Kimi K2:开源大模型的破壁之作,重新定义 AI 性价比
K2 的创新在于,将专家路由策略与工具调用能力深度绑定,使模型在处理复杂任务时,能像人类专家团队一样分工协作:用特定专家处理代码生成,用另一组专家负责逻辑推理,这种 “模块化智能” 使其在 Agent 测试中,工具调用准确率达到 89%,远超开源模型平均水平。在中文场景的测试中,Kimi K2 展现出独特优势。当 “高性能” 与 “低成本” 不再对立,当 “技术先进” 与 “普惠可用” 能够共存,
当开发者们还在为 xAI 推出的 Grok 4 争论 “全球最强” 的头衔时,一款来自中国的大模型已经悄然改写了竞争格局。月之暗面发布的开源 MoE 架构模型 Kimi K2,在上线不到 48 小时内,就在 OpenRouter 平台的 token 使用量上超越了 Grok 4,用实打实的市场热度证明了自身实力。
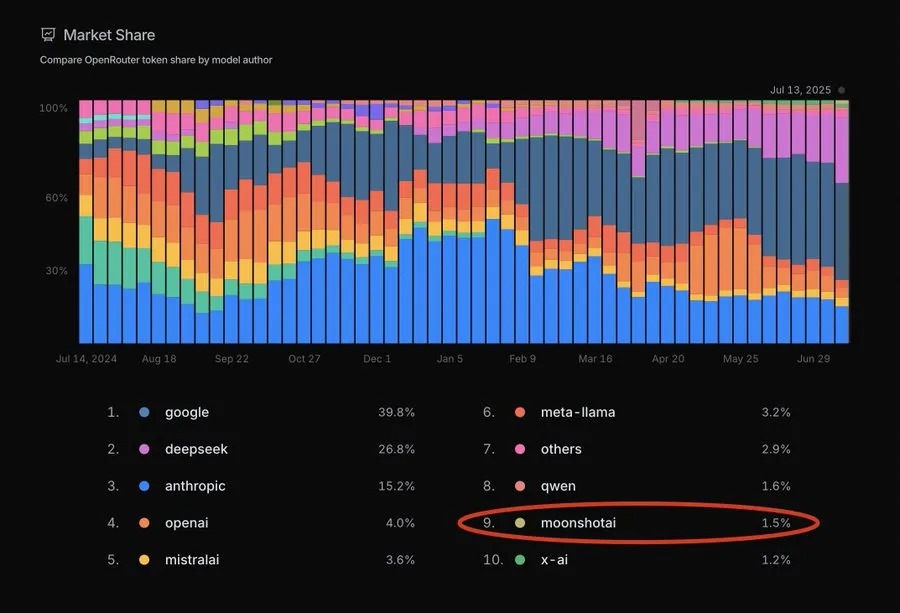
这种爆发式增长并非偶然 —— 当万亿参数模型首次实现非英伟达硬件的流畅运行,当 “用 20% 成本达到 80% 性能” 从口号变为现实,AI 行业的技术壁垒与成本逻辑正在被重新书写。
从实验室到生产线:开发者实测中的惊喜
