【课程笔记】华为 HCIE-AI Solution Architect 人工智能11:MindFormers实战进阶
(1) 大模型使能套件:全流程覆盖大模型开发、训练、微调、推理(2) MindFormers大模型套件介绍(3) MindFormers概述MindFormers套件的目标是构建一个集大模型开发、训练、微调、评估、推理、部署全流程的开发套件,提供业内主流的Transformer类预训练模型和SOTA下游任务应用,涵盖丰富的并行特性(1) MindFormers支持任务及模型列表(1) MindFo
MindFormers实战进阶
目录
一、MindFormers介绍
(1) 大模型使能套件:全流程覆盖大模型开发、训练、微调、推理
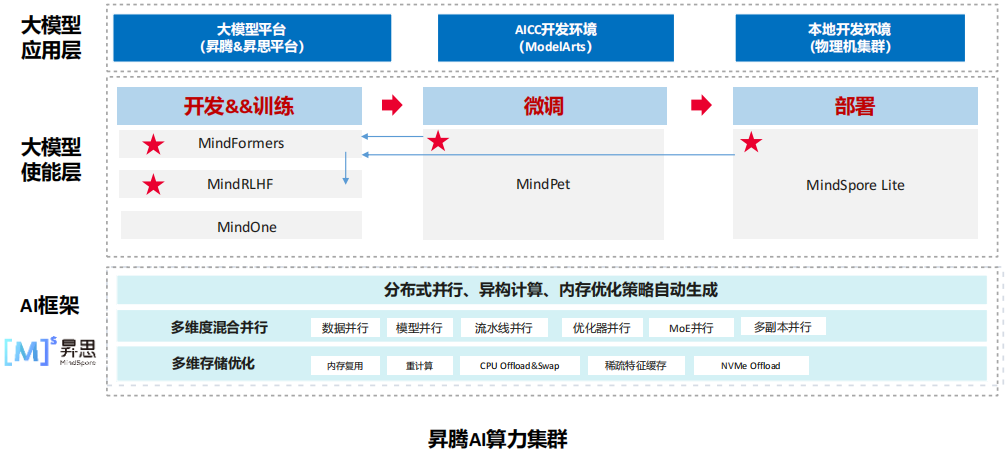
(2) MindFormers大模型套件介绍
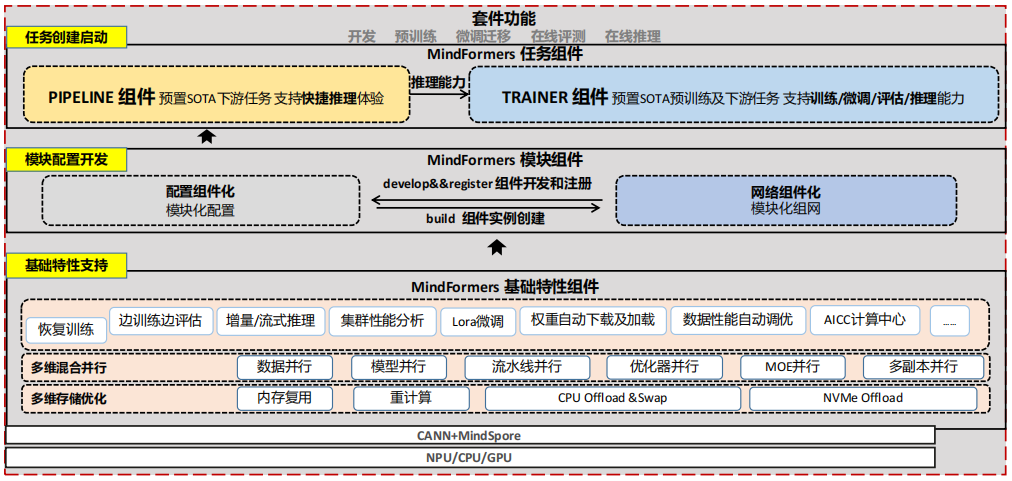
(3) MindFormers概述
MindFormers套件的目标是构建一个集大模型开发、训练、微调、评估、推理、部署全流程的开发套件,提供业内主流的Transformer类预训练模型和SOTA下游任务应用,涵盖丰富的并行特性

二、设计与特性介绍
1. 任务及模型支持
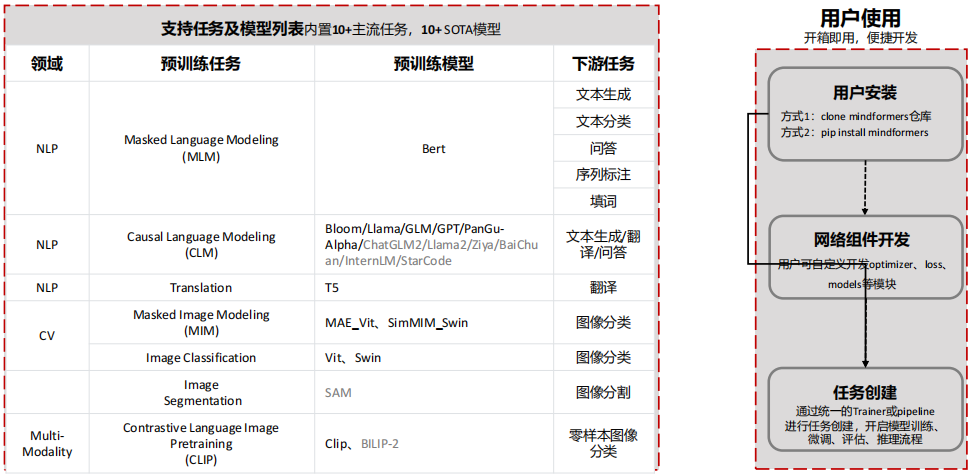
(1) MindFormers支持任务及模型列表
2. 设计介绍
(1) MindFormers设计整体介绍

3. 特性介绍
(1) MindFormers特性整体介绍
MindFormers提供了多种特性,方便用户加载数据集、可视化训练过程、迁移模型、提高模型训练速度等
