第2章:核心三剑客 - Embedding、向量和向量数据库
Embedding:神奇的“翻译官”,把世间万物翻译成AI能懂的数学语言,并保留其深层含义。向量 (Vector):万物在语义空间的“GPS坐标”,一个由数字组成的、可计算的“数学身份证”。向量数据库:存储和高效检索海量“GPS坐标”的“超级索引”,AI的长期记忆海马体。
嘿,兄弟们,欢迎回到阿威的专栏。
在上一章,我们把大语言模型(LLM)这个“超级实习生”给认识了。我们知道了他很牛,但也知道了他有个致命的毛病——记性差。他的记忆力受限于一个叫“上下文窗口”的东西,就像金鱼的七秒记忆一样,聊着聊着就把前面的事儿给忘了。
这就带来一个直击灵魂的问题:如果我想让AI成为我个人或公司的专家,能回答关于我私有知识(比如几百页的产品文档、内部技术Wiki、法律条款)的问题,我该怎么办?
总不能每次提问,都把几百页的文档复制粘贴到Prompt里吧?先不说你手会不会抽筋,光是那点可怜的上下文窗口(Context Window)和高昂的Token费用,就直接把你劝退了。
这就好比你想让一个厨子学会做你家的祖传秘方菜,你不能每次都让他把整本菜谱背一遍,而是应该把菜谱放在厨房的书架上,让他做菜的时候能随时翻阅查询。
那么,AI的“厨房书架”是什么?
今天,我就为你隆重介绍构建这个“书架”的核心三剑客:Embedding(嵌入)、Vector(向量) 和 Vector Database(向量数据库)。
这三个概念,听起来一个比一个唬人,但请相信我,它们是整个AI应用开发中最优雅、最天才的设计之一。搞懂了它们,你就掌握了为AI建立“长期记忆”的钥匙,也就推开了通往高级AI应用(比如我们后面要做的知识库问答机器人)的大门。
坐稳了,咱们的发车速度要开始加快了!
2.1 第一剑客:Embedding - 万物皆可“数学化”的翻译官
让我们先从最核心的Embedding开始。
Embedding的本质,就是一个“翻译官”。
但它翻译的不是中英日文,而是把我们世界中那些非结构化的、计算机看不懂的信息,翻译成计算机能理解、能计算的数学语言。
这些“非结构化信息”可以是:
- 一段文字:“AI应用开发真有趣”
- 一张图片:一只正在打篮球的猫
- 一段音频:周杰伦的《青花瓷》
而它翻译出的“数学语言”,就是我们马上要讲的向量(Vector)。
为什么需要这个“翻译官”?
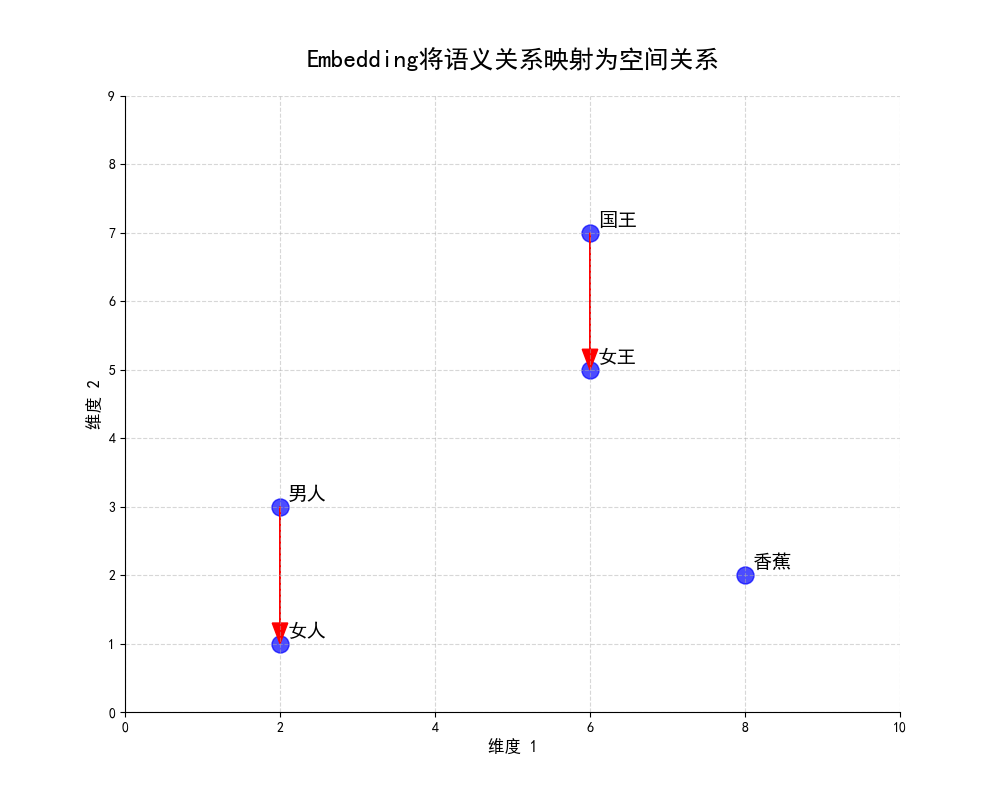
因为计算机是个“铁憨憨”。在它的世界里,没有“国王”和“皇帝”的尊贵,也没有“苹果”和“香蕉”的香甜。它只认识数字。你直接问它“‘国王’和‘皇帝’这两个词像不像?”,它会一脸懵逼。
但如果我们能把“国王”和“皇帝”这两个词,都翻译成一串数字(也就是向量),比如:
- 国王 ->
[0.8, 0.2, 0.9, ...] - 皇帝 ->
[0.81, 0.19, 0.92, ...] - 香蕉 ->
[0.1, 0.9, 0.3, ...]