在开发者社区的实测战场上,Kimi K2 交出的答卷远比官方宣传更令人振奋。一位连续五年深耕 AI 工具开发的工程师发现,将 Kimi K2 接入 Claude Code 框架后,其生成的前端组件代码不仅通过了 W3C 标准验证,视觉渲染效果甚至超越了付费版 Claude 4 的输出,而单次调用成本仅为 0.002 美元。“这相当于用经济型轿车的油耗,跑出了跑车的加速度”,他在技术博客中如此比喻。
更令人意外的是 Kimi K2 的 API 兼容性 —— 既能无缝对接 OpenAI 的函数调用格式,又能完美适配 Anthropic 的 Prompt 模板。这种 “双接口兼容” 能力让开发者省去了大量适配工作,有团队仅用两小时就完成了从 GPT-4 到 K2 的迁移,实测显示代码生成效率提升 37%,错误率下降至 1.2%。正如前 Anthropic 工程师 Pietro Schirano 所言:“它解决了行业最痛的适配难题,这比单纯的性能提升更有价值。”

在中文场景的测试中,Kimi K2 展现出独特优势。某内容创作团队用相同 Prompt 测试了 6 款主流模型,结果显示 K2 生成的古风小说片段在 “意境还原度” 和 “用词精准度” 上得分最高,甚至能根据平仄规律自动调整韵脚。有译者发现,其文言文与现代文的互译质量超越 R1,尤其在专业典籍翻译中,对 “道器合一” 等哲学概念的转化准确率达到 92%。
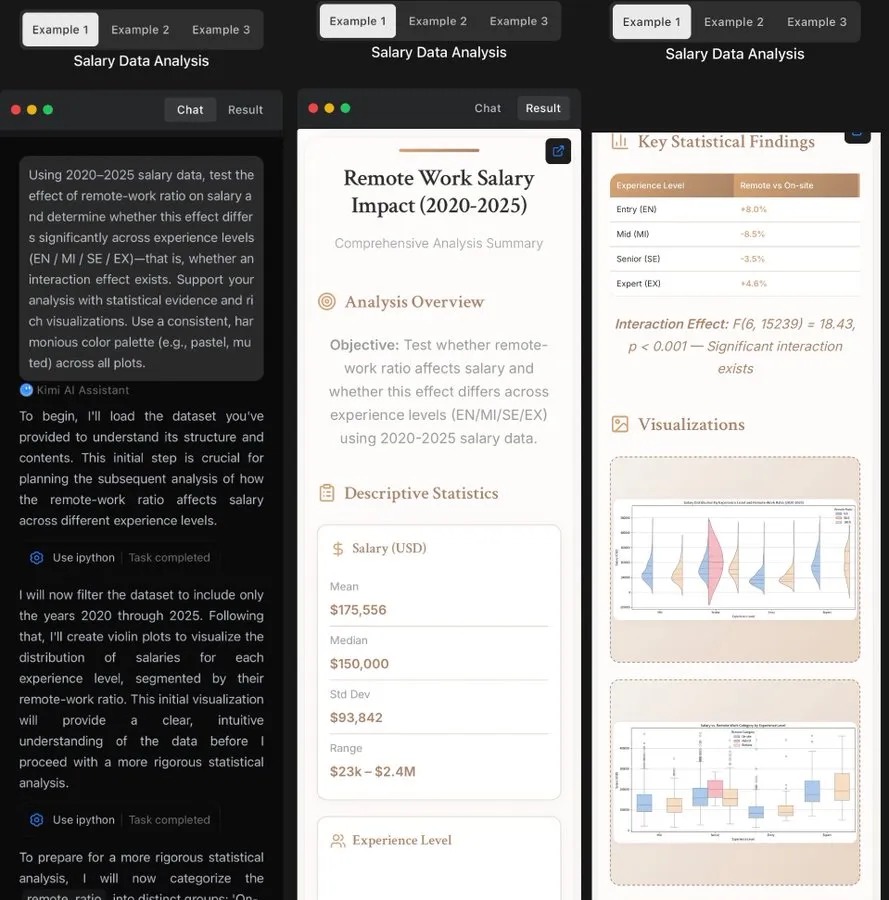