| LLM数据集在线加载 | MindFormers大模型套件支持直接读取非mindrecord格式的数据,如json、parquet等,主要依赖TrainingDataLoader和SFTDataLoader实现,其中是TrainingDataLoader主要用于预训练数据集的读取,SFTDataLoader主要用于微调数据集的读取 |
|---|---|
| 断点续训 | MindFormers支持step级断点续训,在训练过程中如果遇到意外情况导致训练中断,可以使用断点续训的方式恢复之前的状态继续训练 |
| 边训练边评估 | 大模型的训练效果需要评测任务来作为衡量标准,而当前大模型的训练耗时长,等到训练整体结束后再进行评测任务的时间与算力成本过高 |
| 训练优化算法 | MindFormers套件集成了许多模型训练中通用的优化算法,并提供了便捷的使用方式,包括梯度累积、梯度裁剪、优化器异构等 |
| 离线权重转换 | 在分布式训练/推理中,当预训练权重与分布式策略不匹配时,需要将预训练权重转换为对应分布式策略的权重 |
| 自动权重转换(推荐) | MindFormers支持自动权重转换,相比权重离线切分转换提升了任务启动效率 |
| Text Generator | 能够便捷地使用生成类语言模型进行文本生成任务,包括但不限于解答问题、填充不完整文本或翻译源语言到目标语言等 |
| 低参微调 | 低参微调针对MindFormers仓库已有的大模型进行统一架构设计,对于LLM类语言模型,可以统一调度修改,做到只需要调用接口或者是自定义相关配置文件,即可完成对LLM类模型的低参微调算法的适配 |
| Chat Web | Chat Web提供了一套对话推理服务(chat server)和网页应用(web demo),让用户可以通过类似线上聊天的方式使用MindFormers大语言模型(LLM)推理能力 |
