常见的 AI 模型格式以及如何学习AI大模型
过去两年,开源 AI 社区一直在热烈讨论新 AI 模型的开发。每天都有越来越多的模型在Hugging Face上发布,并被用于实际应用中。然而,开发者在使用这些模型时面临的一个挑战是。我们将分析每种格式的,并提供,帮助你选择最适合的格式。
过去两年,开源 AI 社区一直在热烈讨论新 AI 模型的开发。每天都有越来越多的模型在Hugging Face上发布,并被用于实际应用中。然而,开发者在使用这些模型时面临的一个挑战是模型格式的多样性。
在本文中,我们将探讨当下常见的 AI 模型格式,包括:
- GGUF
- PyTorch
- Safetensors
- ONNX
我们将分析每种格式的优缺点,并提供使用建议,帮助你选择最适合的格式。
GGUF
GGUF 最初是为llama.cpp项目开发的。GGUF 是一种二进制格式,旨在实现快速的模型加载和保存,并易于阅读。模型通常使用 PyTorch 或其他框架开发,然后转换为 GGUF 格式以与 GGML 一起使用。
随着时间的推移,GGUF 已成为开源社区中共享 AI 模型最流行的格式之一。它得到了许多知名推理运行时的支持,包括 llama.cpp、ollama和vLLM。
目前,GGUF 主要用于语言模型。虽然也可以将其用于其他类型的模型,例如通过stable-diffusion.cpp实现的扩散模型,但这并不像在语言模型中的应用那样普遍。
GGUF 文件包含以下部分:
- 一个以键值对组织的元数据部分。该部分包含有关模型的信息,例如其架构、版本和超参数。
- 一个张量元数据部分。该部分包括模型中张量的详细信息,例如它们的形状、数据类型和名称。
- 最后,一个包含张量数据本身的部分。

GGUF 格式和 GGML 库还提供了灵活的量化方案,能够在保持良好精度的同时实现高效的模型存储。一些最常见的量化方案包括:
Q4_K_M:大多数张量被量化为 4 位,部分张量被量化为 6 位。这是最常用的量化方案。IQ4_XS:几乎所有张量都被量化为 4 位,但借助重要性矩阵。该矩阵用于校准每个张量的量化,可能在保持存储效率的同时提高精度。IQ2_M:类似于IQ4_XS,但使用 2 位量化。这是最激进的量化方案,但在某些模型上仍能实现良好的精度。它适用于内存非常有限的硬件。Q8_0:所有张量都被量化为 8 位。这是最不激进的量化方案,提供几乎与原始模型相同的精度。
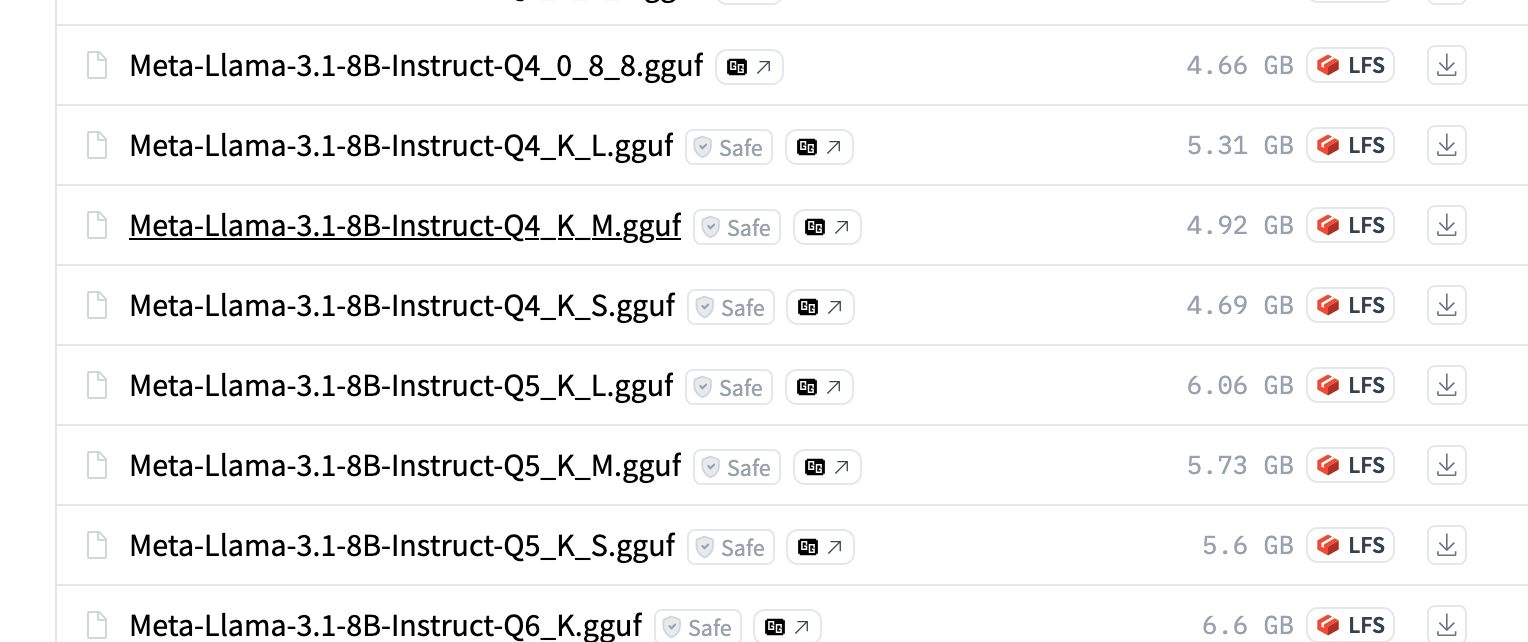
GGUF 格式的 Llama-3.1 8B 模型示例