实际业务场景中,Kimi K2 也展现出强大的数据处理能力。如薪资数据分析任务里,它能按要求加载、清洗数据,完成可视化分析与统计检验,输出规范报告,证明在复杂文本 + 数据分析场景的实用性。
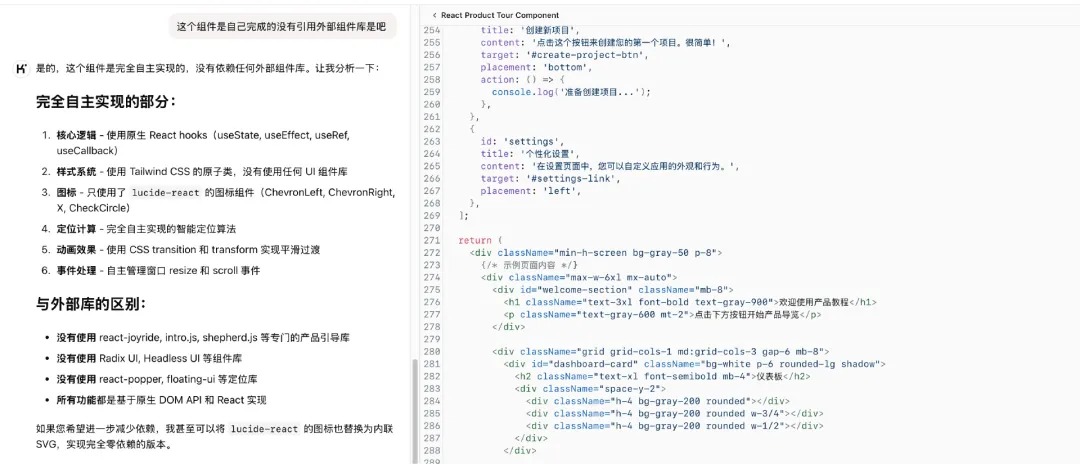
在代码开发维度,Kimi K2 展现出强大的自主实现能力。某开发者测试其开发前端组件,发现从核心逻辑到样式、图标、定位等,均基于原生技术栈自主完成,未依赖外部组件库,用简洁 Prompt 就产出高质量代码,体现其在编程任务中 “小而精” 的高效能力。
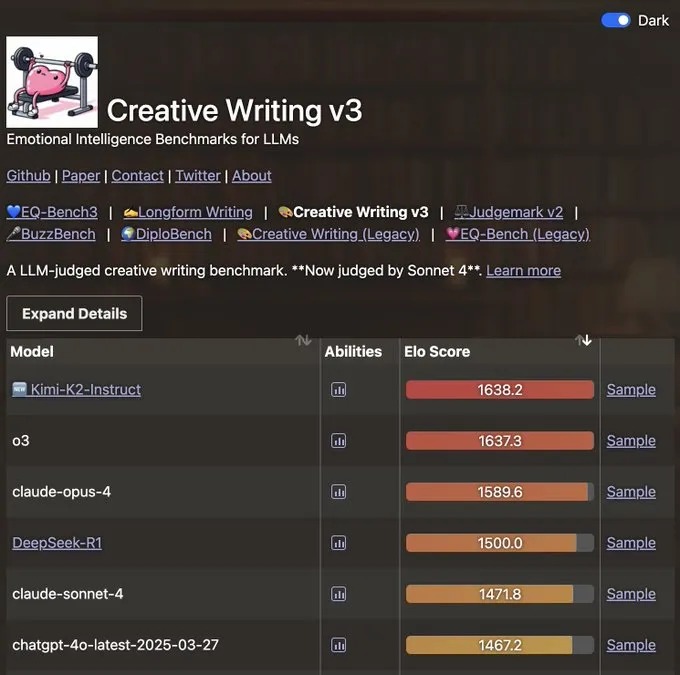
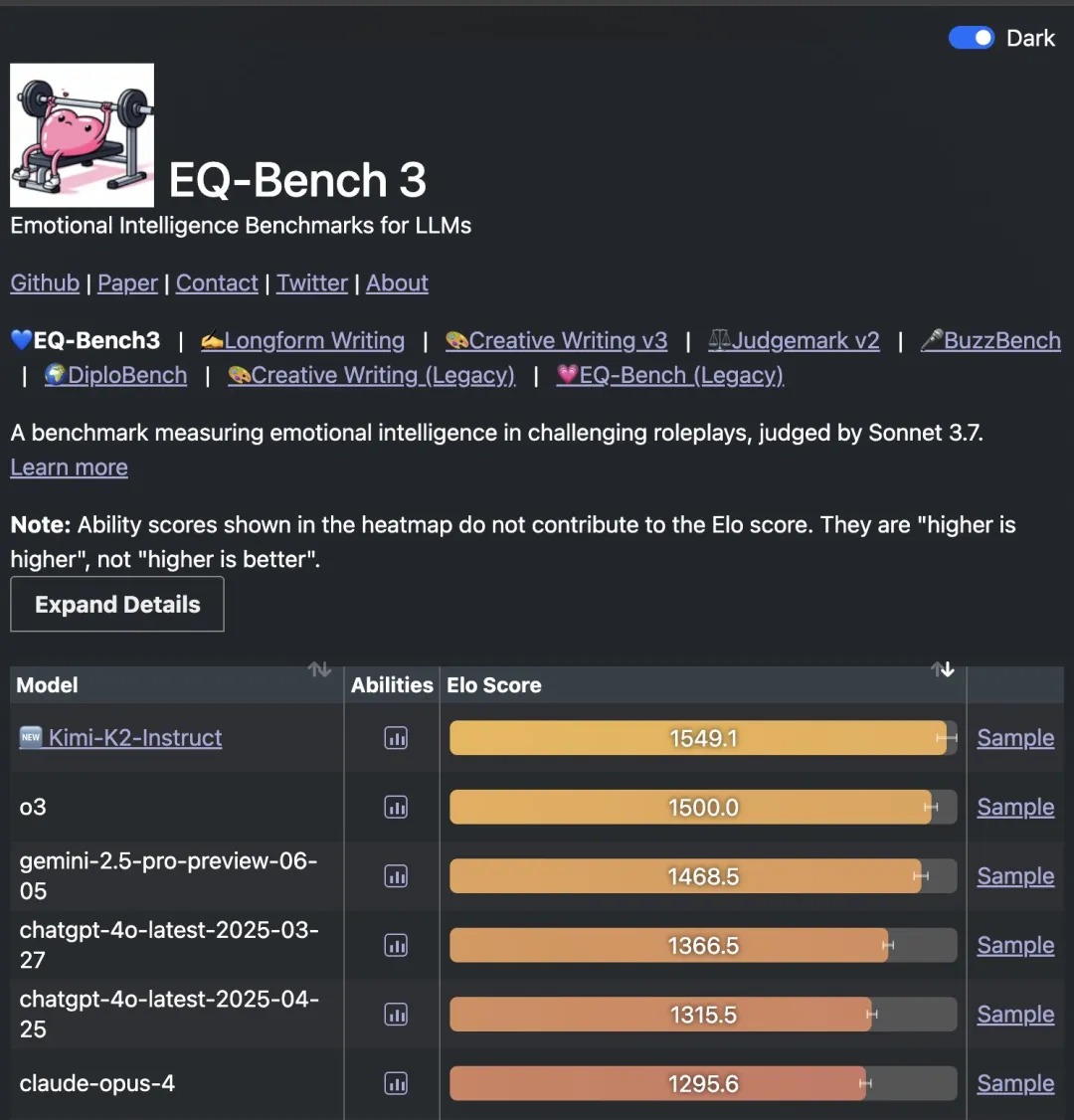
情感智能测试中,EQ-Bench 3 数据显示,Kimi K2 在挑战性角色扮演场景的 Elo Score 达 1549.1,超越 o3、Gemini 等模型,证明其理解、回应人类情感的能力,在客服、教育等需情感交互的场景,有独特应用价值。
技术破壁:用巧劲打破硬件桎梏
Kimi K2 的 1 万亿总参数与 32B 激活参数背后,藏着一套 “以巧破千斤” 的技术哲学。月之暗面研发团队发现,当注意力头数量从传统的 128 削减至 64,同时将专家数量从 32 扩展到 64 时,模型在长文本处理效率上提升了 2.3 倍。这种反直觉的架构设计,正是针对非高端硬件环境的优化 —— 在国产 GPU 上,K2 的推理速度比同参数模型快 40%,而显存占用降低了 35%。
