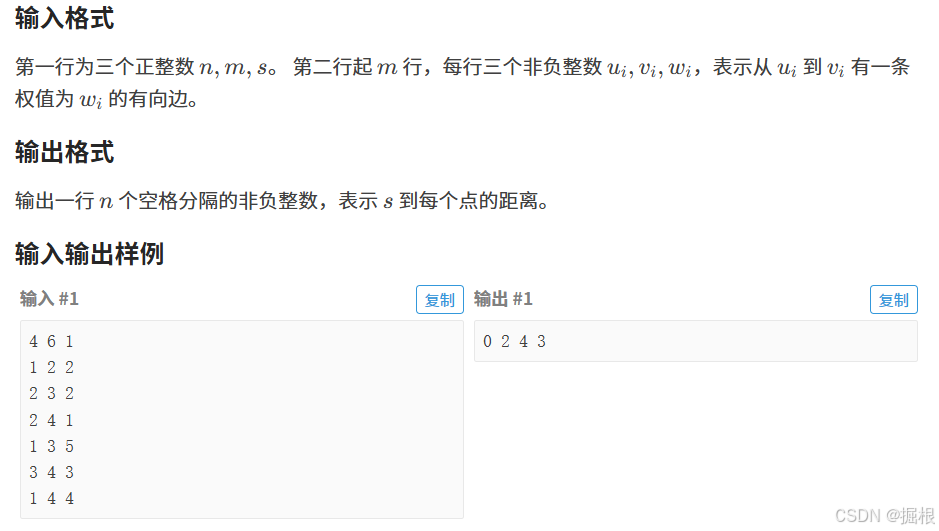

这题的权值不是负数,我们优先选择使用dijkstra算法。但是使用普通版本的dijkstra会超时,所以我们得使用堆优化版本的dijkstra算法
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
typedef pair<int,int> PII;
vector<PII>edges[N];
int dist[N];
bool check[N];
int n,m,s;
void dijkstra()
{
memset(dist,0x3f,sizeof(dist));
priority_queue<PII,vector<PII>,greater<PII>>heap;
dist[s]=0;
heap.push({dist[s],s});
while(heap.size())
{
int minnode=heap.top().second;
heap.pop();
if(check[minnode]==true)
{
continue;
}
check[minnode]=true;
for(auto&tmp:edges[minnode])
{
int y=tmp.first,w=tmp.second;
if(dist[y]>dist[minnode]+w)
{
dist[y]=dist[minnode]+w;
heap.push({dist[y],y});
}
}
}
for(int i=1;i<=n;i++)
{
cout<<dist[i]<<" ";
}
}
int main()
{
cin>>n>>m>>s;
for(int i=1;i<=m;i++)
{
int x,y,z;
cin>>x>>y>>z;
edges[x].push_back({y,z});
}
dijkstra();
} 
题目三——P3385 【模板】负环 - 洛谷
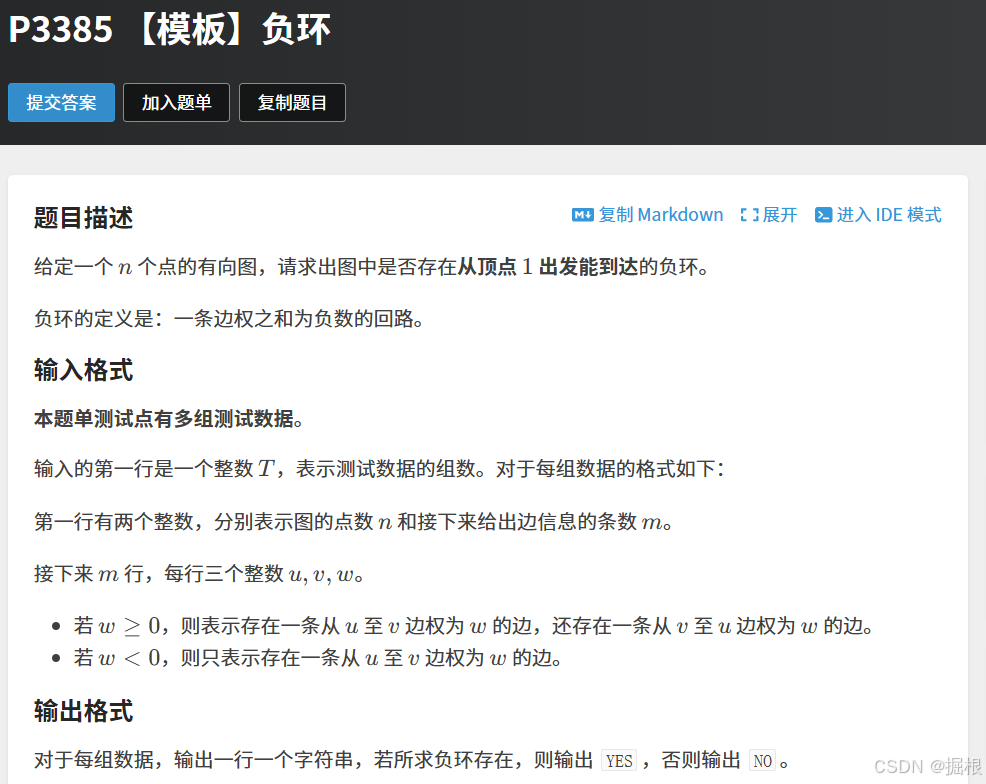
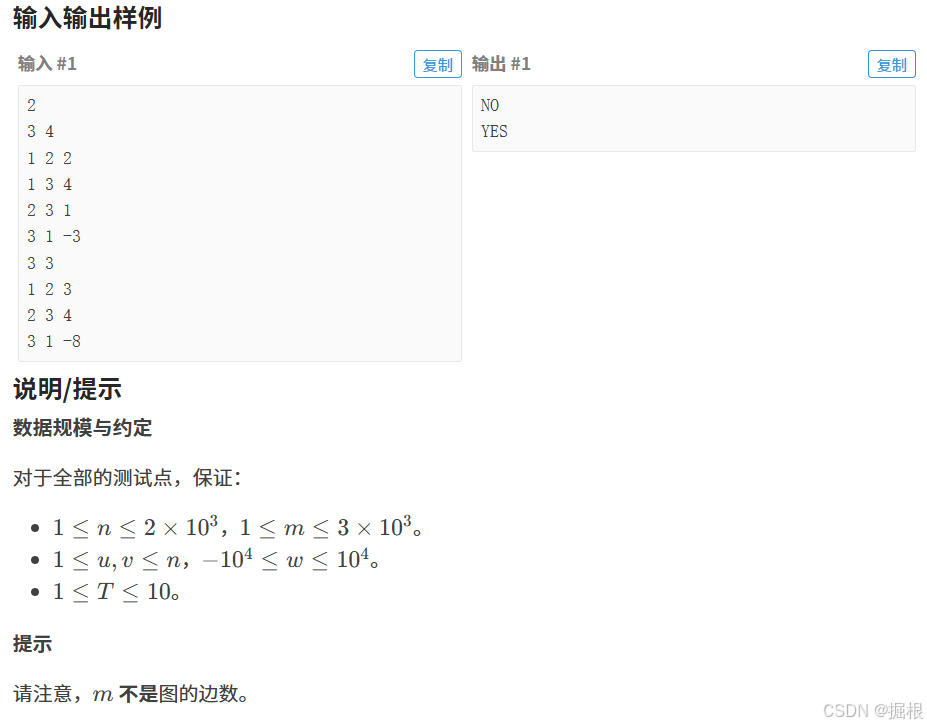
什么是负权环?我们看下面这个图,2-10+7=-1,也就是说经过一次这个环,需要付出-1的代价
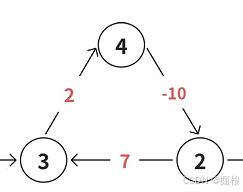
我们先看一下负权环为什么这么特殊:在一个图中,只要一个多边结构不是负权环,那么重复经过此结构时就会导致代价不断增大。在多边结构中唯有负权环会导致重复经过时代价不断减小,故在一些最短路径算法中可能会凭借不断重复经过负权环来得到权和为无穷小的最短路径,但因重复经过边不符合简单路径的定义导致这些算法跑最短路时要避免有负权环的出现。
这类算法说的就是Bellman-ford以及基于它进行优化的spfa了。由于负权环的出现导致这些算法的正确性失效。但这世上没有绝对的废物,我们也可以反过来利用这两种算法对负权环的敏感性来判断一个图内有无负权环。