然后你再问计算机:“嘿,你看这第一串数字和第二串数字,是不是比第一串和第三串更接近?”
计算机立马就来劲了!“那可不!我算一下它们之间的‘距离’… 哎哟,前两个确实近得多!”
通过这种方式,一个关于“语义相似度”的模糊问题,就转换成了一个可以精确计算的“数学距离”问题。
这就是Embedding的魔力所在。它最关键的特性,就是在翻译过程中,能够奇迹般地保留原始信息的“语义”。在它翻译出的那个高维数学空间里:
- 意思相近的东西,它们的向量在空间中的位置也彼此靠近。
- 意思无关的东西,它们的向量在空间中的位置就相距遥远。
这个“翻译”工作是怎么完成的呢?通常是由一个专门的、预训练好的神经网络模型(我们称之为Embedding Model)来完成的。我们作为应用开发者,不需要去训练这个模型,我们只需要像调用一个API一样去使用它就行了。
你给它一段文本,它就还给你一个向量。简单、直接。
2.2 第二剑客:向量 (Vector) - 定义万物语义的“GPS坐标”
如果说Embedding是那个神奇的“翻译系统”,那么向量(Vector),就是它翻译出来的具体结果——那个定义了万物在“语义空间”中精确位置的“GPS坐标”。
别被“向量”这个词吓到,尤其别被“高维空间”这个词吓到。
在中学数学里,我们学过二维坐标 (x, y) 和三维坐标 (x, y, z)。一个向量,无非就是把这个坐标扩展到了几百甚至上千个维度而已。
比如,OpenAI最常用的text-embedding-3-small模型,它生成的向量是1536维的。这意味着,它会把任何一段文本,都“翻译”成一个包含1536个浮点数的列表(或者叫数组)。
它看起来就像这样:[-0.00692, -0.0053, ..., 0.0157, 0.0221] (中间省略1532个数)
这个长长的数字列表,就是那段文本的“数学身份证”或“语义DNA”。 它独一无二,并且蕴含了丰富的语义信息。
那么,我们拿到这个“坐标”之后,能干嘛呢?