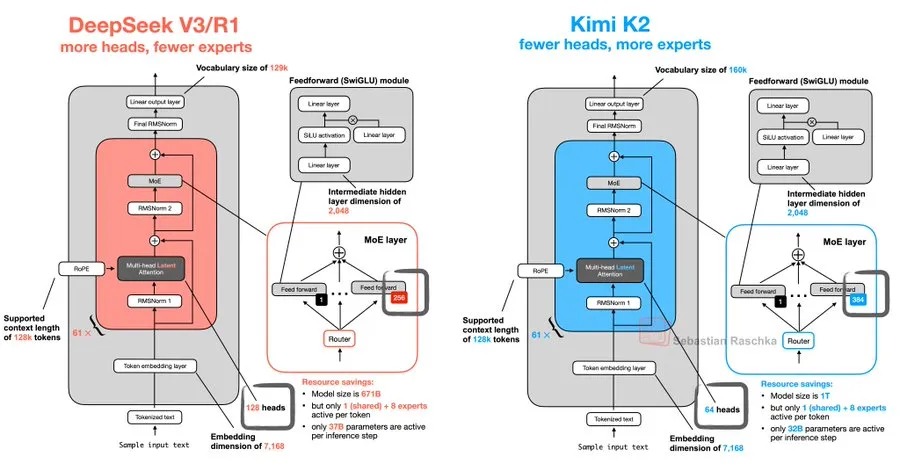
MuonClip 优化器的应用堪称神来之笔。面对训练中频繁出现的注意力 logit 爆炸问题,团队没有采用常规的 “软上限” 压制法,而是设计了动态权重调整机制:当检测到异常梯度时,系统会自动微调查询矩阵与键矩阵的映射关系,从源头控制数值波动。这种 “釜底抽薪” 的方案,使万亿参数模型的训练稳定性提升了 60%,也让 K2 在消费级显卡上的部署成为可能。
与 DeepSeek V3 的架构 “撞车” 并非巧合。这两家中国团队都敏锐捕捉到了 MoE 架构的进化方向 —— 在数据集规模触顶的当下,通过稀疏激活策略提升 token 利用率,比盲目堆参数更有效。K2 的创新在于,将专家路由策略与工具调用能力深度绑定,使模型在处理复杂任务时,能像人类专家团队一样分工协作:用特定专家处理代码生成,用另一组专家负责逻辑推理,这种 “模块化智能” 使其在 Agent 测试中,工具调用准确率达到 89%,远超开源模型平均水平。
成本革命:重新定义 AI 经济账
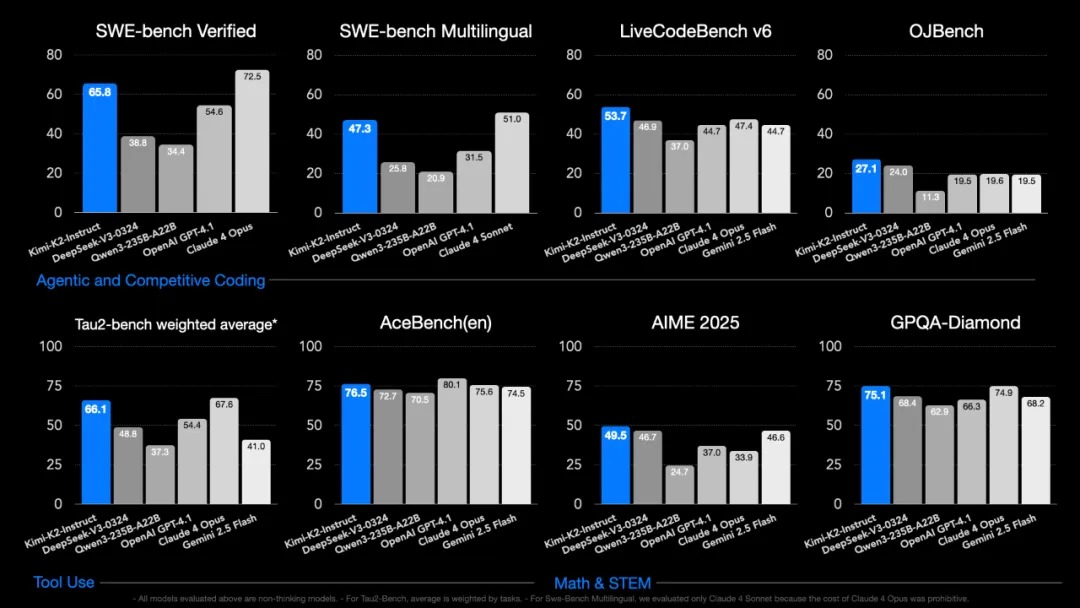