| Inference | Inference模块采用的后端是MindSpore Lite,按照任务类别设计推理流水线,支持任务类别的可扩展,针对同一类任务兼容不同模型进行推理,实现模型可扩展的设计 |
| Lazy Inline | 为了减轻inline对编译性能带来的损耗,对于重复调用相同计算单元的场景(典型的场景是在for循环中调用同一个Cell类的不同实例),支持通过环境变量的方式调用MindSpore的lazy_inline方法来减少编译时间 |
三、模型调试调优
(1) MindFormers精度调优
为了对训练过程进行分析,用户需要感知训练过程中算子的输入和输出数据。异步/同步dump的操作步骤基本一样,区别在于json文件不同
异步dump(训练结束后dump数据):
①创建json配置文件
②设置Dump环境变量
③启动网络训练脚本
④解析Dump数据文件
同步dump(训练的同时进行数据dump):
①除了json配置文件不同,其他与上面一致
(2) MindFormers性能调优
Profiler数据采集
支持AICORE算子、AICPU算子、HostCPU算子、内存、设备通信、集群等数据的分析
Summary数据采集
可设置数据收集的频率、种类、行为、日志大小等
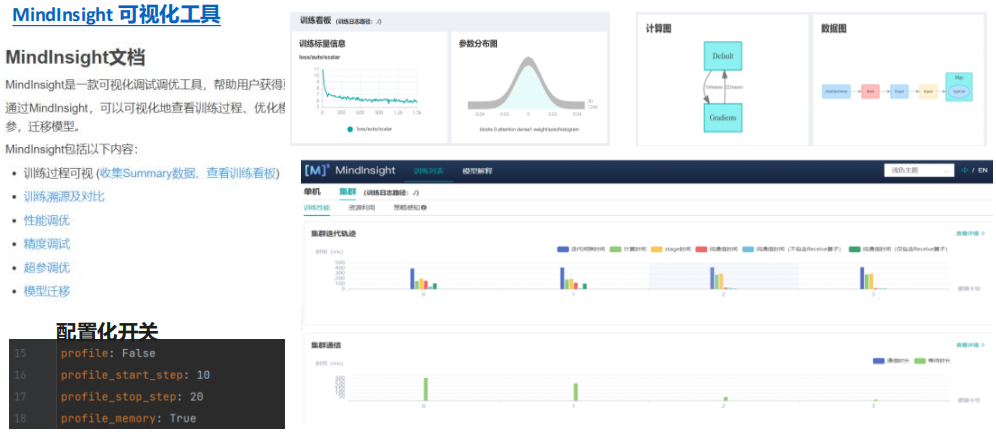
MindInsight可视化调优
MindInsight能可视化Summary收集到的数据,帮助进行性能分析和调优
保存IR图
IR是程序编译过程中介于源语言和目标语言之间的程序表示,以方便编译器进行程序分析和优化,MindSpore提供了保存中间编译图的功能,主要有三种格式:
①IR后缀结尾的IR文件:一种比较直观易懂的以文本格式描述模型结构的文件,可以直接用文本编辑软件查看