首先我们需要明白:对于n个顶点的图,对于单源最短路径,每次对n条边进行松弛,理论上需要做n-1次松弛,因为最短路径最多有n-1条边。如果在n-1次之后还能继续松弛,说明存在负权回路,因为负权回路可以让路径无限缩短。
结合一下这两个算法的原理,就能很简单地明白判负权回路的原理了:
bellman-ford算法判断负环
Bellman-ford的原理即每次做一次枚举所有边进行一次大松弛操作后必有所有最短路径的第一条边(起点为源点的边)被确定(尽管我们并不确切地知道是哪一条边),被确定后,则会凭这条边再下一次大松弛操作再确定第二条边,以此类推。由于n个点的图的两点间最短路径最长有n-1条边,所以最多要n-1次大松弛就能把一个单源最短路求出(但实际上很多时候不到n-1次大松弛操作,就没有可松弛的了,即已经找到答案,可记录当前大松弛是否做过松弛操作,或基于该缺点改进为spfa)。但如果发现在n-1次大松弛操作后(也就是第n次)还有松弛操作可做,就说明负权回路出现了。时间复杂度O(nm)(m为边数),有点大。
#include<bits/stdc++.h>
using namespace std;
const int N=6e3+10,INF=0x3f3f3f3f;
typedef pair<int,int> PII;
vector<PII>edges[N];
int dist[N];
int n,m;
bool bf()//判断是否有负环
{
memset(dist,INF,sizeof(dist));
dist[1]=0;
bool check=false;
for(int i=1;i<=n;i++)//让它执行n次,如果第n次还进行了松弛操作,就代表有负环
{
check=false;
for(int j=1;j<=n;j++)//遍历n个节点
{
if(dist[j]==INF)
{
continue;
}
for(auto&tmp:edges[j])
{
int y=tmp.first,w=tmp.second;
if(dist[y]>dist[j]+w)
{
dist[y]=dist[j]+w;
check=true;
}
}
}
if(check==false) break;
}
return check;//check代表第n次中是否进行了松弛操作
}
int main()
{
int T;
cin>>T;
while(T--)
{
cin>>n>>m;
for(int i=1;i<=n;i++)//注意一定要清空
{
edges[i].clear();
}
while(m--)
{
int u,v,w;
cin>>u>>v>>w;
edges[u].push_back({v,w});
if(w>=0)
{
edges[v].push_back({u,w});
}
}
int ret=bf();
if(ret==true)
cout<<"YES"<<endl;
else
cout<<"NO"<<endl;
}
} 
SPFA算法版本判断负环