让我们回顾一下 GGUF 的优缺点:
- 优点:
- 简单:单文件格式易于共享和分发。
- 快速:通过与
mmap()的兼容性实现模型的快速加载和保存。 - 高效:提供灵活的量化方案。
- 便携:作为一种二进制格式,无需特定库即可轻松读取。
- 缺点:
- 大多数模型需要从其他格式(如 PyTorch、Safetensors)转换为 GGUF。
- 并非所有模型都可转换。部分模型不受 llama.cpp 支持。
- 模型保存为 GGUF 格式后,修改或微调并不容易。
GGUF 主要用于生产环境中的模型服务,其中快速加载时间至关重要。它也用于开源社区内的模型共享,因为其格式简单,便于分发。
有用资源:
- llama.cpp项目,提供了将 HF 模型转换为 GGUF 的脚本。
- gguf-my-repo空间允许在不下载到本地的情况下将模型转换为 GGUF 格式。
- ollama和HF-ollama 集成支持通过
ollama run命令运行 HF Hub 上的任何 GGUF 模型。
PyTorch (.pt/.pth)
.pt/.pth 扩展名代表 PyTorch 的默认序列化格式,存储包含学习参数(权重、偏置)、优化器状态和训练元数据的模型状态字典。
PyTorch 模型可以保存为两种格式:
- .pt:此格式保存整个模型,包括其架构和学习参数。
- .pth:此格式仅保存模型的状态字典,其中包括模型的学习参数和一些元数据。
PyTorch 格式基于 Python 的pickle模块,该模块用于序列化 Python 对象。为了理解 pickle 的工作原理,让我们看以下示例:
import pickle
model_state_dict = { "layer1": "hello", "layer2": "world" }
pickle.dump(model_state_dict, open("model.pkl", "wb"))
The pickle.dump() 函数将 model_state_dict 字典序列化并保存到名为 model.pkl. 的文件中。输出文件现在包含字典的二进制表示:

model.pkl hex view
要将序列化的字典加载回 Python,我们可以使用 pickle.load() 函数:
import pickle
model_state_dict = pickle.load(open("model.pkl", "rb"))
print(model_state_dict)