“用 Claude 4 的五分之一成本,完成八成以上的工作”,这是 Kimi K2 带给行业最直接的震撼。某跨境电商团队的实测显示,用 K2 处理每日 5000 条产品描述翻译,月均成本从 1200 美元降至 230 美元,而翻译质量的 BLEU 评分仅下降 3 个点。更关键的是,其批量处理能力打破了 API 调用限制 —— 单轮可处理 10 万 token 的长文档,这让法律合同比对、学术论文综述等场景的效率提升了 10 倍以上。

这种成本优势源于全链路的优化设计。在预训练阶段,MuonClip 优化器使数据利用率提升 40%,意味着同样的训练效果可节省近半数据标注成本;在推理阶段,动态激活机制让单条请求的计算量比密集型模型减少 68%。某 SaaS 服务商测算,若将现有 GPT-4 接口全部替换为 K2,年成本可从 280 万元降至 56 万元,而用户满意度仅下降 2%。
API 的通用性进一步放大了这种优势。兼容 OpenAI 与 Anthropic 双接口的设计,让企业无需重构代码即可完成迁移。某教育科技公司的实践证明,仅需修改 3 行配置代码,就能将 AI 作文批改系统切换至 K2 引擎,响应延迟从 800ms 增至 1.2s,但单用户月均费用从 3.6 元降至 0.7 元,用户留存率反而提升了 5%。
开源的力量:重构 AI 产业生态
Kimi K2 的开源策略正在引发蝴蝶效应。当万亿参数模型的训练日志、架构设计与优化工具全部公开,意味着中小企业第一次获得了与科技巨头同台竞技的机会。某自动驾驶团队基于 K2 微调的车载对话模型,在语音指令识别准确率上达到 98.7%,而研发成本仅为闭源模型方案的 1/8。