SPFA则为针对Bellman-ford的缺点做的使每次做的松弛操作更有效的优化。发现在Bellman-ford第一次大松弛中只有松弛从源点出来的边才是有效的,松弛时当边的起点有效(被松弛过)时松弛操作才有效。那我们就不妨每次都只做有效的松弛操作,建一个队列,开始时将源点入队,每次从队头弹出head,尝试松弛所有head的邻接点,若松弛成功且该邻接点不在队中,就把它入队;否则什么也不干。时间复杂度为O(vm),v是一个平均值为2的常数。(因为当我们每次都做有效的松弛操作时,就会发现跑最短路快了很多,在大多数情况下可以吊打各个最短路算法。当然也特别容易被特殊数据卡,此时时间复杂度容易退化为O(nm))。类似的,spfa每做“一层”(层的概念类似于BFS的层)松弛操作就会确定所有最短路的一条边(虽然我们不知道是那条),故最极限的情况spfa做n-1层(源点不用看)松弛操作就可以求出一个单源最短路了。
每层松弛操作只会导致一个点最多出队一次(同一个点两次出队中间经过了:上一层的点全部出队,下一层的先该点再入队前入队的点出队。当边多的点去更新到还在队里的点的值时,那个点还可以算是上一层的,只不过更优了一点),由于最多只有n-1层(第i层(源点第0层)全部出队即求出了所有长度为i的最短路。一条最短路最多有n-1条边),所以每个点的出队次数最多应不超过n-1。不幸的是,spfa的松弛操作碰上负权环时,会发现,从环的某一点a开始松弛其他点时,由于是负权环,所以绕了一圈回来后一定会发现a要被松弛为更小的值b(环外的点松弛环上的点只会使b更小),故就有无限循环松弛出现。记录每个点的出队次数,当发现有一个点的出队次数大于等于n,即为有负权环出现了,或记录每个点在队中没有自己时入队 的次数也可以,这样更快。(BFS版spfa)
善意的提醒:解题推理时从某个结构的基础组成部分入手并扩展,常常遇到惊喜~~~
后记:
如在无向图用spfa算法解最短路或判负环,点入队时要记录“所来的边的对应边”(否则一条负边就会被判成负环)
判断负权回路的话,dfs版spfa在大多情况下优于bfs版spfa。且只是判负环的话dis(最短路长度)可全初始化为0,且再从每个点dfs一遍(dis=0的影响、防止图不连通),这样可减少判环之外的工作量,增加效率。dfs不要忘回溯。
spfa一般写法下本质还是个bfs,记录路径的边数就行了,边数>=n(即出队次数>=n,源点就不该再次出队,不过无妨,一同处理也行)即为有负环。
// spfa 算法判断负环
#include <iostream>
#include <queue>
#include <vector>
#include <cstring>
using namespace std;
typedef pair<int, int> PII;
const int N = 2e3 + 10;
int n, m;
vector<PII> edges[N];
int dist[N];
bool check[N]; //标记哪些点在队列中