# Output: {'layer1': 'hello', 'layer2': 'world'}
如你所见,pickle 模块提供了一种简单的方法来序列化 Python 对象。然而,它也有一些局限性:
- 安全性:任何东西都可以被 pickle,包括恶意代码。如果序列化数据未经过适当验证,这可能会导致安全漏洞。例如,Snyk 的这篇文章解释了pickle 文件如何被植入后门。
- 效率:它不支持延迟加载或部分数据加载。这可能导致在处理大型模型时加载速度慢和内存使用率高。
- 可移植性:它是特定于 Python 的,这使得与其他语言共享模型变得具有挑战性。
如果你仅在 Python 和 PyTorch 环境中工作,PyTorch 格式可能是一个合适的选择。然而,近年来,AI 社区一直在转向更高效和安全的序列化格式,例如 GGUF 和 Safetensors。
有用资源:
- PyTorch 文档关于保存和加载模型。
- executorch项目,提供了一种将 PyTorch 模型转换为
.pte的方法,这些模型可在移动和边缘设备上运行。
Safetensors
由 Hugging Face 开发的safetensors解决了传统 Python 序列化方法(如 PyTorch 使用的 pickle)中存在的安全性和效率问题。该格式使用受限的反序列化过程来防止代码执行漏洞。
一个 safetensors 文件包含:
-
以 JSON 格式保存的元数据部分。该部分包含模型中所有张量的信息,例如它们的形状、数据类型和名称。它还可以选择性地包含自定义元数据。
-
张量数据部分。
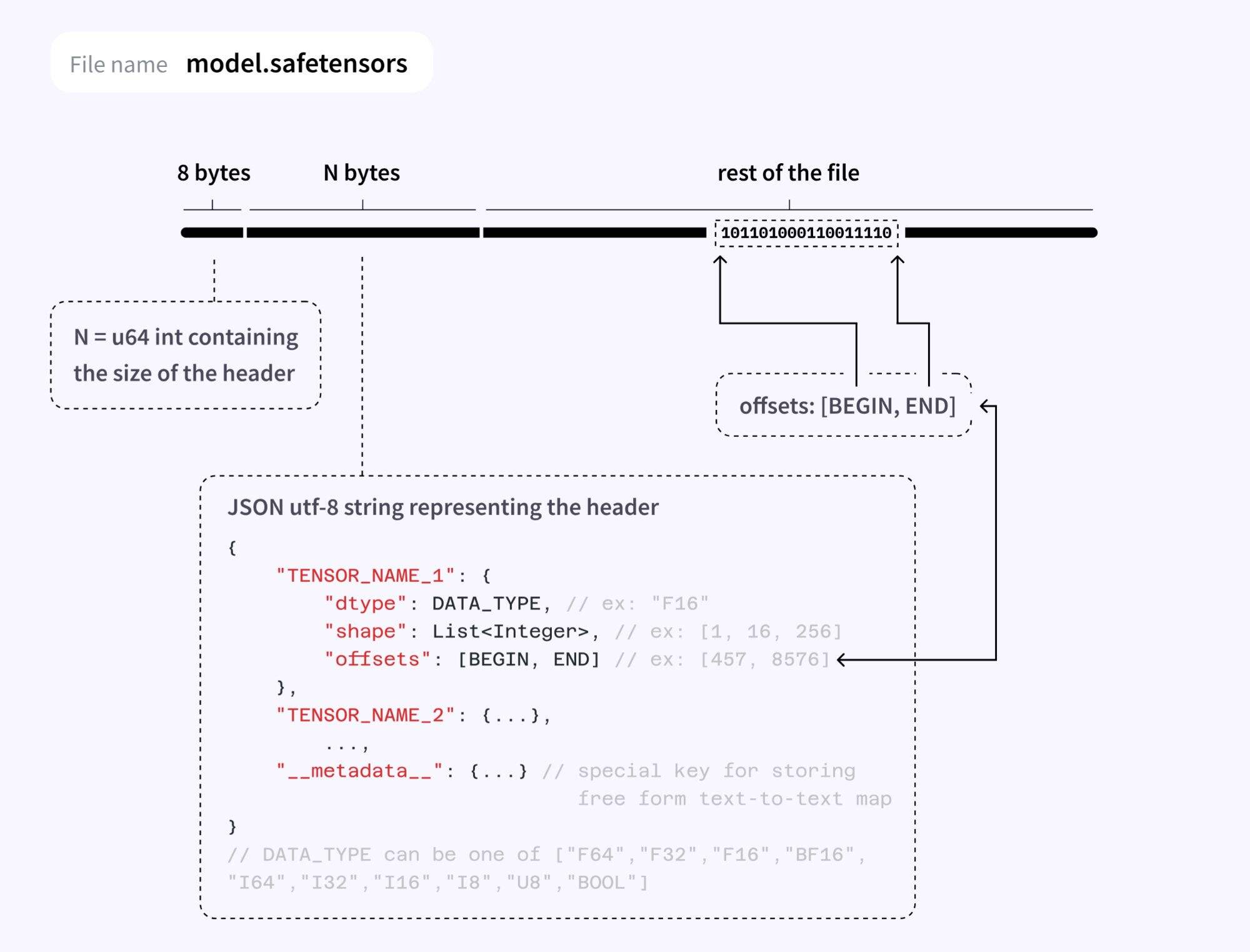
Safetensors 格式结构图
-
优点:
- 安全:Safetensors 采用受限的反序列化过程来防止代码执行漏洞。
- 快速:它支持延迟加载和部分数据加载,从而可以加快加载速度并降低内存使用率。这与 GGUF 类似,你可以使用
mmap()映射文件。 - 高效:支持量化张量。
- 可移植:它设计为跨编程语言可移植,使得与其他语言共享模型变得容易。
-
缺点:
- 量化方案不如 GGUF 灵活。这主要是由于 PyTorch 提供的量化支持有限。
- 需要 JSON 解析器来读取元数据部分。这在处理像 C++ 这样的低级语言时可能会出现问题,因为这些语言没有内置的 JSON 支持。
注意:虽然在理论上元数据可以保存在文件中,但在实践中,模型元数据通常存储在一个单独的 JSON 文件中。这既可能是优点也可能是缺点,具体取决于使用场景。
