Dify RAG混合检索基于权重重排
Dify RAG混合检索系统采用语义检索与全文检索相结合的方式,通过权重重排优化结果。语义检索基于向量空间模型计算余弦相似度,虽能捕获语义信息但存在结果偏差问题。全文检索使用BM25算法(含文档长度归一化但无全局分数归一化)。系统需对BM25分数进行范围归一化后才能与语义检索分数(0-1范围)加权融合。关键词相似度计算采用TF-IDF结合余弦相似度方法,通过结巴分词提取Top10关键词构建稀疏向量
Dify RAG混合检索基于权重重排
1.检索
2.AI生成
检索
语义检索
知识库中每一条文档都转换为向量存储。
查询转换为向量,计算空间距离。
距离计算
欧几里得距离
余弦相似度
优点
1.查询速度快
2.把握同义词等语义信息
缺点
语义被压缩,找到的文档可能不合适。
例如,当用户查询“最新上映的科幻电影推荐”时,可能得到的结果是“科幻电影的历史演变”,虽然从语义上这与科幻电影相关,但并未直接回应用户关于最新电影的查询。
全文检索
重排
所有方式检索的结果都可以使用重排模型进行重排;
如果是混合检索方式:也可以使用权重重要性重排。这可以当做一种重排也可以当做检索的一部分。如果检索中间件支持权重分配,那在检索阶段就可以直接实现。但如果有和检索阶段不同的算分方式,或者不同检索方式得到的检索结果的分数不方便直接加权计算,可以在拿到见多结果后,想办法重新计算相似度分数。
比如想要做不同权重的混合检索,首先想到使用ES的复合查询语句,复合一个keymatcher和一个semanticMathcer, 并且使用boost分配算分后的权重。
ES相似度算法与设置
问题:得到的分数没有归一化
查看当前索引的设置,其中包含了相似度算法的配置。
DSL
在这里插入代码片
ClientAPI
## 配置查询
GetSettingsRequest request = new GetSettingsRequest().indices("index");
request.names("index.number_of_shards");
## 执行查询
GetSettingsResponse getSettingsResponse = client.indices().getSettings(request, requestOptions);
查看某一条查询详细的算分过程。
BM25算法公式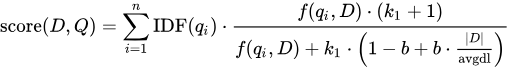
本质依然是用IDF*TF
只不过TF的计算变了花样。
BM25算法在实现过程中确实包含归一化处理,但其归一化主要针对文档长度,而非全局分数范围。以下是详细解答:
- 归一化处理
文档长度归一化:BM25通过参数b对文档长度进行归一化,以平衡长文档和短文档的词频影响。公式中的归一化因子为1 - b + b * (dl / avgdl),其中dl为文档长度,avgdl为平均文档长度。这种处理惩罚了过长的文档,避免其因词频天然较高而获得不合理的高分。
无全局分数归一化:BM25不会将最终相似度分数缩放到固定范围(如0-1),不同查询的分数范围可能差异较大。
- 相似度分数范围
理论范围:分数通常为正数,理论上无严格上限,但实际范围取决于数据集和参数设置:
IDF部分:始终为正(因IDF公式设计避免负值),罕见词IDF值较高。
TF部分:通过参数k1抑制高频词的过度影响,得分有限增长。
实际表现:常见场景中分数多为几十到几百,但特定情况下(如罕见词多次出现)可能更高。
示例说明
高得分场景:若查询含罕见词(高IDF),且某文档多次出现该词(高TF),则得分显著升高。
低得分场景:常见词(低IDF)或匹配次数少(低TF)时得分较低。
总结
BM25通过文档长度归一化缓解长度偏差,但相似度分数无全局标准化,范围不固定,通常为正数,实际值由数据特征和参数(k1, b)共同决定。
因此, BM25算法得到的分数依然是没有被归一化在【0,1】范围内的。
而语义检索的分数范围是【0,1】只内的。所以直接堆着两个分数做加权是不合情理的。需要对全文检索后的分数坐范围的归一化。
Dify中关键词相似度计算方式:
def _calculate_keyword_score(self, query: str, documents: list[Document]) -> list[float]:
"""
Calculate BM25 scores
:param query: search query
:param documents: documents for reranking
:return:
"""
keyword_table_handler = JiebaKeywordTableHandler()
query_keywords = keyword_table_handler.extract_keywords(query, None)
documents_keywords = []
for document in documents:
# get the document keywords
document_keywords = keyword_table_handler.extract_keywords(document.page_content, None)
if document.metadata is not None:
document.metadata["keywords"] = document_keywords
documents_keywords.append(document_keywords)
# Counter query keywords(TF)
query_keyword_counts = Counter(query_keywords)
# total documents
total_documents = len(documents)