int cnt[N];
bool spfa()
{
//初始化
memset(dist, 0x3f, sizeof dist);
memset(check, 0, sizeof check);
memset(cnt, 0, sizeof cnt);
queue<int>q;
q.push(1);
check[1]=true;
dist[1]=0;//注意
cnt[1]=0;//注意
while(q.size())
{
int x=q.front();
q.pop();
check[x]=false;//x出队列了
for(auto&tmp:edges[x])
{
int y=tmp.first,w=tmp.second;
if(dist[y]>dist[x]+w)
{
dist[y]=dist[x]+w;
cnt[y]=cnt[x]+1;
if(cnt[y]>n-1)//超过了n-1次大松弛操作,就代表有负环
{
return true;
}
if(check[y]==false)
{
q.push(y);
check[y]=true;
}
}
}
}
return false;
}
int main()
{
int T; cin >> T;
while (T--)
{
cin >> n >> m;
//清空edges数组
for (int i = 1; i <= n; i++) edges[i].clear();
for (int i = 1; i <= m; i++)
{
int u, v, w; cin >> u >> v >> w;
edges[u].push_back({ v, w });
if (w >= 0) edges[v].push_back({ u, w });
}
if (spfa()) cout << "YES" << endl;
else cout << "NO" << endl;
}
return 0;
}
题目四——P1629 邮递员送信 - 洛谷

我们
从起点找别的点的最短距离很简单,直接跑各种最短路算法均可。 但是从别的点回到起点的最短路,如果直接求时间复杂度巨⾼。
思考⼀件事:
- 假设从某⼀点z,到达起点的最短路径为:z->y->x->s;
- 那么反过来就是s->x->y->z的最短路径。
因此,仅需对原图的所有图建⽴⼀个"反图",然后跑⼀遍最短路即可。这就是建"反图"的技巧。
我们仔细看一下怎么建立反图
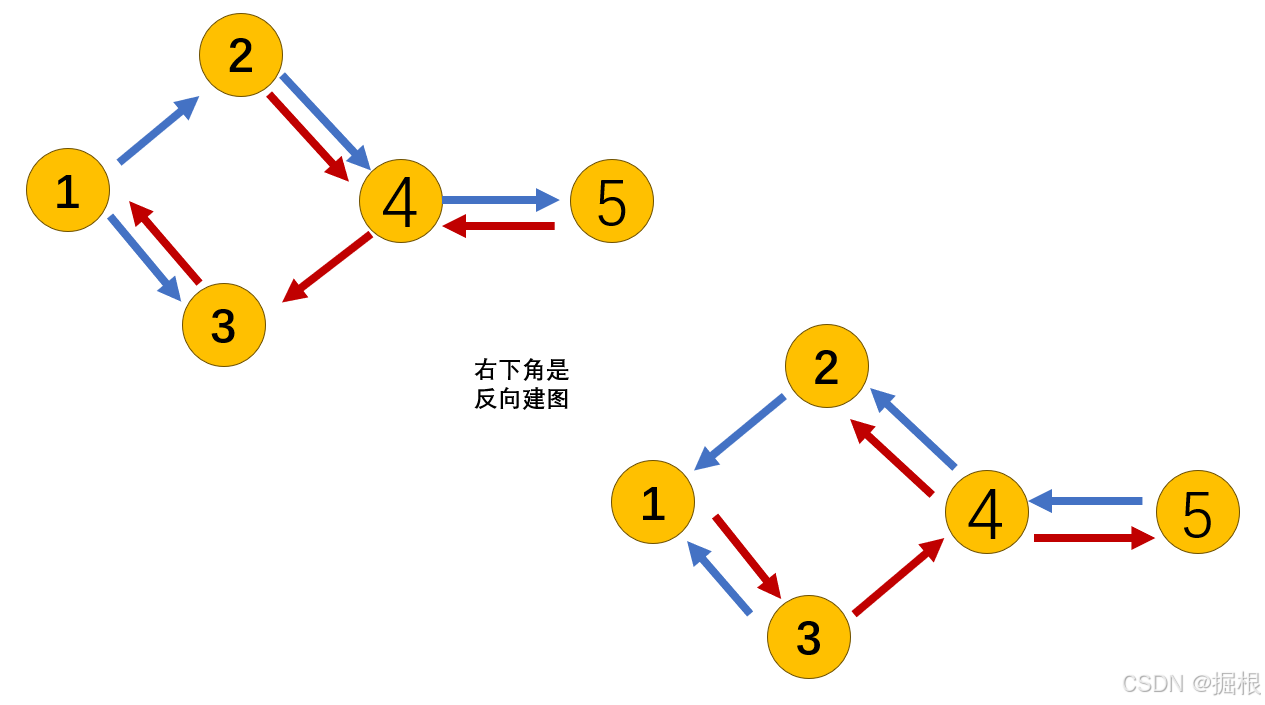 我们发现
我们发现
- 第一次我们只需使用dijkstra算法计算各点到起点1的最短时间即可,这个时间就是骑手从起点1前往目的地的最短时间
- 我们建立反图之后,我们发现我们还是可以使用dijkstra计算各点到起点1的最短时间即可,这个时间也正好是骑手从目的地返回起点1的最短时间
#include<bits/stdc++.h>
using namespace std;
const int N=1e3+10;