②通过设置环境变量export MS_DEV_SAVE_GRAPHS_SORT_MODE=1可以生成的ir后缀结尾的IR文件:格式跟默认的ir文件基本相同,但是生成的异序ir文件的图的生成与打印顺序和默认ir文件不同
③dot后缀结尾的IR文件:描述了不同节点间的拓扑关系,可以用graphviz将此文件作为输入生成图片,方便用户直观地查看模型结构。对于算子比较多的模型,推荐使用可视化组件MindInsight对计算图进行可视化
四、套件组合
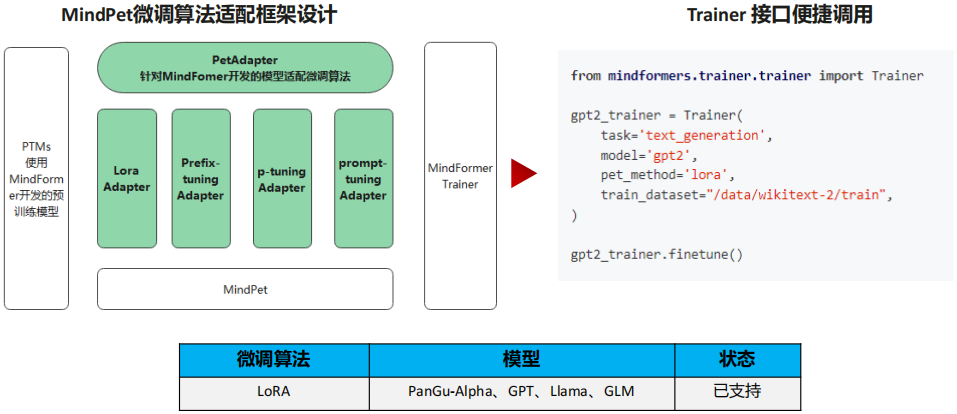
(1) MindFormers大模型套件使能MindPet
(2) MindInsight大规模集群性能分析及可视化,助力大模型调试调优
五、大模型并行特性
(1) 昇思MindSpore原生支持AI大模型训练,使能大模型应用落地

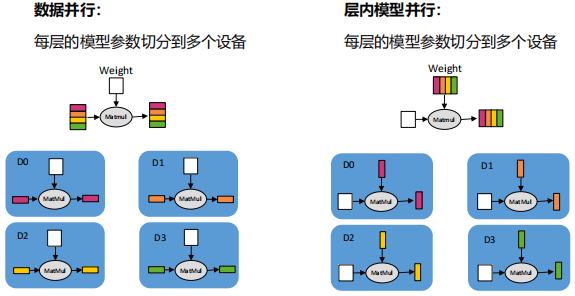
(2) 多维混合并行:模型并行、模型并行
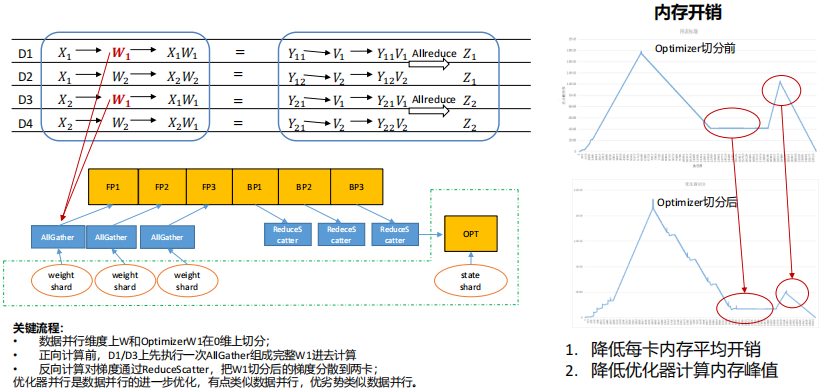
(3) 多维混合并行:优化器并行
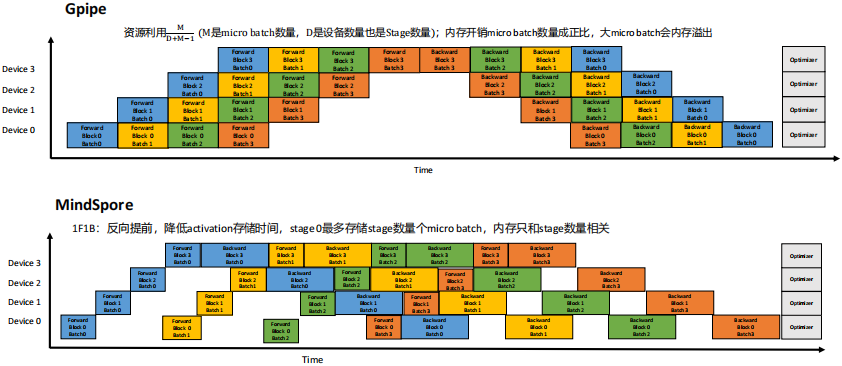
(4) 多维混合并行:PipeLine并行
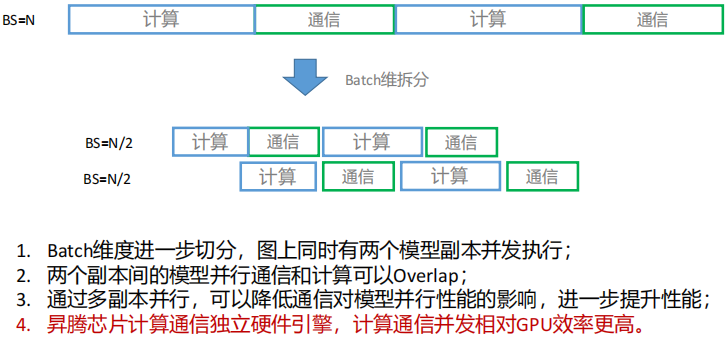
(5) 多维混合并行:多副本并行
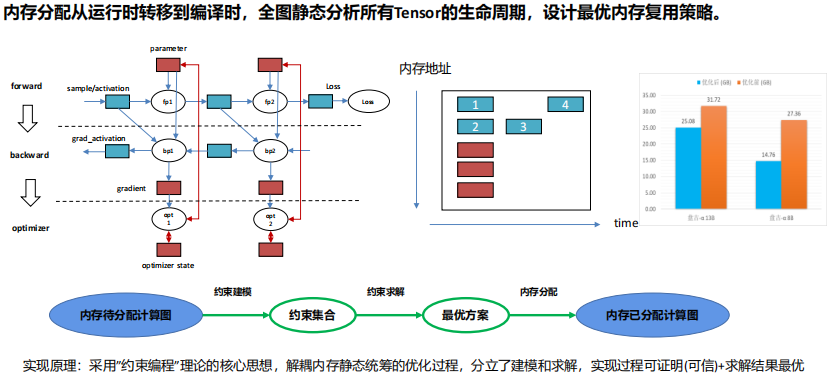
(6) 多级存储优化:整图内存复用
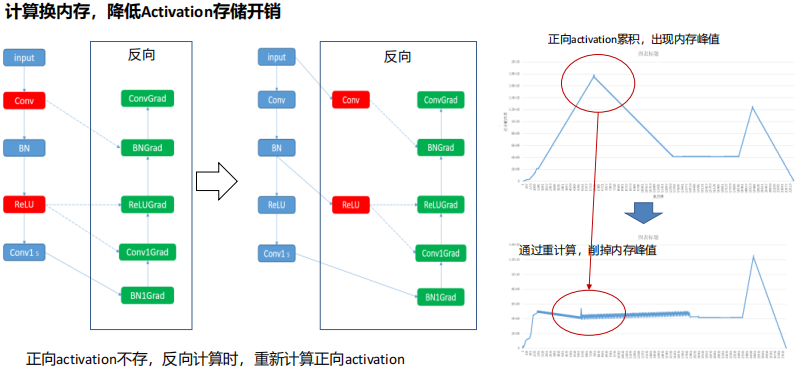
(7) 多级存储优化:重计算

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)