safetensors 格式是 Hugging Face 的transformers库使用的默认序列化格式。它在开源社区中广泛用于共享、训练、微调和部署 AI 模型。Hugging Face 上发布的新模型都以 safetensors 格式存储,包括 Llama、Gemma、Phi、Stable-Diffusion、Flux 等许多模型。
有用资源:
- transformers库关于保存和加载模型的文档。
- bitsandbytes 指南关于如何量化模型并将其保存为 safetensors 格式。
- mlx-community组织在 HF 上提供与 MLX 框架(Apple 芯片)兼容的模型。
ONNX
开放神经网络交换(Open Neural Network Exchange,ONNX)格式提供了一种与供应商无关的机器学习模型表示方法。它是ONNX 生态系统的一部分,该生态系统包括用于不同框架(如 PyTorch、TensorFlow 和 MXNet)之间互操作的工具和库。
ONNX 模型以 .onnx 扩展名的单个文件保存。与 GGUF 或 Safetensors 不同,ONNX 不仅包含模型的张量和元数据,还包含模型的计算图。
在模型文件中包含计算图使得在处理模型时具有更大的灵活性。例如,当发布新模型时,你可以轻松地将其转换为 ONNX 格式,而无需担心模型的架构或推理代码,因为计算图已经保存在文件中。
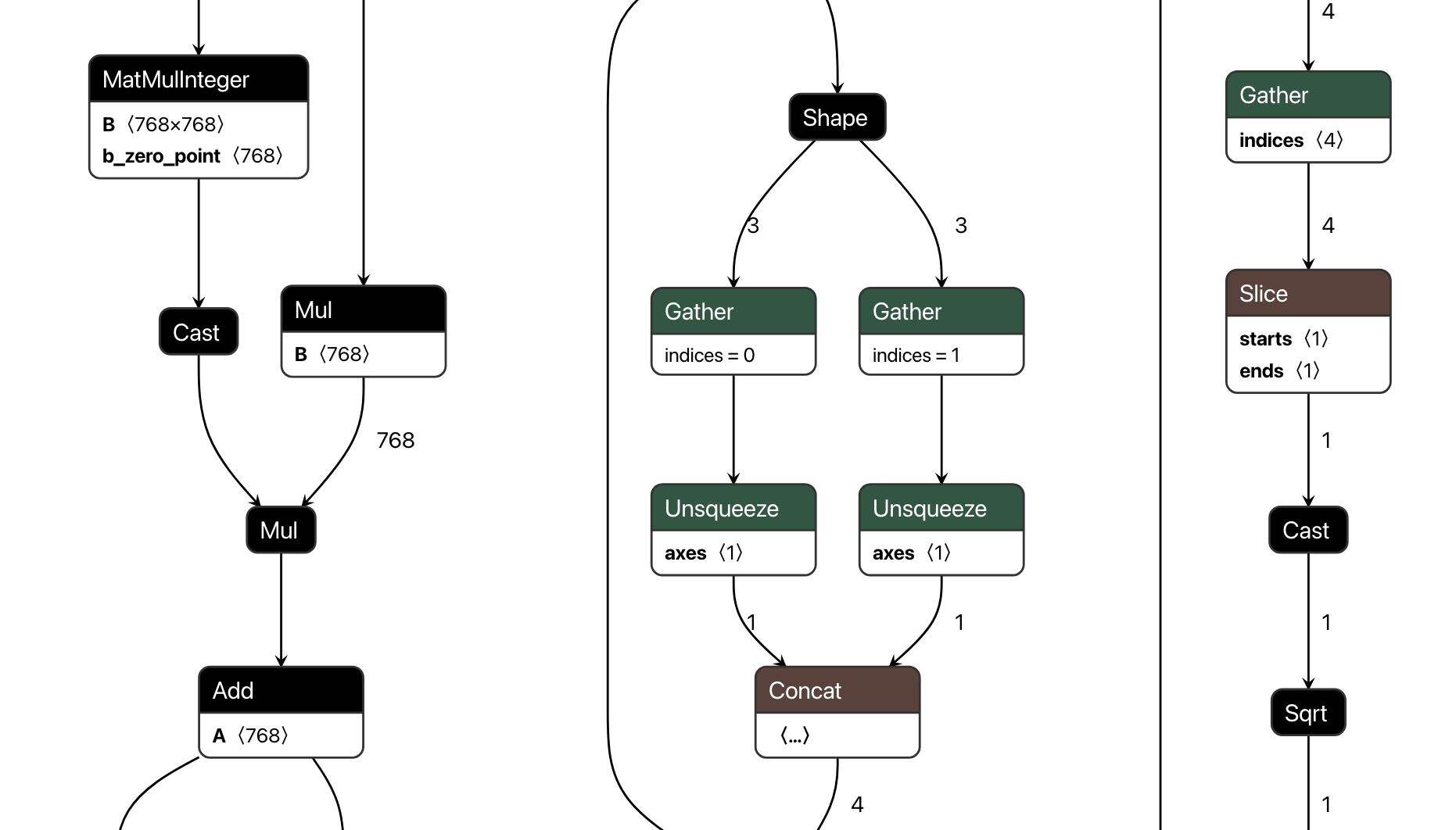
ONNX 格式的计算图示例,由Netron生成
- 优点:
- 灵活性:在模型文件中包含计算图使得在不同框架之间转换模型时更加灵活。
- 可移植性:得益于 ONNX 生态系统,ONNX 格式可以轻松部署在各种平台和设备上,包括移动设备和边缘设备。
- 缺点:
- 对量化张量的支持有限。ONNX 本身不支持量化张量,而是将它们分解为整数张量和比例因子张量。这可能导致在处理量化模型时质量下降。
- 复杂架构可能需要为不支持的层使用操作符回退或自定义实现。这可能会在将模型转换为 ONNX 格式时导致性能损失。
总体而言,如果你正在处理移动设备或浏览器内推理,ONNX 是一个不错的选择。
有用资源:
- onnx-community组织在 HF 上提供 ONNX 格式的模型以及转换指南。
- transformer.js项目,允许在浏览器中使用 WebGPU 或 WebAssembly 运行 ONNX 模型。
- onnxruntime项目,提供在各种平台和硬件上的高性能推理引擎。
- netron项目,允许在浏览器中可视化 ONNX 模型。