int edges[N][N];//注意我们这里使用邻接表,方便后面建立反图
int dist[N];
bool check[N];
int n,m;
void dijkstra()
{
memset(dist,0x3f,sizeof(dist));
memset(check,0,sizeof(check));
dist[1]=0;
for(int i=1;i<=n;i++)
{
int minnode=0;
for(int j=1;j<=n;j++)
{
if(check[j]==false&&dist[j]<dist[minnode])
{
minnode=j;
}
}
check[minnode]=true;
for(int j=1;j<=n;j++)
{
dist[j]=min(dist[j],dist[minnode]+edges[minnode][j]);
}
}
}
int main()
{
int ret=0;
cin>>n>>m;
memset(edges,0x3f,sizeof(edges));
for(int i=1;i<=m;i++)
{
int x,y,z;
cin>>x>>y>>z;
edges[x][y]=min(edges[x][y],z);
}
dijkstra();
for(int i=1;i<=n;i++)
{
ret+=dist[i];
}
//建立反图
for(int i=1;i<=n;i++)
{
for(int j=i+1;j<=n;j++)
{
swap(edges[i][j],edges[j][i]);
}
}
dijkstra();
for(int i=1;i<=n;i++)
{
ret+=dist[i];
}
cout<<ret<<endl;
}
题目五—— P1744 采购特价商品 - 洛谷

看数据范围,所有的最短路算法均可解决,这⾥使⽤BF算法。
⽆需建图,只⽤把所有的边存下来。
注意是⽆向边,所以要存两次,空间也要开两倍。
在所有边上做⼀次bf算法,输出结果即可。
#include <iostream>
#include <cmath>
#include <cstring>
using namespace std;
const int N = 110, M = 1010;
int n, m, s, t;
double x[N], y[N];
struct node
{
int a, b;
double c;
}e[M];
double calc(int i, int j)
{
double dx = x[i] - x[j];
double dy = y[i] - y[j];
return sqrt(dx * dx + dy * dy);
}
double dist[N];
void bf()
{
for (int i = 1; i <= n; i++) dist[i] = 1e10;
dist[s] = 0;
for (int i = 1; i < n; i++)
{
