论文精读(5)——NSA 论文详解
目前主流的架构都在处理大模型长上下文的建模问题,因为这会导致Transformer内存太大;前面我所总结的的论文精读:Titans曾提到其中一个方向是稀疏注意力的方法,而正巧的是NSA和MoBA都提到了这一技术
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
前言
目前主流的架构都在处理大模型长上下文的建模问题,因为这会导致Transformer内存太大;前面我所总结的的论文精读:Titans曾提到其中一个方向是稀疏注意力的方法,而正巧的是NSA和MoBA都提到了这一技术,因此我会对他们进行讲解和总结
NSA主要的方法是采用动态分层的稀疏策略,结合粗粒度的token压缩和细粒度token选择相结合的方式,同样为了适配硬件本身,实现了hardware-algorithm co-design,是目前跨越式的升级
Introduction
这里可以直接看我总结的图: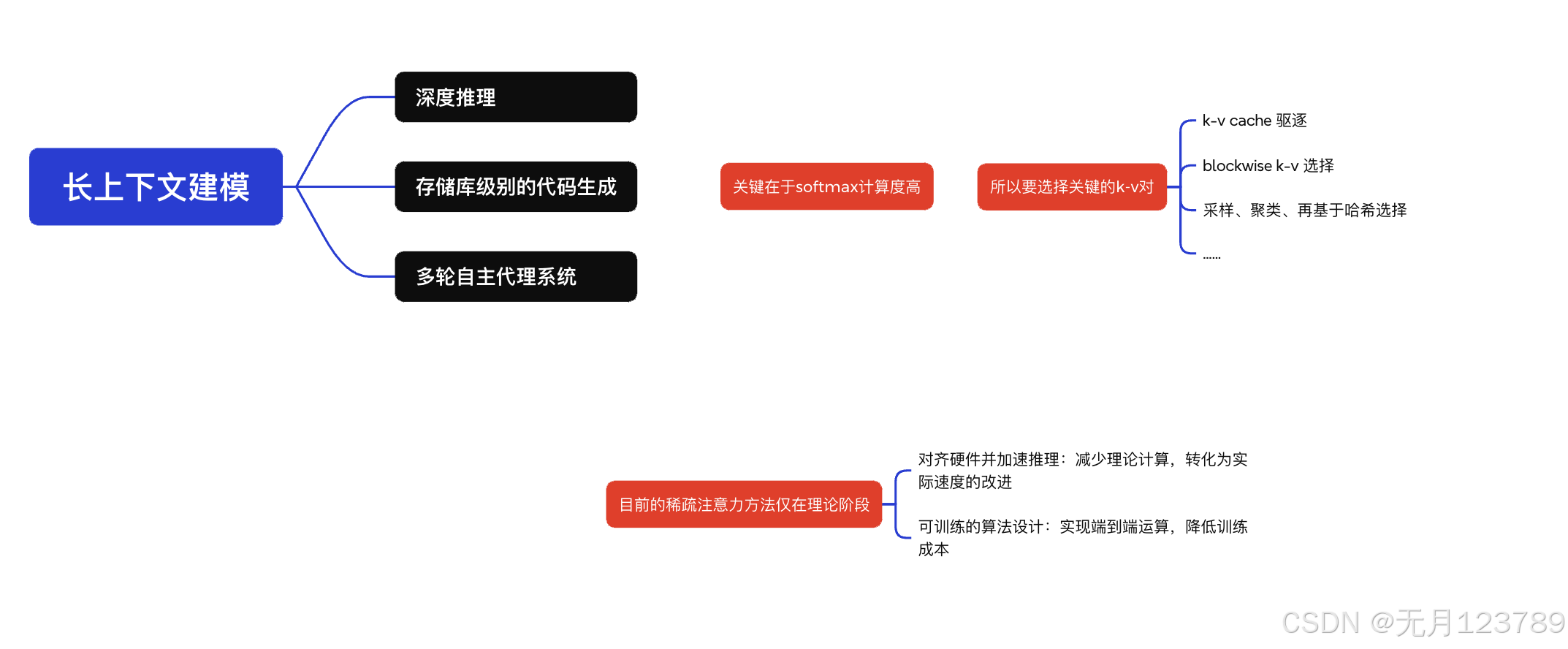
在这里NSA将k-v组织到临时块,并通过三条注意力路径减少每个q的计算:压缩粗粒度的tokens,选择性保留细粒度tokens,本地上下文信息滑动窗口;
评估结果与全量微调相当或更好的性能;并在解码、前向和反向传播阶段加速显著
Rethinking Sparse Attention Methods
- The illusion of efficient inference:主要有两大挑战
-
phase-restricted sparsity : 有的只在解码期间采用稀疏方法,还要在预填充期间做密集型处理; 有的只关注预填充稀疏型; 只做到了阶段的专业化
-
incompatibility with advanced attention architecture : 一些稀疏注意力的方法无法适应现有的解码高效架构
- The myth of trainable sparsity
-
performance degradation : 预训练后使用稀疏会偏离其预训练轨迹
-
training efficiency demands : 有效处理长上下文至关重要, 目前的方法仅专注于推理阶段
此外,在训练期间采用稀疏注意力也存在难点:
-
non-trainable components : 离散运算中一些不可训练的组件会阻止梯度通过标记选择过程
-
inefficient back-propagation : 硬件的利用率低会显著降低训练效率
Methodology
Background
首先还是回顾attention的计算逻辑:对于长度为t的序列,会有如下计算式子:
Attn ( q t , k : t , v : t ) = ∑ i = 1 t α t , i v i ∑ j = 1 t α t , j , α t , i = e q t ⊤ k i d k \text{Attn}\left(\mathbf{q}_t, \mathbf{k}_{:t}, \mathbf{v}_{:t}\right) = \sum_{i=1}^{t} \frac{\alpha_{t,i} \mathbf{v}_i}{\sum_{j=1}^{t} \alpha_{t,j}}, \quad \alpha_{t,i} = e^{\frac{\mathbf{q}_t^\top \mathbf{k}_i}{\sqrt{d_k}}} Attn(qt,k:t,v:t)=i=1∑t∑j=1tαt,jαt,ivi,αt,i=edkqt⊤ki
这里用了 α t , i = e q t ⊤ k i d k \alpha_{t,i} = e^{\frac{\mathbf{q}_t^\top \mathbf{k}_i}{\sqrt{d_k}}} αt,i=edkqt⊤ki来表示注意力权重:随着序列长度的提升,计算开销就会提升,逐渐变成二次平方复杂度
还有个定义为Arithmetic Intensity,是计算作为内存访问的比例:会给定义一个阈值,当高于阈值就是计算限制;低于阈值就是内存限制
Overall framework
首先大体说下NSA的整体流程:第一步是先将k,v重新用自定义的函数表示,至于是怎么表示呢后面会讲:
K ~ t = f K ( q t , k : t , v : t ) , V ~ t = f V ( q t , k : t , v : t ) \tilde{K}_t = f_K(\mathbf{q}_t, \mathbf{k}_{:t}, \mathbf{v}_{:t}), \quad \tilde{V}_t = f_V(\mathbf{q}_t, \mathbf{k}_{:t}, \mathbf{v}_{:t}) K~t=fK(qt,k:t,v:t),V~t=fV(qt,k:t,v:t)
o t ∗ = Attn ( q t , K ~ t , V ~ t ) \mathbf{o}^*_t = \text{Attn}\left(\mathbf{q}_t, \tilde{K}_t, \tilde{V}_t\right) ot∗=Attn(qt,K~t,V~t)
这里的 K ~ t , V ~ t \tilde{K}_t, \tilde{V}_t K~t,V~t是根据当前查询 q t q_t qt和上下文记忆 k : t k_{:t} k:t, v : t v_{:t} v:t动态构建的,这里就可以自定义映射关系;而 o t ∗ \mathbf{o}^*_t ot∗就是注意力输出
o t ∗ = ∑ c ∈ C g t c ⋅ Attn ( q t , K ~ t c , V ~ t c ) . \mathbf{o}^*_t = \sum_{c \in \mathcal{C}} g^c_t \cdot \text{Attn}(\mathbf{q}_t, \tilde{K}^c_t, \tilde{V}^c_t). ot∗=c∈C∑gtc⋅Attn(qt,K~tc,V~tc).