最重要的操作,就是计算两个向量之间的“距离”或“相似度”。这直接对应了两个原始信息在语义上的相关性。
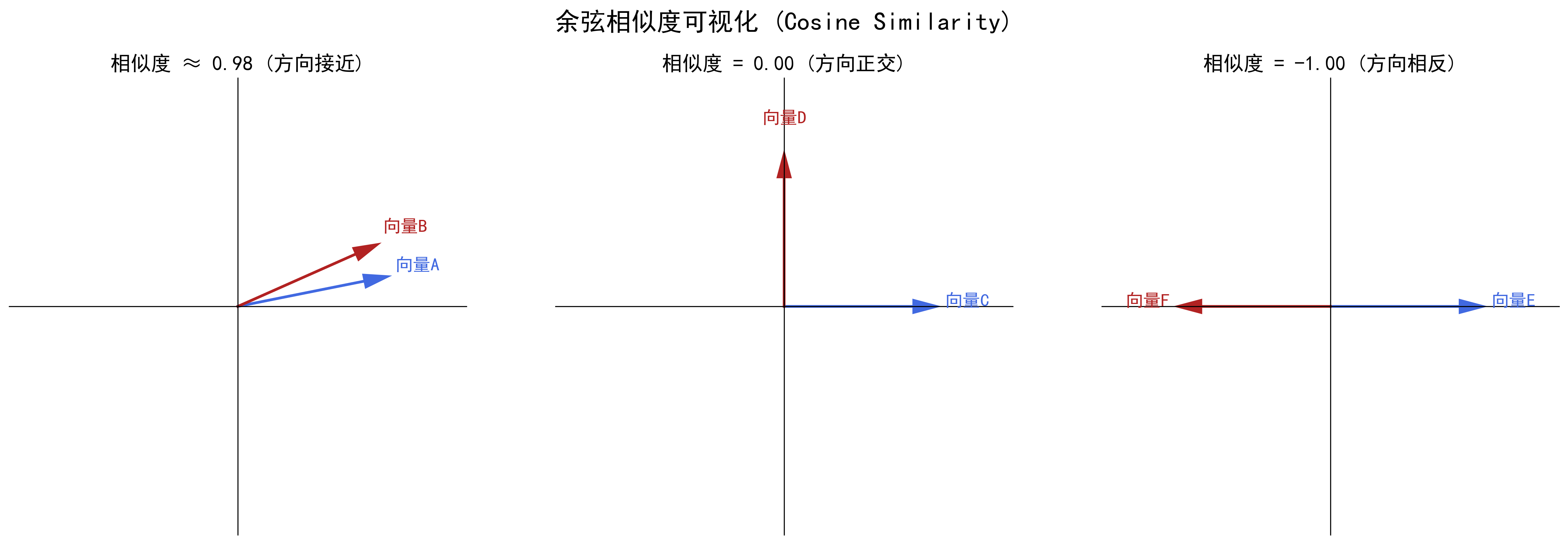
最常用的计算方法叫做“余弦相似度(Cosine Similarity)”。
同样,别被名字吓到。你不需要记住它的数学公式,只需要理解它的直观思想:
余弦相似度衡量的不是两个向量的绝对距离,而是它们在方向上的夹角。
- 如果两个向量指向的方向几乎完全相同,那它们的夹角接近0度,余弦相似度就接近1。这意味着它们代表的语义高度相关。
- 如果两个向量指向的方向完全正交(90度),那它们的余力弦相似度就是0。这意味着它们语义上完全无关。
- 如果两个向量指向的方向完全相反,那它们的夹角是180度,余弦相似度就是-1。这意味着它们语义上相互对立。
有了这个强大的工具,我们就可以做很多以前做不到的事情了。比如,实现一个“按意思搜索”的搜索引擎。用户搜索“夏天适合吃的水果”,我们就可以把这个问句转换成向量,然后去我们的数据库里,找到那些与这个向量“夹角”最小(也就是余弦相似度最高)的水果向量,比如“西瓜”、“荔枝”、“桃子”,而不是那些只包含“夏天”或“水果”这些关键词,但意思不相关的结果。
2.3 第三剑客:向量数据库 - AI的“超级记忆海马体”
现在,我们有了“翻译官”(Embedding Model)和“GPS坐标”(Vector),下一个问题自然而然就来了:
如果我有数百万甚至上亿个这样的“GPS坐标”,我该把它们存到哪里?又该如何高效地从中找出与目标最“近”的那些坐标呢?
总不能每次都从一个巨大的文件里,把上亿个向量都读到内存里,然后一个一个地去计算余弦相似度吧?那服务器早就爆了!