for (int j = 1; j <= m; j++)
{
int a = e[j].a, b = e[j].b;
double c = e[j].c;
if (dist[a] + c < dist[b])
{
dist[b] = dist[a] + c;
}
if (dist[b] + c < dist[a])
{
dist[a] = dist[b] + c;
}
}
}
}
int main()
{
cin >> n;
for (int i = 1; i <= n; i++) cin >> x[i] >> y[i];
cin >> m;
for (int i = 1; i <= m; i++)
{
int a, b; cin >> a >> b;
e[i].a = a; e[i].b = b; e[i].c = calc(a, b);
}
cin >> s >> t;
bf();
printf("%.2lf\n", dist[t]);
return 0;
}
题目六——P2136 拉近距离 - 洛谷
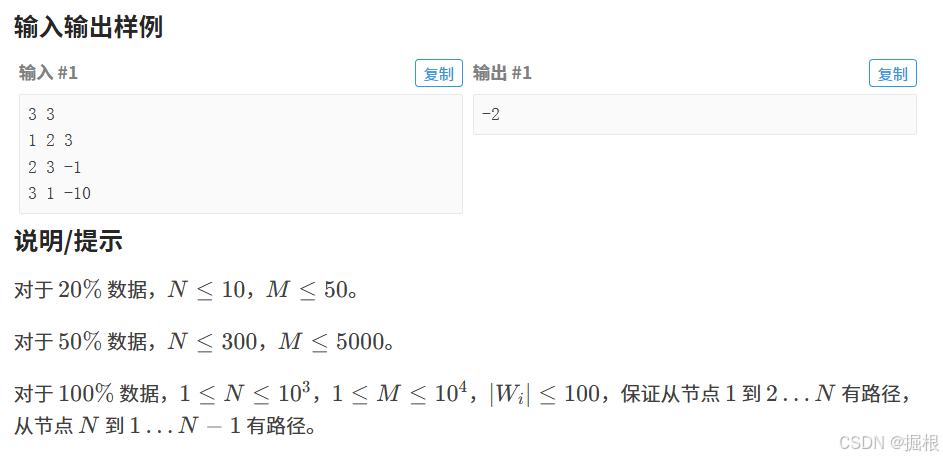 bf 算法判断负环即可。但要注意⼀下细节:
bf 算法判断负环即可。但要注意⼀下细节:
1. 题⽬中给的是距离w是能缩⼩的数,因此存边的时候,应该存成相反数;
2. 爱情是双向奔赴的,我们要在1->n和n->1两种情况⾥⾯选择最⼩值。
#include<bits/stdc++.h>
using namespace std;
const int N=1e3+10;
vector<pair<int,int>>edges[N];
int dist[N];
int n,m;
bool bf(int s)
{
memset(dist,0x3f,sizeof(dist));
dist[s]=0;
bool flag;
for(int i=1;i<=n;i++)//循环n次如果flag=true,就代表有负权图
{
flag=false;
for(int j=1;j<=n;j++)
{
for(auto&tmp:edges[j])
{
int y=tmp.first,w=tmp.second;
if(dist[y]>dist[j]+w)
{
dist[y]=dist[j]+w;
flag=true;
}
}
}
if(flag==false)
{
return flag;
}
}
return flag;
}
int main()
{
cin>>n>>m;
for(int i=1;i<=m;i++)
{
int x,y,z;
cin>>x>>y>>z;
z=-z;
edges[x].push_back({y,z});
}
if(bf(1)==true)
{
cout<<"Forever love"<<endl;
return 0;
}
int ret1=dist[n];
if(bf(n)==true)
{
cout<<"Forever love"<<endl;
return 0;
}