看到k,v上面的c就是自定义的映射关系:C = {cmp, slc, win},也就是压缩(compression)、选择(selection)、滑动窗口(sliding window); g t c g^c_t gtc是门控,利用MLP+ sigmoid来实现对不同策略的权重控制,之后就可以用 N t N_t Nt重新映射的k,v总数:
N t = ∑ c ∈ C size [ K ~ t c ] . N_t = \sum_{c \in \mathcal{C}} \text{size}[\tilde{K}^c_t]. Nt=c∈C∑size[K~tc].
Algorithm Design
首先放张图总结下总体技术~
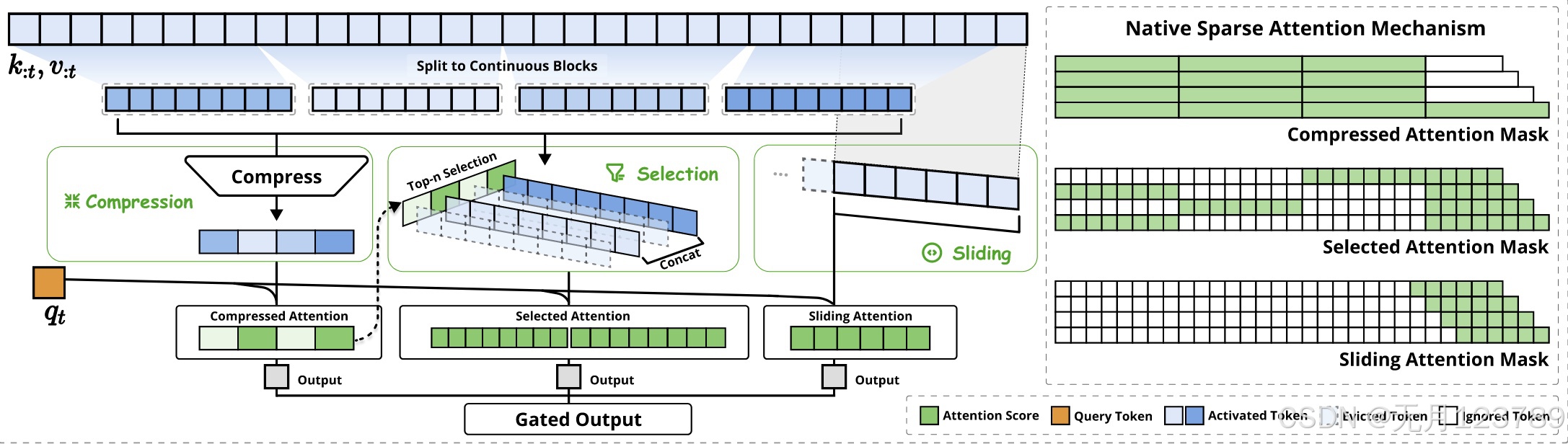
Token compression
先来看看计算式子:
K ~ t cmp = f K cmp ( k : t ) = { φ ( k i d + 1 : i d + l ) | 0 ≤ i ≤ ⌊ t − l d ⌋ } \tilde{K}^{\text{cmp}}_t = f^{\text{cmp}}_K(\mathbf{k}_{:t}) = \left\{ \varphi(\mathbf{k}_{id+1:id+l}) \middle| 0 \leq i \leq \left\lfloor \frac{t-l}{d} \right\rfloor \right\} K~tcmp=fKcmp(k:t)={φ(kid+1:id+l) 0≤i≤⌊dt−l⌋}
是什么意思呢?其实很好理解,就是将token转化为粗粒度表示的block-level,这里的l代表block的长度,d代表相邻块内的滑动步幅,而 φ \varphi φ就是映射函数,这里用的是可学习的MLP;其实就是将块中的键映射为单个压缩的键,根据上图也显然压缩的块有着更明显的粗粒度
Token selection