这时候,我们的第三位剑客——向量数据库(Vector Database),就该闪亮登场了。
如果你是一个Web开发者,那你对MySQL、PostgreSQL、Redis这些传统数据库肯定不陌生。向量数据库,就是专门为存储和查询海量向量而生的新型数据库。
让我们来做一个直观的对比:
| 特性 | 传统数据库 (如 MySQL) | 向量数据库 (如 Chroma, Pinecone, Milvus) |
|---|---|---|
| 核心数据 | 结构化数据 (字符串, 数字, 日期) | 向量 (高维浮点数数组) |
| 查询方式 | 精确匹配 / 关键词匹配 | 近似最近邻搜索 (ANN) |
| 查询语句 | WHERE name = '阿威' 或 WHERE content LIKE '%AI%' |
find_similar_vectors(query_vector, top_k=5) |
| 回答的问题 | “是什么?” / “有没有?” | “像什么?” |
| 核心价值 | 数据的精确存储和事务一致性 | 海量非结构化数据的高效语义检索 |
传统数据库的索引(比如B-Tree),是为了加速“精确查找”而设计的。而向量数据库的核心,是一种叫做**近似最近邻(Approximate Nearest Neighbor, ANN)**的搜索算法。
ANN算法非常聪明,它不会傻乎乎地进行暴力比对,而是通过一些预处理的手段,构建一个巧妙的索引结构。比如,一种流行的算法叫HNSW(Hierarchical Navigable Small World),你可以把它想象成:
为所有的向量建立一个高效的“社交网络”。 意思相近的向量,就像是“好朋友”,它们之间有捷径可以互相访问。当一个新的查询向量进来时,算法会从一个随机的“入口”开始,不断地在网络中“跳跃”,每一次都朝着离目标更近的“朋友群”前进,从而能够极快地找到与目标最相似的那一小撮向量,而无需访问整个数据集。
有了向量数据库,我们就可以把成千上万份文档,先用Embedding模型“翻译”成向量,然后全部存入向量数据库。当用户提问时,我们只需要把用户的问题也翻译成一个向量,然后拿着这个向量去数据库里“按图索骥”,就能在毫秒之间,找到与问题最相关的原始文档片段。
RAG:三剑客合体,打造AI的“开卷考试”模式
好了,现在三位剑客已经全部集结完毕。当它们合体时,就构成了当今AI应用开发领域最重要、最主流的模式之一——RAG(Retrieval-Augmented Generation,检索增强生成)。
RAG的核心思想,就是把LLM的回答模式,从“闭卷考试”(只依赖自己脑子里的旧知识),变成了“开卷考试”(可以先查阅外部资料,再结合自己的理解来回答)。
这个“开卷考试”的流程,就是三剑客的完美协作:
这个流程,我们来拆解一下:
- Embedding提问:当用户提出问题时,我们首先调用Embedding模型,将用户的问题文本转换成一个查询向量。
- 向量数据库检索:我们拿着这个查询向量,去向量数据库中执行一个相似度搜索,找出与它最“像”的Top-K个(比如K=3)文档片段向量,并取回它们对应的原始文本片段。
- 构建增强Prompt:这是最关键的一步!我们不再直接把用户的问题扔给LLM,而是精心构造一个新的Prompt。这个Prompt里包含了:
- 背景信息(Context):我们从向量数据库里检索出的那几个最相关的文档片段。
- 原始问题(Question):用户最初的提问。
- 指令(Instruction):明确告诉LLM,“请你基于我提供的背景信息来回答这个问题”。
- 调用LLM生成回答:最后,我们把这个“信息量爆炸”的增强Prompt发送给LLM。LLM此时就从一个需要“回忆”的考生,变成了一个只需要做“阅读理解”的考生。它会结合你提供的精准资料,生成一个事实性强、准确度高的回答。
通过RAG,我们完美地解决了LLM的两大痛点:
- 知识局限性:我们可以随时更新向量数据库里的知识,让AI的知识库永不过时。
- 幻觉问题:由于回答被限定在提供的背景信息内,AI“一本正经胡说八道”的概率被大大降低了。
动手时间:亲手感受Embedding和向量的魔力
理论说了这么多,是不是手痒了?阿威我最懂你们工程师了,Talk is cheap, show me the code!
下面,我们就用一个完整且可执行的Python代码示例,来亲手体验一下,如何将文本转换成Embedding向量,并计算它们之间的余弦相似度。
准备工作:
- 确保你安装了Python。
- 安装必要的库:
pip install openai scikit-learn numpy python-dotenv - 获取你的OpenAI API Key,并在你的项目根目录下创建一个名为
.env的文件,内容如下:
(记住,永远不要把API Key硬编码在代码里!)OPENAI_API_KEY="sk-YourSuperSecretApiKey"
代码来了 (chapter2_demo.py):
import os
from dotenv import load_dotenv
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# --- 1. 初始化和设置 ---
# 加载 .env 文件中的环境变量
load_dotenv()
# 确保 OPENAI_API_KEY 已经设置
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("请设置 OPENAI_API_KEY 环境变量")
# 初始化 OpenAI 客户端
# 这是与 OpenAI API 交互的推荐方式
client = OpenAI(api_key=api_key)
# --- 2. 核心功能函数 ---
def get_embedding(text: str, model="text-embedding-3-small") -> list[float]:
"""
使用 OpenAI 的 Embedding API 将文本转换为向量。
"""
# 替换换行符,OpenAI 建议这样做以获得更好的结果
text = text.replace("\n", " ")
try:
response = client.embeddings.create(input=[text], model=model)
return response.data[0].embedding
except Exception as e:
print(f"获取Embedding时出错: {e}")
return []
# --- 3. 演示与执行 ---
if __name__ == "__main__":
print("--- 欢迎来到阿威的Embedding与向量相似度演示 ---")
# 我们的“迷你知识库”
corpus = [
"国王是一个国家的男性统治者。",
"女王是一个国家的女性统治者。",
"香蕉是一种黄色的长条形水果。",
"今天的天气真不错,适合出去散步。",
"AI正在改变世界,尤其是在自然语言处理领域。"
]
print("\n[步骤1] 正在为我们的迷你知识库生成Embedding向量...")