int ret2=dist[1];
cout<<min(ret1,ret2)<<endl;
}
题目七——P1144 最短路计数 - 洛谷

解法一:BFS + 动态规划
-
最短路求解:
-
因为边权全都相等,所以可以使用 BFS 找出最短路。
-
在 BFS 找最短路的过程中,更新最短路的条数。
-
-
动态规划:
-
状态表示:设 f[i] 表示从起点走到点 i 的最短路的条数。
-
状态转移方程:f[i]+=f[prev]。其中,prev 表示点 i 的所有前驱,但需要注意的是,这些前驱必须是通过最短路到达 i 的。
-
填表顺序:按照 BFS 的顺序进行填表。
-
解法二:Dijkstra 算法 + 动态规划
-
这种解法更为通用,因为即使边权不相等,也可以使用 Dijkstra 算法来求解最短路。
#include <iostream>
#include <queue>
#include <cstring>
#include <vector>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e6 + 10, M = 2e6 + 10, MOD = 100003;
int n, m;
vector<int> edges[N];
int dist[N];
bool st[N];
int f[N];
void dijkstra()
{
memset(dist, 0x3f, sizeof dist);
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({ 0, 1 });
dist[1] = 0;
f[1] = 1;
while (heap.size())
{
auto t = heap.top(); heap.pop();
int a = t.second;
if (st[a]) continue;
st[a] = true;
for (auto b : edges[a])
{
if (dist[a] + 1 < dist[b])
{
dist[b] = dist[a] + 1;
f[b] = f[a];
heap.push({dist[b], b});
}
else if (dist[a] + 1 == dist[b])
{
f[b] = (f[a] + f[b]) % MOD;
}
}
}
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++)
{
int a, b;
scanf("%d%d", &a, &b);
edges[a].push_back(b);
edges[b].push_back(a);
}
dijkstra();
for (int i = 1; i <= n; i++)
{
printf("%d\n", f[i]);
}
return 0;
}

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)