这一节的讲解会穿插MoBA的一些技术细节,会有对两者技术上的直观对比
在token选择方面,一定选择的是blockwise,这个已经在Flashattention中得到证实
另外的发现是按块分布遵循注意力分数的固有分布模式-> 相邻的key往往具有相似的重要性水平
先决条件满足后,自然的引出第一步:要计算出每个块的重要性分数来判定哪个块比较重要,很显然的会想到softmax~当然,计算式子也是如此:
p t cmp = Softmax ( q t T K ~ t cmp ) \mathbf{p}^{\text{cmp}}_t = \text{Softmax}\left(\mathbf{q}_t^T \tilde{K}^{\text{cmp}}_t\right) ptcmp=Softmax(qtTK~tcmp)
对之前压缩好的token和q做类似attention处理即可;
- 当压缩块和选择块的大小相同时, p t cmp = p t slc \mathbf{p}^{\text{cmp}}_t = \mathbf{p}^{\text{slc}}_t ptcmp=ptslc
- 当大小不同时,计算方式如下:
p t slc [ j ] = ∑ m = 0 l ′ d − 1 ∑ n = 0 l d − 1 p t cmp [ l ′ d j − m − n ] , \mathbf{p}^{\text{slc}}_t[j] = \sum_{m=0}^{\frac{l'}{d}-1} \sum_{n=0}^{\frac{l}{d}-1} \mathbf{p}^{\text{cmp}}_t\left[\frac{l'}{d}j - m - n\right], ptslc[j]=m=0∑dl′−1n=0∑dl−1ptcmp[dl′j−m−n],
别看着很唬人,其实就是双重求和,[]代表的是元素的索引运算,也就是地址啦;然后把各个位置的压缩块求和就是注意力分数~