# calculate all documents' keywords IDF
all_keywords = set()
for document_keywords in documents_keywords:
all_keywords.update(document_keywords)
keyword_idf = {}
for keyword in all_keywords:
# calculate include query keywords' documents
doc_count_containing_keyword = sum(1 for doc_keywords in documents_keywords if keyword in doc_keywords)
# IDF
keyword_idf[keyword] = math.log((1 + total_documents) / (1 + doc_count_containing_keyword)) + 1
query_tfidf = {}
for keyword, count in query_keyword_counts.items():
tf = count
idf = keyword_idf.get(keyword, 0)
query_tfidf[keyword] = tf * idf
# calculate all documents' TF-IDF
documents_tfidf = []
for document_keywords in documents_keywords:
document_keyword_counts = Counter(document_keywords)
document_tfidf = {}
for keyword, count in document_keyword_counts.items():
tf = count
idf = keyword_idf.get(keyword, 0)
document_tfidf[keyword] = tf * idf
documents_tfidf.append(document_tfidf)
def cosine_similarity(vec1, vec2):
intersection = set(vec1.keys()) & set(vec2.keys())
numerator = sum(vec1[x] * vec2[x] for x in intersection)
sum1 = sum(vec1[x] ** 2 for x in vec1)
sum2 = sum(vec2[x] ** 2 for x in vec2)
denominator = math.sqrt(sum1) * math.sqrt(sum2)
if not denominator:
return 0.0
else:
return float(numerator) / denominator
similarities = []
for document_tfidf in documents_tfidf:
similarity = cosine_similarity(query_tfidf, document_tfidf)
similarities.append(similarity)
# for idx, similarity in enumerate(similarities):
# print(f"Document {idx + 1} similarity: {similarity}")
return similarities
如何用向量表达:每一个维度代表一个词对应的TFIDF分数。理论上对此表中每一个词计算分数,但是这样会很稀疏,所以首先用一个通用的分词器得到前10个关键词。以这些关键词代替词表。因此,向量中的一个维度就是代表一个关键词的TFIDF分数。
- 首先使用结巴分词分别得到查询和每一篇文档的前10个关键词。
Query=“有氧运动” => Query_KeyWords = [“有氧”, “运动”]
Documents=[“”, “”] =》DocumentKeywords_List = [[“有氧”, “运动”]]
2 得到全部文档的关键词集合,在这堆文档内,对每一个关键词计算IDF。这一步可以粗略看做得到一份关键词重要性映射表,这是在查询和文档中都通用的。
{
} - 计算查询的向量表达:对查询中的每一个关键字,用TFIDF(IDF=该关键词在上一步得到的关键词重要性映射表中对应的重要性)。如果查询中的关键词不在这个映射表里,就记IDF=0。含义:{关键词:关键词出现的次数关键词重要性}
- 同样,对每一篇文档需要得到一个向量表达: 每一篇中的每一个关键字用同样的方式计算TF*IDF(IDFB不可能为0)
- 接下去就要查询的向量表达和每一篇文档的向量表达的相似度,但是两者的维度是不一样的
余弦相似度: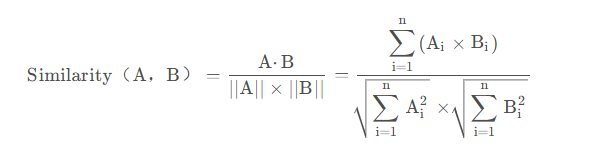
两个词典取共同拥有的维度(即双方都有的一个关键词对应的分数)。
向量相似度重计算
召回阶段
1.选择文本检索, 按关键词检索召回10条。无需重排。
2.选择语义检索,按向量检索召回10条。无需重排。
3.选择混合检索,按关键词检索召回10条, 按向量检索召回10条,共计<=20条。需要重排。
重排阶段
1.选择按权重重排。
2.选择用模型重排。
召回
- 关键词检索TOPK
- 向量检索TOPK文档
- 得到<TOP2K文档集合
重排
重排模式:
- 按权重重排
- 按模型重排
权重重排
模型重排

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)