硬件支持
在选择模型格式时,重要的是要考虑模型将部署在哪种硬件上。下表显示了每种格式的硬件支持建议:
| 硬件 | GGUF | PyTorch | Safetensors | ONNX |
|---|---|---|---|---|
| CPU | ✅ (最佳) | 🟡 | 🟡 | ✅ |
| GPU | ✅ | ✅ | ✅ | ✅ |
| 移动设备部署 | ✅ | 🟡 (通过 executorch) | ❌ | ✅ |
| Apple 芯片 | ✅ | 🟡 | ✅ (通过 MLX 框架) | ✅ |
说明:
- ✅: 完全支持
- 🟡: 部分支持或性能较低
- ❌: 不支持
结论
在本文中,我们探讨了当今使用的一些常见 AI 模型格式,包括 GGUF、PyTorch、Safetensors 和 ONNX。每种格式都有其自身的优缺点,因此根据具体的用例和硬件需求选择合适的格式至关重要。
脚注
mmap:内存映射文件是一种操作系统功能,允许将文件映射到内存中。这对于在不将整个文件加载到内存中的情况下读写大文件非常有益。
延迟加载(lazy-loading):延迟加载是一种技术,它将数据的加载推迟到实际需要时。这有助于在处理大型模型时减少内存使用并提高性能。
计算图(computation graph):在机器学习的上下文中,计算图是一种流程图,展示了数据如何通过模型流动以及每一步如何执行不同的计算(例如加法、乘法或激活函数的应用)。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击文章底部名片大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程
200本大模型PDF书籍
👉学会后的收获:👈
- 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
- 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
- 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
- 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集
大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以点击下方名片保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)