同样的,为了适应 GQA 或 MQA 的模型,其中键值缓存在查询头之间共享,必须确保这些头之间的块选择一致,以最大限度地减少解码期间的 KV 缓存加载:
p t slc’ = ∑ h = 1 H p t slc , ( h ) . \mathbf{p}^{\text{slc'}}_{t} = \sum_{h=1}^{H} \mathbf{p}^{\text{slc},(h)}_{t}. ptslc’=h=1∑Hptslc,(h).
注意力分数计算完后,就可以用Top-k算法,直接选择概率大的一部分块,也就是稀疏化:
I t = { i ∣ rank ( p t slc’ [ i ] ) ≤ n } \mathcal{I}_t = \{i \mid \text{rank}(\mathbf{p}^{\text{slc'}}_ {t}[i]) \leq n\} It={i∣rank(ptslc’[i])≤n}
K ~ t slc = Cat [ { k i l ′ + 1 : ( i + 1 ) l ′ ∣ i ∈ I t } ] \tilde{K}^{\text{slc}}_t = \text{Cat}\left[\left\{\mathbf{k}_{il'+1:(i+1)l'} \mid i \in \mathcal{I}_t\right\}\right] K~tslc=Cat[{kil′+1:(i+1)l′∣i∈It}]
其中 rank(·) 表示降序排列的排名位置,rank = 1 对应最高分;值(Value)和它同样的过程,拿他再和q做注意力计算就好啦~
这里MoBA是怎么做的呢?其实压缩成block并用Top-k算法基本一致,但有另外的一些细节处理:
-
为了保证自回归模型的因果性,就不能让模型注意到未来块,就得让位置从负无穷开始,门控设置为0,并让pos(q) < i * B; i是第几块,B是块的大小;
-
同样,由于MoBA对块用了池化再和q做内积,池化这个过程也会导致看到未来,因此强制每个token回到带q的token中,并应用因果掩码;