# 为知识库中的每句话生成向量
corpus_embeddings = [get_embedding(sentence) for sentence in corpus]
# 过滤掉可能失败的embedding
valid_indices = [i for i, emb in enumerate(corpus_embeddings) if emb]
corpus = [corpus[i] for i in valid_indices]
corpus_embeddings = [emb for emb in corpus_embeddings if emb]
if not corpus_embeddings:
print("无法生成任何Embedding,请检查API Key或网络连接。")
exit()
print("生成完毕!知识库现在已经被“数学化”了。")
# 用户的查询
query = "一个国家的君主是谁?"
print(f"\n[步骤2] 用户查询: '{query}'")
print("正在为用户查询生成Embedding向量...")
query_embedding = get_embedding(query)
if not query_embedding:
print("无法为查询生成Embedding,程序退出。")
exit()
print("生成完毕!")
print("\n[步骤3] 计算查询与知识库中每句话的余弦相似度...")
# scikit-learn的cosine_similarity需要2D数组,所以我们reshape
# query_embedding reshape成 (1, n_features)
# corpus_embeddings 是一个 (n_samples, n_features) 的列表
similarities = cosine_similarity(
np.array(query_embedding).reshape(1, -1),
np.array(corpus_embeddings)
)[0] # [0] 是因为结果是一个嵌套数组 [[...]]
# 将句子和它们的相似度配对并排序
results = sorted(
zip(corpus, similarities),
key=lambda item: item[1],
reverse=True
)
print("\n--- 检索结果 (按相似度从高到低排序) ---")
for sentence, score in results:
print(f"相似度: {score:.4f} | 句子: {sentence}")
print("\n--- 阿威的解读 ---")
print("看到了吗?尽管用户的查询'一个国家的君主是谁?'在字面上与'国王'或'女王'的句子完全不同,")
print("但Embedding模型理解了它们在'语义'上的高度相关性,所以给了它们最高的相似度分数!")
print("而与'香蕉'或'天气'相关的句子,分数就低得多。这就是语义搜索的魔力!")
如何运行和解读?
- 在终端里运行
python chapter2_demo.py。 - 观察输出结果。你会惊奇地发现,尽管用户的查询是“一个国家的君主是谁?”,但相似度最高的句子是“国王是一个国家的男性统治者。”和“女王是一个国家的女性统治者。”,而与“香蕉”或“天气”的句子的相似度则非常低。
没错,你没看错! 这就是Embedding的威力。它超越了简单的关键词匹配,实现了真正的语义理解。
本章小结:三剑客,AI记忆的基石
今天我们啃下了一块硬骨头,但收获是巨大的。让我们再次向这三位伟大的剑客致敬:
- Embedding:神奇的“翻译官”,把世间万物翻译成AI能懂的数学语言,并保留其深层含义。
- 向量 (Vector):万物在语义空间的“GPS坐标”,一个由数字组成的、可计算的“数学身份证”。
- 向量数据库:存储和高效检索海量“GPS坐标”的“超级索引”,AI的长期记忆海马体。
当它们三位一体,就构成了强大的 RAG(检索增强生成) 模式,让AI从一个“闭卷考生”升级为“开卷学霸”,能够基于我们提供的私有知识,给出精准、可靠的回答。
到这里,我们已经把AI应用开发最核心的理论地基给夯实了。你现在已经不再是那个站在门外观望的小白,你已经掌握了AI应用的核心逻辑。
从下一章开始,我们将正式从理论转向实践。我们将请出另一位大神——LangChain,AI应用开发的“瑞士军刀”。我们将学习如何使用这个强大的框架,把我们今天学到的所有理论串联起来,真正开始构建我们的第一个AI应用。
准备好,把你的代码编辑器打开,真正的战斗,即将打响!
我们下期见。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 61
61 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)