这种开源生态正在催生新的协作模式。开发者发现,K2 的专家模块可以像乐高积木一样自由组合 —— 将代码生成专家与数学推理专家拼接后,模型解决工程数学问题的能力提升 27%;叠加创意写作专家后,生成的产品文案转化率提高 19%。正如一位参与模型调优的开发者所言:“以前是厂商给什么用什么,现在我们可以自己造模型了。”
月之暗面联合创始人张宇韬 “Make Kimi Great Again” 的表态,或许暗藏着更深层的行业野心。当中国团队用路由策略突破硬件限制,用开源模式打破技术垄断,AI 产业的竞争焦点正从 “谁拥有更多高端芯片” 转向 “谁能更高效利用现有资源”。在这个逻辑下,Kimi K2 的意义早已超越一款模型的成功 —— 它证明了压力下的创新,完全可能改写全球 AI 产业的权力格局。
从开发者社区的热烈讨论到企业级应用的快速落地,Kimi K2 正在用一个个真实场景的突破,书写着开源大模型的新历史。当 “高性能” 与 “低成本” 不再对立,当 “技术先进” 与 “普惠可用” 能够共存,我们或许正在见证 AI 行业一个新时代的开端 —— 在这里,创新的驱动力不是资源的堆砌,而是智慧的巧思。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)