-
对块做了精细化分割;
-
根据数据和训练情况从而动态选择MoBA和full-attention;
仔细看看第二步和第三步,因果掩码是不是很像DeepseekMoE中设置的静态路由,也就是一些专家块一直保持激活;还有精细化块分割也很类似,具体这里的原理可以看看我写的论文精读(3)
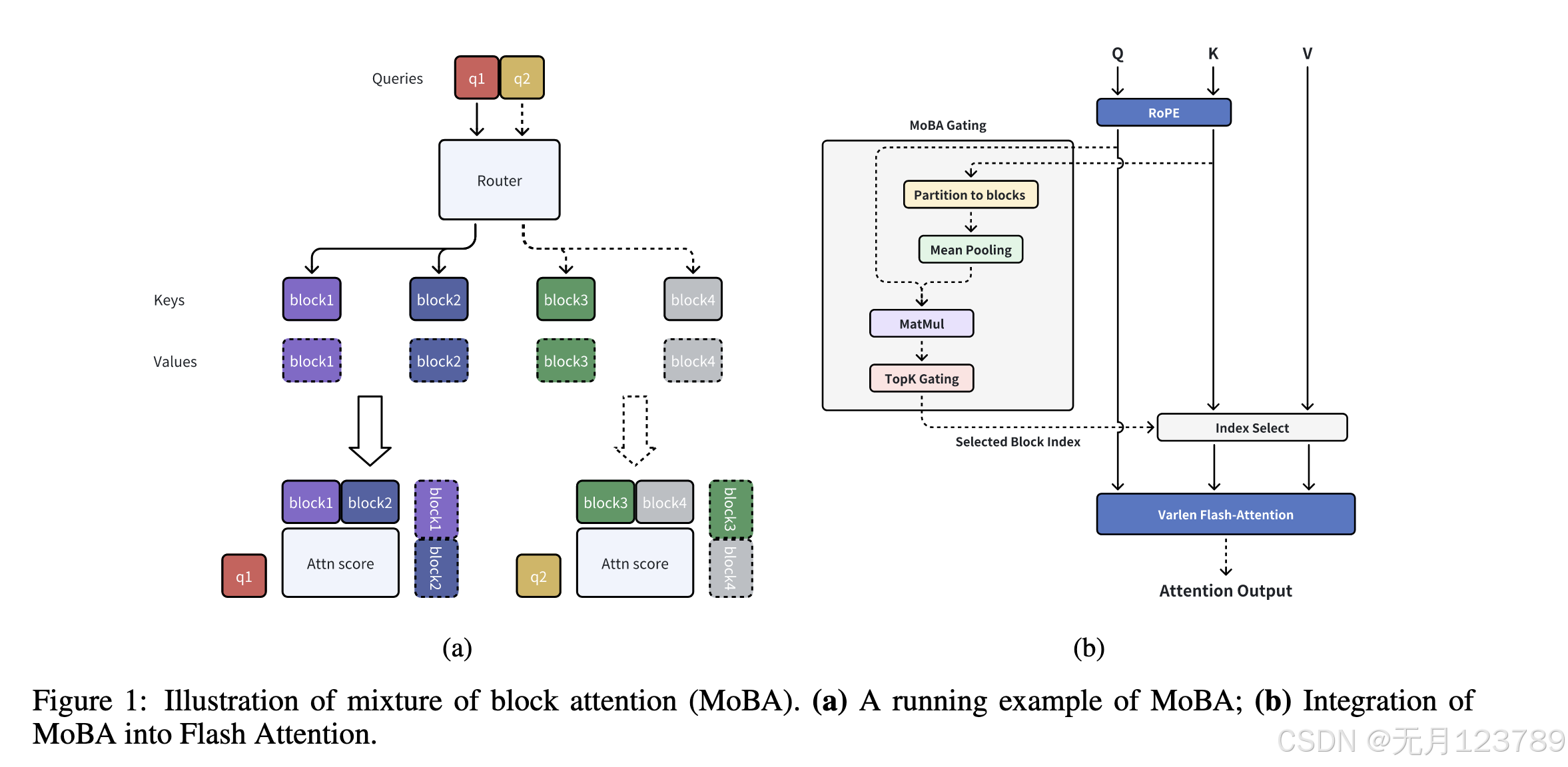
关于这里的技术细节仍有优化,Top-k算法真的合适吗?其实较大的k值提高了准确性但降低了推理性能;较小的k值提升了推理性能但损害了损失性;或许可以根据实际情况来动态调整不同token和不同层的kv预算,那么这篇论文就应运而生了:PSA
这里也有大佬的详细解读,感兴趣的直接看~
难道说NSA就没有技术细节嘛,当然有!那就是kernerl design:
kernerl design
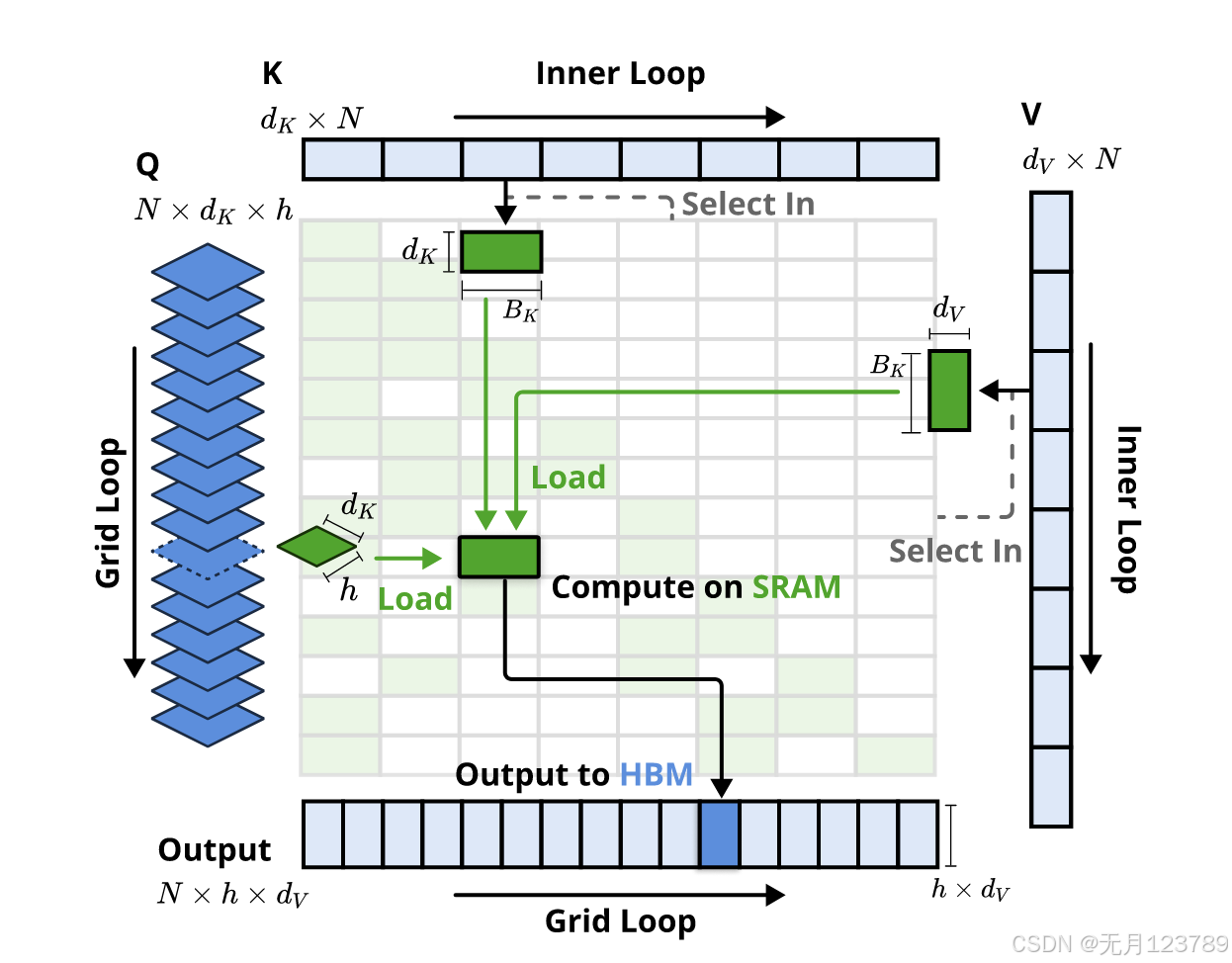
为了实现flashattention级别的加速,重点实现了硬件对齐的稀疏注意力内核,但需要和目前优化的GQA,MQA等架构兼容,因此解决了如下问题:
- 以组为中心的数据加载;对于每个内部循环,在位置 t 处加载组中所有 head 的查询 Q ∈ R[h,dk],它们共享的稀疏键/值块索引 It
- 共享 KV 获取;在内循环中,顺序将 It 索引的连续键值块加载到 SRAM 中
- 网格上的外环;由于不同查询块的内部循环长度(与所选的块数 n 成正比)几乎相同,因此将查询/输出循环放在 Triton 的网格调度器中,以简化和优化内核
如下图所示,可以说几乎完美的实现了hardware-aligned co-design:
最后的Sliding Window就很好理解啦,就是个滑动窗设计,大多数都存在的内容,再次不详细赘述~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)